LLMCompiler
1.0.0
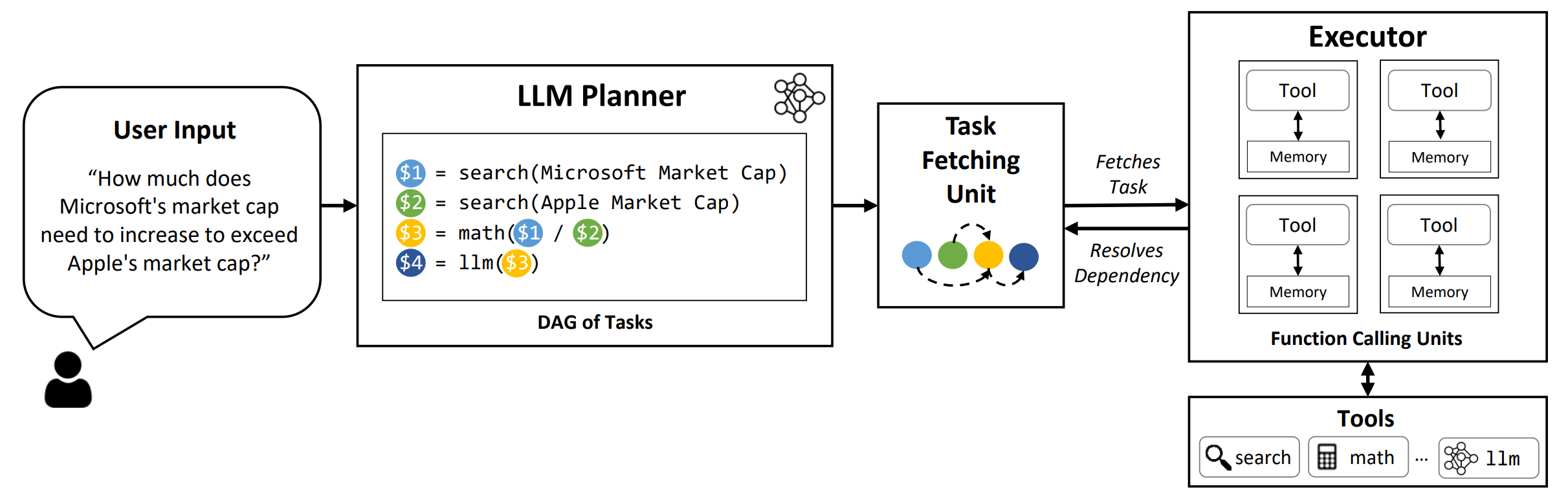
LLMCompilerは、オープンソースモデルとクローズソースモデルの両方を含むLLMとの並列関数呼び出しの効率的かつ効果的なオーケストレーションを可能にするフレームワークであり、どのタスクを並行して実行できるか、どのタスクが相互依存しているかを自動的に識別します。
TL; DR: LLMの推論機能により、ユーザーが提供する機能を使用して固有の制限(知識のカットオフ、算術スキルの低下、またはプライベートデータへのアクセスの欠如)を克服して、複数の関数呼び出しを実行できます。多機能呼び出しにより、より複雑な問題に取り組むことができますが、現在の方法では、各関数の連続的な推論と作用が必要になることが多く、それは高い遅延、コスト、時には不正確な動作をもたらす可能性があります。 LLMCompilerは、問題を並行して実行できる複数のタスクに分解し、多機能呼び出しを効率的に調整することにより、これに対処します。 LLMCompilerを使用すると、ユーザーはツールをオプションのコンテキスト内の例とともに指定し、 LLMCompilerは関数呼び出しの最適化されたオーケストレーションを自動的に計算します。 LLMCompilerは、LlamaなどのオープンソースモデルとOpenaiのGPTモデルで使用できます。並列関数呼び出しの異なるパターンを示すさまざまなタスクにわたって、LLMCompilerは一貫してレイテンシスピードアップ、コスト節約、精度の改善を実証しました。詳細については、論文をご覧ください。
conda create --name llmcompiler python=3.10 -y
conda activate llmcompiler
git clone https://github.com/SqueezeAILab/LLMCompiler
cd LLMCompiler
pip install -r requirements.txt
評価結果を論文で再現するには、次のコマンドを実行します。最初にOpenAI APIキーを環境に登録する必要があります: export OPENAI_API_KEY="sk-xxx"
python run_llm_compiler.py --benchmark {benchmark-name} --store {store-path} [--logging] [--stream]
VLLMフレームワークを使用して提供されるカスタムモデルを実行するには、次のコマンドを実行します。 VLLMフレームワークでカスタムモデルを提供するための詳細な手順は、VLLMドキュメントに記載されています。デフォルトの構成ファイルの事前に定義されたプロンプトは、(非チャット)llama-2 70bに合わせて調整されており、異なるモデルの調整が必要になる場合があることに注意してください。
python run_llm_compiler.py --model_type vllm --benchmark {benchmark-name} --store {store-path} --model_name {vllm-model-name} --vllm_port {vllm-port} [--logging]
--benchmark :ベンチマーク名。 hotpotqa 、 movie 、およびparallelqaを使用して、それぞれHotpotqa、映画の推奨、ParallelqaベンチマークでLLMCompilerを評価します。--store :結果を保存するパス。質問、真のラベル、予測、および例あたりの遅延は、JSON形式に保存されます。--logging :(オプション)ロギングを有効にします。 Vllmのサポートはまだサポートされていません。--do_benchmark :(オプション)詳細な実行時間統計で追加のベンチマークを行います。--stream :(オプション、推奨)を有効にします。プランナーからすべてのタスクが生成されるまで執行者をブロックするのではなく、プランナーからタスクフェッチユニットとエグゼキューターへのタスクをストリーミングすることにより、レイテンシを改善します。--react :(オプション)ベースライン評価のためにLLMCompilerの代わりにReactを使用します。--model_type azureを使用して、Openaiエンドポイントの代わりにAzureエンドポイントをオプションで使用できます。この場合、関連するAzure構成を環境の次のフィールドとして提供する必要があります: AZURE_ENDPOINT 、 AZURE_OPENAI_API_VERSION 、 AZURE_DEPLOYMENT_NAME 、 AZURE_OPENAI_API_KEY 。
--model_type friendliを使用して、friendli endpointを使用できます。この場合、環境でFriendli APIキーを提供する必要があります: FRIENDLI_TOKEN 。さらに、Friendliクライアントをインストールする必要があります。
pip install friendli-client
実行が終了した後、次のコマンドを実行することにより、結果の要約を取得できます。
python evaluate_results.py --file {store-path}
カスタムベンチマークまたはユースケースでLLMCompilerを使用するには、機能とその説明を提供するだけでなく、プロンプトの例のみを提供する必要があります。 configs/hotpotqa 、 configs/movie 、およびconfigs/parallelqaを例として参照してください。
gpt_prompts.py :コンテキスト内の例のプロンプトを定義しますtools.py :使用する関数(つまりツール)とその説明(つまり、指示と引数)を定義します次の機能をまもなく更新する予定です。
LLMCompilerは、次の論文の一部として開発されました。あなたがあなたの仕事に役立つライブラリを見つけたなら、あなたが次の論文を引用してください。
@article{kim2023llmcompiler,
title={An LLM Compiler for Parallel Function Calling},
author={Kim, Sehoon and Moon, Suhong and Tabrizi, Ryan and Lee, Nicholas and Mahoney, Michael and Keutzer, Kurt and Gholami, Amir},
journal={arXiv},
year={2023}
}


