LLMCompiler
1.0.0
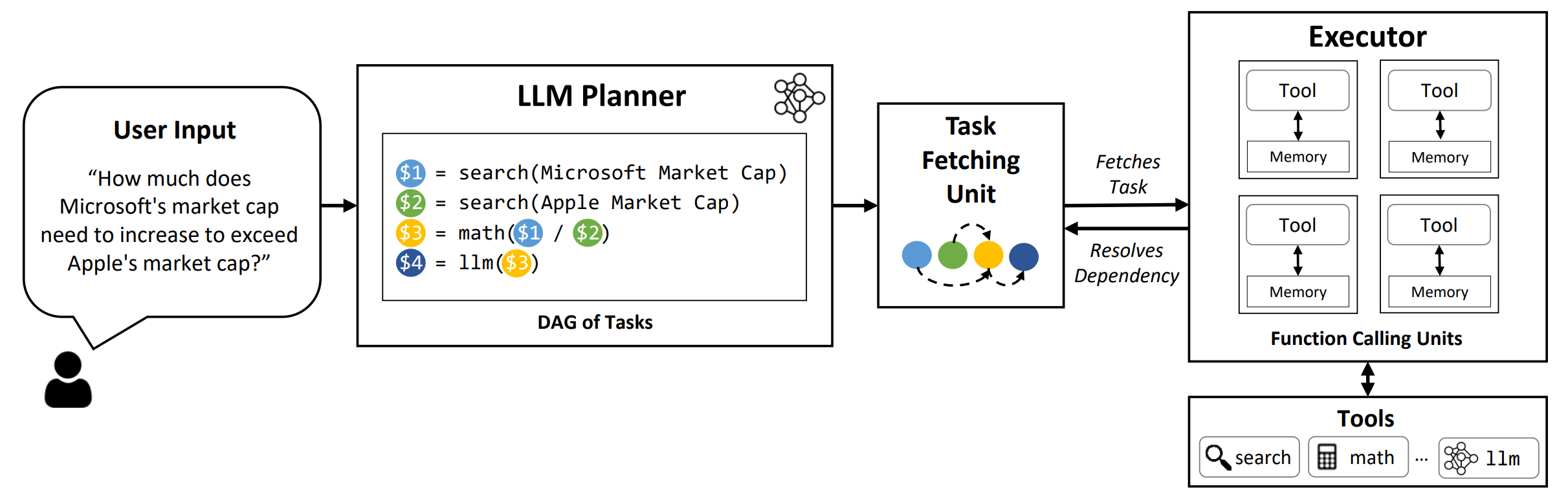
LLMCompiler adalah kerangka kerja yang memungkinkan orkestrasi fungsi paralel yang efisien dan efektif panggilan dengan LLM, termasuk model open-source dan source, dengan mengidentifikasi tugas mana yang dapat dilakukan secara paralel dan mana yang saling bergantung.
TL; DR: Kemampuan penalaran LLM memungkinkan mereka untuk melakukan beberapa panggilan fungsi, menggunakan fungsi yang disediakan pengguna untuk mengatasi keterbatasan yang melekat (misalnya cutoff pengetahuan, keterampilan aritmatika yang buruk, atau kurangnya akses ke data pribadi). Sementara panggilan multi-fungsi memungkinkan mereka untuk mengatasi masalah yang lebih kompleks, metode saat ini sering membutuhkan penalaran dan akting berurutan untuk setiap fungsi yang dapat mengakibatkan latensi tinggi, biaya, dan kadang-kadang perilaku yang tidak akurat. LLMCompiler membahas hal ini dengan menguraikan masalah menjadi beberapa tugas yang dapat dieksekusi secara paralel, dengan demikian secara efisien mengatur panggilan multi-fungsi. Dengan LLMCompiler, pengguna menentukan alat bersama dengan contoh in-context opsional, dan LLMCompiler secara otomatis menghitung orkestrasi yang dioptimalkan untuk panggilan fungsi . LLMCompiler dapat digunakan dengan model open-source seperti LLAMA, serta model GPT Openai. Di berbagai tugas yang menunjukkan pola panggilan fungsi paralel yang berbeda, llmCompiler secara konsisten menunjukkan latensi speedup, penghematan biaya, dan peningkatan akurasi . Untuk detail lebih lanjut, silakan lihat kertas kami.
conda create --name llmcompiler python=3.10 -y
conda activate llmcompiler
git clone https://github.com/SqueezeAILab/LLMCompiler
cd LLMCompiler
pip install -r requirements.txt
Untuk mereproduksi hasil evaluasi di koran, jalankan perintah berikut. Anda harus terlebih dahulu mendaftarkan kunci API OpenAI Anda ke lingkungan: export OPENAI_API_KEY="sk-xxx"
python run_llm_compiler.py --benchmark {benchmark-name} --store {store-path} [--logging] [--stream]
Untuk menjalankan model khusus yang dilayani menggunakan kerangka kerja VLLM, jalankan perintah berikut. Instruksi terperinci untuk melayani model khusus dengan kerangka kerja VLLM dapat ditemukan dalam dokumentasi VLLM. Perhatikan bahwa prompt yang telah ditentukan sebelumnya dalam file konfigurasi default dirancang untuk (non-Chat) LLAMA-2 70B dan mungkin memerlukan penyesuaian untuk model yang berbeda.
python run_llm_compiler.py --model_type vllm --benchmark {benchmark-name} --store {store-path} --model_name {vllm-model-name} --vllm_port {vllm-port} [--logging]
--benchmark : Nama Benchmark. Gunakan hotpotqa , movie , dan parallelqa untuk mengevaluasi llmcompiler di hotpotqa, rekomendasi film, dan tolok ukur paralelqa, masing -masing.--store : Path untuk menyimpan hasilnya. Pertanyaan, label sejati, prediksi, dan latensi per contoh akan disimpan dalam format JSON.--logging : (Opsional) Mengaktifkan logging. Belum didukung untuk VLLM.--do_benchmark : (Opsional) Lakukan pembandingan tambahan pada statistik run-time terperinci.--stream : (Opsional, Disarankan) Mengaktifkan streaming. Ini meningkatkan latensi dengan mengalirkan tugas -tugas dari perencana ke unit pengambilan tugas dan pelaksana segera setelah generasi mereka, daripada memblokir pelaksana sampai semua tugas dihasilkan dari perencana.--react : (Opsional) Gunakan reaksi alih-alih llmcompiler untuk evaluasi dasar. Anda secara opsional dapat menggunakan titik akhir Azure Anda alih -alih titik akhir openai dengan --model_type azure . Dalam hal ini, Anda perlu memberikan konfigurasi Azure terkait sebagai bidang berikut di lingkungan Anda: AZURE_ENDPOINT , AZURE_OPENAI_API_VERSION , AZURE_DEPLOYMENT_NAME , dan AZURE_OPENAI_API_KEY .
Anda dapat menggunakan titik akhir friendli dengan --model_type friendli . Dalam hal ini, Anda perlu memberikan kunci API Friendli di lingkungan Anda: FRIENDLI_TOKEN . Selain itu, Anda perlu menginstal klien friendli:
pip install friendli-client
Setelah menjalankan selesai, Anda bisa mendapatkan ringkasan hasil dengan menjalankan perintah berikut:
python evaluate_results.py --file {store-path}
Untuk menggunakan LLMCompiler pada tolok ukur khusus Anda atau menggunakan kasing, Anda hanya perlu memberikan fungsi dan deskripsi mereka, serta contoh prompt. Silakan merujuk ke configs/hotpotqa , configs/movie , dan configs/parallelqa sebagai contoh.
gpt_prompts.py : mendefinisikan contoh in-context prompttools.py : mendefinisikan fungsi (yaitu alat) untuk digunakan, dan deskripsi mereka (yaitu instruksi dan argumen) Kami berencana untuk segera memperbarui fitur -fitur berikut:
LLMCompiler telah dikembangkan sebagai bagian dari makalah berikut. Kami menghargainya jika Anda mau mengutip makalah berikut jika Anda menemukan perpustakaan berguna untuk pekerjaan Anda:
@article{kim2023llmcompiler,
title={An LLM Compiler for Parallel Function Calling},
author={Kim, Sehoon and Moon, Suhong and Tabrizi, Ryan and Lee, Nicholas and Mahoney, Michael and Keutzer, Kurt and Gholami, Amir},
journal={arXiv},
year={2023}
}


