word2word
1.0.0
3,564 개의 언어 쌍에 대한 사용하기 쉬운 단어 번역.
이것은 LREC 2020 논문과 함께 제공되는 공식 코드입니다.
먼저 pip 사용하여 패키지를 설치하십시오.
pip install word2word또는
git clone https://github.com/kakaobrain/word2word
python setup.py install그런 다음 Python에서 모델을 다운로드하고 주어진 단어의 상단 5 단어 번역을 원하는 언어로 검색하십시오.
from word2word import Word2word
en2fr = Word2word ( "en" , "fr" )
print ( en2fr ( "apple" ))
# out: ['pomme', 'pommes', 'pommier', 'tartes', 'fleurs'] 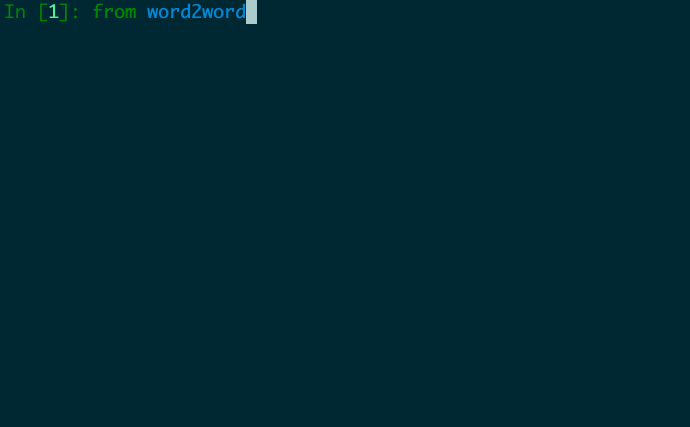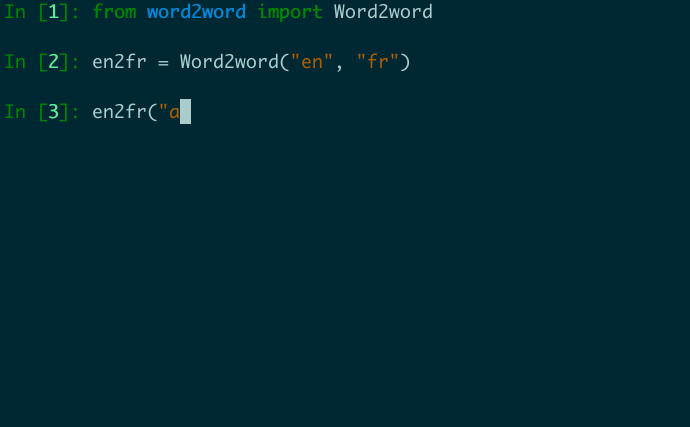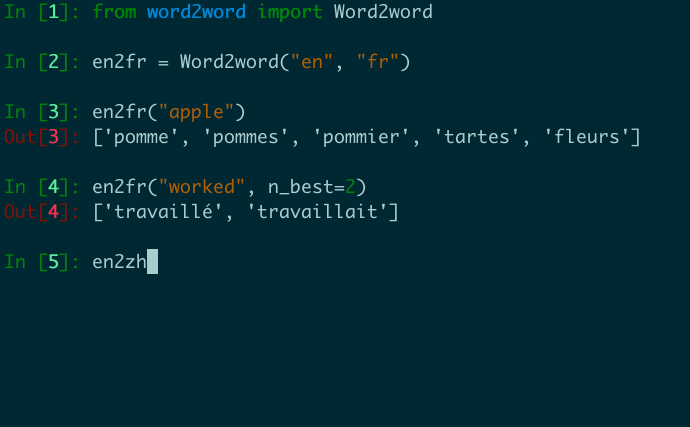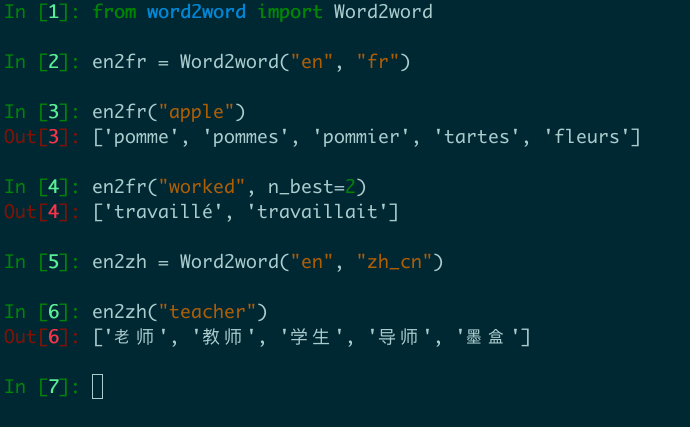
OpenSubtitles2018의 모든 가용 쌍에 걸쳐 Top-K Word-to-Word Translations를 제공합니다. 이것은 62 개의 고유 한 언어에 걸쳐 총 3,564 개의 언어 쌍에 해당합니다.
전체 목록은 여기에 제공됩니다.
우리의 접근 방식은 평행 한 코퍼스의 문구 간 단어 쌍 간의 동시 발생 통계를 기반으로 Top-K Word Translations를 계산합니다. 또한 동일한 문장 내에서 다른 소스 단어에서 나오는 혼란 효과를 제어하는 수정 용어를 추가로 소개합니다. 결과적인 방법은 효율적이고 확장 가능한 접근 방식으로, 주어진 병렬 코퍼스에서 큰 이중 언어 사전을 구성 할 수 있습니다.
자세한 내용은 논문의 방법론 섹션을 참조하십시오.
word2word 패키지는 또한 다른 병렬 코퍼스를 사용하여 맞춤형 이중 언어 사전을 구축하기위한 인터페이스를 제공합니다. 여기에서는 Medline English-French 데이터 세트에서 하나를 구축하는 예를 보여줍니다.
from word2word import Word2word
# custom parallel data: data/pubmed.en-fr.en, data/pubmed.en-fr.fr
my_en2fr = Word2word . make ( "en" , "fr" , "data/pubmed.en-fr" )
# ...building...
print ( my_en2fr ( "mitochondrial" ))
# out: ['mitochondriale', 'mitochondriales', 'mitochondrial',
# 'cytopathies', 'mitochondriaux']소스에서 구축 된 경우 이중 언어 사전은 다음과 같이 명령 줄에서 구성 할 수 있습니다.
python make.py --lang1 en --lang2 fr --datapref data/pubmed.en-fr 두 경우 모두, 사용자 정의 어휘 (기본적으로 datapref/ 에 저장)는 파이썬에서 다시로드 될 수 있습니다.
from word2word import Word2word
my_en2fr = Word2word . load ( "en" , "fr" , "data/pubmed.en-fr" )
# Loaded word2word custom bilingual lexicon from data/pubmed.en-fr/en-fr.pkl Python 인터페이스와 명령 줄 인터페이스 모두에서 기본적으로 16 CPU와의 멀티 프로세싱을 사용 make . CPU 작업자의 수는 num_workers=N (Python) 또는 --num_workers N (명령 줄)을 설정하여 조정할 수 있습니다.
연구에 Word2word를 사용하는 경우 논문을 인용하십시오.
@inproceedings { choe2020word2word ,
author = { Yo Joong Choe and Kyubyong Park and Dongwoo Kim } ,
title = { word2word: A Collection of Bilingual Lexicons for 3,564 Language Pairs } ,
booktitle = { Proceedings of the 12th International Conference on Language Resources and Evaluation (LREC 2020) } ,
year = { 2020 }
}우리의 사전 계산 된 이중 언어 사전은 모두 공개적으로 이용 가능한 OpenSubtitles2018 데이터 세트로 구성되었습니다.
@inproceedings { lison-etal-2018-opensubtitles2018 ,
title = " {O}pen{S}ubtitles2018: Statistical Rescoring of Sentence Alignments in Large, Noisy Parallel Corpora " ,
author = { Lison, Pierre and
Tiedemann, J{"o}rg and
Kouylekov, Milen } ,
booktitle = " Proceedings of the Eleventh International Conference on Language Resources and Evaluation ({LREC} 2018) " ,
month = may,
year = " 2018 " ,
address = " Miyazaki, Japan " ,
publisher = " European Language Resources Association (ELRA) " ,
url = " https://www.aclweb.org/anthology/L18-1275 " ,
}Kyubyong Park, Dongwoo Kim 및 YJ Choe


