torchsparse
v2.0.0

Torchsparse هي مكتبة شبكة عصبية عالية الأداء لمعالجة السحابة النقطة.
أصبح الحساب السحابي النقطة بمثابة عبء عمل أكثر أهمية للقيادة المستقلة والتطبيقات الأخرى. على عكس الحساب ثنائي الأبعاد الكثيف ، يحتوي الالتفاف السحابي على أنماط حساب متناثرة وغير منتظمة ، وبالتالي يتطلب دعم نظام الاستدلال المخصص مع نواة متخصصة عالية الأداء. في حين أن مكتبات التعلم العميقة Cloud Point Cloud قد طورت تدفقات بيانات مختلفة من أجل الالتفاف حول غيوم النقطة ، فإنها تفترض تدفق بيانات واحد طوال تنفيذ النموذج بأكمله. في هذا العمل ، نقوم بتحليل وتحسين تدفقات البيانات الحالية بشكل منهجي. يحقق نظامنا الناتج ، Torchsparse ، 2.9x ، 3.3x ، 2.2x و 1.7x مقاسًا سريعًا من طرف إلى طرف على وحدة معالجة الرسومات Nvidia A100 على أحدث طراز Minkowskiengine ، SPConv 1.2 ، Torchsparse (MLSYS) و Spconv V2 على التوالي.
[2024/11] يدعم Torchsparse ++ الآن MMDetection3D و OpenPcDet عبر الإضافات! العرض التوضيحي الكامل متاح.
[2023/11] تم اعتماد Torchsparse ++ بواسطة One-2-3-45 ++ من Prof. Hao Su's Lab (UCSD) لتوليد الكائنات ثلاثية الأبعاد!
[2023/10] نقدم Torchsparse ++ في ندوة IEEE/ACM الدولية 56th IEEE/ACM على الهندسة المعمارية الدقيقة (Micro 2023). نقوم أيضًا بإصدار رمز المصدر لـ Torchsparse ++ بالكامل.
[2023/6] تم اعتماد Torchsparse ++ من قبل واحد 2-3-45 من Prof. Hao Su's Lab (UCSD) لإعادة بناء شبكة ثلاثية الأبعاد!
[2023/6] تم إصدار Torchsparse ++ وعرضه في ورش عمل CVPR 2023 حول القيادة المستقلة. يحقق تسريع من 1.7-2.9x على النظم السابقة.
[2023/1] تقوم مجموعة بيانات Argoverse 2 بتنفيذ كاشف خط الأساس الخاص بها مع Torchsparse.
[2022/8] يتم تقديم Torchsparse في MLSYS 2022. فيديو الحديث متاح هنا.
[2022/6] تم اعتماد Torchsparse بواسطة Sparseneus لإعادة بناء السطح العصبي.
[2022/1] تم قبول Torchsparse في MLSYS 2022 ، ويتميز بتجميع تكاثر المصفوفة التكيفية والوصول إلى الذاكرة على دراية بالمنطقة.
[2021/6] تم إصدار Torchsparse v1.4.
نحن نقدم حزم Torchsparse V2.1.0 مصنوعة مسبقًا (موصى بها) مع إصدارات مختلفة من Pytorch و CUDA لتبسيط المبنى لنظام Linux.
تأكد من تثبيت Pytorch 1.9.0 على الأقل:
python -c " import torch; print(torch.__version__) "
>>> 1.10.0إذا كنت ترغب في استخدام Torchsparse مع وحدات معالجة الرسومات ، فيرجى التأكد من تثبيت Pytorch مع CUDA:
python -c " import torch; print(torch.version.cuda) "
>>> 11.3ثم يمكن العثور على عجلة Torchsparse اليمنى وتثبيتها عن طريق تشغيل البرنامج النصي للتثبيت:
python -c " $( curl -fsSL https://raw.githubusercontent.com/mit-han-lab/torchsparse/master/install.py ) "إذا لم يعمل خادم PYPI كما هو متوقع ، فلا تقلق ، فلا يزال بإمكانك تنزيل العجلات يدويًا. يتم سرد العجلات في هذا الموقع. يمكن للمرء الاستفادة من برنامج التثبيت الخاص بنا لتحديد رقم الإصدار المستخدم تلقائيًا لفهرسة العجلات. على سبيل المثال ، إذا كنت تستخدم Pytorch 1.11.0 ، CUDA 11.5 ، سينتهي رقم الإصدار إلى 2.1.0+Torch111CU115. يمكنك بعد ذلك تحديد العجلة المناسبة وفقًا لإصدار Python الخاص بك.
يمكنك أيضًا تثبيت مكتبتنا بدلاً من ذلك من المصدر عبر:
python setup.py installفي المستودع ، أو باستخدام
pip install git+https://github.com/mit-han-lab/torchsparse.git
دون الحاجة لاستنساخ المستودع.
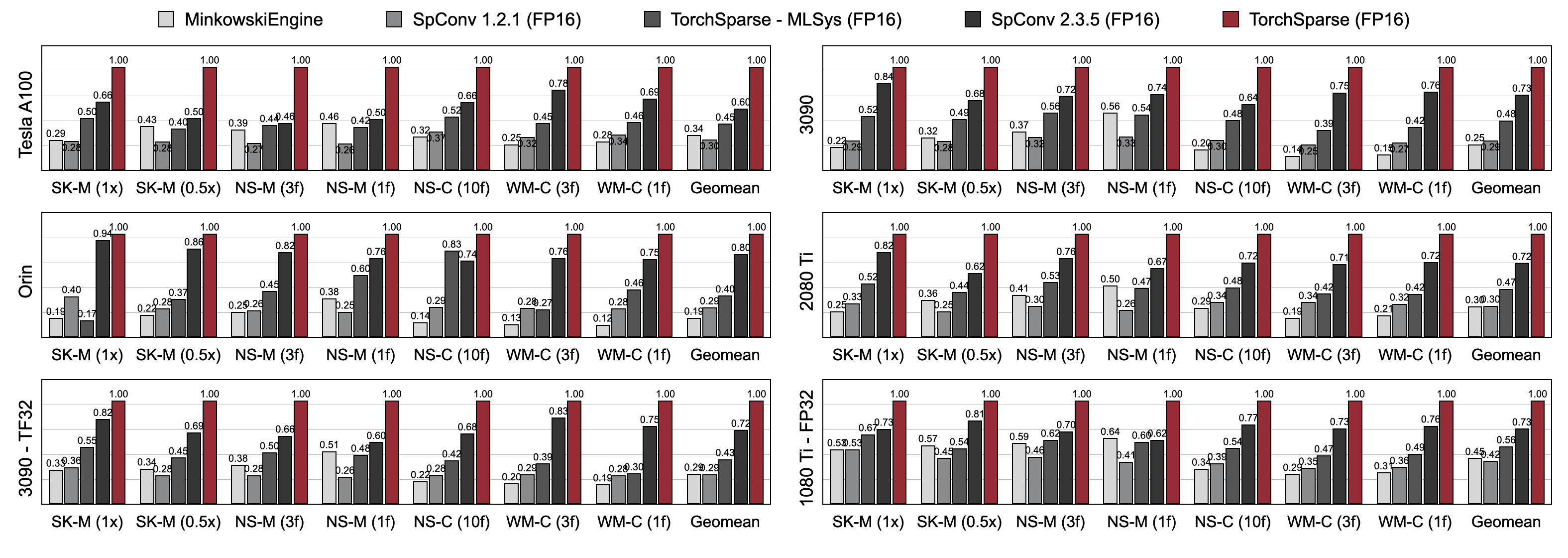
تتفوق Torchsparse بشكل كبير على محركات الاستدلال السحابة النقطة الحالية في كل من معايير الكشف عن الكائنات ثلاثية الأبعاد ومعايير تجزئة Lidar عبر ثلاثة أجيال من بنية GPU (Pascal ، Turing و Ampere) وجميع الدقة (FP16 ، TF32 ، FP32). تصل إلى 1.7x أسرع من أحدث طراز SPConv 2.3.5 ويصل إلى 2.2x أسرع من
torchsparse-mlsys على وحدات معالجة الرسومات السحابة. كما أنه يحسن زمن انتقال SPConv 2.3.5 بمقدار 1.25 × على أورين.

يحقق Torchsparse سرعة تدريب مختلطة فائقة مقارنة مع Minkowskiengine و Torchsparse-Mlsys و SPConv 2.3.5. على وجه التحديد ، هو أسرع 1.16x على Tesla A100 ، 1.27x أسرع على RTX 2080 Ti من أحدث SPConv 2.3.5. كما أنه يتفوق بشكل كبير على MinkowskiEngine بمقدار 4.6-4.8x عبر سبعة معايير على A100 و 2080 Ti. تقاس مع حجم الدُفعة = 2.
قد تجد معاييرنا من هذا الرابط. للوصول إلى مجموعات البيانات المعالجة مسبقًا ، يرجى الاتصال بالمؤلفين. لا يمكننا إصدار البيانات الخام علنًا من Semantickitti و Nuscenes و Waymo بسبب متطلبات الترخيص.
تم تطوير Torchsparse من قبل الفريق الرائع التالي:
إذا كنت تستخدم Torchsparse ، فيرجى استخدام إدخالات bibtex التالية للاستشهاد:
يتم تقديم Torchsparse ++ (Torchsparse v2.1) في Micro 2023:
@inproceedings { tangandyang2023torchsparse ,
title = { TorchSparse++: Efficient Training and Inference Framework for Sparse Convolution on GPUs } ,
author = { Tang, Haotian and Yang, Shang and Liu, Zhijian and Hong, Ke and Yu, Zhongming and Li, Xiuyu and Dai, Guohao and Wang, Yu and Han, Song } ,
booktitle = { IEEE/ACM International Symposium on Microarchitecture (MICRO) } ,
year = { 2023 }
}يتم تقديم النسخة الأولية من Torchsparse ++ (Torchsparse v2.1) في ورش عمل CVPR 2023:
@inproceedings { tangandyang2023torchsparse++ ,
title = { {TorchSparse++: Efficient Point Cloud Engine} } ,
author = { Tang, Haotian and Yang, Shang and Liu, Zhijian and Hong, Ke and Yu, Zhongming and Li, Xiuyu and Dai, Guohao and Wang, Yu and Han, Song } ,
booktitle = { Computer Vision and Pattern Recognition Workshops (CVPRW) } ,
year = { 2023 }
}يتم تقديم Torchsparse في MLSYS 2022:
@inproceedings { tang2022torchsparse ,
title = { {TorchSparse: Efficient Point Cloud Inference Engine} } ,
author = { Tang, Haotian and Liu, Zhijian and Li, Xiuyu and Lin, Yujun and Han, Song } ,
booktitle = { Conference on Machine Learning and Systems (MLSys) } ,
year = { 2022 }
}الإصدار الأولي من Torchsparse هو جزء من ورقة SPVNAs في ECCV 2020:
@inproceedings { tang2020searching ,
title = { {Searching Efficient 3D Architectures with Sparse Point-Voxel Convolution} } ,
author = { Tang, Haotian and Liu, Zhijian and Zhao, Shengyu and Lin, Yujun and Lin, Ji and Wang, Hanrui and Han, Song } ,
booktitle = { European Conference on Computer Vision (ECCV) } ,
year = { 2020 }
}يتم قبول ورقة PCENGINE بواسطة MLSYS 2023:
@inproceedings { hong2023pcengine ,
title = { {Exploiting Hardware Utilization and Adaptive Dataflow for Efficient Sparse Convolution in 3D Point Clouds} } ,
author = { Hong, Ke and Yu, Zhongming and Dai, Guohao and Yang, Xinhao and Lian, Yaoxiu and Liu, Zehao and Xu, Ningyi and Wang, Yu } ,
booktitle = { Sixth Conference on Machine Learning and Systems (MLSys) } ,
year = { 2023 }
}نشكر يان يان من Tusimple على مناقشات مفيدة. يرجى أيضًا إلقاء نظرة على مكتبة DGSparse ، والتي تم تصميمها للحساب السريع والفعال على الرسوم البيانية والغيوم النقطية. يرتبط فريق العمل من PCENGINE (MLSYS 2023) ارتباطًا وثيقًا أيضًا بنا.
Torchsparse مستوحى من العديد من المكتبات الموجودة مفتوحة المصدر ، بما في ذلك (على سبيل المثال لا الحصر) Minkowskiengine ، Second و Sparseconvnet.
نشكر أيضًا المنسوبة على توفير طريقة أنيقة لإدارة تكوينات kernel/model.


