torchsparse
v2.0.0

TorchSparse-это высокопроизводительная библиотека нейронной сети для обработки облака точек.
Облачное вычисление точек становится все более важной рабочей нагрузкой для автономного вождения и других приложений. В отличие от плотных 2D вычислений, точечная облачная свертка имеет разреженные и нерегулярные вычисления и, следовательно, требует выделенной поддержки системы вывода со специализированными высокопроизводительными ядрами. В то время как существующие библиотеки глубокого обучения в облаке точек разработали различные потоки данных для свертки на точечных облаках, они предполагают один поток данных на протяжении всего выполнения всей модели. В этой работе мы систематически анализируем и улучшаем существующие потоки данных. Наша полученная система, TorchSparse, достигает 2,9x , 3,3x , 2,2x и 1,7x измеренное сквозное ускорение на GPU Nvidia A100 над современным Minkowskiengine, SPCONV 1.2, Torchsparse (MLSYS) и SPCONV V2 в выводе соответственно.
[2024/11] TorchSparse ++ теперь поддерживает MMDetection3D и OpenPCDET через плагины! Полная демонстрация доступна.
[2023/11] TorchSparse ++ был принят одним 2-3-45 ++ из лаборатории профессора Хао Су (UCSD) для генерации 3D объекта!
[2023/10] Мы представляем TorchSparse ++ на 56 -м Международном симпозиуме IEEE/ACM по микроархитектуре (Micro 2023). Мы также полностью отпускаем исходный код TorchSparse ++.
[2023/6] TorchSparse ++ был принят одним 2-3-45 из лаборатории профессора Хао Су (UCSD) для реконструкции 3D сетки!
[2023/6] TorchSparse ++ был выпущен и представлен на семинарах CVPR 2023 по автономному вождению. Он достигает ускорения вывода 1,7-2,9x по сравнению с предыдущими современными системами.
[2023/1] Набор данных Argoverse 2 реализует их базовый детектор TorchSparse.
[2022/8] TorchSparse представлен на MLSYS 2022. Здесь доступно видео.
[2022/6] TorchSparse был принят Sparseneus для реконструкции нейронной поверхности.
[2022/1] TorchSparse был принят в MLSYS 2022, в котором участвуют группировка умножения адаптивной матрицы и доступ к памяти.
[2021/6] TorchSparse v1.4 был выпущен.
Мы предоставляем предварительно построенные пакеты TorchSparse v2.1.0 (рекомендуется) с различными версиями Pytorch и CUDA, чтобы упростить здание для системы Linux.
Убедитесь, что по крайней мере Pytorch 1.9.0 установлен:
python -c " import torch; print(torch.__version__) "
>>> 1.10.0Если вы хотите использовать TorchSparse с графическими процессорами, убедитесь, что Pytorch был установлен с CUDA:
python -c " import torch; print(torch.version.cuda) "
>>> 11.3Затем можно найти правильное колесо TorchSparse и установлено с помощью сценария установки:
python -c " $( curl -fsSL https://raw.githubusercontent.com/mit-han-lab/torchsparse/master/install.py ) "Если PYPI Server не работает, как и ожидалось, не беспокойтесь, вы все равно можете загрузить колеса вручную. Колеса перечислены на этом сайте. Можно использовать наш сценарий установки для автоматического определения номера версии, используемого для индексации колес. Например, если вы используете Pytorch 1.11.0, Cuda 11.5, номер версии в конечном итоге составит 2.1.0+Torch111cu115. Затем вы можете выбрать подходящее колесо в соответствии с вашей версией Python.
Вы также можете альтернативно установить нашу библиотеку из Source Via:
python setup.py installв репозитории или использование
pip install git+https://github.com/mit-han-lab/torchsparse.git
без необходимости клонировать репозиторий.
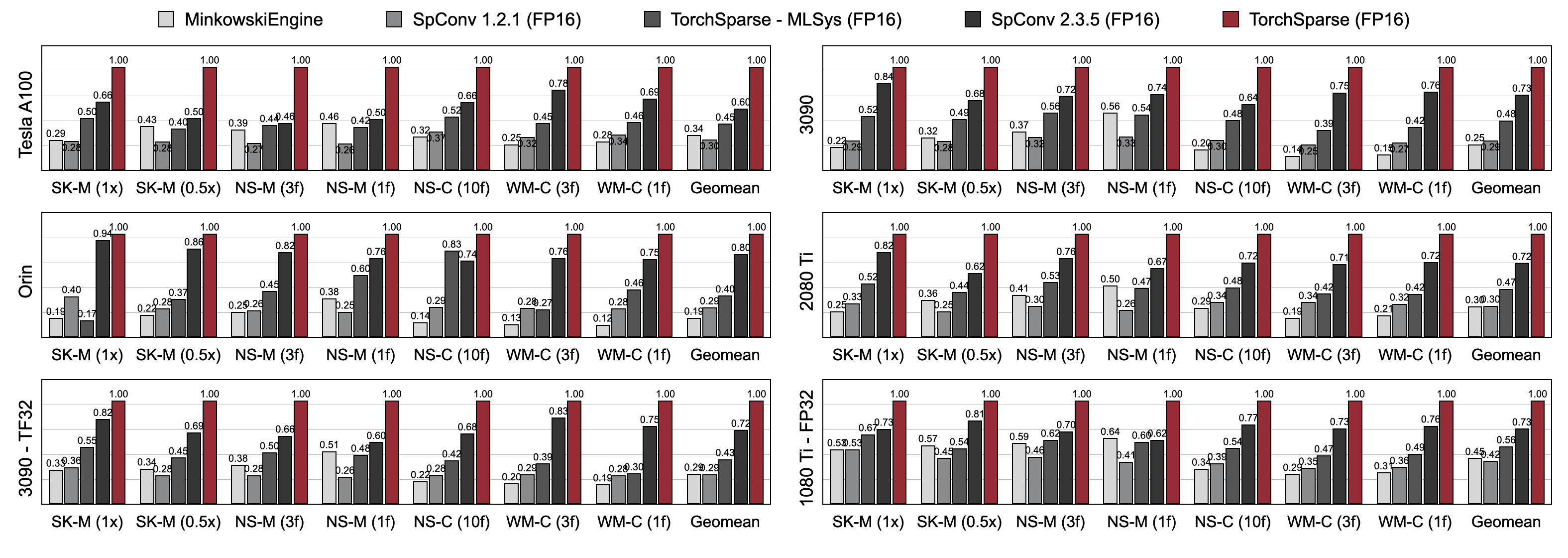
TorchSparse значительно превосходит существующие двигатели с выводом облаков точек как в трехмерном обнаружении объектов, так и в разделе сегментации лидара в трех поколениях архитектуры графических процессоров (Pascal, Turing и Ampere) и всех точек (FP16, TF32, FP32). Это на 1,7 раза быстрее, чем современный SPCONV 2.3.5 и в 2,2 раза быстрее, чем
Torchsparse-Mlsys на облачных графических процессорах. Это также улучшает задержку SPCONV 2.3.5 на 1,25 × на Orin.

TorchSparse достигает превосходной скорости тренировок смешанного назначения по сравнению с Minkowskiengine, Torchsparse-Mlsys и SPConv 2.3.5. В частности, на Tesla A100 на 1,16 раза , на 1,27 раза быстрее на RTX 2080 TI, чем современный SPCONV 2.3.5. Он также значительно превосходит Minkowskiengine на 4,6-4,8x по семи контрольным показателям на A100 и 2080 TI. Измерено с помощью размера партии = 2.
Вы можете найти наши тесты по этой ссылке. Чтобы получить доступ к предварительным наборам данных, пожалуйста, свяжитесь с авторами. Мы не можем публично выпустить необработанные данные из Semantickitti, Nuscenes и Waymo из -за требований лицензии.
TorchSparse разработан следующей замечательной командой:
Если вы используете TorchSparse, используйте следующие записи Bibtex, чтобы цитировать:
TorchSparse ++ (TorchSparse v2.1) представлен на Micro 2023:
@inproceedings { tangandyang2023torchsparse ,
title = { TorchSparse++: Efficient Training and Inference Framework for Sparse Convolution on GPUs } ,
author = { Tang, Haotian and Yang, Shang and Liu, Zhijian and Hong, Ke and Yu, Zhongming and Li, Xiuyu and Dai, Guohao and Wang, Yu and Han, Song } ,
booktitle = { IEEE/ACM International Symposium on Microarchitecture (MICRO) } ,
year = { 2023 }
}Предварительная версия TorchSparse ++ (TorchSparse v2.1) представлена на семинарах CVPR 2023:
@inproceedings { tangandyang2023torchsparse++ ,
title = { {TorchSparse++: Efficient Point Cloud Engine} } ,
author = { Tang, Haotian and Yang, Shang and Liu, Zhijian and Hong, Ke and Yu, Zhongming and Li, Xiuyu and Dai, Guohao and Wang, Yu and Han, Song } ,
booktitle = { Computer Vision and Pattern Recognition Workshops (CVPRW) } ,
year = { 2023 }
}TorchSparse представлен на MLSYS 2022:
@inproceedings { tang2022torchsparse ,
title = { {TorchSparse: Efficient Point Cloud Inference Engine} } ,
author = { Tang, Haotian and Liu, Zhijian and Li, Xiuyu and Lin, Yujun and Han, Song } ,
booktitle = { Conference on Machine Learning and Systems (MLSys) } ,
year = { 2022 }
}Первоначальная версия TorchSparse является частью бумаги SPVNAS в ECCV 2020:
@inproceedings { tang2020searching ,
title = { {Searching Efficient 3D Architectures with Sparse Point-Voxel Convolution} } ,
author = { Tang, Haotian and Liu, Zhijian and Zhao, Shengyu and Lin, Yujun and Lin, Ji and Wang, Hanrui and Han, Song } ,
booktitle = { European Conference on Computer Vision (ECCV) } ,
year = { 2020 }
}Pcengine Paper принимается MLSYS 2023:
@inproceedings { hong2023pcengine ,
title = { {Exploiting Hardware Utilization and Adaptive Dataflow for Efficient Sparse Convolution in 3D Point Clouds} } ,
author = { Hong, Ke and Yu, Zhongming and Dai, Guohao and Yang, Xinhao and Lian, Yaoxiu and Liu, Zehao and Xu, Ningyi and Wang, Yu } ,
booktitle = { Sixth Conference on Machine Learning and Systems (MLSys) } ,
year = { 2023 }
}Мы благодарим Яна Яна из Тусимпла за полезные обсуждения. Пожалуйста, также посмотрите на библиотеку DGSPARSE, которая предназначена для быстрых и эффективных разреженных вычислений на графиках и точечных облаках. Работа от команды PCengine (MLSYS 2023) также тесно связана с нами.
TorchSparse вдохновлен многими существующими библиотеками с открытым исходным кодом, включая (но не ограничивается) Minkowskiengine, Second и SparseConvnet.
Мы также благодарим Attructuctedict за предоставление элегантного способа управления конфигурациями ядра/модели.


