DiffSinger
1.0.0
DiffsingerのPytorch実装:浅い拡散メカニズムを介した歌声合成の歌声(Diffspeechに焦点を当てています)。
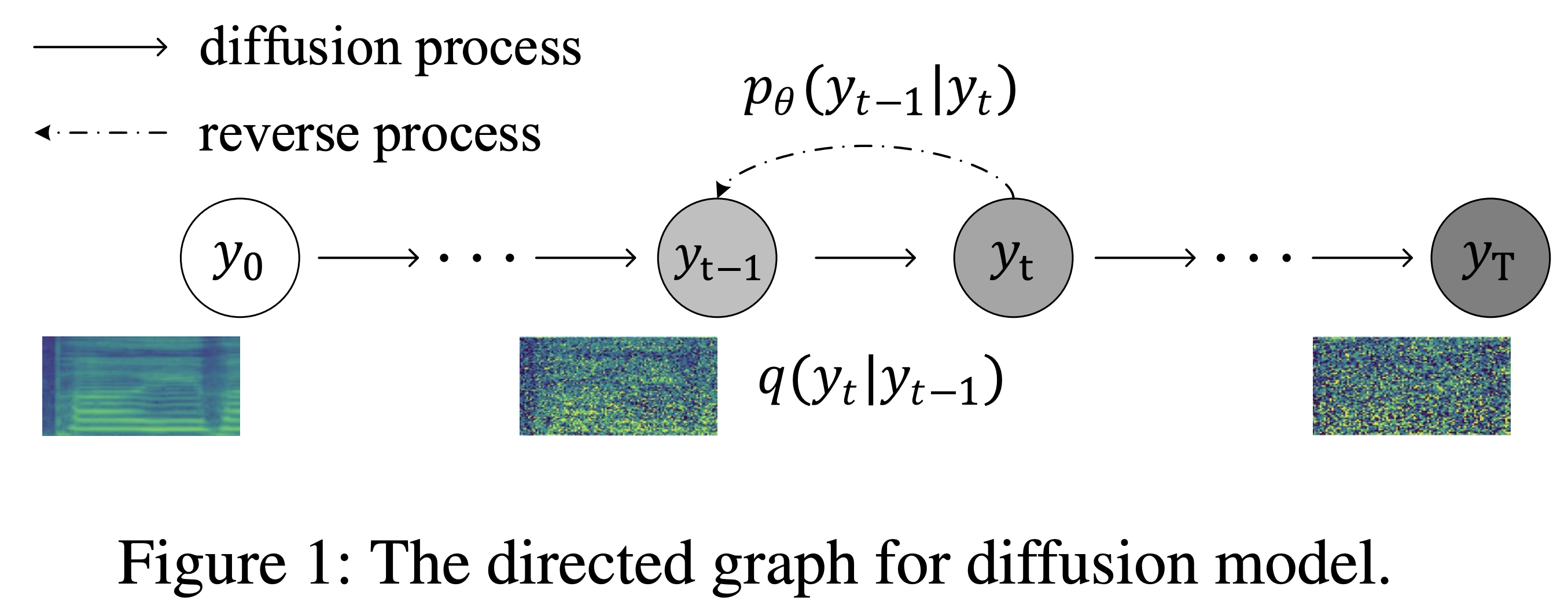
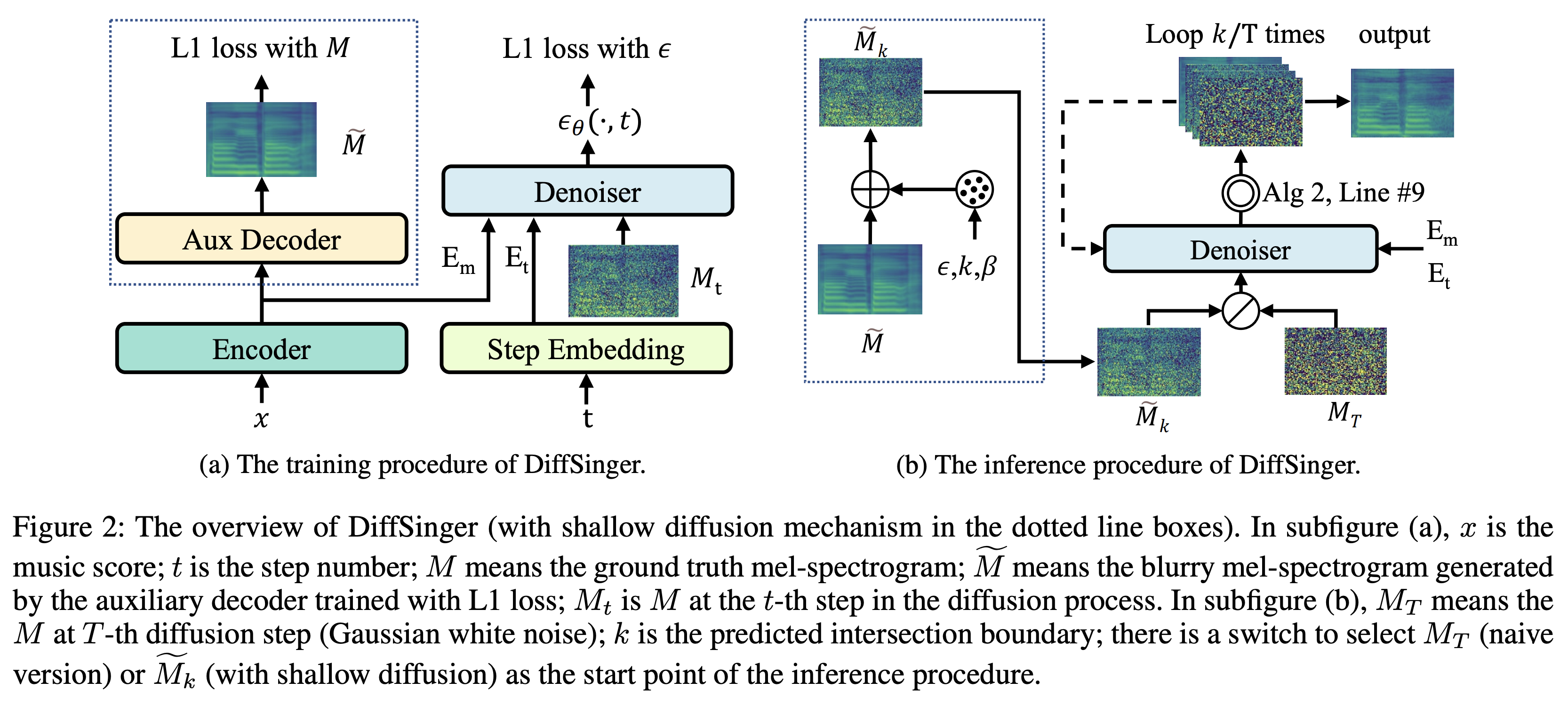
Kの境界予測の簡単なトリックK最大時間ステップとして使用して、事前に訓練された補助デコーダー +トレーニング除去者の活用データセットとは、次のドキュメントでLJSpeechなどのデータセットの名前を指します。
モデルは、モデルのタイプを指します(「ナイーブ」、「 aux 」、「浅い」から選択します)。
Python依存関係をインストールできます
pip3 install -r requirements.txt
既製のモデルをダウンロードして、それらを入れなければなりません
output/ckpt/LJSpeech_naive/ for ' naive 'モデル。output/ckpt/LJSpeech_shallow/ for ' shallow 'モデル。 「浅い」モデルのチェックポイントには「浅い」モデルと「 aux 」モデルの両方が含まれており、これら2つのモデルはプロセス全体を通して結果を除くすべてのディレクトリを共有することに注意してください。英語の単一スピーカーTTSの場合、実行します
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --model MODEL --restore_step RESTORE_STEP --mode single --dataset DATASET
生成された発話はoutput/result/に配置されます。
バッチ推論もサポートされています
python3 synthesize.py --source preprocessed_data/LJSpeech/val.txt --model MODEL --restore_step RESTORE_STEP --mode batch --dataset DATASET
preprocessed_data/LJSpeech/val.txtのすべての発話を合成する。
合成された発話のピッチ/ボリューム/発話レートは、目的のピッチ/エネルギー/持続時間比を指定することで制御できます。たとえば、発言率を20%上げて、体積を20%減らすことができます
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --model MODEL --restore_step RESTORE_STEP --mode single --dataset DATASET --duration_control 0.8 --energy_control 0.8
制御可能性はfastspeech2に由来し、diffseechの重要な関心ではないことに注意してください。
サポートされているデータセットは次のとおりです
まず、実行します
python3 prepare_align.py --dataset DATASET
いくつかの準備のために。
強制アライメントのために、モントリオールの強制アライナー(MFA)を使用して、発話と音素シーケンスの間のアライメントを取得します。データセットの事前に抽出されたアライメントはここに記載されています。 preprocessed_data/DATASET/TextGrid/でファイルを解凍する必要があります。または、自分でアライナーを実行できます。
その後、前処理スクリプトを実行します
python3 preprocess.py --dataset DATASET
「ナイーブ」、「 aux 」、「浅い」という3種類のモデルをトレーニングできます。
トレーニングナイーブバージョン(「ナイーブ」):
ナイーブバージョンをでトレーニングします
python3 train.py --model naive --dataset DATASET
浅いバージョン用のトレーニング補助デコーダー( ' aux '):
浅いバージョンをトレーニングするには、事前に訓練されたFastSpeech2が必要です。以下のコマンドでは、補助デコーダーを含むFastSpeech2モジュールをトレーニングできます。
python3 train.py --model aux --dataset DATASET
境界予測の簡単なトリック:
検証データセットから境界Kを取得するには、次のコマンドで事前に訓練された補助FastSpeech2を使用して境界予測子を実行できます。
python3 boundary_predictor.py --restore_step RESTORE_STEP --dataset DATASET
コマンドログに予測値(たとえば、 K_STEP )が印刷されます。
次に、次のように予測値で構成を設定します
# In the model.yaml
denoiser :
K_step : K_STEPこれは、付録Bで導入されたトリックに基づいていることに注意してください。
浅いバージョンのトレーニング(「浅い」):
補助デコーダーを含むPre-Trained FastSpeech2を活用するには、補助fastspeech2トレーニングの最終ステップでrestore_step次のコマンドとして設定する必要があります。
python3 train.py --model shallow --restore_step RESTORE_STEP --dataset DATASET
たとえば、補助トレーニング中に最後のチェックポイントが160000ステップで保存されている場合、 160000でrestore_step設定する必要があります。次に、AUXモデルをロードし、浅いトレーニングメカニズムの下でトレーニングを続けます。
使用
tensorboard --logdir output/log/LJSpeech
LocalHostでTensorboardを提供します。損失曲線、合成されたメルスペクトルグラム、およびオーディオが表示されます。
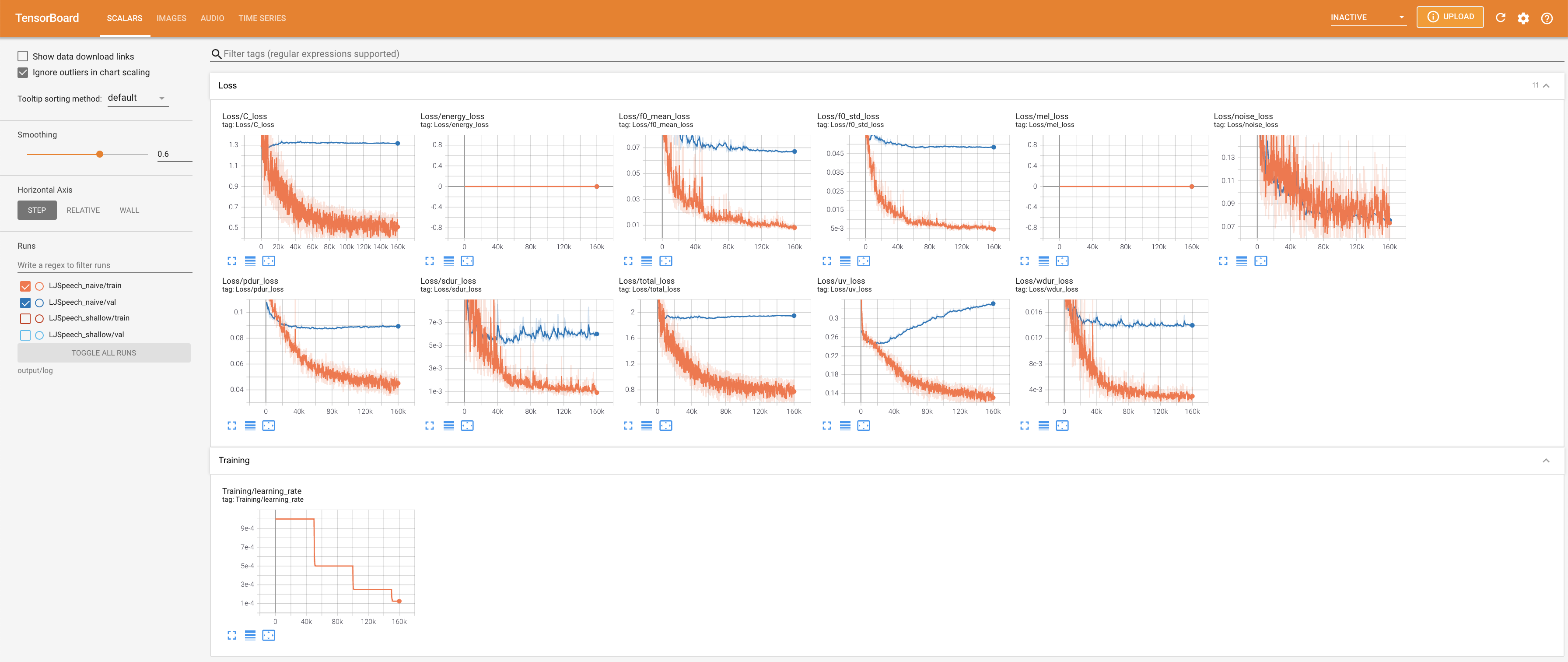
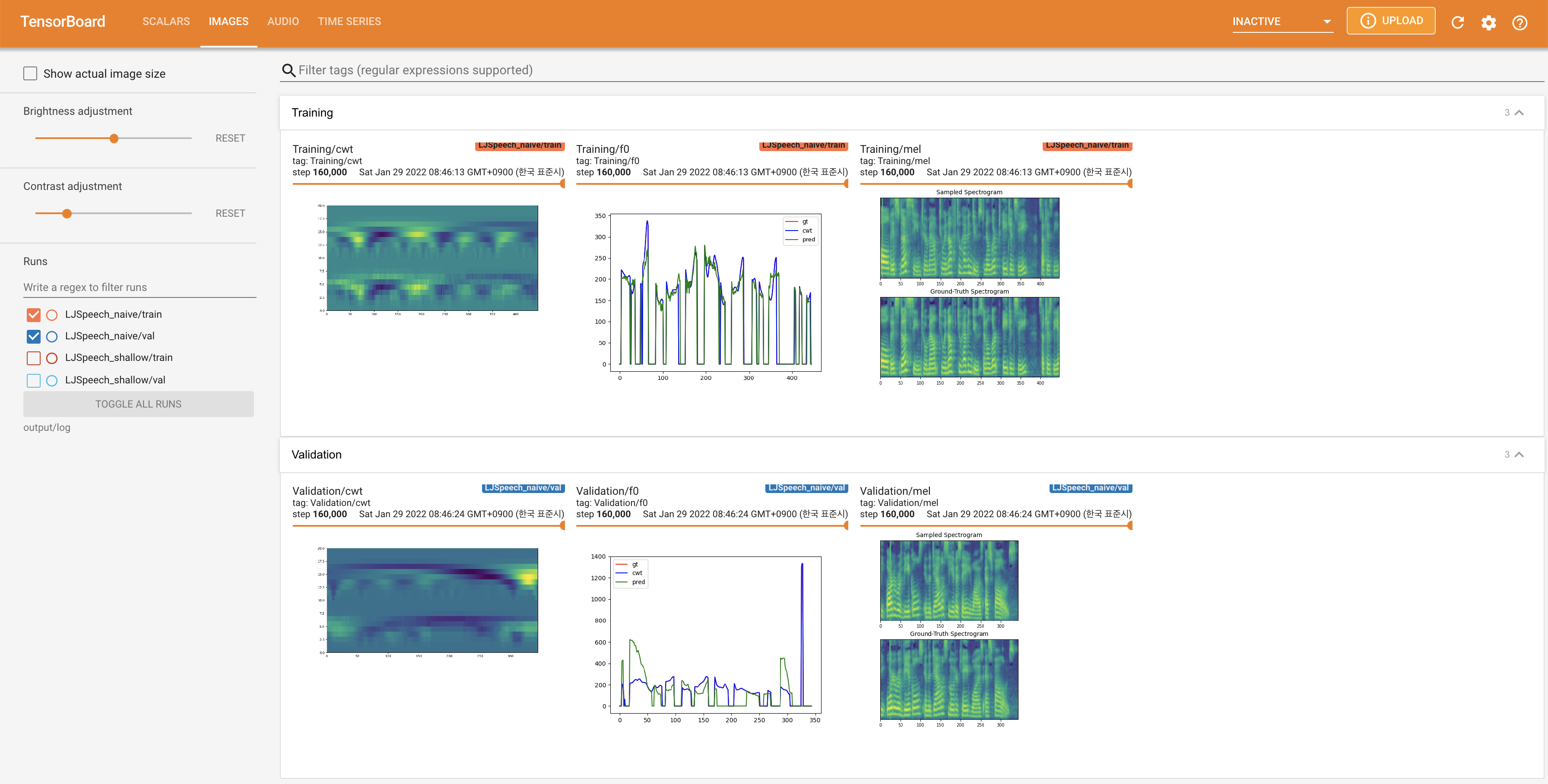
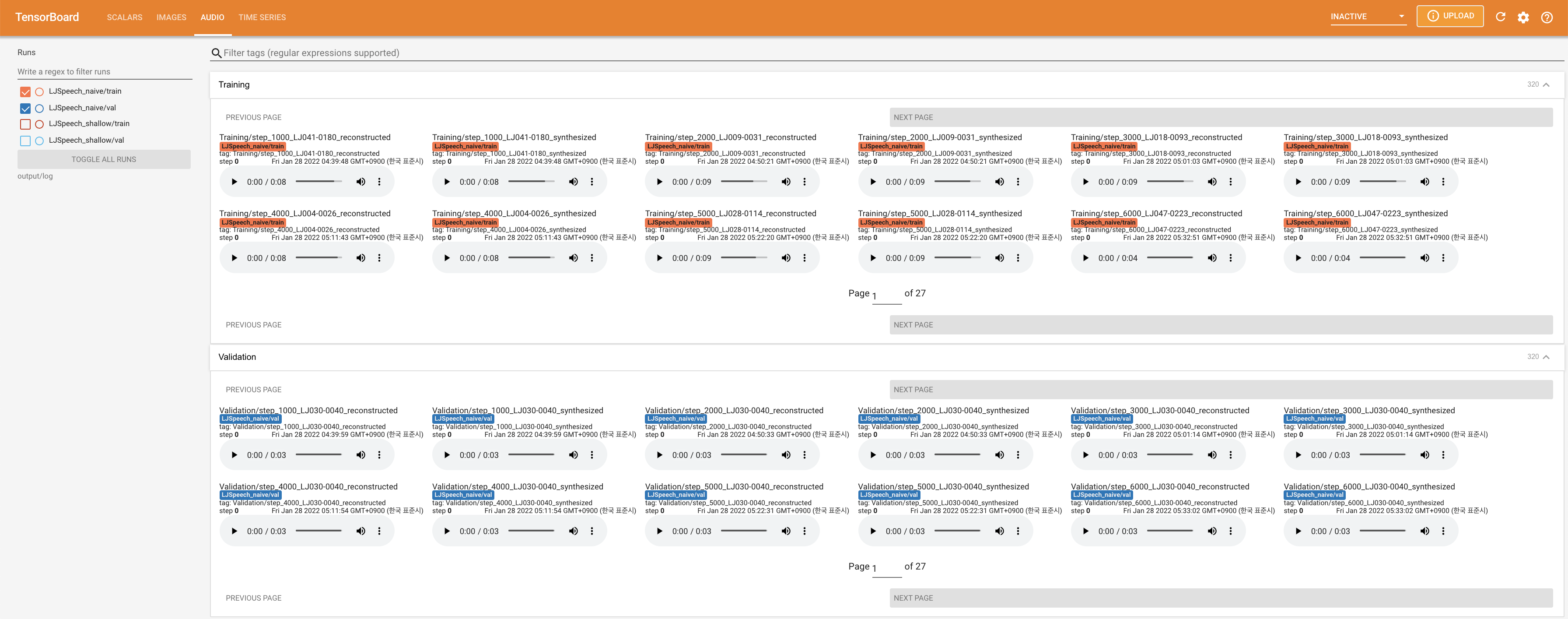
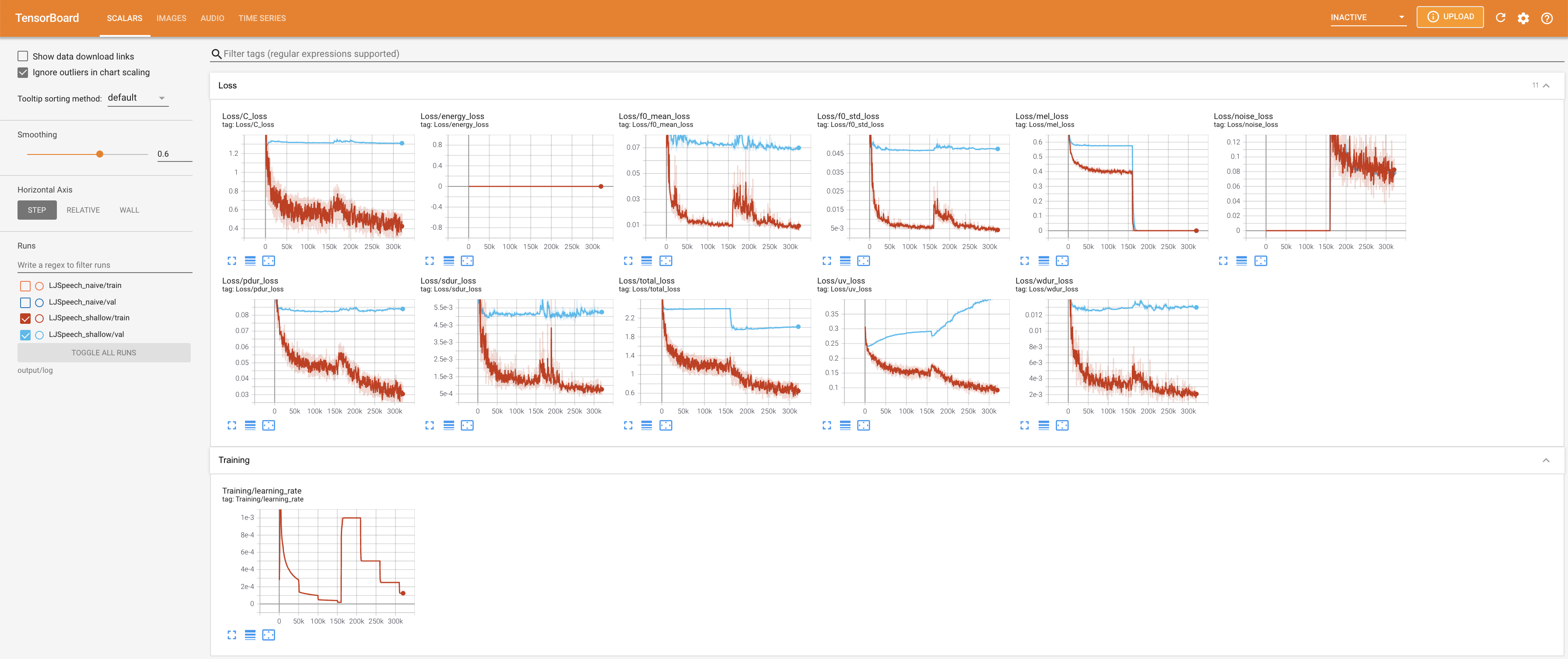
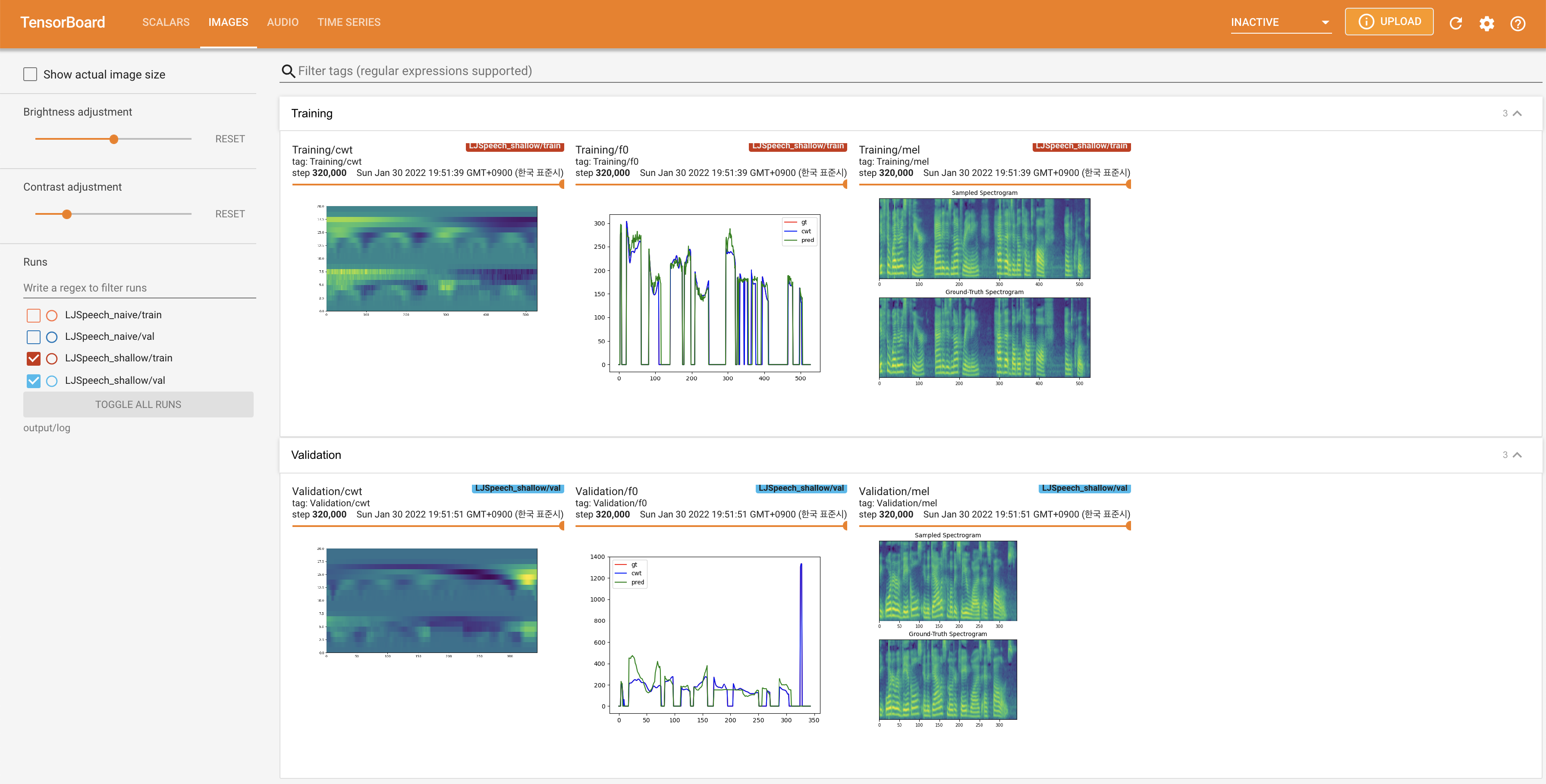
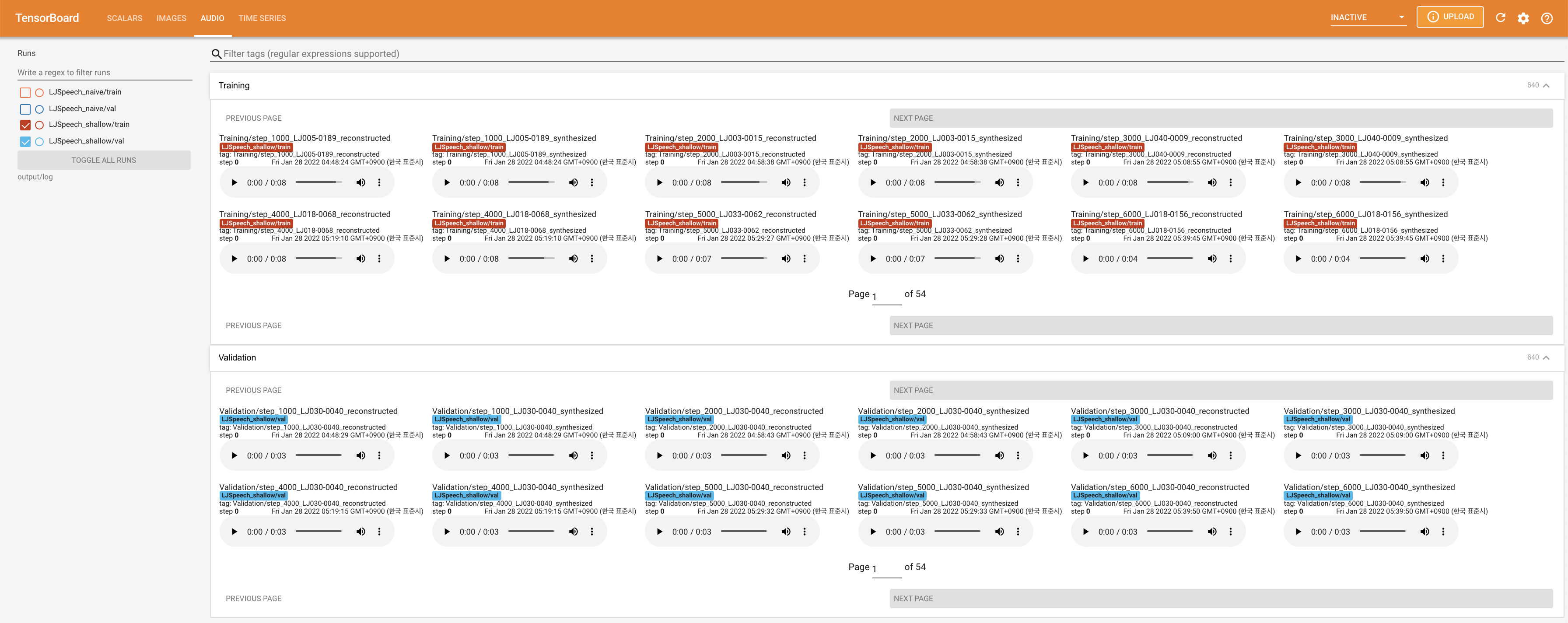
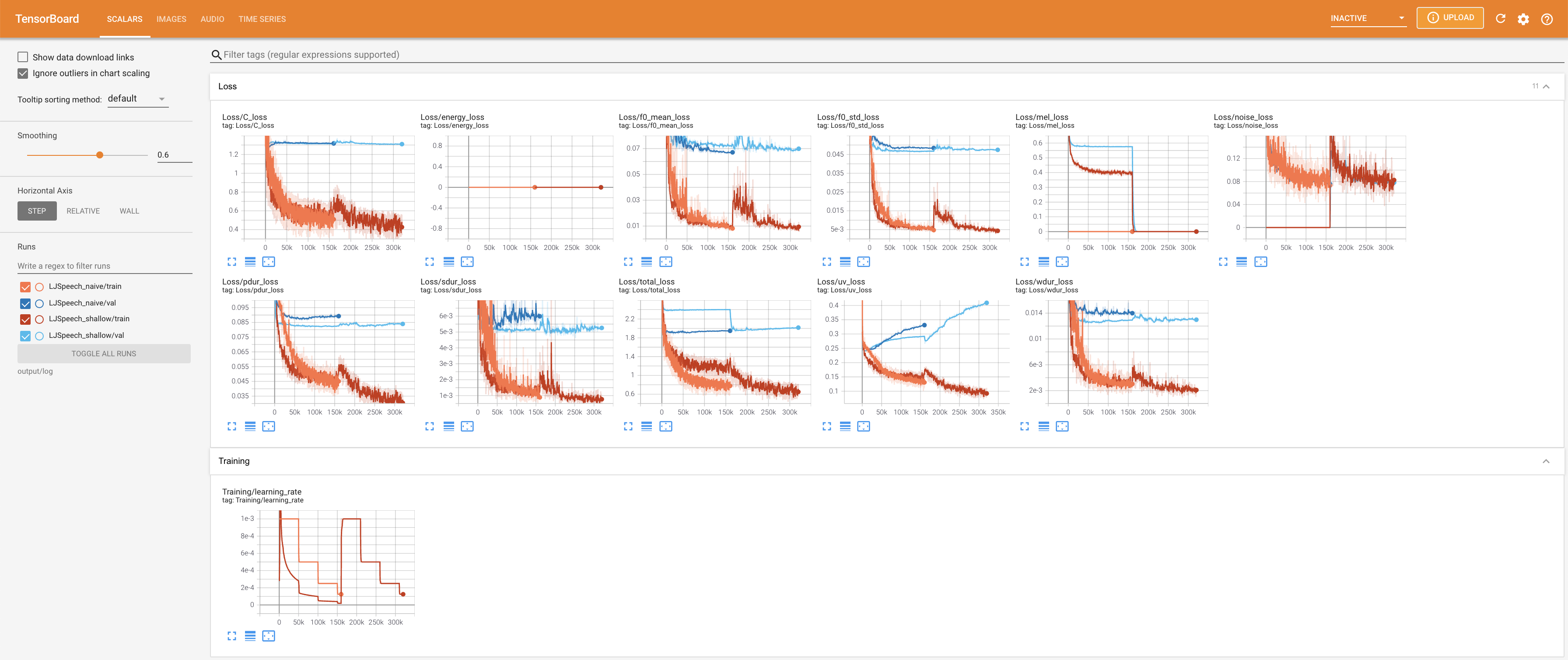
27.767Mで、元の論文( 27.722M )に似ています。100であり、これは拡散ステップに利点がないように、ナイーブ拡散の完全なタイムステップです。 @misc{lee2021diffsinger,
author = {Lee, Keon},
title = {DiffSinger},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/keonlee9420/DiffSinger}}
}


