torchsparse
v2.0.0

Torchsparseは、ポイントクラウド処理のための高性能ニューラルネットワークライブラリです。
ポイントクラウドの計算は、自律運転やその他のアプリケーションのためにますます重要なワークロードになりました。高密度の2D計算とは異なり、Point Cloud Convolutionにはまばらで不規則な計算パターンがあるため、特殊な高性能カーネルを備えた専用の推論システムサポートが必要です。既存のPoint Cloud Deep Learningライブラリは、ポイントクラウド上の畳み込みのために異なるデータフローを開発していますが、モデル全体の実行中に単一のデータフローを想定しています。この作業では、既存のデータフローを体系的に分析および改善します。結果として得られるシステムであるTorchsparseは、最先端のMinkowskiengine、SPCONV 1.2、Torchsperse(MLSYS)およびSPCONV V2で、NVIDIA A100 GPUで2.9X 、 3.3X 、 2.2X 、2.2X、および1.7Xのエンドツーエンドのスピードアップを達成しました。
[2024/11] Torchsparse ++は、プラグインを介してMMDETection3DおよびOpenPCDETをサポートしています!完全なデモが利用可能です。
[2023/11] Torchsparse ++は、3Dオブジェクト生成のためにHao Suのラボ(UCSD)教授から1-2-3-45 ++で採用されています!
[2023/10]第56回IEEE/ACM International Symposium on Microarchitecture(Micro 2023)でTorchsparse ++を提示します。また、Torchsparse ++のソースコードも完全にリリースします。
[2023/6] Torchsparse ++は、3Dメッシュ再建のためにHao Suのラボ(UCSD)教授から1-2-3-45に採用されています!
[2023/6] Torchsparse ++はリリースされ、CVPR 2023ワークショップで自律運転に関するワークショップで発表されました。これは、以前の最先端のシステムで1.7-2.9xの推論スピードアップを達成します。
[2023/1] 2つのデータセットがトーチスパルスを使用してベースライン検出器を実装しています。
[2022/8] TorchsparseはMLSYS 2022で発表されています。トークビデオはこちらから入手できます。
[2022/6] Torchsparseは、神経表面再建のためにSparseneusによって採用されています。
[2022/1] TorchsparseはMLSYS 2022に受け入れられ、適応マトリックスの乗算グループ化とローカリティ認識メモリアクセスを特徴としています。
[2021/6] Torchsparse V1.4がリリースされました。
Linuxシステムの建物を簡素化するために、さまざまなPytorchおよびCudaバージョンを備えた事前に構築されたTorchsparse V2.1.0パッケージ(推奨)を提供します。
少なくともPytorch 1.9.0がインストールされていることを確認してください。
python -c " import torch; print(torch.__version__) "
>>> 1.10.0GPUでTorchsparseを使用したい場合は、PytorchがCUDAでインストールされていることを確認してください。
python -c " import torch; print(torch.version.cuda) "
>>> 11.3次に、右のTorchsparseホイールを見つけて、インストールスクリプトを実行することでインストールできます。
python -c " $( curl -fsSL https://raw.githubusercontent.com/mit-han-lab/torchsparse/master/install.py ) "Pypiサーバーが期待どおりに機能しない場合、心配はありませんが、ホイールを手動でダウンロードできます。ホイールはこのウェブサイトにリストされています。インストールスクリプトを利用して、ホイールのインデックスを作成するために使用されるバージョン番号を自動的に決定できます。たとえば、Pytorch 1.11.0、Cuda 11.5を使用すると、バージョン番号は2.1.0+Torch111Cu115になります。その後、Pythonバージョンに応じて適切なホイールを選択できます。
また、以下をソースからライブラリをインストールすることもできます。
python setup.py installリポジトリまたは使用
pip install git+https://github.com/mit-han-lab/torchsparse.git
リポジトリをクローンする必要なく。
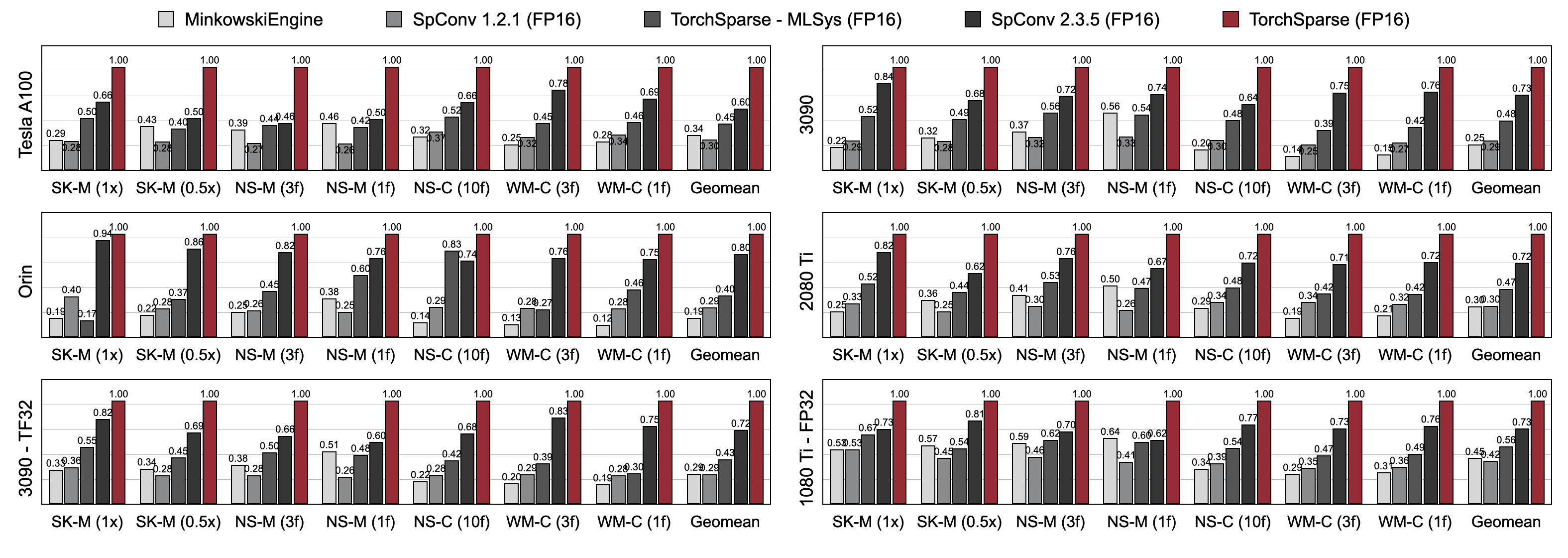
Torchsparseは、3世代のGPUアーキテクチャ(Pascal、Turing、Ampere)およびすべての精度(FP16、TF32、FP32)にわたる3Dオブジェクト検出およびLIDARセグメンテーションベンチマークの両方で、既存のポイントクラウド推論エンジンを大幅に上回ります。最先端のSPCONV 2.3.5よりも最大1.7倍高速で、最大2.2倍高速です
クラウドGPUのTorchsparse-Mlsys。また、OrinでSPCONV 2.3.5 x 1.25×の遅延を改善します。

Torchsparseは、Minkowskiengine、Torchsparse-Mlsys、SPCONV 2.3.5と比較して、優れた混合精度トレーニング速度を達成します。具体的には、Tesla A100で1.16倍高速で、最先端のSPCONV 2.3.5よりもRTX 2080 TIで1.27倍高速です。また、A100および2080 TIの7つのベンチマークでMinkowskiengineを4.6-4.8倍上回ることも大幅に上回ります。バッチサイズ= 2で測定。
このリンクからベンチマークを見つけることができます。前処理されたデータセットにアクセスするには、著者に連絡してください。ライセンス要件により、Semantickitti、Nuscenes、Waymoから生データを公開することはできません。
Torchsparseは、次の素晴らしいチームによって開発されています。
Torchsparseを使用する場合は、次のBibtexエントリを使用して引用してください。
Torchsparse ++(Torchsparse V2.1)は、Micro 2023で提示されています。
@inproceedings { tangandyang2023torchsparse ,
title = { TorchSparse++: Efficient Training and Inference Framework for Sparse Convolution on GPUs } ,
author = { Tang, Haotian and Yang, Shang and Liu, Zhijian and Hong, Ke and Yu, Zhongming and Li, Xiuyu and Dai, Guohao and Wang, Yu and Han, Song } ,
booktitle = { IEEE/ACM International Symposium on Microarchitecture (MICRO) } ,
year = { 2023 }
}Torchsparse ++(Torchsparse V2.1)の予備バージョンは、CVPRワークショップ2023で発表されています。
@inproceedings { tangandyang2023torchsparse++ ,
title = { {TorchSparse++: Efficient Point Cloud Engine} } ,
author = { Tang, Haotian and Yang, Shang and Liu, Zhijian and Hong, Ke and Yu, Zhongming and Li, Xiuyu and Dai, Guohao and Wang, Yu and Han, Song } ,
booktitle = { Computer Vision and Pattern Recognition Workshops (CVPRW) } ,
year = { 2023 }
}TorchsparseはMLSYS 2022で発表されています。
@inproceedings { tang2022torchsparse ,
title = { {TorchSparse: Efficient Point Cloud Inference Engine} } ,
author = { Tang, Haotian and Liu, Zhijian and Li, Xiuyu and Lin, Yujun and Han, Song } ,
booktitle = { Conference on Machine Learning and Systems (MLSys) } ,
year = { 2022 }
}Torchsparseの初期バージョンは、ECCV 2020のSPVNASペーパーの一部です。
@inproceedings { tang2020searching ,
title = { {Searching Efficient 3D Architectures with Sparse Point-Voxel Convolution} } ,
author = { Tang, Haotian and Liu, Zhijian and Zhao, Shengyu and Lin, Yujun and Lin, Ji and Wang, Hanrui and Han, Song } ,
booktitle = { European Conference on Computer Vision (ECCV) } ,
year = { 2020 }
}PCENGINEペーパーはMLSYS 2023によって受け入れられています。
@inproceedings { hong2023pcengine ,
title = { {Exploiting Hardware Utilization and Adaptive Dataflow for Efficient Sparse Convolution in 3D Point Clouds} } ,
author = { Hong, Ke and Yu, Zhongming and Dai, Guohao and Yang, Xinhao and Lian, Yaoxiu and Liu, Zehao and Xu, Ningyi and Wang, Yu } ,
booktitle = { Sixth Conference on Machine Learning and Systems (MLSys) } ,
year = { 2023 }
}有益な議論をしてくれたTusimpleのYan Yanに感謝します。また、グラフとポイントクラウドで高速で効率的なスパース計算用に設計されたDGSParseライブラリもご覧ください。 PCENGINE(MLSYS 2023)チームからの作業も私たちと非常に関連しています。
Torchsparseは、Minkowskiengine、Second、SparseConvnetなど、既存の多くのオープンソースライブラリに触発されています。
また、カーネル/モデルの構成を管理するエレガントな方法を提供してくれたAtributedictに感謝します。


