torchsparse
v2.0.0

Torchsparse เป็นไลบรารีเครือข่ายประสาทประสิทธิภาพสูงสำหรับการประมวลผลแบบคลาวด์จุด
การคำนวณแบบคลาวด์ของ Point ได้กลายเป็นภาระงานที่สำคัญยิ่งขึ้นสำหรับการขับขี่แบบอิสระและแอพพลิเคชั่นอื่น ๆ ซึ่งแตกต่างจากการคำนวณ 2D ที่หนาแน่น Point Cloud Convolution มีรูปแบบการคำนวณ ที่กระจัดกระจาย และ ผิดปกติ และต้องใช้การสนับสนุนระบบการอนุมานโดยเฉพาะกับเมล็ดที่มีประสิทธิภาพสูงพิเศษ ในขณะที่ไลบรารีการเรียนรู้เชิงลึกของคลาวด์พอยต์ที่มีอยู่ได้พัฒนา dataflow ที่แตกต่างกันสำหรับ convolution on point clouds พวกเขาถือว่าการไหลของข้อมูลเดียวตลอดการดำเนินการของทั้งรุ่น ในงานนี้เราวิเคราะห์และปรับปรุงการไหลของข้อมูลที่มีอยู่อย่างเป็นระบบ ระบบผลลัพธ์ของเรา Torchsparse บรรลุ 2.9x , 3.3x , 2.2x และ 1.7x วัดการเร่งความเร็วแบบ end-to-end บน Nvidia A100 GPU เหนือ MinkowskiEngine, SPCONV 1.2, TorchSparse (MLSYS) และ SPCONV V2 ตามลำดับ
[2024/11] TorchSparse ++ กำลังรองรับ MMDetection3D และ OpenPCDet ผ่านปลั๊กอิน! มีการสาธิตเต็มรูปแบบ
[2023/11] Torchsparse ++ ได้รับการรับรองโดย One-2-3-45 ++ จาก Prof. Hao Su's Lab (UCSD) สำหรับการสร้างวัตถุ 3 มิติ!
[2023/10] เรานำเสนอ Torchsparse ++ ที่ 56th IEEE/ACM International Symposium บน Microarchitecture (Micro 2023) นอกจากนี้เรายังปล่อยซอร์สโค้ดของ TorchSparse ++ อย่างเต็มที่
[2023/6] Torchsparse ++ ได้รับการรับรองโดย One-2-3-45 จาก Prof. Hao Su's Lab (UCSD) สำหรับการสร้างตาข่าย 3D!
[2023/6] Torchsparse ++ ได้รับการปล่อยตัวและนำเสนอในการประชุมเชิงปฏิบัติการ CVPR 2023 เกี่ยวกับการขับขี่แบบอิสระ มันประสบความสำเร็จ 1.7-2.9x การอนุมานการอนุมานผ่านระบบที่ทันสมัยก่อนหน้านี้
[2023/1] ชุดข้อมูล Argoverse 2 ใช้เครื่องตรวจจับพื้นฐานด้วย Torchsparse
[2022/8] Torchsparse นำเสนอที่ MLSYS 2022 วิดีโอพูดคุยมีให้ที่นี่
[2022/6] Torchsparse ได้รับการรับรองจาก Sparseneus สำหรับการสร้างพื้นผิวประสาท
[2022/1] Torchsparse ได้รับการยอมรับจาก MLSYS 2022 ซึ่งมีการจัดกลุ่มการคูณเมทริกซ์แบบปรับตัวและการเข้าถึงหน่วยความจำที่รับรู้ได้
[2021/6] Torchsparse v1.4 ได้รับการปล่อยตัวแล้ว
เราให้บริการแพ็คเกจ Torchsparse V2.1.0 ที่สร้างไว้ล่วงหน้า (แนะนำ) ด้วยรุ่น pytorch และ cuda ที่แตกต่างกันเพื่อทำให้อาคารสำหรับระบบ Linux ง่ายขึ้น
ตรวจสอบให้แน่ใจว่ามีการติดตั้ง Pytorch 1.9.0 อย่างน้อย:
python -c " import torch; print(torch.__version__) "
>>> 1.10.0หากคุณต้องการใช้ Torchsparse กับ GPU โปรดตรวจสอบให้แน่ใจว่า Pytorch ติดตั้งด้วย CUDA:
python -c " import torch; print(torch.version.cuda) "
>>> 11.3จากนั้นล้อ Torchsparse ด้านขวาสามารถพบและติดตั้งได้โดยเรียกใช้สคริปต์การติดตั้ง:
python -c " $( curl -fsSL https://raw.githubusercontent.com/mit-han-lab/torchsparse/master/install.py ) "หากเซิร์ฟเวอร์ PYPI ไม่ทำงานตามที่คาดไว้ไม่ต้องกังวลคุณยังสามารถดาวน์โหลดล้อด้วยตนเองได้ ล้ออยู่ในเว็บไซต์นี้ หนึ่งสามารถใช้สคริปต์การติดตั้งของเราเพื่อกำหนดหมายเลขรุ่นที่ใช้ในการจัดทำดัชนีล้อโดยอัตโนมัติ ตัวอย่างเช่นหากคุณใช้ Pytorch 1.11.0, Cuda 11.5 หมายเลขเวอร์ชันจะจบลงที่ 2.1.0+Torch111cu115 จากนั้นคุณสามารถเลือกล้อที่เหมาะสมตามรุ่น Python ของคุณ
คุณอาจติดตั้งไลบรารีของเราจากแหล่งที่มาผ่าน:
python setup.py installในที่เก็บหรือใช้
pip install git+https://github.com/mit-han-lab/torchsparse.git
โดยไม่จำเป็นต้องโคลนพื้นที่เก็บข้อมูล
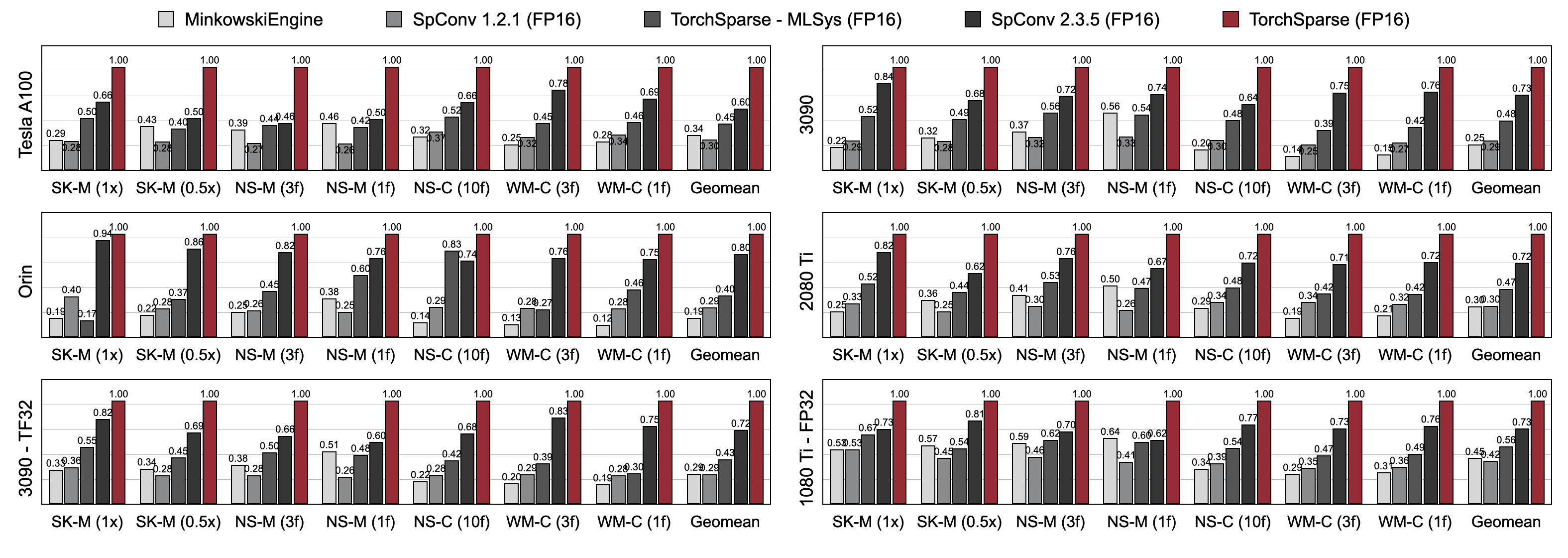
Torchsparse มีประสิทธิภาพสูงกว่าการอนุมานจุดคลาวด์ที่มีอยู่อย่างมีนัยสำคัญทั้งในการตรวจจับวัตถุ 3 มิติและมาตรฐานการแบ่งส่วน LiDAR ในสถาปัตยกรรม GPU สามรุ่น (Pascal, Turing และ Ampere) และ Precisions ทั้งหมด (FP16, TF32, FP32) มันเร็วกว่า 1.7x เร็วกว่า SPCONV 2.3.5 ที่ทันสมัยและเร็วกว่า 2.2 เท่า เร็วกว่า
Torchsparse-MLSYS บนคลาวด์ GPU นอกจากนี้ยังปรับปรุงเวลาแฝงของ SPCONV 2.3.5 โดย 1.25 × ON ORIN

Torchsparse บรรลุความเร็วการฝึกอบรมที่มีความแม่นยำผสมที่เหนือกว่าเมื่อเทียบกับ MinkowskiEngine, Torchsparse-MLSYS และ SPCONV 2.3.5 โดยเฉพาะอย่างยิ่งมันเร็วขึ้น 1.16x บน Tesla A100, เร็วขึ้น 1.27x บน RTX 2080 TI มากกว่า SPCONV ที่ทันสมัย 2.3.5 นอกจากนี้ยังมีประสิทธิภาพสูงกว่า MinkowskiEngine อย่างมีนัยสำคัญโดย 4.6-4.8x ในเจ็ดเกณฑ์มาตรฐานใน A100 และ 2080 TI วัดด้วยขนาดแบทช์ = 2
คุณอาจพบเกณฑ์มาตรฐานของเราจากลิงค์นี้ หากต้องการเข้าถึงชุดข้อมูลที่ประมวลผลล่วงหน้าโปรดติดต่อผู้เขียน เราไม่สามารถเปิดเผยข้อมูลดิบจาก Semantickitti, Nuscenes และ Waymo ได้เนื่องจากข้อกำหนดใบอนุญาต
Torchsparse ได้รับการพัฒนาโดยทีมที่ยอดเยี่ยมต่อไปนี้:
หากคุณใช้ Torchsparse โปรดใช้รายการ BibTex ต่อไปนี้เพื่ออ้างอิง:
Torchsparse ++ (Torchsparse v2.1) นำเสนอที่ Micro 2023:
@inproceedings { tangandyang2023torchsparse ,
title = { TorchSparse++: Efficient Training and Inference Framework for Sparse Convolution on GPUs } ,
author = { Tang, Haotian and Yang, Shang and Liu, Zhijian and Hong, Ke and Yu, Zhongming and Li, Xiuyu and Dai, Guohao and Wang, Yu and Han, Song } ,
booktitle = { IEEE/ACM International Symposium on Microarchitecture (MICRO) } ,
year = { 2023 }
}Torchsparse ++ เวอร์ชันเบื้องต้น (Torchsparse v2.1) นำเสนอที่ CVPR Workshops 2023:
@inproceedings { tangandyang2023torchsparse++ ,
title = { {TorchSparse++: Efficient Point Cloud Engine} } ,
author = { Tang, Haotian and Yang, Shang and Liu, Zhijian and Hong, Ke and Yu, Zhongming and Li, Xiuyu and Dai, Guohao and Wang, Yu and Han, Song } ,
booktitle = { Computer Vision and Pattern Recognition Workshops (CVPRW) } ,
year = { 2023 }
}Torchsparse นำเสนอที่ MLSYS 2022:
@inproceedings { tang2022torchsparse ,
title = { {TorchSparse: Efficient Point Cloud Inference Engine} } ,
author = { Tang, Haotian and Liu, Zhijian and Li, Xiuyu and Lin, Yujun and Han, Song } ,
booktitle = { Conference on Machine Learning and Systems (MLSys) } ,
year = { 2022 }
}Torchsparse เวอร์ชันเริ่มต้นเป็นส่วนหนึ่งของกระดาษ SPVNAS ที่ ECCV 2020:
@inproceedings { tang2020searching ,
title = { {Searching Efficient 3D Architectures with Sparse Point-Voxel Convolution} } ,
author = { Tang, Haotian and Liu, Zhijian and Zhao, Shengyu and Lin, Yujun and Lin, Ji and Wang, Hanrui and Han, Song } ,
booktitle = { European Conference on Computer Vision (ECCV) } ,
year = { 2020 }
}PCENGINE PAPER ได้รับการยอมรับโดย MLSYS 2023:
@inproceedings { hong2023pcengine ,
title = { {Exploiting Hardware Utilization and Adaptive Dataflow for Efficient Sparse Convolution in 3D Point Clouds} } ,
author = { Hong, Ke and Yu, Zhongming and Dai, Guohao and Yang, Xinhao and Lian, Yaoxiu and Liu, Zehao and Xu, Ningyi and Wang, Yu } ,
booktitle = { Sixth Conference on Machine Learning and Systems (MLSys) } ,
year = { 2023 }
}เราขอขอบคุณ Yan Yan จาก Tusimple สำหรับการสนทนาที่เป็นประโยชน์ โปรดดูที่ไลบรารี DGSparse ซึ่งออกแบบมาสำหรับการคำนวณแบบเบาบางที่รวดเร็วและมีประสิทธิภาพบนกราฟและเมฆจุด ทีมงานจากทีม PCEngine (MLSYS 2023) นั้นมีความสัมพันธ์อย่างมากกับเราเช่นกัน
Torchsparse ได้รับแรงบันดาลใจจากห้องสมุดโอเพนซอร์ซที่มีอยู่หลายแห่งรวมถึง (แต่ไม่ จำกัด เพียง) MinkowskiEngine, Second และ Sparseconvnet
นอกจากนี้เรายังขอขอบคุณที่มีส่วนร่วมในการจัดหาวิธีที่สง่างามในการจัดการการกำหนดค่าเคอร์เนล/โมเดล


