word2word
1.0.0
ترجمات الكلمات سهلة الاستخدام لـ 3564 زوجًا من اللغة.
هذا هو الرمز الرسمي المصاحب لورقة LREC 2020.
أولاً ، قم بتثبيت الحزمة باستخدام pip :
pip install word2wordأو
git clone https://github.com/kakaobrain/word2word
python setup.py installبعد ذلك ، في Python ، قم بتنزيل النموذج واسترداد ترجمات Word-5 Word لأي كلمة معينة إلى اللغة المطلوبة:
from word2word import Word2word
en2fr = Word2word ( "en" , "fr" )
print ( en2fr ( "apple" ))
# out: ['pomme', 'pommes', 'pommier', 'tartes', 'fleurs'] 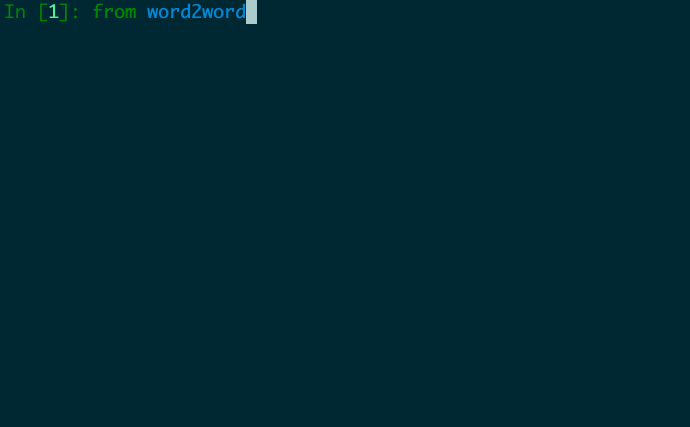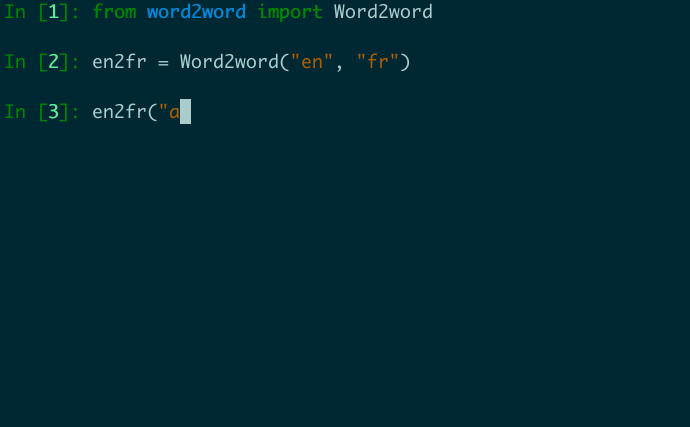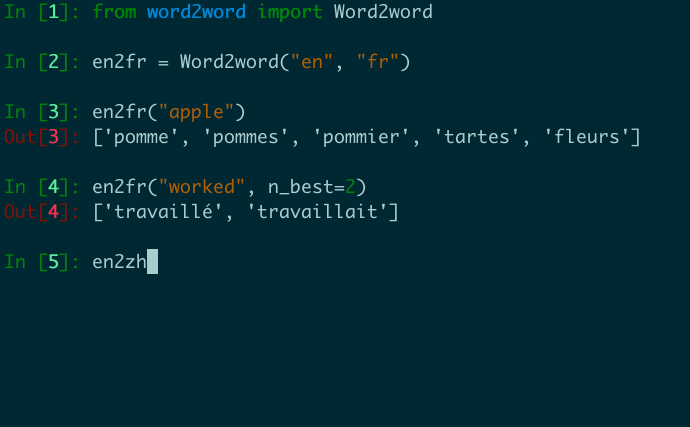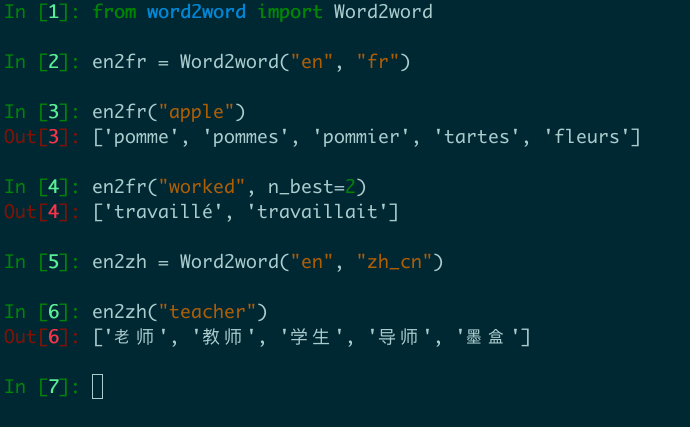
نحن نقدم ترجمات من أعلى إلى كلمة عبر جميع الأزواج المتاحة من OpenSubTitles2018. هذا يصل إلى ما مجموعه 3564 زوجًا من اللغات عبر 62 لغة فريدة.
يتم توفير القائمة الكاملة هنا.
يحسب نهجنا ترجمات الكلمات العليا على أساس إحصائيات التداخل المشترك بين أزواج الكلمات عبر اللغات في مجموعة موازية. بالإضافة إلى ذلك ، نقدم مصطلح تصحيح يتحكم في أي تأثير مربك قادم من كلمات المصدر الأخرى في نفس الجملة. الطريقة الناتجة هي نهج فعال وقابل للتطوير يتيح لنا بناء قواميس كبيرة ثنائية اللغة من أي مجموعة متوازية معينة.
لمزيد من التفاصيل ، راجع قسم المنهجية في ورقتنا.
توفر حزمة word2word أيضًا واجهة لبناء معجم ثنائي اللغة مخصص باستخدام مجموعة مختلفة متوازية. هنا ، نعرض مثالًا على بناء واحدة من مجموعة بيانات Medline English-French:
from word2word import Word2word
# custom parallel data: data/pubmed.en-fr.en, data/pubmed.en-fr.fr
my_en2fr = Word2word . make ( "en" , "fr" , "data/pubmed.en-fr" )
# ...building...
print ( my_en2fr ( "mitochondrial" ))
# out: ['mitochondriale', 'mitochondriales', 'mitochondrial',
# 'cytopathies', 'mitochondriaux']عندما يتم بناؤها من المصدر ، يمكن أيضًا إنشاء المعجم ثنائي اللغة من سطر الأوامر على النحو التالي:
python make.py --lang1 en --lang2 fr --datapref data/pubmed.en-fr في كلتا الحالتين ، يمكن إعادة تحميل المعجم المخصص (المحفوظ إلى datapref/ افتراضيًا) في Python:
from word2word import Word2word
my_en2fr = Word2word . load ( "en" , "fr" , "data/pubmed.en-fr" )
# Loaded word2word custom bilingual lexicon from data/pubmed.en-fr/en-fr.pkl في كل من واجهة Python وواجهة سطر الأوامر ، make يستخدم المعالجة المتعددة مع 16 وحدة المعالجة المركزية بشكل افتراضي. يمكن تعديل عدد عمال وحدة المعالجة المركزية عن طريق تعيين num_workers=N (python) أو --num_workers N (سطر الأوامر).
إذا كنت تستخدم Word2Word للبحث ، فيرجى الاستشهاد بورقة:
@inproceedings { choe2020word2word ,
author = { Yo Joong Choe and Kyubyong Park and Dongwoo Kim } ,
title = { word2word: A Collection of Bilingual Lexicons for 3,564 Language Pairs } ,
booktitle = { Proceedings of the 12th International Conference on Language Resources and Evaluation (LREC 2020) } ,
year = { 2020 }
}تم إنشاء جميع معجورنا ثنائية اللغة من مجموعة بيانات OpenSubTitles2018 المتاحة للجمهور:
@inproceedings { lison-etal-2018-opensubtitles2018 ,
title = " {O}pen{S}ubtitles2018: Statistical Rescoring of Sentence Alignments in Large, Noisy Parallel Corpora " ,
author = { Lison, Pierre and
Tiedemann, J{"o}rg and
Kouylekov, Milen } ,
booktitle = " Proceedings of the Eleventh International Conference on Language Resources and Evaluation ({LREC} 2018) " ,
month = may,
year = " 2018 " ,
address = " Miyazaki, Japan " ,
publisher = " European Language Resources Association (ELRA) " ,
url = " https://www.aclweb.org/anthology/L18-1275 " ,
}Kyubyong Park و Dongwoo Kim و YJ Choe


