torchsparse
v2.0.0

Torchsparse est une bibliothèque de réseaux neuronaux haute performance pour le traitement des nuages de points.
Le calcul du cloud de points est devenu une charge de travail de plus en plus importante pour la conduite autonome et d'autres applications. Contrairement au calcul 2D dense, la convolution des nuages de points a des modèles de calcul clairsemés et irréguliers et nécessite donc un support de système d'inférence dédié avec des noyaux haute performance spécialisés. Bien que les bibliothèques de profondeur de ponctuel existantes aient développé différents flux de données pour la convolution sur les nuages ponctuels, ils supposent un seul flux de données tout au long de l'exécution de l'ensemble du modèle. Dans ce travail, nous analysons et améliorons systématiquement les flux de données existants. Notre système résultant, Torchsparse, atteint respectivement 2,9x , 3,3x , 2,2x et 1,7x de bout en bout sur un GPU NVIDIA A100 sur le Minkowskienne, SPCONV 1.2, Torchsparse (MLSYS) et SPCONV) et SPCONV V2.
[2024/11] Torchsparse ++ prend désormais en charge MMDection3d et OpenPCDET via des plugins! Une démo complète est disponible.
[2023/11] Torchsparse ++ a été adopté par One-2-3-45 ++ du laboratoire du Prof. Hao Su (UCSD) pour la génération d'objets 3D!
[2023/10] Nous présentons Torchsparse ++ au 56th IEEE / ACM International Symposium on Microarchitecture (Micro 2023). Nous libérons également entièrement le code source de Torchsparse ++.
[2023/6] Torchsparse ++ a été adopté par One-2-3-45 du laboratoire du Prof. Hao Su (UCSD) pour la reconstruction du maillage 3D!
[2023/6] Torchsparse ++ a été publié et présenté lors d'ateliers CVPR 2023 sur la conduite autonome. Il atteint une accélération d'inférence de 1,7 à 2,9x sur les systèmes de pointe précédents.
[2023/1] L'ensemble de données de DROVOVORSE 2 implémente leur détecteur de base avec Torchsparse.
[2022/8] Torchsparse est présenté au MLSYS 2022. La vidéo Talk est disponible ici.
[2022/6] Torchsparse a été adopté par Sparseneus pour la reconstruction de surface neuronale.
[2022/1] Torchsparse a été accepté dans MLSYS 2022, avec un regroupement de multiplication de matrice adaptative et un accès à la mémoire conscient de la localité.
[2021/6] Torchsparse v1.4 a été publié.
Nous fournissons des packages Torchsparse V2.1.0 prédéfinis (recommandés) avec différentes versions Pytorch et CUDA pour simplifier le bâtiment pour le système Linux.
Assurez-vous qu'au moins Pytorch 1.9.0 est installé:
python -c " import torch; print(torch.__version__) "
>>> 1.10.0Si vous souhaitez utiliser Torchsparse avec des GPU, veuillez vous assurer que Pytorch a été installé avec CUDA:
python -c " import torch; print(torch.version.cuda) "
>>> 11.3Ensuite, la roue Torchspathse droite peut être trouvée et installée en exécutant le script d'installation:
python -c " $( curl -fsSL https://raw.githubusercontent.com/mit-han-lab/torchsparse/master/install.py ) "Si le serveur PYPI ne fonctionne pas comme prévu, pas de soucis, vous pouvez toujours télécharger manuellement les roues. Les roues sont répertoriées sur ce site Web. On peut utiliser notre script d'installation pour déterminer automatiquement le numéro de version utilisé pour indexer les roues. Par exemple, si vous utilisez Pytorch 1.11.0, CUDA 11.5, le numéro de version finira par 2,1.0 + TORCH111CU115. Vous pouvez ensuite sélectionner la roue appropriée en fonction de votre version Python.
Vous pouvez également installer alternativement notre bibliothèque à partir de la source via:
python setup.py installdans le référentiel, ou en utilisant
pip install git+https://github.com/mit-han-lab/torchsparse.git
sans avoir besoin de cloner le référentiel.
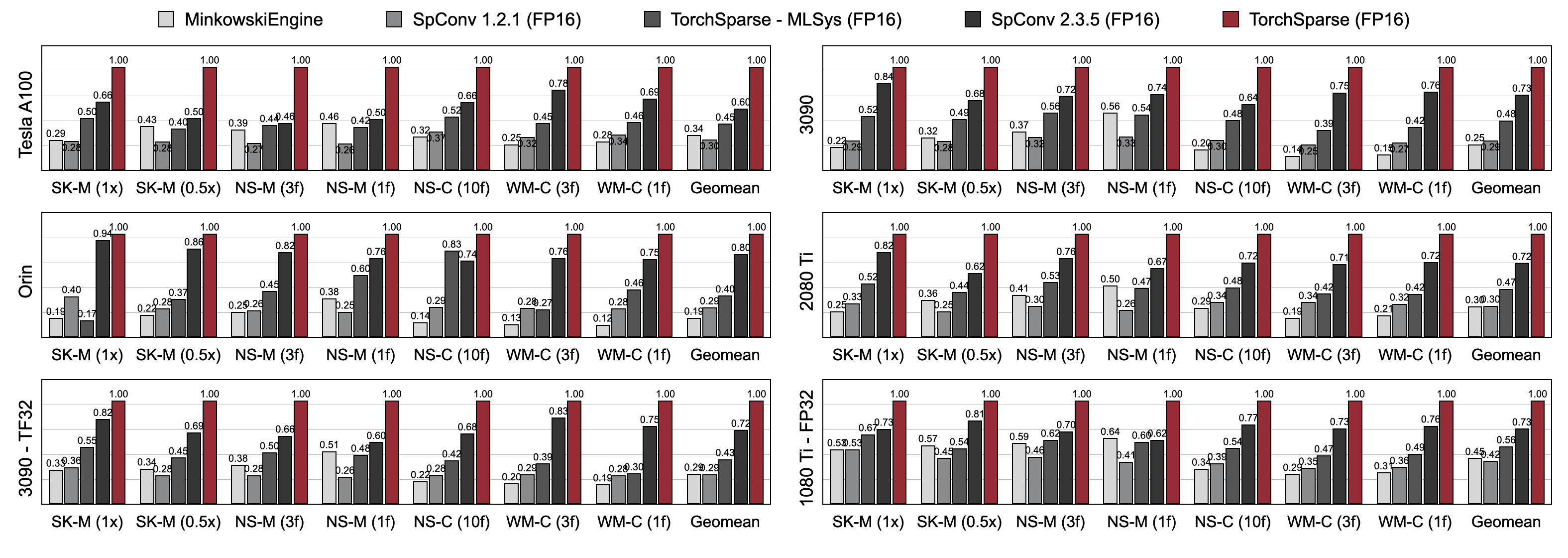
Torchsparse surpasse considérablement les moteurs existants d'inférence de nuages de points dans la détection d'objets 3D et les repères de segmentation lidar sur trois générations d'architecture GPU (Pascal, Turing et Ampère) et toutes les précisions (FP16, TF32, FP32). Il est jusqu'à 1,7x plus rapide que SPCONV 2.3.5 à la pointe de la technologie et est jusqu'à 2,2x plus rapide que
TORCHSPARSE-MLSYS sur les GPU cloud. Il améliore également la latence de SPCONV 2.3.5 par 1,25 × sur Orin.

Torchsparse atteint une vitesse de formation de précision mixte supérieure par rapport à Minkowskienne, Torchsparse-MLSYS et SPCONV 2.3.5. Plus précisément, il est plus rapide de 1,16x sur Tesla A100, 1,27x plus rapidement sur RTX 2080 Ti que SPCONV 2.3.5. Il surpasse également de manière significative Minkowskienne de 4,6-4,8x sur sept repères sur A100 et 2080 Ti. Mesuré avec une taille de lot = 2.
Vous pouvez trouver nos repères à partir de ce lien. Pour accéder aux ensembles de données prétraités, veuillez contacter les auteurs. Nous ne pouvons pas publier publiquement les données brutes de Semantictickitti, Nuscenes et Waymo en raison des exigences de licence.
Torchsparse est développé par la merveilleuse équipe suivante:
Si vous utilisez Torchsparse, veuillez utiliser les entrées Bibtex suivantes pour citer:
Torchsparse ++ (Torchsparse v2.1) est présenté au micro 2023:
@inproceedings { tangandyang2023torchsparse ,
title = { TorchSparse++: Efficient Training and Inference Framework for Sparse Convolution on GPUs } ,
author = { Tang, Haotian and Yang, Shang and Liu, Zhijian and Hong, Ke and Yu, Zhongming and Li, Xiuyu and Dai, Guohao and Wang, Yu and Han, Song } ,
booktitle = { IEEE/ACM International Symposium on Microarchitecture (MICRO) } ,
year = { 2023 }
}La version préliminaire de Torchsparse ++ (Torchsparse v2.1) est présentée aux ateliers CVPR 2023:
@inproceedings { tangandyang2023torchsparse++ ,
title = { {TorchSparse++: Efficient Point Cloud Engine} } ,
author = { Tang, Haotian and Yang, Shang and Liu, Zhijian and Hong, Ke and Yu, Zhongming and Li, Xiuyu and Dai, Guohao and Wang, Yu and Han, Song } ,
booktitle = { Computer Vision and Pattern Recognition Workshops (CVPRW) } ,
year = { 2023 }
}Torchsparse est présenté à MLSYS 2022:
@inproceedings { tang2022torchsparse ,
title = { {TorchSparse: Efficient Point Cloud Inference Engine} } ,
author = { Tang, Haotian and Liu, Zhijian and Li, Xiuyu and Lin, Yujun and Han, Song } ,
booktitle = { Conference on Machine Learning and Systems (MLSys) } ,
year = { 2022 }
}La version initiale de Torchsparse fait partie du papier SPVNA à ECCV 2020:
@inproceedings { tang2020searching ,
title = { {Searching Efficient 3D Architectures with Sparse Point-Voxel Convolution} } ,
author = { Tang, Haotian and Liu, Zhijian and Zhao, Shengyu and Lin, Yujun and Lin, Ji and Wang, Hanrui and Han, Song } ,
booktitle = { European Conference on Computer Vision (ECCV) } ,
year = { 2020 }
}Le papier pcengine est accepté par MLSYS 2023:
@inproceedings { hong2023pcengine ,
title = { {Exploiting Hardware Utilization and Adaptive Dataflow for Efficient Sparse Convolution in 3D Point Clouds} } ,
author = { Hong, Ke and Yu, Zhongming and Dai, Guohao and Yang, Xinhao and Lian, Yaoxiu and Liu, Zehao and Xu, Ningyi and Wang, Yu } ,
booktitle = { Sixth Conference on Machine Learning and Systems (MLSys) } ,
year = { 2023 }
}Nous remercions Yan Yan de Tusimple pour les discussions utiles. Veuillez également consulter la bibliothèque DGSParse, qui est conçue pour un calcul rapide et efficace clairsemé sur les graphiques et les nuages de points. Le travail de l'équipe PCEngine (MLSYS 2023) est également très lié à nous.
Torchsparse est inspiré par de nombreuses bibliothèques open source existantes, y compris (mais sans s'y limiter) Minkowskienne, deuxième et SparsEconvnet.
Nous remercions également Attributedict d'avoir fourni un moyen élégant de gérer les configurations du noyau / modèle.


