DiffSinger
1.0.0
Реализация Pytorch Diffsinger: петь голосовой синтез с помощью механизма мелкого диффузии (сфокусирован на Diffspeech).
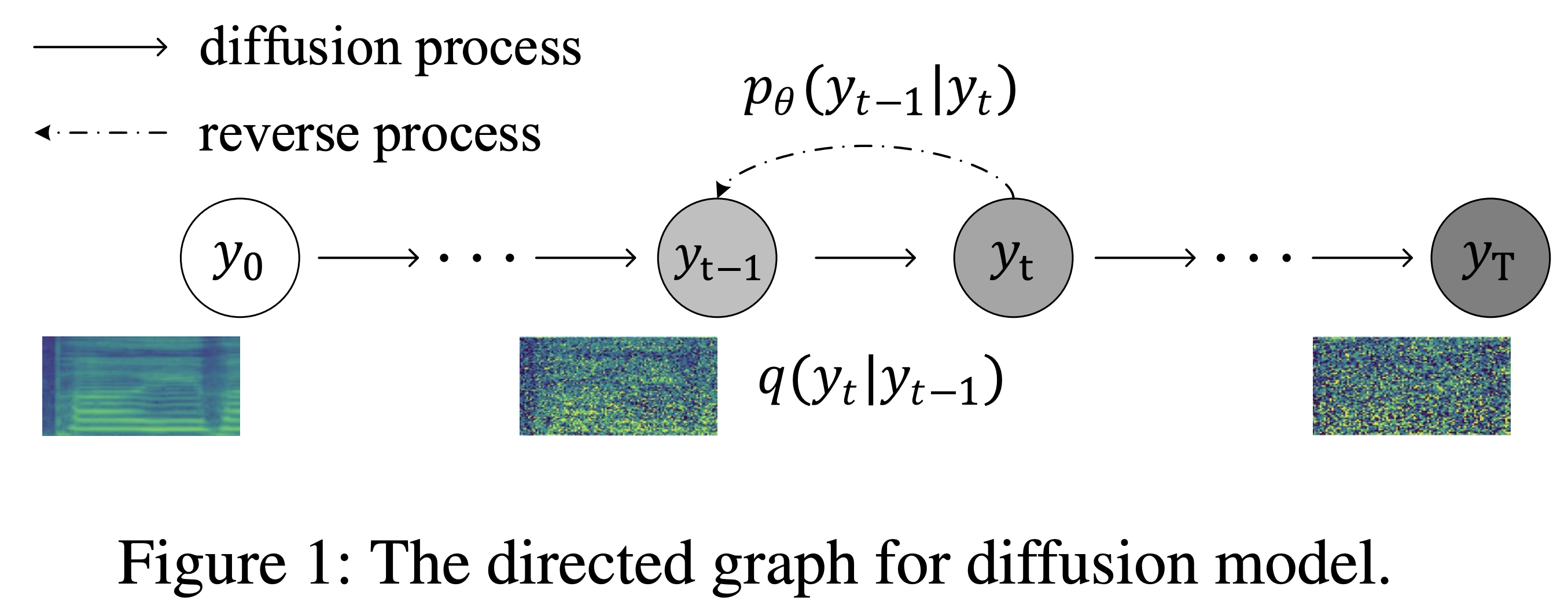
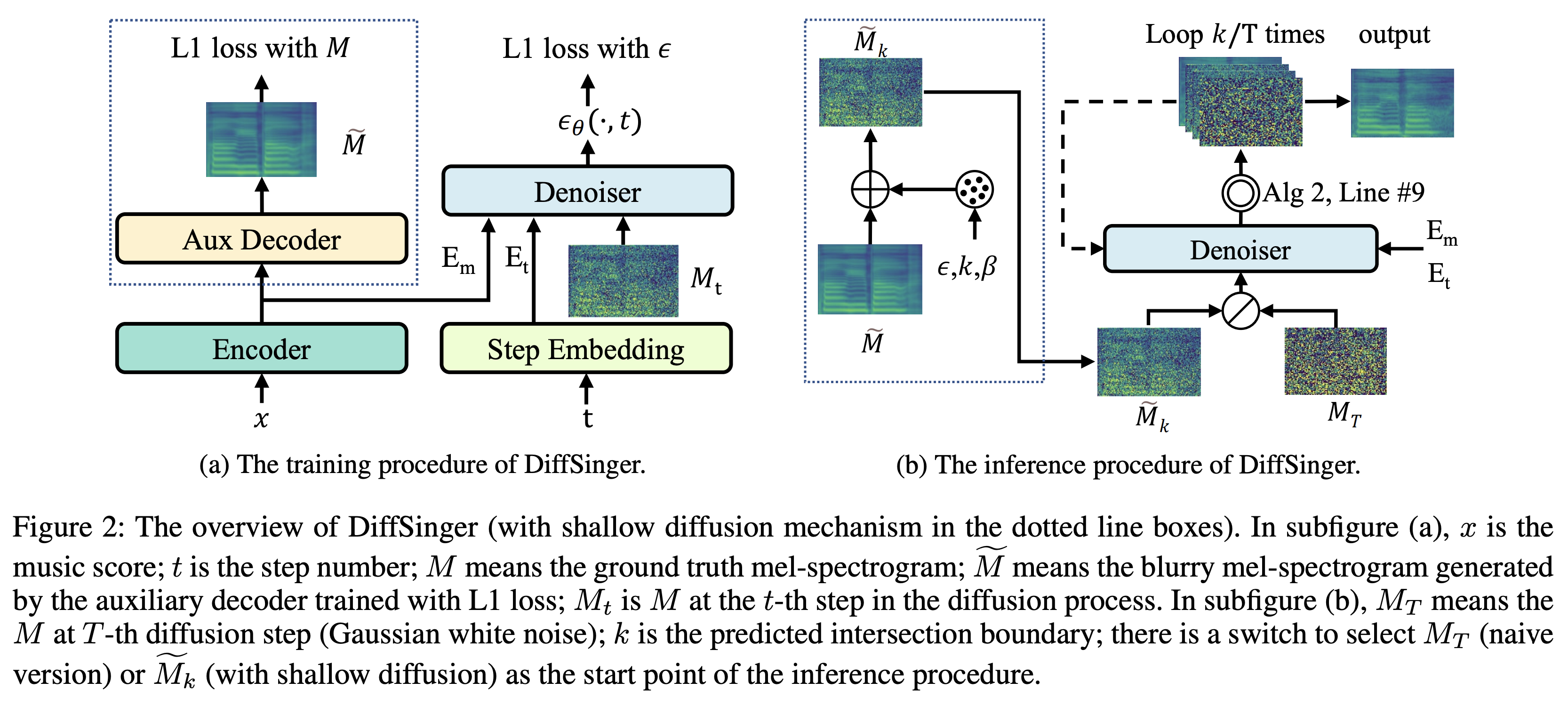
K K в качестве максимального временного шага Набор данных относится к именам наборов данных, таких как LJSpeech в следующих документах.
Модель относится к типам модели (выберите « Наив », « aux », « мелкий »).
Вы можете установить зависимости Python с
pip3 install -r requirements.txt
Вы должны скачать предварительно подготовленные модели и поместить их в
output/ckpt/LJSpeech_naive/ FOR ' NAIVE ' MODEL.output/ckpt/LJSpeech_shallow/ FOR ' MEANTOW ' MODEL. Обратите внимание, что контрольная точка « мелкой » модели содержит как « мелкие », так и модели « Aux », и эти две модели будут использовать все каталоги, за исключением результатов на протяжении всего процесса.Для английских однополосных TTS, бегите
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --model MODEL --restore_step RESTORE_STEP --mode single --dataset DATASET
Сгенерированные высказывания будут помещены в output/result/ .
Пакетный вывод также поддерживается, попробуйте
python3 synthesize.py --source preprocessed_data/LJSpeech/val.txt --model MODEL --restore_step RESTORE_STEP --mode batch --dataset DATASET
синтезировать все высказывания в preprocessed_data/LJSpeech/val.txt .
Скорость шага/объема/разговора синтезированных высказываний можно контролировать, указав желаемый коэффициент высоты/энергии/продолжительности. Например, можно увеличить скорость разговора на 20 % и уменьшить объем на 20 % на
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --model MODEL --restore_step RESTORE_STEP --mode single --dataset DATASET --duration_control 0.8 --energy_control 0.8
Обратите внимание, что управляемость происходит от Fastspeech2 и не является жизненно важным интересом Diffspeech.
Поддерживаемые наборы данных
Сначала беги
python3 prepare_align.py --dataset DATASET
для некоторых приготовлений.
Для принудительного выравнивания Монреаль принудительный выравниватель (MFA) используется для получения выравнивания между высказываниями и последовательностями фонем. Предварительные выравнивания для наборов данных представлены здесь. Вы должны расстегнуть разанипировать файлы в preprocessed_data/DATASET/TextGrid/ . С другой стороны, вы можете запустить выравниватель самостоятельно.
После этого запустите сценарий предварительной обработки
python3 preprocess.py --dataset DATASET
Вы можете обучить три типа модели: « Наив », « Aux » и « мелкие ».
Обучение наивной версии (« Наив »):
Тренировать наивную версию с
python3 train.py --model naive --dataset DATASET
Обучающий вспомогательный декодер для мелкой версии (' aux '):
Чтобы тренировать мелкую версию, нам нужна предварительно обученная Fastspeech2. Команда ниже позволит вам обучать модули FastSpeech2, включая вспомогательный декодер.
python3 train.py --model aux --dataset DATASET
Более легкий трюк для граничного прогноза:
Чтобы получить границу K из нашего набора данных проверки, вы можете запустить предиктора пограничного, используя предварительно обученную вспомогательную Fastspeech2 по следующей команде.
python3 boundary_predictor.py --restore_step RESTORE_STEP --dataset DATASET
Он распечатает прогнозируемое значение (скажем, K_STEP ) в журнале команды.
Затем установите конфигурацию с прогнозируемым значением следующим образом
# In the model.yaml
denoiser :
K_step : K_STEPОбратите внимание, что это основано на трюке, представленном в Приложении B.
Учебная неглубокая версия (« мелкая »):
Чтобы использовать предварительно обученный FastSpeech2, включая вспомогательный декодер, вы должны установить restore_step с последним этапом вспомогательного обучения FASTSPEECH2 в качестве следующей команды.
python3 train.py --model shallow --restore_step RESTORE_STEP --dataset DATASET
Например, если последняя контрольная точка сохраняется на уровне 160000 во время вспомогательного обучения, вам нужно установить restore_step с 160000 . Затем он загрузит модель AUX, а затем продолжит обучение в соответствии с мелким механизмом обучения.
Использовать
tensorboard --logdir output/log/LJSpeech
Подавать в Tensorboard на вашем местном хосте. Кривые потерь, синтезированные мель-спектрограммы и аудио показаны.
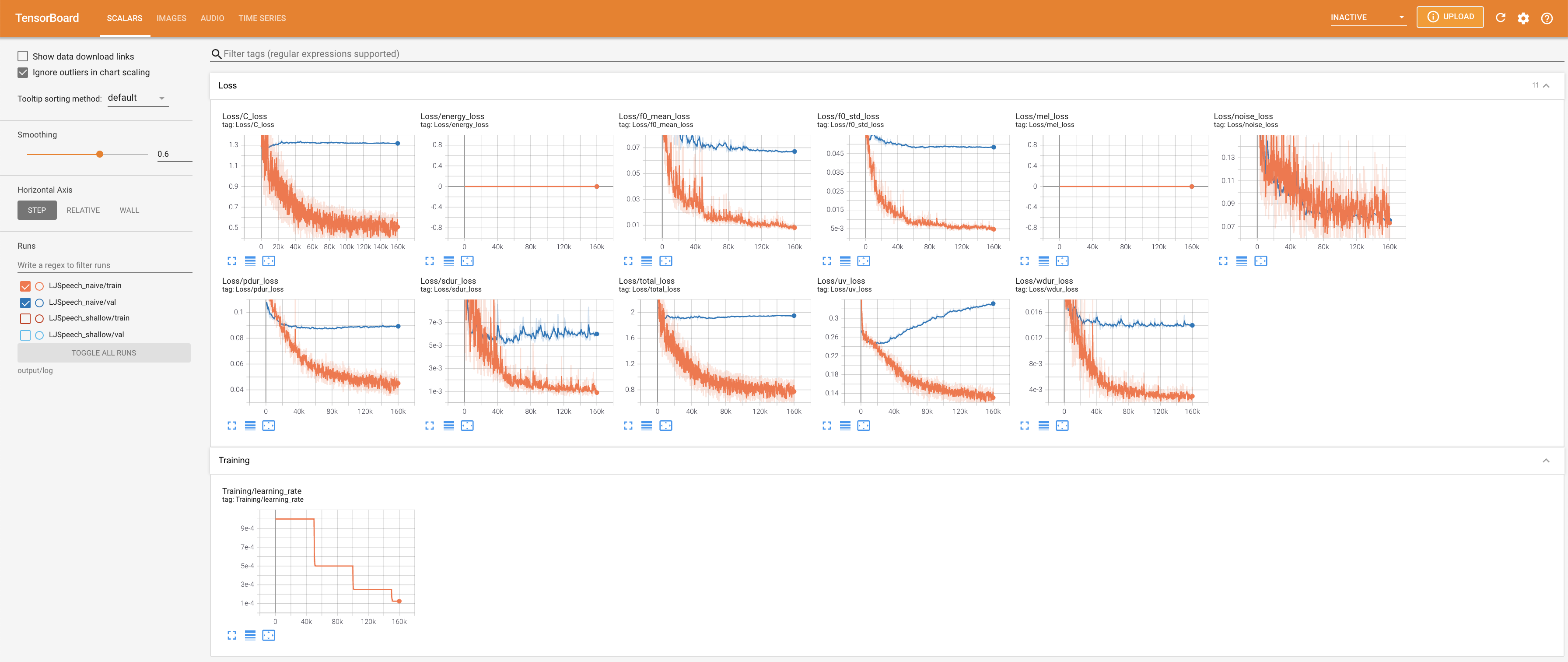
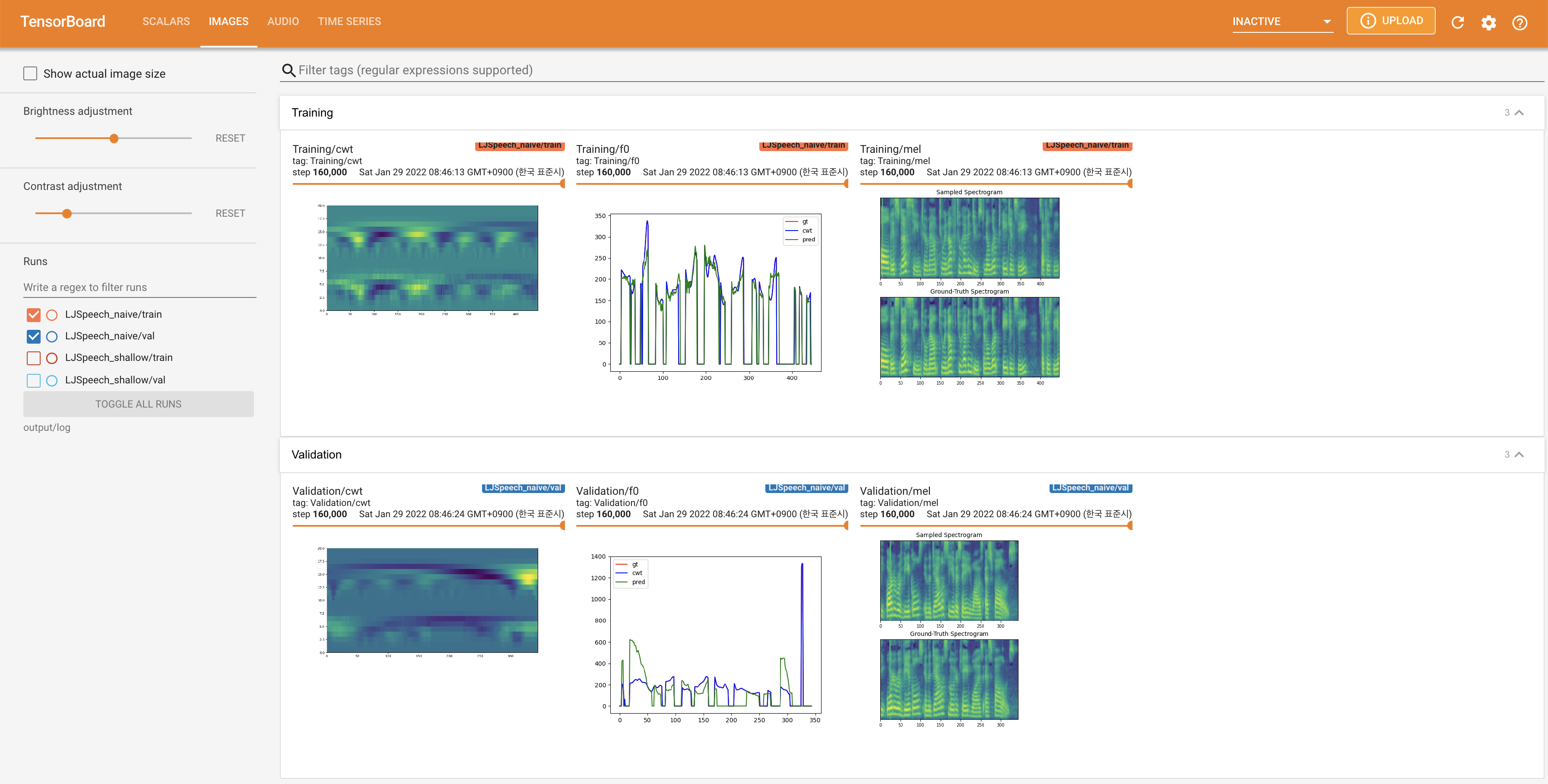
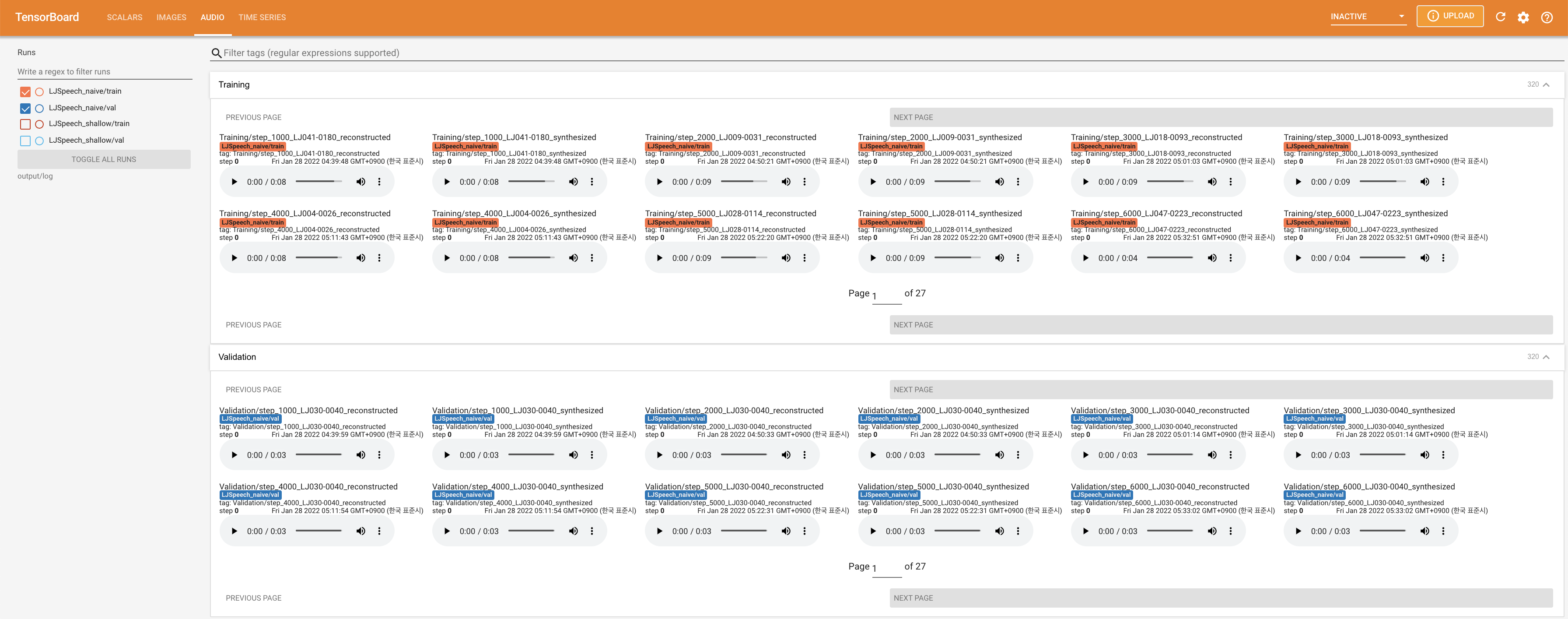
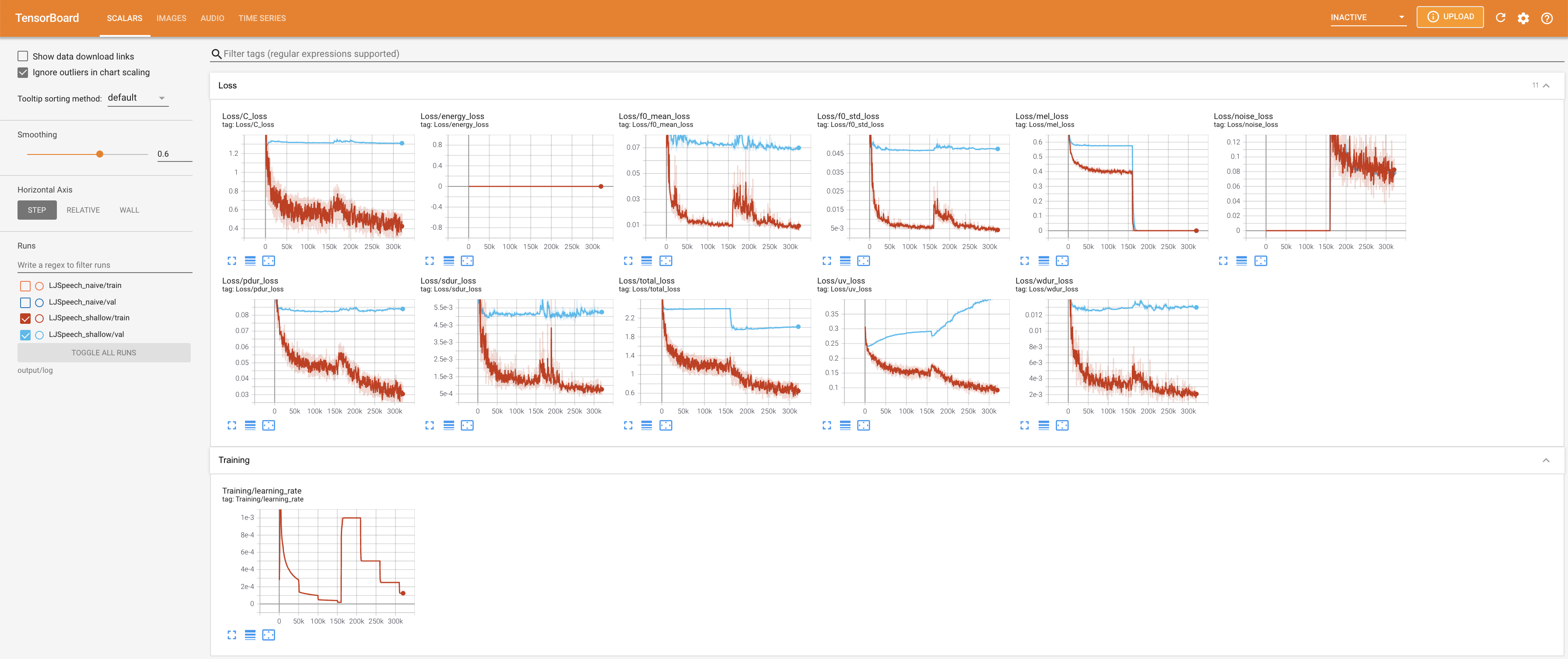
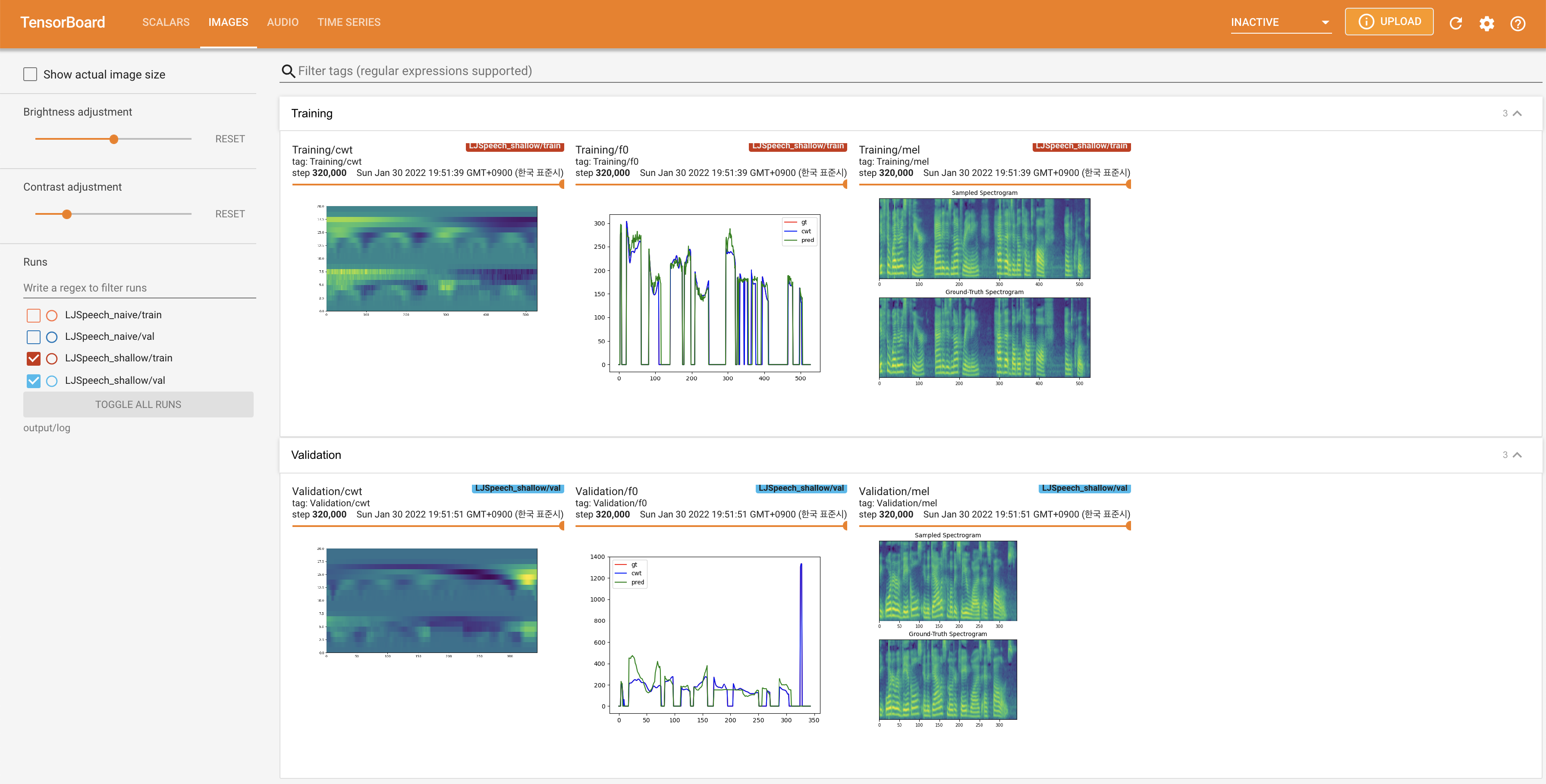
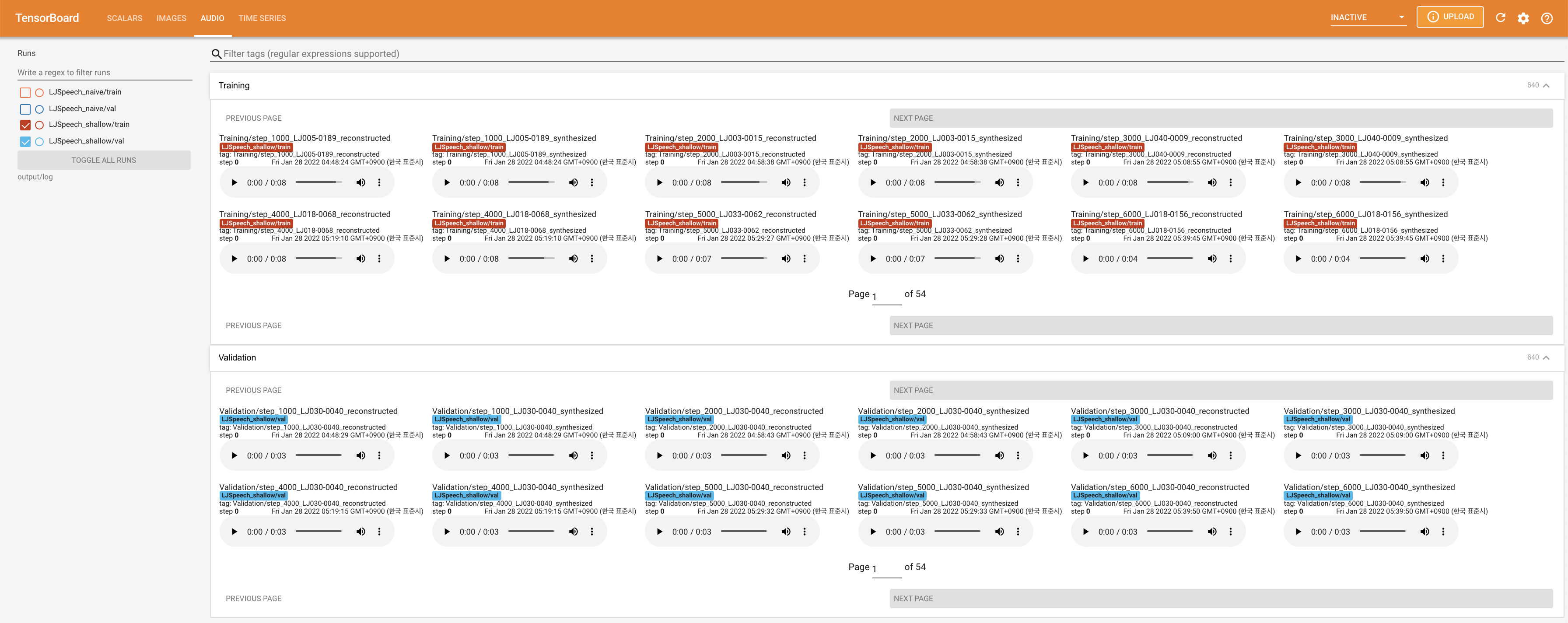
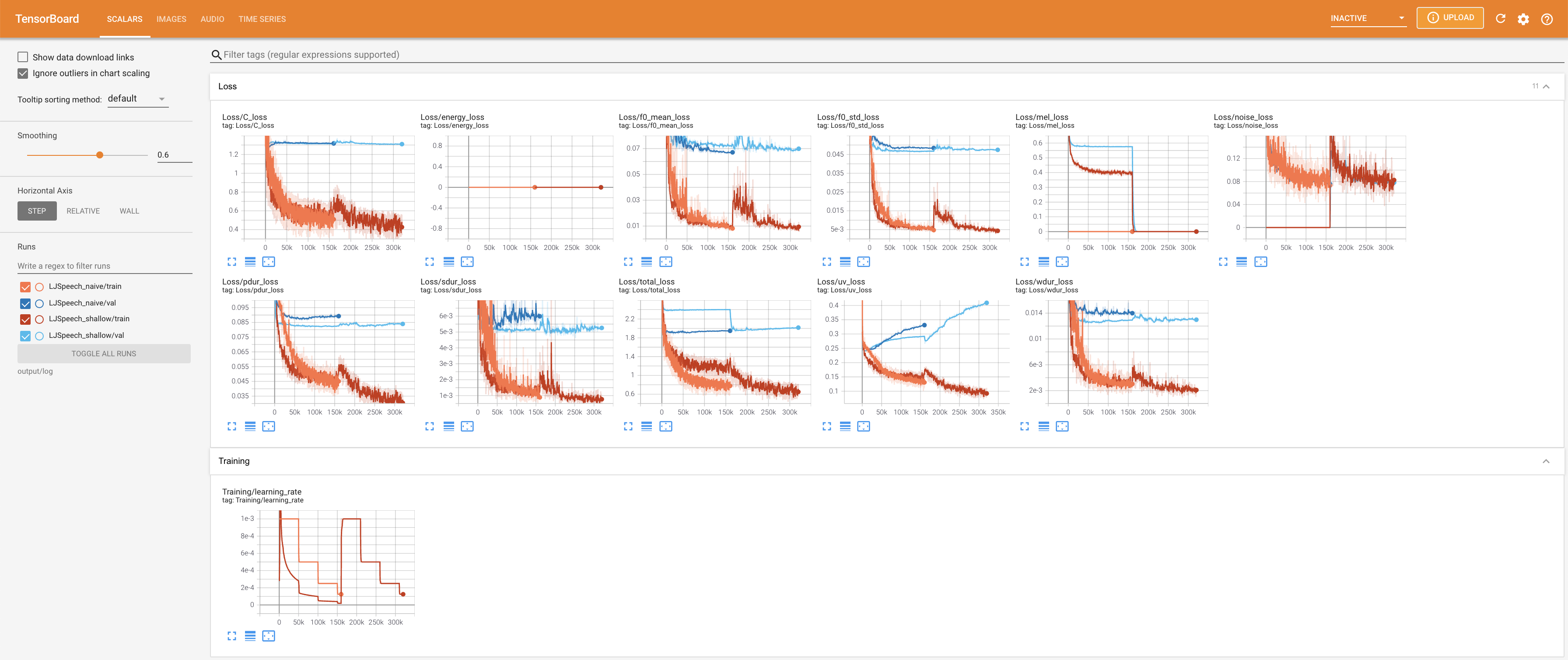
27.767M , что аналогично исходной статье ( 27.722M ).100 , что является полным временем наивной диффузии, так что на этапах диффузии нет преимуществ. @misc{lee2021diffsinger,
author = {Lee, Keon},
title = {DiffSinger},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/keonlee9420/DiffSinger}}
}


