LLMCompiler
1.0.0
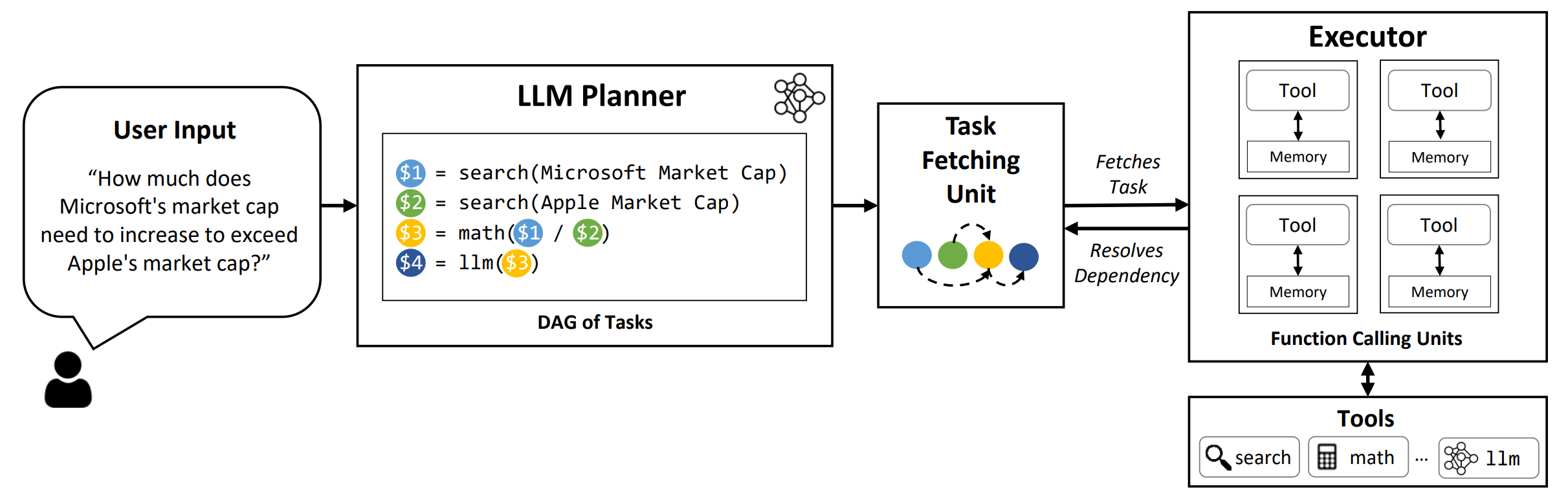
O LLMCompiler é uma estrutura que permite uma orquestração eficiente e eficaz da chamada de função paralela com os LLMs, incluindo modelos de código aberto e de fonte próxima, identificando automaticamente quais tarefas podem ser executadas em paralelo e quais são interdependentes.
TL; DR: Os recursos de raciocínio do LLMS permitem que eles executem várias chamadas de função, usando funções fornecidas pelo usuário para superar suas limitações inerentes (por exemplo, corte de conhecimento, más habilidades aritméticas ou falta de acesso a dados privados). Enquanto a chamada multifuncional permite que eles resolvam problemas mais complexos, os métodos atuais geralmente requerem raciocínio seqüencial e atuação para cada função que pode resultar em alta latência, custo e às vezes comportamento impreciso. O LLMCompiler aborda isso decompondo problemas em várias tarefas que podem ser executadas em paralelo, orquestrando com eficiência chamadas multifuncionais. Com o LLMCompiler, o usuário especifica as ferramentas junto com exemplos opcionais no contexto, e o LLMCompiler calcula automaticamente uma orquestração otimizada para as chamadas de função . O LLMCompiler pode ser usado com modelos de código aberto, como o LLAMA, bem como os modelos GPT da OpenAI. Em uma variedade de tarefas que exibem diferentes padrões de chamada de função paralela, o LLMCompiler demonstrou consistentemente aceleração de latência, economia de custos e melhoria da precisão . Para mais detalhes, consulte nosso artigo.
conda create --name llmcompiler python=3.10 -y
conda activate llmcompiler
git clone https://github.com/SqueezeAILab/LLMCompiler
cd LLMCompiler
pip install -r requirements.txt
Para reproduzir os resultados da avaliação no artigo, execute o seguinte comando. Você precisa primeiro registrar sua chave da API do OpenAI para o meio ambiente: export OPENAI_API_KEY="sk-xxx"
python run_llm_compiler.py --benchmark {benchmark-name} --store {store-path} [--logging] [--stream]
Para executar modelos personalizados servidos usando a estrutura VLLM, execute o seguinte comando. Instruções detalhadas para servir modelos personalizados com a estrutura VLLM podem ser encontrados na documentação VLLM. Observe que os avisos predefinidos nos arquivos de configuração padrão são adaptados para a llama-2 70B (não-chat) e podem precisar de ajustes para diferentes modelos.
python run_llm_compiler.py --model_type vllm --benchmark {benchmark-name} --store {store-path} --model_name {vllm-model-name} --vllm_port {vllm-port} [--logging]
--benchmark : Nome da referência. Use hotpotqa , movie e parallelqa para avaliar o LLMCompiler no Hotpotqa, recomendação de filmes e paralelqa Benchmarks, respectivamente.--store : caminho para salvar o resultado. Pergunta, rótulo verdadeiro, previsão e latência por exemplo serão armazenados em um formato JSON.--logging : (Opcional) Ativa o registro. Ainda não é apoiado para VLLM.--do_benchmark : (opcional) Faça benchmarking adicional em estatísticas detalhadas de tempo de execução.--stream : (opcional, recomendado) Ativa o streaming. Isso melhora a latência transmitindo tarefas do planejador para a unidade de busca de tarefas e executor imediatamente após sua geração, em vez de bloquear o executor até que todas as tarefas sejam geradas a partir do planejador.--react : (opcional) Use react em vez de llmcompiler para avaliação da linha de base. Opcionalmente, você pode usar seu terminal do Azure em vez do OpenAI final com --model_type azure . Nesse caso, você precisa fornecer a configuração do Azure associada como os seguintes campos em seu ambiente: AZURE_ENDPOINT , AZURE_OPENAI_API_VERSION , AZURE_DEPLOYMENT_NAME e AZURE_OPENAI_API_KEY .
Você pode usar o Friendli Endpoint com --model_type friendli . Nesse caso, você precisa fornecer a chave da API do FIRELI em seu ambiente: FRIENDLI_TOKEN . Além disso, você precisa instalar o cliente amigável:
pip install friendli-client
Após o término da corrida, você pode obter o resumo dos resultados executando o seguinte comando:
python evaluate_results.py --file {store-path}
Para usar o LLMCompiler em seus benchmarks ou casos de uso personalizados, você só precisa fornecer as funções e suas descrições, bem como avisos de exemplo. Consulte o configs/hotpotqa , configs/movie e configs/parallelqa como exemplos.
gpt_prompts.py : define exemplos de exemplo no contexto.tools.py : define funções (ou seja, ferramentas) a serem usadas e suas descrições (ou seja, instruções e argumentos) Estamos planejando atualizar os seguintes recursos em breve:
O LLMCompiler foi desenvolvido como parte do artigo a seguir. Agradecemos se você citar o seguinte artigo se achar a biblioteca útil para o seu trabalho:
@article{kim2023llmcompiler,
title={An LLM Compiler for Parallel Function Calling},
author={Kim, Sehoon and Moon, Suhong and Tabrizi, Ryan and Lee, Nicholas and Mahoney, Michael and Keutzer, Kurt and Gholami, Amir},
journal={arXiv},
year={2023}
}


