妥協

控えめな自然言語処理
npm install compromise
スペンサー・ケリーと多くの貢献者
妥協は、テキストをデータに変えるために
最善を尽くします。
それは限定的で賢明な決定を下します。
それはあなたが思うほど賢くありません。
import nlp from 'compromise'
let doc = nlp ( 'she sells seashells by the seashore.' )
doc . verbs ( ) . toPastTense ( )
doc . text ( )
// 'she sold seashells by the seashore.'
派手にならないでください:
if ( doc . has ( 'simon says #Verb' ) ) {
return true
}
テキストの部分をつかむ:
let doc = nlp ( entireNovel )
doc . match ( 'the #Adjective of times' ) . text ( )
// "the blurst of times?"
ドキュメントを一致させます
データを取得:
import plg from 'compromise-speech'
nlp . extend ( plg )
let doc = nlp ( 'Milwaukee has certainly had its share of visitors..' )
doc . compute ( 'syllables' )
doc . places ( ) . json ( )
/*
[{
"text": "Milwaukee",
"terms": [{
"normal": "milwaukee",
"syllables": ["mil", "wau", "kee"]
}]
}]
*/ JSON Docs
脆いパーサーの問題を避けてください:
let doc = nlp ( "we're not gonna take it.." )
doc . has ( 'gonna' ) // true
doc . has ( 'going to' ) // true (implicit)
// transform
doc . contractions ( ) . expand ( )
doc . text ( )
// 'we are not going to take it..'
収縮文書
そして、それがデータのようにむさぼりのようなもの:
let doc = nlp ( 'ninety five thousand and fifty two' )
doc . numbers ( ) . add ( 20 )
doc . text ( )
// 'ninety five thousand and seventy two'
番号ドキュメント
- 実際には -
let doc = nlp ( 'the purple dinosaur' )
doc . nouns ( ) . toPlural ( )
doc . text ( )
// 'the purple dinosaurs'
名詞ドキュメント
クライアント側で使用します:
< script src =" https://unpkg.com/compromise " > </ script >
< script >
var doc = nlp ( 'two bottles of beer' )
doc . numbers ( ) . minus ( 1 )
document . body . innerHTML = doc . text ( )
// 'one bottle of beer'
</ script >
または同様に:
import nlp from 'compromise'
var doc = nlp ( 'London is calling' )
doc . verbs ( ) . toNegative ( )
// 'London is not calling'
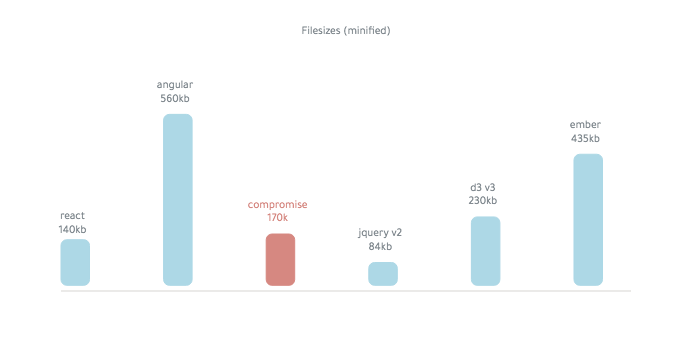
妥協点は〜250kb (マニファイ)です。
それはかなり速いです。キープレスで実行できます:
主に、基本的な単語リストのあらゆる形式を共役させることで機能します。
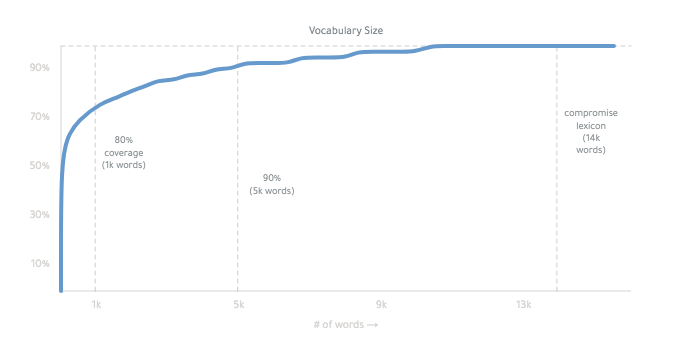
最後の辞書は約14,000語です。
こちらの仕組みについては、詳細をご覧ください。奇妙です。
わかった -
compromise/one
単語、文、句読点のtokenizer 。
import nlp from 'compromise/one'
let doc = nlp ( "Wayne's World, party time" )
let data = doc . json ( )
/* [{
normal:"wayne's world party time",
terms:[{ text: "Wayne's", normal: "wayne" },
...
]
}]
*/トークネイザードキュメント
妥協/1つはあなたのテキストを分割し、それを便利なAPIに包みます、
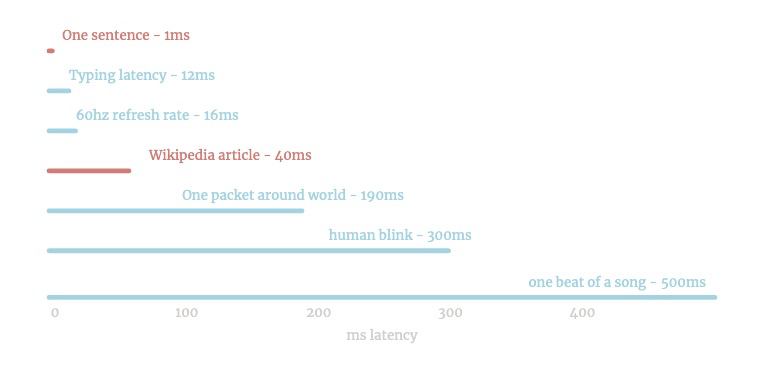
/1つは迅速です - ほとんどの文章は10分の1ミリ秒かかります。
1秒または10枚のウィキペディアページで〜1MBのテキストを実行できます。
Infinite Jestには3秒かかります。
また、妥協速度で並行したり、テキストをストリーミングしたりすることもできます。
compromise/two
part-of-speechタガー、および文法インタープレーター。
import nlp from 'compromise/two'
let doc = nlp ( "Wayne's World, party time" )
let str = doc . match ( '#Possessive #Noun' ) . text ( )
// "Wayne's World"
タガードキュメント
妥協/2は、各単語の非常に基本的な文法を自動的に計算します。
これは、人々が時々気づくよりも便利です。
Light Grammarは、クリーナーテンプレートを作成し、情報に近づくのに役立ちます。
妥協案には83のタグがあり、ハンサムなグラフに配置されています。
#firstname → #person → #propernoun → #noun
doc.debug()を実行することで、各単語の文法を見ることができます
nlp.verbose('tagger')を使用して、各タグの推論を見ることができます。
Pennタグを好む場合は、次のように導き出すことができます。
let doc = nlp ( 'welcome thrillho' )
doc . compute ( 'penn' )
doc . json ( )
compromise/three
Phraseと文のツール。
import nlp from 'compromise/three'
let doc = nlp ( "Wayne's World, party time" )
let str = doc . people ( ) . normalize ( ) . text ( )
// "wayne"
選択ドキュメント
妥協/3は、テキストの一部をズームインして操作するためのツールセットです。
.numbers() 、たとえば、ドキュメント内のすべての数値をつかみ、 .subtract()などの新しいメソッドで拡張します。
フレーズ、または単語のグループがある場合、 .json()でそれについて追加のメタデータを見ることができます
let doc = nlp ( 'four out of five dentists' )
console . log ( doc . fractions ( ) . json ( ) )
/*[{
text: 'four out of five',
terms: [ [Object], [Object], [Object], [Object] ],
fraction: { numerator: 4, denominator: 5, decimal: 0.8 }
}
]*/ let doc = nlp ( '$4.09CAD' )
doc . money ( ) . json ( )
/*[{
text: '$4.09CAD',
terms: [ [Object] ],
number: { prefix: '$', num: 4.09, suffix: 'cad'}
}
]*/
API
妥協/1
出力
- .text() - ドキュメントをテキストとして返します
- .json() - ドキュメントをデータとして返します
- .debug() - 解釈されたドキュメントをきれいにプリントします
- .out() - 名前付きまたはカスタム出力
- .html({{}) - マッチの出力カスタムHTMLタグ
- .wrap({}) - ドキュメントマッチ用にカスタム出力を生成します
utils
- .Found [getter] - このドキュメントは空ですか?
- .docs [getter] jsonとして用語オブジェクトを取得します
- .length [getter] - ドキュメント内の文字の#をカウント(文字列長)
- .isview [getter] - 妥協オブジェクトを特定します
- .compute() - ドキュメントで名前付き分析を実行します
- .clone() - ドキュメントをディープコピーして、参照が残っていないように
- .termlist() - 一致のすべての用語オブジェクトのフラットリストを返します
- .cache({{}) - 速度のためにドキュメントの現在の状態をフリーズします
- .uncache() - ドキュメントの現在の状態を除去するので、変換される可能性があります
- .freeze({{}) - これらの用語でタグが削除されるのを防ぎます
- .unfreeze({}) - デフォルトとして、タグを再度変更することを許可します
アクセッサ
- .all() - 元のドキュメント全体を返します(「ズームアウト」)
- .terms() - 個々の用語ごとに分割された結果
- .first(n) - 最初の結果のみを使用します
- .last(n) - 最後の結果のみを使用します
- .slice(n、n) - 結果のサブセットをつかみます
- .eq(n) - nの結果のみを使用します
- .firstterms() - 各試合で最初の単語を取得します
- .lastterms() - 各マッチで終了単語を取得します
- .fullsentences() - 各マッチの全文を取得します
- .groups() - マッチから名前付きキャプチャグループをつかみます
- .WordCount() - ドキュメント内の用語の#をカウントします
- .confidence() - POSタグ解釈の平均スコア
マッチ
(マッチメソッドはマッチシンタックスを使用します。)
- .MATCH( '') - 新しいドキュメントを親として返す新しいドキュメントを返します
- .not( '') - これを除くすべての結果を返します
- .Matchone( '') - 最初の一致のみを返します
- .if( '') - この一致が含まれている場合にのみ、各フレーズを返します( 'のみ)
- .ifno( '') - この一致のある現在のフレーズ( 'notif')をフィルタリングします
- .has( '') - この一致が存在する場合はブール値を返します
- .before( '') - 各フレーズの一致前にすべての条件を返します
- .After( '') - 各フレーズで、一致後にすべての条件を返します
- .union() - 複製なしのマッチを複製せずに返します
- .intersection() - 複製のみの一致のみを返します
- .complement() - 別の一致ではなくすべてを取得します
- .settle() - マッチからオーバーラップを削除します
- .growright( '') - 各一致の直後に一致する用語を追加する
- .GrowLeft( '') - 各一致の直前に一致する用語を追加します
- .grow( '') - 各一致の前または後に一致する項を追加します
- .sweep(net) - 一連のマッチオブジェクトをドキュメントに適用します
- .spliton( '') - 一致ごとに3つの部分を持つドキュメントを返します( 'spliton')
- .splitbefore( '') - 一致する各セグメントの前にフレーズをパーティションします
- .splitafter( '') - 一致する各セグメントの後にフレーズをパーティションします
- .join() - 各試合の隣接する用語をマージします
- .joinif(leftmatch、rightmatch) - 特定の条件下で隣接する項をマージする
- .lookup([]) - 文字列一致の配列のクイック検索
- .autofill() - ドキュメントにタイプアヘッドの仮定を作成します
タグ
- .tag( '') - すべての項に指定されたタグを与えます
- .tagsafe( '') - 現在のタグと一致している場合にのみ、タグを用語に適用します
- .untag( '') - 指定された用語からこの用語を削除します
- 。
場合
- .tolowercase() - すべての用語のすべての文字を低cseに変えます
- .touppercase() - すべての用語のすべての文字を大文字にめくる
- .totitlecase() - 各用語の最初の文字
- .tocamelcase() - 各用語ごとに白人とタイトルケースを削除します
空白
- .pre( '') - 各試合の前にこの句読点または白文学を追加する
- .post( '') - 各マッチの後にこの句読点または空白を追加する
- .trim() - 開始を削除して、Whitespaceを終了します
- .hyphenate() - 単語をハイフンと接続し、白面を削除します
- .dehyphenate() - 単語の間でハイフンを削除し、白面を設定します
- .toquotations() - これらの一致の周りに引用符を追加します
- .toparenthes() - これらのマッチの周りにブラケットを追加します
ループ
- .map(fn) - 関数を介して各フレーズを実行し、新しいドキュメントを作成します
- .foreach(fn) - 個々のドキュメントとして、各フレーズの関数を実行します
- .filter(fn) - trueを返すフレーズのみを返します
- .find(fn) - 一致する最初のフレーズのみでドキュメントを返します
- .some(fn) - 一致するフレーズが1つある場合はtrueまたはfalseを返します
- .Random(FN) - 結果のサブセットをサンプリングします
入れる
- .replace(一致、交換) - 新しいコンテンツで一致を検索して交換する
- .replacewith(置き換え) - 新しいテキストの代用
- .remove() - これらの用語をドキュメントから完全に削除します
- .intertbefore(str) - これらの新しい用語を各マッチの前面に追加します(prepend)
- .InserTafter(str) - これらの新しい用語を各マッチの最後に追加します(append)
- .concat() - これらの新しいものを最後に追加します
- .swap(fromlemma、tolemma) - 適切な共役を使用して、ルートワードのスマート交換
変身
- .sort( 'method') - マッチの順序を再配置(所定の位置)
- .Reverse() - 一致の順序を逆にしますが、単語ではありません
- .normalize({{}) - さまざまな方法でテキストをクリーンアップします
- .unique() - 重複する一致を削除します
lib
(これらのメソッドはメインnlpオブジェクトにあります)
nlp.tokenize(str) -Posタグを実行せずにテキストを解析します
nlp.lazy(str、match) - 最小分析でテキストをスキャンしてください
nlp.plugin({}) - 妥協とpluginを混ぜます
NLP.PARSEMATC(STR) - JSONへのマッチステートメント前の任意のパース
nlp.world() - ライブラリの内部をつかむか変更します
nlp.model() - 現在のすべての言語データをつかみます
nlp.methods() - 内部メソッドをつかむか変更します
nlp.hooks() - どの計算メソッドが自動的に実行されるかを参照してください
nlp.verbose(モード) - デバッグのために意思決定を記録します
NLP.Version-ライブラリの現在のSEMVERバージョン
nlp.addwords(obj、isfrozen?) - レキシコンに新しい単語を追加します
NLP.ADDTAGS(OBJ) - タグセットに新しいタグを追加します
nlp.typeahead(arr) - 自動充填辞書に単語を追加します
nlp.buildtrie(arr) - 単語のリストを速いルックアップフォームにコンパイルする
nlp.buildnet(arr) - マッチのリストをファストマッチフォームにコンパイルする
妥協/2:
収縮
- .Contractions() - 「Not」のようなもの
- .contractions()。expand() - 「not」のようなもの
- .contract() - 「しなかった」のようなもの
妥協/3:
名詞
- .nouns() - 名詞としてタグ付けされた後続の用語を返します
- .nouns()。json() - 名詞メタデータを使用したオーバーロード出力
- .nouns()。parse() - トークン化された名詞-phraseを取得します
- .nouns()。isplural() - 複数名詞のみを返します
- .nouns()。Issingular() - 単数名詞のみを返します
- .nouns()。toplural() -
'football captain' → 'football captains' - .nouns()。tosingular() -
'turnovers' → 'turnover' - .nouns()。形容詞() - この名詞を説明する形容詞を取得します
動詞
- .verbs() - 動詞としてタグ付けされた後続の用語を返します
- .verbs()。json() - 動詞メタデータを使用した過負荷出力
- .verbs()。parse() - トークン化された動詞-phraseを取得します
- .verbs()。subjects() - 動詞アクションを実行していること
- .verbs()。副詞() - この動詞を説明する副詞を返します。
- .verbs()。issingular() - 「スペンサーウォーク」のような単数動詞を返します
- .verbs()。isplural() - 「We Walk」のような複数の動詞を返します
- .verbs()。isimperative() - 「Eat It!」のような命令動詞のみの動詞
- .verbs()。topaStense() -
'will go' → 'went' - .verbs()。topresenttense() -
'walked' → 'walks' - .verbs()。tofuturetense() -
'walked' → 'will walk' - .verbs()。toinfinitive() -
'walks' → 'walk' - .verbs()。togerund() -
'walks' → 'walking' - .verbs()。topastparticiple() -
'drive' → 'had driven' - .verbs()。共役() - これらの動詞のすべてのコンジュゲーションを返します
- .verbs()。isNegative() - 「not」、「never」、または 'no'で動詞を返します
- .verbs()。ispositive() - 「not」、「never」、または 'no'のない動詞のみ
- .verbs()。tonegative() -
'went' → 'did not go' - .verbs()。topositive() -
"didn't study" → 'studied'
数字
- .Numbers() - 書かれた値と数値をすべてつかみます
- .Numbers()。parse() - トークン化された数値を取得します
- .Numbers()。get() - 簡単なJavaScript番号を取得します
- .Numbers()。json() - 数字メタデータを使用した過負荷出力
- .Numbers()。tonumber() - 「5」を
5に変換します - .numbers()。tolocalestring() - コンマを追加するか、数字の良いフォーマットを追加します
- .numbers()。totext() - '5'を
fiveに変換します - .Numbers()。toordinal() - 「5」を
fifthまたは5thに変換します - .Numbers()。tocardinal() - 「5番目」を
fiveまたは5に変換します - .Numbers()。ISORDINAL() - 順序数のみを返します
- .numbers()。iscardinal() - 枢機sumberのみを返します
- .Numbers()。iSequal(n) - この値で数値を返します
- .Numbers()。GREARTHAN(MIN) - nよりも大きい返品数を返します
- .numbers()。lessthan(max) - nよりも小さい返品番号
- .Numbers()。間(min、max) - minとmaxの間の返品数
- .Numbers()。iSunit(unit) - 「km」のように、指定されたユニットの数字のみを返します
- .Numbers()。set(n) - nに設定数を設定します
- .Numbers()。追加(n) - nで数値を増やします
- .Numbers()。減算(n) - nによって数値を減らします
- .numbers()。increment() - 数を増やします
- .numbers()。decroment() - 数を減少させます
- .money() -
'$2.50'のようなもの- .money()。get() - 解析された金額を取得します
- .money()。json() - 通貨 +番号情報
- .money()。currency() - 通貨はお金があります
- .fractions() - 「2/3rds」または「5つのうち1つ」のように
- .FRACTIONS()。parse() - トークン化された画分を取得します
- .fractions()。get() - 単純な分子、分母データ
- .FRACTIONS()。json() - jsonメソッドが分数データで過負荷になっています
- .fractions()。todecimal() - '2/3' - > '0.66'
- .FRACTIONS()。remormize() - '10' - > '4/10'
- .fractions()。totext() - '4/10' - > '4分の1'
- .fractions()。topercentage() - '4/10' - > '40% '
- .percentages() - '2.5%'のように
- .percentages()。get() - パーセンテージ番号 / 100を返します
- .percentages()。json() - jsonはパーセント情報で過負荷になりました
- .percentages()。tofraction() - '80% ' - >' 8/10 '
文
- .sentences() - 追加の方法で文クラスを返します
- .sentences()。json() - 文のメタデータを使用した過負荷出力
- .sentences()。topasttense() -
he walks - > he walked - .sentences()。topresenttense() -
he walked - > he walks - .sentences()。tofuturetense() -
he walks - > he will walk - .sentences()。toinfinitive() - 動詞ルートフォーム
he walks - > he walk - .sentences()。tonegative() -
he walks - > he didn't walk - .sentences()。isquestion() - 質問を返しますか
? - .sentences()。isexclamation() - aで文を返す
! - .sentences()。isstatement() - 文を返すことなく
?または!
形容詞
- .adjectives() -
'quick'のようなもの- .adjectives()。json() - 形容詞メタデータを取得します
- .adjectives()。共役() - これらの形容詞のすべての変曲を返します
- .adjectives()。adverbs() - この形容詞を説明する副詞を取得します
- .adjectives()。tocomparative() - 'Quick' - > 'より速い'
- .adjectives()。tosuperlative() - 'Quick' - > 'Quickest'
- .adjectives()。toadverb() - 'Quick' - > 'すばやく'
- .adjectives()。tonoun() - 'Quick' - > 'Quickness'
その他の選択
- .clauses() - 文章を複数期フレーズに分割します
- .Chunks() - 分割文名詞と動詞-Phrase
- .hyphenated() - ハイフンまたは
'wash-out'のようなダッシュに接続されたすべての用語 - .phoneNumbers() -
'(939) 555-0113'のようなもの - .hashtags() -
'#nlp'のようなもの - .emails() -
'[email protected]'のようなもの - .emoticons() -
:) - .emojis() - もののようなもの
? - .atmentions() -
'@nlp_compromise'のようなもの - .urls() -
'compromise.cool'のようなもの - .pronouns() -
'he'のようなもの - .conjunctions() -
'but'のようなもの - .prepositions() -
'of'のようなもの - .abbreviations() -
'Mrs.'のようなもの - .People() - 「John F. Kennedy」のような名前
- .people()。json() - get person -nameメタデータを取得します
- .people()。parse() - 個人名の解釈を取得します
- .places() - 「パリ、フランス」のように
- .ORGANIZATIONS() - 「Google、Inc」のように
- .topics() -
people() + places() + organizations() - .adverbs() -
'quickly'のようなもの- .adverbs()。json() - 副詞メタデータを取得します
- .ACRONYMS() -
'FBI'のようなもの- .ACRONYMS()。ストリップ() - 頭字語から期間を削除します
- .acronyms()。addperiods() - 頭字語に期間を追加します
- .parenthes() - 内部を返す(括弧)
- .parenthes()。strip() - ブラケットを取り外します
- .possessives() -
"Spencer's"のようなもの- .possessives()。strip() - "Spencer's" - > "Spencer"
- .Quotations() - ペアの引用マーク内の用語を返します
- .Quotations()。strip() - 引用符を削除します
- .slashes() - スラッシュによってグループ化された任意の用語を返します
- .slashes()。split() - 「愛/憎しみ」を「愛の憎しみ」に変える
。伸ばす():
このライブラリには、英語の文法のための思いやりのある常識的なベースラインが付属しています。
あなたは自由に変更することができます、またはあらゆる設定を廃止することができます - これは実際に楽しい部分です。
最も簡単な部分は、特定の単語のタグを提案することだけです。
let myWords = {
kermit : 'FirstName' ,
fozzie : 'FirstName' ,
}
let doc = nlp ( muppetText , myWords )または、妥協プラギンでより重い変更を加えます。
import nlp from 'compromise'
nlp . extend ( {
// add new tags
tags : {
Character : {
isA : 'Person' ,
notA : 'Adjective' ,
} ,
} ,
// add or change words in the lexicon
words : {
kermit : 'Character' ,
gonzo : 'Character' ,
} ,
// change inflections
irregulars : {
get : {
pastTense : 'gotten' ,
gerund : 'gettin' ,
} ,
} ,
// add new methods to compromise
api : View => {
View . prototype . kermitVoice = function ( ) {
this . sentences ( ) . prepend ( 'well,' )
this . match ( 'i [(am|was)]' ) . prepend ( 'um,' )
return this
}
} ,
} ) .plugin()docs
ドキュメント:
穏やかな紹介:
- #1)入力→出力
- #2)マッチと変換
- #3)チャットボットを作る
ドキュメント:
| 概念 | API | プラグイン |
|---|
| 正確さ | アクセッサ | 形容詞 |
| キャッシング | コンストラクターメソッド | 日付 |
| 場合 | 収縮 | 輸出 |
| filesize | 入れる | ハッシュ |
| 内部 | JSON | HTML |
| 正当化 | 文字オフセット | キープレス |
| レキシコン | ループ | ngrams |
| 一致シンタックス | マッチ | 数字 |
| パフォーマンス | 名詞 | 段落 |
| プラグイン | 出力 | スキャン |
| プロジェクト | 選択 | 文 |
| タガー | ソート | 音節 |
| タグ | スプリット | 発音する |
| トークン化 | 文章 | 厳しい |
| 名前付きエンティティ | utils | ペンタグ |
| 空白 | 動詞 | Typeahead |
| 世界データ | 正規化 | スイープ |
| ファジーマッチング | タイプスクリプト | 突然変異 |
| ルートフォーム | | |
講演:
- インターフェイスとしての言語- スペンサーケリーによる
- チャットボットのコーディング-Kahwee Tengによる
- タイピングとデータについて-Spencer Kellyによる
記事:
- NLPおよびJavaScriptとの社会的会話をジオコーディング- マイクロソフト
- マイクロサービスレシピ-Eventnによる
- アドベンチャーゲームの文は妥協を伴います
- テキストベースのゲームの構築-Matt Elandによる
- BigQueryのJavaScriptとの楽しみ- フェリペ・ホッファ著
- 自然言語処理...ブラウザ内? - チャールズ・ランダウ
いくつかの楽しいアプリケーション:
- 自動化されたBechdelテスト- ガーディアンによる
- ストーリー生成フレームワーク- ホセ・フロッカ著
- リストのタンブラーブログ-Horse -ebooksのようなリスト-MichaelPaulukonis
- 転写からのビデオ編集- 新しい理論による
- ブラウザ拡張ファクトチェック-AlexanderKiddによる
- Siriショートカット-Michael Byrnsによる
- Amazonスキル- Tajddin Maghniによる
- タスキングスラックボット-KevinSuhによる[詳細を参照]
比較
プラグイン:
これらはいくつかの役立つ拡張機能です:
日付
npm install compromise-dates
- .dates() -
June 8thまたは03/03/18のような日付を見つけます- .dates()。get() - simple start/end jsonの結果
- .dates()。json() - 日付メタデータを使用したオーバーロード出力
- .dates()。形式( '') - 日付を特定の形式に変換します
- .dates()。toshortform() - 「水曜日」を「水」などに変換します
- .dates()。tolongform() - 「2月」を「2月」などに変換します
- .Durations() -
2 weeksまたは5mins- .durations()。get() - simple jsonを返します
- .Durations()。json() - 持続時間メタデータを使用した過負荷出力
- .times() -
4:30pmまたはhalf past five- .times()。get() - 時間のために単純なjsonを返します
- .times()。json() - 時間メタデータを使用した過負荷出力
統計
npm install compromise-stats
.tfidf({}) - 頻度と一意性で単語をランク付けします
.ngrams({}) - ワードカウントで、すべての繰り返しサブフラゼをリストします
.unigrams() - n -grams 1つの単語で
.bigrams() - 2つの単語のn -grams
.trigrams() - n -grams 3つの単語
.startgrams() - フレーズの最初の用語を含むnグラム
.endgrams() - フレーズの最後の用語を含むnグラム
.EDEDGRAMS() - フレーズの最初または最後の用語を含むnグラム
スピーチ
npm install compromise-syllables
- .syllables() - 典型的な発音によって各用語を分割します
- .soundslike() - 推定発音を生成します
ウィキペディア
npm install compromise-wikipedia
タイプスクリプト
私たちは、メインと公式の両方で、タイプスクリプト/デノのサポートに取り組んでいます。
import nlp from 'compromise'
import stats from 'compromise-stats'
const nlpEx = nlp . extend ( stats )
nlpEx ( 'This is type safe!' ) . ngrams ( { min : 1 } )タイプスクリプトドキュメント
制限:
Slash-Support:私たちは現在、ハイフンのように、スラッシュをさまざまな単語として分割しています。したがって、このようなことは機能しません: nlp('the koala eats/shoots/leaves').has('koala leaves') //false
センテンス間の一致:デフォルトでは、文はトップレベルの抽象化です。インターセンテンス、またはマルチセンテンスマッチはプラグインなしではサポートされていません: nlp("that's it. Back to Winnipeg!").has('it back')//false
ネストされた一致構文: Regexの危険な美しさは、無期限に再発できることです。私たちのマッチ構文ははるかに弱いです。このようなことは(まだ)不可能です: doc.match('(modern (major|minor))? general')複雑な一致は、連続した.match()ステートメントで達成する必要があります。
依存関係の解析:適切な文の変換には、文の構文ツリーを理解する必要がありますが、現在はしていません。私たちはすべきです!これで望んでいたのは助けになります。
よくある質問
☂♥もjavascriptではありません...
ええ、そうです!
NLTKと競合するために構築されておらず、すべてのプロジェクトに適合しない場合があります。
文字列処理も同期しており、並列化ノードプロセスは奇妙です。
スピードとパフォーマンスの詳細については、プロジェクトの動機についてはこちらをご覧ください
? Arduino-Watchで実行できますか?
それが水に満ちている場合にのみ!
ワーカー、モバイルアプリ、あらゆる種類の面白い環境で妥協を実行するためのクイックスタートを読んでください。
?他の言語での妥協?
同じ哲学では、ドイツ語、フランス語、スペイン語、イタリア語の進行中のフォークを持っています。
そして、いくつかの助けが必要です。
部分的なビルド?
トークンのみのビルドを提供しています。
しかし、そうでなければ、妥協は簡単に樹状に揺れることはありません。
タグ付け方法は競争力があり、貪欲なので、物事を引き出すことはお勧めしません。
完全なPOSタグがなければ、収縮パーサーは完全に機能しないことに注意してください。 ( (スペンサーのクール) vs. (スペンサーの家) )
ライブラリを完全に実行することをお勧めします。
参照:
en-pos-アレックス・コルヴィによる非常に賢いJavaScript pos-tagger
NaturalNode -JavaScriptのファンシー統計NLP
Winkjs -JavaScriptのPos-Tagger、Tokenizer、Machine-Learning
Dariusk/POS -JS -JavaScriptのFastTagフォーク
compendium -js -JavaScriptのPOSおよび感情分析
ノードボックス言語学- 共役、javascriptの変曲
Retext- JavaScriptの非常に印象的なテキストユーティリティ
SuperScript- JSの会話エンジン
jspos -JavaScript現在のテストされたブリルタガーのビルド
スペイシー- c/pythonのスピーディで多言語タガー
散文- ジョセフ・カトによるゴーのクイックタガー
TextBlob -Python Tagger
mit