LLMCompiler
1.0.0
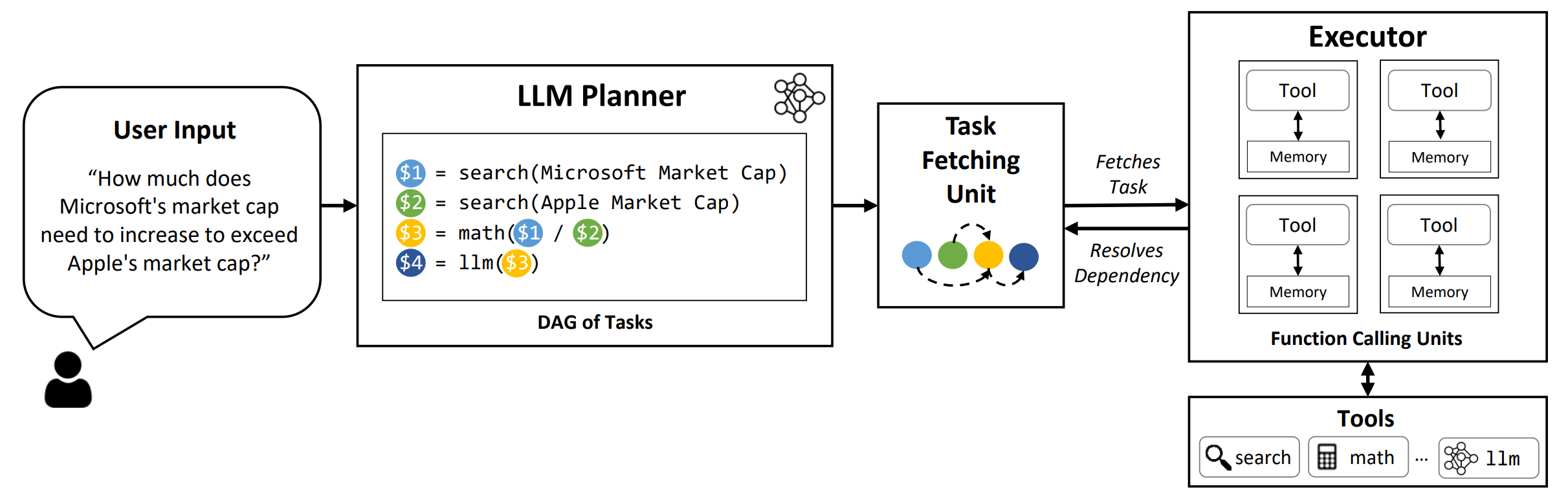
LLMCompiler est un cadre qui permet une orchestration efficace et efficace de la fonction parallèle appelant avec des LLM, y compris les modèles open-source et proches, en identifiant automatiquement quelles tâches peuvent être effectuées en parallèle et celles interdépendantes.
TL; DR: Les capacités de raisonnement des LLM leur permettent d'exécuter plusieurs appels de fonction, en utilisant des fonctions fournies par l'utilisateur pour surmonter leurs limitations inhérentes (par exemple, les coupures de connaissances, les compétences arithmétiques médiocres ou le manque d'accès aux données privées). Bien que les appels multi-fonctions leur permettent de résoudre des problèmes plus complexes, les méthodes actuelles nécessitent souvent un raisonnement séquentiel et un agissant pour chaque fonction qui peut entraîner une latence élevée, un coût et parfois un comportement inexact. LLMCompiler aborde cela en décomposant les problèmes en plusieurs tâches qui peuvent être exécutées en parallèle, orchestrant ainsi efficacement les appels multi-fonctions. Avec LLMCompiler, l'utilisateur spécifie les outils ainsi que des exemples facultatifs dans le contexte, et LLMCompiler calcule automatiquement une orchestration optimisée pour les appels de fonction . LLMCompiler peut être utilisé avec des modèles open source tels que LLAMA, ainsi que les modèles GPT d'OpenAI. À travers une gamme de tâches qui présentent différents modèles d'appels de fonctions parallèles, LLMCompiler a constamment démontré une accélération de latence, une économie de coûts et une amélioration de la précision . Pour plus de détails, veuillez consulter notre article.
conda create --name llmcompiler python=3.10 -y
conda activate llmcompiler
git clone https://github.com/SqueezeAILab/LLMCompiler
cd LLMCompiler
pip install -r requirements.txt
Pour reproduire les résultats de l'évaluation dans le papier, exécutez la commande suivante. Vous devez d'abord enregistrer votre touche API OpenAI à l'environnement: export OPENAI_API_KEY="sk-xxx"
python run_llm_compiler.py --benchmark {benchmark-name} --store {store-path} [--logging] [--stream]
Pour exécuter un modèle personnalisé servi à l'aide du framework VLLM, exécutez la commande suivante. Des instructions détaillées pour servir des modèles personnalisés avec le cadre VLLM peuvent être trouvées dans la documentation VLLM. Notez que les invites prédéfinies dans les fichiers de configuration par défaut sont adaptées à (non chat) llama-2 70b et peuvent nécessiter des ajustements pour différents modèles.
python run_llm_compiler.py --model_type vllm --benchmark {benchmark-name} --store {store-path} --model_name {vllm-model-name} --vllm_port {vllm-port} [--logging]
--benchmark : Nom de référence. Utilisez hotpotqa , movie et parallelqa pour évaluer LLMCompiler sur le Hotpotqa, la recommandation de film et les repères parallelqa, respectivement.--store : chemin pour enregistrer le résultat. La question, la véritable étiquette, la prédiction et la latence par exemple seront stockées dans un format JSON.--logging : (facultatif) permet la journalisation. Pas encore pris en charge pour VLLM.--do_benchmark : (facultatif) Faire l'analyse comparative supplémentaire sur des statistiques d'exécution détaillées.--stream : (facultatif, recommandé) permet le streaming. Il améliore la latence en diffusant les tâches du planificateur à l'unité de récupération et à l'exécuteur de la tâche immédiatement après leur génération, plutôt que de bloquer l'exécuteur jusqu'à ce que toutes les tâches soient générées par le planificateur.--react : (facultatif) Utiliser React au lieu de LLMCompiler pour l'évaluation de base. Vous pouvez éventuellement utiliser votre point de terminaison Azure au lieu d'Openai Endpoint avec --model_type azure . Dans ce cas, vous devez fournir la configuration Azure associée comme les champs suivants dans votre environnement: AZURE_ENDPOINT , AZURE_OPENAI_API_VERSION , AZURE_DEPLOYMENT_NAME et AZURE_OPENAI_API_KEY .
Vous pouvez utiliser un point de terminaison Friendli avec --model_type friendli . Dans ce cas, vous devez fournir une clé API Friendli dans votre environnement: FRIENDLI_TOKEN . De plus, vous devez installer un client Amidli:
pip install friendli-client
Une fois l'exécution terminée, vous pouvez obtenir le résumé des résultats en exécutant la commande suivante:
python evaluate_results.py --file {store-path}
Pour utiliser LLMCompiler sur vos repères personnalisés ou vos cas d'utilisation, vous n'avez qu'à fournir les fonctions et leurs descriptions, ainsi que des invites d'exemples. Veuillez vous référer aux configs/hotpotqa , configs/movie et configs/parallelqa comme exemples.
gpt_prompts.py : définit les invites d'exemple en contextetools.py : définit les fonctions (c.-à-d. Les outils) à utiliser et leurs descriptions (c.-à-d. Instructions et arguments) Nous prévoyons de mettre à jour les fonctionnalités suivantes bientôt:
LLMCompiler a été développé dans le cadre du document suivant. Nous l'apprécions si vous veuillez citer le document suivant si vous trouviez la bibliothèque utile pour votre travail:
@article{kim2023llmcompiler,
title={An LLM Compiler for Parallel Function Calling},
author={Kim, Sehoon and Moon, Suhong and Tabrizi, Ryan and Lee, Nicholas and Mahoney, Michael and Keutzer, Kurt and Gholami, Amir},
journal={arXiv},
year={2023}
}


