مساومة

معالجة لغة طبيعية متواضعة
npm install compromise
بقلم سبنسر كيلي والعديد من المساهمين
الفرنسية • الألمانية • الإيطالية • الإسبانية
تسوية
تحاول قصارى جهدها لتحويل النص إلى بيانات.
إنه يتخذ قرارات محدودة ومعقولة.
إنه ليس ذكيًا كما تعتقد.
import nlp from 'compromise'
let doc = nlp ( 'she sells seashells by the seashore.' )
doc . verbs ( ) . toPastTense ( )
doc . text ( )
// 'she sold seashells by the seashore.'
لا تكن خيالًا على الإطلاق:
if ( doc . has ( 'simon says #Verb' ) ) {
return true
}
الاستيلاء على أجزاء من النص:
let doc = nlp ( entireNovel )
doc . match ( 'the #Adjective of times' ) . text ( )
// "the blurst of times?"
مستندات مطابقة
والحصول على البيانات:
import plg from 'compromise-speech'
nlp . extend ( plg )
let doc = nlp ( 'Milwaukee has certainly had its share of visitors..' )
doc . compute ( 'syllables' )
doc . places ( ) . json ( )
/*
[{
"text": "Milwaukee",
"terms": [{
"normal": "milwaukee",
"syllables": ["mil", "wau", "kee"]
}]
}]
*/ مستندات JSON
تجنب مشاكل المحللين الهش:
let doc = nlp ( "we're not gonna take it.." )
doc . has ( 'gonna' ) // true
doc . has ( 'going to' ) // true (implicit)
// transform
doc . contractions ( ) . expand ( )
doc . text ( )
// 'we are not going to take it..'
مستندات الانكماش
ويخفق الأشياء مثل البيانات:
let doc = nlp ( 'ninety five thousand and fifty two' )
doc . numbers ( ) . add ( 20 )
doc . text ( )
// 'ninety five thousand and seventy two'
مستندات رقم
-لأنه في الواقع-
let doc = nlp ( 'the purple dinosaur' )
doc . nouns ( ) . toPlural ( )
doc . text ( )
// 'the purple dinosaurs'
مستندات الاسم
استخدمه على جانب العميل:
< script src =" https://unpkg.com/compromise " > </ script >
< script >
var doc = nlp ( 'two bottles of beer' )
doc . numbers ( ) . minus ( 1 )
document . body . innerHTML = doc . text ( )
// 'one bottle of beer'
</ script >
أو بالمثل:
import nlp from 'compromise'
var doc = nlp ( 'London is calling' )
doc . verbs ( ) . toNegative ( )
// 'London is not calling'
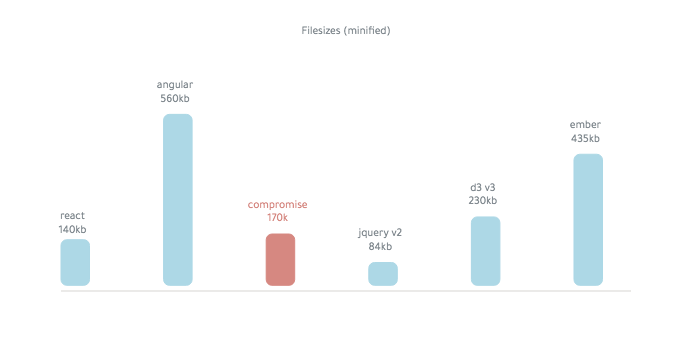
التسوية هي ~ 250 كيلو بايت (مصغرة):
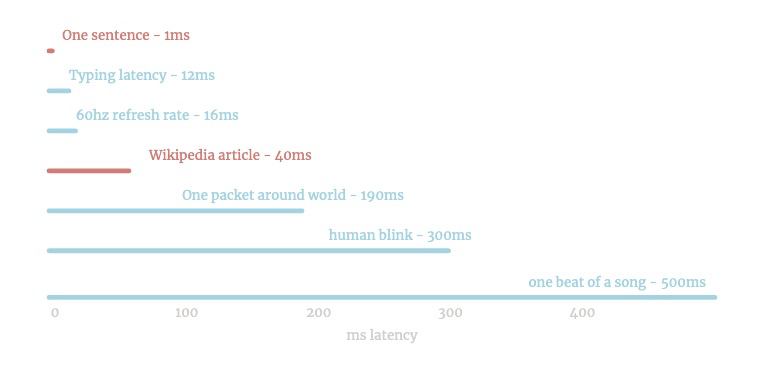
إنه سريع جدًا. يمكن أن يعمل على keypress:
إنه يعمل بشكل رئيسي عن طريق ربط جميع أشكال قائمة الكلمات الأساسية.
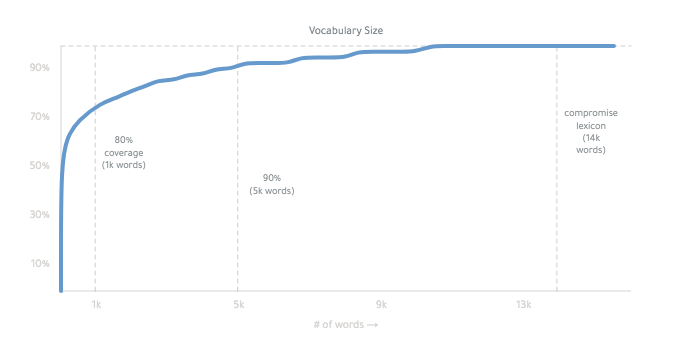
المعجم النهائي هو حوالي 14000 كلمة:
يمكنك قراءة المزيد حول كيفية عملها ، هنا. إنه غريب.
تمام -
compromise/one
tokenizer الكلمات والجمل وعلامات الترقيم.
import nlp from 'compromise/one'
let doc = nlp ( "Wayne's World, party time" )
let data = doc . json ( )
/* [{
normal:"wayne's world party time",
terms:[{ text: "Wayne's", normal: "wayne" },
...
]
}]
*/ مستندات Tokenizer
تسوية/ يقسم نصك ، يلفه في واجهة برمجة تطبيقات مفيدة ،
/واحد سريع - معظم الجمل تستغرق 10 ميلي ثانية.
يمكن أن تفعل ~ 1 ميغابايت من النص الثاني - أو 10 صفحات ويكيبيديا.
لا نهائي يذوب يأخذ 3s.
يمكنك أيضًا التوازي ، أو دفق النص عليه مع سرعة التسوية.
compromise/two
part-of-speech ، ومهرجان القواعد.
import nlp from 'compromise/two'
let doc = nlp ( "Wayne's World, party time" )
let str = doc . match ( '#Possessive #Noun' ) . text ( )
// "Wayne's World"
مستندات تاججر
تسوية/اثنين يحسب تلقائيا القواعد الأساسية جدا لكل كلمة.
هذا أكثر فائدة مما يدرك الناس أحيانًا.
تساعدك القواعد النحوية على كتابة قوالب أنظف ، والاقتراب من المعلومات.
التسوية لها 83 علامة ، مرتبة في رسم بياني وسيم.
#firstname → #person → #propernoun → #noun
يمكنك رؤية قواعد كل كلمة عن طريق تشغيل doc.debug()
يمكنك رؤية منطق كل علامة مع nlp.verbose('tagger') .
إذا كنت تفضل علامات Penn ، فيمكنك استخلاصها بـ:
let doc = nlp ( 'welcome thrillho' )
doc . compute ( 'penn' )
doc . json ( )
compromise/three
Phrase والجملة أدوات.
import nlp from 'compromise/three'
let doc = nlp ( "Wayne's World, party time" )
let str = doc . people ( ) . normalize ( ) . text ( )
// "wayne"
مستندات الاختيار
التسوية/ثلاثة هي مجموعة من الأدوات للتكبير والعمل على أجزاء من النص.
.numbers() يمسك جميع الأرقام في وثيقة ، على سبيل المثال - ويمتدها بطرق جديدة ، مثل .subtract() .
عندما يكون لديك عبارة ، أو مجموعة من الكلمات ، يمكنك رؤية بيانات تعريف إضافية حولها باستخدام .json()
let doc = nlp ( 'four out of five dentists' )
console . log ( doc . fractions ( ) . json ( ) )
/*[{
text: 'four out of five',
terms: [ [Object], [Object], [Object], [Object] ],
fraction: { numerator: 4, denominator: 5, decimal: 0.8 }
}
]*/ let doc = nlp ( '$4.09CAD' )
doc . money ( ) . json ( )
/*[{
text: '$4.09CAD',
terms: [ [Object] ],
number: { prefix: '$', num: 4.09, suffix: 'cad'}
}
]*/
API
حل وسط/واحد
الإخراج
- .Text () - إرجاع المستند كنص
- .json () - إرجاع المستند كبيانات
- .Debug () - طباعة جميلة الوثيقة المفسرة
- .out () - إخراج مخصص أو مخصص
- .html ({}) - علامات HTML مخصصة للإخراج للمطابقات
- .wrap ({}) - إنتاج إخراج مخصص لمطابقات المستندات
utils
- .found [getter] - هل هذه الوثيقة فارغة؟
- .Docs [getter] الحصول على كائنات مصطلح مثل JSON
- .Length [getter] - عد رقم الأحرف في المستند (طول السلسلة)
- .isview [getter] - تحديد كائن حل وسط
- . compute () - قم بتشغيل تحليل مسمى على المستند
- .clone () - نسخة عميقة الوثيقة ، بحيث لا تبقى أي مراجع
- .TermList () - إرجاع قائمة مسطحة لجميع كائنات الأجل في المطابقة
- .cache ({}) - تجميد الوثيقة الحالية للوثيقة ، لعمليات السرعة
- . uncache () - UN -Freezates الحالة الحالية للوثيقة ، لذلك قد يتم تحويلها
- .freeze ({}) - منع أي علامات من إزالتها ، في هذه المصطلحات
- .unfreeze ({}) - السماح للعلامات بالتغيير مرة أخرى ، كإعداد افتراضي
الملحقات
- . جميع
- .Terms () - نتائج الانقسام بمقدار كل مصطلح فردي
- .
- .Last (n) - استخدم فقط النتيجة (s) الأخيرة
- .slice (n ، n) - احصل على مجموعة فرعية من النتائج
- .eq (n) - استخدم النتيجة التاسعة فقط
- . firstterms () - احصل على الكلمة الأولى في كل مباراة
- .lastterms () - احصل على الكلمة النهائية في كل مباراة
- .fullsentences () - احصل على الجملة بأكملها لكل مباراة
- .
- .wordcount () - عد رقم المصطلحات في المستند
- .
مباراة
(طرق المطابقة استخدم Match-Syntax.)
- .Match ('') - إرجاع مستند جديد ، مع هذا الوالد كوالد
- . لا ('') - إرجاع جميع النتائج باستثناء هذا
- .Matchone ('') - إرجاع المباراة الأولى فقط
- . هل
- .fno ('') - تصفية أي عبارات حالية لها هذه المطابقة ('Notif')
- .has ('') - إرجاع منطقية إذا كانت هذه المباراة موجودة
- .
- .
- . Union () - الإرجاع المدمجة بدون تكرارات
- .intersection () - إرجاع المباريات المكررة فقط
- . complement () - احصل على كل شيء في مباراة أخرى
- .settle () - إزالة التداخل من المباريات
- .Growright ('') - أضف أي مصطلحات مطابقة مباشرة بعد كل مباراة
- . Growleft ('') - أضف أي مصطلحات مطابقة مباشرة قبل كل مباراة
- .grow ('') - أضف أي مصطلحات مطابقة قبل أو بعد كل مباراة
- .SEEP (NET) - تطبيق سلسلة من كائنات المطابقة على المستند
- .Spliton ('') - إرجاع مستند بثلاثة أجزاء لكل مباراة ('Spliton')
- .splitbefore ('') - قسم عبارة قبل كل جزء مطابق
- .splitafter ('') - قسم عبارة بعد كل جزء مطابق
- .
- .
- .lookup ([]) - البحث السريع لمجموعة من مباريات السلسلة
- .Autofill () - إنشاء افتراضات من النوع على المستند
علامة
- .tag ('') - أعط جميع المصطلحات العلامة المحددة
- .Tagsafe ('') - تطبيق العلامة فقط على المصطلحات إذا كانت متسقة مع العلامات الحالية
- .antag ('') - قم بإزالة هذا المصطلح من المصطلحات المعطاة
- .Canbe ('') - إرجاع المصطلحات التي يمكن أن تكون هذه العلامة فقط
قضية
- .ToLowerCase () - اقلب كل حرف من كل مصطلح إلى Lower Cse
- . touppercase () - اقلب كل حرف من كل مصطلح إلى العلبة العليا
- .TotitleCase () - الحالة العلوية الحرف الأول من كل مصطلح
- .tocamelcase () - قم بإزالة المسافة البيضاء وعنوان كل مصطلح
مساحة بيضاء
- .pre ('') - أضف هذا الترقيم أو المسافة البيضاء قبل كل مباراة
- .post ('') - أضف هذا الترقيم أو المسافة البيضاء بعد كل مباراة
- .trim () - قم بإزالة الساحة البيضاء البدء والنهاية
- .hhyphenate () - قم بتوصيل الكلمات بالواصلة ، وإزالة المسافة البيضاء
- .
- .Toquotations () - إضافة علامات اقتباس حول هذه المباريات
- .Toparentheses () - إضافة قوسين حول هذه المباريات
حلقات
- .map (fn) - قم بتشغيل كل عبارة من خلال وظيفة ، وإنشاء مستند جديد
- . من أجل (FN) - قم بتشغيل وظيفة على كل عبارة ، كوثائق فردية
- .filter (FN) - إرجاع فقط العبارات التي تعود صحيحة
- .find (FN) - إرجاع مستند مع العبارة الأولى فقط التي تتطابق
- . بعض (FN) - إرجاع صحيح أو خطأ إذا كانت هناك عبارة واحدة مطابقة
- .Random (FN) - عينة مجموعة فرعية من النتائج
أدخل
- .replace (تطابق ، استبدال) - البحث واستبدل المطابقة بمحتوى جديد
- .replacewith (استبدال) - نص جديد
- .Remove () - قم بإزالة هذه المصطلحات بالكامل من المستند
- .insertbefore (Str) - أضف هذه المصطلحات الجديدة إلى مقدمة كل مباراة (مسبقة)
- .insertafter (STR) - أضف هذه المصطلحات الجديدة إلى نهاية كل مباراة (إلحاق)
- .concat () - أضف هذه الأشياء الجديدة إلى النهاية
- .swap (Fromlemma ، Tolemma) - استبدال ذكي للكلمات الجذرية ، باستخدام الاقتران المناسب
تحول
- .sort ('method') - إعادة ترتيب ترتيب المباريات (في مكان)
- .reverse () - عكس ترتيب المباريات ، ولكن ليس الكلمات
- .Normalization ({}) - تنظيف النص بطرق مختلفة
- .unique () - إزالة أي مباريات مكررة
ليب
(هذه الطرق موجودة على كائن nlp الرئيسي)
NLP.Tokenize (STR) - نص التحليل دون تشغيل علامات نقاط البيع
NLP.Lazy (Str ، Match) - مسح من خلال نص مع الحد الأدنى من التحليل
nlp.plugin ({}) - مزيج في حل وسط - plugin
NLP.Parsematch (STR) - أي ما قبل أي عبارات تطابق في JSON
nlp.world () - الاستيلاء أو تغيير المكتبة الداخلية
nlp.model () - الاستيلاء على جميع البيانات اللغوية الحالية
nlp.methods () - الاستيلاء أو تغيير الطرق الداخلية
nlp.hooks () - انظر أي طرق حسابية تعمل تلقائيًا
NLP.Verbose (الوضع) - قم بتسجيل اتخاذ القرارات الخاصة بنا لتصحيح الأخطاء
nlp.version - إصدار Semver الحالي من المكتبة
nlp.addwords (OBJ ، isfrozen؟) - أضف كلمات جديدة إلى المعجم
NLP.Addtags (OBJ) - إضافة علامات جديدة إلى Tagset
nlp.typeahead (ARR) - أضف كلمات إلى قاموس الملء التلقائي
NLP.Buildtrie (ARR) - تجميع قائمة من الكلمات في شكل بحث سريع
NLP.BUILDNET (ARR) - تجميع قائمة بالمطابقات في نموذج المباراة السريعة
حل وسط/اثنان:
الانقباضات
- .contractions () - أشياء مثل "لم"
- .contractions (). توسيع () - أشياء مثل "لم تفعل"
- .contract () - أشياء مثل "لم"
حل وسط/ثلاثة:
الأسماء
- .Nouns () - إرجاع أي شروط لاحقة تم وضع علامة عليها على أنها اسم
- .nouns ().
- .nouns (). parse () - احصل
- .Nouns ()
- .nouns (). issingarile () - إرجاع الأسماء المفردة فقط
- .nouns (). Toplural () -
'football captain' → 'football captains' - .nouns
'turnovers' → 'turnover' ) - .Nouns (). الصفات () - احصل على أي صفات تصف هذا الاسم
الأفعال
- .Verbs () - إرجاع أي مصطلحات لاحقة تم وضع علامة عليها على أنها فعل
- .VERBS (). JSON () - الإخراج الزائد مع بيانات التعريف
- .VERBS (). parse () - احصل على عبارة الفعل المميز
- .Verbs (). الموضوعات () - ما الذي يفعله فعل الفعل
- .Verbs (). adverbs () - إرجاع الظروف التي تصف هذا الفعل.
- .Verbs (). issingular () - إرجاع الأفعال المفردة مثل "سبنسر مناحي"
- .فيرز ()
- .Verbs (). isimperative () - فقط أفعال التعليمات مثل "أكلها!"
- .Verbs (). Topasttense () -
'will go' → 'went' - .Verbs (). TopResenttense () -
'walked' → 'walks' - .Verbs (). tofutureTense () -
'walked' → 'will walk' - .Verbs ()
'walks' → 'walk' - .Verbs (). Togerund () -
'walks' → 'walking' - .VERBS (). TOPASTPARTISTICLE () -
'drive' → 'had driven' - .Verbs (). conjugate () - إرجاع جميع الاقتران من هذه الأفعال
- .Verbs (). isnegative () - أفعال إرجاع مع "لا" أو "لا" أو "لا"
- .Verbs (). Ispositive () - فقط الأفعال بدون "لا" أو "لا" أو "لا"
- .Verbs (). Tonegative () -
'went' → 'did not go' - .Verbs (). topositive () -
"didn't study" → 'studied'
أرقام
- .numbers () - احصل على جميع القيم المكتوبة والرقمية
- .numbers (). parse () - احصل
- .numbers (). get () - احصل على رقم JavaScript بسيط
- .numbers ().
- .numbers (). tonumber () - تحويل "خمسة" إلى
5 - .numbers (). tolocalestring () - إضافة فواصل ، أو تنسيق أجمل للأرقام
- .numbers (). totext () - تحويل '
five ' -
5th () fifth - .numbers (). tocardinal () - تحويل "الخامس" إلى
five أو 5 - .numbers (). Isordinal () - إرجاع الأرقام الترتيبية فقط
- .numbers (). iscardinal () - إرجاع أرقام الكاردينال فقط
- .numbers (). isequal (n) - أرقام الإرجاع مع هذه القيمة
- .numbers (). الكبرى (دقيقة) - أرقام العودة أكبر من n
- .numbers (). lessthan (Max) - أرقام الإرجاع أصغر من n
- .numbers ().
- .numbers (). isUnit (الوحدة) - إرجاع أرقام فقط في الوحدة المحددة ، مثل "KM"
- .Numbers (). SET (N) - SET NUMBER TO N
- .numbers (). إضافة (n) - زيادة الرقم بواسطة n
- .numbers (). اطرح (N) - انخفاض رقم N
- .numbers (). زيادة () - زيادة عددها بمقدار 1
- .numbers (). الانخفاض () - انخفاض رقم 1
- .Money () - أشياء مثل
'$2.50'- .Money (). GET () - استرداد المبلغ (المبلغ) من المال.
- .Money (). JSON () - العملة + معلومات الرقم
- .Money (). العملة () - أي عملة هي المال في
- .
- .fractions (). parse () - احصل
- .
- .
- .
- .
- .
- .
- .percentages () - مثل "2.5 ٪"
- .percentages (). get () - إرجاع الرقم المئوي / 100
- .percentages ().
- .percentages (). tofraction () - '80 ٪ ' ->' 8/10 '
جمل
- .sentences () - إرجاع فئة الجملة بطرق إضافية
- .
he walks he walked -
he walks () he walked - .sentences (). tofutureTense ()
he walks -> he will walk -
he walk () he walks - .sentences (). Tonegative () - -
he walks -> he didn't walk - .sentences (). isquestion () - إرجاع الأسئلة مع
? - .sentences (). isexclamation () - جمل الإرجاع مع
! - .sentences (). isStatement () - جمل العودة بدون
? أو !
الصفات
- .
'quick'- .
- .
- .edjectives (). adverbs () - احصل
- .adjectives ().
- .edjectives (). tosuperlative () - 'Quick' -> 'أسرع'
- .
- .
اختيارات MISC
- .Clauses () -جمل تقسيم إلى عبارات متعددة الأجل
- .Chunks () -عبارات جمل تقسيم الأسماء وأجمل الفعل
- .
'wash-out' - .
'(939) 555-0113' - .hashtags () - أشياء مثل
'#nlp' - .
'[email protected]' - .emoticons () - أشياء مثل
:) - .emojis () - أشياء مثل
? - .atmentions () - أشياء مثل
'@nlp_compromise' - .rls () - أشياء مثل
'compromise.cool' - .pronouns () - أشياء مثل
'he' - .conjunctions () - أشياء مثل
'but' - .
'of' - .
'Mrs.' - .
- .people (). JSON () - الحصول على بيانات تعريف الشخص
- .people (). parse () - احصل على تفسير اسم الشخص
- .places () - مثل "باريس ، فرنسا"
- .
- .Topics () -
people() + places() + organizations() - . adverbs () - أشياء مثل
'quickly'- .adverbs (). json () - الحصول على بيانات تعريف adverb
- .Acronyms () - أشياء مثل
'FBI'- .Acronyms (). Strip () - إزالة الفترات من الاختصارات
- .acronyms (). addperiods () - إضافة فترات إلى اختصارات
- .Parentheses () - إرجاع أي شيء إلى الداخل (أقواس)
- .Parentheses (). Strip () - إزالة الأقواس
- .possessives () - أشياء مثل
"Spencer's" - .
- .slashes () - إرجاع أي مصطلحات تم تجميعها بواسطة Slashes
- .slashes (). split () - تحويل "الحب/الكراهية" إلى "الحب الكراهية"
.يمتد():
تأتي هذه المكتبة مع خط أساسي للمرور المنطقي لقواعد اللغة الإنجليزية.
أنت حر في التغيير ، أو وضع النفايات في أي إعدادات - وهو الجزء الممتع في الواقع.
أسهل جزء هو مجرد اقتراح علامات لأي كلمات معينة:
let myWords = {
kermit : 'FirstName' ,
fozzie : 'FirstName' ,
}
let doc = nlp ( muppetText , myWords ) أو إجراء تغييرات أثقل مع حل وسط.
import nlp from 'compromise'
nlp . extend ( {
// add new tags
tags : {
Character : {
isA : 'Person' ,
notA : 'Adjective' ,
} ,
} ,
// add or change words in the lexicon
words : {
kermit : 'Character' ,
gonzo : 'Character' ,
} ,
// change inflections
irregulars : {
get : {
pastTense : 'gotten' ,
gerund : 'gettin' ,
} ,
} ,
// add new methods to compromise
api : View => {
View . prototype . kermitVoice = function ( ) {
this . sentences ( ) . prepend ( 'well,' )
this . match ( 'i [(am|was)]' ) . prepend ( 'um,' )
return this
}
} ,
} ) .plugin () مستندات
المستندات:
مقدمة لطيفة:
- #1) الإدخال ← الإخراج
- #2) المباراة والتحويل
- #3) صنع بروت الدردشة
الوثائق:
| المفاهيم | API | الإضافات |
|---|
| دقة | الملحقات | الصفات |
| التخزين المؤقت | مايثودات مُنشئ | بلح |
| قضية | الانقباضات | يصدّر |
| ملفات | أدخل | التجزئة |
| الداخلية | جيسون | HTML |
| التبرير | تعويضات الشخصية | keypress |
| معجم | حلقات | ngrams |
| Match-Syntax | مباراة | أرقام |
| أداء | الأسماء | الفقرات |
| الإضافات | الإخراج | مسح |
| المشاريع | اختيارات | جمل |
| تاججر | فرز | المقاطع |
| العلامات | ينقسم | نطق |
| الرمز المميز | نص | حازم |
| تدعى | utils | بين علامات |
| مساحة بيضاء | الأفعال | typeahead |
| بيانات العالم | تطبيع | اكتساح |
| مطابقة غامضة | TypeScript | طفرة |
| أشكال الجذر | | |
محادثات:
- اللغة كواجهة - بقلم سبنسر كيلي
- برامج الدردشة الترميز - بقلم Kahwee Teng
- على الكتابة والبيانات - بواسطة سبنسر كيلي
المقالات:
- محادثات اجتماعية مع NLP و JavaScript - بواسطة Microsoft
- وصفة الخدمات المجهرية - عن طريق الحدث
- جملة لعبة المغامرة تولاذ مع حل وسط
- بناء الألعاب القائمة على النص - بقلم مات إيلاند
- متعة مع JavaScript في Bigquery - بقلم فيليب هوفا
- معالجة اللغة الطبيعية ... في المتصفح؟ - بقلم تشارلز لانداو
بعض التطبيقات الممتعة:
- اختبار Bechdel الآلي - بواسطة الوصي
- إطار توليد القصة - بقلم خوسيه Phrocca
- مدونة Tumbler من القوائم - قوائم شبيهة بالخيول - بقلم Michael Paulukonis
- تحرير الفيديو من النسخ - بواسطة نظرية جديدة
- تمديد المتصفح ، التحقق من الحقائق - بقلم ألكساندر كيدد
- اختصار سيري - بقلم مايكل بيرنز
- مهارة الأمازون - بقلم تاجدين ماجني
- مهام الركود - بقلم كيفن سوه [انظر المزيد]
مقارنات
- التسوية و spacy
- التسوية و NLTK
الإضافات:
هذه بعض الامتدادات المفيدة:
بلح
npm install compromise-dates
- .dates () - العثور على تواريخ مثل
June 8th أو 03/03/18- .dates (). GET () - نتيجة مبدئية/نهاية JSON
- .dates (). JSON () - الإخراج الزائد مع بيانات التعريف التاريخ
- .dates (). التنسيق ('') - تحويل التواريخ إلى تنسيقات محددة
- .dates (). Toshortform () - تحويل "الأربعاء" إلى "الأربعاء" ، إلخ
- .dates (). tolongform () - تحويل "فبراير" إلى "فبراير" ، إلخ
- . الأدوار () -
2 weeks أو 5mins- .Durations (). GET () - إرجاع JSON البسيط للمدة
- .Durations (). JSON () - الإخراج المفرط مع بيانات التعريف
- .Times () -
4:30pm أو half past five- .Times (). GET () - إرجاع Simple JSON للأوقات
- .Times (). JSON () - الإخراج الزائد مع بيانات التعريف الزمنية
الإحصائيات
npm install compromise-stats
.tfidf ({}) - ترتيب الكلمات حسب التردد والتفرد
.ngrams ({}) -قائمة جميع برامج التكرار الفرعية ، بواسطة count word
.unigrams () - n -grams بكلمة واحدة
.bigrams () - n -grams مع كلمتين
.trigrams () - n -grams مع ثلاث كلمات
.startgrams () - n -grams بما في ذلك المصطلح الأول من العبارة
.
.edgegrams () - n -grams بما في ذلك الفترة الأولى أو الأخيرة من العبارة
خطاب
npm install compromise-syllables
- .syllables () - تقسيم كل مصطلح بواسطة نطقه النموذجي
- .soundslike () - إنتاج نطق مقدر
ويكيبيديا
npm install compromise-wikipedia
- .wikipedia () - تسوية مقال مضغوطة
TypeScript
نحن ملتزمون بدعم TypeScript/Deno ، في كل من Plugins الرسمي:
import nlp from 'compromise'
import stats from 'compromise-stats'
const nlpEx = nlp . extend ( stats )
nlpEx ( 'This is type safe!' ) . ngrams ( { min : 1 } ) مستندات TypeScript
القيود:
Slash-Support: قمنا حاليًا بتقسيم المائل ككلمات مختلفة ، مثلما نفعل للواصلة. لذا فإن أشياء مثل هذه لا تعمل: nlp('the koala eats/shoots/leaves').has('koala leaves') //false
مطابقة بين الخلاصة: بشكل افتراضي ، الجمل هي التجريد على المستوى الأعلى. لا يتم دعم المباريات المتداخلة ، أو مباريات متعددة الجنسيات بدون مكون إضافي: nlp("that's it. Back to Winnipeg!").has('it back')//false
بناء جملة المباراة المتداخلة: جمال الخطر من Regex هو أنه يمكنك إعادة التكرار إلى أجل غير مسمى. بناء جملة المباراة لدينا أضعف بكثير. أشياء مثل هذه ليست (حتى الآن) ممكنة: يجب تحقيق doc.match('(modern (major|minor))? general') مع عبارات .match () متتالية.
تحليل التبعية: يتطلب تحول الجملة الصحيح فهم شجرة بناء الجملة من الجملة ، وهو ما لا نفعله حاليًا. يجب علينا! مساعدة مطلوبة مع هذا.
التعليمات
☂ ليس JavaScript أيضًا ...
نعم هو!
لم يتم تصميمه للتنافس مع NLTK ، وقد لا يناسب كل مشروع.
معالجة السلسلة متزامنة أيضًا ، وموازاة عمليات العقدة غريبة.
انظر هنا للحصول على معلومات حول السرعة والأداء ، وهنا لدوافع المشروع
؟ هل يمكن أن تعمل على مراقبة Arduino؟
فقط إذا كان مقاوم للماء!
اقرأ Quick Start لتشغيل التسوية في العمال وتطبيقات الأجهزة المحمولة وجميع أنواع البيئات المضحكة.
؟ حل وسط بلغات أخرى؟
لقد حصلنا على شوكات عمل في مجال الأعمال الألمانية والفرنسية والإسبانية والإيطالية في نفس الفلسفة.
وتحتاج إلى بعض المساعدة.
بنيات جزئية؟
نحن نقدم بناء رمز فقط ، والذي تم سحبه.
ولكن على خلاف ذلك ، فإن التسوية ليست بسهولة الأشجار.
أساليب العلامات تنافسية وجشع ، لذلك لا ينصح بسحب الأشياء.
لاحظ أنه بدون علامات نقاط البيع الكاملة ، لن يعمل التقلص بشكل مثالي. ( (Spencer's Cool) vs. (Spencer's House) )
يوصى بتشغيل المكتبة بالكامل.
انظر أيضا:
En-Pos -JavaScript Pos-tagger من Alex Corvi
NaturalNode - NLP الإحصائي المربي في JavaScript
Winkjs -Pos-tagger ، Tokenizer ، تعلم الآلة في JavaScript
Dariusk/POS -JS - Fasttag Fork في JavaScript
Compendium -JS - POS وتحليل المشاعر في JavaScript
اللغويات Nodebox - الاقتران ، الانعكاس في JavaScript
الاستعادة - أدوات مساعدة نصية رائعة للغاية في JavaScript
SuperScript - محرك محادثة في JS
Jspos- بناء JavaScript من Brill-Tagger الذي تم اختباره للوقت
spacy - tagger سريع ، متعدد اللغات في C/python
النثر - tagger Quick in Go by Joseph Kato
TextBlob - Python Tagger
معهد ماساتشوستس للتكنولوجيا