word2word
1.0.0
Traductions de mots faciles à utiliser pour 3 564 paires de langues.
Il s'agit du code officiel accompagnant notre article LREC 2020.
Tout d'abord, installez le package à l'aide de pip :
pip install word2wordOU
git clone https://github.com/kakaobrain/word2word
python setup.py installEnsuite, dans Python, téléchargez le modèle et récupérez les traductions des mots top 5 de tout mot donné à la langue souhaitée:
from word2word import Word2word
en2fr = Word2word ( "en" , "fr" )
print ( en2fr ( "apple" ))
# out: ['pomme', 'pommes', 'pommier', 'tartes', 'fleurs'] 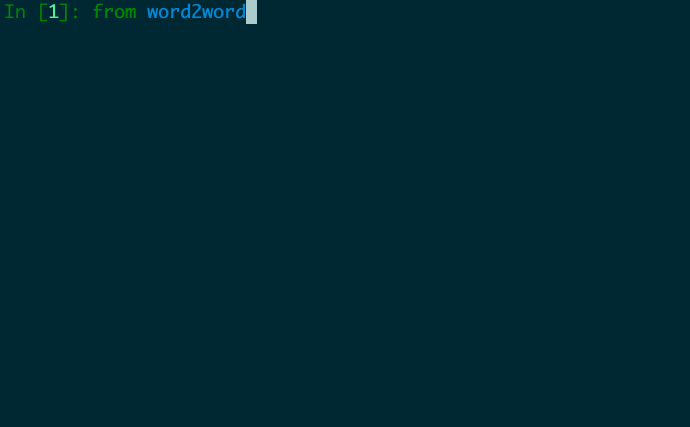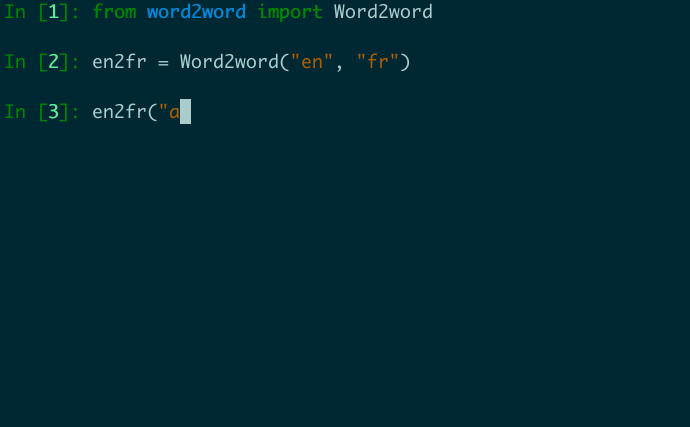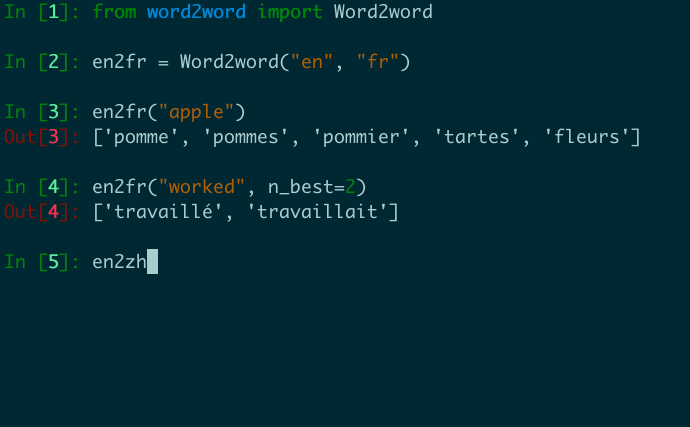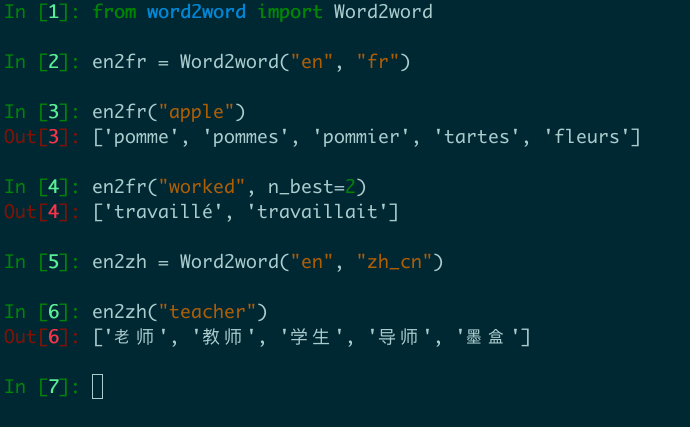
Nous fournissons des traductions de mot à mot haut de gamme sur toutes les paires disponibles à partir d'OpenSubtitles2018. Cela représente un total de 3 564 paires de langues dans 62 langues uniques.
La liste complète est fournie ici.
Notre approche calcule les traductions de mots supérieures basées sur les statistiques de cooccurrence entre les paires de mots trans-lingues dans un corpus parallèle. Nous introduisons en outre un terme de correction qui contrôle tout effet de confusion provenant d'autres mots source au sein de la même phrase. La méthode résultante est une approche efficace et évolutive qui nous permet de construire de grands dictionnaires bilingues à partir d'un corpus parallèle donné.
Pour plus de détails, consultez la section méthodologie de notre article.
Le package word2word fournit également une interface pour construire un lexique bilingue personnalisé à l'aide d'un corpus parallèle différent. Ici, nous montrons un exemple de création d'un à partir de l'ensemble de données en anglais Medline:
from word2word import Word2word
# custom parallel data: data/pubmed.en-fr.en, data/pubmed.en-fr.fr
my_en2fr = Word2word . make ( "en" , "fr" , "data/pubmed.en-fr" )
# ...building...
print ( my_en2fr ( "mitochondrial" ))
# out: ['mitochondriale', 'mitochondriales', 'mitochondrial',
# 'cytopathies', 'mitochondriaux']Lorsqu'il est construit à partir de source, le lexique bilingue peut également être construit à partir de la ligne de commande comme suit:
python make.py --lang1 en --lang2 fr --datapref data/pubmed.en-fr Dans les deux cas, le lexique personnalisé (enregistré sur datapref/ par défaut) peut être rechargé dans Python:
from word2word import Word2word
my_en2fr = Word2word . load ( "en" , "fr" , "data/pubmed.en-fr" )
# Loaded word2word custom bilingual lexicon from data/pubmed.en-fr/en-fr.pkl Dans l'interface Python et l'interface de ligne de commande, make par défaut le multiprocessement des utilisations avec 16 processeurs. Le nombre de travailleurs du processeur peut être ajusté en définissant num_workers=N (python) ou --num_workers N (ligne de commande).
Si vous utilisez Word2Word pour la recherche, veuillez citer notre article:
@inproceedings { choe2020word2word ,
author = { Yo Joong Choe and Kyubyong Park and Dongwoo Kim } ,
title = { word2word: A Collection of Bilingual Lexicons for 3,564 Language Pairs } ,
booktitle = { Proceedings of the 12th International Conference on Language Resources and Evaluation (LREC 2020) } ,
year = { 2020 }
}Tous nos lexiques bilingues pré-calculés ont été construits à partir de l'ensemble de données OpenSubtitles2018 accessible au public:
@inproceedings { lison-etal-2018-opensubtitles2018 ,
title = " {O}pen{S}ubtitles2018: Statistical Rescoring of Sentence Alignments in Large, Noisy Parallel Corpora " ,
author = { Lison, Pierre and
Tiedemann, J{"o}rg and
Kouylekov, Milen } ,
booktitle = " Proceedings of the Eleventh International Conference on Language Resources and Evaluation ({LREC} 2018) " ,
month = may,
year = " 2018 " ,
address = " Miyazaki, Japan " ,
publisher = " European Language Resources Association (ELRA) " ,
url = " https://www.aclweb.org/anthology/L18-1275 " ,
}Kyubyong Park, Dongwoo Kim et YJ Choe


