torchsparse
v2.0.0

Torchsparse es una biblioteca de red neuronal de alto rendimiento para el procesamiento de nubes de puntos.
El cálculo de la nube de puntos se ha convertido en una carga de trabajo cada vez más importante para la conducción autónoma y otras aplicaciones. A diferencia del cálculo 2D denso, la convolución de la nube de puntos tiene patrones de cálculo escasos e irregulares y, por lo tanto, requiere soporte de sistema de inferencia dedicado con núcleos especializados de alto rendimiento. Si bien las bibliotecas existentes de aprendizaje profundo de Point Cloud han desarrollado diferentes flujos de datos para la convolución en las nubes de puntos, asumen un solo flujo de datos durante la ejecución de todo el modelo. En este trabajo, analizamos y mejoramos sistemáticamente los flujos de datos existentes. Nuestro sistema resultante, TorchsParse, logra 2.9x , 3.3x , 2.2x y 1.7x midió la aceleración de extremo a extremo en una GPU NVIDIA A100 sobre la MinkowskiEngine de última generación, SPCONV 1.2, TorchsParse (MLSYS) y SPCONV V2 en influencia respectivamente.
[2024/11] TorchsParse ++ ahora admite MMDetection3D y OpenPCDet a través de complementos. Una demostración completa está disponible.
[2023/11] Torchsparse ++ ha sido adoptada por One-2-3-45 ++ del Laboratorio del Prof. Hao Su (UCSD) para la generación de objetos 3D!
[2023/10] Presentamos TorchsParse ++ en el 56º Simposio Internacional IEEE/ACM sobre microarquitectura (Micro 2023). También lanzamos completamente el código fuente de TorchsParse ++.
[2023/6] Torchsparse ++ ha sido adoptada por One-2-3-45 del Laboratorio del Prof. Hao Su (UCSD) para la reconstrucción de la malla 3D!
[2023/6] TorchsParse ++ ha sido lanzado y presentado en Talleres CVPR 2023 sobre conducción autónoma. Logra 1.7-2.9x aceleración de inferencia sobre sistemas de estado de arte anteriores.
[2023/1] Groverse 2 DataSet implementa su detector de referencia con antorchas.
[2022/8] Torchsparse se presenta en MLSYS 2022. El video de Talk está disponible aquí.
[2022/6] La antorchas ha sido adoptada por Sparseneus para la reconstrucción de la superficie neural.
[2022/1] Torchsparse ha sido aceptado para MLSYS 2022, con agrupación de multiplicación de matriz adaptativa y acceso a la memoria consciente de la localidad.
[2021/6] Se ha lanzado la Torchsparse V1.4.
Proporcionamos paquetes de antorchas v2.1.0 pre-construidos (recomendados) con diferentes versiones de Pytorch y CUDA para simplificar el edificio para el sistema Linux.
Asegúrese de que esté instalado al menos Pytorch 1.9.0:
python -c " import torch; print(torch.__version__) "
>>> 1.10.0Si desea usar TorchsParse con GPU, asegúrese de que Pytorch se instalara con CUDA:
python -c " import torch; print(torch.version.cuda) "
>>> 11.3Luego se puede encontrar e instalar la rueda correcta de antorchas de antorchas ejecutando el script de instalación:
python -c " $( curl -fsSL https://raw.githubusercontent.com/mit-han-lab/torchsparse/master/install.py ) "Si el servidor PYPI no funciona como se esperaba, no se preocupe, aún puede descargar manualmente las ruedas. Las ruedas se enumeran en este sitio web. Se puede utilizar nuestro script de instalación para determinar automáticamente el número de versión utilizado para indexar las ruedas. Por ejemplo, si usa Pytorch 1.11.0, CUDA 11.5, el número de versión finalizará para ser 2.1.0+antorch111cu115. Luego puede seleccionar la rueda adecuada de acuerdo con su versión de Python.
También puede instalar alternativamente nuestra biblioteca desde la fuente a través de:
python setup.py installen el repositorio, o usando
pip install git+https://github.com/mit-han-lab/torchsparse.git
sin la necesidad de clonar el repositorio.
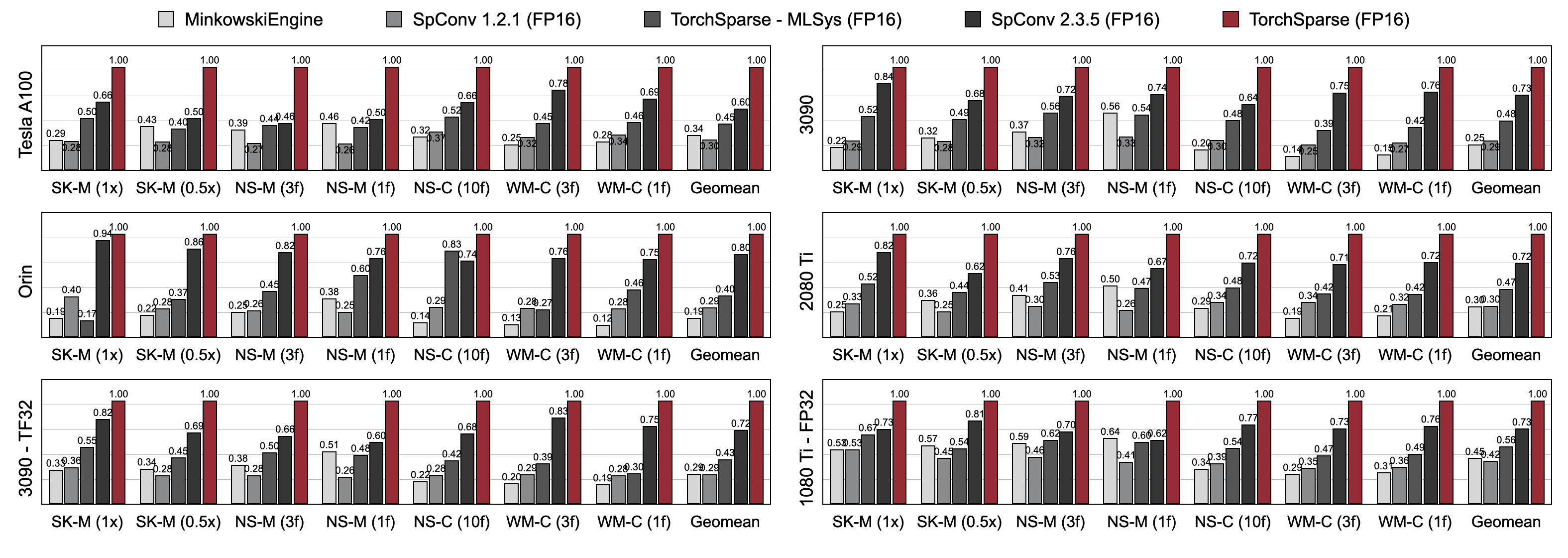
Torchsparse supera significativamente a los motores de inferencia de nubes de puntos existentes tanto en la detección de objetos 3D como en los puntos de referencia de segmentación LIDAR en tres generaciones de arquitectura de GPU (Pascal, Turing y Ampere) y todas las precisiones (FP16, TF32, FP32). Es hasta 1.7 veces más rápido que el spconv 2.3.5 de última generación y es hasta 2.2x más rápido que
Torchsparse-MLSYS en GPU de la nube. También mejora la latencia de SPCONV 2.3.5 por 1.25 × en Orin.

Torchsparse logra una velocidad de entrenamiento de precisión mixta superior en comparación con MinkowskiEngine, TorchsParse-MLSYS y SPCONV 2.3.5. Específicamente, es 1.16x más rápido en Tesla A100, 1.27x más rápido en RTX 2080 Ti que SPCONV 2.3.5 de vanguardia. También supera significativamente a MinkowskiEngine en 4.6-4.8x en siete puntos de referencia en A100 y 2080 Ti. Medido con tamaño por lotes = 2.
Puede encontrar nuestros puntos de referencia de este enlace. Para acceder a conjuntos de datos preprocesados, comuníquese con los autores. No podemos publicar públicamente datos sin procesar de Semantickitti, Nuscenes y Waymo debido a los requisitos de licencia.
Torchsparse es desarrollado por el siguiente equipo maravilloso:
Si usa TorchsParse, use las siguientes entradas de Bibtex para citar:
Torchsparse ++ (Torchsparse v2.1) se presenta en Micro 2023:
@inproceedings { tangandyang2023torchsparse ,
title = { TorchSparse++: Efficient Training and Inference Framework for Sparse Convolution on GPUs } ,
author = { Tang, Haotian and Yang, Shang and Liu, Zhijian and Hong, Ke and Yu, Zhongming and Li, Xiuyu and Dai, Guohao and Wang, Yu and Han, Song } ,
booktitle = { IEEE/ACM International Symposium on Microarchitecture (MICRO) } ,
year = { 2023 }
}La versión preliminar de TorchsParse ++ (Torchsparse v2.1) se presenta en los talleres CVPR 2023:
@inproceedings { tangandyang2023torchsparse++ ,
title = { {TorchSparse++: Efficient Point Cloud Engine} } ,
author = { Tang, Haotian and Yang, Shang and Liu, Zhijian and Hong, Ke and Yu, Zhongming and Li, Xiuyu and Dai, Guohao and Wang, Yu and Han, Song } ,
booktitle = { Computer Vision and Pattern Recognition Workshops (CVPRW) } ,
year = { 2023 }
}Torchsparse se presenta en MLSYS 2022:
@inproceedings { tang2022torchsparse ,
title = { {TorchSparse: Efficient Point Cloud Inference Engine} } ,
author = { Tang, Haotian and Liu, Zhijian and Li, Xiuyu and Lin, Yujun and Han, Song } ,
booktitle = { Conference on Machine Learning and Systems (MLSys) } ,
year = { 2022 }
}La versión inicial de TorchsParse es parte del documento SpvNas en ECCV 2020:
@inproceedings { tang2020searching ,
title = { {Searching Efficient 3D Architectures with Sparse Point-Voxel Convolution} } ,
author = { Tang, Haotian and Liu, Zhijian and Zhao, Shengyu and Lin, Yujun and Lin, Ji and Wang, Hanrui and Han, Song } ,
booktitle = { European Conference on Computer Vision (ECCV) } ,
year = { 2020 }
}El papel pcengine es aceptado por MLSYS 2023:
@inproceedings { hong2023pcengine ,
title = { {Exploiting Hardware Utilization and Adaptive Dataflow for Efficient Sparse Convolution in 3D Point Clouds} } ,
author = { Hong, Ke and Yu, Zhongming and Dai, Guohao and Yang, Xinhao and Lian, Yaoxiu and Liu, Zehao and Xu, Ningyi and Wang, Yu } ,
booktitle = { Sixth Conference on Machine Learning and Systems (MLSys) } ,
year = { 2023 }
}Agradecemos a Yan Yan de Tusimple por sus útiles discusiones. También eche un vistazo a la biblioteca DGSPARSE, que está diseñada para un cálculo disperso rápido y eficiente en gráficos y nubes de puntos. El trabajo del equipo Pcengine (MLSYS 2023) también está altamente relacionado con nosotros.
Torchsparse se inspira en muchas bibliotecas de código abierto existentes, incluidas (entre otros) MinkowskiEngine, Second y Sparseconvnet.
También agradecemos a Attributedict por proporcionar una forma elegante de administrar las configuraciones del núcleo/modelo.


