PTMGPT2
v0.0.1: Update README.md
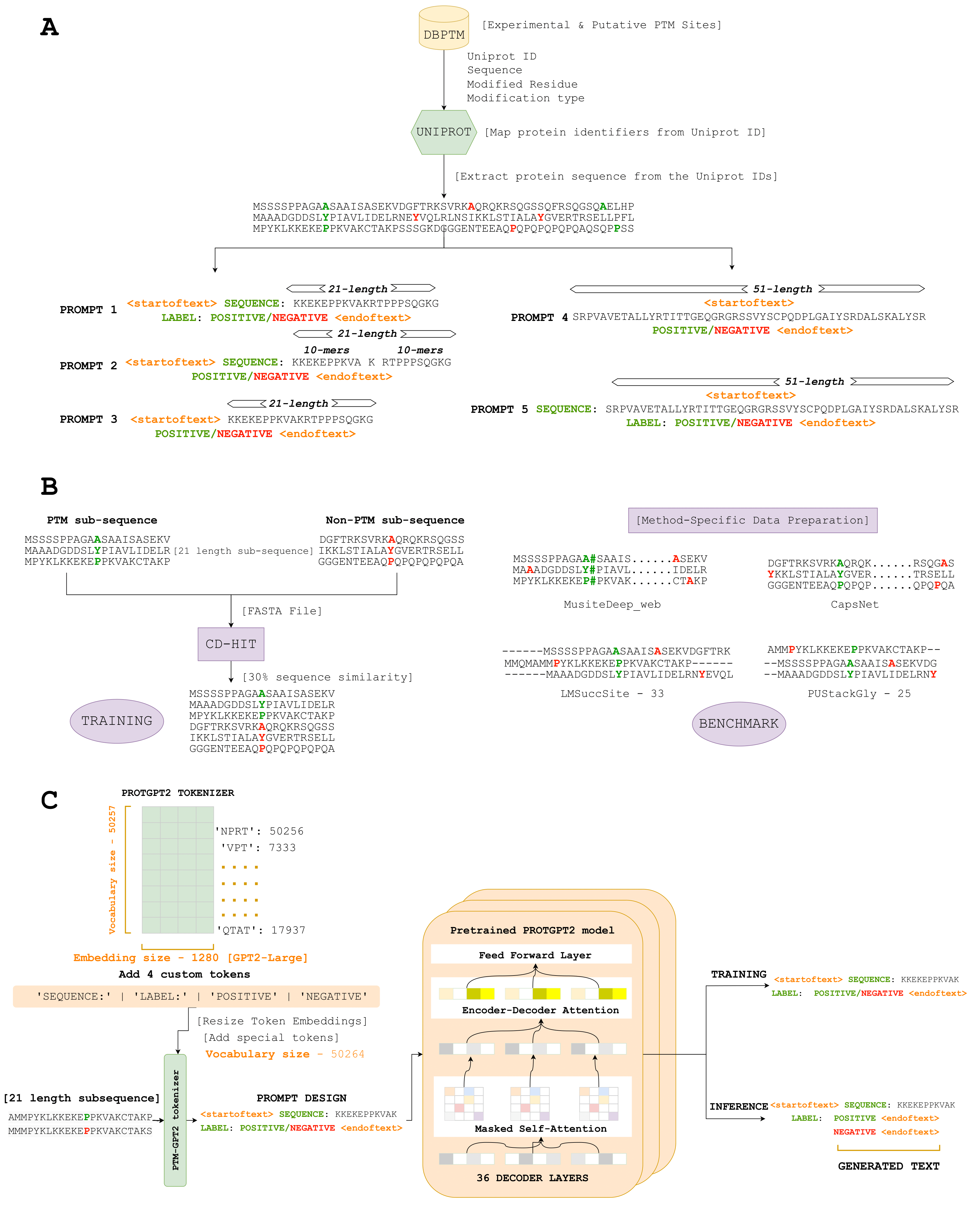
ที่นี่เราแนะนำ PTMGPT2 ซึ่งเป็นชุดของรุ่นที่สามารถสร้างโทเค็นที่มีความหมายว่าลำดับโปรตีนที่ปรับเปลี่ยนซึ่งมีความสำคัญสำหรับการระบุไซต์ PTM ที่สำคัญของแพลตฟอร์มนี้คือ Protgpt2 ซึ่งเป็นโมเดลหม้อแปลงอัตโนมัติ เราได้ดัดแปลง ProtGPT2 โดยใช้เป็นแบบจำลองที่ผ่านการฝึกอบรมมาก่อนและปรับแต่งเพิ่มเติมสำหรับงาน SPE Cific ในการสร้างฉลากการจำแนกประเภทสำหรับประเภท PTM ที่กำหนด ไม่ซ้ำกัน PTMGPT2 ใช้สถาปัตยกรรมแบบถอดรหัสอย่างเดียวซึ่งไม่จำเป็นต้องใช้หัว clas-sification เฉพาะงานในระหว่างการฝึกอบรม แทนเลเยอร์สุดท้ายของตัวถอดรหัสทำหน้าที่เป็นภาพฉายกลับไปยังพื้นที่คำศัพท์ซึ่งสร้างโทเค็นที่เป็นไปได้ต่อไปได้อย่างมีประสิทธิภาพตามรูปแบบที่เรียนรู้ระหว่างโทเค็นในพรอมต์อินพุต
ลิงค์ - (https://nsclbio.jbnu.ac.kr/gpt_model/)
ติดต่อเราโดยตรงที่ [email protected] สำหรับการคาดการณ์จำนวนมากและแบบจำลองที่ผ่านการฝึกอบรม
ลิงค์ - (https://nsclbio.jbnu.ac.kr/tools/ptmgpt2/)
ลิงค์ - (https://doi.org/10.5281/zenodo.11371883)
ลิงค์ - (https://zenodo.org/records/11362322)
ลิงค์ - (https://doi.org/10.5281/zenodo.11377398)
Python 3.11.3
Transformers 4.29.2
Scikit-learn 1.2.2
Pytorch 2.0.1
Pytorch-Cuda 11.7
•โมเดล: โฟลเดอร์นี้เป็นโฮสต์ตัวอย่างตัวอย่างที่ออกแบบมาเพื่อทำนายไซต์ PTM จากลำดับโปรตีนที่กำหนดโดยแสดงแอปพลิเคชันของ PTMGPT2
• Tokenizer: โฟลเดอร์นี้มีตัวอย่าง tokenizer ที่รับผิดชอบลำดับโปรตีน tokenizing รวมถึงโทเค็นที่ทำด้วยมือสำหรับกรดอะมิโนหรือลวดลายเฉพาะ
• inference.ipynb: ไฟล์นี้มีรหัสที่เรียกใช้งานได้สำหรับการใช้โมเดล PTMGPT2 และ Tokenizer เพื่อทำนายไซต์ PTM ซึ่งทำหน้าที่เป็นคู่มือปฏิบัติสำหรับผู้ใช้ในการใช้โมเดลกับชุดข้อมูลของพวกเขา


