DiffSinger
1.0.0
Implementação de Pytorch de DiffSinger: Síntese de voz de canto via mecanismo de difusão superficial (focado no DiffSpeech).
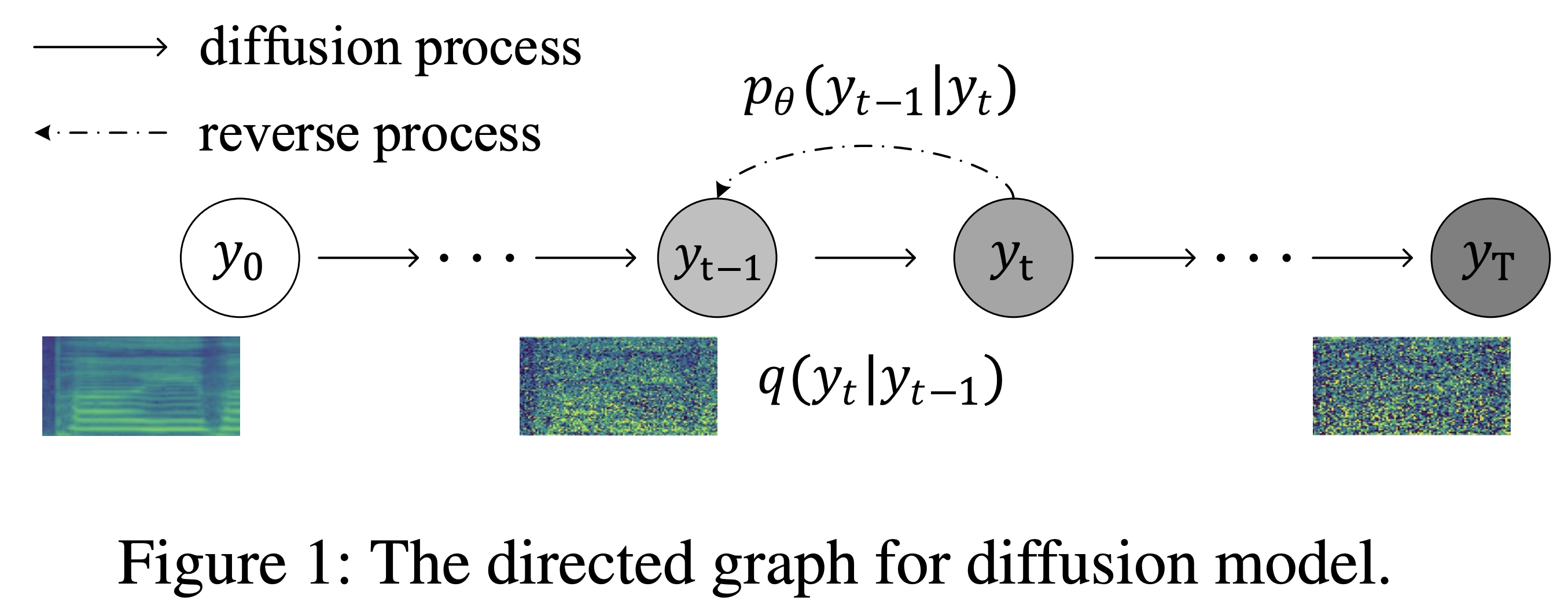
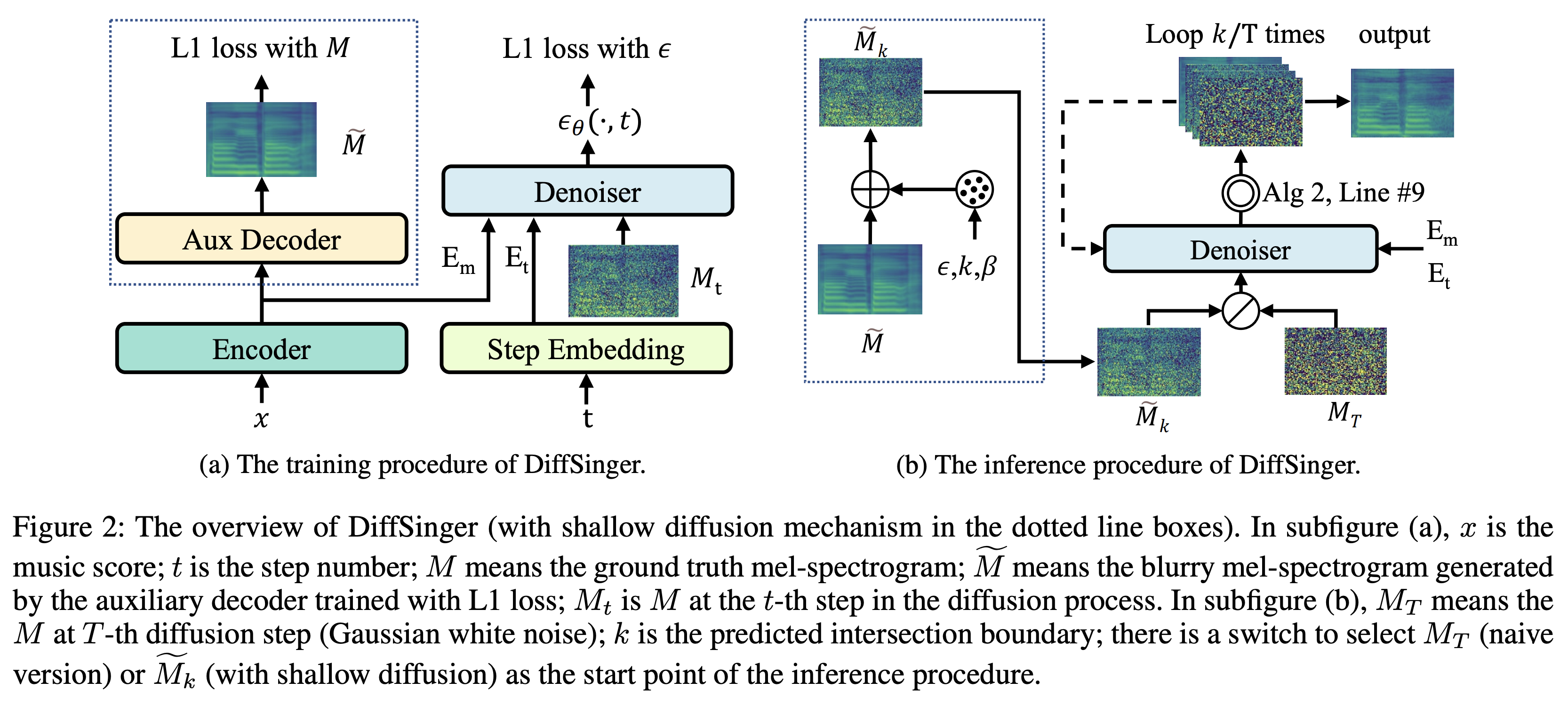
K K como uma etapa máxima de tempo O conjunto de dados refere -se aos nomes de conjuntos de dados como LJSpeech nos documentos a seguir.
O modelo refere -se aos tipos de modelo (escolha de ' ingênuo ', ' aux ', ' raso ').
Você pode instalar as dependências do Python com
pip3 install -r requirements.txt
Você tem que baixar os modelos pré -teremam e colocá -los em
output/ckpt/LJSpeech_naive/ para modelo " ingênuo ".output/ckpt/LJSpeech_shallow/ para modelo ' raso '. Observe que o ponto de verificação do modelo ' raso ' contém modelos ' rasos ' e ' aux ', e esses dois modelos compartilharão todos os diretórios, exceto os resultados durante todo o processo.Para TTS de alto-falante inglês, execute
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --model MODEL --restore_step RESTORE_STEP --mode single --dataset DATASET
Os enunciados gerados serão colocados em output/result/ .
A inferência em lote também é suportada, tente
python3 synthesize.py --source preprocessed_data/LJSpeech/val.txt --model MODEL --restore_step RESTORE_STEP --mode batch --dataset DATASET
Para sintetizar todos os enunciados em preprocessed_data/LJSpeech/val.txt .
A taxa de afinação/volume/fala dos enunciados sintetizados pode ser controlada especificando as taxas desejadas de afinação/energia/duração. Por exemplo, pode -se aumentar a taxa de fala em 20 % e diminuir o volume em 20 % em
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --model MODEL --restore_step RESTORE_STEP --mode single --dataset DATASET --duration_control 0.8 --energy_control 0.8
Observe que a controlabilidade é originada no FastSpeech2 e não é um interesse vital do DiffSpeech.
Os conjuntos de dados suportados são
Primeiro, corra
python3 prepare_align.py --dataset DATASET
para alguns preparativos.
Para o alinhamento forçado, o alinhador forçado de Montreal (MFA) é usado para obter os alinhamentos entre os enunciados e as seqüências de fonemas. Alinhamentos pré-extraídos para os conjuntos de dados são fornecidos aqui. Você precisa descompactar os arquivos em preprocessed_data/DATASET/TextGrid/ . Como alternativa, você pode executar o alinhador sozinho.
Depois disso, execute o script de pré -processamento por
python3 preprocess.py --dataset DATASET
Você pode treinar três tipos de modelo: ' ingênuo ', ' aux ' e ' raso '.
Treinando versão ingênua (' ingênua '):
Treine a versão ingênua com
python3 train.py --model naive --dataset DATASET
Treinando decodificador auxiliar para versão rasa (' aux '):
Para treinar a versão rasa, precisamos de um FastSpeech2 pré-treinado. O comando abaixo permitirá que você treine os módulos FastSpeech2, incluindo o decodificador auxiliar.
python3 train.py --model aux --dataset DATASET
Um truque mais fácil para a previsão de limites:
Para obter o limite K do nosso conjunto de dados de validação, você pode executar o preditor de limites usando o FastSpeech2 pré-treinado pelo comando a seguir.
python3 boundary_predictor.py --restore_step RESTORE_STEP --dataset DATASET
Ele imprimirá o valor previsto (digamos, K_STEP ) no log de comando.
Em seguida, defina a configuração com o valor previsto da seguinte forma
# In the model.yaml
denoiser :
K_step : K_STEPObserve que isso é baseado no truque introduzido no Apêndice B.
Treinando versão rasa (' rasa '):
Para aproveitar o FastSpeech2 pré-treinado, incluindo o decodificador auxiliar, você deve definir restore_step com a etapa final do treinamento auxiliar do FastSpeech2 como o comando a seguir.
python3 train.py --model shallow --restore_step RESTORE_STEP --dataset DATASET
Por exemplo, se o último ponto de verificação for salvo a 160000 etapas durante o treinamento auxiliar, você deverá definir restore_step com 160000 . Em seguida, ele carregará o modelo AUX e continuará o treinamento sob um mecanismo de treinamento superficial.
Usar
tensorboard --logdir output/log/LJSpeech
Para servir o Tensorboard em sua localhost. As curvas de perda, os espectrogramas MEL sintetizados e os áudios são mostrados.
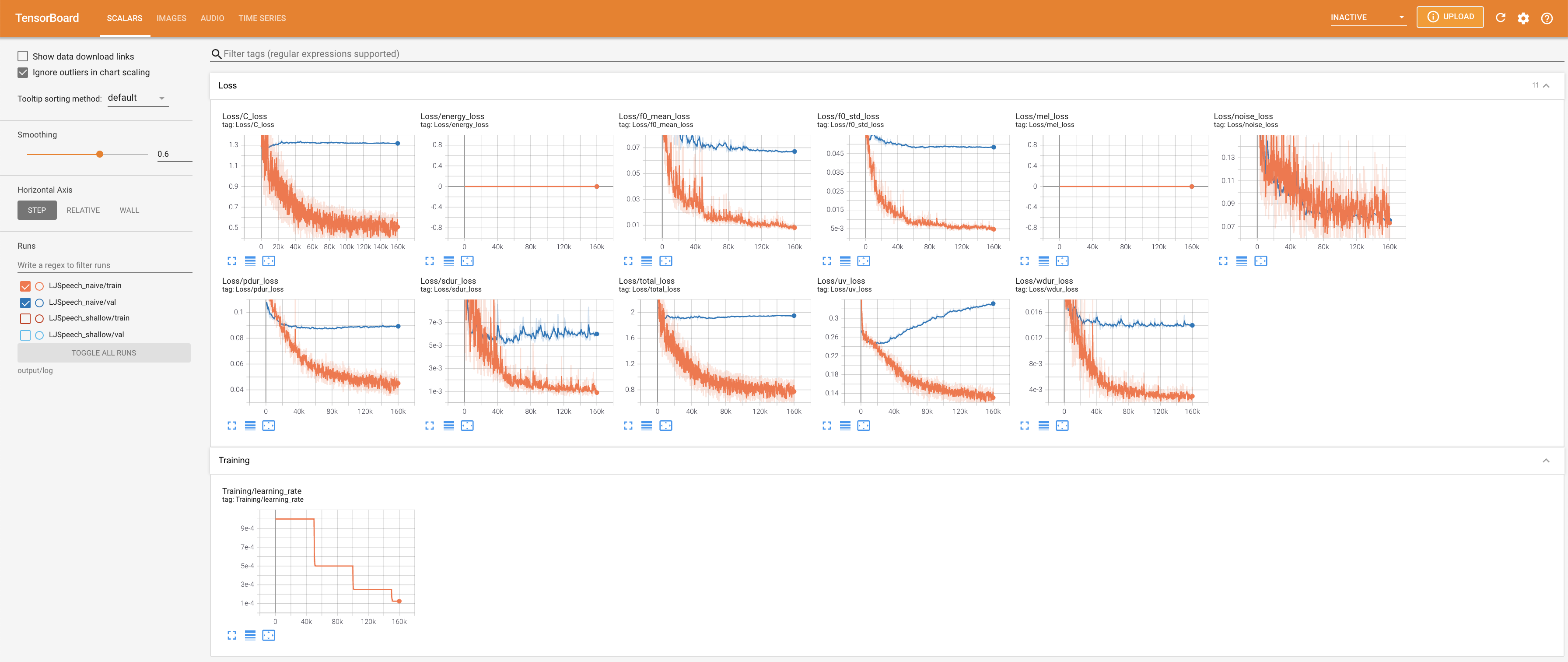
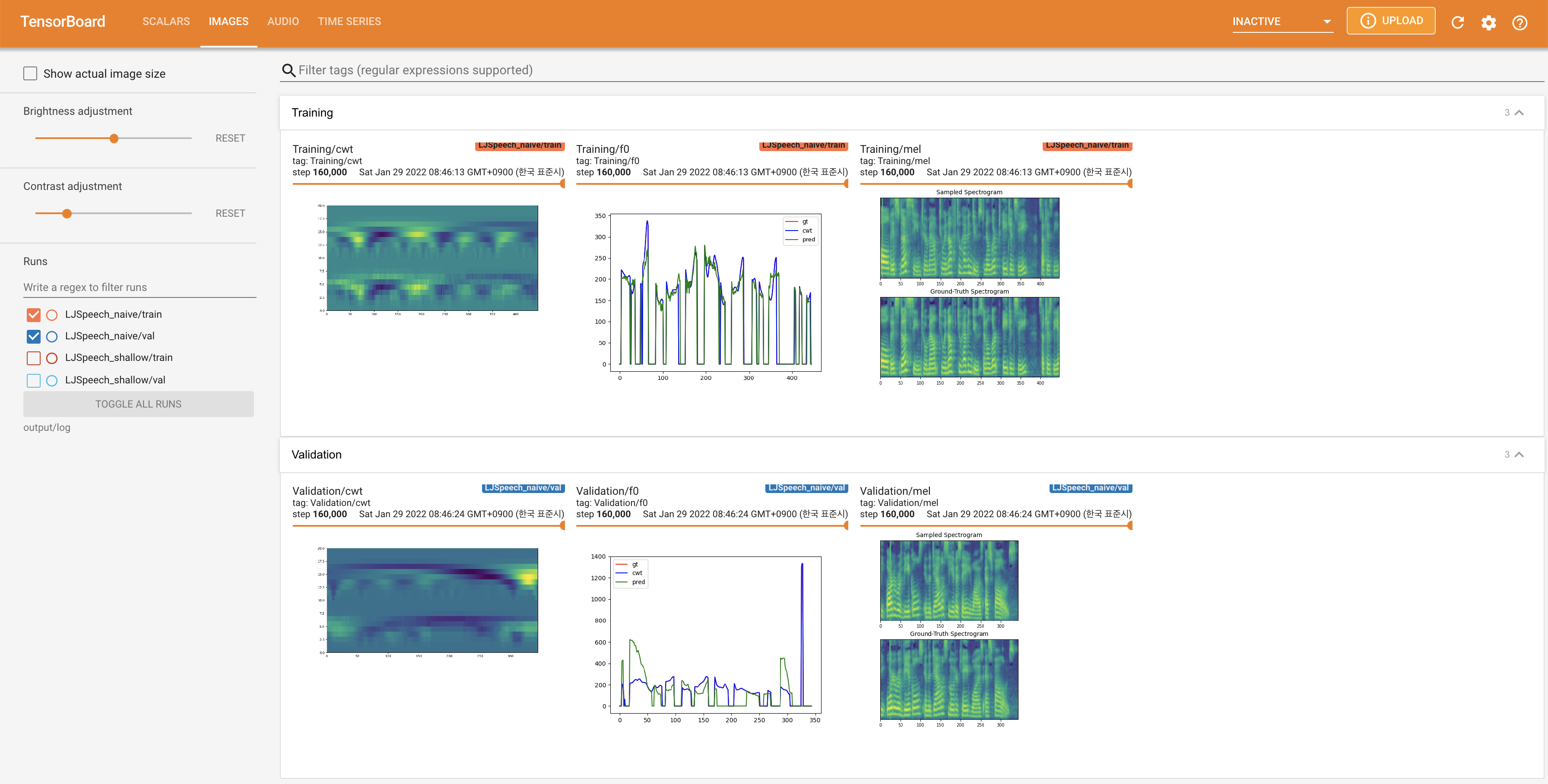
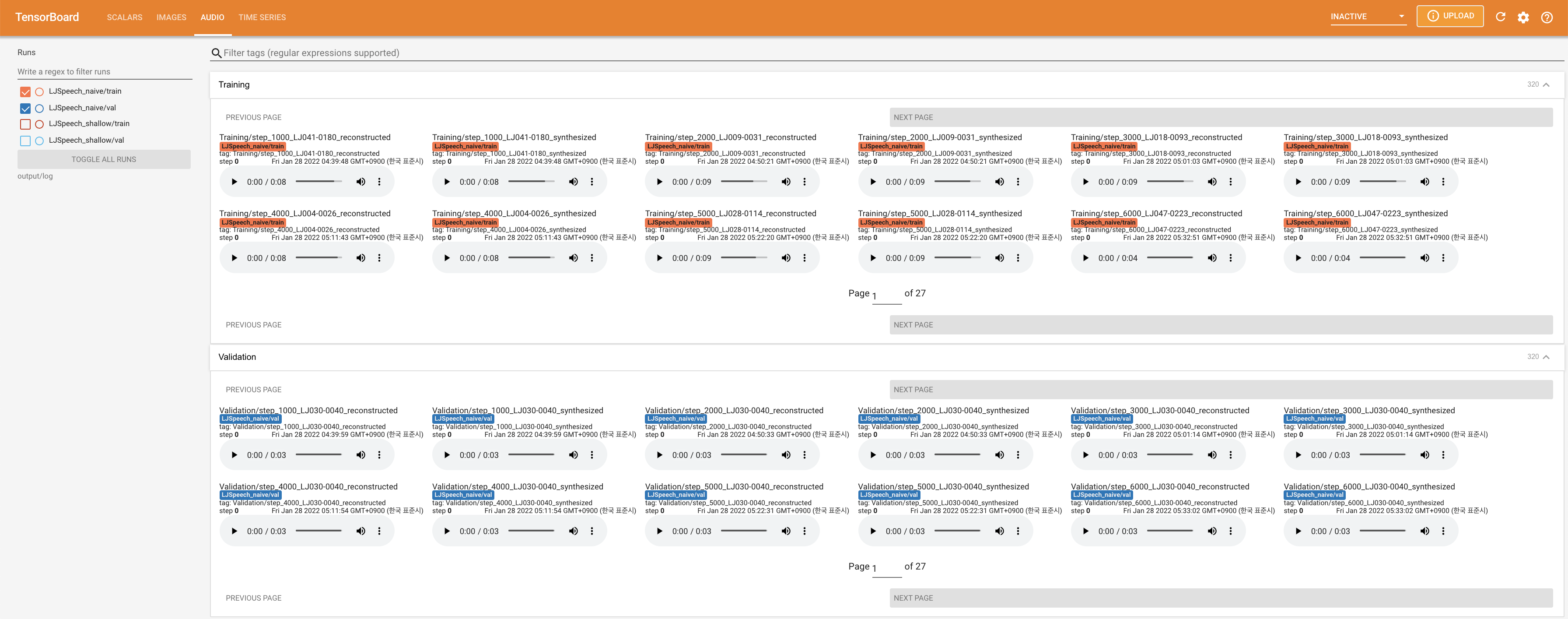
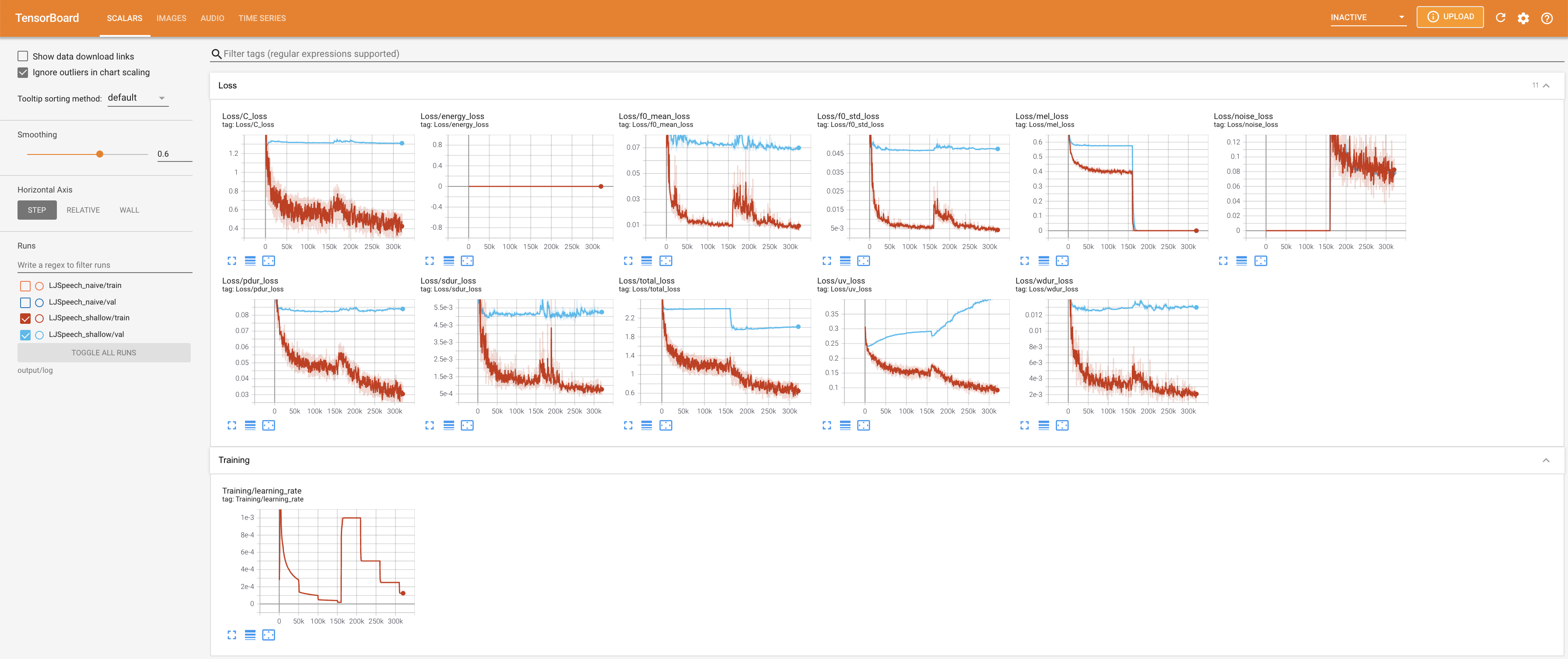
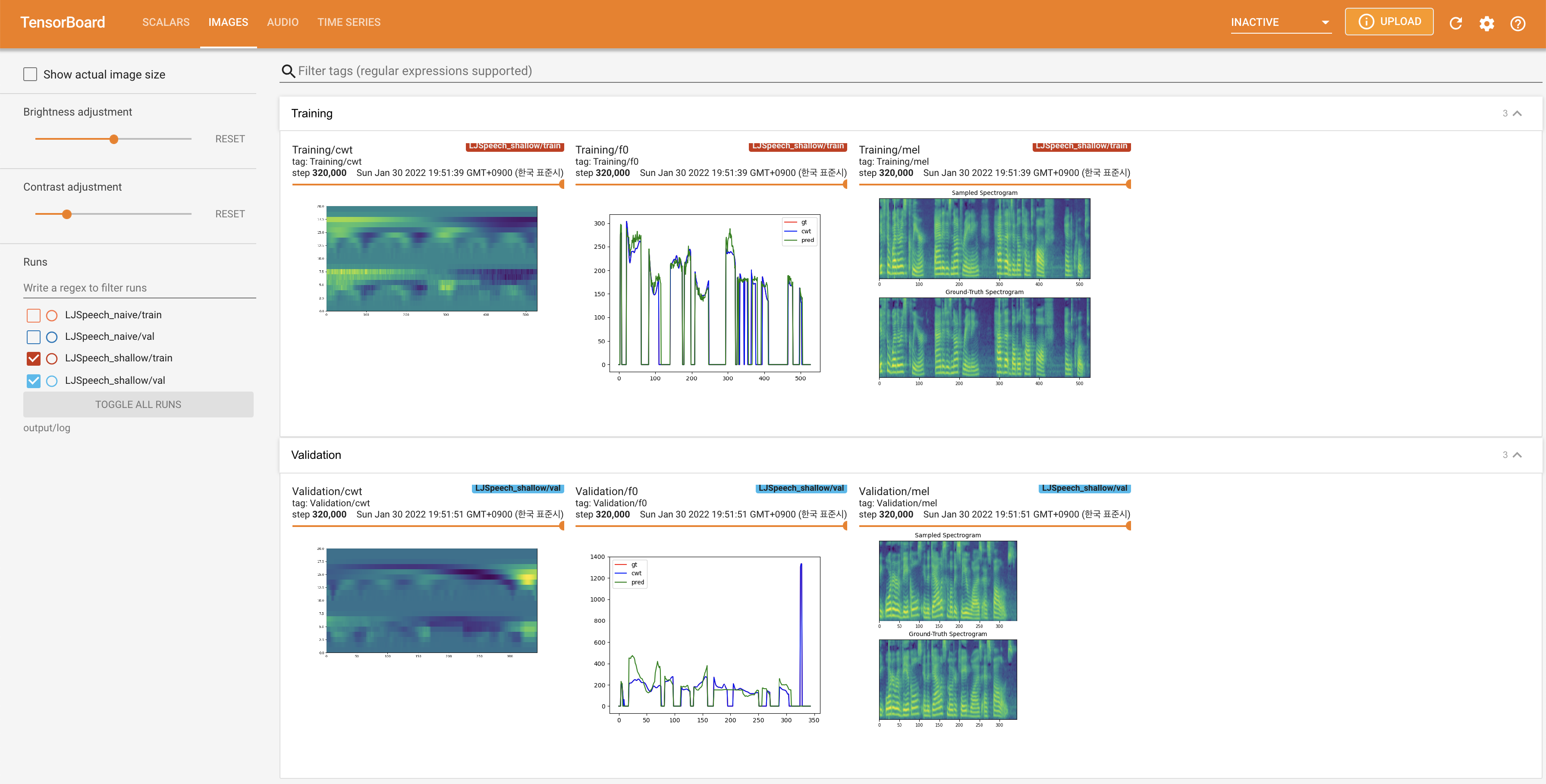
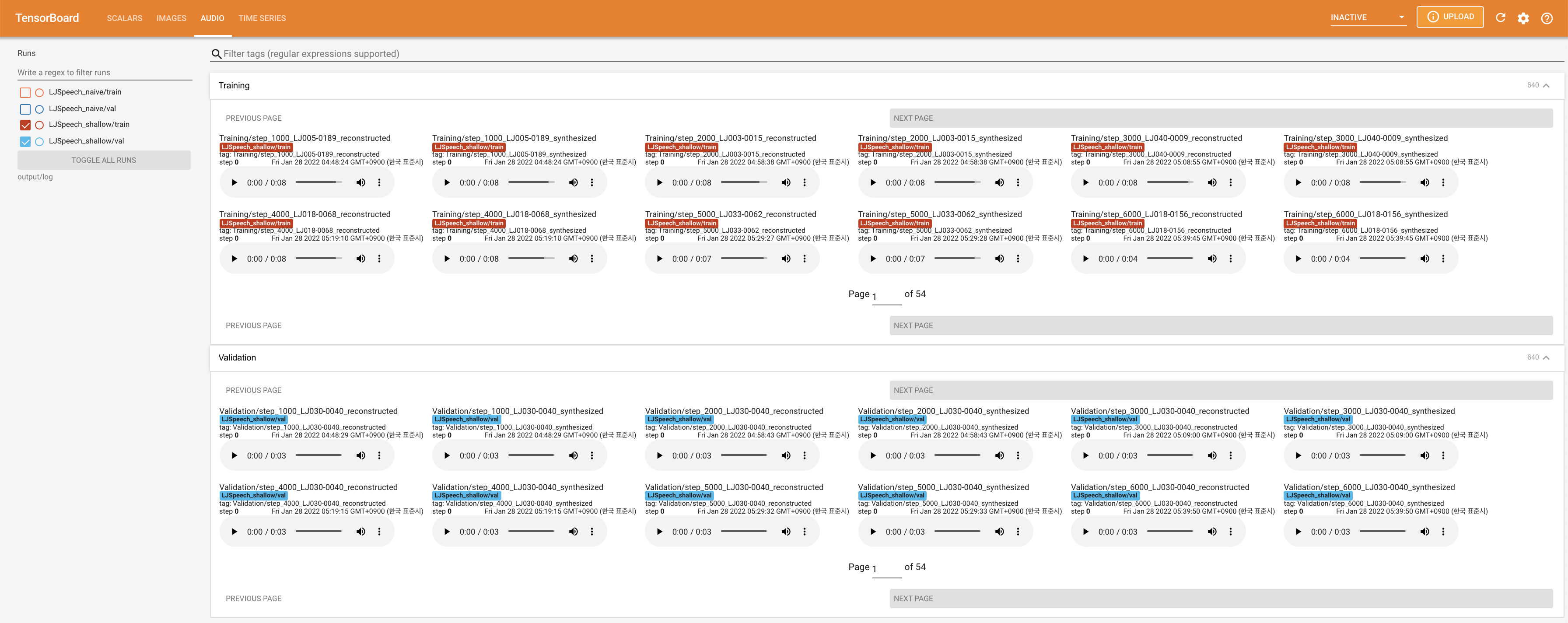
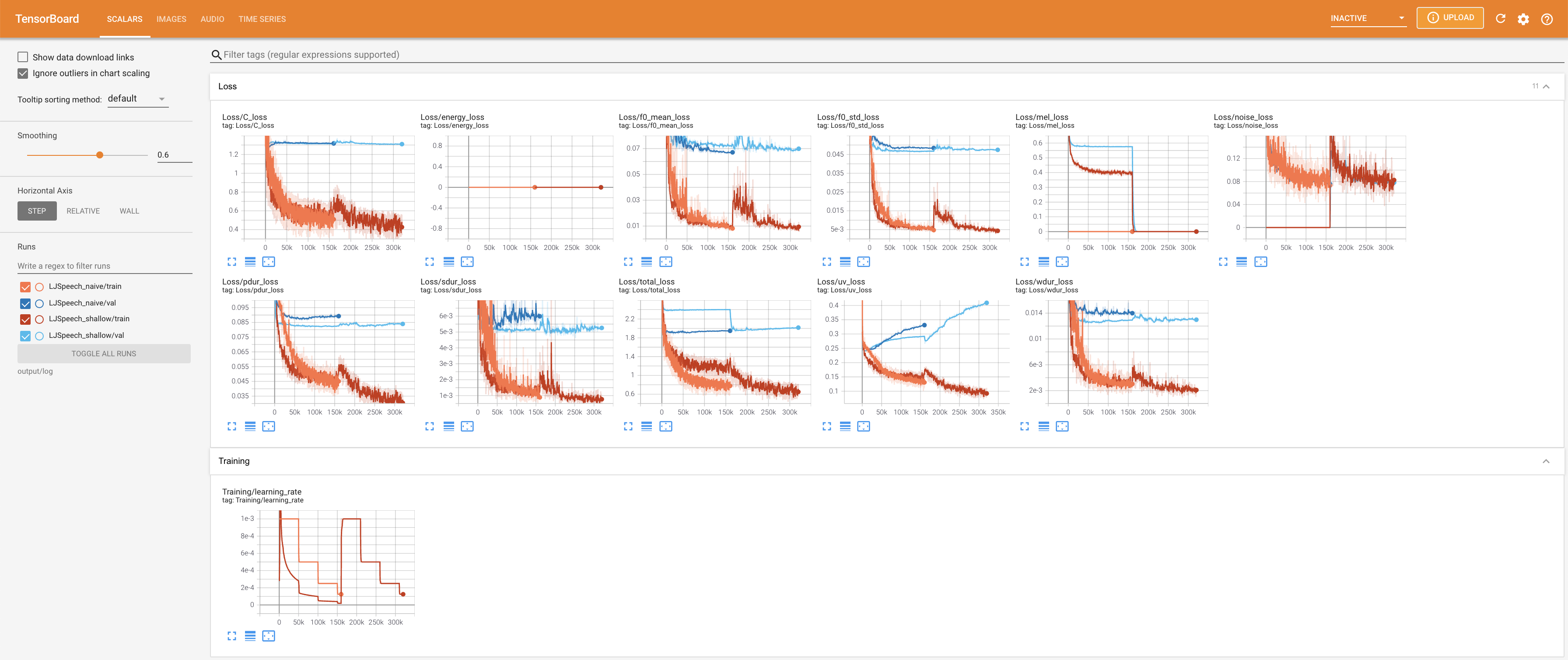
27.767M , que é semelhante ao artigo original ( 27.722M ).100 , que é o tempo completo da difusão ingênua, para que não haja vantagem nas etapas de difusão. @misc{lee2021diffsinger,
author = {Lee, Keon},
title = {DiffSinger},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/keonlee9420/DiffSinger}}
}


