compromis

MODESTE Traitement du langage naturel
npm install compromise
par Spencer Kelly et de nombreux contributeurs
Français • allemand • Italien • Espagnol
Ne le trouvez pas étrange,
Compromis
essaie de transformer le texte en données.
Il prend des décisions limitées et sensées.
Ce n'est pas aussi intelligent que vous le pensez.
import nlp from 'compromise'
let doc = nlp ( 'she sells seashells by the seashore.' )
doc . verbs ( ) . toPastTense ( )
doc . text ( )
// 'she sold seashells by the seashore.'
Ne soyez pas fantaisiste, du tout:
if ( doc . has ( 'simon says #Verb' ) ) {
return true
}
Saisissez des parties du texte:
let doc = nlp ( entireNovel )
doc . match ( 'the #Adjective of times' ) . text ( )
// "the blurst of times?"
Match Docs
et obtenir des données:
import plg from 'compromise-speech'
nlp . extend ( plg )
let doc = nlp ( 'Milwaukee has certainly had its share of visitors..' )
doc . compute ( 'syllables' )
doc . places ( ) . json ( )
/*
[{
"text": "Milwaukee",
"terms": [{
"normal": "milwaukee",
"syllables": ["mil", "wau", "kee"]
}]
}]
*/ Docs JSON
Évitez les problèmes des analyseurs fragiles:
let doc = nlp ( "we're not gonna take it.." )
doc . has ( 'gonna' ) // true
doc . has ( 'going to' ) // true (implicit)
// transform
doc . contractions ( ) . expand ( )
doc . text ( )
// 'we are not going to take it..'
Docs de contraction
Et fouetter les trucs comme si ce sont des données:
let doc = nlp ( 'ninety five thousand and fifty two' )
doc . numbers ( ) . add ( 20 )
doc . text ( )
// 'ninety five thousand and seventy two'
nombres documents
-CACAUSE IL EST ES-
let doc = nlp ( 'the purple dinosaur' )
doc . nouns ( ) . toPlural ( )
doc . text ( )
// 'the purple dinosaurs'
Docs de noms
Utilisez-le sur le côté client:
< script src =" https://unpkg.com/compromise " > </ script >
< script >
var doc = nlp ( 'two bottles of beer' )
doc . numbers ( ) . minus ( 1 )
document . body . innerHTML = doc . text ( )
// 'one bottle of beer'
</ script >
ou de même:
import nlp from 'compromise'
var doc = nlp ( 'London is calling' )
doc . verbs ( ) . toNegative ( )
// 'London is not calling'
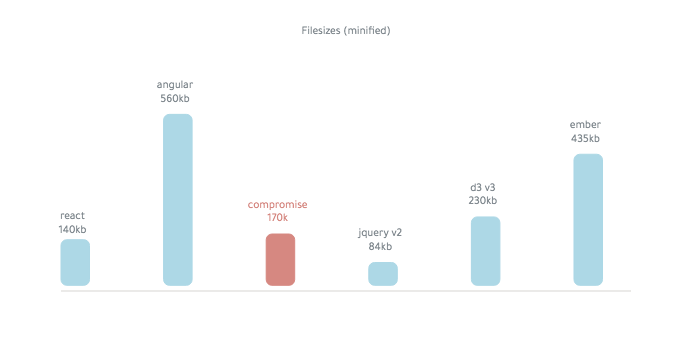
Le compromis est d'environ 250 Ko (minifié):
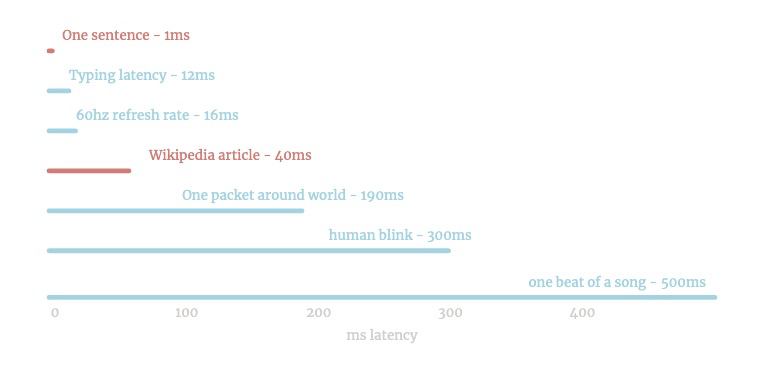
C'est assez rapide. Il peut fonctionner sur la pression de Keyp:
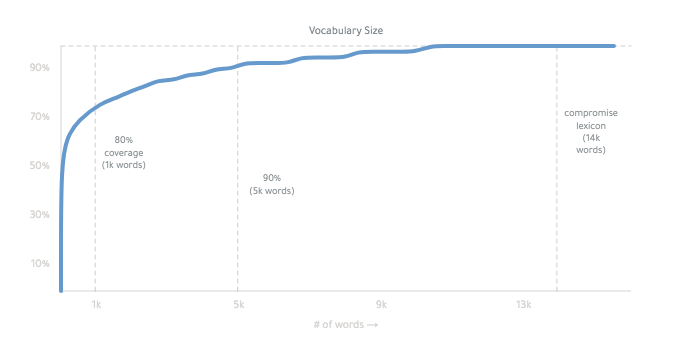
Il fonctionne principalement en conjuguant toutes les formes d'une liste de mots de base.
Le lexique final est d'environ 14 000 mots:
Vous pouvez en savoir plus sur la façon dont cela fonctionne, ici. C'est bizarre.
d'accord -
compromise/one
Un tokenizer de mots, de phrases et de ponctuation.
import nlp from 'compromise/one'
let doc = nlp ( "Wayne's World, party time" )
let data = doc . json ( )
/* [{
normal:"wayne's world party time",
terms:[{ text: "Wayne's", normal: "wayne" },
...
]
}]
*/ Docs à jetons
Compromis / One divise votre texte, l'enveloppe dans une API pratique,
et ne fait rien d'autre -
/ L'une est rapide - la plupart des phrases prennent un 10e de milliseconde.
Il peut faire ~ 1 Mo de texte par seconde - ou 10 pages Wikipedia.
Infinite Jest prend 3s.
Vous pouvez également paralléliser ou y diffuser du texte avec une vitesse de compromis.
compromise/two
Un étiqueteur part-of-speech et une grammaire-interpréter.
import nlp from 'compromise/two'
let doc = nlp ( "Wayne's World, party time" )
let str = doc . match ( '#Possessive #Noun' ) . text ( )
// "Wayne's World"
Docs du tagger
Compromis / deux calcule automatiquement la grammaire très basique de chaque mot.
C'est plus utile que les gens ne le pensent parfois.
La grammaire légère vous aide à écrire des modèles plus propres et à vous rapprocher des informations.
Le compromis a 83 balises , disposées dans un beau graphique.
#FirstName → #Serson → #propernoun → #noun
Vous pouvez voir la grammaire de chaque mot en exécutant doc.debug()
Vous pouvez voir le raisonnement pour chaque balise avec nlp.verbose('tagger') .
Si vous préférez les balises Penn , vous pouvez les dériver avec:
let doc = nlp ( 'welcome thrillho' )
doc . compute ( 'penn' )
doc . json ( )
compromise/three
Phrase et outillage de phrases.
import nlp from 'compromise/three'
let doc = nlp ( "Wayne's World, party time" )
let str = doc . people ( ) . normalize ( ) . text ( )
// "wayne"
Docs de sélection
Compromis / Three est un ensemble d'outillage pour zoomer et fonctionner sur certaines parties d'un texte.
.numbers() saisit tous les nombres dans un document, par exemple - et l'étend avec de nouvelles méthodes, comme .subtract() .
Lorsque vous avez une phrase ou un groupe de mots, vous pouvez voir des métadonnées supplémentaires à ce sujet avec .json()
let doc = nlp ( 'four out of five dentists' )
console . log ( doc . fractions ( ) . json ( ) )
/*[{
text: 'four out of five',
terms: [ [Object], [Object], [Object], [Object] ],
fraction: { numerator: 4, denominator: 5, decimal: 0.8 }
}
]*/ let doc = nlp ( '$4.09CAD' )
doc . money ( ) . json ( )
/*[{
text: '$4.09CAD',
terms: [ [Object] ],
number: { prefix: '$', num: 4.09, suffix: 'cad'}
}
]*/
API
Compromis / un
Sortir
- .Text () - Renvoyez le document en tant que texte
- .json () - Renvoyez le document sous forme de données
- .Debug () - A assez imprimé le document interprété
- .out () - une sortie nommée ou personnalisée
- .html ({}) - Sortir des balises HTML personnalisées pour les correspondances
- .Wrap ({}) - produire une sortie personnalisée pour les correspondances de documents
Utils
- .found [Getter] - Ce document est-il vide?
- .Docs [Getter] Obtenez des objets à terme en tant que JSON
- .Length [Getter] - Comptez le # des caractères dans le document (longueur de chaîne)
- .isview [Getter] - Identifiez un objet de compromis
- .Compute () - Exécutez une analyse nommée sur le document
- .Clone () - Deep-Copy le document, de sorte qu'aucune référence ne reste
- .termList () - Renvoyez une liste plate de tous les objets à terme en correspondance
- .Cache ({}) - geler l'état actuel du document, pour les réseaux de vitesse
- .UnCache () - UN-gelier l'état actuel du document, il peut donc être transformé
- .freeze ({}) - Empêcher que les balises soient supprimées, en ces termes
- .unfreeze ({}) - Autoriser les balises à changer à nouveau, par défaut
Accessoires
- .all () - Renvoyez l'ensemble du document original («zoom arrière»)
- .terms () - Résultats de division par chaque terme individuel
- . premier (n) - Utilisez uniquement les premiers résultats (s)
- .Last (n) - Utilisez uniquement les derniers résultats (s)
- .slice (n, n) - Prenez un sous-ensemble des résultats
- .eq (n) - Utilisez uniquement le résultat nème
- .Firsterms () - Obtenez le premier mot de chaque match
- .lastterms () - Obtenez le mot final dans chaque match
- .fullSentences () - Obtenez la phrase entière pour chaque match
- .groups () - saisir tous les groupes de capture nommés à partir d'un match
- .wordCount () - Comptez le # des termes dans le document
- .Confidence () - Un score moyen pour les interprétations de balises POS
Correspondre
(Les méthodes de correspondance utilisent la correspondance de syntax.)
- .match ('') - Renvoyez un nouveau doc, avec celui-ci en tant que parent
- .pas ('') - Renvoyez tous les résultats sauf pour cela
- .matchone ('') - Renvoyez uniquement le premier match
- .i ('') - Renvoyez chaque phrase actuelle, seulement si elle contient cette correspondance ('seulement')
- .ifno ('') - filtrez toutes les phrases actuelles qui ont cette correspondance ('notif')
- .has ('') - Renvoyez un booléen si ce match existe
- .before ('') - Renvoyez tous les termes avant un match, dans chaque phrase
- .After ('') - Renvoyez tous les termes après un match, dans chaque phrase
- .Union () - retourner les matchs combinés sans doublons
- .INTERSECTION () - RETOUR uniquement les matchs en double
- .Complement () - Obtenez tout pas dans un autre match
- .Settle () - supprimer les chevauchements des correspondances
- .growright ('') - Ajoutez tous les termes correspondants immédiatement après chaque match
- .growleft ('') - Ajoutez tous les termes correspondants immédiatement avant chaque match
- .grow ('') - Ajoutez tous les termes correspondants avant ou après chaque match
- .sweep (net) - Appliquez une série d'objets de match au document
- .spliton ('') - Renvoyez un document avec trois parties pour chaque match ('Spliton')
- .splitbefore ('') - partitionner une phrase avant chaque segment correspondant
- .splitafter ('') - partitionner une phrase après chaque segment correspondant
- .join () - fusionnez tous les termes voisins de chaque match
- .JoinIF (LeftMatch, Rightmatch) - fusionnez tous les termes voisins dans des conditions données
- .lookup ([]) - trouver rapidement pour un tableau de correspondances de chaînes
- .Autofill () - Créer des hypothèses de type de type sur le document
Étiqueter
- .tag ('') - Donnez à tous les termes la balise donnée
- .tagsafe ('') - Appliquez une balise uniquement aux termes si elle est cohérente avec les balises actuelles
- .untag ('') - Supprimer ce terme des termes donnés
- .Canbe ('') - Renvoyez uniquement les termes qui peuvent être cette balise
Cas
- .TolowerCase () - Tournez chaque lettre de chaque trimestre en plus bas
- .ToupperCase () - Tournez chaque lettre de chaque terme en majuscules
- .ToTitleCase () - Case supérieure La première lettre de chaque terme
- .TocamelCase () - Supprimer les espaces et la cas de titre à chaque terme
Espace blanc
- .pre ('') - Ajoutez cette ponctuation ou ce Whitespace avant chaque match
- .Post ('') - Ajoutez cette ponctuation ou ce Whitespace après chaque match
- .trim () - supprimer le début et la fin des espaces
- .hyphénate () - Connectez les mots à trait d'union et retirez l'espace blanc
- .dehyphénate () - Retirez les traits de traits entre les mots et définissez l'espace blanc
- .Toquotations () - Ajouter des guillemets autour de ces matchs
- .Toparentheses () - Ajouter des supports autour de ces matchs
Boucles
- .map (fn) - Exécutez chaque phrase via une fonction et créez un nouveau document
- .ForEach (FN) - Exécutez une fonction sur chaque phrase, en tant que document individuel
- .filter (fn) - Renvoyez uniquement les phrases qui renvoient vrai
- .find (fn) - Renvoyez un document avec seulement la première phrase qui correspond
- .Some (fn) - retourner vrai ou faux s'il y a une phrase correspondante
- .Random (FN) - Échantillonnant un sous-ensemble des résultats
Insérer
- .replace (correspondant, remplacer) - Rechercher et remplacer la correspondance par un nouveau contenu
- .replacewith (remplacer) - Substitut dans un nouveau texte
- .Remove () - supprimer complètement ces termes du document
- .InsertBefore (Str) - Ajoutez ces nouveaux termes à l'avant de chaque match (Présenter)
- .Insertafter (STR) - Ajoutez ces nouveaux termes à la fin de chaque match (ajouter)
- .Concat () - Ajoutez ces nouvelles choses à la fin
- .swap (Fromlemma, Tolemma) - Remplacement intelligent des mots racinaires, en utilisant une conjugaison appropriée
Transformer
- .sort ('méthode') - réorganisez l'ordre des matchs (en place)
- .reverse () - inverser l'ordre des matchs, mais pas les mots
- .Normalize ({}) - Nettoyez le texte de diverses manières
- .Unique () - Supprimer les correspondances en double
Lib
(ces méthodes sont sur l'objet nlp principal)
NLP.Tokenize (STR) - Parse Text sans exécuter
NLP.lazy (Str, Match) - Numéro à travers un texte avec une analyse minimale
nlp.plugin ({}) - mélanger dans un compromis-plugin
NLP.Parsematch (STR) - Pré-parse toute instruction de match dans JSON
nlp.world () - Grab ou modifier les internes de la bibliothèque
NLP.Model () - Saisissez toutes les données linguistiques actuelles
nlp.methods () - saisir ou modifier les méthodes internes
nlp.hooks () - voir quelles méthodes de calcul s'exécutent automatiquement
NLP.Verbose (mode) - Logation de notre prise de décision pour le débogage
NLP.Version - Version Semver actuelle de la bibliothèque
nlp.addwords (obj, isfrozen?) - Ajoutez de nouveaux mots au lexique
nlp.addtags (obj) - Ajoutez de nouvelles balises au tagset
NLP.TYPEAHEAD (ARR) - Ajouter des mots au dictionnaire de remplissage automatique
NLP.BUILDTRIE (ARR) - Compilez une liste de mots dans un formulaire de recherche rapide
NLP.BUILDNET (ARR) - Compilez une liste de correspondances dans un formulaire de match rapide
compromis / deux:
Contractions
- .Contractions () - Des choses comme "ne pas"
- .Contractions (). Expand () - Des choses comme "ne pas"
- .Contract () - Des choses comme "ne pas"
compromis / trois:
Noms
- .Nouns () - Renvoyez les termes ultérieurs tagués comme un nom
- .Nouns (). JSON () - Sortie surchargée avec métadonnées du nom
- .Nouns (). Parse () - Get Tokenisé Noun-Phrase
- .Nouns (). ISLURAL () - RETOUR uniquement les noms pluriels
- .Nouns (). Issingular () - Return Only Singuar Nouns
- .Nouns (). TopLural () -
'football captain' → 'football captains' - .Nouns (). Tosingular () -
'turnovers' → 'turnover' - .Nouns (). adjectifs () - Obtenez des adjectifs décrivant ce nom
Verbes
- .Verbs () - Renvoyez tous les termes ultérieurs tagués comme un verbe
- .Verbs (). JSON () - sortie surchargée avec des métadonnées verbales
- .Verbs (). Parse () - Get Tokeniszed Verb-Phrase
- .verbs (). sujets () - Qu'est-ce qui fait l'action du verbe
- .Verbes (). AdverBS () - Renvoyez les adverbes décrivant ce verbe.
- .Verbs (). Issingular () - Retournez des verbes singuliers comme «Spencer Walks»
- .Verbes (). ISLURAL () - Retournez les verbes pluriels comme «nous marchons»
- .Verbes (). Isimpératif () - Seuls les verbes d'instruction comme «Mangez!
- .Verbs (). Topasttense () -
'will go' → 'went' - .Verbs (). topresenttense () -
'walked' → 'walks' - .Verbs (). TofutureTense () -
'walked' → 'will walk' - .Verbs (). Toinfinitive () -
'walks' → 'walk' - .Verbs (). TOGERUND () -
'walks' → 'walking' - .Verbs (). TopastParticiple () -
'drive' → 'had driven' - .Verbs (). conjugate () - retourner toutes les conjugaisons de ces verbes
- .Verbs (). isNegative () - Retournez les verbes avec «pas», «jamais» ou «non»
- .Verbs (). isPositive () - seulement des verbes sans «pas», «jamais» ou «non»
- .Verbs (). Tonegative () -
'went' → 'did not go' - .Verbs (). topositive () -
"didn't study" → 'studied'
Nombres
- .numbers () - Saisissez toutes les valeurs écrites et numériques
- .Numbers (). Parse () - Get Tokeniszed Number Phrase
- .Numbers (). get () - Obtenez un numéro JavaScript simple
- .Numbers (). JSON () - sortie surchargée avec des métadonnées numériques
- .Numbers (). Tonumber () - Convertir «cinq» en
5 - .Numbers (). TolocaleString () - Ajouter des virgules, ou plus beau formatage pour les nombres
- .Numbers (). Totext () - Convertir «5» en
five - .Numbers (). TOORORDINAL () - Convertir «cinq» en
fifth ou 5th - .numbers (). tocardininal () - convertir le «cinquième» en
five ou 5 - .Numbers (). Isordinal () - retourner uniquement les nombres ordinaux
- .Numbers (). IsCardinal () - Renvoyez uniquement les numéros cardinaux
- .Numbers (). IsEqual (n) - Retour nombres avec cette valeur
- .numbers ().
- .Numbers (). Moins moins (max) - Nombres de retour plus petits que n
- .Numbers (). Entre (min, max) - Nombres de retour entre min et max
- .Numbers (). ISUnit (unité) - Renvoyez uniquement les nombres dans l'unité donnée, comme «km»
- .Numbers (). set (n) - Définir le numéro sur n
- .Numbers (). Ajouter (n) - augmenter le nombre de n
- .Numbers (). Soustraire (n) - Nombre de diminution de n
- .numbers (). incrément () - augmenter le nombre de 1
- .numbers (). décrément () - diminution du nombre de 1
- .money () - des choses comme
'$2.50'- .money (). get () - récupérer le montant analysé de l'argent
- .money (). JSON () - Currency + Nombre Info
- .money (). Currency () - Dans quelle monnaie dans laquelle se trouve l'argent
- .fractions () - comme «2 / 3rds» ou «un sur cinq»
- .Fractions (). Parse () - Get Tokenisé Fraction
- .Fractions (). get () - Numérisateur simple, données de dénominateur
- .Fractions (). JSON () - Méthode JSON surchargée de données de fractions
- .Fractions (). TODECIMAL () - '2/3' -> '0,66'
- .Fractions (). normaliser () - 'quatre sur 10' -> '4/10'
- .Fractions (). Totext () - '4/10' -> 'quatre dixièmes'
- .Fractions (). ToperCentage () - '4/10' -> '40% '
- .Percentages () - comme «2,5%»
- .Percentages (). get () - retourner le pourcentage de numéro / 100
- .Percentages (). JSON () - JSON surchargé avec en pourcentage d'informations
- .Percentages (). tofraction () - '80% '->' 8/10 '
Phrases
- .Sentences () - Renvoyez une classe de phrases avec des méthodes supplémentaires
- .Sentences (). JSON () - Sortie surchargée avec métadonnées de la phrase
- .Sentences (). Topasttense () -
he walks -> he walked - .Sentences (). topresenttense () -
he walked -> he walks - .Sentences (). tofuturetense () -
he walks -> he will walk - .Sentences (). Toinfinitive () - Verbe Root-Form
he walks -> he walk - .Sentences (). Tonegative () - -
he walks -> he didn't walk - .Sentences (). Isquestion () - Retour des questions avec un
? - .Sentences (). IsExclamation () - Retourne les phrases avec A
! - .Sentences (). isStatement () - Retour des phrases sans
? ou !
Adjectifs
- .adjectifs () - Des choses comme
'quick'- .adjectifs (). JSON () - Obtenez des métadonnées adjectives
- .adjectifs (). conjugate () - retourner toutes les inflexions de ces adjectifs
- .adjectifs (). Adverbs () - Obtenez des adverbes décrivant cet adjectif
- .adjectifs (). ToComparative () - 'rapide' -> 'plus rapide'
- .adjectifs (). toSuperlative () - 'rapide' -> 'plus rapide'
- .adjectifs (). Toadverb () - 'rapide' -> 'rapidement'
- .adjectifs (). Tonoun () - 'rapide' -> 'rapidité'
Sélections divers
- .clauses () - Spases de division en phrases à plusieurs termes
- .Chunks () - phrases séparées des phrases et phrases verbes
- .hyphénated () - Tous les termes liés à un trait d'union ou à un tiret comme
'wash-out' - .PhonEnUmbers () - Des choses comme
'(939) 555-0113' - .hashtags () - des choses comme
'#nlp' - .emails () - des choses comme
'[email protected]' - .Moticons () - des choses comme
:) - .emojis () - des choses comme
? - .Atmentions () - des choses comme
'@nlp_compromise' - .urls () - des choses comme
'compromise.cool' - .pronouns () - des choses comme
'he' - .Conjunctions () - des choses comme
'but' - .Prepositions () - des choses comme
'of' - .Abbreviations () - Des choses comme
'Mrs.' - .People () - des noms comme «John F. Kennedy»
- .People (). JSON () - Obtenez des métadonnées personnelles-nom
- .People (). Parse () - obtenir une interprétation de la personne-nom
- .places () - Comme «Paris, France»
- .Organizations () - Comme 'Google, Inc'
- .Topics () -
people() + places() + organizations() - .adverbs () - des choses comme
'quickly'- .adverbs (). JSON () - Obtenez des métadonnées adverbes
- .ACRONYMS () - Des choses comme
'FBI'- .ACRONYMS (). Strip () - Retirez les périodes des acronymes
- .ACRONYMS (). Addperiods () - Ajouter des périodes aux acronymes
- .Parentheses () - Renvoyez n'importe quoi à l'intérieur (parenthèses)
- .Parentheses (). Strip () - Retirez les supports
- .Possessives () - Des choses comme
"Spencer's"- .Possessives (). Strip () - "Spencer's" -> "Spencer"
- .quotations () - Renvoyez tous les termes à l'intérieur de guillemets appariés
- .quotations (). strip () - supprimer les guillemets
- .slashes () - Renvoyez les termes groupés par des barres obliques
- .slashes (). Split () - Transformez «Love / Hate» en «amour haine»
.étendre():
Cette bibliothèque est livrée avec une base de référence et de bon sens pour la grammaire anglaise.
Vous êtes libre de modifier ou de déchets de pose sur tous les paramètres - ce qui est la partie amusante en fait.
La partie la plus simple est juste de suggérer des balises pour tout mot donné:
let myWords = {
kermit : 'FirstName' ,
fozzie : 'FirstName' ,
}
let doc = nlp ( muppetText , myWords ) Ou apportez des changements plus lourds avec un compromis-plugine.
import nlp from 'compromise'
nlp . extend ( {
// add new tags
tags : {
Character : {
isA : 'Person' ,
notA : 'Adjective' ,
} ,
} ,
// add or change words in the lexicon
words : {
kermit : 'Character' ,
gonzo : 'Character' ,
} ,
// change inflections
irregulars : {
get : {
pastTense : 'gotten' ,
gerund : 'gettin' ,
} ,
} ,
// add new methods to compromise
api : View => {
View . prototype . kermitVoice = function ( ) {
this . sentences ( ) . prepend ( 'well,' )
this . match ( 'i [(am|was)]' ) . prepend ( 'um,' )
return this
}
} ,
} ) .Plugin () Docs
Docs:
Introduction douce:
- # 1) Entrée → Sortie
- # 2) Match & Transform
- # 3) Faire un chat-bot
Documentation:
| Concepts | API | Plugins |
|---|
| Précision | Accessoires | Adjectifs |
| Mise en cache | Méthodes de constructeur | Dates |
| Cas | Contractions | Exporter |
| Size fichiers | Insérer | Hacher |
| Internes | Json | Html |
| Justification | Décalages de caractère | Pression des clés |
| Lexique | Boucles | Ngrams |
| Match-syntax | Correspondre | Nombres |
| Performance | Noms | Paragraphes |
| Plugins | Sortir | Balayage |
| Projets | Sélections | Phrases |
| Étiqueteur | Tri | Syllabes |
| Balises | Diviser | Prononcer |
| Tokenisation | Texte | Strict |
| Named-entities | Utils | Penn-tags |
| Espace blanc | Verbes | Type de type |
| Données mondiales | Normalisation | Balayer |
| Apparition floue | Manuscrit | Mutation |
| Formes de racine | | |
Pourparlers:
- Langue comme interface - par Spencer Kelly
- Codage bots de chat - par Kahwee Teng
- Sur la saisie et les données - par Spencer Kelly
Articles:
- Géocodage des conversations sociales avec NLP et JavaScript - par Microsoft
- Recette de microservice - par Eventn
- Adventure Game Stin phrase analyse avec compromis
- Construire des jeux basés sur le texte - par Matt Eland
- Amusant avec JavaScript à BigQuery - par Felipe Hoffa
- Traitement du langage naturel ... dans le navigateur? - par Charles Landau
Quelques applications amusantes:
- Test de Bechdel automatisé - par le gardien
- Framework de génération d'histoires - par Jose Phrocca
- Blog de toboggans de listes - Listes de type Horse-Ebooks - par Michael Paulukonis
- Édition vidéo de la transcription - par nouvelle théorie
- Extension du navigateur Checking - par Alexander Kidd
- SIRI Raccourci - par Michael Byrns
- Amazon Skill - par Tajddin Maghni
- Tasking Slack-bot - par Kevin Suh [voir plus]
Comparaisons
- Compromis et spationy
- Compromis et NLTK
Plugins:
Ce sont des extensions utiles:
Dates
npm install compromise-dates
- .Dates () - Trouver des dates comme
June 8th ou 03/03/18- .dates (). get () - simple démarrage / fin JSON Résultat
- .Dates (). JSON () - Sortie surchargée avec métadonnées de date
- .Dates (). Format ('') - Convertir les dates en formats spécifiques
- .Dates (). ToshortForm () - Convertir «mercredi» en «mer», etc.
- .Dates (). TolongForm () - Convertir «février» en «février», etc.
- .Durations () -
2 weeks ou 5mins- .Durations (). get () - retourner JSON simple pour la durée
- .Durations (). JSON () - sortie surchargée avec des métadonnées de durée
- .Times () -
4:30pm ou half past five- .Times (). get () - retourner JSON simple pour les temps
- .Times (). JSON () - Sortie surchargée avec des métadonnées de temps
Statistiques
npm install compromise-stats
.tfidf ({}) - classer les mots par fréquence et unicité
.NGRAMS ({}) - Liste toutes les sous-phrases répétitives, par nombre de mots
.Unigrams () - n-grammes avec un mot
.bigrams () - n-grammes avec deux mots
.Trigrams () - n-grammes avec trois mots
.startGrams () - n-grams, y compris le premier terme d'une phrase
.endgrams () - n-grams, y compris le dernier terme d'une phrase
.EdgeGrams () - n-grams, y compris le premier ou le dernier terme d'une phrase
Discours
npm install compromise-syllables
- .Syllables () - diviser chaque terme par sa prononciation typique
- .soundslike () - produire une prononciation estimée
Wikipedia
npm install compromise-wikipedia
- .Wikipedia () - Réconciliation de l'article comprimé
Manuscrit
Nous nous engageons à prendre le support dactylographié / Deno, à la fois dans le principal et dans les plagins officiels:
import nlp from 'compromise'
import stats from 'compromise-stats'
const nlpEx = nlp . extend ( stats )
nlpEx ( 'This is type safe!' ) . ngrams ( { min : 1 } ) Docs dactylographiés
Limites:
Slash-Support: Nous partageons actuellement des slashs comme des mots différents, comme nous le faisons pour les traits de traits. Donc, des choses comme ça ne fonctionnent pas: nlp('the koala eats/shoots/leaves').has('koala leaves') //false
Match intersentente: par défaut, les phrases sont l'abstraction de niveau supérieur. Les matchs intervente ou multi-phrases ne sont pas pris en charge sans plugin: nlp("that's it. Back to Winnipeg!").has('it back')//false
Syntaxe de correspondance imbriquée: la beauté du danger de Regex est que vous pouvez vous concrétiser indéfiniment. Notre syntaxe de match est beaucoup plus faible. Des choses comme celle-ci ne sont pas (encore) possibles: doc.match('(modern (major|minor))? general') Les matchs complexes doivent être atteints avec des instructions successives .match () .
Analyse de dépendance: la transformation appropriée de la phrase nécessite de comprendre l'arbre de syntaxe d'une phrase, ce que nous ne faisons pas actuellement. Nous devrions! Aide recherché avec ça.
FAQ
☂️ n'est pas aussi javascript ...
Ouais c'est!
Il n'a pas été conçu pour rivaliser avec NLTK et peut ne pas s'adapter à chaque projet.
Le traitement des chaînes est également synchrone et la parallélisation des processus de nœud est bizarre.
Voir ici pour des informations sur la vitesse et les performances, et ici pour les motivations du projet
? Peut-il fonctionner sur mon Arduino-watch?
Seulement s'il est étanche à l'eau!
Lisez le démarrage rapide pour exécuter des compromis dans les travailleurs, les applications mobiles et toutes sortes d'environnements amusants.
? Compromis dans d'autres langues?
Nous avons des fourches en cours en cours pour l'allemand, le français, l'espagnol et l'italien dans la même philosophie.
et ont besoin d'aide.
Constructions partielles?
Nous proposons une construction uniquement en tokenize, qui a la tutelle de point de vente.
Mais sinon, le compromis n'est pas facilement tremblé par les arbres.
Les méthodes de marquage sont compétitives et gourmandes, il n'est donc pas recommandé de retirer les choses.
Notez que sans un plateau de point de vente complet, le porte-contracteur ne fonctionnera pas parfaitement. ( (Spencer's Cool) vs (maison de Spencer) ))
Il est recommandé d'exécuter complètement la bibliothèque.

Voir aussi:
En-POS - très intelligent Javascript Pos-Tagger par Alex Corvi
NaturalNode - NLP statistique plus chic en JavaScript
WinkJS - Pos-Tagger, Tokenizer, Machine-Learning in JavaScript
Dariusk / POS-JS - Fasttag Fork en JavaScript
Compendium-js - POS et analyse des sentiments en javascript
Linguistique de nodebox - conjugaison, inflexion en JavaScript
Retext - Utilitaires de texte très impressionnants en javascript
Exposant - Moteur de conversation dans JS
JSPOS - construction javascript de la baillon éprouvée dans le temps
Spacy - Tagger rapide et multilingue en C / Python
Prose - Tagger rapide dans GO par Joseph Kato
TextBlob - Tagger Python
Mit