LLMCompiler
1.0.0
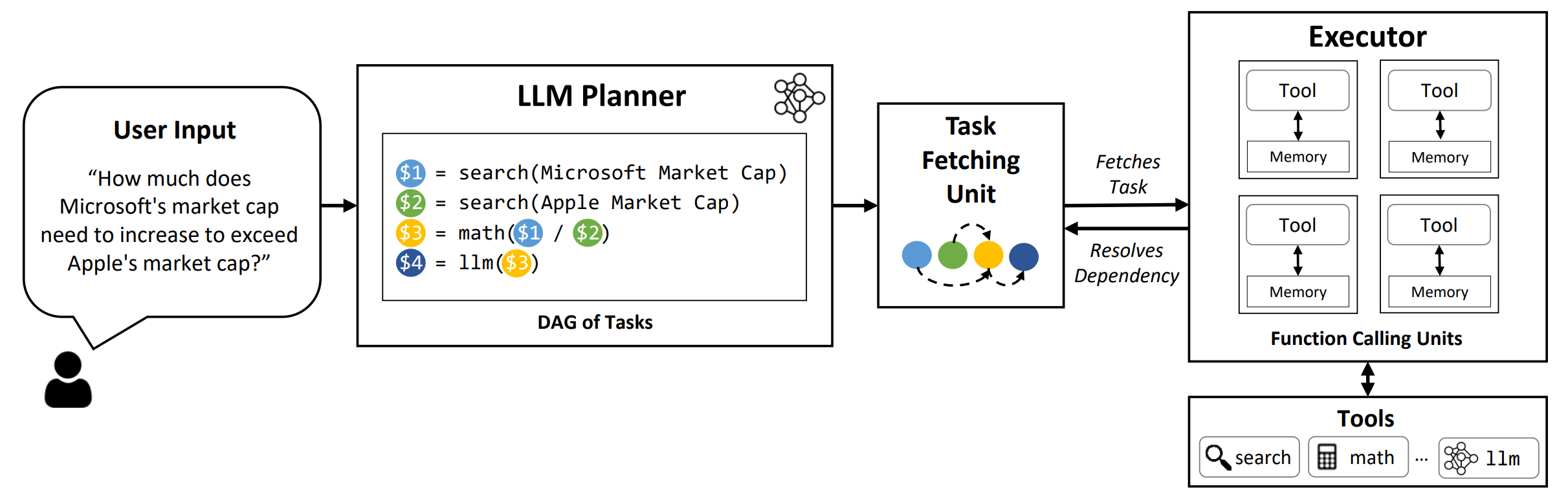
LLMCompiler es un marco que permite una orquestación eficiente y efectiva de la función paralela que llama con LLM, incluidos los modelos de código abierto y de código cerrado, identificando automáticamente qué tareas se pueden realizar en paralelo y cuáles son interdependientes.
TL; DR: Las capacidades de razonamiento de los LLM les permiten ejecutar múltiples llamadas de funciones, utilizando funciones proporcionadas por el usuario para superar sus limitaciones inherentes (por ejemplo, recortes de conocimiento, habilidades aritméticas pobres o falta de acceso a datos privados). Si bien la llamada multifunción les permite abordar problemas más complejos, los métodos actuales a menudo requieren razonamiento secuencial y actuación para cada función que puede dar como resultado un comportamiento de alta latencia, costo y, a veces, inexacto. LLMCompiler aborda esto mediante la descomposición de problemas en múltiples tareas que se pueden ejecutar en paralelo, organizando así eficientemente las llamadas multifunción. Con LLMCompiler, el usuario especifica las herramientas junto con ejemplos opcionales en contexto, y LLMCompiler calcula automáticamente una orquestación optimizada para las llamadas de funciones . LLMCompiler se puede usar con modelos de código abierto como LLAMA, así como los modelos GPT de OpenAI. En una variedad de tareas que exhiben diferentes patrones de llamadas de funciones paralelas, LLMCompiler demostró constantemente aceleración de latencia, ahorro de costos y mejora de la precisión . Para obtener más detalles, consulte nuestro documento.
conda create --name llmcompiler python=3.10 -y
conda activate llmcompiler
git clone https://github.com/SqueezeAILab/LLMCompiler
cd LLMCompiler
pip install -r requirements.txt
Para reproducir los resultados de la evaluación en el documento, ejecute el siguiente comando. Primero debe registrar su tecla API de OpenAI al entorno: export OPENAI_API_KEY="sk-xxx"
python run_llm_compiler.py --benchmark {benchmark-name} --store {store-path} [--logging] [--stream]
Para ejecutar un modelos personalizados servidos utilizando el marco VLLM, ejecute el siguiente comando. Las instrucciones detalladas para servir modelos personalizados con el marco VLLM se pueden encontrar en la documentación VLLM. Tenga en cuenta que las indicaciones predefinidas en los archivos de configuración predeterminados están adaptados para (no chat) LLAMA-2 70B y pueden necesitar ajustes para diferentes modelos.
python run_llm_compiler.py --model_type vllm --benchmark {benchmark-name} --store {store-path} --model_name {vllm-model-name} --vllm_port {vllm-port} [--logging]
--benchmark : nombre de referencia. Use hotpotqa , movie y parallelqa para evaluar LLMCompiler en Hotpotqa, recomendación de películas y puntos de referencia ParallElQA, respectivamente.--store : ruta para guardar el resultado. Pregunta, etiqueta verdadera, predicción y latencia por ejemplo se almacenará en formato JSON.--logging : (opcional) habilita el registro. Todavía no es compatible para VLLM.--do_benchmark : (Opcional) Realice evaluación comparativa adicional en estadísticas detalladas de tiempo de ejecución.--stream : (opcional, recomendado) Habilita la transmisión. Mejora la latencia transmitiendo las tareas del planificador a la unidad de recolección de tareas y al albacea inmediatamente después de su generación, en lugar de bloquear al albacea hasta que todas las tareas se generen desde el planificador.--react : (opcional) Use React en lugar de LLMCompiler para la evaluación de referencia. Opcionalmente, puede usar su punto final Azure en lugar de OpenAI Endpoint con --model_type azure . En este caso, debe proporcionar la configuración de Azure asociada como los siguientes campos en su entorno: AZURE_ENDPOINT , AZURE_OPENAI_API_VERSION , AZURE_DEPLOYMENT_NAME y AZURE_OPENAI_API_KEY .
Puedes usar el punto final de Friendli con --model_type friendli . En este caso, debe proporcionar una clave de API de FriendLi en su entorno: FRIENDLI_TOKEN . Además, debe instalar el cliente de FriendLi:
pip install friendli-client
Después de que termine la ejecución, puede obtener el resumen de los resultados ejecutando el siguiente comando:
python evaluate_results.py --file {store-path}
Para usar LLMCompiler en sus puntos de referencia o casos de uso personalizados, solo necesita proporcionar las funciones y sus descripciones, así como las indicaciones de ejemplo. Consulte configs/hotpotqa , configs/movie , y configs/parallelqa como ejemplos.
gpt_prompts.py : define las indicaciones de ejemplo de contextotools.py : Define las funciones (es decir, herramientas) para usar y sus descripciones (es decir, instrucciones y argumentos) Estamos planeando actualizar las siguientes funciones pronto:
LLMCompiler se ha desarrollado como parte del siguiente documento. Agradecemos si desea citar el siguiente documento si encontró la biblioteca útil para su trabajo:
@article{kim2023llmcompiler,
title={An LLM Compiler for Parallel Function Calling},
author={Kim, Sehoon and Moon, Suhong and Tabrizi, Ryan and Lee, Nicholas and Mahoney, Michael and Keutzer, Kurt and Gholami, Amir},
journal={arXiv},
year={2023}
}


