word2word
1.0.0
3,564の言語ペアの使いやすい単語翻訳。
これは、LREC 2020ペーパーに付随する公式コードです。
まず、 pipを使用してパッケージをインストールします。
pip install word2wordまたは
git clone https://github.com/kakaobrain/word2word
python setup.py install次に、Pythonでモデルをダウンロードし、特定の単語のトップ5ワード翻訳を目的の言語に取得します。
from word2word import Word2word
en2fr = Word2word ( "en" , "fr" )
print ( en2fr ( "apple" ))
# out: ['pomme', 'pommes', 'pommier', 'tartes', 'fleurs'] 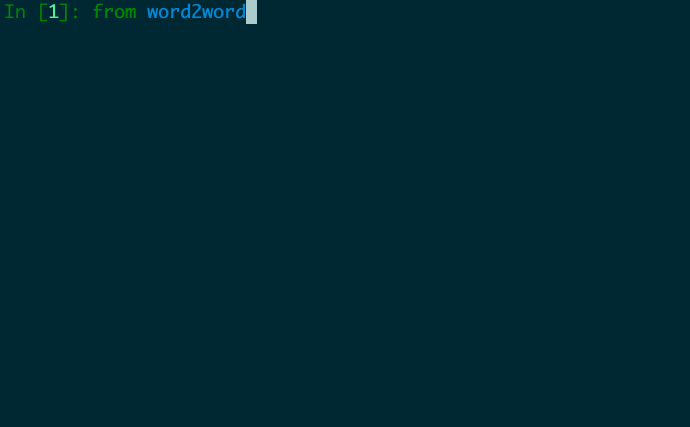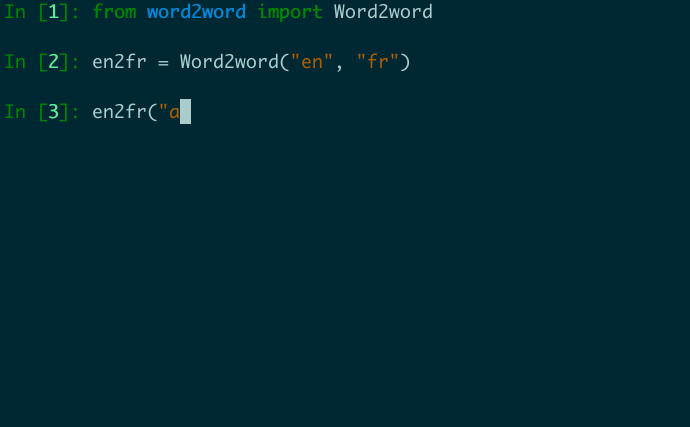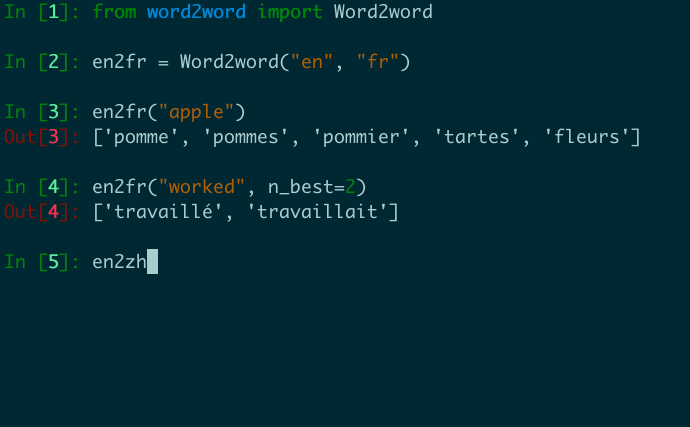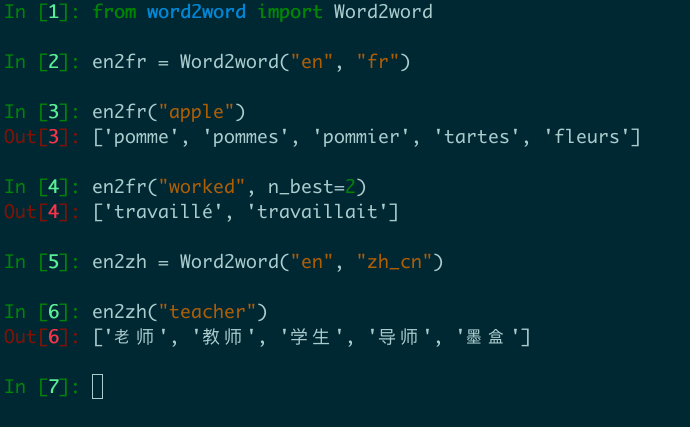
OpenSubTitles2018から利用可能なすべてのペアで、トップKワード間の翻訳を提供します。これは、62の一意の言語にわたって合計3,564の言語ペアになります。
完全なリストはここにあります。
私たちのアプローチは、平行なコーパス内の横断的単語ペア間の共起統計に基づいて、トップKの単語翻訳を計算します。さらに、同じ文内の他のソース語からの交絡効果を制御する修正用語を導入します。結果の方法は、特定の平行コーパスから大きなバイリンガル辞書を構築できる効率的でスケーラブルなアプローチです。
詳細については、論文の方法論セクションを参照してください。
word2wordパッケージは、異なる並列コーパスを使用してカスタムバイリンガルレキシコンを構築するためのインターフェイスも提供します。ここでは、Medline English-French Datasetの構築例を示しています。
from word2word import Word2word
# custom parallel data: data/pubmed.en-fr.en, data/pubmed.en-fr.fr
my_en2fr = Word2word . make ( "en" , "fr" , "data/pubmed.en-fr" )
# ...building...
print ( my_en2fr ( "mitochondrial" ))
# out: ['mitochondriale', 'mitochondriales', 'mitochondrial',
# 'cytopathies', 'mitochondriaux']ソースから構築される場合、バイリンガルレキシコンは次のようにコマンドラインから構築することもできます。
python make.py --lang1 en --lang2 fr --datapref data/pubmed.en-frどちらの場合も、カスタムレキシコン(デフォルトではdatapref/に保存)をPythonで再ロードできます。
from word2word import Word2word
my_en2fr = Word2word . load ( "en" , "fr" , "data/pubmed.en-fr" )
# Loaded word2word custom bilingual lexicon from data/pubmed.en-fr/en-fr.pklPythonインターフェイスとコマンドラインインターフェイスの両方で、デフォルトで16 CPUでマルチプロセシングを使用しmake 。 CPUワーカーの数はnum_workers=N (python)または--num_workers N (コマンドライン)を設定することで調整できます。
Word2Wordを調査に使用する場合は、私たちの論文を引用してください。
@inproceedings { choe2020word2word ,
author = { Yo Joong Choe and Kyubyong Park and Dongwoo Kim } ,
title = { word2word: A Collection of Bilingual Lexicons for 3,564 Language Pairs } ,
booktitle = { Proceedings of the 12th International Conference on Language Resources and Evaluation (LREC 2020) } ,
year = { 2020 }
}事前に計算されたバイリンガルレキシコンはすべて、公開されているOpenSubTitles2018データセットから構築されました。
@inproceedings { lison-etal-2018-opensubtitles2018 ,
title = " {O}pen{S}ubtitles2018: Statistical Rescoring of Sentence Alignments in Large, Noisy Parallel Corpora " ,
author = { Lison, Pierre and
Tiedemann, J{"o}rg and
Kouylekov, Milen } ,
booktitle = " Proceedings of the Eleventh International Conference on Language Resources and Evaluation ({LREC} 2018) " ,
month = may,
year = " 2018 " ,
address = " Miyazaki, Japan " ,
publisher = " European Language Resources Association (ELRA) " ,
url = " https://www.aclweb.org/anthology/L18-1275 " ,
}Kyubyong Park、Dongwoo Kim、YJ Choe


