LLMCompiler
1.0.0
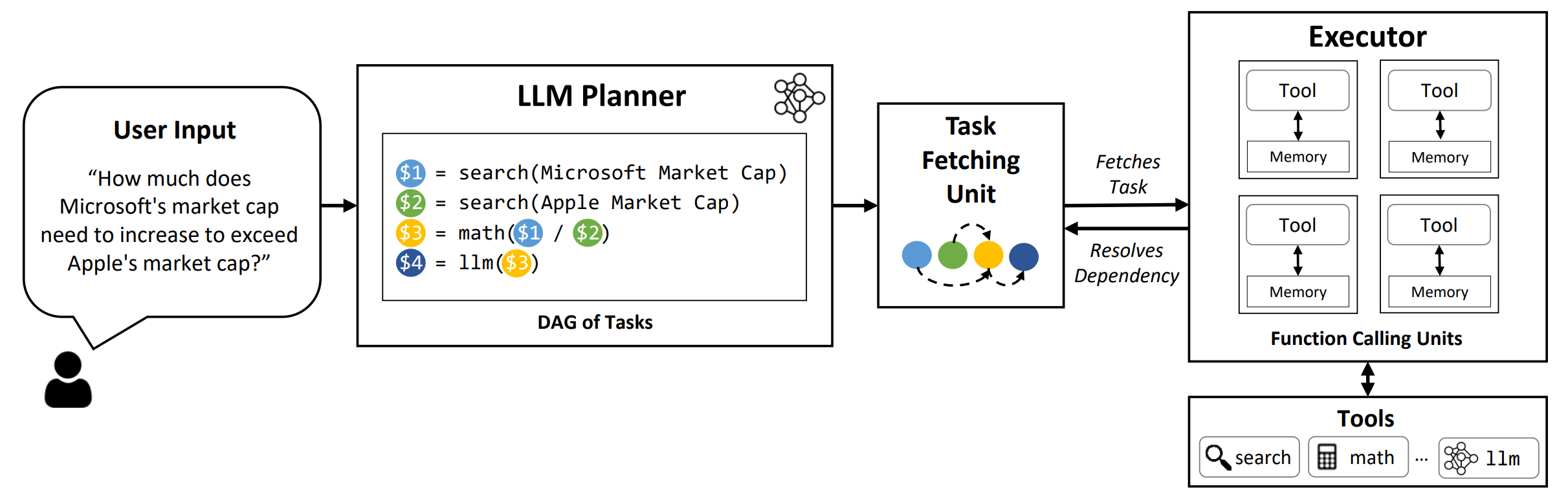
LLMCompiler เป็นเฟรมเวิร์กที่ช่วยให้ การประสานงานที่มีประสิทธิภาพและมีประสิทธิภาพของฟังก์ชั่นขนานที่เรียก ด้วย LLMs รวมถึงทั้งแบบโอเพนซอร์ซและแบบใกล้ชิดโดยอัตโนมัติโดยการระบุว่างานใดสามารถดำเนินการในแบบคู่ขนานได้โดยอัตโนมัติ
TL; DR: ความสามารถในการใช้เหตุผลของ LLMS ช่วยให้พวกเขาสามารถเรียกใช้การโทรหลายฟังก์ชั่นโดยใช้ฟังก์ชั่นที่ผู้ใช้ให้เพื่อเอาชนะข้อ จำกัด โดยธรรมชาติ (เช่นการตัดความรู้ทักษะการคำนวณทางคณิตศาสตร์ที่ไม่ดีหรือขาดการเข้าถึงข้อมูลส่วนตัว) ในขณะที่การโทรแบบมัลติฟังก์ชั่นช่วยให้พวกเขาสามารถจัดการกับปัญหาที่ซับซ้อนมากขึ้นวิธีการปัจจุบันมักจะต้องใช้การให้เหตุผลตามลำดับและทำหน้าที่สำหรับแต่ละฟังก์ชั่นซึ่งอาจส่งผลให้เกิดความหน่วงแฝงสูงราคาและบางครั้งพฤติกรรมที่ไม่ถูกต้อง LLMCompiler กล่าวถึงสิ่งนี้โดยการย่อยสลายปัญหาเป็นงานหลายอย่างที่สามารถดำเนินการในแบบคู่ขนานได้อย่างมีประสิทธิภาพในการจัดเรียงการโทรแบบมัลติฟังก์ชั่น ด้วย LLMCompiler ผู้ใช้จะระบุเครื่องมือพร้อมกับตัวอย่างในบริบทที่เป็นตัวเลือกและ LLMCompiler จะคำนวณ orchestration ที่ปรับให้เหมาะสมสำหรับการเรียกใช้ฟังก์ชันโดยอัตโนมัติ LLMCompiler สามารถใช้กับรุ่นโอเพนซอร์ซเช่น LLAMA รวมถึงรุ่น GPT ของ OpenAI ในช่วงของงานที่แสดงรูปแบบที่แตกต่างกันของการเรียกฟังก์ชั่นแบบขนาน LLMCompiler แสดงให้เห็นถึง การเร่งความเร็วเวลาแฝงการประหยัดต้นทุนและการปรับปรุงความแม่นยำ อย่างต่อเนื่อง สำหรับรายละเอียดเพิ่มเติมโปรดตรวจสอบกระดาษของเรา
conda create --name llmcompiler python=3.10 -y
conda activate llmcompiler
git clone https://github.com/SqueezeAILab/LLMCompiler
cd LLMCompiler
pip install -r requirements.txt
ในการทำซ้ำผลลัพธ์การประเมินในกระดาษให้เรียกใช้คำสั่งต่อไปนี้ คุณต้องลงทะเบียนคีย์ OpenAI API ของคุณก่อน: export OPENAI_API_KEY="sk-xxx"
python run_llm_compiler.py --benchmark {benchmark-name} --store {store-path} [--logging] [--stream]
ในการเรียกใช้โมเดลที่กำหนดเองที่ให้บริการโดยใช้เฟรมเวิร์ก VLLM ให้เรียกใช้คำสั่งต่อไปนี้ คำแนะนำโดยละเอียดสำหรับการให้บริการแบบจำลองที่กำหนดเองด้วยเฟรมเวิร์ก VLLM สามารถพบได้ในเอกสาร VLLM โปรดทราบว่าพรอมต์ที่กำหนดไว้ล่วงหน้าในไฟล์การกำหนดค่าเริ่มต้นนั้นได้รับการปรับแต่งสำหรับ (ไม่ใช่แชท) LLAMA-2 70B และอาจต้องปรับเปลี่ยนสำหรับรุ่นที่แตกต่างกัน
python run_llm_compiler.py --model_type vllm --benchmark {benchmark-name} --store {store-path} --model_name {vllm-model-name} --vllm_port {vllm-port} [--logging]
--benchmark : ชื่อมาตรฐาน ใช้ hotpotqa , movie และ parallelqa เพื่อประเมิน LLMCOMPILER บน HOTPOTQA, คำแนะนำภาพยนตร์และเกณฑ์มาตรฐาน ParallelQa ตามลำดับ--store : เส้นทางที่จะบันทึกผลลัพธ์ คำถามฉลากที่แท้จริงการทำนายและเวลาแฝงต่อตัวอย่างจะถูกเก็บไว้ในรูปแบบ JSON--logging : (ไม่บังคับ) เปิดใช้งานการบันทึก ยังไม่ได้รับการสนับสนุนสำหรับ VLLM--do_benchmark : (ไม่บังคับ) ทำการเปรียบเทียบเพิ่มเติมเกี่ยวกับสถิติรันไทม์โดยละเอียด--stream : (ไม่บังคับแนะนำ) เปิดใช้งานการสตรีม มันปรับปรุงเวลาแฝงโดยการสตรีมงานออกจากผู้วางแผนไปยังหน่วยการดึงงานและผู้ดำเนินการทันทีหลังจากรุ่นของพวกเขาแทนที่จะปิดกั้นผู้บริหารจนกว่างานทั้งหมดจะถูกสร้างขึ้นจากผู้วางแผน--react : (ไม่บังคับ) ใช้ React แทน LLMCompiler สำหรับการประเมินพื้นฐาน คุณสามารถเลือกใช้จุดสิ้นสุด Azure ของคุณแทน Openai Endpoint ด้วย --model_type azure ในกรณีนี้คุณต้องจัดเตรียมการกำหนดค่า Azure ที่เกี่ยวข้องเป็นฟิลด์ต่อไปนี้ในสภาพแวดล้อมของคุณ: AZURE_ENDPOINT , AZURE_OPENAI_API_VERSION , AZURE_DEPLOYMENT_NAME และ AZURE_OPENAI_API_KEY
คุณสามารถใช้จุดสิ้นสุดของมิตรกับ --model_type friendli ในกรณีนี้คุณต้องจัดเตรียมคีย์ API Friendli ในสภาพแวดล้อมของคุณ: FRIENDLI_TOKEN นอกจากนี้คุณต้องติดตั้งไคลเอนต์ Friendli:
pip install friendli-client
หลังจากการรันสิ้นสุดลงคุณจะได้รับสรุปผลลัพธ์โดยเรียกใช้คำสั่งต่อไปนี้:
python evaluate_results.py --file {store-path}
ในการใช้ LLMCompiler บนเกณฑ์มาตรฐานที่กำหนดเองหรือใช้กรณีคุณจะต้องให้ฟังก์ชั่นและคำอธิบายของพวกเขารวมถึงตัวอย่าง โปรดดูที่ configs/hotpotqa , configs/movie และ configs/parallelqa เป็นตัวอย่าง
gpt_prompts.py : กำหนดตัวอย่างตัวอย่างในบริบทtools.py : กำหนดฟังก์ชั่น (เช่นเครื่องมือ) ที่จะใช้และคำอธิบายของพวกเขา (เช่นคำแนะนำและอาร์กิวเมนต์) เรากำลังวางแผนที่จะอัปเดตคุณสมบัติต่อไปนี้เร็ว ๆ นี้:
LLMCompiler ได้รับการพัฒนาเป็นส่วนหนึ่งของกระดาษต่อไปนี้ เราขอขอบคุณถ้าคุณโปรดอ้างอิงกระดาษต่อไปนี้หากคุณพบว่าห้องสมุดมีประโยชน์สำหรับงานของคุณ:
@article{kim2023llmcompiler,
title={An LLM Compiler for Parallel Function Calling},
author={Kim, Sehoon and Moon, Suhong and Tabrizi, Ryan and Lee, Nicholas and Mahoney, Michael and Keutzer, Kurt and Gholami, Amir},
journal={arXiv},
year={2023}
}


