word2word
1.0.0
Простые в использовании перевод слов для 3564 языковых пар.
Это официальный код, сопровождающий нашу бумагу LREC 2020.
Сначала установите пакет с помощью pip :
pip install word2wordИЛИ
git clone https://github.com/kakaobrain/word2word
python setup.py installЗатем, в Python, загрузите модель и получите переводы Top-5 слов любого данного слова на желаемый язык:
from word2word import Word2word
en2fr = Word2word ( "en" , "fr" )
print ( en2fr ( "apple" ))
# out: ['pomme', 'pommes', 'pommier', 'tartes', 'fleurs'] 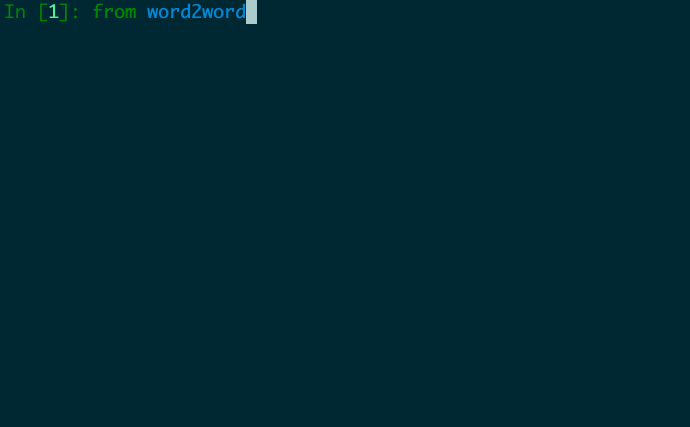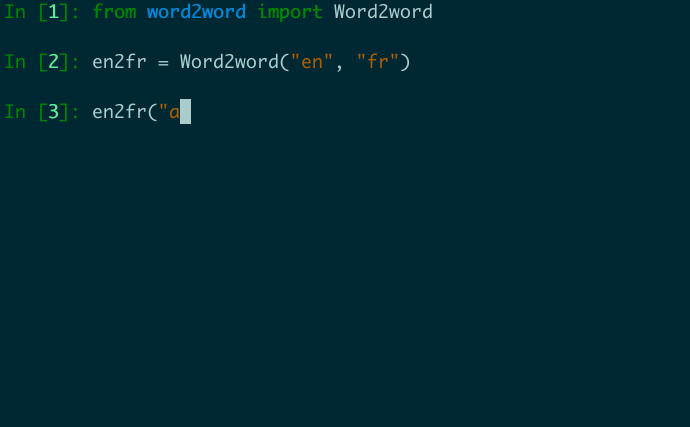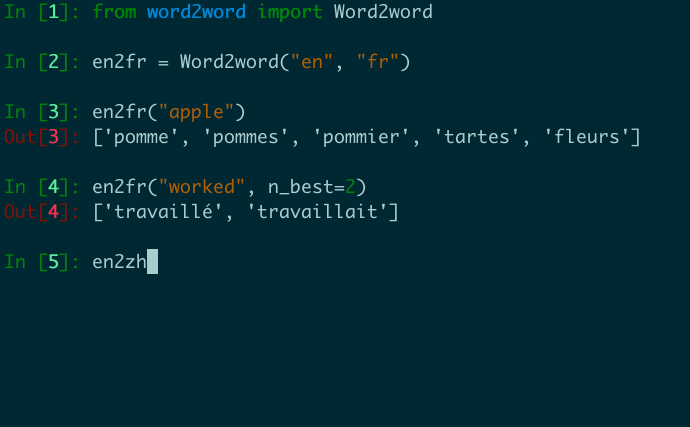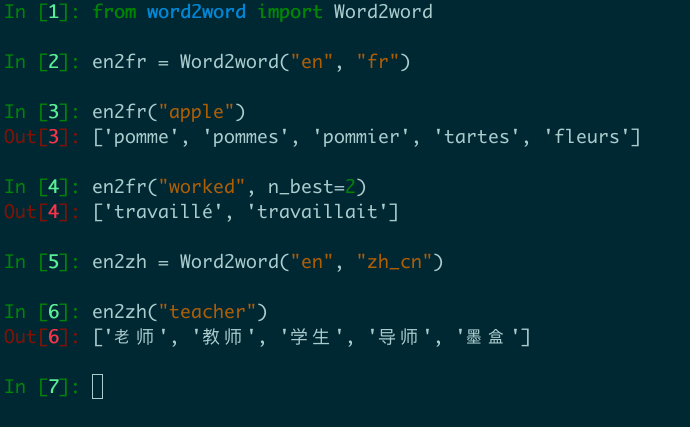
Мы предоставляем переводы Top-K Word-Cord во всех доступных парах от opensubtitles2018. Это составляет в общей сложности 3564 языковых пар на 62 уникальных языках.
Полный список предоставлен здесь.
Наш подход вычисляет переводы Top-K Word, основанные на статистике совместного появления между межсочевыми парами слов в параллельном корпусе. Кроме того, мы вводим коррекционный термин, который контролирует любой смешанный эффект, исходящий от других исходных слов в том же предложении. Полученный метод является эффективным и масштабируемым подходом, который позволяет нам построить большие двуязычные словари из любого данного параллельного корпуса.
Более подробную информацию см. В разделе методологии нашей статьи.
Пакет word2word также предоставляет интерфейс для создания нестандартной двуязычной лексики с использованием другого параллельного корпуса. Здесь мы показываем пример создания одного из набора данных по английскому франции Medline:
from word2word import Word2word
# custom parallel data: data/pubmed.en-fr.en, data/pubmed.en-fr.fr
my_en2fr = Word2word . make ( "en" , "fr" , "data/pubmed.en-fr" )
# ...building...
print ( my_en2fr ( "mitochondrial" ))
# out: ['mitochondriale', 'mitochondriales', 'mitochondrial',
# 'cytopathies', 'mitochondriaux']При построении из источника двуязычная лексика также может быть построена из командной строки следующим образом:
python make.py --lang1 en --lang2 fr --datapref data/pubmed.en-fr В обоих случаях пользовательский лексикон (сохраненный в datapref/ по умолчанию) может быть перегружена в Python:
from word2word import Word2word
my_en2fr = Word2word . load ( "en" , "fr" , "data/pubmed.en-fr" )
# Loaded word2word custom bilingual lexicon from data/pubmed.en-fr/en-fr.pkl Как в интерфейсе Python, так и в интерфейсе командной строки, по умолчанию make многопроцессорную работу с 16 процессорами. Количество работников ЦП может быть скорректировано путем установки num_workers=N (python) или --num_workers N (командная строка).
Если вы используете Word2word для исследований, пожалуйста, укажите нашу статью:
@inproceedings { choe2020word2word ,
author = { Yo Joong Choe and Kyubyong Park and Dongwoo Kim } ,
title = { word2word: A Collection of Bilingual Lexicons for 3,564 Language Pairs } ,
booktitle = { Proceedings of the 12th International Conference on Language Resources and Evaluation (LREC 2020) } ,
year = { 2020 }
}Все наши предварительно вычисленные двуязычные лексиконы были построены из общедоступного набора данных OpenSubtitles2018:
@inproceedings { lison-etal-2018-opensubtitles2018 ,
title = " {O}pen{S}ubtitles2018: Statistical Rescoring of Sentence Alignments in Large, Noisy Parallel Corpora " ,
author = { Lison, Pierre and
Tiedemann, J{"o}rg and
Kouylekov, Milen } ,
booktitle = " Proceedings of the Eleventh International Conference on Language Resources and Evaluation ({LREC} 2018) " ,
month = may,
year = " 2018 " ,
address = " Miyazaki, Japan " ,
publisher = " European Language Resources Association (ELRA) " ,
url = " https://www.aclweb.org/anthology/L18-1275 " ,
}Kyubyong Park, Dongwoo Kim и YJ Choe


