word2word
1.0.0
Traducciones de palabras fáciles de usar para 3,564 pares de idiomas.
Este es el código oficial que acompaña a nuestro artículo LREC 2020.
Primero, instale el paquete con pip :
pip install word2wordO
git clone https://github.com/kakaobrain/word2word
python setup.py installLuego, en Python, descargue el modelo y recupere las traducciones de 5 palabras de Top 5 de cualquier palabra dada al idioma deseado:
from word2word import Word2word
en2fr = Word2word ( "en" , "fr" )
print ( en2fr ( "apple" ))
# out: ['pomme', 'pommes', 'pommier', 'tartes', 'fleurs'] 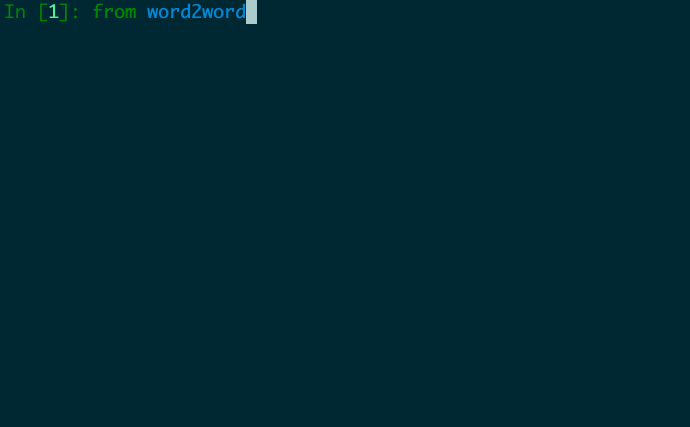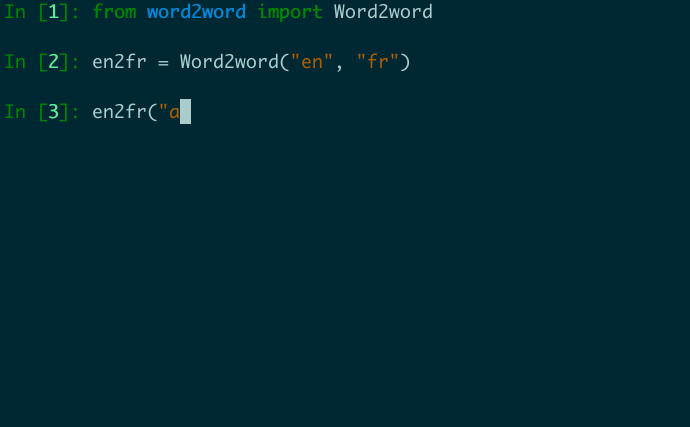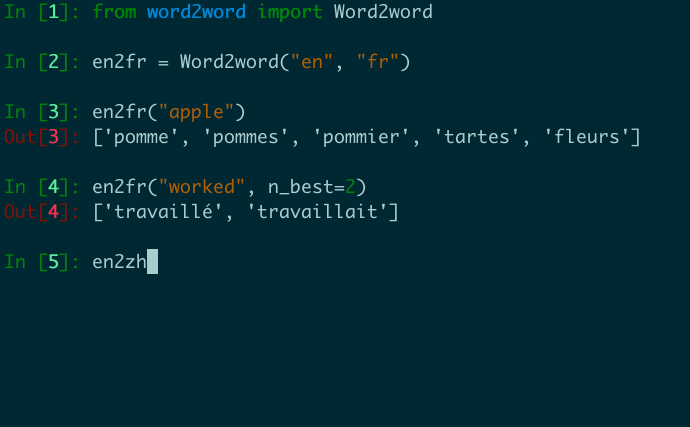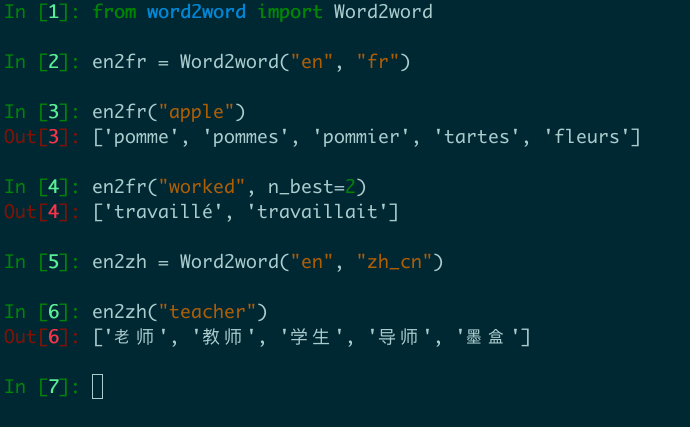
Proporcionamos traducciones de palabra a palabra de Top-K en todos los pares disponibles de OpenSubtitles2018. Esto equivale a un total de 3,564 pares de idiomas en 62 idiomas únicos.
La lista completa se proporciona aquí.
Nuestro enfoque calcula las traducciones de palabras de Top-K basadas en las estadísticas de concurrencia entre pares de palabras interlingües en un corpus paralelo. Además, presentamos un término de corrección que controla para cualquier efecto de confusión proveniente de otras palabras fuente dentro de la misma oración. El método resultante es un enfoque eficiente y escalable que nos permite construir grandes diccionarios bilingües a partir de cualquier corpus paralelo dado.
Para obtener más detalles, consulte la sección de metodología de nuestro artículo.
El paquete word2word también proporciona interfaz para construir un léxico bilingüe personalizado que utiliza un corpus paralelo diferente. Aquí, mostramos un ejemplo de construcción de uno del conjunto de datos Medline English-French:
from word2word import Word2word
# custom parallel data: data/pubmed.en-fr.en, data/pubmed.en-fr.fr
my_en2fr = Word2word . make ( "en" , "fr" , "data/pubmed.en-fr" )
# ...building...
print ( my_en2fr ( "mitochondrial" ))
# out: ['mitochondriale', 'mitochondriales', 'mitochondrial',
# 'cytopathies', 'mitochondriaux']Cuando se construye desde la fuente, el léxico bilingüe también se puede construir desde la línea de comando de la siguiente manera:
python make.py --lang1 en --lang2 fr --datapref data/pubmed.en-fr En ambos casos, el léxico personalizado (guardado en datapref/ por defecto) se puede volver a cargar en Python:
from word2word import Word2word
my_en2fr = Word2word . load ( "en" , "fr" , "data/pubmed.en-fr" )
# Loaded word2word custom bilingual lexicon from data/pubmed.en-fr/en-fr.pkl Tanto en la interfaz de Python como en la interfaz de línea de comando, make utilizar multiprocesamiento con 16 CPU por defecto. El número de trabajadores de la CPU se puede ajustar configurando num_workers=N (python) o --num_workers N (línea de comandos).
Si usa Word2word para investigación, cite nuestro documento:
@inproceedings { choe2020word2word ,
author = { Yo Joong Choe and Kyubyong Park and Dongwoo Kim } ,
title = { word2word: A Collection of Bilingual Lexicons for 3,564 Language Pairs } ,
booktitle = { Proceedings of the 12th International Conference on Language Resources and Evaluation (LREC 2020) } ,
year = { 2020 }
}Todos nuestros léxicos bilingües precomputados se construyeron a partir del conjunto de datos OpenSubtitles2018 disponible públicamente:
@inproceedings { lison-etal-2018-opensubtitles2018 ,
title = " {O}pen{S}ubtitles2018: Statistical Rescoring of Sentence Alignments in Large, Noisy Parallel Corpora " ,
author = { Lison, Pierre and
Tiedemann, J{"o}rg and
Kouylekov, Milen } ,
booktitle = " Proceedings of the Eleventh International Conference on Language Resources and Evaluation ({LREC} 2018) " ,
month = may,
year = " 2018 " ,
address = " Miyazaki, Japan " ,
publisher = " European Language Resources Association (ELRA) " ,
url = " https://www.aclweb.org/anthology/L18-1275 " ,
}Parque Kyubyong, Dongwoo Kim y YJ Choe


