torchsparse
v2.0.0

Torchsparse는 포인트 클라우드 처리를위한 고성능 신경망 라이브러리입니다.
포인트 클라우드 계산은 자율 주행 및 기타 응용 프로그램을위한 점점 더 중요한 워크로드가되었습니다. 밀도가 높은 2D 계산과 달리 Point Cloud Convolution은 희박 하고 불규칙한 계산 패턴을 가지므로 특수 고성능 커널을 사용한 전용 추론 시스템 지원이 필요합니다. 기존 포인트 클라우드 딥 러닝 라이브러리는 포인트 클라우드의 컨볼 루션을위한 다양한 데이터 플로우를 개발했지만 전체 모델 실행 전반에 걸쳐 단일 데이터 흐름을 가정합니다. 이 작업에서는 기존 데이터 흐름을 체계적으로 분석하고 개선합니다. 우리의 결과 시스템 인 Torchsparse는 각각 최신 Minkowskiengine, SPCONV 1.2, Torchsparse (MLSYS) 및 SPCONV V2에 대한 NVIDIA A100 GPU에서 2.9x , 3.3x , 2.2x 및 1.7x 측정 엔드 투 엔드 속도를 달성했습니다.
[2024/11] Torchsparse ++는 이제 플러그인을 통해 mmdetection3d 및 OpenPCDet을 지원하고 있습니다! 전체 데모를 사용할 수 있습니다.
[2023/11] Torchsparse ++는 3D 객체 생성을 위해 Hao Su 's Lab (UCSD)의 One-2-3-45 ++에 의해 채택되었습니다!
[2023/10] 우리는 56 번째 IEEE/ACM International Symposium on Microarchitecture (Micro 2023)에 Torchsparse ++를 제시합니다. 우리는 또한 Torchsparse ++의 소스 코드를 완전히 공개합니다.
[2023/6] Torchsparse ++는 3D 메쉬 재구성을 위해 Hao Su 's Lab (UCSD)의 One-2-3-45에 의해 채택되었습니다!
[2023/6] Torchsparse ++는 자율 주행에 관한 CVPR 2023 워크샵에서 발표 및 발표되었습니다. 이전 최신 시스템에 대한 1.7-2.9 배의 추론 속도를 달성합니다.
[2023/1] Argoves 2 데이터 세트는 Torchsparse와 함께 기준 감지기를 구현합니다.
[2022/8] Torchsparse는 MLSYS 2022에 발표됩니다. Talk 비디오는 여기에서 제공됩니다.
[2022/6] Torchsparse는 Sparseneus에 의해 신경 표면 재건을 위해 채택되었습니다.
[2022/1] Torchsparse는 적응 형 매트릭스 곱셈 그룹화 및 지역 인식 메모리 액세스를 특징으로하는 MLSYS 2022에 허용되었습니다.
[2021/6] Torchsparse v1.4가 출시되었습니다.
우리는 Linux 시스템의 건물을 단순화하기 위해 다양한 Pytorch 및 Cuda 버전과 함께 사전 구축 된 Torchsparse v2.1.0 패키지 (권장)를 제공합니다.
최소한 Pytorch 1.9.0이 설치되었는지 확인하십시오.
python -c " import torch; print(torch.__version__) "
>>> 1.10.0GPU와 함께 Torchsparse를 사용하려면 Pytorch가 Cuda와 함께 설치되었는지 확인하십시오.
python -c " import torch; print(torch.version.cuda) "
>>> 11.3그런 다음 설치 스크립트를 실행하여 오른쪽 Torchsparse 휠을 찾아 설치할 수 있습니다.
python -c " $( curl -fsSL https://raw.githubusercontent.com/mit-han-lab/torchsparse/master/install.py ) "PYPI 서버가 예상대로 작동하지 않으면 걱정하지 않으면 휠을 수동으로 다운로드 할 수 있습니다. 바퀴는이 웹 사이트에 나열되어 있습니다. 설치 스크립트를 사용하여 휠을 인덱싱하는 데 사용되는 버전 번호를 자동으로 결정할 수 있습니다. 예를 들어, Pytorch 1.11.0, Cuda 11.5를 사용하는 경우 버전 번호는 2.1.0+Torch111CU115입니다. 그런 다음 파이썬 버전에 따라 적절한 휠을 선택할 수 있습니다.
당신은 또한 다음을 통해 소스에서 라이브러리를 설치할 수도 있습니다.
python setup.py install저장소에서 또는 사용
pip install git+https://github.com/mit-han-lab/torchsparse.git
저장소를 복제 할 필요없이.
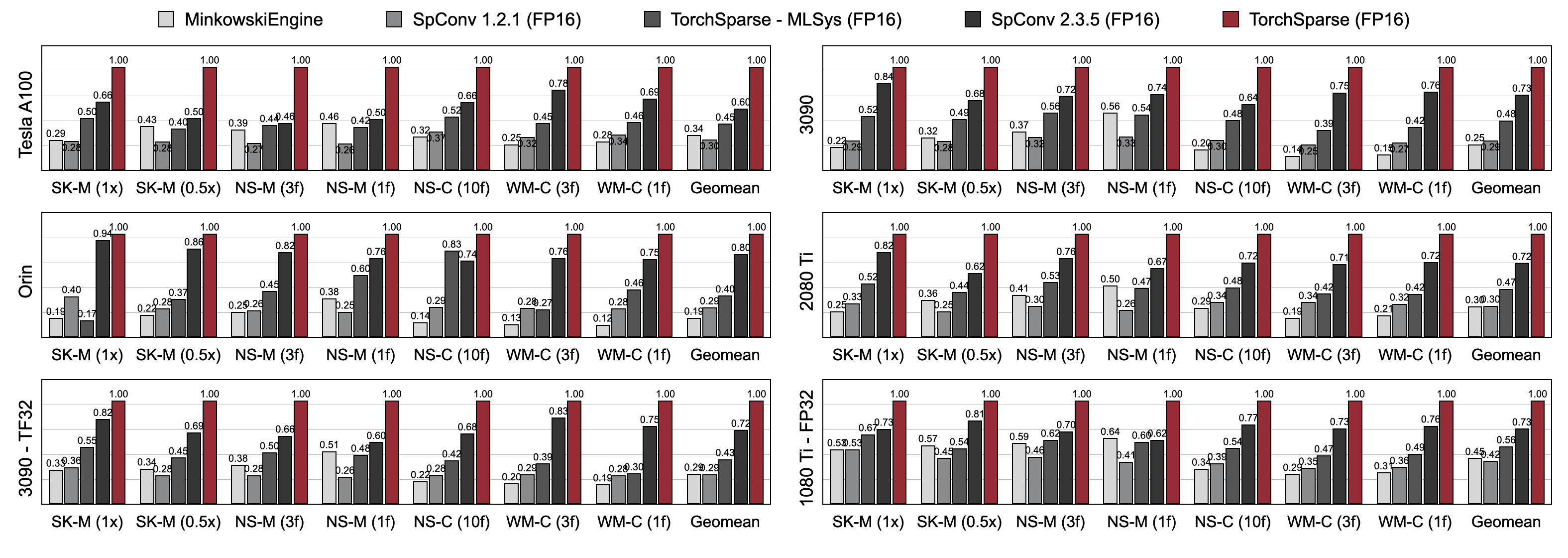
Torchsparse는 3 세대 GPU 아키텍처 (Pascal, Turing and Ampere) 및 모든 선행 (FP16, TF32, FP32)에서 3D 객체 감지 및 LIDAR 세분화 벤치 마크에서 기존 포인트 클라우드 추론 엔진을 훨씬 능가합니다. 최첨단 SPCONV 2.3.5보다 최대 1.7 배 빠르며
클라우드 GPU의 Torchsparse-Mlsys. 또한 Orin에서 SPCONV 2.3.5의 대기 시간을 1.25 x 로 향상시킵니다.

Torchsparse는 MinkowskiEngine, Torchsparse-MLSYS 및 SPCONV 2.3.5와 비교하여 우수한 혼합 정밀 훈련 속도를 달성합니다. 구체적으로, Tesla A100에서는 1.16 배 빠르며 RTX 2080 TI에서 최첨단 SPCONV 2.3.5보다 1.27 배 빠릅니다. 또한 A100 및 2080 TI의 7 개의 벤치 마크에서 MinkowskiEngine을 4.6-4.8 배 보다 훨씬 능가합니다. 배치 크기 = 2로 측정.
이 링크에서 벤치 마크를 찾을 수 있습니다. 전처리 데이터 세트에 액세스하려면 저자에게 문의하십시오. 라이센스 요구 사항으로 인해 Semantickitti, Nuscenes 및 Waymo의 원시 데이터를 공개적으로 공개 할 수 없습니다.
Torchsparse는 다음과 같은 멋진 팀에 의해 개발되었습니다.
Torchsparse를 사용하는 경우 다음 Bibtex 항목을 사용하여 다음과 같습니다.
Torchsparse ++ (Torchsparse v2.1)는 Micro 2023에서 제시됩니다.
@inproceedings { tangandyang2023torchsparse ,
title = { TorchSparse++: Efficient Training and Inference Framework for Sparse Convolution on GPUs } ,
author = { Tang, Haotian and Yang, Shang and Liu, Zhijian and Hong, Ke and Yu, Zhongming and Li, Xiuyu and Dai, Guohao and Wang, Yu and Han, Song } ,
booktitle = { IEEE/ACM International Symposium on Microarchitecture (MICRO) } ,
year = { 2023 }
}Torchsparse ++의 예비 버전 (Torchsparse v2.1)은 CVPR 워크샵 2023에서 발표됩니다.
@inproceedings { tangandyang2023torchsparse++ ,
title = { {TorchSparse++: Efficient Point Cloud Engine} } ,
author = { Tang, Haotian and Yang, Shang and Liu, Zhijian and Hong, Ke and Yu, Zhongming and Li, Xiuyu and Dai, Guohao and Wang, Yu and Han, Song } ,
booktitle = { Computer Vision and Pattern Recognition Workshops (CVPRW) } ,
year = { 2023 }
}Torchsparse는 MLSYS 2022에서 발표됩니다.
@inproceedings { tang2022torchsparse ,
title = { {TorchSparse: Efficient Point Cloud Inference Engine} } ,
author = { Tang, Haotian and Liu, Zhijian and Li, Xiuyu and Lin, Yujun and Han, Song } ,
booktitle = { Conference on Machine Learning and Systems (MLSys) } ,
year = { 2022 }
}Torchsparse의 초기 버전은 ECCV 2020의 SPVNAS 용지의 일부입니다.
@inproceedings { tang2020searching ,
title = { {Searching Efficient 3D Architectures with Sparse Point-Voxel Convolution} } ,
author = { Tang, Haotian and Liu, Zhijian and Zhao, Shengyu and Lin, Yujun and Lin, Ji and Wang, Hanrui and Han, Song } ,
booktitle = { European Conference on Computer Vision (ECCV) } ,
year = { 2020 }
}PCENGINE PAPER은 MLSYS 2023에 의해 허용됩니다.
@inproceedings { hong2023pcengine ,
title = { {Exploiting Hardware Utilization and Adaptive Dataflow for Efficient Sparse Convolution in 3D Point Clouds} } ,
author = { Hong, Ke and Yu, Zhongming and Dai, Guohao and Yang, Xinhao and Lian, Yaoxiu and Liu, Zehao and Xu, Ningyi and Wang, Yu } ,
booktitle = { Sixth Conference on Machine Learning and Systems (MLSys) } ,
year = { 2023 }
}유용한 토론을 위해 Tusimple의 Yan Yan에게 감사드립니다. 또한 그래프 및 포인트 클라우드에서 빠르고 효율적인 희소 계산을 위해 설계된 DGSPARSE 라이브러리를 살펴보십시오. PCENGINE (MLSYS 2023) 팀의 작업도 우리와 관련이 있습니다.
Torchsparse는 Minkowskiengine, Sec
또한 커널/모델 구성을 관리하는 우아한 방법을 제공해 주신 Edributedict에 감사드립니다.


