torchsparse
v2.0.0

Torchsparse ist eine leistungsstarke Bibliothek für neuronale Netzwerke für die Point Cloud-Verarbeitung.
Die Punkt -Cloud -Berechnung ist zu einer immer wichtigeren Arbeitsbelastung für autonomes Fahren und andere Anwendungen geworden. Im Gegensatz zur dichten 2D-Berechnung weist Point Cloud-Faltung spärliche und unregelmäßige Berechnungsmuster auf und erfordert somit eine dedizierte Inferenzsystemunterstützung mit speziellen Hochleistungskerneln. Während bestehende Point Cloud Deep -Learning -Bibliotheken unterschiedliche Datenflows für Faltung in Punktwolken entwickelt haben, nehmen sie während der gesamten Ausführung des gesamten Modells einen einzelnen Datenfluss aus. In dieser Arbeit analysieren und verbessern wir systematisch vorhandene Datenflüsse. Unser resultierendes System, Torchsparse, erreicht 2,9x , 3,3x , 2,2x und 1,7X die End-to-End-Beschleunigung an einer NVIDIA A100 GPU über den hochmodernen Minkowskiengine, SPCONV 1.2, Torchsparse (MLSYS) und SPCONV V2 in Inferenz.
[2024/11] Torchsparse ++ unterstützt jetzt mmDection3D und OpenPCDET über Plugins! Eine vollständige Demo ist verfügbar.
[2023/11] Torchsparse ++ wurde von One-2-3-45 ++ aus dem Labor von Prof. Hao Su für 3D-Objektgenerierung übernommen!
[2023/10] Wir präsentieren Torchsparse ++ auf dem 56. IEEE/ACM Internationales Symposium für Mikroarchitektur (MICRO 2023). Wir geben auch den Quellcode von Torchsparse ++ vollständig frei.
[2023/6] Torchsparse ++ wurde von One-2-3-45 aus dem Labor von Prof. Hao SU (UCSD) zur 3D-Netzrekonstruktion übernommen!
[2023/6] Torchsparse ++ wurde in den Workshops CVPR 2023 zum autonomen Fahren veröffentlicht und präsentiert. Es erreicht 1,7-2.9x Inferenz beschleunigt über frühere hochmoderne Systeme.
[2023/1] Argoverse 2 Dataset implementiert ihren Baseline -Detektor mit Torchsparse.
[2022/8] Torchsparse wird bei MLSYS 2022 präsentiert. Das Talk -Video ist hier verfügbar.
[2022/6] Torchsparse wurde von Sparseneus für die Rekonstruktion der neuralen Oberfläche übernommen.
[2022/1] Torchsparse wurde in MLSYS 2022 mit adaptiver Matrix-Multiplikationsgruppierung und örtlichem Speicherzugriff aufgenommen.
[2021/6] Torchsparse V1.4 wurde veröffentlicht.
Wir bieten vorgefertigte Torchsparse V2.1.0 Pakete (empfohlen) mit verschiedenen Pytorch- und CUDA-Versionen, um das Gebäude für das Linux-System zu vereinfachen.
Stellen Sie sicher, dass mindestens Pytorch 1.9.0 installiert ist:
python -c " import torch; print(torch.__version__) "
>>> 1.10.0Wenn Sie Torchsparse mit GPUs verwenden möchten, stellen Sie sicher, dass Pytorch mit CUDA installiert wurde:
python -c " import torch; print(torch.version.cuda) "
>>> 11.3Dann kann das rechte Torchsparse -Rad gefunden und installiert werden, indem das Installationsskript ausgeführt wird:
python -c " $( curl -fsSL https://raw.githubusercontent.com/mit-han-lab/torchsparse/master/install.py ) "Wenn PYPI Server nicht wie erwartet funktioniert, können Sie die Räder immer noch manuell herunterladen. Die Räder sind auf dieser Website aufgeführt. Man kann unser Installationsskript verwenden, um die Versionsnummer automatisch zu bestimmen, die zum Index der Räder verwendet wird. Wenn Sie beispielsweise Pytorch 1.11.0, CUDA 11.5 verwenden, liegt die Versionsnummer von 2.1.0+Torch111cu115. Sie können dann das richtige Rad gemäß Ihrer Python -Version auswählen.
Sie können unsere Bibliothek auch alternativ von der Quelle aus der Quelle installieren.
python setup.py installim Repository oder verwendet
pip install git+https://github.com/mit-han-lab/torchsparse.git
ohne die Notwendigkeit, das Repository zu klonen.
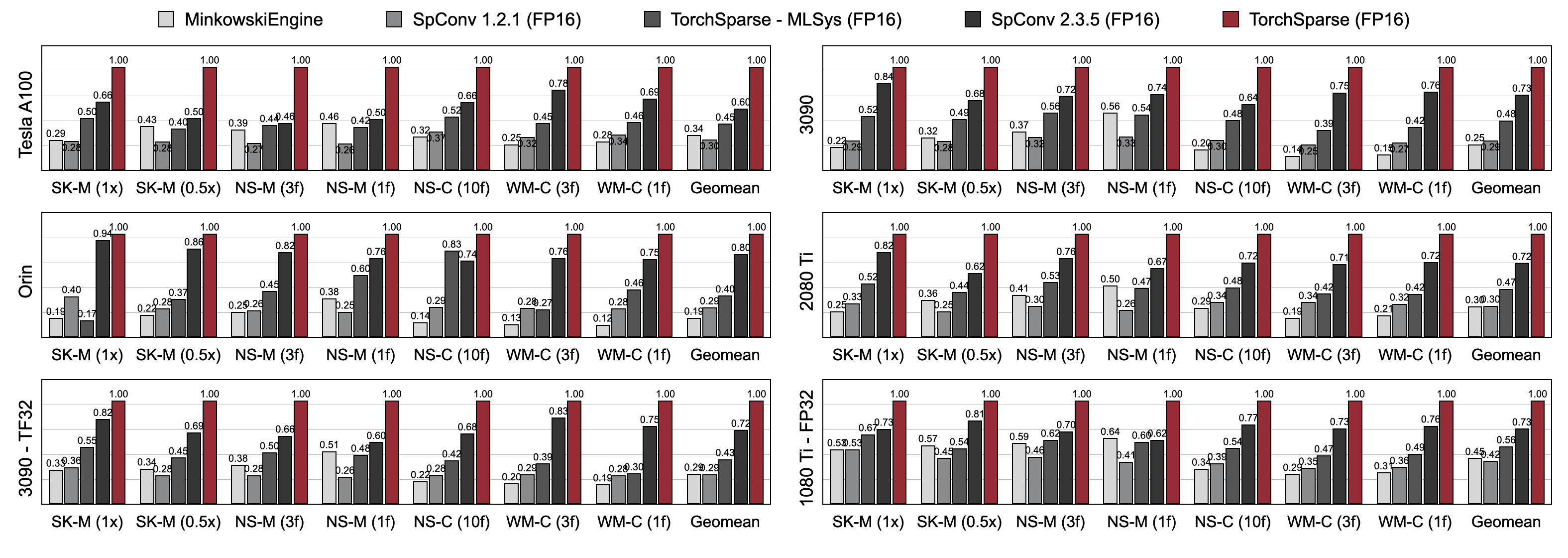
Torchsparse übertrifft die bestehenden Point -Cloud -Inferenzmotoren sowohl in 3D -Objekterkennung als auch in den LIDAR -Segmentierungsbenchmarks über drei Generationen der GPU -Architektur (Pascal, Turing und Ampere) und alle Präzisionen (FP16, TF32, FP32) erheblich. Es ist bis zu 1,7x schneller als auf dem neuesten Stand der Technik und bis zu 2,2-fach schneller als bis zu 2,2x
Torchsparse-MLSYS am Cloud-GPUs. Es verbessert auch die Latenz von SPCONV 2.3.5 um 1,25 × auf Orin.

Torchsparse erreicht eine überlegene Trainingsgeschwindigkeit im Vergleich zu Minkowskiengine, Torchsparse-MLSYS und SPCONV 2.3.5. Insbesondere ist es bei Tesla A100, 1,27x schneller auf RTX 2080 TI, 1,16x schneller als auf dem neuesten Stand der Technik. Es übertrifft auch minkowskiengine erheblich um 4,6-4,8x über sieben Benchmarks auf A100 und 2080 Ti. Gemessen mit Chargengröße = 2.
Möglicherweise finden Sie unsere Benchmarks von diesem Link. Um auf vorverarbeitete Datensätze zuzugreifen, wenden Sie sich bitte an die Autoren. Aufgrund der Lizenzanforderungen können wir keine Rohdaten von Semantickitti, Nuscenen und Waymo freigeben.
Torchsparse wird vom folgenden wunderbaren Team entwickelt:
Wenn Sie Torchsparse verwenden, verwenden Sie bitte die folgenden Bibtex -Einträge, um zu zitieren:
Torchsparse ++ (Torchsparse v2.1) wird bei Micro 2023 dargestellt:
@inproceedings { tangandyang2023torchsparse ,
title = { TorchSparse++: Efficient Training and Inference Framework for Sparse Convolution on GPUs } ,
author = { Tang, Haotian and Yang, Shang and Liu, Zhijian and Hong, Ke and Yu, Zhongming and Li, Xiuyu and Dai, Guohao and Wang, Yu and Han, Song } ,
booktitle = { IEEE/ACM International Symposium on Microarchitecture (MICRO) } ,
year = { 2023 }
}Vorläufige Version von Torchsparse ++ (Torchsparse v2.1) wird in CVPR -Workshops 2023 dargestellt:
@inproceedings { tangandyang2023torchsparse++ ,
title = { {TorchSparse++: Efficient Point Cloud Engine} } ,
author = { Tang, Haotian and Yang, Shang and Liu, Zhijian and Hong, Ke and Yu, Zhongming and Li, Xiuyu and Dai, Guohao and Wang, Yu and Han, Song } ,
booktitle = { Computer Vision and Pattern Recognition Workshops (CVPRW) } ,
year = { 2023 }
}Torchsparse wird bei MLSYS 2022 präsentiert:
@inproceedings { tang2022torchsparse ,
title = { {TorchSparse: Efficient Point Cloud Inference Engine} } ,
author = { Tang, Haotian and Liu, Zhijian and Li, Xiuyu and Lin, Yujun and Han, Song } ,
booktitle = { Conference on Machine Learning and Systems (MLSys) } ,
year = { 2022 }
}Die erste Version von Torchsparse ist Teil des SPVNAS -Papiers bei ECCV 2020:
@inproceedings { tang2020searching ,
title = { {Searching Efficient 3D Architectures with Sparse Point-Voxel Convolution} } ,
author = { Tang, Haotian and Liu, Zhijian and Zhao, Shengyu and Lin, Yujun and Lin, Ji and Wang, Hanrui and Han, Song } ,
booktitle = { European Conference on Computer Vision (ECCV) } ,
year = { 2020 }
}Das PCEngine -Papier wird von MLSYS 2023 akzeptiert:
@inproceedings { hong2023pcengine ,
title = { {Exploiting Hardware Utilization and Adaptive Dataflow for Efficient Sparse Convolution in 3D Point Clouds} } ,
author = { Hong, Ke and Yu, Zhongming and Dai, Guohao and Yang, Xinhao and Lian, Yaoxiu and Liu, Zehao and Xu, Ningyi and Wang, Yu } ,
booktitle = { Sixth Conference on Machine Learning and Systems (MLSys) } ,
year = { 2023 }
}Wir danken Yan Yan von Tusimple für hilfreiche Diskussionen. Bitte schauen Sie sich auch die DGSparse -Bibliothek an, die für schnelle und effiziente spärliche Berechnung in Diagramme und Punktwolken ausgelegt ist. Die Arbeiten des PCEngine -Teams (MLSYS 2023) sind ebenfalls in hohem Maße mit uns verwandt.
Torchsparse ist von vielen vorhandenen Open-Source-Bibliotheken inspiriert, darunter (aber nicht beschränkt auf) Minkowskiengine, Second und SparseConvnet.
Wir danken auch zugeschrieben, dass sie eine elegante Möglichkeit zur Verwaltung der Kernel/Modellkonfigurationen zur Verfügung gestellt haben.


