word2word
1.0.0
Traduções de palavras fáceis de usar para 3.564 pares de idiomas.
Este é o código oficial que acompanha nosso artigo do LREC 2020.
Primeiro, instale o pacote usando pip :
pip install word2wordOU
git clone https://github.com/kakaobrain/word2word
python setup.py installEm seguida, em Python, faça o download do modelo e recupere as 5 traduções de palavras de qualquer palavra para o idioma desejado:
from word2word import Word2word
en2fr = Word2word ( "en" , "fr" )
print ( en2fr ( "apple" ))
# out: ['pomme', 'pommes', 'pommier', 'tartes', 'fleurs'] 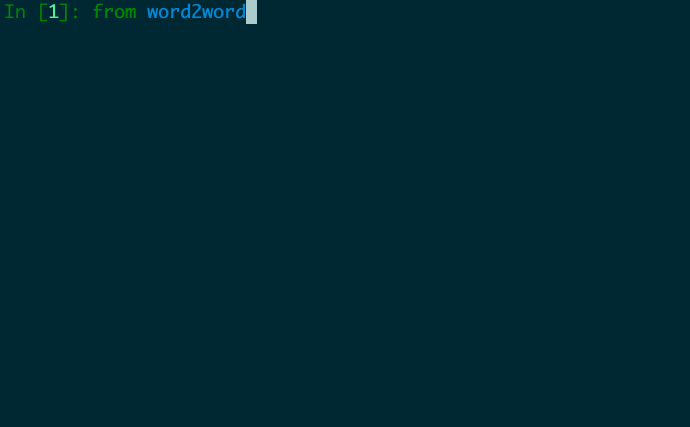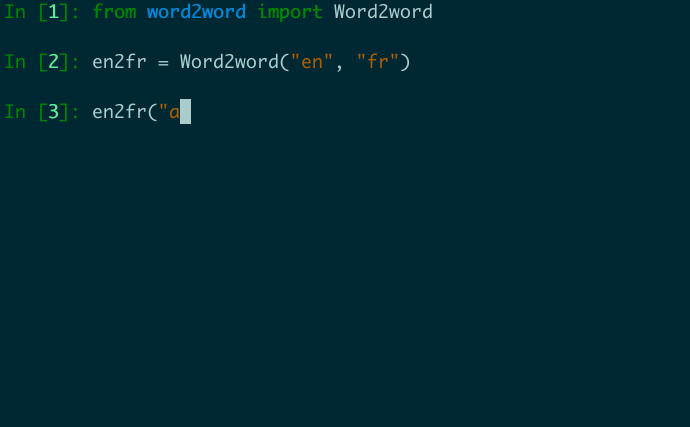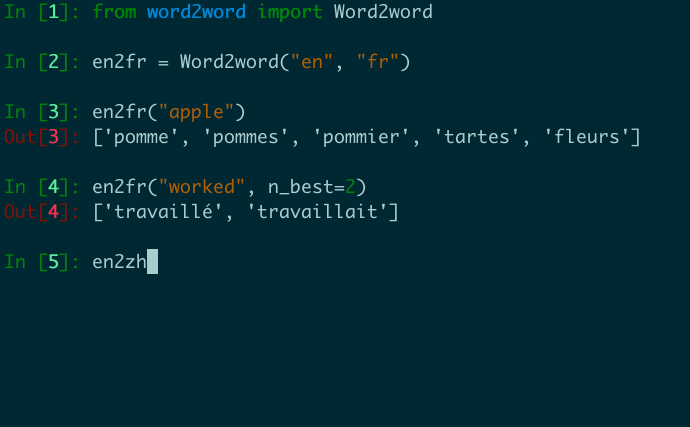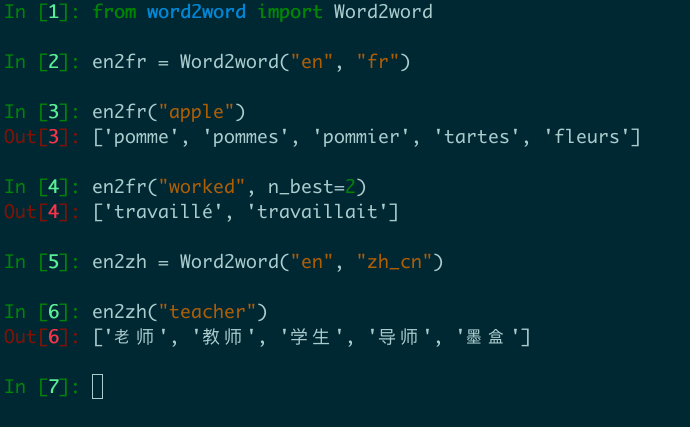
Fornecemos traduções de palavras-palavras top-k em todos os pares disponíveis do OpenSubtitles2018. Isso equivale a um total de 3.564 pares de idiomas em 62 idiomas únicos.
A lista completa é fornecida aqui.
Nossa abordagem calcula traduções de palavras de topo-K com base nas estatísticas de co-ocorrência entre pares de palavras transfrondual em um corpus paralelo. Além disso, introduzimos um termo de correção que controla qualquer efeito de confusão proveniente de outras palavras de origem na mesma frase. O método resultante é uma abordagem eficiente e escalável que nos permite construir grandes dicionários bilíngues a partir de qualquer corpus paralelo.
Para mais detalhes, consulte a seção de metodologia do nosso artigo.
O pacote word2word também fornece interface para a criação de um léxico bilíngue personalizado usando um corpus paralelo diferente. Aqui, mostramos um exemplo de construção de um do conjunto de dados Medline English-French:
from word2word import Word2word
# custom parallel data: data/pubmed.en-fr.en, data/pubmed.en-fr.fr
my_en2fr = Word2word . make ( "en" , "fr" , "data/pubmed.en-fr" )
# ...building...
print ( my_en2fr ( "mitochondrial" ))
# out: ['mitochondriale', 'mitochondriales', 'mitochondrial',
# 'cytopathies', 'mitochondriaux']Quando construído a partir da fonte, o léxico bilíngue também pode ser construído a partir da linha de comando da seguinte maneira:
python make.py --lang1 en --lang2 fr --datapref data/pubmed.en-fr Nos dois casos, o léxico personalizado (salvo para datapref/ por padrão) pode ser recarregado no Python:
from word2word import Word2word
my_en2fr = Word2word . load ( "en" , "fr" , "data/pubmed.en-fr" )
# Loaded word2word custom bilingual lexicon from data/pubmed.en-fr/en-fr.pkl Na interface Python e na interface da linha de comando, make o multiprocessamento com 16 CPUs por padrão. O número de trabalhadores da CPU pode ser ajustado definindo num_workers=N (python) ou --num_workers N (linha de comando).
Se você usar o Word2word para pesquisa, cite nosso artigo:
@inproceedings { choe2020word2word ,
author = { Yo Joong Choe and Kyubyong Park and Dongwoo Kim } ,
title = { word2word: A Collection of Bilingual Lexicons for 3,564 Language Pairs } ,
booktitle = { Proceedings of the 12th International Conference on Language Resources and Evaluation (LREC 2020) } ,
year = { 2020 }
}Todos os nossos léxicos bilíngues pré-computados foram construídos a partir do conjunto de dados OpenSubtitles2018 disponível ao público:
@inproceedings { lison-etal-2018-opensubtitles2018 ,
title = " {O}pen{S}ubtitles2018: Statistical Rescoring of Sentence Alignments in Large, Noisy Parallel Corpora " ,
author = { Lison, Pierre and
Tiedemann, J{"o}rg and
Kouylekov, Milen } ,
booktitle = " Proceedings of the Eleventh International Conference on Language Resources and Evaluation ({LREC} 2018) " ,
month = may,
year = " 2018 " ,
address = " Miyazaki, Japan " ,
publisher = " European Language Resources Association (ELRA) " ,
url = " https://www.aclweb.org/anthology/L18-1275 " ,
}Kyubyong Park, Dongwoo Kim e YJ Choe


