compromisso

processamento modesto de linguagem natural
npm install compromise
por Spencer Kelly e muitos colaboradores
Francês • Alemão • Italiano • Espanhol
O compromisso
é possível transformar o texto em dados.
toma decisões limitadas e sensatas.
Não é tão inteligente quanto você pensaria.
import nlp from 'compromise'
let doc = nlp ( 'she sells seashells by the seashore.' )
doc . verbs ( ) . toPastTense ( )
doc . text ( )
// 'she sold seashells by the seashore.'
Não seja sofisticado:
if ( doc . has ( 'simon says #Verb' ) ) {
return true
}
Pegue partes do texto:
let doc = nlp ( entireNovel )
doc . match ( 'the #Adjective of times' ) . text ( )
// "the blurst of times?"
Match Docs
e obtenha dados:
import plg from 'compromise-speech'
nlp . extend ( plg )
let doc = nlp ( 'Milwaukee has certainly had its share of visitors..' )
doc . compute ( 'syllables' )
doc . places ( ) . json ( )
/*
[{
"text": "Milwaukee",
"terms": [{
"normal": "milwaukee",
"syllables": ["mil", "wau", "kee"]
}]
}]
*/ JSON DOCs
Evite os problemas de analisadores quebradiços:
let doc = nlp ( "we're not gonna take it.." )
doc . has ( 'gonna' ) // true
doc . has ( 'going to' ) // true (implicit)
// transform
doc . contractions ( ) . expand ( )
doc . text ( )
// 'we are not going to take it..'
Documentos de contração
e chicotear coisas como se fossem dados:
let doc = nlp ( 'ninety five thousand and fifty two' )
doc . numbers ( ) . add ( 20 )
doc . text ( )
// 'ninety five thousand and seventy two'
Docos numéricos
-Vue que realmente é-
let doc = nlp ( 'the purple dinosaur' )
doc . nouns ( ) . toPlural ( )
doc . text ( )
// 'the purple dinosaurs'
substantivo docs
Use-o no lado do cliente:
< script src =" https://unpkg.com/compromise " > </ script >
< script >
var doc = nlp ( 'two bottles of beer' )
doc . numbers ( ) . minus ( 1 )
document . body . innerHTML = doc . text ( )
// 'one bottle of beer'
</ script >
ou da mesma forma:
import nlp from 'compromise'
var doc = nlp ( 'London is calling' )
doc . verbs ( ) . toNegative ( )
// 'London is not calling'
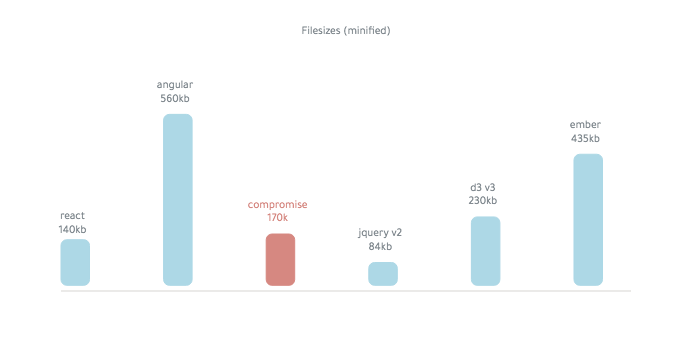
Compromisso é ~ 250kb (minificado):
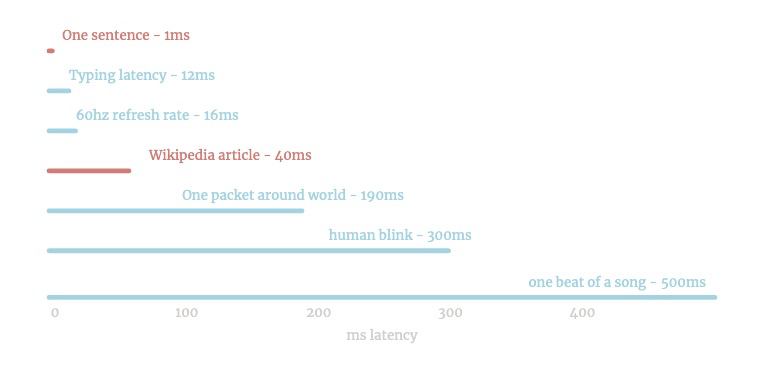
É muito rápido. Pode ser executado no KeyPress:
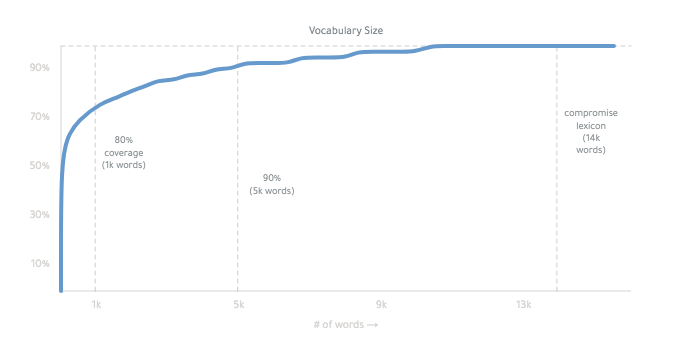
Funciona principalmente conjugando todas as formas de uma lista básica de palavras.
O léxico final é ~ 14.000 palavras:
Você pode ler mais sobre como funciona, aqui. É estranho.
OK -
compromise/one
Um tokenizer de palavras, frases e pontuação.
import nlp from 'compromise/one'
let doc = nlp ( "Wayne's World, party time" )
let data = doc . json ( )
/* [{
normal:"wayne's world party time",
terms:[{ text: "Wayne's", normal: "wayne" },
...
]
}]
*/ Docs tokenizer
Compromisso/um divide seu texto, envolve -o em uma API útil,
/Um é rápido - a maioria das frases toma 10º de um milissegundo.
Pode fazer ~ 1 MB de texto em uma segunda - ou 10 páginas da Wikipedia.
Jest Infinite leva 3s.
Você também pode paralelizar ou transmitir texto a ele com velocidade de compromisso.
compromise/two
Um tagger part-of-speech e interpretador gramatical.
import nlp from 'compromise/two'
let doc = nlp ( "Wayne's World, party time" )
let str = doc . match ( '#Possessive #Noun' ) . text ( )
// "Wayne's World"
DOCs de tagger
O compromisso/dois calcula automaticamente a gramática básica de cada palavra.
Isso é mais útil do que as pessoas às vezes imaginam.
A gramática leve ajuda a escrever modelos mais limpos e se aproximar das informações.
O compromisso possui 83 tags , dispostas em um gráfico bonito.
#Firstname → #person → #propernoun → #noun
Você pode ver a gramática de cada palavra executando doc.debug()
Você pode ver o raciocínio para cada tag com nlp.verbose('tagger') .
Se você preferir tags Penn , pode derivá -las com:
let doc = nlp ( 'welcome thrillho' )
doc . compute ( 'penn' )
doc . json ( )
compromise/three
Ferramenta Phrase e frase.
import nlp from 'compromise/three'
let doc = nlp ( "Wayne's World, party time" )
let str = doc . people ( ) . normalize ( ) . text ( )
// "wayne"
documentos de seleção
Compromise/três é um conjunto de ferramentas para aumentar o zoom e operar em partes de um texto.
.numbers() pega todos os números em um documento, por exemplo - e o estende com novos métodos, como .subtract() .
Quando você tem uma frase ou grupo de palavras, pode ver metadados adicionais sobre isso com .json()
let doc = nlp ( 'four out of five dentists' )
console . log ( doc . fractions ( ) . json ( ) )
/*[{
text: 'four out of five',
terms: [ [Object], [Object], [Object], [Object] ],
fraction: { numerator: 4, denominator: 5, decimal: 0.8 }
}
]*/ let doc = nlp ( '$4.09CAD' )
doc . money ( ) . json ( )
/*[{
text: '$4.09CAD',
terms: [ [Object] ],
number: { prefix: '$', num: 4.09, suffix: 'cad'}
}
]*/
API
Compromisso/um
Saída
- .Text () - Retorne o documento como texto
- .json () - Retorne o documento como dados
- .Debug () - Pretty -Print O documento interpretado
- .out () - uma saída nomeada ou personalizada
- .html ({}) - Saída tags html personalizadas para correspondências
- .Wrap ({}) - Produza saída personalizada para correspondências de documentos
UTILS
- .found [getter] - Este documento está vazio?
- .docs [getter] Obtenha objetos de termo como json
- .Length [getter] - Conte o número de caracteres no documento (comprimento da string)
- .isView [getter] - Identifique um objeto de compromisso
- .compute () - Execute uma análise nomeada no documento
- .clone () - cópia profunda do documento, para que nenhuma referência permaneça
- .termlist () - Retorne uma lista plana de todos os objetos de termo na correspondência
- .cache ({}) - congele o estado atual do documento, para purposes de velocidade
- .uncache () - despertar o estado atual do documento, para que possa ser transformado
- .freeze ({}) - impedem que qualquer tags seja removido, nesses termos
- .unfreeze ({}) - Permita que as tags mudem novamente, como padrão
Acessores
- .All () - Retorne o documento original inteiro ('Zoom Out')
- .terms () - Resultados divididos por cada termo individual
- . Primeiro (n) - use apenas os primeiros resultados
- .Last (n) - Use apenas os últimos resultados
- .Slice (n, n) - Pegue um subconjunto dos resultados
- .eq (n) - use apenas o enésimo resultado
- .Firstterms () - Obtenha a primeira palavra em cada partida
- .Lastterms () - Obtenha a palavra final em cada partida
- .fullSentences () - Obtenha a frase inteira para cada partida
- .groups () - Pegue todos os grupos de captura nomeados de uma partida
- .WordCount () - Conte o número de termos no documento
- .confidence () - uma pontuação média para interpretações de tags de POS
Corresponder
(Os métodos de correspondência usam o Match-Syntax.)
- .match ('') - devolva um novo documento, com este como um pai
- .Not ('') - retorne todos os resultados, exceto por isso
- .matchone ('') - retorne apenas a primeira partida
- .if ('') - retorne cada frase atual, apenas se contiver esta correspondência ('somente')
- .IFNO ('') - Filtre todas as frases atuais que tenham essa correspondência ('notif')
- .has ('') - retorne um booleano se essa partida existir
- .Before ('') - Retorne todos os termos antes de uma partida, em cada frase
- .aFter ('') - Retorne todos os termos após uma partida, em cada frase
- .Union () - Retorno correspondências combinadas sem duplicatas
- .Intersection () - Retorne apenas correspondências duplicadas
- .Complement () - Obtenha tudo em outra partida
- .Settle () - Remova sobreposições das correspondências
- .growright ('') - Adicione todos os termos correspondentes imediatamente após cada partida
- .growleft ('') - Adicione todos os termos correspondentes imediatamente antes de cada partida
- .grow ('') - Adicione todos os termos correspondentes antes ou depois de cada partida
- .sweep (net) - aplique uma série de objetos de correspondência no documento
- .Spliton ('') - Retorne um documento com três partes para cada partida ('Spliton')
- .SplitBefore ('') - Partição de uma frase antes de cada segmento correspondente
- .splitafter ('') - Partição uma frase após cada segmento correspondente
- .Join () - mesclar qualquer termos vizinhos em cada partida
- .Joinif (LeftMatch, RightMatch) - Mesclar todos os termos vizinhos em determinadas condições
- .lookup ([]) - Encontre rápido para uma variedade de correspondências de string
- .AUTOFILL () - Crie suposições do tipo Ahead no documento
Marcação
- .TAG ('') - Dê a todos os termos a tag fornecida
- .TAGSAFE ('') - aplique apenas tag nos termos se for consistente com as tags atuais
- .untrag ('') - remova este termo dos termos fornecidos
- .CANBE ('') - retorne apenas os termos que podem ser esta tag
Caso
- .TolowerCase () - Gire todas
- .TOUPPERCASE () - Gire todas as letras de cada termo para maiúsculas
- .TotitLecase () - Caso superior da primeira letra de cada termo
- .TocamelCase () - Remova o espaço em branco e o título de cada termo
Espaço em branco
- .pre ('') - Adicione esta pontuação ou espaço em branco antes de cada partida
- .Post ('') - Adicione esta pontuação ou espaço em branco após cada partida
- .Trim () - Remova o espaço em branco inicial e final
- . -hifenato () - conecte palavras com hífen e remova o espaço em branco
- .DEHIPENATE () - Remova os hífens entre as palavras e defina espaço em branco
- .toquotações () - Adicione aspas em torno dessas partidas
- .toparentesses () - Adicione colchetes em torno dessas partidas
Loops
- .MAP (FN) - Execute cada frase através de uma função e crie um novo documento
- .ForEach (FN) - Execute uma função em cada frase, como um documento individual
- .Filter (FN) - Retorne apenas as frases que retornam verdadeiro
- .Find (FN) - Retorne um documento com apenas a primeira frase que corresponde
- . Alguns (fn) - retorne verdadeiro ou falso se houver uma frase correspondente
- .Random (FN) - Amostra um subconjunto dos resultados
Inserir
- .place (corresponda, substitua) - Pesquise e substitua a correspondência com o novo conteúdo
- .LeRplacewith (Substituir) - Substituir novo texto
- .remove () - remova totalmente estes termos do documento
- .InsertBefore (STR) - Adicione esses novos termos à frente de cada partida (precente)
- .Insertafter (STR) - Adicione esses novos termos ao final de cada partida (Anexo)
- .CONCAT () - Adicione essas coisas novas ao fim
- .swap (fromlemma, tolemma) - Smart Substituir de palavras -raiz, usando a conjugação adequada
Transformar
- .sort ('método') - reorganize a ordem das partidas (no lugar)
- .ververse () - reverte a ordem das correspondências, mas não as palavras
- .Normalize ({}) - Limpe o texto de várias maneiras
- .Unique () - Remova qualquer correspondência duplicada
Lib
(Esses métodos estão no objeto nlp principal)
nlp.tokenize (str) - Parse o texto sem executar a margem de posse
NLP.LAZY (STR, Match) - Digitalizar um texto com análise mínima
nlp.plugin ({}) - Misture em um compromisso -plugin
NLP.PARSEMATCH (STR) - Pré -parse qualquer declaração de partida no JSON
nlp.world () - Agarre ou alterar a biblioteca interna
nlp.model () - Pegue todos os dados lingüísticos atuais
nlp.methods () - Agarre ou altere os métodos internos
nlp.Hooks () - Veja quais métodos de computação são executados automaticamente
nlp.verbose (modo) - registre nossa tomada de decisão para depuração
NLP.Version - Versão atual de Semver da biblioteca
nlp.addwords (obj, isfrozen?) - Adicione novas palavras ao léxico
nlp.addtags (obj) - Adicione novas tags ao tagset
nlp.typeahead (arr) - Adicione palavras ao dicionário de preenchimento automático
nlp.buildtrie (arr) - Compile uma lista de palavras em um formulário de pesquisa rápida
nlp.buildNet (arr) - Compile uma lista de correspondências em uma forma de correspondência rápida
compromisso/dois:
Contrações
- .Contactions () - coisas como "não"
- .Contactions (). Expand () - coisas como "não"
- .CoCract () - coisas como "não"
Compromisso/três:
Substantivos
- .Nouns () - Retorne quaisquer termos subsequentes marcados como um substantivo
- .Nouns (). JSON () - Saída sobrecarregada com metadados substantivos
- .Nouns ().
- .Nouns (). Isplural () - Retorne apenas substantivos plurais
- .Nouns (). Issingular () - Retorne apenas substantivos singulares
- .Nouns (). Toplural () -
'football captain' → 'football captains' - .Nouns (). Tosingular () -
'turnovers' → 'turnover' - .Nouns (). Adjetivos () - Obtenha adjetivos que descrevem este substantivo
Verbos
- .verbs () - Retorne quaisquer termos subsequentes marcados como um verbo
- .verbs (). json () - saída sobrecarregada com metadados verbos
- .verbs (). parse () - obtenha o frasco verbal tokenizado
- .verbs (). sujeitos () - o que está fazendo a ação verbal
- .verbs (). Adverbs () - Retorne os advérbios que descrevem este verbo.
- .VERBS (). ISSINGULAR () - Retorne verbos singulares como 'Spencer Walks'
- .verbs (). isplural () - retorna verbos plurais como 'We Walk'
- .verbs (). isimperative () - apenas verbos de instrução como 'coma!'
- .verbs (). topASTTense () -
'will go' → 'went' - .verbs (). topResentTense () -
'walked' → 'walks' - .verbs (). TofutureTense () -
'walked' → 'will walk' - .verbs (). Toinfinitive () -
'walks' → 'walk' - .verbs (). TOGERUND () -
'walks' → 'walking' - .verbs (). topASTParticiple () -
'drive' → 'had driven' - .verbs (). conjugate () - retorna todas as conjugações desses verbos
- .verbs (). Isnegative () - Retornar verbos com 'não', 'nunca' ou 'não'
- .verbs (). ispositivo () - apenas verbos sem 'não', 'nunca' ou 'não'
- .verbs (). Tonegative () -
'went' → 'did not go' - .verbs (). topoosition () -
"didn't study" → 'studied'
Números
- .Numbers () - Pegue todos os valores escritos e numéricos
- .Numbers (). Parse () - Obtenha a frase numérica tokenizada
- .Numbers (). Get () - Obtenha um número de javascript simples
- .Numbers (). JSON () - Saída sobrecarregada com metadados numéricos
- .Numbers (). Tonumber () - converta 'cinco' para
5 - .Numbers (). Tolocalestring () - Adicione vírgulas ou formatação mais agradável para números
- .Numbers (). Totext () - converta '5' a
five -
fifth () 5th - .Numbers (). Tocardinal () - converta 'quinto' para
five ou 5 - .Numbers (). Isordinal () - Retorne apenas números ordinais
- .numbers (). iscardinal () - Retorne apenas números cardinais
- .Numbers (). ISequal (n) - Retornar números com este valor
- .Numbers (). Greaterthan (min) - Retornar números maiores que n
- .Numbers (). LessThan (max) - Retorno números menores que n
- .Numbers (). Entre (min, max) - retorna números entre min e max
- .Numbers (). Isunit (unidade) - Retorne apenas números na unidade especificada, como 'km'
- .Numbers (). Set (n) - Defina o número como n
- .Numbers (). Add (n) - Aumente o número por n
- .Numbers (). Subtrair (n) - diminuir o número por n
- .numbers (). increment () - aumente o número em 1
- .Numbers (). decremento () - diminua o número em 1
- .Money () - coisas como
'$2.50'- .Money (). Get () - Recupere a (s) quantia (s) de dinheiro (s) analisada (s)
- .Money (). JSON () - Moeda + Informações do Número
- .Money (). Currency () - Qual moeda o dinheiro está em
- .frações () - como '2/3rds' ou 'um em cada cinco'
- .Frações (). Parse () - Obtenha fração tokenizada
- .frações (). get () - numerador simples, dados de denominador
- .FRACTIONS (). JSON () - JSON Método sobrecarregado com dados de frações
- .frações (). Todecimal () - '2/3' -> '0,66'
- .frações (). normalize () - 'quatro de 10' -> '4/10'
- .frações (). Totext () - '4/10' -> 'Quatro décimos'
- .FRACTIONS (). TOPERCENTAGE () - '4/10' -> '40%'
- .Percentages () - como '2,5%'
- .Percentages (). Get () - Retorne o número percentual / 100
- .Percentages ().
- .Percentages (). Tofraction () - '80%' ->' 8/10 '
Frases
- .Sentences () - Retorne uma classe de frase com métodos adicionais
- .Sentences (). JSON () - Saída sobrecarregada com metadados da frase
- .
he walks he walked - .
he walked he walks - .
he walks he will walk - .
he walks he walk - .
he walks he didn't walk - .SENTENCES (). ISQUESTION () - Retornar perguntas com um
? - .Sentences (). isExclamation () - Retorno frases com um
! - .Sentences (). isStatement () - Retorno frases sem
? ou !
Adjetivos
- .Adjectives () - coisas como
'quick'- .Adjetivos (). JSON () - Obtenha metadados adjetivos
- .Adjectives (). conjugate () - Retorne todas as inflexões desses adjetivos
- .Adjetivos (). Advérbios () - Obtenha advérbios descrevendo este adjetivo
- .Adjectives (). TOCOMPARATIVO () - 'RÁPIDO' -> 'mais rápido'
- .Adjetivos (). Tosuperlative () - 'Quick' -> 'mais rápido'
- .Adjectives (). Toadverb () - 'Quick' -> 'Rapidamente'
- .Adjectives (). Tonoun () - 'Rápido' -> 'rapidez'
Seleções Misc
- .claUses () -Split-up frases em frases multi-terminadas
- .chunks () -frases divididas em frases e frases verbais
- .Hifenado () - Todos os termos relacionados a um hífen ou traço como
'wash-out' - .phonenumbers () - coisas como
'(939) 555-0113' - .hashtags () - coisas como
'#nlp' - .Emails () - coisas como
'[email protected]' - .emoticons () - coisas como
:) - .emojis () - coisas como
? - .atmentions () - coisas como
'@nlp_compromise' - .urls () - coisas como
'compromise.cool' - .prons () - coisas como
'he' - .conjunctions () - coisas como
'but' - .Prepositions () - coisas como
'of' - .ABBREVIATIONS () - Coisas como
'Mrs.' - .People () - Nomes como 'John F. Kennedy'
- .People (). JSON () - Obtenha metadados do nome da pessoa
- .People (). Parse () - Obtenha a interpretação do nome da pessoa
- .places () - como 'Paris, França'
- .Organizações () - como 'Google, Inc'
- .Topics () -
people() + places() + organizations() - .Adverbs () - coisas como
'quickly'- .Adverbs (). JSON () - Obtenha metadados de advérbios
- .ACRONYMS () - Coisas como
'FBI'- .acrônimos (). Strip () - Remova períodos de acrônimos
- .ACRONYMS (). addPeriods () - Adicione períodos às acrônimas
- .Parenthesses () - Retorne qualquer coisa dentro (parênteses)
- .parentesses (). Strip () - Remova os colchetes
- .Possessives () - coisas como
"Spencer's"- .Possessives (). Strip () - "Spencer's" -> "Spencer"
- .quotações () - Retorne todos os termos dentro de aspas emparelhadas
- .quotações (). Strip () - Remova as aspas
- .SLASHES () - Retorne todos os termos agrupados por barras
- .SLASHES (). Split () - Transforme 'Love/Hate' em 'Love Hate'
.Extend ():
Esta biblioteca vem com uma linha de base de senso comum e atencioso para a gramática inglesa.
Você é livre para mudar ou lateral para qualquer configuração - que é a parte divertida.
A parte mais fácil é apenas sugerir tags para qualquer palavra:
let myWords = {
kermit : 'FirstName' ,
fozzie : 'FirstName' ,
}
let doc = nlp ( muppetText , myWords ) Ou faça alterações mais pesadas com um comprometimento-plugina.
import nlp from 'compromise'
nlp . extend ( {
// add new tags
tags : {
Character : {
isA : 'Person' ,
notA : 'Adjective' ,
} ,
} ,
// add or change words in the lexicon
words : {
kermit : 'Character' ,
gonzo : 'Character' ,
} ,
// change inflections
irregulars : {
get : {
pastTense : 'gotten' ,
gerund : 'gettin' ,
} ,
} ,
// add new methods to compromise
api : View => {
View . prototype . kermitVoice = function ( ) {
this . sentences ( ) . prepend ( 'well,' )
this . match ( 'i [(am|was)]' ) . prepend ( 'um,' )
return this
}
} ,
} ) .Plugin () Docs
Documentos:
Introdução suave:
- #1) Entrada → Saída
- #2) Combine e transforme
- #3) Fazendo um bate-papo
Documentação:
| Conceitos | API | Plugins |
|---|
| Precisão | Acessores | Adjetivos |
| Cache | Construtor-métodos | Datas |
| Caso | Contrações | Exportar |
| LIMPERIDO FIONS | Inserir | Hash |
| Internalas | JSON | Html |
| Justificação | Compensações de personagens | KeyPress |
| Léxico | Loops | Ngrams |
| Match-Syntax | Corresponder | Números |
| Desempenho | Substantivos | Parágrafos |
| Plugins | Saída | Scan |
| Projetos | Seleções | Frases |
| Tagger | Classificação | Sílabas |
| Tags | Dividir | Pronunciar |
| Tokenização | Texto | Estrito |
| Nomeadas-entidades | UTILS | Penn-Tags |
| Espaço em branco | Verbos | Typeahead |
| Dados mundiais | Normalização | Varrer |
| Combinação difusa | TypeScript | Mutação |
| Formas de raiz | | |
Conversas:
- Linguagem como uma interface - de Spencer Kelly
- Coding Chat Bots - Por Kahwee Teng
- Sobre digitação e dados - de Spencer Kelly
Artigos:
- Conversas sociais de geocodificação com PNL e JavaScript - da Microsoft
- Receita de microsserviço - por eventn
- Aventure Game Sinence analisando com compromisso
- Construindo jogos baseados em texto - de Matt Eland
- Diversão com JavaScript em BigQuery - de Felipe Hoffa
- Processamento de linguagem natural ... no navegador? - por Charles Landau
Alguns aplicativos divertidos:
- Teste de Bechdel automatizado - pelo Guardian
- Estrutura de geração de histórias - por Jose Phrocca
- Tumbler Blog of Lists - Listas do tipo Horse -Ebooks - Por Michael Paulukonis
- Edição de vídeo da transcrição - por nova teoria
- Extensão do navegador Verificação de fatos - por Alexander Kidd
- Atalho Siri - de Michael Byrns
- Habilidade da Amazon - de Tajddin Maghni
- Tasking Slack -Bot - Por Kevin Suh [Veja mais]
Comparações
- Compromisso e Spacy
- Compromisso e NLTK
Plugins:
Estas são algumas extensões úteis:
Datas
npm install compromise-dates
- .DATES () - Encontre datas como
June 8th ou 03/03/18- .DATES (). Get () - Resultado de JSON de início/final simples
- .DATES (). JSON () - Saída sobrecarregada com metadados de data
- .dates (). formato ('') - converta as datas em formatos específicos
- .DATES ().
- .DATES (). TOLONGFORM () - Converta 'fev' para 'fevereiro', etc.
- .durações () -
2 weeks ou 5mins- .durações (). Get () - Retorne JSON simples por duração
- .durações (). JSON () - Saída sobrecarregada com metadados de duração
- .Times () -
4:30pm ou half past five- .Times (). Get () - Retorne JSON simples para os tempos
- .Times (). JSON () - Saída sobrecarregada com metadados do tempo
Estatísticas
npm install compromise-stats
.tfidf ({}) - classifique as palavras por frequência e singularidade
.ngrams ({}) -liste todas as sub-frases repetidas, por contagem de palavras
.Unigrams () - n -gramas com uma palavra
.bigrams () - n -gramas com duas palavras
.TRIGRAMS () - N -Grams com três palavras
.StartGrams () - n -gramas, incluindo o primeiro mandato de uma frase
.ENDGRAMS () - N -Grams, incluindo o último mandato de uma frase
.EdgeGrams () - n -gramas, incluindo o primeiro ou o último mandato de uma frase
Discurso
npm install compromise-syllables
- .syllables () - divida cada termo por sua pronúncia típica
- .SoundsLike () - produz uma pronúncia estimada
Wikipedia
npm install compromise-wikipedia
- .wikipedia () - Reconciliação do artigo comprimido
TypeScript
Estamos comprometidos com o suporte de TypeScript/deno, tanto no Principal quanto no Plugins Oficiais:
import nlp from 'compromise'
import stats from 'compromise-stats'
const nlpEx = nlp . extend ( stats )
nlpEx ( 'This is type safe!' ) . ngrams ( { min : 1 } ) Documentos datilografados
Limitações:
Atualmente , o suporte de barra: Atualmente, dividimos o corte como palavras diferentes, como fazemos para os hífens. Então, coisas assim não funcionam: nlp('the koala eats/shoots/leaves').has('koala leaves') //false
Combinação entre sentenças: por padrão, as frases são a abstração de nível superior. As correspondências inter-sentenças, ou multi-frase, não são suportadas sem um plug-in: nlp("that's it. Back to Winnipeg!").has('it back')//false
Sintaxe do Match Nested: A beleza do perigo de Regex é que você pode voltar indefinidamente. Nossa sintaxe de partida é muito mais fraca. Coisas como essa não são (ainda) possíveis: doc.match('(modern (major|minor))? general') Matches complexos devem ser alcançados com declarações sucessivas .match () .
Analisação de dependência: a transformação adequada da frase requer a compreensão da árvore de sintaxe de uma frase, o que não fazemos atualmente. Devemos! Ajuda desejada com isso.
Perguntas frequentes
☂️ Não é JavaScript também ...
Sim, é!
Foi construído para competir com o NLTK e pode não se encaixar em todos os projetos.
O processamento de string também é síncrono e os processos de nó paralelo são estranhos.
Veja aqui as informações sobre velocidade e desempenho, e aqui para motivações do projeto
? Ele pode ser executado no meu Arduino-Watch?
Somente se for à prova de água!
Leia o início rápido para o comprometimento de trabalhadores, aplicativos móveis e todos os tipos de ambientes engraçados.
? Compromisso em outros idiomas?
Temos garfos de trabalho em andamento para alemão, francês, espanhol e italiano na mesma filosofia.
e precisa de ajuda.
Construções parciais?
Oferecemos uma construção somente para tokenize, que tem o post-tagge.
Mas, caso contrário, o compromisso não é facilmente agitado em árvores.
Os métodos de marcação são competitivos e gananciosos, por isso não é recomendável tirar as coisas.
Observe que, sem um POS completo, o parador de contração não funcionará perfeitamente. ( (Spencer's Cool) vs. (casa de Spencer) )
É recomendável executar a biblioteca completamente.

Veja também:
EN-POS -JavaScript Pos-Tagger muito inteligente por Alex Corvi
NaturalNode - NLP estatística mais sofisticada em JavaScript
Winkjs -Pos-Tagger, tokenizer, aprendizado de máquina em JavaScript
Dariusk/Pos -JS - FastTag Fork em JavaScript
Compêndio -JS - POS e análise de sentimentos em JavaScript
Linguística de Nodebox - conjugação, inflexão em JavaScript
RETEXT - Utilitários de texto muito impressionantes em JavaScript
SUPERSCRIPT - MOTOR DE CONVERSA EM JS
JSPOs -Javascript Build of the Time Tested Brill-Tagger
Spacy - Tagger rápido e multilíngue em C/Python
Prosa - Tagger rápido em Go por Joseph Kato
TextBlob - Python Tagger
Mit