ประนีประนอม

การประมวลผลภาษาธรรมชาติที่เรียบง่าย
npm install compromise
โดย Spencer Kelly และผู้มีส่วนร่วมหลายคน
ฝรั่งเศส•เยอรมัน•อิตาลี•สเปน
การประนีประนอม
พยายามอย่างเต็มที่ ที่จะเปลี่ยนข้อความเป็นข้อมูล
มันทำให้การตัดสินใจที่ จำกัด และสมเหตุสมผล
มันไม่ฉลาดเท่าที่คุณคิด
import nlp from 'compromise'
let doc = nlp ( 'she sells seashells by the seashore.' )
doc . verbs ( ) . toPastTense ( )
doc . text ( )
// 'she sold seashells by the seashore.'
อย่าแฟนซีเลย:
if ( doc . has ( 'simon says #Verb' ) ) {
return true
}
คว้าส่วนของข้อความ:
let doc = nlp ( entireNovel )
doc . match ( 'the #Adjective of times' ) . text ( )
// "the blurst of times?"
จับคู่เอกสาร
และรับข้อมูล:
import plg from 'compromise-speech'
nlp . extend ( plg )
let doc = nlp ( 'Milwaukee has certainly had its share of visitors..' )
doc . compute ( 'syllables' )
doc . places ( ) . json ( )
/*
[{
"text": "Milwaukee",
"terms": [{
"normal": "milwaukee",
"syllables": ["mil", "wau", "kee"]
}]
}]
*/ เอกสาร JSON
หลีกเลี่ยงปัญหาของตัวแยกวิเคราะห์ที่เปราะ:
let doc = nlp ( "we're not gonna take it.." )
doc . has ( 'gonna' ) // true
doc . has ( 'going to' ) // true (implicit)
// transform
doc . contractions ( ) . expand ( )
doc . text ( )
// 'we are not going to take it..'
เอกสารการหดตัว
และทำสิ่งต่าง ๆ รอบ ๆ เหมือนข้อมูล:
let doc = nlp ( 'ninety five thousand and fifty two' )
doc . numbers ( ) . add ( 20 )
doc . text ( )
// 'ninety five thousand and seventy two'
เอกสารหมายเลข
-เพราะมันเป็นจริง-
let doc = nlp ( 'the purple dinosaur' )
doc . nouns ( ) . toPlural ( )
doc . text ( )
// 'the purple dinosaurs'
เอกสารคำนาม
ใช้มันในฝั่งไคลเอ็นต์:
< script src =" https://unpkg.com/compromise " > </ script >
< script >
var doc = nlp ( 'two bottles of beer' )
doc . numbers ( ) . minus ( 1 )
document . body . innerHTML = doc . text ( )
// 'one bottle of beer'
</ script >
หรือเช่นเดียวกัน:
import nlp from 'compromise'
var doc = nlp ( 'London is calling' )
doc . verbs ( ) . toNegative ( )
// 'London is not calling'
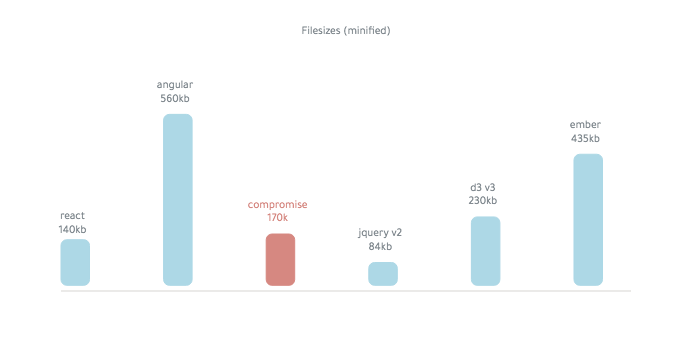
การประนีประนอมคือ ~ 250kB (minified):
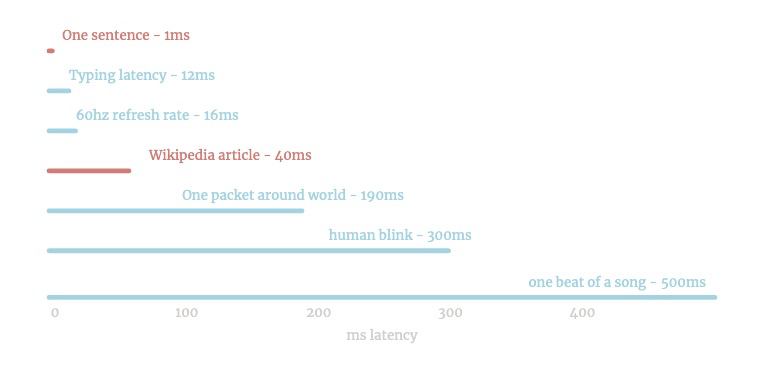
มันค่อนข้างเร็ว มันสามารถทำงานบน keypress:
มันทำงานเป็นหลักโดยการเชื่อมต่อทุกรูปแบบของรายการคำพื้นฐาน
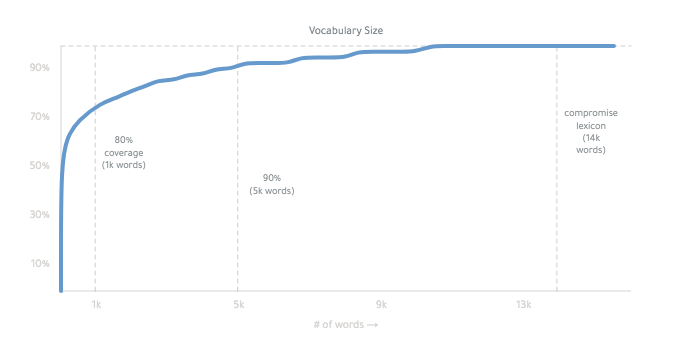
พจนานุกรมสุดท้ายคือ ~ 14,000 คำ:
คุณสามารถอ่านเพิ่มเติมเกี่ยวกับวิธีการทำงานที่นี่ มันแปลก
ตกลง -
compromise/one
tokenizer ของคำประโยคและเครื่องหมายวรรคตอน
import nlp from 'compromise/one'
let doc = nlp ( "Wayne's World, party time" )
let data = doc . json ( )
/* [{
normal:"wayne's world party time",
terms:[{ text: "Wayne's", normal: "wayne" },
...
]
}]
*/ เอกสาร Tokenizer
การประนีประนอม/หนึ่ง แยกข้อความของคุณขึ้นห่อด้วย API ที่มีประโยชน์
/หนึ่ง อย่างรวดเร็ว - ประโยคส่วนใหญ่ใช้เวลา 10 มิลลิวินาที
มันสามารถทำได้ ~ 1MB ของข้อความหน้าวินาที - หรือ 10 หน้าวิกิพีเดีย
Infinite Jest ใช้เวลา 3 วินาที
นอกจากนี้คุณยังสามารถขนานหรือสตรีมข้อความด้วยการประนีประนอมความเร็ว
compromise/two
Tagger part-of-speech และไวยากรณ์ interpreter
import nlp from 'compromise/two'
let doc = nlp ( "Wayne's World, party time" )
let str = doc . match ( '#Possessive #Noun' ) . text ( )
// "Wayne's World"
เอกสาร Tagger
การประนีประนอม/สอง จะคำนวณไวยากรณ์พื้นฐานของแต่ละคำโดยอัตโนมัติ
สิ่งนี้มีประโยชน์มากกว่าบางครั้งผู้คนก็ตระหนัก
ไวยากรณ์แสงช่วยให้คุณเขียนเทมเพลตที่สะอาดและเข้าใกล้ข้อมูลมากขึ้น
การประนีประนอมมี 83 แท็ก จัดเรียงในกราฟหล่อ
#firstName → #person → #ProperNoun → #Noun
คุณสามารถดูไวยากรณ์ของแต่ละคำโดยใช้ doc.debug()
คุณสามารถเห็นเหตุผลสำหรับแต่ละแท็กด้วย nlp.verbose('tagger')
หากคุณต้องการ แท็กเพนน์ คุณสามารถหาได้ด้วย:
let doc = nlp ( 'welcome thrillho' )
doc . compute ( 'penn' )
doc . json ( )
compromise/three
Phrase และเครื่องมือประโยค
import nlp from 'compromise/three'
let doc = nlp ( "Wayne's World, party time" )
let str = doc . people ( ) . normalize ( ) . text ( )
// "wayne"
เอกสารการเลือก
การประนีประนอม/สาม เป็นชุดเครื่องมือใน การซูม และทำงานในส่วนของข้อความ
.numbers() คว้าตัวเลขทั้งหมดในเอกสารตัวอย่างเช่น - และขยายด้วยวิธีการใหม่เช่น .subtract()
เมื่อคุณมีวลีหรือกลุ่มคำคุณสามารถดูข้อมูลเมตาเพิ่มเติมเกี่ยวกับมันด้วย .json()
let doc = nlp ( 'four out of five dentists' )
console . log ( doc . fractions ( ) . json ( ) )
/*[{
text: 'four out of five',
terms: [ [Object], [Object], [Object], [Object] ],
fraction: { numerator: 4, denominator: 5, decimal: 0.8 }
}
]*/ let doc = nlp ( '$4.09CAD' )
doc . money ( ) . json ( )
/*[{
text: '$4.09CAD',
terms: [ [Object] ],
number: { prefix: '$', num: 4.09, suffix: 'cad'}
}
]*/
API
ประนีประนอม/หนึ่ง
เอาท์พุท
- .Text () - ส่งคืนเอกสารเป็นข้อความ
- .json () - ส่งคืนเอกสารเป็นข้อมูล
- .Debug () - พิมพ์เอกสารที่ตีความได้
- .out () - เอาต์พุตชื่อหรือแบบกำหนดเอง
- .html ({}) - แท็ก HTML ที่กำหนดเองที่กำหนดเองสำหรับการจับคู่
- .Wrap ({}) - ผลิตผลลัพธ์ที่กำหนดเองสำหรับการจับคู่เอกสาร
เครื่องใช้
- .Found [Getter] - เอกสารนี้ว่างเปล่าหรือไม่?
- .docs [getter] รับคำศัพท์เป็น JSON
- .length [getter] - นับ # ของอักขระในเอกสาร (ความยาวสตริง)
- .isView [getter] - ระบุวัตถุประนีประนอม
- .Compute () - เรียกใช้การวิเคราะห์ที่มีชื่อในเอกสาร
- .clone () - สำเนาเอกสารลึกเพื่อไม่ให้มีการอ้างอิงใด ๆ
- .MLIST () - ส่งคืนรายการแบนของวัตถุคำทั้งหมดในการจับคู่
- .CACHE ({}) - ตรึงสถานะปัจจุบันของเอกสารสำหรับจุดประสงค์ความเร็ว
- .uncache () - ไม่ทำให้สถานะปัจจุบันของเอกสารไม่เย็น
- .freeze ({}) - ป้องกันไม่ให้แท็กใดถูกลบออกในข้อกำหนดเหล่านี้
- .UNFREEZE ({}) - อนุญาตให้แท็กเปลี่ยนอีกครั้งเป็นค่าเริ่มต้น
อุปกรณ์เสริม
- .All () - ส่งคืนเอกสารต้นฉบับทั้งหมด ('ซูมออก')
- .Terms () - ผลการแยกตามแต่ละคำศัพท์
- . First (N) - ใช้เฉพาะผลลัพธ์แรกเท่านั้น
- .last (n) - ใช้เฉพาะผลลัพธ์สุดท้ายเท่านั้น
- .Slice (n, n) - คว้าชุดย่อยของผลลัพธ์
- .eq (n) - ใช้เฉพาะผลลัพธ์ nth
- .Firstterms () - รับคำแรกในการแข่งขันแต่ละครั้ง
- .lastterms () - รับคำสิ้นสุดในแต่ละนัด
- . fullsentences () - รับประโยคทั้งหมดสำหรับการแข่งขันแต่ละครั้ง
- .groups () - คว้ากลุ่มจับคู่ที่มีชื่อจากการแข่งขัน
- .WordCount () - นับ # ของคำในเอกสาร
- .Confidence () - คะแนนเฉลี่ยสำหรับการตีความแท็ก POS
จับคู่
(วิธีการจับคู่ใช้ Match-Syntax)
- .Match ('') - ส่งคืนเอกสารใหม่โดยที่เอกสารนี้เป็นผู้ปกครอง
- . ไม่ ('') - ส่งคืนผลลัพธ์ทั้งหมดยกเว้นสิ่งนี้
- .Matchone ('') - ส่งคืนเฉพาะนัดแรก
- .if ('') - ส่งคืนวลีปัจจุบันแต่ละวลีเฉพาะในกรณีที่มีการจับคู่นี้ ('เท่านั้น')
- .IFNO ('') - กรองวลีปัจจุบันใด ๆ ที่มีการจับคู่นี้ ('NOTIF')
- .has ('') - ส่งคืนบูลีนถ้าการแข่งขันนี้มีอยู่
- . ก่อน ('') - ส่งคืนคำศัพท์ทั้งหมดก่อนการแข่งขันในแต่ละวลี
- . หลังจาก ('') - ส่งคืนคำศัพท์ทั้งหมดหลังจากการแข่งขันในแต่ละวลี
- .UNION () - ส่งคืนการจับคู่แบบรวมโดยไม่ต้องทำซ้ำ
- .intersection () - ส่งคืนการจับคู่ที่ซ้ำกันเท่านั้น
- .Complement () - รับทุกอย่างที่ไม่ได้อยู่ในการแข่งขันอื่น
- .SetTle () - ลบการทับซ้อนออกจากการแข่งขัน
- .growright ('') - เพิ่มข้อกำหนดการจับคู่ใด ๆ ทันทีหลังจากการแข่งขันแต่ละครั้ง
- .growleft ('') - เพิ่มข้อกำหนดการจับคู่ใด ๆ ทันทีก่อนการแข่งขันแต่ละครั้ง
- .grow ('') - เพิ่มข้อกำหนดการจับคู่ใด ๆ ก่อนหรือหลังการแข่งขันแต่ละครั้ง
- .Sweep (net) - ใช้ชุดของวัตถุจับคู่กับเอกสาร
- .SPLITON ('') - ส่งคืนเอกสารด้วยสามส่วนสำหรับทุกการแข่งขัน ('Spliton')
- .splitbefore ('') - พาร์ติชันวลีก่อนแต่ละเซ็กเมนต์การจับคู่
- .splitafter ('') - พาร์ติชันวลีหลังจากแต่ละเซ็กเมนต์การจับคู่
- .Join () - รวมข้อกำหนดใด ๆ ที่อยู่ใกล้เคียงในแต่ละนัด
- .Joinif (ซ้าย - rightmatch) - รวมข้อกำหนดใด ๆ ที่อยู่ใกล้เคียงภายใต้เงื่อนไขที่กำหนด
- .lookup ([]) - ค้นหาอย่างรวดเร็วสำหรับอาร์เรย์ของสตริงที่ตรงกัน
- .AutoFill () - สร้างสมมติฐานแบบต่อหน้าต่อไปนี้ในเอกสาร
ติดแท็ก
- .TAG ('') - ให้คำศัพท์ทั้งหมดที่กำหนด
- .tagsafe ('') - ใช้แท็กกับข้อกำหนดเฉพาะหากสอดคล้องกับแท็กปัจจุบัน
- .untag ('') - ลบคำนี้ออกจากข้อกำหนดที่กำหนด
- .canbe ('') - ส่งคืนเฉพาะคำที่สามารถเป็นแท็กนี้ได้
กรณี
- .ToLowerCase () - เปลี่ยนจดหมายทุกฉบับของทุกเทอมเป็น Lower -Cse
- .touppercase () - หมุนตัวอักษรทุกคำในทุกเทอมเป็นตัวพิมพ์ใหญ่
- .totitlecase () - ตัวอักษรบนตัวอักษรตัวแรกของแต่ละเทอม
- .tocamelcase () - ลบช่องว่างและชื่อเรื่องแต่ละคำในแต่ละเทอม
ช่องว่าง
- .pre ('') - เพิ่มเครื่องหมายวรรคตอนนี้หรือช่องว่างก่อนการแข่งขันแต่ละครั้ง
- .post ('') - เพิ่มเครื่องหมายวรรคตอนนี้หรือช่องว่างหลังการแข่งขันแต่ละครั้ง
- .Trim () - ลบช่องว่างเริ่มต้นและสิ้นสุด
- .Hyphenate () - เชื่อมต่อคำด้วยยัติภังค์และลบช่องว่าง
- .Dehyphenate () - ลบยัติภังค์ระหว่างคำและตั้งช่องว่าง
- .toQuotations () - เพิ่มเครื่องหมายใบเสนอราคารอบการแข่งขันเหล่านี้
- .Toparentheses () - เพิ่มวงเล็บรอบการแข่งขันเหล่านี้
ลูป
- .Map (FN) - เรียกใช้แต่ละวลีผ่านฟังก์ชั่นและสร้างเอกสารใหม่
- .Foreach (FN) - เรียกใช้ฟังก์ชั่นในแต่ละวลีเป็นเอกสารแต่ละฉบับ
- .Filter (FN) - ส่งคืนเฉพาะวลีที่กลับมาจริง
- .Find (FN) - ส่งคืนเอกสารด้วยวลีแรกที่ตรงกับ
- . บางอย่าง (fn) - ส่งคืนจริงหรือเท็จหากมีหนึ่งวลีที่ตรงกัน
- .RANDOM (FN) - ตัวอย่างชุดย่อยของผลลัพธ์
แทรก
- .replace (จับคู่แทนที่) - ค้นหาและแทนที่การจับคู่ด้วยเนื้อหาใหม่
- .replacewith (แทนที่) - แทนที่ข้อความใหม่
- .remove () - ลบข้อกำหนดเหล่านี้ออกจากเอกสารอย่างเต็มที่
- .inSertBefore (STR) - เพิ่มข้อกำหนดใหม่เหล่านี้ลงในด้านหน้าของการแข่งขันแต่ละครั้ง (prepend)
- .insertafter (STR) - เพิ่มข้อกำหนดใหม่เหล่านี้ในตอนท้ายของการแข่งขันแต่ละครั้ง (ผนวก)
- .concat () - เพิ่มสิ่งใหม่ ๆ เหล่านี้ลงในตอนท้าย
- .SWAP (Fromlemma, Tolemma) - การเปลี่ยนสมาร์ทของคำศัพท์โดยใช้การผันคำกริยาที่เหมาะสม
เปลี่ยนรูป
- .sort ('วิธี') - จัดลำดับคำสั่งของการแข่งขันอีกครั้ง (ในสถานที่)
- .reverse () - ย้อนกลับลำดับของการแข่งขัน แต่ไม่ใช่คำ
- . normalize ({}) - ทำความสะอาดข้อความด้วยวิธีต่าง ๆ
- .Unique () - ลบการแข่งขันที่ซ้ำกัน
lib
(วิธีการเหล่านี้อยู่ในวัตถุ nlp หลัก)
nlp.tokenize (str) - การแยกวิเคราะห์ข้อความโดยไม่ต้องใช้ pos -tagging
nlp.lazy (str, match) - สแกนผ่านข้อความที่มีการวิเคราะห์น้อยที่สุด
nlp.plugin ({}) - ผสมในการประนีประนอม - plugin
NLP.ParSEmatch (STR) - pre -parse คำสั่งการจับคู่ใด ๆ ใน JSON
nlp.world () - คว้าหรือเปลี่ยนห้องสมุดภายใน
nlp.model () - คว้าข้อมูลภาษาปัจจุบันทั้งหมด
nlp.methods () - คว้าหรือเปลี่ยนวิธีการภายใน
nlp.hooks () - ดูว่าวิธีการคำนวณใดทำงานโดยอัตโนมัติ
nlp.verbose (โหมด) - บันทึกการตัดสินใจของเราสำหรับการดีบัก
NLP.Version - เวอร์ชัน SEMVER ปัจจุบันของไลบรารี
nlp.addwords (obj, isfrozen?) - เพิ่มคำใหม่ลงในพจนานุกรม
nlp.addtags (obj) - เพิ่มแท็กใหม่ลงในแท็กเซ็ต
nlp.typeahead (arr) - เพิ่มคำลงในพจนานุกรมเติมอัตโนมัติ
nlp.buildtrie (arr) - รวบรวมรายการคำในรูปแบบการค้นหาที่รวดเร็ว
nlp.buildnet (arr) - รวบรวมรายการการจับคู่ลงในแบบฟอร์มการจับคู่ที่รวดเร็ว
ประนีประนอม/สอง:
การหดตัว
- .Contractions () - สิ่งต่าง ๆ เช่น "ไม่ได้"
- .Contractions (). ขยาย () - สิ่งต่าง ๆ เช่น "ไม่ได้"
- .contract () - สิ่งต่าง ๆ เช่น "ไม่ได้"
ประนีประนอม/สาม:
คำนาม
- .nouns () - ส่งคืนข้อกำหนดที่ตามมาติดแท็กเป็นคำนาม
- .nouns (). JSON () - เอาต์พุตเกินพิกัดด้วยคำนามข้อมูลเมตา
- .nouns (). parse () - รับวลีคำนาม tokenized
- .nouns (). isplural () - กลับคำนามพหูพจน์เท่านั้น
- .nouns (). issingular () - กลับคำนามเอกพจน์เท่านั้น
- .nouns (). toplural () -
'football captain' → 'football captains' - .nouns (). Tosingular () -
'turnovers' → 'turnover' - .nouns (). คำคุณศัพท์ () - รับคำคุณศัพท์ใด ๆ ที่อธิบายคำนามนี้
คำกริยา
- . verbs () - ส่งคืนข้อกำหนดที่ตามมาติดแท็กเป็นคำกริยา
- . verbs (). JSON () - เอาต์พุตที่โอเวอร์โหลดด้วยคำกริยาข้อมูลเมตา
- . verbs (). parse () - รับวลีคำกริยา tokenized
- . verbs (). subjects () - สิ่งที่ทำคำกริยาการกระทำ
- . verbs (). Adverbs () - ส่งคืนคำวิเศษณ์ที่อธิบายคำกริยานี้
- . verbs (). issingular () - กลับคำกริยาเอกพจน์เช่น 'Spencer Walks'
- . verbs (). isplural () - คำกริยาพหูพจน์กลับเช่น 'We Walk'
- . verbs (). isimperative () - คำแนะนำเฉพาะเช่น 'กินมัน!'
- . verbs (). opasttense () -
'will go' → 'went' - . verbs (). topresenttense () -
'walked' → 'walks' - . verbs (). tofuturetense () -
'walked' → 'will walk' - . verbs (). toinfinitive () -
'walks' → 'walk' - . verbs (). togerund () -
'walks' → 'walking' - . verbs (). opastparticiple () -
'drive' → 'had driven' - . verbs (). Conjugate () - ส่งคืนการผันคำกริยาเหล่านี้ทั้งหมด
- . verbs (). isnegative () - กลับคำกริยาด้วย 'ไม่', 'ไม่' หรือ 'ไม่'
- . verbs (). ispositive () - เฉพาะคำกริยาที่ไม่มี 'ไม่', 'ไม่' หรือ 'ไม่'
- . verbs (). tonegative () -
'went' → 'did not go' - . verbs (). topositive () -
"didn't study" → 'studied'
ตัวเลข
- .numbers () - คว้าค่าที่เขียนและตัวเลขทั้งหมด
- .numbers (). parse () - รับวลีตัวเลขที่โทเค็น
- .numbers (). get () - รับหมายเลขจาวาสคริปต์ง่ายๆ
- .numbers (). JSON () - เอาต์พุตเกินพิกัดพร้อมข้อมูลเมตาดาต้าหมายเลข
- .numbers (). tonumber () - แปลง 'ห้า' เป็น
5 - .numbers (). tolocalestring () - เพิ่มเครื่องหมายจุลภาคหรือการจัดรูปแบบที่ดีกว่าสำหรับตัวเลข
- .numbers (). totext () - แปลง '5' เป็น
five - .numbers (). toordinal () - แปลง 'ห้า' เป็น
fifth หรือ 5th - .numbers (). tocardinal () - แปลง 'ห้า' เป็น
five หรือ 5 - .numbers (). isordinal () - ส่งคืนตัวเลขตามลำดับเท่านั้น
- .numbers (). isCardinal () - ส่งคืนเฉพาะหมายเลขพระคาร์ดินัล
- .numbers (). isequal (n) - หมายเลขส่งคืนด้วยค่านี้
- .numbers (). Greaterthan (min) - ส่งคืนตัวเลขที่ใหญ่กว่า n
- .numbers (). Lessthan (สูงสุด) - ส่งคืนหมายเลขเล็กกว่า N
- .numbers (). ระหว่าง (ขั้นต่ำ, สูงสุด) - ส่งคืนหมายเลขระหว่างขั้นต่ำและสูงสุด
- .numbers (). isunit (หน่วย) - ส่งคืนตัวเลขเฉพาะในหน่วยที่กำหนดเช่น 'km'
- .numbers (). set (n) - ตั้งหมายเลขเป็น n
- .numbers (). เพิ่ม (n) - เพิ่มจำนวนโดย n
- .numbers (). ลบ (n) - ลดจำนวนโดย n
- .numbers (). เพิ่ม () - เพิ่มจำนวนโดย 1
- .numbers (). การลดลง () - ลดจำนวนลง 1
- .money () - สิ่งต่าง ๆ เช่น
'$2.50'- .money (). get () - ดึงเงินที่แยกวิเคราะห์ได้
- .Money (). JSON () - สกุลเงิน + ข้อมูลหมายเลข
- .money (). Currency () - เงินใดอยู่ในสกุลเงิน
- .fractions () - เช่น '2/3rds' หรือ 'หนึ่งในห้า'
- .Fractions (). parse () - รับเศษส่วนที่โทเค็น
- .Fractions (). get () - ตัวเศษง่าย ๆ , ข้อมูลส่วนข้อมูล
- .Fractions (). JSON () - เมธอด JSON มากเกินไปด้วยข้อมูลเศษส่วน
- .Fractions (). todecimal () - '2/3' -> '0.66'
- .Fractions (). Normalize () - 'Four Of Of 10' -> '4/10'
- .Fractions (). Totext () - '4/10' -> 'Four Tenths'
- .Fractions (). TOPERCENTAGE () - '4/10' -> '40%'
- .Percentages () - เช่น '2.5%'
- .Percentages (). get () - ส่งคืนหมายเลขเปอร์เซ็นต์ / 100
- .Percentages (). JSON () - JSON มากเกินไปด้วยข้อมูลเปอร์เซ็นต์
- . percentages (). tofraction () - '80%' ->' 8/10 '
ประโยค
- .Sentences () - กลับคลาสประโยคด้วยวิธีการเพิ่มเติม
- .Sentences (). JSON () - เอาต์พุตเกินพิกัดพร้อมข้อมูลเมตาประโยค
- .Sentences (). topasttense () -
he walks -> he walked - .Sentences (). TopresentTense () -
he walked -> he walks - .Sentences (). tofutureTense () -
he walks -> he will walk - .Sentences (). toinfinitive () -คำกริยารากรูปแบบ
he walks -> he walk - .Sentences (). Tonegative () - -
he walks -> he didn't walk - .Sentences (). ISQUESTION () - กลับคำถามด้วย A
? - .Sentences (). isExClamation () - กลับประโยคด้วย A
! - .Sentences (). iSstatement () - ส่งคืนประโยคโดยไม่ต้อง
? หรือ !
คำคุณศัพท์
- . คำสั่ง () - สิ่งต่าง ๆ เช่น
'quick'- . คำสั่ง (). json () - รับข้อมูลเมตาคำคุณศัพท์
- . คำสั่ง (). คอนจูเกต () - ส่งคืนการผันคำคุณศัพท์ทั้งหมดของคำคุณศัพท์เหล่านี้
- . คำสั่ง (). คำวิเศษณ์ () - รับคำวิเศษณ์ที่อธิบายคำคุณศัพท์นี้
- . adjectives (). tocomparative () - 'ด่วน' -> 'เร็วกว่า'
- . คำสั่ง (). tosuperlative () - 'ด่วน' -> 'เร็วที่สุด'
- . คำสั่ง (). toadverb () - 'ด่วน' -> 'เร็ว'
- . adjectives (). tonoun () - 'ด่วน' -> 'ความรวดเร็ว'
การเลือกอื่น ๆ
- .clauses () -ประโยคแยกออกเป็นวลีหลายวลี
- .CHUNKS () -ประโยคแบบแยกส่วนคำนามและวรรค
- .Hyphenated () - คำทั้งหมดที่เชื่อมต่อกับยัติภังค์หรือเส้นประเช่น
'wash-out' - .PHONENUMBERS () - สิ่งต่าง ๆ เช่น
'(939) 555-0113' - .HashTags () - สิ่งต่าง ๆ เช่น
'#nlp' - .Emails () - สิ่งต่าง ๆ เช่น
'[email protected]' - .EMOTICONS () - สิ่งที่ชอบ
:) - .EMOJIS () - สิ่งที่ชอบ
? - .atmentions () - สิ่งต่าง ๆ เช่น
'@nlp_compromise' - .URLS () - สิ่งต่าง ๆ เช่น
'compromise.cool' - .Pronouns () - สิ่งต่าง ๆ เช่น
'he' - .Conjunctions () - สิ่งต่าง ๆ เช่น
'but' - .Prepositions () - สิ่งที่ชอบ
'of' - .abbreviations () - สิ่งต่าง ๆ เช่น
'Mrs.' - .people () - ชื่อเช่น 'John F. Kennedy'
- . people (). json () - รับข้อมูลเมตาชื่อบุคคล
- .people (). parse () - รับการตีความชื่อบุคคล
- . places () - เช่น 'ปารีส, ฝรั่งเศส'
- .Organizations () - เช่น 'Google, Inc'
- .TOPICS () -
people() + places() + organizations() - .Adverbs () - สิ่งต่าง ๆ เช่น
'quickly'- .Adverbs (). JSON () - รับข้อมูลเมตาของคำวิเศษณ์
- .Acronyms () - สิ่งต่าง ๆ เช่น
'FBI'- .Acronyms (). strip () - ลบช่วงเวลาออกจากคำย่อ
- .Acronyms (). addPeriods () - เพิ่มช่วงเวลาลงในคำย่อ
- .Parentheses () - ส่งคืนสิ่งของภายใน (วงเล็บ)
- .Parentheses (). strip () - ถอดวงเล็บ
- .Possessives () - สิ่งต่าง ๆ เช่น
"Spencer's"- .Possessives (). Strip () - "Spencer's" -> "Spencer"
- .quotations () - ส่งคืนข้อกำหนดใด ๆ ภายในเครื่องหมายใบเสนอราคาคู่
- .quotations (). strip () - ลบเครื่องหมายใบเสนอราคา
- .Slashes () - ส่งคืนคำศัพท์ใด ๆ ที่จัดกลุ่มโดย Slashes
- .Slashes (). split () - เปลี่ยน 'ความรัก/ความเกลียด' เป็น 'รักรัก'
.ขยาย():
ห้องสมุดนี้มาพร้อมกับพื้นฐานที่มีน้ำใจและมีน้ำใจสำหรับไวยากรณ์ภาษาอังกฤษ
คุณมีอิสระที่จะเปลี่ยนแปลงหรือวางขยะไปยังการตั้งค่าใด ๆ - ซึ่งเป็นส่วนที่สนุกจริง ๆ
ส่วนที่ง่ายที่สุดคือการแนะนำแท็กสำหรับคำใด ๆ ที่กำหนด:
let myWords = {
kermit : 'FirstName' ,
fozzie : 'FirstName' ,
}
let doc = nlp ( muppetText , myWords ) หรือทำการเปลี่ยนแปลงที่หนักขึ้นด้วยการประนีประนอม
import nlp from 'compromise'
nlp . extend ( {
// add new tags
tags : {
Character : {
isA : 'Person' ,
notA : 'Adjective' ,
} ,
} ,
// add or change words in the lexicon
words : {
kermit : 'Character' ,
gonzo : 'Character' ,
} ,
// change inflections
irregulars : {
get : {
pastTense : 'gotten' ,
gerund : 'gettin' ,
} ,
} ,
// add new methods to compromise
api : View => {
View . prototype . kermitVoice = function ( ) {
this . sentences ( ) . prepend ( 'well,' )
this . match ( 'i [(am|was)]' ) . prepend ( 'um,' )
return this
}
} ,
} ) .plugin () เอกสาร
เอกสาร:
การแนะนำอย่างอ่อนโยน:
- #1) อินพุต→เอาต์พุต
- #2) Match & Transform
- #3) การแชทบอท
เอกสาร:
| แนวคิด | API | ปลั๊กอิน |
|---|
| ความแม่นยำ | อุปกรณ์เสริม | คำคุณศัพท์ |
| การแคช | วิธีการสร้าง | วันที่ |
| กรณี | การหดตัว | ส่งออก |
| ปรับขนาด | แทรก | กัญชา |
| ภายใน | JSON | HTML |
| การให้เหตุผล | ตัวละครชดเชย | การกดปุ่ม |
| พจนานุกรม | ลูป | ngrams |
| Match-Syntax | จับคู่ | ตัวเลข |
| ผลงาน | คำนาม | ย่อหน้า |
| ปลั๊กอิน | เอาท์พุท | สแกน |
| โครงการ | การเลือก | ประโยค |
| กระหน่ำ | การจัดเรียง | พยางค์ |
| แท็ก | แยก | ออกเสียง |
| การทำให้โทเค็น | ข้อความ | เข้มงวด |
| สิ่งที่มีชื่อ | เครื่องใช้ | แท็กเพนน์ |
| ช่องว่าง | คำกริยา | หัวพิมพ์ |
| ข้อมูลโลก | การทำให้เป็นมาตรฐาน | กวาด |
| การจับคู่ที่คลุมเครือ | ตัวพิมพ์ใหญ่ | การกลายพันธุ์ |
| รูปแบบราก | | |
พูดคุย:
- ภาษาเป็นอินเทอร์เฟซ - โดย Spencer Kelly
- การเข้ารหัสแชทบอท - โดย Kahwee Teng
- เกี่ยวกับการพิมพ์และข้อมูล - โดย Spencer Kelly
บทความ:
- การสนทนาทางสังคม Geocoding ด้วย NLP และ JavaScript - โดย Microsoft
- สูตร Microservice - โดย Eventn
- ประโยคเกมผจญภัยแยกวิเคราะห์ด้วยการประนีประนอม
- การสร้างเกมที่ใช้ข้อความ - โดย Matt Eland
- สนุกกับ JavaScript ใน BigQuery - โดย Felipe Hoffa
- การประมวลผลภาษาธรรมชาติ ... ในเบราว์เซอร์? - โดย Charles Landau
แอปพลิเคชั่นสนุก ๆ :
- การทดสอบ Bechdel อัตโนมัติ - โดย Guardian
- กรอบการสร้างเรื่องราว - โดย Jose Phrocca
- บล็อก Tumbler ของรายการ - รายการเหมือน bebooks - โดย Michael Paulukonis
- การแก้ไขวิดีโอจากการถอดความ - โดยทฤษฎีใหม่
- การตรวจสอบข้อเท็จจริงเกี่ยวกับเบราว์เซอร์ - โดย Alexander Kidd
- Siri ทางลัด - โดย Michael Byrns
- Skill Amazon - โดย Tajddin Maghni
- Tasking Slack -Bot - โดย Kevin Suh [ดูเพิ่มเติม]
การเปรียบเทียบ
- ประนีประนอม
- ประนีประนอมและ NLTK
ปลั๊กอิน:
นี่คือส่วนขยายที่เป็นประโยชน์:
วันที่
npm install compromise-dates
- .DATES () - ค้นหาวันที่เช่น
June 8th หรือ 03/03/18- .DATES (). GET () - ผลลัพธ์ JSON เริ่มต้น/สิ้นสุดง่ายๆ
- .DATES (). JSON () - เอาต์พุตที่โอเวอร์โหลดพร้อมข้อมูลเมตาวันที่
- .DATES (). รูปแบบ ('') - แปลงวันที่เป็นรูปแบบเฉพาะ
- .DATES (). TOSHORTFORM () - แปลง 'วันพุธ' เป็น 'พุธ' ฯลฯ
- .DATES (). TOLONGFORM () - แปลง 'FEB' เป็น 'กุมภาพันธ์' ฯลฯ
- .durations () -
2 weeks หรือ 5mins- .Durations (). get () - ส่งคืน JSON ง่าย ๆ ในระยะเวลา
- .Durations (). JSON () - เอาต์พุตเกินพิกัดด้วยข้อมูลเมตาระยะเวลา
- .times () -
4:30pm หรือ half past five- .times (). get () - ส่งคืน JSON ง่ายๆสำหรับเวลา
- .times (). JSON () - เอาต์พุตเกินพิกัดกับข้อมูลเมตาเวลา
สถิติ
npm install compromise-stats
.tfidf ({}) - อันดับคำตามความถี่และเอกลักษณ์
.NGRAMS ({}) -แสดงรายการซ้ำทั้งหมดซ้ำ ๆ โดยการนับคำ
.Unigrams () - n -grams ด้วยคำเดียว
.Bigrams () - n -grams ที่มีสองคำ
.Trigrams () - n -grams ที่มีสามคำ
.StartGrams () - N -Grams รวมถึงเทอมแรกของวลี
.endGrams () - N -Grams รวมถึงเทอมสุดท้ายของวลี
.EdgeGrams () - N -Grams รวมถึงคำแรกหรือคำสุดท้ายของวลี
คำพูด
npm install compromise-syllables
- .Syllables () - แยกแต่ละคำโดยการออกเสียงทั่วไป
- .Soundslike () - ผลิตการออกเสียงโดยประมาณ
วิกิพีเดีย
npm install compromise-wikipedia
- .Wikipedia () - การกระทบยอดบทความที่บีบอัด
ตัวพิมพ์ใหญ่
เรามุ่งมั่นที่จะสนับสนุน TypeScript/Deno ทั้งในหลักและในการจัดวางอย่างเป็นทางการ:
import nlp from 'compromise'
import stats from 'compromise-stats'
const nlpEx = nlp . extend ( stats )
nlpEx ( 'This is type safe!' ) . ngrams ( { min : 1 } ) เอกสาร TypeScript
ข้อ จำกัด :
Slash-Support: ขณะนี้เราแยก Slashes เป็นคำที่แตกต่างเช่นที่เราทำเพื่อยัติภังค์ ดังนั้นสิ่งนี้ไม่ได้ผล: nlp('the koala eats/shoots/leaves').has('koala leaves') //false
การจับคู่ระหว่างประโยค: โดยค่าเริ่มต้นประโยคเป็นนามธรรมระดับบนสุด การจับคู่ระหว่างประโยคหรือหลายประโยคไม่ได้รับการสนับสนุนโดยไม่มีปลั๊กอิน: nlp("that's it. Back to Winnipeg!").has('it back')//false
ไวยากรณ์การจับคู่ซ้อนกัน: ความงาม ที่เป็นอันตราย ของ Regex คือคุณสามารถกลับมาอีกครั้งได้อย่างไม่มีกำหนด ไวยากรณ์การจับคู่ของเราอ่อนแอกว่ามาก สิ่งนี้ยังไม่เป็น ไป ได้ (ยัง) : doc.match('(modern (major|minor))? general')
การแยกวิเคราะห์การพึ่งพา: การแปลงประโยคที่เหมาะสมต้องมีการทำความเข้าใจต้นไม้ไวยากรณ์ของประโยคซึ่งเราไม่ได้ทำในขณะนี้ เราควร! ความช่วยเหลือที่ต้องการกับสิ่งนี้
คำถามที่พบบ่อย
☂ไม่ใช่ JavaScript ด้วย ...
ใช่มันคือ!
มันไม่ได้ถูกสร้างขึ้นเพื่อแข่งขันกับ NLTK และอาจไม่พอดีกับทุกโครงการ
การประมวลผลสตริงก็เป็นแบบซิงโครนัสเช่นกันและกระบวนการโหนดแบบขนานนั้นแปลก
ดูที่นี่สำหรับข้อมูลเกี่ยวกับ Speed & Performance และที่นี่สำหรับแรงจูงใจของโครงการ
- มันสามารถทำงานบน Arduino-watch ของฉันได้หรือไม่?
ถ้ามันกันน้ำ!
อ่านอย่างรวดเร็วเริ่มต้นสำหรับการประนีประนอมในคนงานแอพมือถือและสภาพแวดล้อมที่ตลกทุกประเภท
- ประนีประนอมในภาษาอื่น ๆ ?
เรามีส้อมที่กำลังดำเนินการสำหรับภาษาเยอรมันฝรั่งเศสสเปนและอิตาลีในปรัชญาเดียวกัน
และต้องการความช่วยเหลือ
สร้างบางส่วน?
เรานำเสนอการสร้างแบบโทเค็นอย่างเดียวซึ่งมีการดึง pos-tagger ออก
แต่มิฉะนั้นการประนีประนอมไม่ได้เขย่าต้นไม้อย่างง่ายดาย
วิธีการติดแท็กมีการแข่งขันและโลภดังนั้นจึงไม่แนะนำให้ดึงสิ่งต่าง ๆ ออกมา
โปรดทราบว่าหากไม่มีการติดแท็กแบบเต็มรูปแบบการหดตัวของ Parser จะไม่ทำงานอย่างสมบูรณ์ ( (Spencer's Cool) vs. (บ้านของ Spencer)) )
ขอแนะนำให้เรียกใช้ห้องสมุดอย่างเต็มที่
ดูเพิ่มเติม:
en-pos -JavaScript Pos-Tagger โดย Alex Corvi
NaturalNode - นักสถิติ NLP ใน JavaScript
Winkjs -Pos-Tagger, Tokenizer, Machine-Learning ใน JavaScript
dariusk/pos -js - fasttag fork ใน JavaScript
บทสรุป - JS - การวิเคราะห์ POS และความเชื่อมั่นใน JavaScript
NodeBox Linguistics - การผันคำกริยาใน JavaScript
retext - ยูทิลิตี้ข้อความที่น่าประทับใจมากใน JavaScript
SuperScript - เครื่องมือสนทนาใน JS
JSPOS -JavaScript Build ของ Brill-tagger ที่ผ่านการทดสอบตามเวลา
spacy - รวดเร็ว, tagger หลายภาษาใน c/python
ร้อยแก้ว - Tagger Quick In Go By Joseph Kato
Textblob - Python Tagger
มิกซ์