LLMCompiler
1.0.0
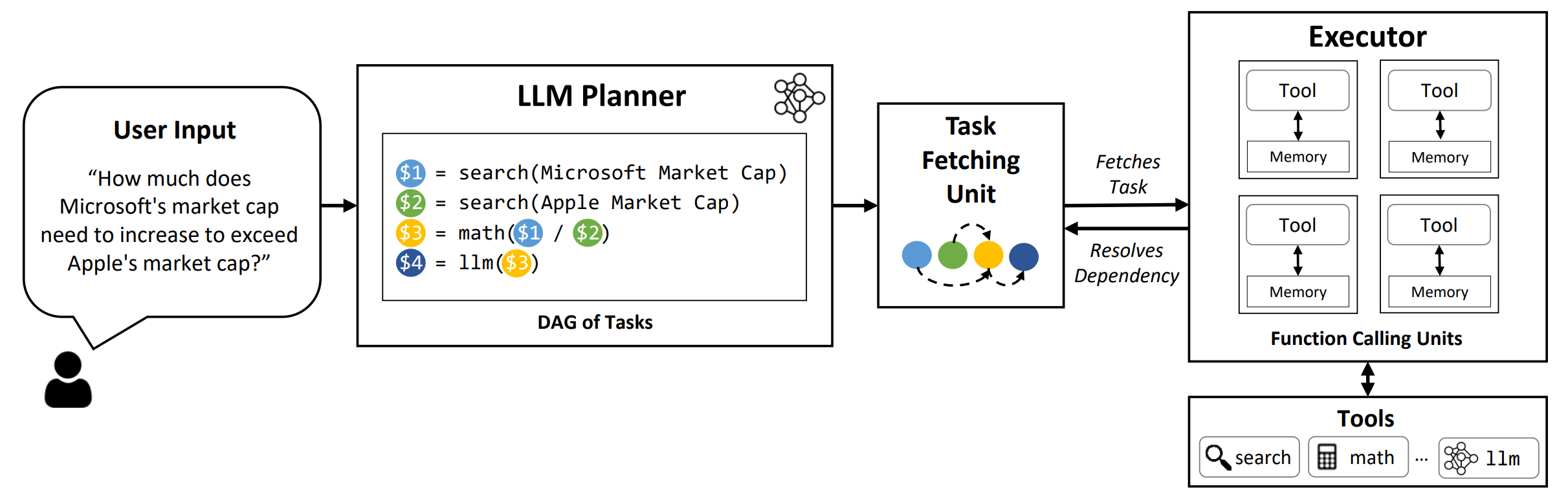
LLMCOMPILER هو إطار يتيح تزامنًا فعالًا وفعالًا لدعوة الوظائف المتوازية مع LLMS ، بما في ذلك كل من النماذج المفتوحة المصدر والمصادر القريبة ، من خلال تحديد المهام التي يمكن تنفيذها بشكل متوازي وتلك التي تعتمد.
TL ؛ DR: تمكنهم إمكانيات التفكير في LLMs من تنفيذ مكالمات وظائف متعددة ، باستخدام وظائف مقدمة من المستخدم للتغلب على قيودهم المتأصلة (مثل قطع المعرفة ، أو مهارات الحساب الضعيفة ، أو عدم الوصول إلى البيانات الخاصة). على الرغم من أن الاتصال متعدد الوظائف يتيح لهم معالجة مشاكل أكثر تعقيدًا ، فإن الطرق الحالية غالبًا ما تتطلب التفكير والتمثيل المتسلسل لكل وظيفة يمكن أن تؤدي إلى زمن استمرار وتكلفة وسلوك غير دقيق في بعض الأحيان. يعالج LLMCOMPILER هذا من خلال تحلل المشكلات إلى مهام متعددة يمكن تنفيذها بالتوازي ، وبالتالي تنظيم استدعاء متعدد الوظائف بكفاءة. مع LLMCOMPILER ، يحدد المستخدم الأدوات جنبًا إلى جنب مع أمثلة اختيارية داخل السياق ، ويحسب LLMCOMPILER تلقائيًا تزامنًا محسّنًا لمكالمات الوظائف . يمكن استخدام LLMCOMPILER مع نماذج مفتوحة المصدر مثل LLAMA ، وكذلك نماذج GPT من Openai. عبر مجموعة من المهام التي تظهر أنماطًا مختلفة من استدعاء الوظائف المتوازية ، أظهرت LLMCompiler باستمرار تسريع الكمون وتوفير التكاليف وتحسين الدقة . لمزيد من التفاصيل ، يرجى مراجعة ورقتنا.
conda create --name llmcompiler python=3.10 -y
conda activate llmcompiler
git clone https://github.com/SqueezeAILab/LLMCompiler
cd LLMCompiler
pip install -r requirements.txt
لإعادة إنتاج نتائج التقييم في الورقة ، قم بتشغيل الأمر التالي. تحتاج أولاً إلى تسجيل مفتاح Openai API الخاص بك في البيئة: export OPENAI_API_KEY="sk-xxx"
python run_llm_compiler.py --benchmark {benchmark-name} --store {store-path} [--logging] [--stream]
لتشغيل نماذج مخصصة يتم تقديمها باستخدام إطار VLLM ، قم بتشغيل الأمر التالي. يمكن العثور على إرشادات مفصلة لخدمة النماذج المخصصة مع إطار VLLM في وثائق VLLM. لاحظ أن المطالبات المحددة مسبقًا في ملفات التكوين الافتراضية مصممة خصيصًا (غير) LLAMA-2 70B وقد تحتاج إلى تعديلات لنماذج مختلفة.
python run_llm_compiler.py --model_type vllm --benchmark {benchmark-name} --store {store-path} --model_name {vllm-model-name} --vllm_port {vllm-port} [--logging]
--benchmark : الاسم القياسي. استخدم hotpotqa ، movie ، و parallelqa لتقييم LLMCompiler على Hotpotqa ، توصية الفيلم ، ومعايير ParallelQA ، على التوالي.--store : مسار لحفظ النتيجة. سيتم تخزين السؤال والتسمية الحقيقية والتنبؤ والكمون لكل مثال بتنسيق JSON.--logging : (اختياري) يتيح التسجيل. لم تدعم بعد لـ VLLM.--do_benchmark : (اختياري) قم بتقييم إضافي على إحصائيات وقت تشغيل مفصلة.--stream : (اختياري ، موصى به) يتيح البث. إنه يحسن الكمون عن طريق دفق المهام من المخطط إلى وحدة جلب المهمة والمنفذ مباشرة بعد توليدها ، بدلاً من منع المنفذ حتى يتم إنشاء جميع المهام من المخطط.--react : (اختياري) استخدم React بدلاً من LLMCOMPILER لتقييم خط الأساس. يمكنك اختياريا استخدام نقطة نهاية Azure بدلاً من نقطة نهاية Openai مع --model_type azure . في هذه الحالة ، تحتاج إلى توفير تكوين Azure المرتبط باعتباره الحقول التالية في بيئتك: AZURE_ENDPOINT ، AZURE_OPENAI_API_VERSION ، AZURE_DEPLOYMENT_NAME ، و AZURE_OPENAI_API_KEY .
يمكنك استخدام نقطة نهاية Friendli مع --model_type friendli . في هذه الحالة ، تحتاج إلى توفير مفتاح واجهة برمجة تطبيقات Friendli في بيئتك: FRIENDLI_TOKEN . بالإضافة إلى ذلك ، تحتاج إلى تثبيت عميل Friendli:
pip install friendli-client
بعد انتهاء التشغيل ، يمكنك الحصول على ملخص النتائج عن طريق تشغيل الأمر التالي:
python evaluate_results.py --file {store-path}
لاستخدام LLMCOMPILER على معاييرك المخصصة أو الحالات ، تحتاج فقط إلى توفير الوظائف وأوصافها ، بالإضافة إلى مطالبات مثال. يرجى الرجوع إلى configs/hotpotqa ، configs/movie ، configs/parallelqa كأمثلة.
gpt_prompts.py : يحدد مطالبات مثال في السياقtools.py : يحدد الوظائف (أي أدوات) للاستخدام ، وأوصافها (أي تعليمات وحجج) نخطط لتحديث الميزات التالية قريبًا:
تم تطوير LLMCOMPILER كجزء من الورقة التالية. نحن نقدر ذلك إذا كنت ستشير إلى الورقة التالية إذا وجدت المكتبة مفيدة لعملك:
@article{kim2023llmcompiler,
title={An LLM Compiler for Parallel Function Calling},
author={Kim, Sehoon and Moon, Suhong and Tabrizi, Ryan and Lee, Nicholas and Mahoney, Michael and Keutzer, Kurt and Gholami, Amir},
journal={arXiv},
year={2023}
}


