compromiso

Procesamiento de lenguaje natural modesto
npm install compromise
por Spencer Kelly y muchos contribuyentes
francés • alemán • italiano • español
¿No lo encuentras extraño?
El compromiso
intenta convertir el texto en datos.
Toma decisiones limitadas y sensatas.
No es tan inteligente como piensas.
import nlp from 'compromise'
let doc = nlp ( 'she sells seashells by the seashore.' )
doc . verbs ( ) . toPastTense ( )
doc . text ( )
// 'she sold seashells by the seashore.'
No seas elegante, en absoluto:
if ( doc . has ( 'simon says #Verb' ) ) {
return true
}
Agarra partes del texto:
let doc = nlp ( entireNovel )
doc . match ( 'the #Adjective of times' ) . text ( )
// "the blurst of times?"
Documentos de coincidencia
y obtener datos:
import plg from 'compromise-speech'
nlp . extend ( plg )
let doc = nlp ( 'Milwaukee has certainly had its share of visitors..' )
doc . compute ( 'syllables' )
doc . places ( ) . json ( )
/*
[{
"text": "Milwaukee",
"terms": [{
"normal": "milwaukee",
"syllables": ["mil", "wau", "kee"]
}]
}]
*/ JSON DOCS
Evite los problemas de los analizadores quebradizos:
let doc = nlp ( "we're not gonna take it.." )
doc . has ( 'gonna' ) // true
doc . has ( 'going to' ) // true (implicit)
// transform
doc . contractions ( ) . expand ( )
doc . text ( )
// 'we are not going to take it..'
documentos de contracción
y lanzar cosas como son los datos:
let doc = nlp ( 'ninety five thousand and fifty two' )
doc . numbers ( ) . add ( 20 )
doc . text ( )
// 'ninety five thousand and seventy two'
documentos numéricos
-porque en realidad es-
let doc = nlp ( 'the purple dinosaur' )
doc . nouns ( ) . toPlural ( )
doc . text ( )
// 'the purple dinosaurs'
documentos sustantivos
Úselo en el lado del cliente:
< script src =" https://unpkg.com/compromise " > </ script >
< script >
var doc = nlp ( 'two bottles of beer' )
doc . numbers ( ) . minus ( 1 )
document . body . innerHTML = doc . text ( )
// 'one bottle of beer'
</ script >
o también:
import nlp from 'compromise'
var doc = nlp ( 'London is calling' )
doc . verbs ( ) . toNegative ( )
// 'London is not calling'
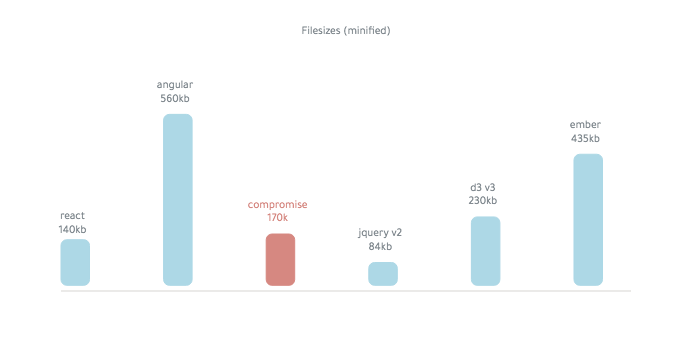
El compromiso es ~ 250kb (minificado):
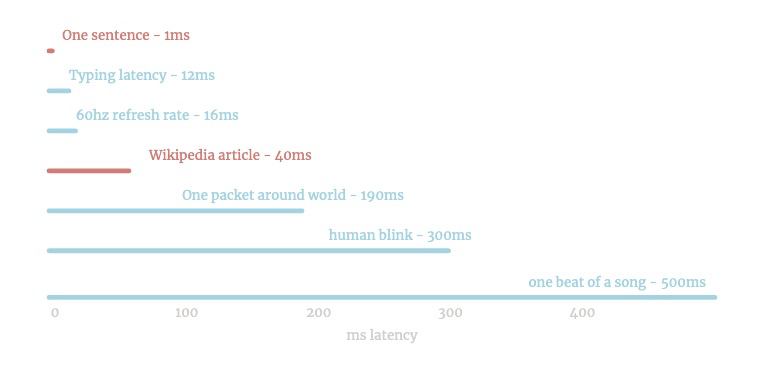
Es bastante rápido. Puede ejecutarse en KeyPress:
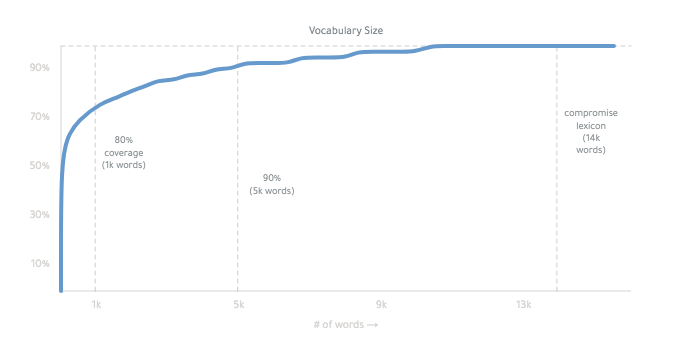
Funciona principalmente conjugando todas las formas de una lista de palabras básicas.
El léxico final es ~ 14,000 palabras:
Puedes leer más sobre cómo funciona, aquí. Es raro.
bueno -
compromise/one
Un tokenizer de palabras, oraciones y puntuación.
import nlp from 'compromise/one'
let doc = nlp ( "Wayne's World, party time" )
let data = doc . json ( )
/* [{
normal:"wayne's world party time",
terms:[{ text: "Wayne's", normal: "wayne" },
...
]
}]
*/ Tokenizer Docs
compromiso/uno divide su texto, lo envuelve en una práctica API,
/Una es rápida: la mayoría de las oraciones toman un décimo de un milisegundo.
Puede hacer ~ 1 MB de texto una segunda o 10 páginas de Wikipedia.
Infinite Jest toma 3s.
También puede paralelizar o transmitir texto con compromiso con velocidad.
compromise/two
Un etiquetador part-of-speech e interprendedor de la gramática.
import nlp from 'compromise/two'
let doc = nlp ( "Wayne's World, party time" )
let str = doc . match ( '#Possessive #Noun' ) . text ( )
// "Wayne's World"
Tagger Docs
Compromiso/Dos calcula automáticamente la gramática muy básica de cada palabra.
Esto es más útil de lo que la gente a veces se da cuenta.
La gramática ligera lo ayuda a escribir plantillas más limpias y acercarse a la información.
El compromiso tiene 83 etiquetas , dispuestas en un gráfico guapo.
#FirstName → #Person → #Propernoun → #noun
Puede ver la gramática de cada palabra ejecutando doc.debug()
Puede ver el razonamiento para cada etiqueta con nlp.verbose('tagger') .
Si prefiere las etiquetas Penn , puede derivarlas con:
let doc = nlp ( 'welcome thrillho' )
doc . compute ( 'penn' )
doc . json ( )
compromise/three
Phrase y herramientas de oración.
import nlp from 'compromise/three'
let doc = nlp ( "Wayne's World, party time" )
let str = doc . people ( ) . normalize ( ) . text ( )
// "wayne"
documentos de selección
Compromise/Three es un conjunto de herramientas para acercarse y operar en partes de un texto.
.numbers() toma todos los números en un documento, por ejemplo, y lo extiende con nuevos métodos, como .subtract() .
Cuando tienes una frase o un grupo de palabras, puedes ver metadatos adicionales al respecto con .json()
let doc = nlp ( 'four out of five dentists' )
console . log ( doc . fractions ( ) . json ( ) )
/*[{
text: 'four out of five',
terms: [ [Object], [Object], [Object], [Object] ],
fraction: { numerator: 4, denominator: 5, decimal: 0.8 }
}
]*/ let doc = nlp ( '$4.09CAD' )
doc . money ( ) . json ( )
/*[{
text: '$4.09CAD',
terms: [ [Object] ],
number: { prefix: '$', num: 4.09, suffix: 'cad'}
}
]*/
API
Compromiso/uno
Producción
- .Text () - Devuelve el documento como texto
- .json () - Devuelva el documento como datos
- .debug () - Pronta del documento interpretado
- .out () - una salida con nombre o personalizada
- .html ({}) - Etiquetas HTML personalizadas de salida para coincidencias
- .wrap ({}) - Producir salida personalizada para coincidencias de documentos
Tensiones
- .found [Getter] - ¿Está este documento vacío?
- .docs [Getter] Obtenga objetos de término como JSON
- .length [getter] - Cuente el # de caracteres en el documento (longitud de cadena)
- .Isview [Getter] - Identificar un objeto de compromiso
- .Compute () - Ejecute un análisis con nombre en el documento
- .Clone () - Copia profunda del documento, para que no queden referencias
- .termList () - devuelva una lista plana de todos los objetos de término en el partido
- .cache ({}) - congele el estado actual del documento, para las propuestas de velocidad
- .uncache () - Un -congelas el estado actual del documento, por lo que puede transformarse
- .Freeze ({}) - Evite que se eliminen las etiquetas, en estos términos
- .Unfreeze ({}) - Permitir que las etiquetas cambien nuevamente, como predeterminado
Accesorios
- .all () - Devuelve todo el documento original ('Zoom Out')
- .terms () : resultados divididos por cada término individual
- .First (n) - use solo los primeros resultados (s)
- .last (n) - use solo los últimos resultados
- .slice (n, n) : tome un subconjunto de los resultados
- .eq (n) - use solo el enésimo resultado
- .Firstterms () - Obtenga la primera palabra en cada partido
- .lastterms () - Obtenga la palabra final en cada partido
- .fullSentences () - Obtenga la oración completa para cada partido
- .Groups () - Tome cualquier grupo de captura llamado de un partido
- .WordCount () - Cuente el # de términos en el documento
- .confidence () : una puntuación promedio para interpretaciones de etiquetas POS
Fósforo
(Los métodos de coincidencia usan el syntax de coincidencia).
- .match ('') - Devuelve un nuevo documento, con este como padre
- .not ('') - devuelva todos los resultados excepto esto
- .matchone ('') - Devuelve solo el primer partido
- .If ('') - Devuelva cada frase actual, solo si contiene esta coincidencia ('solo')
- .IfNO ('') - Filtrate las frases actuales que tengan esta coincidencia ('Notif')
- .Has ('') - Devuelve un booleano si existe este partido
- .before ('') - Devuelva todos los términos antes de un partido, en cada frase
- .After ('') - Devuelva todos los términos después de un partido, en cada frase
- .union () - return coincidentes combinados sin duplicados
- .intersection () - return solo coincidencias duplicadas
- .Complement () - Obtenga todo no en otro partido
- .settle () - Retire las superposiciones de los partidos
- .Growright ('') - Agregue los términos coincidentes inmediatamente después de cada partido
- .Growleft ('') : agregue los términos coincidentes inmediatamente antes de cada partido
- .Grow ('') : agregue los términos coincidentes antes o después de cada partido
- .sweep (net) : aplique una serie de objetos de coincidencia al documento
- .spliton ('') : devuelva un documento con tres partes para cada partido ('Spliton')
- .splitbefore ('') - Partir una frase antes de cada segmento coincidente
- .splitafter ('') - Partir una frase después de cada segmento coincidente
- .Join () - Fusionar los términos vecinos en cada partido
- .Joinif (LeftMatch, RightMatch) : fusione los términos vecinos en condiciones dadas
- .okingUp ([]) - Findir rápido para una matriz de coincidencias de cadenas
- .Autofill () - Crear supuestos de tipo aviso en el documento
Etiqueta
- .tag ('') - Dale a todos los términos la etiqueta dada
- .tagsafe ('') : solo aplique la etiqueta a los términos si es consistente con las etiquetas actuales
- .untag ('') - Elimine este término de los términos dados
- .canbe ('') : devuelva solo los términos que pueden ser esta etiqueta
Caso
- .tolowercase () - Gire cada letra de cada término a la baja -CSE
- .ToUpperCase () - Gire cada letra de cada término a la caja superior
- .totitlecase () - Case superior la primera letra de cada término
- .TocamelCase () - Retire el espacio en blanco y el caso de título cada término
Whitepace
- .pre ('') - Agregue esta puntuación o espacio en blanco antes de cada partido
- .post ('') - Agregue esta puntuación o espacio en blanco después de cada partido
- .trim () : elimine el espacio en blanco de inicio y finalización
- .Hyphenate () - Conecte las palabras con el guión y elimine el espacio en blanco
- .dehyphenate () - Elimine los guiones entre las palabras y establezca el espacio en blanco
- .Toquotations () - Agregar comillas alrededor de estos partidos
- .Toparentheses () - Agregue soportes alrededor de estos partidos
Bucles
- .map (fn) : ejecute cada frase a través de una función y cree un nuevo documento
- .ForEach (FN) : ejecute una función en cada frase, como un documento individual
- .filter (fn) - devuelve solo las frases que devuelven verdaderas
- .find (fn) : devuelve un documento con solo la primera frase que coincide
- . Algunos (fn) - Devuelve verdadero o falso si hay una frase coincidente
- .Random (FN) : muestra un subconjunto de los resultados
Insertar
- .Replace (coincidir, reemplazar) : busque y reemplace la coincidencia con el nuevo contenido
- .ReplaceWith (reemplazar) - sustituto en el nuevo texto
- .remove () - Elimine completamente estos términos del documento
- .insertbefore (str) - Agregue estos nuevos términos al frente de cada partido (prepend)
- .insertAfter (STR) - Agregue estos nuevos términos al final de cada coincidencia (adjunto)
- .concat () - Agregue estas cosas nuevas al final
- .swap (Fromlemma, tolemma) - Reemplazo inteligente de las palabras raíz, utilizando la conjugación adecuada
Transformar
- .sort ('método') : reorganice el orden de las coincidencias (en su lugar)
- .Reverse () - Revertir el orden de las coincidencias, pero no las palabras
- .normalizal ({}) - limpie el texto de varias maneras
- .unique () - Eliminar las coincidencias duplicadas
Lib
(Estos métodos están en el objeto nlp principal)
nlp.tokenize (str) - texto de análisis sin ejecutar
nlp.lazy (str, coincy) : escanee a través de un texto con un análisis mínimo
nlp.plugin ({}) - Mezclar en un compromiso -plugin
NLP.Parsematch (STR) - Pre -PARTIR Las declaraciones de coincidencia en JSON
nlp.world () - Grab o cambie la biblioteca internal
nlp.model () : tome todos los datos lingüísticos actuales
nlp.methods () - agarre o cambie los métodos internos
nlp.hooks () - vea qué métodos de cálculo se ejecutan automáticamente
NLP.verbose (Modo) - Registre nuestra toma de decisiones para la depuración
NLP.Version - Versión actual de Semver de la biblioteca
nlp.addwords (obj, isfrozen?) - Agregue nuevas palabras al léxico
nlp.addtags (obj) - Agregue nuevas etiquetas al conjunto de etiquetas
NLP.TypeAhead (ARR) : agregue palabras al diccionario de relleno automático
nlp.buildtrie (arr) - compile una lista de palabras en un formulario de búsqueda rápida
NLP.Buildnet (ARR) : compile una lista de coincidencias en un formulario de coincidencia rápida
compromiso/dos:
Contracciones
- .contracciones () - cosas como "no"
- .contracciones (). expand () - cosas como "no"
- .contrato () - cosas como "no"
compromiso/tres:
Sustantivos
- .nouns () - Devuelva los términos posteriores etiquetados como un sustantivo
- .nouns (). json () - salida sobrecargada con metadatos sustantivos
- .nouns (). parse () - obtener frase de sustantivo tokenizado
- .nouns (). isplural () - return solo sustantivos plurales
- .nouns (). Issingular () - Devuelve solo sustantivos singulares
- .nouns (). TopLural () -
'football captain' → 'football captains' - .nouns (). tosissular () -
'turnovers' → 'turnover' - .nouns (). Adjectives () - Obtenga cualquier adjetivo que describa este sustantivo
Verbos
- .verbs () : devuelva los términos posteriores etiquetados como verbo
- .verbs (). json () - Salida sobrecargada con metadatos verbales
- .verbs (). parse () - obtener frase verbal tokenizado
- .verbs (). Sujetos () - ¿Qué está haciendo la acción verbal?
- .verbs (). Adverbs () - Devuelve los adverbios que describen este verbo.
- .verbios (). Issingular () - Versos singulares de retorno como 'Spencer Walks'
- .verbios (). isplural () - VERBOS plural de retorno como 'We Walk'
- .verbios (). isImperative () - Solo verbos de instrucciones como '¡comerlo!'
- .verbs (). topastTense () -
'will go' → 'went' - .verbs (). topResentTense () -
'walked' → 'walks' - .verbios (). tofuturetense () -
'walked' → 'will walk' - .verbios (). ToinFinitive () -
'walks' → 'walk' - .verbios (). toGerund () -
'walks' → 'walking' - .verbs (). topastParticiple () -
'drive' → 'had driven' - .verbs (). conjugate () - Devuelva todas las conjugaciones de estos verbos
- .verbios (). isNegative () - VERBOS DE Vuelve con 'no', 'nunca' o 'no'
- .verbios (). ispositivo () - Solo verbos sin 'no', 'nunca' o 'no'
- .verbs (). Tonegative () -
'went' → 'did not go' - .verbs (). topositivo () -
"didn't study" → 'studied'
Números
- .numbers () - Tome todos los valores escritos y numéricos
- .numbers (). parse () - obtener frase de número tokenizado
- .numbers (). get () - Obtenga un número simple de JavaScript
- .numbers (). json () - salida sobrecargada con metadatos numéricos
- .numbers (). Tonumber () - Convertir 'cinco' a
5 - .numbers (). TOLOCALECRING () - Agregar comas o formato más agradable para números
- .numbers (). Totext () - Convertir '5' a
five - .numbers (). toordinal () - Convertir 'cinco' a
fifth o 5th - .numbers (). tCardinal () - Convierta 'quinto' a
five o 5 - .numbers (). isordinal () - return solo números ordinales
- .numbers (). IScardinal () - Devuelve solo números cardinales
- .numbers (). ISequal (n) - Números de retorno con este valor
- .numbers (). GranThan (min) - Números de retorno más grandes que n
- .numbers (). LessThan (Max) - Números de retorno más pequeños que n
- .numbers (). Entre (min, max) - números de retorno entre min y max
- .numbers (). ISUNIT (Unidad) - Devuelve solo números en la unidad dada, como 'km'
- .numbers (). set (n) - establecer el número en n
- .numbers (). Agregar (n) - aumentar el número por n
- .numbers (). Restar (n) - disminuir el número por n
- .numbers (). increment () - Aumente el número en 1
- .numbers (). Decrement () - Número de disminución en 1
- .money () - cosas como
'$2.50'- .money (). get () - Recupere la cantidad (s) de dinero analizado
- .money (). json () - moneda + información de número
- .money (). moneda () - en qué moneda se encuentra el dinero
- .fracciones () - como '2/3rds' o 'uno de los cinco'
- .fracciones (). parse () - obtener fracción tokenizada
- .fracciones (). get () - Datos simples de numeradores, denominadores
- .fracciones (). JSON () - Método JSON sobrecargado con datos de fracciones
- .fracciones (). TODECIMAL () - '2/3' -> '0.66'
- .fracciones (). Normalize () - 'cuatro de 10' -> '4/10'
- .fracciones (). Totext () - '4/10' -> 'Cuatro décimas'
- .fracciones (). topercentage () - '4/10' -> '40%'
- .perceCedages () - como '2.5%'
- .perceCedages (). get () - devuelva el número de porcentaje / 100
- .PerceGes (). JSON () - JSON sobrecargado con información porcentual
- .PerceGages (). Tofraction () - '80%' ->' 8/10 '
Oraciones
- .sentences () - Devuelva una clase de oración con métodos adicionales
- .sentences (). json () - salida sobrecargada con metadatos de oración
- .sentences (). topastTense () -
he walks -> he walked - .sentences (). topresentTense () -
he walked -> he walks - .sentences (). Tofuturetense ()
he walks -> he will walk - .sentences (). ToinFinitive () -VERBO ROOT Forma
he walks -> he walk - .sentences (). Tonegative () - -
he walks -> he didn't walk - .Sentences (). ISQuestion () - Devuelve preguntas con A
? - .sentences (). ISEXCLAMATION () - Devuelve las oraciones con un
! - .sentences (). isStatement () - ¿Devolver oraciones sin
? o !
Adjetivos
- .Adjectives () - Cosas como
'quick'- .Adjectives (). json () - Obtener metadatos de adjetivo
- .Adjectives (). conjugate () - devuelva todas las inflexiones de estos adjetivos
- .Adjectives (). Adverbs () - Obtenga adverbios que describan este adjetivo
- .Adjectives (). TOCOMPARATIVO () - 'Quick' -> 'Quicker'
- .Adjectives (). Tosuperlative () - 'Quick' -> 'más rápido'
- .Adjectives (). Toadverb () - 'Quick' -> 'Rápidamente'
- .Adjectives (). Tonoun () - 'Quick' -> 'Quickness'
Selecciones misceláneas
- .CLAUSES () -FIRAS DISPARADAS EN FRASES Multi-PAR
- .chunks () -Frases de oraciones divididas frases y frases verbales
- .Hyphenated () - Todos los términos conectados con un guión o guión como
'wash-out' - .phonenumbers () - Cosas como
'(939) 555-0113' - .hashtags () - cosas como
'#nlp' - .EMAILS () - Cosas como
'[email protected]' - .Emoticons () - Cosas como
:) - .Emojis () - ¿Cosas como
? - .atmentions () - Cosas como
'@nlp_compromise' - .Urls () - Cosas como
'compromise.cool' - .Pronouns () - Cosas como
'he' - .conjunctions () - cosas como
'but' - .PrePositions () - Cosas como
'of' - .abbreviations () - Cosas como
'Mrs.' - .People () - Nombres como 'John F. Kennedy'
- .People (). json () - Obtener metadatos de nombre de persona
- .People (). parse () - Obtener interpretación de nombre de persona
- .PLACES () - como 'París, Francia'
- .organizations () - como 'Google, Inc'
- .Topics () -
people() + places() + organizations() - .Adverbs () - Cosas como
'quickly'- .Adverbs (). json () - Obtener metadatos de adverbio
- .acronms () - cosas como
'FBI'- .acronms (). Strip () - Eliminar períodos de acrónimos
- .acronsms (). addperiods () - Agregar períodos a acrónimos
- .Parentheses () - Devuelve cualquier cosa adentro (paréntesis)
- .Parentheses (). Strip () - Retire los soportes
- Possessives () - Cosas como
"Spencer's"- .Possessives (). Strip () - "Spencer" -> "Spencer"
- .quotations () - Devuelva cualquier término dentro de comillas emparejadas
- .quotations (). Strip () - Eliminar las comillas
- .slashes () - Devuelva cualquier término agrupado por barras
- .Slashes (). Split () - Convierte 'Amor/Odio' en 'Love Odio'
.extender():
Esta biblioteca viene con una línea de base considerada de sentido común para la gramática inglesa.
Usted es libre de cambiar o poner los desechos a cualquier configuración, que en realidad es la parte divertida.
La parte más fácil es sugerir etiquetas para cualquier palabra dada:
let myWords = {
kermit : 'FirstName' ,
fozzie : 'FirstName' ,
}
let doc = nlp ( muppetText , myWords ) o hacer cambios más pesados con un compromiso-plugin.
import nlp from 'compromise'
nlp . extend ( {
// add new tags
tags : {
Character : {
isA : 'Person' ,
notA : 'Adjective' ,
} ,
} ,
// add or change words in the lexicon
words : {
kermit : 'Character' ,
gonzo : 'Character' ,
} ,
// change inflections
irregulars : {
get : {
pastTense : 'gotten' ,
gerund : 'gettin' ,
} ,
} ,
// add new methods to compromise
api : View => {
View . prototype . kermitVoice = function ( ) {
this . sentences ( ) . prepend ( 'well,' )
this . match ( 'i [(am|was)]' ) . prepend ( 'um,' )
return this
}
} ,
} ) .plugin () documentos
Documentos:
Introducción suave:
- #1) Entrada → Salida
- #2) Match & Transform
- #3) Hacer un chat-bot
Documentación:
| Conceptos | API | Complementos |
|---|
| Exactitud | Accesorios | Adjetivos |
| Almacenamiento en caché | Métodos constructores | Fechas |
| Caso | Contracciones | Exportar |
| Tamaño de filtro | Insertar | Picadillo |
| Interno | Json | Html |
| Justificación | Compensaciones de personajes | Llave |
| Léxico | Bucles | Ngrams |
| Sintaxi | Fósforo | Números |
| Actuación | Sustantivos | Párrafos |
| Complementos | Producción | Escanear |
| Proyectos | Trozos escogidos | Oraciones |
| Tagro | Clasificación | Sílabas |
| Etiquetas | Dividir | Pronunciar |
| Tokenización | Texto | Estricto |
| Entidades nombradas | Tensiones | Tags Penn |
| Whitepace | Verbos | Típico |
| Datos mundiales | Normalización | Barrer |
| Combate confuso | Mecanografiado | Mutación |
| Formas de raíz | | |
Negociaciones:
- El lenguaje como interfaz - por Spencer Kelly
- Codificación de bots de chat - por Kahwee Teng
- Sobre la escritura y los datos - por Spencer Kelly
Artículos:
- Geocoding Social Conversations con NLP y JavaScript - por Microsoft
- Receta de microservicio - por eventn
- Frase del juego de aventura con compromiso
- Construyendo juegos basados en texto - por Matt Eland
- Diversión con JavaScript en BigQuery - por Felipe Hoffa
- Procesamiento del lenguaje natural ... ¿en el navegador? - Por Charles Landau
Algunas aplicaciones divertidas:
- Prueba automatizada de Bechdel - por The Guardian
- Marco de generación de historias - por Jose Phrocca
- Blog de tumbler de listas - listas de Horse -Ebooks - por Michael Paulukonis
- Edición de video de la transcripción - por nueva teoría
- Verificación de hechos de extensión del navegador - por Alexander Kidd
- Siri atajo - por Michael Byrns
- Habilidad de Amazon - por Tajddin Maghni
- Tasking Slack -Bot - por Kevin Suh [ver más]
Comparaciones
- Compromiso y espacios
- Compromiso y nltk
Complementos:
Estas son algunas extensiones útiles:
Fechas
npm install compromise-dates
- .Dates () - Encuentre fechas como
June 8th o 03/03/18- .Dates (). get () - Resultado de JSON de inicio/finalización simple
- .Dates (). json () - Salida sobrecargada con metadatos de fecha
- .Dates (). Format ('') - Convierta las fechas en formatos específicos
- .Dates (). Toshortform () - Convertir 'Miércoles' a 'Wed', etc.
- .Dates (). tolongform () - Convertir 'febrero' a 'febrero', etc.
- .durations () -
2 weeks o 5mins- .durations (). get () - return simple json para duración
- .durations (). json () - salida sobrecargada con metadatos de duración
- .Times () -
4:30pm o half past five- .Times (). get () - Devuelve JSON simple para los tiempos
- .Times (). json () - salida sobrecargada con metadatos de tiempo
Estadísticas
npm install compromise-stats
.tfidf ({}) - clasifique las palabras por frecuencia y singularidad
.ngrams ({}) -Enumere todas las sub-frases repetidas, por conteo de palabras
.unigrams () - n -gramos con una palabra
.bigrams () - n -gramos con dos palabras
.trigrams () - n -gramos con tres palabras
.startgrams () - n -gramos, incluido el primer término de una frase
.endgrams () - n -gramos, incluido el último término de una frase
.EdgeGrams () - n -gramos, incluido el primer o último término de una frase
Discurso
npm install compromise-syllables
- .syllable () - dividiera cada término por su pronunciación típica
- .SoundSike () - producir una pronunciación estimada
Wikipedia
npm install compromise-wikipedia
- .wikipedia () - Reconciliación de artículos comprimidos
Mecanografiado
Estamos comprometidos con el soporte TypeScript/Deno, tanto en Main como en las pluginas oficiales:
import nlp from 'compromise'
import stats from 'compromise-stats'
const nlpEx = nlp . extend ( stats )
nlpEx ( 'This is type safe!' ) . ngrams ( { min : 1 } ) Docios mecanografiados
Limitaciones:
Slash-Support: Actualmente dividimos las cortes como palabras diferentes, como lo hacemos para los guiones. Entonces, cosas como esta no funcionan: nlp('the koala eats/shoots/leaves').has('koala leaves') //false
coincidencia entre orientaciones: por defecto, las oraciones son la abstracción de nivel superior. Los partidos entre-sentencia o de múltiples oraciones no son compatibles sin un complemento: nlp("that's it. Back to Winnipeg!").has('it back')//false
Sintaxis del partido anidado: el peligro de belleza de Regex es que puedes recurrir indefinidamente. Nuestra sintaxis de coincidencia es mucho más débil. Cosas como esta no son (todavía) posibles: doc.match('(modern (major|minor))? general') Las coincidencias complejas deben lograrse con declaraciones sucesivas .match () .
Analización de dependencia: la transformación adecuada de la oración requiere comprender el árbol de sintaxis de una oración, lo que no hacemos actualmente. ¡Deberíamos! Ayuda se buscan con esto.
Preguntas frecuentes
☂️ no es JavaScript también ...
¡Sí, lo es!
No estaba construido para competir con NLTK, y es posible que no se ajuste a todos los proyectos.
El procesamiento de cadenas también es sincrónico, y la paralelización de procesos de nodo es extraño.
Consulte aquí para obtener información sobre velocidad y rendimiento, y aquí para motivaciones del proyecto
? ¿Puede funcionar en mi Arduino-Watch?
¡Solo si es a prueba de agua!
Lea el inicio rápido para ejecutar compromiso en trabajadores, aplicaciones móviles y todo tipo de entornos divertidos.
? Compromiso en otros idiomas?
Tenemos horquillas de trabajo en progreso para alemán, francés, español e italiano en la misma filosofía.
Y necesito ayuda.
Construcciones parciales?
Ofrecemos una construcción de solo tokenize, que tiene la tagger POS sacada.
Pero de lo contrario, el compromiso no se sacude fácilmente.
Los métodos de etiquetado son competitivos y codiciosos, por lo que no se recomienda sacar las cosas.
Tenga en cuenta que sin una etiqueta POS completa, el Parser de contracción no funcionará perfectamente. ( (Spencer's Cool) vs. (casa de Spencer) )
Se recomienda ejecutar la biblioteca por completo.

Ver también:
En-Pos -Javascript muy inteligente POS-Tagger de Alex Corvi
NaturalNode - NLP estadístico más elegante en JavaScript
Winkjs -POS-Tagger, Tokenizer, Machine-Learning en JavaScript
Dariusk/Pos -JS - Fasttag Fork en JavaScript
Compendium -JS - POS y análisis de sentimientos en JavaScript
Lingüística de Nodebox - Conjugación, inflexión en JavaScript
Retext : utilidades de texto muy impresionantes en JavaScript
SuperScript - Motor de conversación en JS
JSPOS -JavaScript Build of the Time Taging Tagger probado
SPACIA - Tagger multilingüe rápido en C/Python
PROSA - Tagger rápido en Go by Joseph Kato
Textblob - Python Tagger
MIT