torchsparse
v2.0.0

A Torchsparse é uma biblioteca de rede neural de alto desempenho para o processamento da nuvem de pontos.
A computação em nuvem de pontos tornou -se uma carga de trabalho cada vez mais importante para direção autônoma e outros aplicativos. Ao contrário do cálculo 2D denso, a convolução da nuvem de pontos tem padrões escassos e irregulares de computação e, portanto, requer suporte dedicado ao sistema de inferência com kernels especializados de alto desempenho. Embora as bibliotecas de aprendizado profundo de pontos existentes tenham desenvolvido diferentes fluxos de dados para convolução nas nuvens de pontos, elas assumem um único fluxo de dados durante toda a execução de todo o modelo. Neste trabalho, analisamos sistematicamente e melhoramos os fluxos de dados existentes. Nosso sistema resultante, que a tocha, atinge 2,9x , 3,3x , 2,2x e 1,7x mediram a aceleração de ponta a ponta em uma GPU da NVIDIA A100 sobre o MinkowskiEngine de última geração, SpConv 1.2, tochpara (MLSYS) e Spconv V2 em Inference.
[2024/11] Torchsparse ++ agora está suportando MMDETECTION3D e OPENPCDET via plugins! Uma demonstração completa está disponível.
[2023/11] Torchsparse ++ foi adotado por um 2-3-3-45 ++ do Laboratório do Prof. Hao Su (UCSD) para geração de objetos 3D!
[2023/10] Apresentamos Torchsparse ++ na 56th IEEE/ACM International Simpósio sobre Microarquitetura (Micro 2023). Também lançamos totalmente o código -fonte do Torchsparse ++.
[2023/6] Torchsparse ++ foi adotado por um 2-3-45 do Laboratório do Prof. Hao SU (UCSD) para reconstrução de malha 3D!
[2023/6] Torchsparse ++ foi lançado e apresentado nos workshops CVPR 2023 sobre direção autônoma. Atinge a velocidade de inferência de 1,7-2.9x em relação aos sistemas anteriores de última geração.
[2023/1] Argovesse 2 DataSet implementa seu detector de linha de base com tocha.
[2022/8] A Torchsparse é apresentada no MLSYS 2022. O vídeo Talk está disponível aqui.
[2022/6] Torchsparse foi adotado por Sparseneus para reconstrução da superfície neural.
[2022/1] Torchsparse foi aceito no MLSYS 2022, com agrupamento de multiplicação de matriz adaptável e acesso à memória com conhecimento de localidade.
[2021/6] Torchsparse v1.4 foi lançado.
Fornecemos pacotes de Torchsparse v2.1.0 pré-criados (recomendados) com diferentes versões Pytorch e Cuda para simplificar o edifício para o sistema Linux.
Verifique se pelo menos Pytorch 1.9.0 está instalado:
python -c " import torch; print(torch.__version__) "
>>> 1.10.0Se você deseja usar o Torchsparse com GPUs, verifique se Pytorch foi instalado com CUDA:
python -c " import torch; print(torch.version.cuda) "
>>> 11.3Em seguida, a roda de tochas certas pode ser encontrada e instalada executando o script de instalação:
python -c " $( curl -fsSL https://raw.githubusercontent.com/mit-han-lab/torchsparse/master/install.py ) "Se o servidor Pypi não funcionar como esperado, não se preocupe, você ainda poderá baixar manualmente as rodas. As rodas estão listadas neste site. Pode -se utilizar nosso script de instalação para determinar automaticamente o número da versão usado para indexar as rodas. Por exemplo, se você usar o Pytorch 1.11.0, CUDA 11.5, o número da versão acabará para 2.1.0+TORCH111CU115. Em seguida, você pode selecionar a roda adequada de acordo com sua versão Python.
Você também pode instalar nossa biblioteca a partir da fonte via:
python setup.py installno repositório, ou usando
pip install git+https://github.com/mit-han-lab/torchsparse.git
sem a necessidade de clonar o repositório.
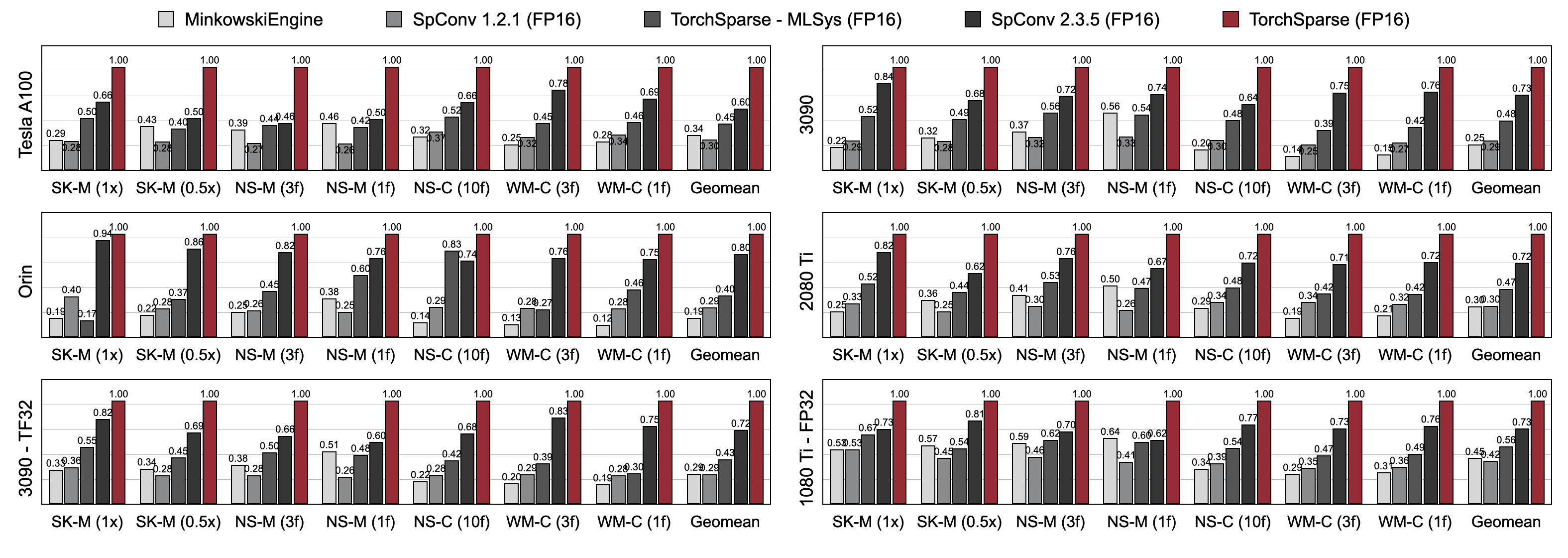
A Torchsparse supera significativamente os mecanismos de inferência de nuvem de pontos existentes nos benchmarks de detecção de objetos 3D e de segmentação de Lidar em três gerações de arquitetura de GPU (Pascal, Turing e Ampere) e todas as precisões (FP16, TF32, FP32). É até 1,7x mais rápido que o SPCONV 2.3.5 de última geração e é de até 2,2x mais rápido que
Torchsparse-mlsys nas GPUs em nuvem. Também melhora a latência do SPCONV 2.3.5 por 1,25 × On Orin.

A Torchsparse atinge a velocidade de treinamento de precisão mista superior em comparação com Minkowskiengine, Torchsparse-MLSYS e SPCONV 2.3.5. Especificamente, é 1,16x mais rápido no Tesla A100, 1,27x mais rápido no RTX 2080 Ti do que o SPCONV de última geração 2.3.5. Também supera significativamente o Minkowskiengine em 4,6-4.8x em sete benchmarks em A100 e 2080 Ti. Medido com tamanho de lote = 2.
Você pode encontrar nossos benchmarks a partir deste link. Para acessar conjuntos de dados pré -processados, entre em contato com os autores. Não podemos liberar publicamente dados brutos de Semantickitti, Nuscena e Waymo devido a requisitos de licença.
Torchsparse é desenvolvido pela seguinte equipe maravilhosa:
Se você usar o Torchsparse, use as seguintes entradas Bibtex para citar:
Torchsparse ++ (Torchsparse v2.1) é apresentado em Micro 2023:
@inproceedings { tangandyang2023torchsparse ,
title = { TorchSparse++: Efficient Training and Inference Framework for Sparse Convolution on GPUs } ,
author = { Tang, Haotian and Yang, Shang and Liu, Zhijian and Hong, Ke and Yu, Zhongming and Li, Xiuyu and Dai, Guohao and Wang, Yu and Han, Song } ,
booktitle = { IEEE/ACM International Symposium on Microarchitecture (MICRO) } ,
year = { 2023 }
}A versão preliminar do Torchsparse ++ (Torchsparse v2.1) é apresentada nos workshops CVPR 2023:
@inproceedings { tangandyang2023torchsparse++ ,
title = { {TorchSparse++: Efficient Point Cloud Engine} } ,
author = { Tang, Haotian and Yang, Shang and Liu, Zhijian and Hong, Ke and Yu, Zhongming and Li, Xiuyu and Dai, Guohao and Wang, Yu and Han, Song } ,
booktitle = { Computer Vision and Pattern Recognition Workshops (CVPRW) } ,
year = { 2023 }
}Torchsparse é apresentado no MLSYS 2022:
@inproceedings { tang2022torchsparse ,
title = { {TorchSparse: Efficient Point Cloud Inference Engine} } ,
author = { Tang, Haotian and Liu, Zhijian and Li, Xiuyu and Lin, Yujun and Han, Song } ,
booktitle = { Conference on Machine Learning and Systems (MLSys) } ,
year = { 2022 }
}A versão inicial do Torchsparse faz parte do artigo SPVNAS no ECCV 2020:
@inproceedings { tang2020searching ,
title = { {Searching Efficient 3D Architectures with Sparse Point-Voxel Convolution} } ,
author = { Tang, Haotian and Liu, Zhijian and Zhao, Shengyu and Lin, Yujun and Lin, Ji and Wang, Hanrui and Han, Song } ,
booktitle = { European Conference on Computer Vision (ECCV) } ,
year = { 2020 }
}O artigo do PCEngine é aceito pelo MLSYS 2023:
@inproceedings { hong2023pcengine ,
title = { {Exploiting Hardware Utilization and Adaptive Dataflow for Efficient Sparse Convolution in 3D Point Clouds} } ,
author = { Hong, Ke and Yu, Zhongming and Dai, Guohao and Yang, Xinhao and Lian, Yaoxiu and Liu, Zehao and Xu, Ningyi and Wang, Yu } ,
booktitle = { Sixth Conference on Machine Learning and Systems (MLSys) } ,
year = { 2023 }
}Agradecemos a Yan Yan de Tusimple pelas discussões úteis. Por favor, dê uma olhada na biblioteca DGSPARSE, projetada para computação esparsa rápida e eficiente em gráficos e nuvens de pontos. O trabalho da equipe PCEngine (MLSYS 2023) também está altamente relacionado a nós.
A Torchsparse é inspirada em muitas bibliotecas de código aberto existentes, incluindo (mas não se limitando a) Minkowskiengine, Second e SparSeConvnet.
Agradecemos também ao Attributedict por fornecer uma maneira elegante de gerenciar as configurações de kernel/modelo.


