타협

겸손한 자연어 처리
npm install compromise
Spencer Kelly와 많은 기고자
타협은 텍스트를 데이터로 바꾸는
최선을 다합니다 .
그것은 제한적이고 합리적인 결정을 만듭니다.
생각만큼 똑똑하지 않습니다.
import nlp from 'compromise'
let doc = nlp ( 'she sells seashells by the seashore.' )
doc . verbs ( ) . toPastTense ( )
doc . text ( )
// 'she sold seashells by the seashore.'
전혀 화려하지 마십시오.
if ( doc . has ( 'simon says #Verb' ) ) {
return true
}
텍스트의 일부를 가져옵니다.
let doc = nlp ( entireNovel )
doc . match ( 'the #Adjective of times' ) . text ( )
// "the blurst of times?"
문서와 일치합니다
데이터 가져 오기 :
import plg from 'compromise-speech'
nlp . extend ( plg )
let doc = nlp ( 'Milwaukee has certainly had its share of visitors..' )
doc . compute ( 'syllables' )
doc . places ( ) . json ( )
/*
[{
"text": "Milwaukee",
"terms": [{
"normal": "milwaukee",
"syllables": ["mil", "wau", "kee"]
}]
}]
*/ JSON 문서
취성 파서의 문제를 피하십시오.
let doc = nlp ( "we're not gonna take it.." )
doc . has ( 'gonna' ) // true
doc . has ( 'going to' ) // true (implicit)
// transform
doc . contractions ( ) . expand ( )
doc . text ( )
// 'we are not going to take it..'
수축 문
그리고 데이터와 같은 주위에 물건을 채찍질합니다.
let doc = nlp ( 'ninety five thousand and fifty two' )
doc . numbers ( ) . add ( 20 )
doc . text ( )
// 'ninety five thousand and seventy two'
번호 문서
-실제로는-
let doc = nlp ( 'the purple dinosaur' )
doc . nouns ( ) . toPlural ( )
doc . text ( )
// 'the purple dinosaurs'
명사 문서
클라이언트 측에서 사용하십시오.
< script src =" https://unpkg.com/compromise " > </ script >
< script >
var doc = nlp ( 'two bottles of beer' )
doc . numbers ( ) . minus ( 1 )
document . body . innerHTML = doc . text ( )
// 'one bottle of beer'
</ script >
또는 마찬가지로 :
import nlp from 'compromise'
var doc = nlp ( 'London is calling' )
doc . verbs ( ) . toNegative ( )
// 'London is not calling'
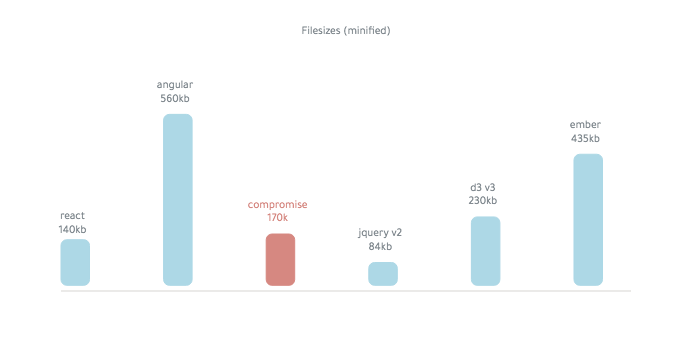
타협은 ~ 250kb (미니딩)입니다.
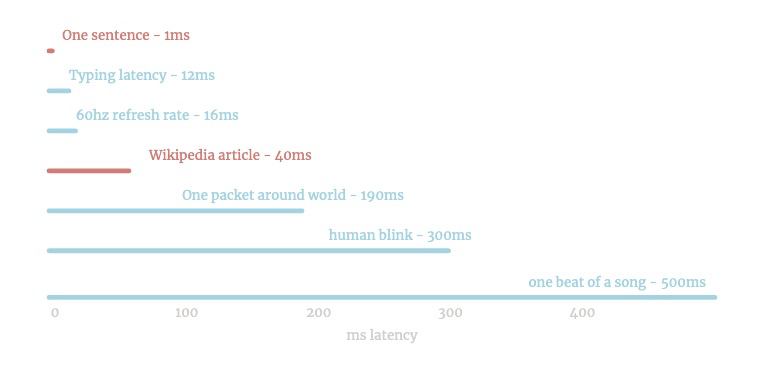
꽤 빠릅니다. Keypress에서 실행할 수 있습니다.
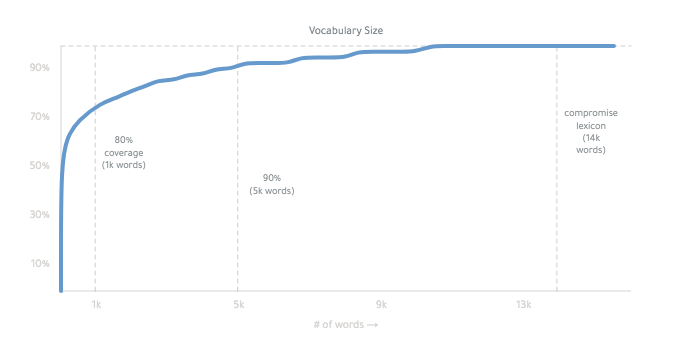
주로 기본 단어 목록의 모든 형태를 활용하여 작동합니다.
최종 어휘는 ~ 14,000 단어입니다.
작동 방식에 대한 자세한 내용은 여기를 참조하십시오. 이상해.
좋아요 -
compromise/one
단어, 문장 및 구두점의 tokenizer .
import nlp from 'compromise/one'
let doc = nlp ( "Wayne's World, party time" )
let data = doc . json ( )
/* [{
normal:"wayne's world party time",
terms:[{ text: "Wayne's", normal: "wayne" },
...
]
}]
*/ 토큰 화기 문서
타협/하나는 텍스트를 쪼개고 편리한 API로 감싸고,
/하나는 빠릅니다. 대부분의 문장은 10 밀리 초의 10 분의 1을 차지합니다.
~ 1MB 의 텍스트 1 초 또는 10 개의 Wikipedia 페이지를 수행 할 수 있습니다.
무한 농담은 3 초를 차지합니다.
타협 속도로 병렬화하거나 텍스트를 스트리밍 할 수도 있습니다.
compromise/two
part-of-speech 거 및 문법 간 프리터.
import nlp from 'compromise/two'
let doc = nlp ( "Wayne's World, party time" )
let str = doc . match ( '#Possessive #Noun' ) . text ( )
// "Wayne's World"
태그 문서
타협/둘은 각 단어의 기본 문법을 자동으로 계산합니다.
이것은 사람들이 때때로 깨닫는 것보다 더 유용합니다.
가벼운 문법은 청정 템플릿을 작성하고 정보에 더 가까이 다가 갈 수 있도록 도와줍니다.
타협에는 83 개의 태그가 있으며 잘 생긴 그래프로 배열됩니다.
#FirstName → #Person → #ProperNoun → #Noun
doc.debug() 실행하여 각 단어의 문법을 볼 수 있습니다.
nlp.verbose('tagger') 로 각 태그에 대한 추론을 볼 수 있습니다.
Penn Tags를 선호하는 경우 다음과 같이 도출 할 수 있습니다.
let doc = nlp ( 'welcome thrillho' )
doc . compute ( 'penn' )
doc . json ( )
compromise/three
Phrase 및 문장 툴링.
import nlp from 'compromise/three'
let doc = nlp ( "Wayne's World, party time" )
let str = doc . people ( ) . normalize ( ) . text ( )
// "wayne"
선택 문서
타협/3은 텍스트의 일부를 확대 하고 작동하는 일련의 툴링 세트입니다.
.numbers() 예를 들어 문서의 모든 숫자를 가져 와서 .subtract() 와 같은 새로운 메소드로 확장합니다.
문구 또는 단어 그룹이 있으면 .json() 로 추가 메타 데이터를 볼 수 있습니다.
let doc = nlp ( 'four out of five dentists' )
console . log ( doc . fractions ( ) . json ( ) )
/*[{
text: 'four out of five',
terms: [ [Object], [Object], [Object], [Object] ],
fraction: { numerator: 4, denominator: 5, decimal: 0.8 }
}
]*/ let doc = nlp ( '$4.09CAD' )
doc . money ( ) . json ( )
/*[{
text: '$4.09CAD',
terms: [ [Object] ],
number: { prefix: '$', num: 4.09, suffix: 'cad'}
}
]*/
API
타협/하나
산출
- .text () - 문서를 텍스트로 반환합니다
- .json () - 문서를 데이터로 반환합니다
- .debug () - 해석 된 문서를 예쁘게 인쇄합니다
- .out () - 명명 또는 사용자 정의 출력
- .html ({}) - 일치하는 경우 사용자 정의 HTML 태그를 출력합니다
- .wrap ({}) - 문서 일치에 대한 사용자 정의 출력을 생성합니다
utils
- .found [getter] -이 문서가 비어 있습니까?
- .docs [getter] 용어 객체를 JSON으로 가져옵니다
- .length [getter] - 문서에서 문자의 # 계산 (문자열 길이)
- .isview [getter] - 타협 객체를 식별하십시오
- .compute () - 문서에서 이름의 이름을 실행합니다
- .Clone () - 딥 코피 문서, 참조가 남아 있지 않도록
- . termlist () - 일치중인 모든 용어 객체의 평평한 목록을 반환합니다.
- .cache ({}) - 속도가 설득하기 위해 문서의 현재 상태를 동결하십시오.
- .Uncache () - 현재 문서의 현재 상태를 사용하지 않으므로 변환 될 수 있습니다.
- .freeze ({}) -이 용어로 태그가 제거되는 것을 방지합니다.
- .unfreeze ({}) - 기본적으로 태그를 다시 변경하도록 허용합니다
접근자
- .all () - 전체 원본 문서를 반환합니다 ( 'Zoom Out')
- .terms () - 각 개별 용어 별 분할 결과
- .first (n) - 첫 번째 결과 만 사용하십시오 (들)
- .last (n) - 마지막 결과 만 사용하십시오 (들)
- .Slice (n, n) - 결과의 하위 집합을 잡습니다
- .eq (n) - n 번째 결과 만 사용하십시오
- .firstterms () - 각 경기에서 첫 번째 단어를 얻습니다
- .lastterms () - 각 경기에서 끝 단어를 얻습니다
- .fullSentences () - 각 일치에 대한 전체 문장을 얻습니다
- .groups () - 경기에서 이름이 지정된 캡처 그룹을 잡습니다
- .WordCount () - 문서의 용어 # 계산
- .confidence () - POS 태그 해석의 평균 점수
성냥
(매치 메소드는 매치시 틴을 사용합니다.)
- .match ( '') - 새 문서를 부모로 반환합니다.
- .not ( '') -이를 제외한 모든 결과를 반환합니다
- .MatchOne ( '') - 첫 번째 일치 만 반환합니다
- .if ( '') - 각 현재 문구를 반환합니다.이 일치가 포함 된 경우에만 ( '만')
- .ifno ( '') -이 일치가있는 현재 문구를 필터링합니다 ( 'notif')
- .HAS ( '') -이 일치가 존재하면 부울을 반환합니다
- .pore ( '') - 각 문구에서 일치하기 전에 모든 용어를 반환합니다.
- .After ( '') - 각 문구에서 일치 후 모든 용어를 반환합니다.
- .union () - 복합 경기없이 결합 된 일치를 반환합니다
- .intersection () - 중복 일치 만 반환합니다
- .complement () - 다른 경기가 아닌 모든 것을 얻습니다
- .Settle () - 일치에서 오버랩을 제거합니다
- .growright ( '') - 각 경기 직후 일치하는 용어 추가
- .growleft ( '') - 각 경기 직전에 일치하는 용어 추가
- . 그로우 ( '') - 각 경기 전후에 일치하는 항을 추가
- .sweep (net) - 문서에 일련의 일치 객체를 적용
- .spliton ( '') - 매치마다 세 부분이있는 문서를 반환합니다 ( 'spliton')
- .splitbefore ( '') - 각 일치 세그먼트 앞에 문구를 파티션합니다
- .SplitAfter ( '') - 각 일치하는 세그먼트 다음에 문구를 파티션합니다
- .join () - 각 경기에서 인접한 용어를 병합합니다
- .joinif (LeftMatch, RightMatch) - 주어진 조건에 따라 인접한 용어를 병합합니다.
- .Lookup ([]) - 문자열 일치 배열에 대한 빠른 찾기
- .autofill () - 문서에서 유형 - 승인 가정을 만듭니다
꼬리표
- .tag ( '') - 주어진 태그를 모든 용어로 제공하십시오
- .TagSafe ( '') - 현재 태그와 일치하는 경우 용어에 태그 만 적용합니다.
- .untag ( '') - 주어진 용어 에서이 용어를 제거하십시오
- .Canbe ( '') -이 태그가 될 수있는 용어 만 반환합니다.
사례
- .TOLOWERCASE () - 모든 용어의 모든 문자를 하단으로 돌립니다.
- .toupperCase () - 모든 용어의 모든 문자를 대문자로 돌립니다.
- .totitleCase () - 각 용어의 첫 번째 문자를 상단으로 생각합니다
- .tocamelcase () - 흰색 스페이스를 제거하고 각 용어를 제목으로 삼으십시오
공백
- .pre ( '') - 각 경기 전에이 구두점 또는 공백을 추가하십시오.
- .post ( '') - 각 경기 후이 구두점 또는 공백을 추가합니다.
- .trim () - 시작 및 끝 공백을 제거합니다
- .hyphenate () - 하이픈과 단어를 연결하고 공백을 제거하십시오
- .dehyphenate () - 단어 사이에서 하이픈을 제거하고 공백을 설정하십시오
- .ToQuotations () -이 일치에 따옴표를 추가합니다
- .toparentheses () -이 일치 주위에 괄호를 추가합니다
루프
- .map (fn) - 함수를 통해 각 문구를 실행하고 새 문서를 만듭니다.
- .foreach (fn) - 개별 문서로 각 문구에서 함수를 실행합니다.
- .filter (fn) - true를 반환하는 문구 만 반환합니다
- .find (fn) - 일치하는 첫 번째 문구만으로 문서를 반환합니다.
- .Some (fn) - 일치하는 문구가있는 경우 true 또는 false를 반환합니다.
- .RANDOM (FN) - 결과의 하위 집합을 샘플링합니다
끼워 넣다
- .replace (일치, 교체) - 새 콘텐츠로 일치하는 검색 및 교체
- .replaceWith (replace) - 대체 된 새 텍스트
- .remove () - 문서 에서이 용어를 완전히 제거하십시오
- .Insertbefore (str) -이 새로운 용어를 각 경기의 전면에 추가합니다 (prepend)
- .insertafter (str) - 각 경기 끝에이 새로운 용어를 추가합니다 (Append)
- .concat () -이 새로운 것을 끝에 추가하십시오
- .Swap (Fromlemma, Tolemma) - 적절한 컨쥬 게이션을 사용하여 루트 단어의 스마트 대체
변환
- .SORT ( 'method') - 매치 순서 재발 (제자리에)
- .reverse () - 성냥 순서를 반전하지만 단어는 아닙니다.
- .normanize ({}) - 다양한 방식으로 텍스트를 정리하십시오
- .unique () - 중복 일치를 제거합니다
lib
(이 방법은 기본 nlp 객체에 있습니다)
nlp.tokenize (str) - pos -tagging을 실행하지 않고 텍스트를 구문 분석합니다
nlp.lazy (str, match) - 최소한의 분석으로 텍스트를 스캔
nlp.plugin ({}) - 타협 - 플러그 인에서 혼합
NLP.PARSEMATCH (STR) - JSON에 대한 일치 문을 미리 정리합니다
nlp.world () - 도서관 내부를 잡거나 변경합니다
nlp.model () - 모든 현재 언어 데이터를 가져옵니다
nlp.methods () - 내부 방법을 잡거나 변경합니다
nlp.hooks () - 어떤 컴퓨팅 메소드가 자동으로 실행되는지 확인하십시오
NLP.VERBOSE (모드) - 디버깅에 대한 의사 결정을 기록하십시오
NLP.Version- 라이브러리의 현재 Semver 버전
nlp.addwords (obj, isfrozen?) - 사전에 새 단어를 추가하십시오
nlp.addtags (OBJ) - Tagset에 새 태그를 추가합니다
nlp.typeahead (ARR) - 자동 필 사전에 단어를 추가하십시오
nlp.buildtrie (ARR) - 단어 목록을 빠른 조회 양식으로 컴파일
nlp.buildnet (ARR) - 일치 목록을 빠른 경기 양식으로 컴파일합니다.
타협/2 :
수축
- .contractions () - "하지 않았다"와 같은 것
- .contractions (). expand () - "do n't"와 같은 것들
- .Contract () - "하지 않았다"와 같은 것
타협/3 :
명사
- .nouns () - 명사로 태그가 지정된 후속 용어를 반환합니다.
- .nouns (). json () - 명사 메타 데이터로 과부하 된 출력
- .nouns (). parse () - 토큰 화 된 명사를 얻습니다
- .nouns (). isplural () - 복수 명사 만 반환합니다
- .nouns (). issingular () - 단수 명사 만 반환합니다
- .nouns (). toplural () -
'football captain' → 'football captains' - .nouns (). Tosingular () -
'turnovers' → 'turnover' - .nouns (). 형용사 () -이 명사를 설명하는 형용사를 얻습니다
동사
- .verbs () - 동사로 태그가 지정된 후속 용어를 반환합니다.
- .verbs (). json () - 동사 메타 데이터로 과부하 된 출력
- .verbs (). parse () - 토큰 화 된 동사 - 판
- .verbs (). ufforms () - 동사 동작을 수행하는 일
- .verbs (). adverbs () -이 동사를 설명하는 부사를 반환합니다.
- .verbs (). issingular () - 'Spencer Walks'와 같은 단수 동사를 반환합니다.
- .verbs (). isplural () - 복수 동사 'We Walk'와 같은 복수 동사 반환
- .verbs (). isimperative () - '먹기!'와 같은 지시 동사 만 있습니다.
- .verbs (). topasttense () -
'will go' → 'went' - .verbs (). TopResentTense () -
'walked' → 'walks' - .verbs (). tofutureTense () -
'walked' → 'will walk' - .verbs (). toinfinitive () -
'walks' → 'walk' - .verbs (). Togerund () -
'walks' → 'walking' - .verbs (). TopastPartIficle () -
'drive' → 'had driven' - .verbs (). conjugate () -이 동사의 모든 컨쥬 게이션을 반환합니다
- .verbs (). isnegative () - 'not', 'never'또는 'no'로 반환 동사
- .verbs (). ispositive () - 'not', 'never'또는 'no'가없는 동사 만
- .verbs (). tonegative () -
'went' → 'did not go' - .verbs (). topositive () -
"didn't study" → 'studied'
숫자
- .numbers () - 모든 서면 및 숫자 값을 잡습니다
- .numbers (). parse () - 토큰 화 된 숫자 구절을 얻습니다
- .numbers (). get () - 간단한 JavaScript 번호를 가져옵니다
- .numbers (). json () - 숫자 메타 데이터가있는 과부하 출력
- .numbers (). tonumber () - '5'를
5 로 변환합니다 - .numbers (). Tolocalestring () - 쉼표를 추가하거나 숫자에 대한 더 좋은 형식
- .numbers (). totext () - '5'를
five 로 변환합니다 - .numbers (). Toordinal () - '5'를
fifth 또는 5th 변환합니다 - .numbers (). Tocardinal () - '5 번째'를
five 또는 5 로 변환합니다 - .numbers (). Isordinal () - 서수 만 반환합니다
- .numbers (). iscardinal () - 추기경 숫자 만 반환합니다
- .Numbers (). ISEALEL (n) -이 값으로 반환 번호
- .numbers (). Greaterthan (Min) - 반환 번호는 n보다 큰 숫자
- .numbers (). Lessthan (Max) - N보다 작은 반환 번호
- .numbers (). 간 (Min, Max) - Min과 Max 사이의 반환 번호
- .numbers (). Isunit (Unit) - 'km'과 같이 주어진 단위의 숫자 만 반환합니다.
- .numbers (). set (n) - n 숫자를 n으로 설정합니다
- .numbers (). Add (n) - n 씩 숫자를 늘리십시오
- .numbers (). suxcract (n) - n 숫자 감소
- .numbers (). excrement () - 숫자 증가 1
- .numbers (). exent () - 감소 숫자 1 씩
- .money () -
'$2.50' 과 같은 것들- .money (). get () - 돈의 양자 금액을 검색합니다
- .money (). json () - 통화 + 번호 정보
- .money (). Currency () - 돈이 어떤 통화에 있는지
- .fractions () - '2/3rds'또는 '5 개 중 1 개'
- .fractions (). parse () - 토큰 화 분수를 얻습니다
- .fractions (). get () - 간단한 분자, 분모 데이터
- .fractions (). JSON () - JSON 메서드는 분수 데이터로 과부하되었습니다
- .fractions (). todecimal () - '2/3' -> '0.66'
- .fractions (). 정규화 () - '10 개 중 4 개' -> '4/10'
- .fractions (). toText () - '4/10' -> 'Four Tenths'
- .fractions (). ToperCentage () - '4/10' -> '40%'
- .percentages () - '2.5%'좋아요
- .percentages (). get () - 백분율 번호 / 100을 반환합니다
- .percentages (). json () - JSON 백분율 정보가 과부하되었습니다
- .percentages (). tofraction () - '80%' ->'8/10 '
문장
- .Sentences () - 추가 방법으로 문장 클래스를 반환합니다
- .Sentences (). json () - 문장 메타 데이터와 함께 과부하 된 출력
- .Sentences (). Topasttense () -
he walks -> he walked - .Sentences (). TopResentTense () -
he walked -> he walks - .Sentences (). tofutureTense () -
he walks -> he will walk - .Sentences (). toinfinitive () -동사 루트 형식
he walks -> he walk - .Sentences (). ToneGative () -
he walks -> he didn't walk - .Sentences (). isquestion () - a와 함께 질문을 반환하십시오
? - .sentences (). isexclamation () - retences 문장이 a
! - .Sentences (). isstatement () -없는 문장없이
? 또는 !
형용사
- .adjectives () -
'quick' 것과 같은 것들- .adjectives (). json () - 형용사 메타 데이터를 얻습니다
- .adjectives (). conjugate () -이 형용사의 모든 변곡을 반환합니다
- .adjectives (). adverbs () -이 형용사를 설명하는 부사를 얻습니다
- .adjectives (). tocomparative () - 'Quick' -> '빠른'
- .adjectives (). toSuperlative () - 'Quick' -> 'Quickest'
- .adjectives (). toadverb () - 'Quick' -> '빠르게'
- .adjectives (). tonoun () - 'Quick' -> 'Quickness'
기타 선택
- .Clauses () -문장 분할 문장을 다기 문구로 분리합니다
- .Chunks () -분할 문장 명사 -PHRASES 및 VERB-PHRASES
- .hyphenated () - 하이픈 또는 대시와 같은
'wash-out' 과 연결된 모든 용어 - .PhonEnumbers () -
'(939) 555-0113' 과 같은 것들 - .hashtags () -
'#nlp' 와 같은 것 - .emails () -
'[email protected]' 과 같은 것들 - .emoticons () - 같은 것
:) - .emojis () - 좋아요
? - .atmentions () -
'@nlp_compromise' 와 같은 것 - .urls () -
'compromise.cool' 과 같은 것들 - .Pronouns () -
'he' 와 같은 것 - .conjunctions () -
'but' 와 같은 것들 - .prepositions () -
'of' 와 같은 것들 - .Abbriations () -
'Mrs.' 와 같은 것들 - .people () - 'John F. Kennedy'와 같은 이름
- .people (). json () - 개인 이름 메타 데이터를 얻습니다
- .people (). parse () - 개인 이름 해석을 얻습니다
- .Places () - '파리, 프랑스'
- . 기르기 () - 'Google, Inc'와 같은
- .Topics () -
people() + places() + organizations() - .adverbs () -
'quickly' 와 같은 것들- .adverbs (). json () - Adverb 메타 데이터를 얻습니다
- .acronyms () -
'FBI' 와 같은 것들- .acronyms (). Strip () - 약어에서 기간을 제거합니다
- .acronyms (). addperiods () - 약어에 기간을 추가합니다
- .parentheses () - 내부에 모든 것을 반환합니다 (괄호)
- .parentheses (). Strip () - 브래킷을 제거합니다
- .possessives () -
"Spencer's" 와 같은 것들- .possessives (). Strip () - "Spencer 's" -> "Spencer"
- .quotations () - 쌍을 이루는 따옴표 마크 내부에서 모든 용어를 반환합니다
- .quotations (). Strip () - 따옴표를 제거합니다
- .Slashes () - 슬래시로 그룹화 된 모든 용어를 반환합니다
- .slashes (). split () - '사랑/증오'를 '사랑 증오'로 돌리십시오.
.연장하다():
이 라이브러리에는 영어 문법을위한 사려 깊고 상식적인 기준이 있습니다.
당신은 자유롭게 변경하거나 낭비 할 수 있습니다.
가장 쉬운 부분은 주어진 단어에 대한 태그를 제안하는 것입니다.
let myWords = {
kermit : 'FirstName' ,
fozzie : 'FirstName' ,
}
let doc = nlp ( muppetText , myWords ) 또는 타협 플루인으로 더 무거운 변화를 만듭니다.
import nlp from 'compromise'
nlp . extend ( {
// add new tags
tags : {
Character : {
isA : 'Person' ,
notA : 'Adjective' ,
} ,
} ,
// add or change words in the lexicon
words : {
kermit : 'Character' ,
gonzo : 'Character' ,
} ,
// change inflections
irregulars : {
get : {
pastTense : 'gotten' ,
gerund : 'gettin' ,
} ,
} ,
// add new methods to compromise
api : View => {
View . prototype . kermitVoice = function ( ) {
this . sentences ( ) . prepend ( 'well,' )
this . match ( 'i [(am|was)]' ) . prepend ( 'um,' )
return this
}
} ,
} ) .plugin () 문서
문서 :
부드러운 소개 :
- #1) 입력 → 출력
- #2) 매치 및 변환
- #3) 채팅 보트 만들기
선적 서류 비치:
| 개념 | API | 플러그인 |
|---|
| 정확성 | 접근자 | 형용사 |
| 캐싱 | 생성자 방법 | 날짜 |
| 사례 | 수축 | 내보내다 |
| 파일 크기 | 끼워 넣다 | 해시시 |
| 내부 | JSON | HTML |
| 정당화 | 캐릭터 오프셋 | 키 프레스 |
| 사전 | 루프 | ngrams |
| 매치 신탁 | 성냥 | 숫자 |
| 성능 | 명사 | 단락 |
| 플러그인 | 산출 | 주사 |
| 프로젝트 | 선택 | 문장 |
| 술래 | 정렬 | 음절 |
| 태그 | 나뉘다 | 발음 |
| 토큰 화 | 텍스트 | 엄격한 |
| 이름이 지정되었습니다 | utils | 펜 태그 |
| 공백 | 동사 | TypeAhead |
| 세계 데이터 | 표준화 | 스위프 |
| 퍼지 매칭 | TypeScript | 돌연변이 |
| 루트 형식 | | |
대화 :
- 인터페이스로서의 언어 -Spencer Kelly의 언어
- 코딩 채팅 봇 - Kahwee Teng의
- 타이핑 및 데이터 - Spencer Kelly
조항:
- NLP 및 JavaScript와의 지오 코딩 - Microsoft의 소셜 대화
- 마이크로 서비스 레시피 - eventn의
- 모험 게임 문장 타협으로 구문 분석
- Matt Eland의 텍스트 기반 게임 구축
- Felipe Hoffa의 BigQuery에서 JavaScript와 함께 재미
- 자연어 처리 ... 브라우저에서? -CHARLES LANDAU
몇 가지 재미있는 응용 프로그램 :
- 가디언의 자동 Bechdel 테스트
- 스토리 세대 프레임 워크 - Jose Phrocca의
- 목록의 텀블러 블로그 - 마이클 Paulukonis
- 전사에서 비디오 편집 - 새로운 이론에 의한
- 브라우저 확장 사실 확인 - Alexander Kidd
- Siri 바로 가기 - Michael Byrns의
- Amazon Skill -Tajddin Maghni의
- 태스크 빙 슬랙 버전 - 작성자 : Kevin Suh [더보기]
비교
플러그인 :
이들은 유용한 확장입니다.
날짜
npm install compromise-dates
- .Dates () -
June 8th 또는 03/03/18 과 같은 날짜를 찾으십시오- .Dates (). get () - 간단한 시작/종료 JSON 결과
- .Dates (). json () - 날짜 메타 데이터와 함께 과부하 된 출력
- .Dates (). 형식 ( '') - 날짜를 특정 형식으로 변환합니다
- .Dates (). TOSHORTFORM () - '수요일'을 '수'등으로 변환합니다
- .Dates (). tolongform () - 'Feb'를 '2 월'등으로 변환합니다
- .durations ()
2 weeks 또는 5mins- .durations (). get () - 기간 동안 간단한 JSON을 반환합니다
- .durations (). json () - 기간 메타 데이터로 과부하 된 출력
- .times () -4
4:30pm 또는 half past five- .times (). get () - 시간 동안 간단한 JSON을 반환합니다
- .times (). json () - 시간 메타 데이터로 과부하 된 출력
통계
npm install compromise-stats
.tfidf ({}) - 주파수와 독창성별로 단어를 순위합니다
.NGRAMS ({}) -모든 반복 하위 프레이즈를 Word-Count로 나열하십시오
.unigrams () -N -Grams 한 단어
.bigrams () -N -Grams 두 단어
.trigrams () -N -Grams는 세 단어입니다
.Startgrams () - 문구의 첫 번째 용어를 포함한 N -Grams
.endgrams () - 문구의 마지막 용어를 포함한 N -Grams
.Edgegrams () - 문구의 첫 번째 또는 마지막 용어를 포함한 N -Grams
연설
npm install compromise-syllables
- .syllables () - 각 용어를 일반적인 발음으로 분할하십시오
- .sounds like () - 추정 발음을 생성합니다
위키 백과
npm install compromise-wikipedia
TypeScript
우리는 메인과 공식 플루그인 모두에서 TypeScript/Deno 지원에 전념하고 있습니다.
import nlp from 'compromise'
import stats from 'compromise-stats'
const nlpEx = nlp . extend ( stats )
nlpEx ( 'This is type safe!' ) . ngrams ( { min : 1 } ) TypeScript DOC
제한 사항 :
슬래시 지원 : 우리는 현재 하이픈과 마찬가지로 슬래시를 다른 단어로 분할합니다. 그래서 이와 같은 것들이 작동하지 않습니다 : nlp('the koala eats/shoots/leaves').has('koala leaves') //false
중심 간 일치 : 기본적으로 문장은 최상위 수준의 추상화입니다. 플러그인 없이는 interentence 또는 Multi-Sentence 경기 nlp("that's it. Back to Winnipeg!").has('it back')//false 지원되지 않습니다.
중첩 성냥 구문 : Regex의 위험의 아름다움은 무기한으로 되돌릴 수 있다는 것입니다. 우리의 매치 구문은 훨씬 약합니다. 이와 같은 것들은 (아직) 가능하지 않습니다 : doc.match('(modern (major|minor))? general') 복잡한 일치는 .match () 문을 사용하여 달성해야합니다.
의존성 구문 분석 : 적절한 문장 변환은 현재하지 않는 문장의 구문 트리를 이해해야합니다. 우리는해야합니다! 도움이 필요합니다.
FAQ
☂️도 JavaScript가 아닙니다 ...
그래!
NLTK와 경쟁하기 위해 구축되지 않았으며 모든 프로젝트에 맞지 않을 수 있습니다.
문자열 처리도 동기식이며 병렬 노드 프로세스는 이상합니다.
속도 및 성능에 대한 자세한 내용은 여기를 참조하고 프로젝트 동기 부여는 여기를 참조하십시오.
? 내 Arduino-Watch에서 실행할 수 있습니까?
방수 인 경우에만!
작업자, 모바일 앱 및 모든 종류의 재미있는 환경에서 타협을 실행하려면 빠른 시작을 읽으십시오.
? 다른 언어로 타협합니까?
우리는 같은 철학에서 독일, 프랑스어, 스페인어 및 이탈리아어를위한 진행중인 포크를 가지고 있습니다.
도움이 필요합니다.
부분 빌드?
우리는 POS-Tagger가 풀린 토큰 화 전용 빌드를 제공합니다.
그러나 그렇지 않으면 타협은 나무로 쉽게 흔들리지 않습니다.
태깅 방법은 경쟁력이 있고 탐욕 스럽기 때문에 물건을 꺼내는 것이 좋습니다.
완전한 pos 태그가 없으면 수축-부서가 완벽하게 작동하지 않습니다. ( (Spencer 's Cool) vs. (Spencer's House)) )
라이브러리를 완전히 실행하는 것이 좋습니다.
또한 참조 :
EN-POS- Alex Corvi의 매우 영리한 JavaScript pos-tagger
NaturalNode- JavaScript의 Fancier 통계 NLP
Winkjs- POS-TAGGER, 토큰 화기, JavaScript의 기계 학습
DARIUSK/POS -JS- JavaScript 의 Fasttag Fork
Compendium -JS- JavaScript의 POS 및 감정 분석
노드 박스 언어학 - 컨쥬 게이션, 자바 스크립트의 변곡
RETEXT- JavaScript의 매우 인상적인 텍스트 유틸리티
슈퍼 스크립트 - JS의 대화 엔진
JSPOS- 시간 테스트 된 브릴 태거의 JavaScript 빌드
Spacy- C/Python의 빠른, 다국어 태그
산문 - 조셉 카토의 빠른 태그
TextBlob -Python Tagger
MIT