word2word
1.0.0
การแปลคำที่ใช้งานง่ายสำหรับ 3,564 คู่ภาษา
นี่คือรหัสอย่างเป็นทางการที่มาพร้อมกับกระดาษ LREC 2020 ของเรา
ก่อนอื่นติดตั้งแพ็คเกจโดยใช้ pip :
pip install word2wordหรือ
git clone https://github.com/kakaobrain/word2word
python setup.py installจากนั้นใน Python ให้ดาวน์โหลดโมเดลและดึงคำแปลท็อป 5 คำของคำใด ๆ ที่กำหนดไปยังภาษาที่ต้องการ:
from word2word import Word2word
en2fr = Word2word ( "en" , "fr" )
print ( en2fr ( "apple" ))
# out: ['pomme', 'pommes', 'pommier', 'tartes', 'fleurs'] 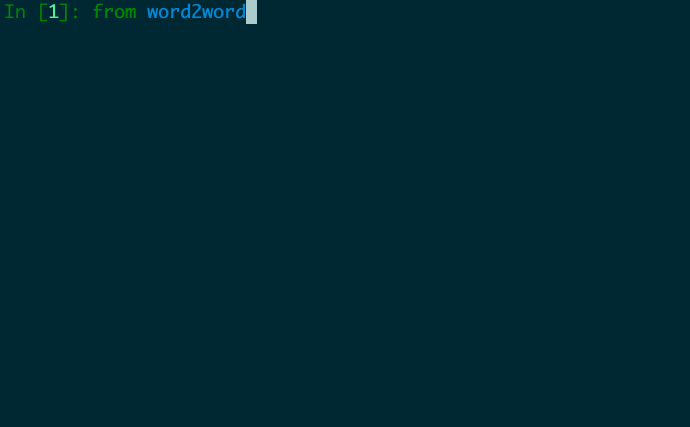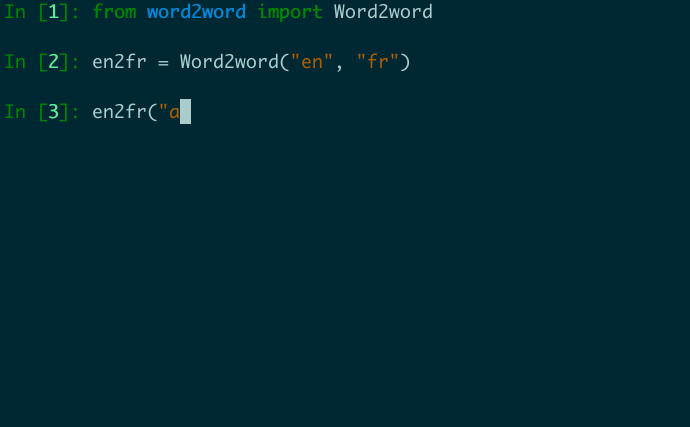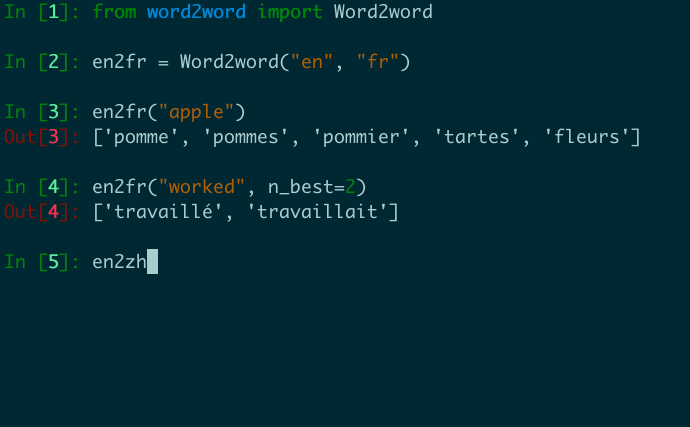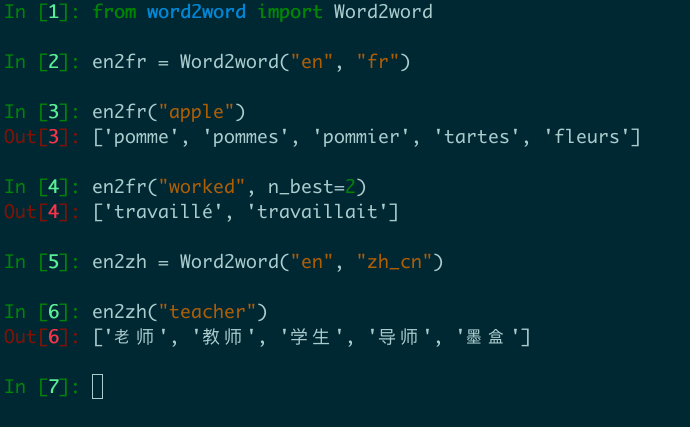
เราให้บริการการแปลแบบคำเป็นคำสูงสุดในทุกคู่ที่มีอยู่ทั้งหมดจาก OpenSubtitles2018 จำนวนนี้มีจำนวน 3,564 คู่ในภาษาที่ไม่ซ้ำกัน 62 ภาษา
รายการทั้งหมดมีให้ที่นี่
วิธีการของเราคำนวณการแปลคำสูงสุด K ตามสถิติการเกิดร่วมระหว่างคู่คำข้ามภาษาในคลังข้อมูลคู่ขนาน นอกจากนี้เรายังแนะนำคำแก้ไขที่ควบคุมผลกระทบใด ๆ ที่มาจากคำแหล่งอื่น ๆ ภายในประโยคเดียวกัน วิธีการที่ได้เป็นวิธีที่มีประสิทธิภาพและปรับขนาดได้ซึ่งช่วยให้เราสามารถสร้างพจนานุกรมสองภาษาขนาดใหญ่จากคลังข้อมูลคู่ขนานใด ๆ
สำหรับรายละเอียดเพิ่มเติมดูส่วนวิธีการของบทความของเรา
แพ็คเกจ word2word ยังมีอินเทอร์เฟซสำหรับการสร้างพจนานุกรมสองภาษาแบบกำหนดเองโดยใช้คลังข้อมูลขนานที่แตกต่างกัน ที่นี่เราแสดงตัวอย่างของการสร้างหนึ่งจากชุดข้อมูล Medline English-French:
from word2word import Word2word
# custom parallel data: data/pubmed.en-fr.en, data/pubmed.en-fr.fr
my_en2fr = Word2word . make ( "en" , "fr" , "data/pubmed.en-fr" )
# ...building...
print ( my_en2fr ( "mitochondrial" ))
# out: ['mitochondriale', 'mitochondriales', 'mitochondrial',
# 'cytopathies', 'mitochondriaux']เมื่อสร้างขึ้นจากแหล่งที่มาพจนานุกรมสองภาษาสามารถสร้างได้จากบรรทัดคำสั่งดังนี้:
python make.py --lang1 en --lang2 fr --datapref data/pubmed.en-fr ในทั้งสองกรณีคำศัพท์ที่กำหนดเอง (บันทึกลงใน datapref/ โดยค่าเริ่มต้น) สามารถโหลดได้อีกครั้งใน Python:
from word2word import Word2word
my_en2fr = Word2word . load ( "en" , "fr" , "data/pubmed.en-fr" )
# Loaded word2word custom bilingual lexicon from data/pubmed.en-fr/en-fr.pkl ในทั้งอินเทอร์เฟซ Python และอินเตอร์เฟสบรรทัดคำสั่ง make ใช้การใช้มัลติโปรเซสเซอร์ด้วย 16 CPU โดยค่าเริ่มต้น จำนวนคนงาน CPU สามารถปรับได้โดยการตั้งค่า num_workers=N (python) หรือ --num_workers N (บรรทัดคำสั่ง)
หากคุณใช้ Word2word สำหรับการวิจัยโปรดอ้างอิงบทความของเรา:
@inproceedings { choe2020word2word ,
author = { Yo Joong Choe and Kyubyong Park and Dongwoo Kim } ,
title = { word2word: A Collection of Bilingual Lexicons for 3,564 Language Pairs } ,
booktitle = { Proceedings of the 12th International Conference on Language Resources and Evaluation (LREC 2020) } ,
year = { 2020 }
}คำศัพท์สองภาษาที่คำนวณล่วงหน้าทั้งหมดของเราถูกสร้างขึ้นจากชุดข้อมูล OpenSubtitles2018 ที่เปิดเผยต่อสาธารณะ:
@inproceedings { lison-etal-2018-opensubtitles2018 ,
title = " {O}pen{S}ubtitles2018: Statistical Rescoring of Sentence Alignments in Large, Noisy Parallel Corpora " ,
author = { Lison, Pierre and
Tiedemann, J{"o}rg and
Kouylekov, Milen } ,
booktitle = " Proceedings of the Eleventh International Conference on Language Resources and Evaluation ({LREC} 2018) " ,
month = may,
year = " 2018 " ,
address = " Miyazaki, Japan " ,
publisher = " European Language Resources Association (ELRA) " ,
url = " https://www.aclweb.org/anthology/L18-1275 " ,
}Kyubyong Park, Dongwoo Kim และ YJ Choe


