LLMCompiler
1.0.0
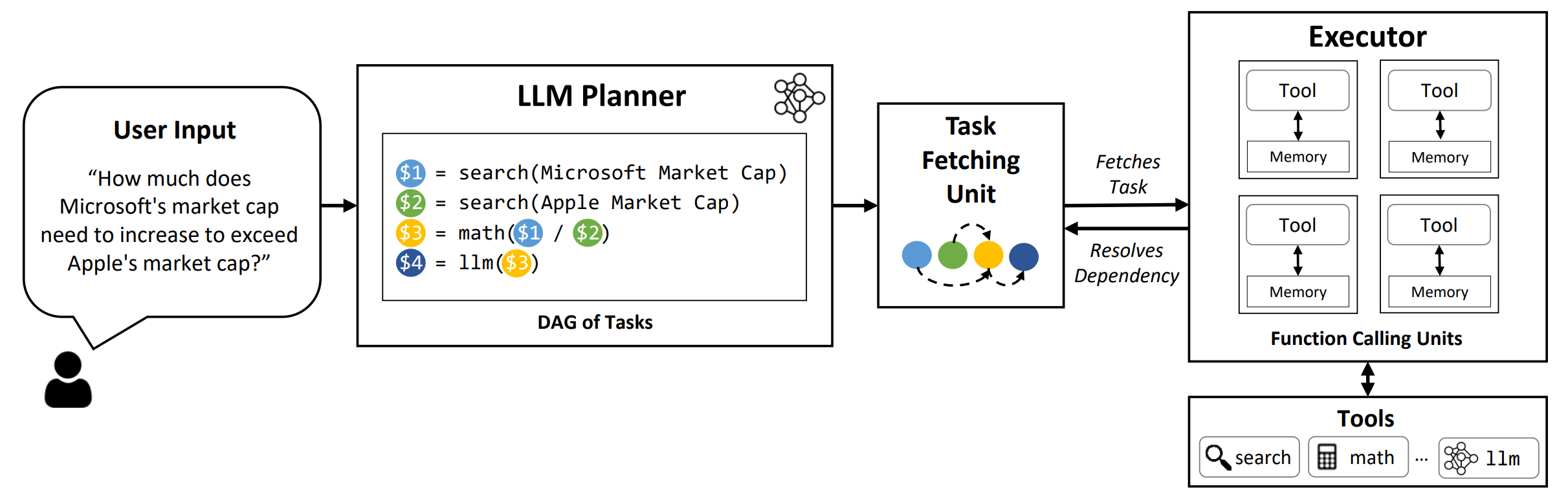
LLMCompiler -это структура, которая обеспечивает эффективную и эффективную оркестровку параллельной функции вызова с помощью LLMS, включая как модели с открытым исходным кодом, так и модели с закрытым исходным кодом, путем автоматического определения того, какие задачи могут выполняться параллельно, а какие взаимозависимы.
TL; DR: возможности рассуждения LLMS позволяют им выполнять несколько функциональных вызовов, используя предоставленные пользователем функции для преодоления их неотъемлемых ограничений (например, отсечение знаний, плохие навыки арифметики или отсутствие доступа к частным данным). В то время как многофункциональные вызовы позволяют им решать более сложные проблемы, текущие методы часто требуют последовательных рассуждений и действующих лиц для каждой функции, что может привести к высокой латентности, стоимости и иногда неточному поведению. LLMCompiler рассматривает это путем разложения проблем на несколько задач, которые можно выполнять параллельно, тем самым эффективно организуя многофункциональные вызова. С помощью LLMCompiler пользователь определяет инструменты вместе с дополнительными примерами в контексте, а LLMCompiler автоматически вычисляет оптимизированную оркестровку для вызовов функций . LLMCompiler можно использовать с такими моделями с открытым исходным кодом, как Llama, а также модели GPT Openai. В рамках ряда задач, которые демонстрируют различные модели вызова параллельных функций, LLMCompiler последовательно продемонстрировал ускорение задержки, экономию средств и повышение точности . Для получения более подробной информации, пожалуйста, ознакомьтесь с нашей газетой.
conda create --name llmcompiler python=3.10 -y
conda activate llmcompiler
git clone https://github.com/SqueezeAILab/LLMCompiler
cd LLMCompiler
pip install -r requirements.txt
Чтобы воспроизвести результаты оценки в статье, запустите следующую команду. Вам нужно сначала зарегистрировать свой ключ API OpenAI в среду: export OPENAI_API_KEY="sk-xxx"
python run_llm_compiler.py --benchmark {benchmark-name} --store {store-path} [--logging] [--stream]
Чтобы запустить пользовательские модели, обслуживаемые с помощью Framework VLLM, запустите следующую команду. Подробные инструкции по обслуживанию пользовательских моделей с структурой VLLM можно найти в документации VLLM. Обратите внимание, что предварительно определенные подсказки в файлах конфигурации по умолчанию адаптированы для (не-чат) Llama-2 70b и могут потребоваться корректировки для различных моделей.
python run_llm_compiler.py --model_type vllm --benchmark {benchmark-name} --store {store-path} --model_name {vllm-model-name} --vllm_port {vllm-port} [--logging]
--benchmark : эталонное название. Используйте hotpotqa , movie и parallelqa , чтобы оценить LLMCompiler на HotPotqa, рекомендации фильма и контрольных показателей Parallelqa, соответственно.--store : Путь к сохранению результата. Вопрос, истинный этикетка, прогноз и задержка за пример будут храниться в формате JSON.--logging : (необязательно) включает ведение журнала. Еще не поддерживается для VLLM.--do_benchmark : (Необязательно) Сделайте дополнительную анализу по подробной статистике времени выполнения.--stream : (необязательно, рекомендуется) включает потоковую передачу. Это улучшает задержку, выпуская задачи от планировщика до задачи, выбирая единицу и исполнителя сразу после их генерации, вместо того, чтобы блокировать исполнителя, пока все задачи не будут генерируются от планировщика.--react : (необязательно) Используйте React вместо LLMCompiler для базовой оценки. При желании вы можете использовать свою конечную точку Azure вместо конечной точки Openai с помощью --model_type azure . В этом случае вам необходимо предоставить связанную конфигурацию Azure в качестве следующих полей в вашей среде: AZURE_ENDPOINT , AZURE_OPENAI_API_VERSION , AZURE_DEPLOYMENT_NAME и AZURE_OPENAI_API_KEY .
Вы можете использовать конечную точку Friendli с --model_type friendli . В этом случае вам нужно предоставить ключ API Prowithli в вашей среде: FRIENDLI_TOKEN . Кроме того, вам нужно установить клиент Friendli:
pip install friendli-client
После окончания пробега вы можете получить сводку результатов, выполнив следующую команду:
python evaluate_results.py --file {store-path}
Чтобы использовать LLMCompiler на ваших пользовательских критериях или вариантах использования, вам необходимо только предоставить функции и их описания, а также примеры. Пожалуйста, обратитесь к configs/hotpotqa , configs/movie и configs/parallelqa в качестве примеров.
gpt_prompts.py : определяет встроенные примеры подсказкиtools.py . Мы планируем в ближайшее время обновить следующие функции:
LLMCompiler был разработан в рамках следующей статьи. Мы ценим это, если вы, пожалуйста, процитируйте следующую статью, если вы нашли библиотеку полезной для вашей работы:
@article{kim2023llmcompiler,
title={An LLM Compiler for Parallel Function Calling},
author={Kim, Sehoon and Moon, Suhong and Tabrizi, Ryan and Lee, Nicholas and Mahoney, Michael and Keutzer, Kurt and Gholami, Amir},
journal={arXiv},
year={2023}
}


