word2word
1.0.0
Terjemahan kata yang mudah digunakan untuk 3.564 pasangan bahasa.
Ini adalah kode resmi yang menyertai kertas LREC 2020 kami.
Pertama, instal paket menggunakan pip :
pip install word2wordATAU
git clone https://github.com/kakaobrain/word2word
python setup.py installKemudian, dalam Python, unduh model dan ambil terjemahan Word top-5 dari kata apa pun yang diberikan ke bahasa yang diinginkan:
from word2word import Word2word
en2fr = Word2word ( "en" , "fr" )
print ( en2fr ( "apple" ))
# out: ['pomme', 'pommes', 'pommier', 'tartes', 'fleurs'] 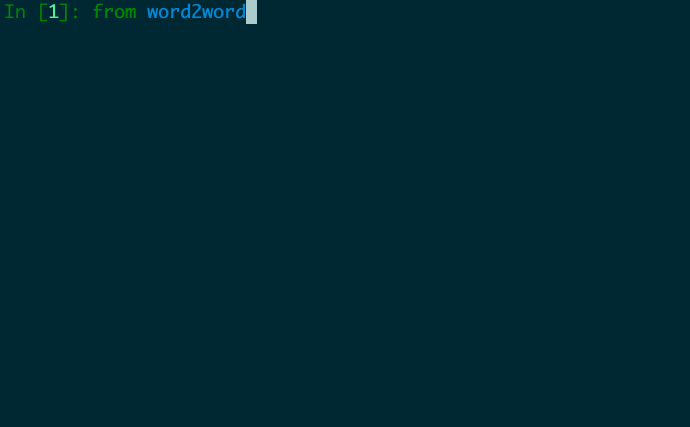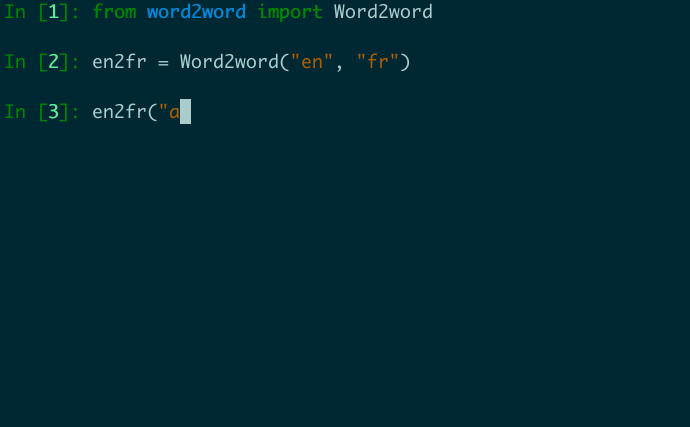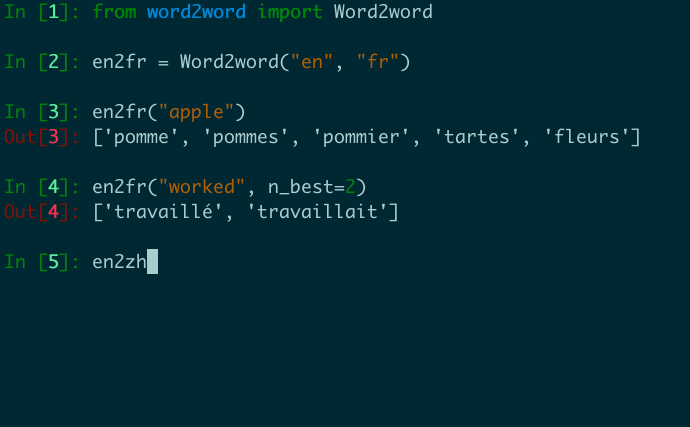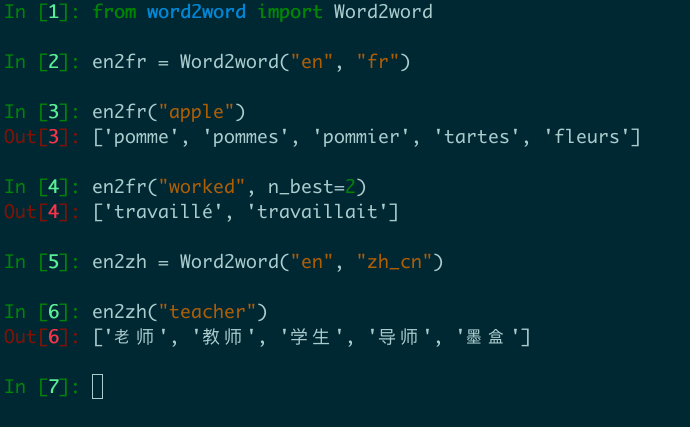
Kami menyediakan terjemahan Word-to-Word top-ke-word di semua pasangan yang tersedia dari OpenSubtitles2018. Ini berjumlah total 3.564 pasangan bahasa di 62 bahasa unik.
Daftar lengkap disediakan di sini.
Pendekatan kami menghitung terjemahan kata-K atas berdasarkan statistik co-kejadian antara pasangan kata lintas-bahasa dalam korpus paralel. Kami juga memperkenalkan istilah koreksi yang mengontrol efek perancu yang berasal dari kata -kata sumber lain dalam kalimat yang sama. Metode yang dihasilkan adalah pendekatan yang efisien dan dapat diskalakan yang memungkinkan kita untuk membuat kamus bilingual besar dari korpus paralel tertentu.
Untuk detail lebih lanjut, lihat bagian Metodologi Makalah kami.
Paket word2word juga menyediakan antarmuka untuk membangun leksikon bilingual khusus menggunakan korpus paralel yang berbeda. Di sini, kami menunjukkan contoh membangun satu dari dataset Medline English-Prancis:
from word2word import Word2word
# custom parallel data: data/pubmed.en-fr.en, data/pubmed.en-fr.fr
my_en2fr = Word2word . make ( "en" , "fr" , "data/pubmed.en-fr" )
# ...building...
print ( my_en2fr ( "mitochondrial" ))
# out: ['mitochondriale', 'mitochondriales', 'mitochondrial',
# 'cytopathies', 'mitochondriaux']Saat dibangun dari sumber, leksikon bilingual juga dapat dibangun dari baris perintah sebagai berikut:
python make.py --lang1 en --lang2 fr --datapref data/pubmed.en-fr Dalam kedua kasus, leksikon kustom (disimpan ke datapref/ secara default) dapat dimuat ulang di Python:
from word2word import Word2word
my_en2fr = Word2word . load ( "en" , "fr" , "data/pubmed.en-fr" )
# Loaded word2word custom bilingual lexicon from data/pubmed.en-fr/en-fr.pkl Baik di antarmuka Python dan antarmuka baris perintah, make menggunakan multiprosesing dengan 16 CPU secara default. Jumlah pekerja CPU dapat disesuaikan dengan mengatur num_workers=N (python) atau --num_workers N (baris perintah).
Jika Anda menggunakan Word2word untuk penelitian, silakan kutip makalah kami:
@inproceedings { choe2020word2word ,
author = { Yo Joong Choe and Kyubyong Park and Dongwoo Kim } ,
title = { word2word: A Collection of Bilingual Lexicons for 3,564 Language Pairs } ,
booktitle = { Proceedings of the 12th International Conference on Language Resources and Evaluation (LREC 2020) } ,
year = { 2020 }
}Semua leksikon bilingual kami yang telah dikomputasi sebelumnya dibangun dari dataset OpenSubtitles2018 yang tersedia untuk umum:
@inproceedings { lison-etal-2018-opensubtitles2018 ,
title = " {O}pen{S}ubtitles2018: Statistical Rescoring of Sentence Alignments in Large, Noisy Parallel Corpora " ,
author = { Lison, Pierre and
Tiedemann, J{"o}rg and
Kouylekov, Milen } ,
booktitle = " Proceedings of the Eleventh International Conference on Language Resources and Evaluation ({LREC} 2018) " ,
month = may,
year = " 2018 " ,
address = " Miyazaki, Japan " ,
publisher = " European Language Resources Association (ELRA) " ,
url = " https://www.aclweb.org/anthology/L18-1275 " ,
}Taman Kyubyong, Dongwoo Kim, dan YJ Choe


