DiffSinger
1.0.0
تنفيذ Pytorch لـ Diffsinger: غناء التوليف الصوتي عبر آلية الانتشار الضحلة (تركز على Diffspeech).
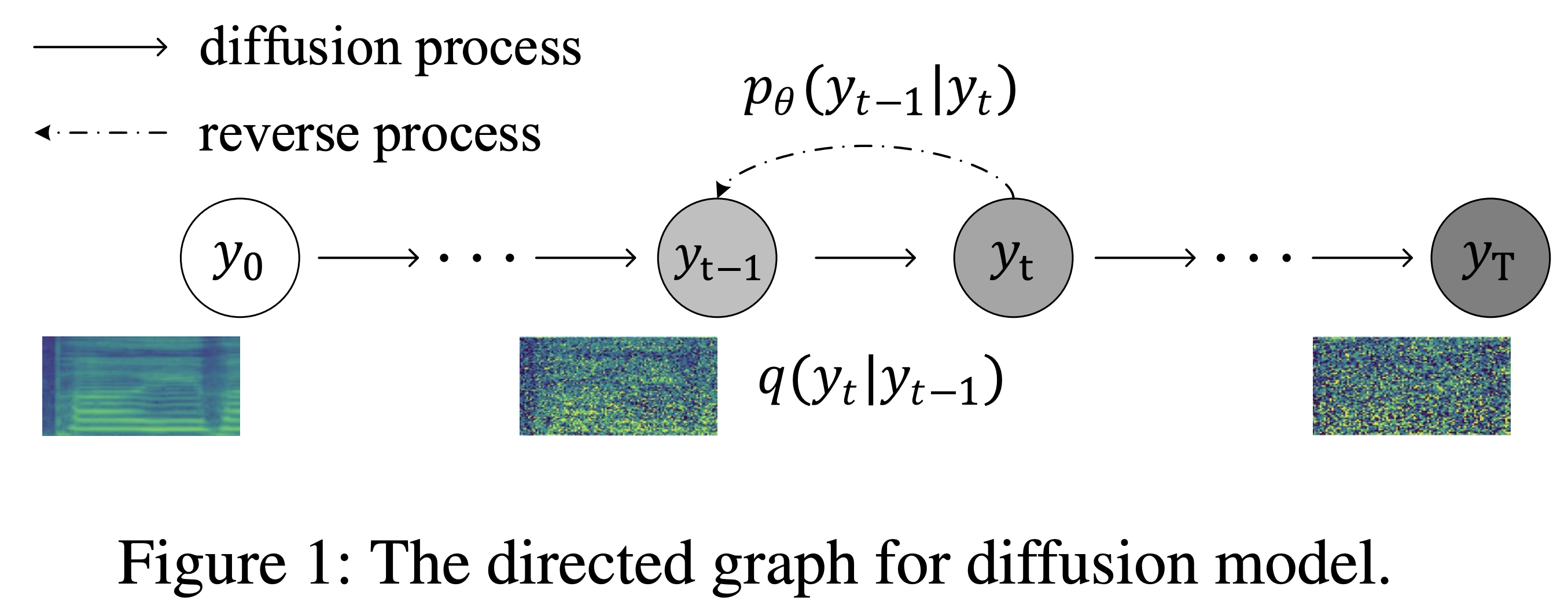
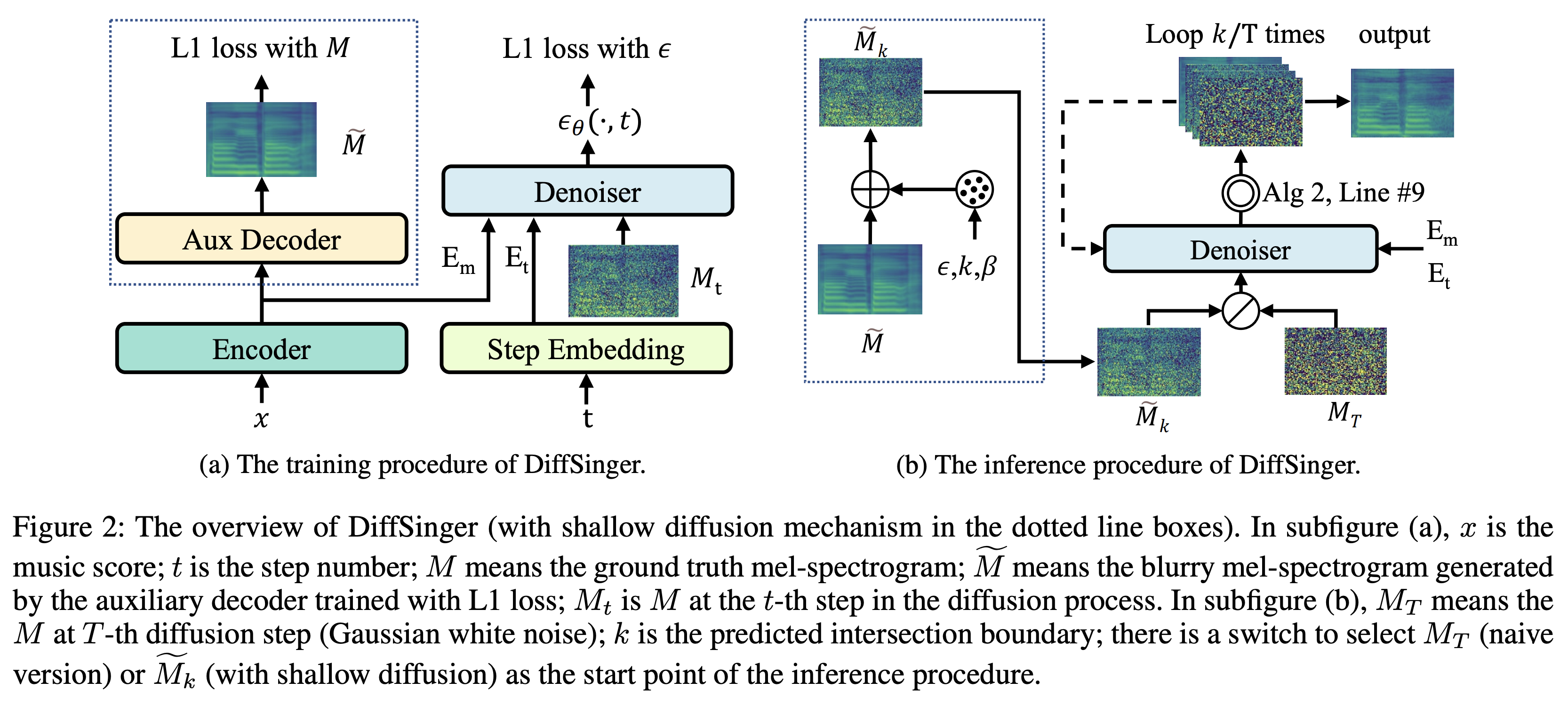
K K كخطوة زمنية قصوى تشير مجموعة البيانات إلى أسماء مجموعات البيانات مثل LJSpeech في المستندات التالية.
يشير النموذج إلى أنواع النموذج (اختر من " ساذجة " ، " aux " ، " ضحلة ").
يمكنك تثبيت تبعيات Python مع
pip3 install -r requirements.txt
يجب عليك تنزيل النماذج المسبقة ووضعها في
output/ckpt/LJSpeech_naive/ لنموذج " ساذج ".output/ckpt/LJSpeech_shallow/ لنموذج " الضحلة ". يرجى ملاحظة أن نقطة تفتيش النموذج " الضحل " تحتوي على كل من طرازي " الضحلة " و " AUX " ، وسيشارك هذان النموذجان جميع الدلائل باستثناء النتائج طوال العملية.للحصول على TTS الفردية الإنجليزية ، قم بتشغيل
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --model MODEL --restore_step RESTORE_STEP --mode single --dataset DATASET
سيتم وضع الكلمات المولدة في output/result/ .
يتم دعم استنتاج الدُفعات أيضًا ، حاول
python3 synthesize.py --source preprocessed_data/LJSpeech/val.txt --model MODEL --restore_step RESTORE_STEP --mode batch --dataset DATASET
لتوليف جميع الكلمات في preprocessed_data/LJSpeech/val.txt .
يمكن السيطرة على معدل الملعب/الحجم/التحدث للكلمات التوليف عن طريق تحديد نسب الملعب/الطاقة/المدة المطلوبة. على سبيل المثال ، يمكن للمرء زيادة معدل التحدث بنسبة 20 ٪ وتقليل الحجم بنسبة 20 ٪ بنسبة 20 ٪
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --model MODEL --restore_step RESTORE_STEP --mode single --dataset DATASET --duration_control 0.8 --energy_control 0.8
يرجى ملاحظة أن قابلية التحكم نشأت من Fastspeade2 وليس مصلحة حيوية لـ Diffspeech.
مجموعات البيانات المدعومة
أولا ، الجري
python3 prepare_align.py --dataset DATASET
لبعض الاستعدادات.
بالنسبة للمحاذاة القسرية ، يتم استخدام Montreal القسري Aligner (MFA) للحصول على المحاذاة بين الكلمات وتسلسلات الصوت. يتم توفير محاذاة مسبقًا لمجموعات البيانات هنا. يجب عليك إلغاء ضغط الملفات في preprocessed_data/DATASET/TextGrid/ . بالتناوب ، يمكنك تشغيل جهاز Aligner بنفسك.
بعد ذلك ، قم بتشغيل البرنامج النصي المسبق
python3 preprocess.py --dataset DATASET
يمكنك تدريب ثلاثة أنواع من النماذج: " ساذجة " و " aux " و " الضحلة ".
تدريب النسخة الساذجة (" ساذجة "):
تدريب النسخة الساذجة مع
python3 train.py --model naive --dataset DATASET
تدريب وحدة فك ترميز المساعد للإصدار الضحل (' aux '):
لتدريب النسخة الضحلة ، نحتاج إلى fastspech2 المدربة مسبقًا. سيتيح لك الأمر أدناه تدريب وحدات Fastspech2 ، بما في ذلك وحدة فك ترميز الإضافية.
python3 train.py --model aux --dataset DATASET
خدعة أسهل للتنبؤ بالحدود:
للحصول على الحدود K من مجموعة بيانات التحقق من الصحة ، يمكنك تشغيل المتنبئ الحدودي باستخدام Fastspeesh2 المساعد الذي تم تدريبه مسبقًا بواسطة الأمر التالي.
python3 boundary_predictor.py --restore_step RESTORE_STEP --dataset DATASET
سوف تقوم بطباعة القيمة المتوقعة (على سبيل المثال ، K_STEP ) في سجل الأوامر.
ثم ، قم بتعيين التكوين بالقيمة المتوقعة على النحو التالي
# In the model.yaml
denoiser :
K_step : K_STEPيرجى ملاحظة أن هذا يعتمد على الخدعة التي تم تقديمها في التذييل ب.
تدريب النسخة الضحلة (" ضحلة "):
للاستفادة من Fastspeesh2 المدربة مسبقًا ، بما في ذلك وحدة فك الترميز الإضافية ، يجب عليك تعيين restore_step مع الخطوة الأخيرة من تدريب Fastspeech2 المساعد كأمر التالي.
python3 train.py --model shallow --restore_step RESTORE_STEP --dataset DATASET
على سبيل المثال ، إذا تم حفظ نقطة التفتيش الأخيرة في 160000 خطوة خلال التدريب الإضافي ، فيجب عليك تعيين restore_step مع 160000 . ثم سيتم تحميل نموذج AUX ثم متابعة التدريب تحت آلية التدريب الضحلة.
يستخدم
tensorboard --logdir output/log/LJSpeech
لخدمة Tensorboard على مضيفك المحلي. يتم عرض منحنيات الخسارة ، وتوليف الطيف الطيف ، والسمعات.
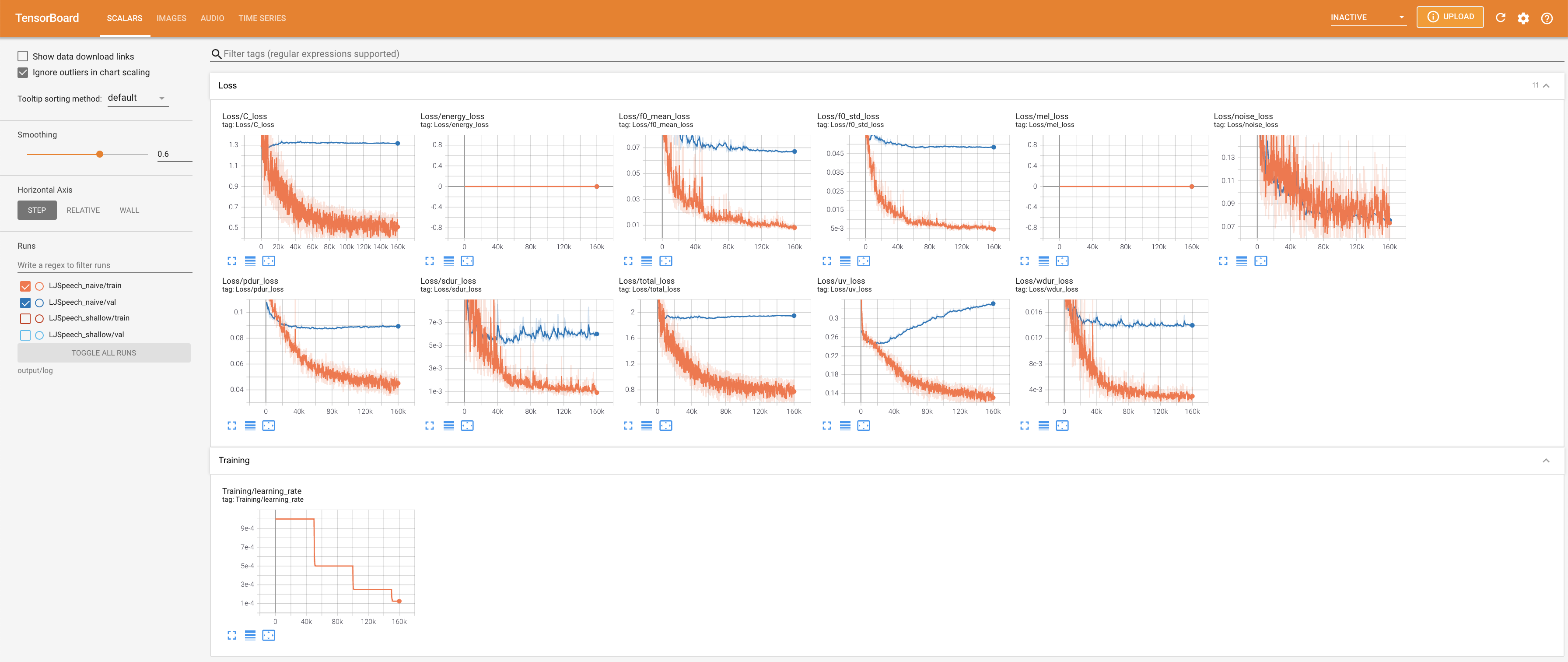
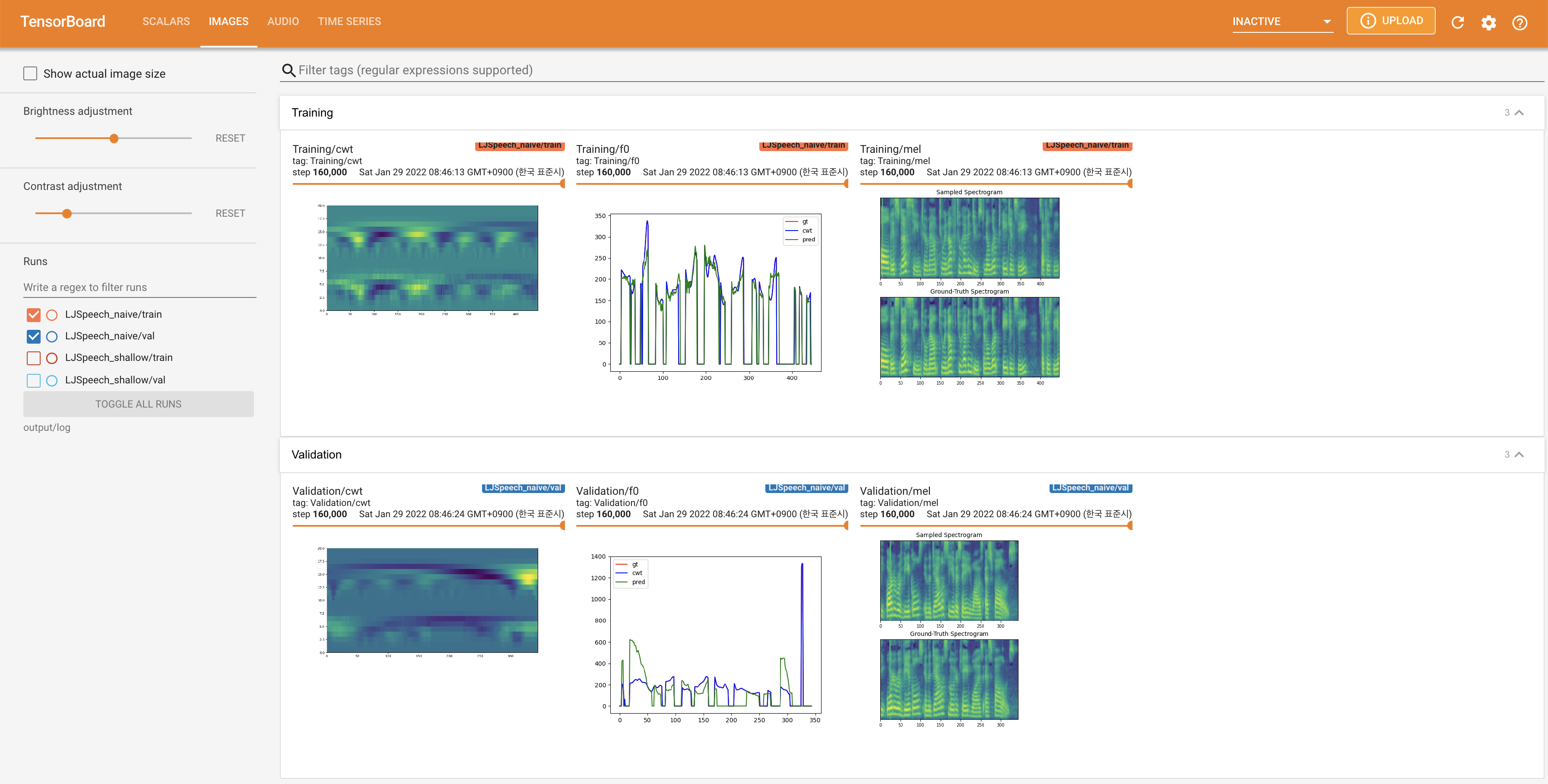
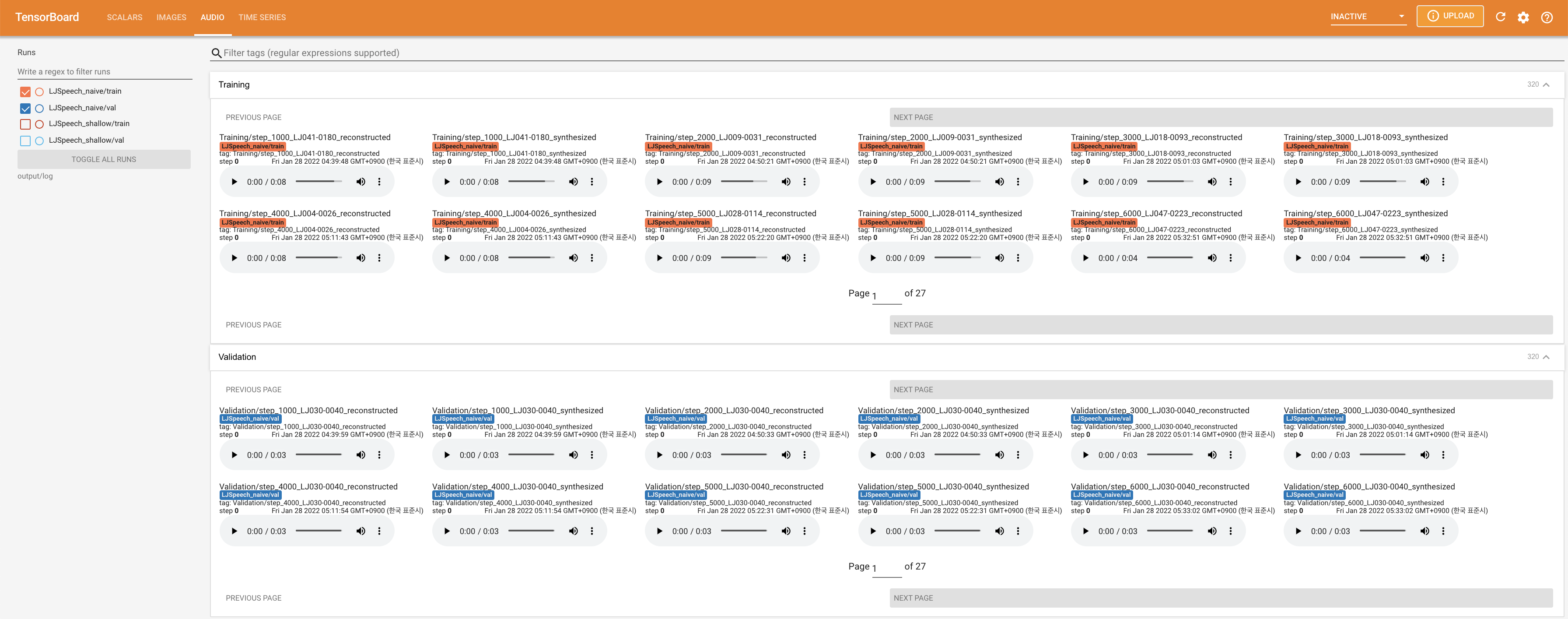
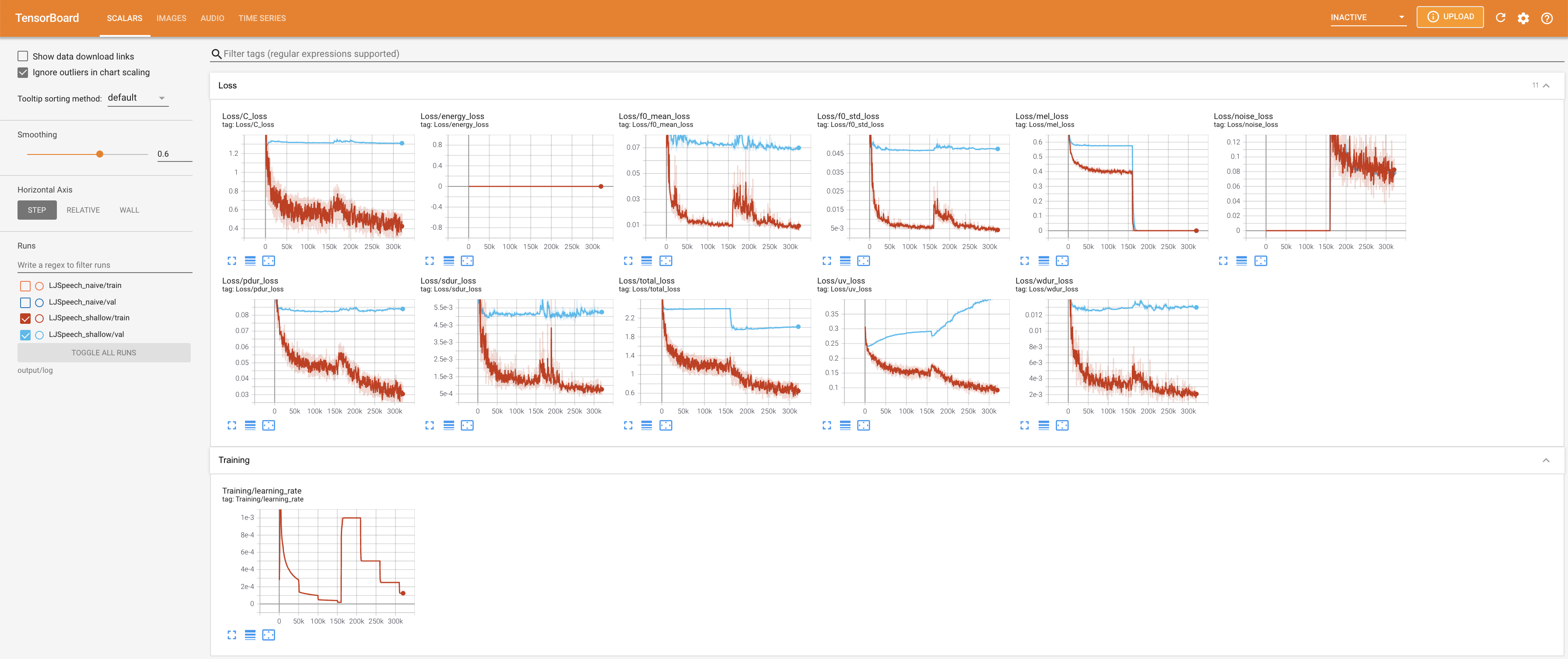
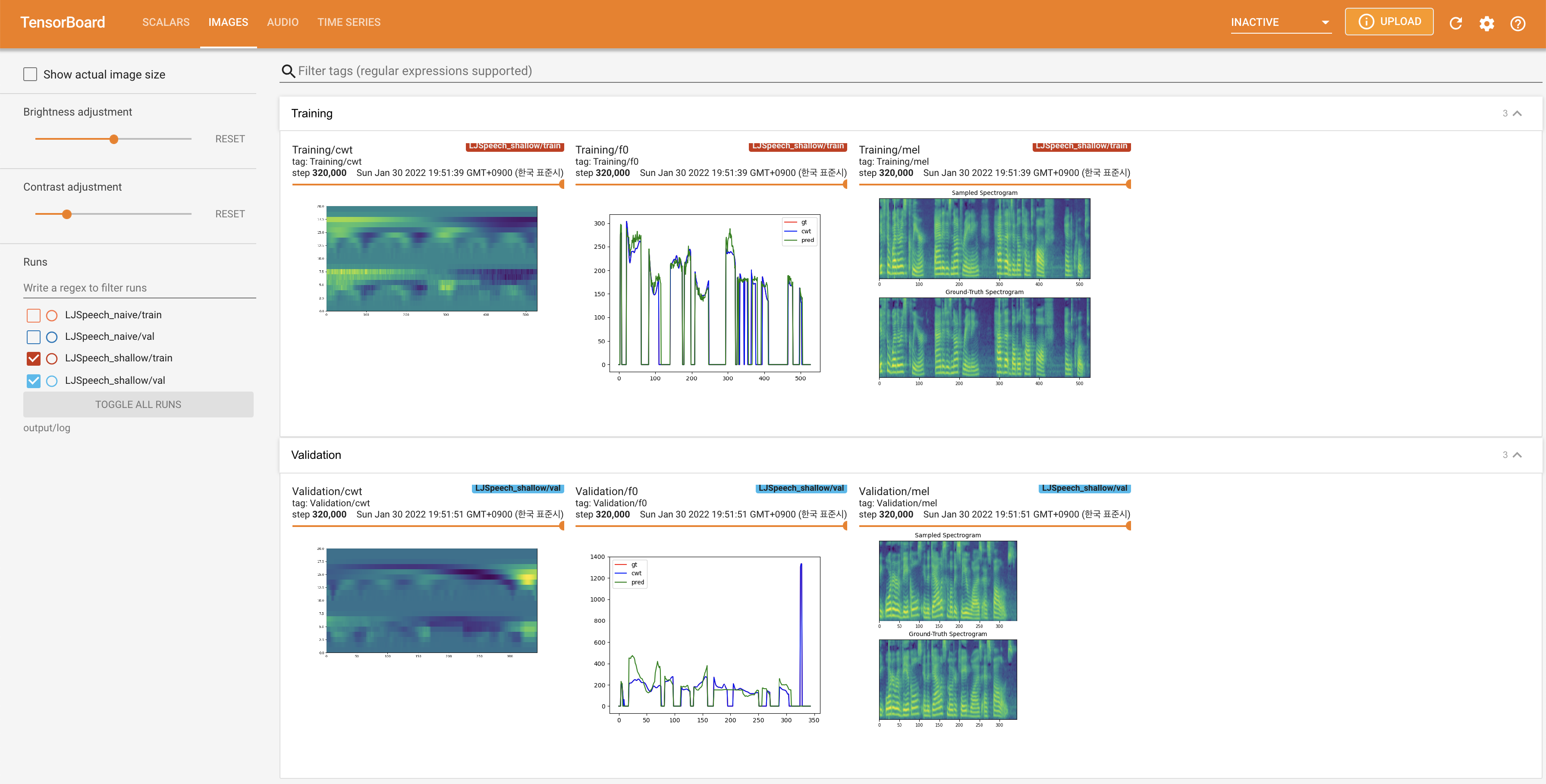
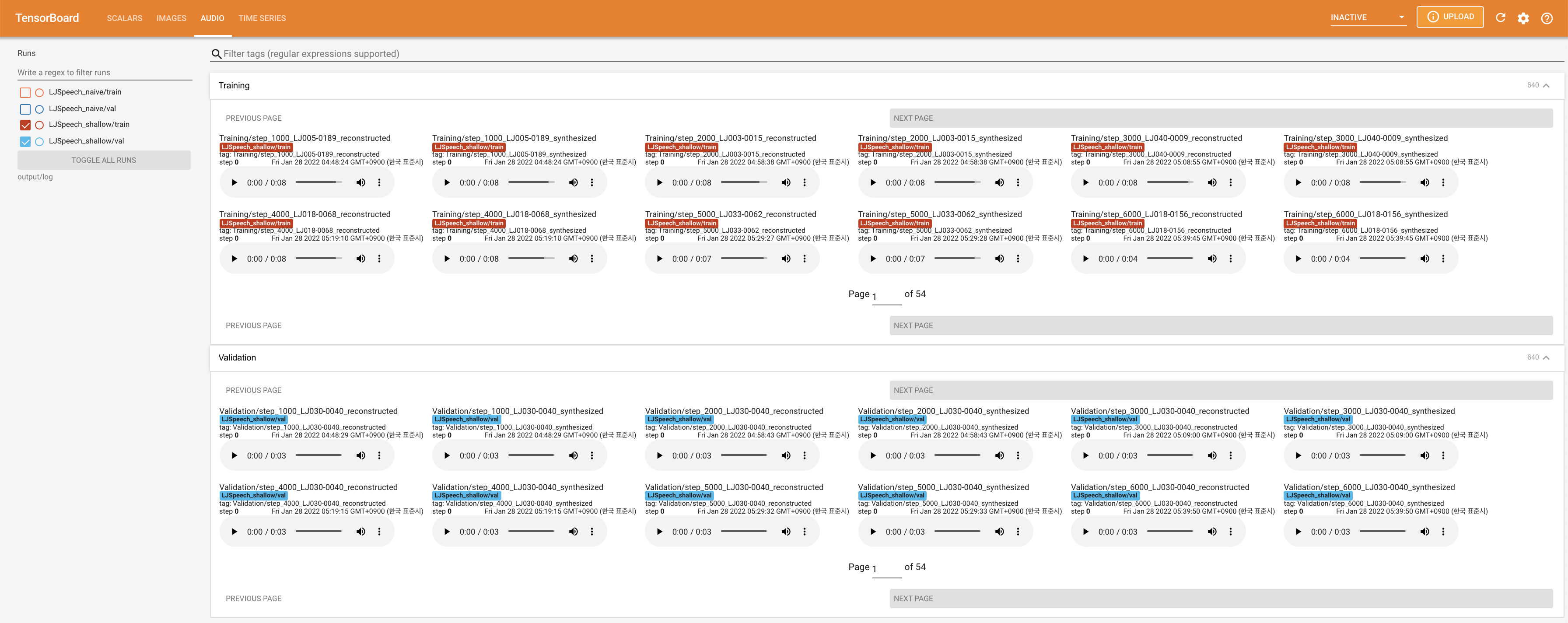
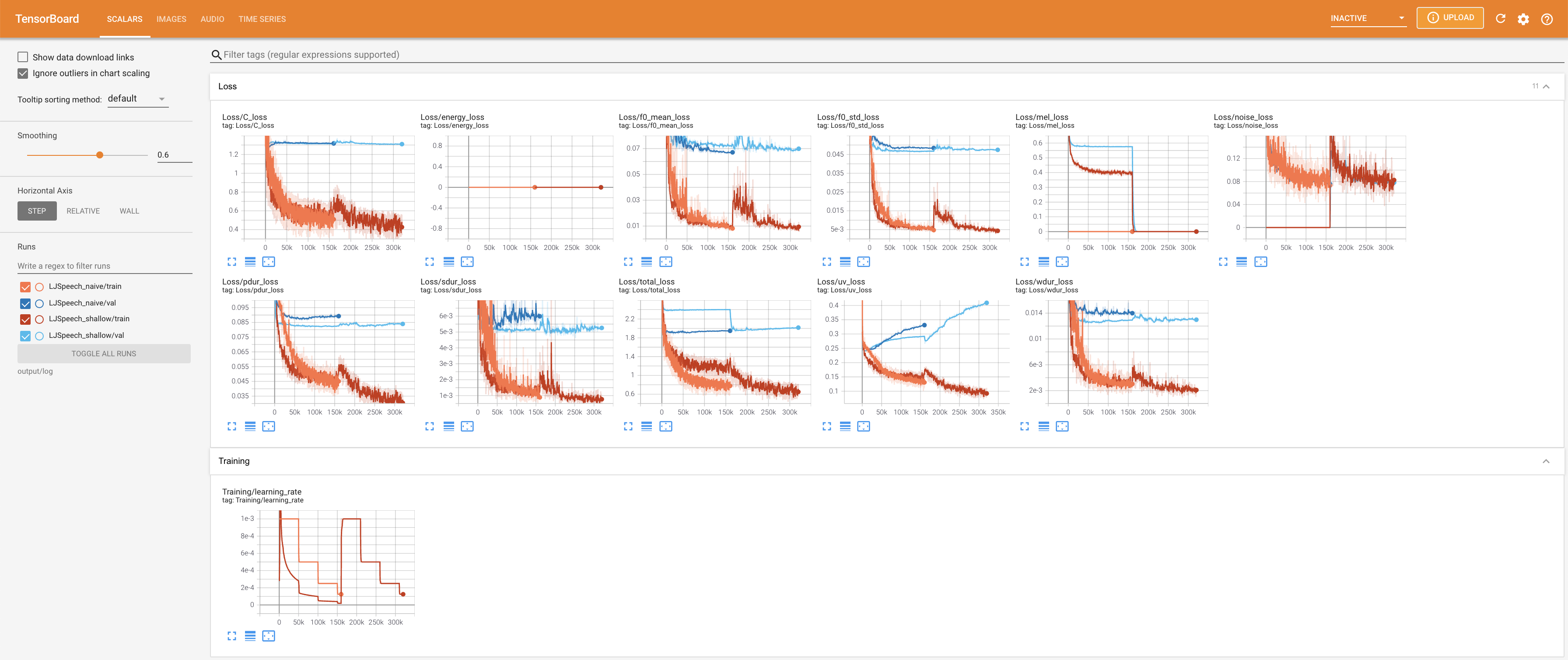
27.767M ، وهو ما يشبه الورقة الأصلية ( 27.722M ).100 ، وهي الأوقات الطوعية الكاملة للانتشار الساذج بحيث لا توجد ميزة على خطوات الانتشار. @misc{lee2021diffsinger,
author = {Lee, Keon},
title = {DiffSinger},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/keonlee9420/DiffSinger}}
}


