LLMCompiler
1.0.0
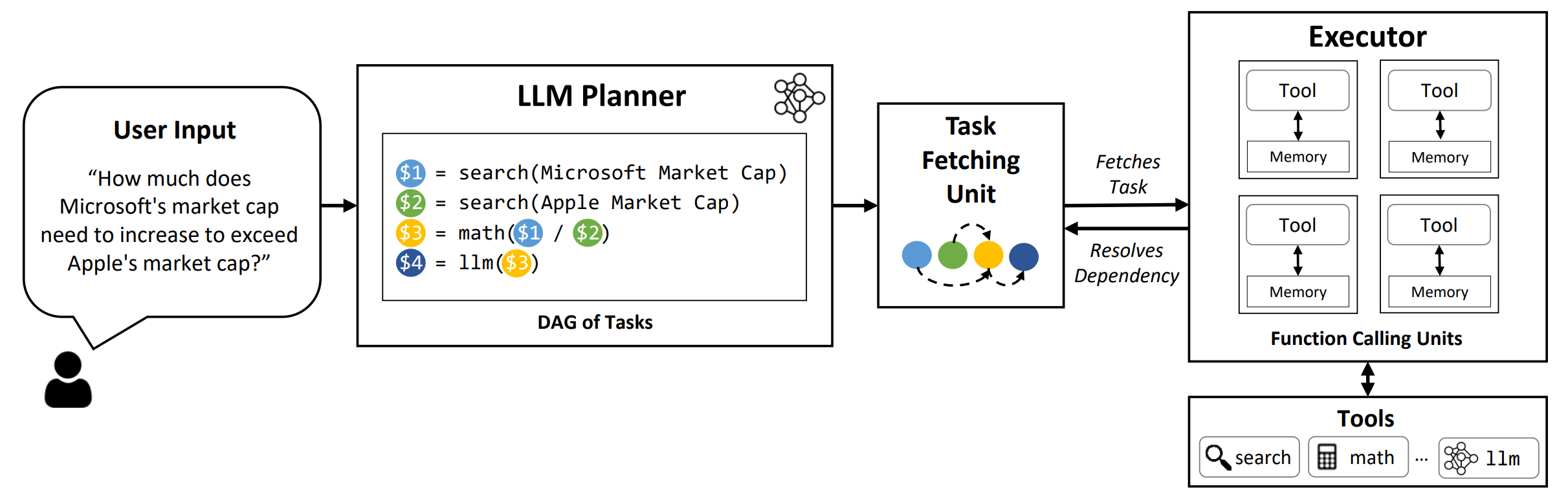
LLMCompiler ist ein Framework, das eine effiziente und effektive Orchestrierung paralleler Funktionen mit LLMs ermöglicht, einschließlich Modellen für Open-Source- und Close-Source, indem automatisch festgestellt wird, welche Aufgaben parallel ausgeführt werden können und welche voneinander abhängig sind.
TL; DR: Die Argumentationsfunktionen von LLMs ermöglichen es ihnen, mehrere Funktionsaufrufe auszuführen, wobei benutzerbereitete Funktionen verwendet werden, um ihre inhärenten Einschränkungen zu überwinden (z. Während Multifunktionsaufruf es ihnen ermöglicht, komplexere Probleme anzugehen, erfordern aktuellere Methoden häufig ein sequentielles Denken und das Handeln für jede Funktion, die zu hoher Latenz, Kosten und manchmal ungenauen Verhaltensweisen führen kann. LLMCompiler befasst sich damit, dass Probleme in mehrere Aufgaben zerlegt werden, die parallel ausgeführt werden können, wodurch die Multifunktionsanrufe effizient orchestriert. Mit LLMCompiler gibt der Benutzer die Tools zusammen mit optionalen In-Kontext-Beispielen an, und LLMCompiler berechnet automatisch eine optimierte Orchestrierung für die Funktionsaufrufe . LLMCompiler kann mit Open-Source-Modellen wie Lama sowie OpenAI-GPT-Modellen verwendet werden. In einer Reihe von Aufgaben, die unterschiedliche Muster paralleler Funktionen aufweisen, zeigten LLMCompiler die Latenz -Beschleunigung, Kosteneinsparung und Genauigkeitsverbesserung . Weitere Informationen finden Sie in unserem Papier.
conda create --name llmcompiler python=3.10 -y
conda activate llmcompiler
git clone https://github.com/SqueezeAILab/LLMCompiler
cd LLMCompiler
pip install -r requirements.txt
Führen Sie den folgenden Befehl aus, um die Bewertungsergebnisse im Papier zu reproduzieren. Sie müssen zuerst Ihren OpenAI-API-Schlüssel in der Umgebung registrieren: export OPENAI_API_KEY="sk-xxx"
python run_llm_compiler.py --benchmark {benchmark-name} --store {store-path} [--logging] [--stream]
Führen Sie den folgenden Befehl aus. Detaillierte Anweisungen zum Servieren von benutzerdefinierten Modellen mit dem VLLM -Framework finden Sie in der VLLM -Dokumentation. Beachten Sie, dass die vordefinierten Eingabeaufforderungen in den Standardkonfigurationsdateien auf (Nicht-Chat-) LLAMA-2 70B zugeschnitten sind und möglicherweise Anpassungen für verschiedene Modelle erfordern.
python run_llm_compiler.py --model_type vllm --benchmark {benchmark-name} --store {store-path} --model_name {vllm-model-name} --vllm_port {vllm-port} [--logging]
--benchmark : Benchmark-Name. Verwenden Sie hotpotqa , movie und parallelqa , um LLMCompiler auf die Hotpotqa, Filmempfehlung bzw. Parallelqa -Benchmarks zu bewerten.--store : Pfad, um das Ergebnis zu speichern. Frage, echte Etikett, Vorhersage und Latenz pro Beispiel werden in einem JSON -Format gespeichert.--logging : (Optional) Ermöglicht die Protokollierung. Noch nicht für vllm unterstützt.--do_benchmark : (optional) Führen Sie zusätzliche Benchmarking für detaillierte Laufzeitstatistiken durch.--stream : (optional, empfohlen) Ermöglicht das Streaming. Es verbessert die Latenz, indem sie Aufgaben vom Planer auf die Aufgabe abrufen, unmittelbar nach seiner Generation abzuholen, anstatt den Testamentsvollstrecker zu blockieren, bis alle Aufgaben vom Planer generiert werden.--react : (optional) Verwenden Sie React anstelle von llmCompiler zur Basisbewertung. Sie können optional Ihren Azure -Endpunkt anstelle des OpenAI -Endpunkts mit --model_type azure verwenden. In diesem Fall müssen Sie die zugehörige Azure -Konfiguration als folgende Felder in Ihrer Umgebung bereitstellen: AZURE_ENDPOINT , AZURE_OPENAI_API_VERSION , AZURE_DEPLOYMENT_NAME und AZURE_OPENAI_API_KEY .
Sie können den Friendli -Endpunkt mit --model_type friendli verwenden. In diesem Fall müssen Sie in Ihrer Umgebung einen Freund der Friendli -API angeben: FRIENDLI_TOKEN . Zusätzlich müssen Sie den Freund des Frientli -Clients installieren:
pip install friendli-client
Nachdem der Lauf vorbei ist, können Sie die Zusammenfassung der Ergebnisse erhalten, indem Sie den folgenden Befehl ausführen:
python evaluate_results.py --file {store-path}
Um LLMCompiler für Ihre benutzerdefinierten Benchmarks oder Anwendungsfälle zu verwenden, müssen Sie nur die Funktionen und deren Beschreibungen sowie beispielsweise Eingabeaufforderungen bereitstellen. Weitere Informationen finden Sie in configs/hotpotqa , configs/movie und configs/parallelqa als Beispiele.
gpt_prompts.py : Definiert Beispielaufforderungen in Kontexttools.py : Definiert Funktionen (dh Tools) und deren Beschreibungen (dh Anweisungen und Argumente). Wir planen, bald die folgenden Funktionen zu aktualisieren:
LLMCompiler wurde als Teil des folgenden Papiers entwickelt. Wir schätzen es, wenn Sie bitte das folgende Papier zitieren würden, wenn Sie die Bibliothek für Ihre Arbeit nützlich fanden:
@article{kim2023llmcompiler,
title={An LLM Compiler for Parallel Function Calling},
author={Kim, Sehoon and Moon, Suhong and Tabrizi, Ryan and Lee, Nicholas and Mahoney, Michael and Keutzer, Kurt and Gholami, Amir},
journal={arXiv},
year={2023}
}


