компромисс

скромная обработка естественного языка
npm install compromise
Спенсер Келли и многие участники
Французский • Немецкий • Итальянский • Испанский
Разве ты не считаешь это странным,
Компромисс
старается лучше превратить текст в данные.
Это принимает ограниченные и разумные решения.
Это не так умно, как вы думаете.
import nlp from 'compromise'
let doc = nlp ( 'she sells seashells by the seashore.' )
doc . verbs ( ) . toPastTense ( )
doc . text ( )
// 'she sold seashells by the seashore.'
Вообще не будь фантазией:
if ( doc . has ( 'simon says #Verb' ) ) {
return true
}
Возьмите части текста:
let doc = nlp ( entireNovel )
doc . match ( 'the #Adjective of times' ) . text ( )
// "the blurst of times?"
Сопоставленные документы
и получить данные:
import plg from 'compromise-speech'
nlp . extend ( plg )
let doc = nlp ( 'Milwaukee has certainly had its share of visitors..' )
doc . compute ( 'syllables' )
doc . places ( ) . json ( )
/*
[{
"text": "Milwaukee",
"terms": [{
"normal": "milwaukee",
"syllables": ["mil", "wau", "kee"]
}]
}]
*/ JSON DOCS
Избегайте проблем хрупких анализаторов:
let doc = nlp ( "we're not gonna take it.." )
doc . has ( 'gonna' ) // true
doc . has ( 'going to' ) // true (implicit)
// transform
doc . contractions ( ) . expand ( )
doc . text ( )
// 'we are not going to take it..'
Сокращение документов
И взбейте вещи, как это данные:
let doc = nlp ( 'ninety five thousand and fifty two' )
doc . numbers ( ) . add ( 20 )
doc . text ( )
// 'ninety five thousand and seventy two'
номер документы
-М, если это на самом деле-
let doc = nlp ( 'the purple dinosaur' )
doc . nouns ( ) . toPlural ( )
doc . text ( )
// 'the purple dinosaurs'
существительные документы
Используйте его на стороне клиента:
< script src =" https://unpkg.com/compromise " > </ script >
< script >
var doc = nlp ( 'two bottles of beer' )
doc . numbers ( ) . minus ( 1 )
document . body . innerHTML = doc . text ( )
// 'one bottle of beer'
</ script >
или также:
import nlp from 'compromise'
var doc = nlp ( 'London is calling' )
doc . verbs ( ) . toNegative ( )
// 'London is not calling'
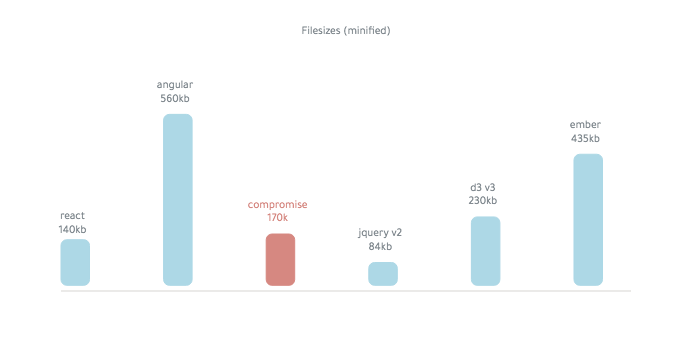
Компромисс составляет ~ 250 КБ (минимизированный):
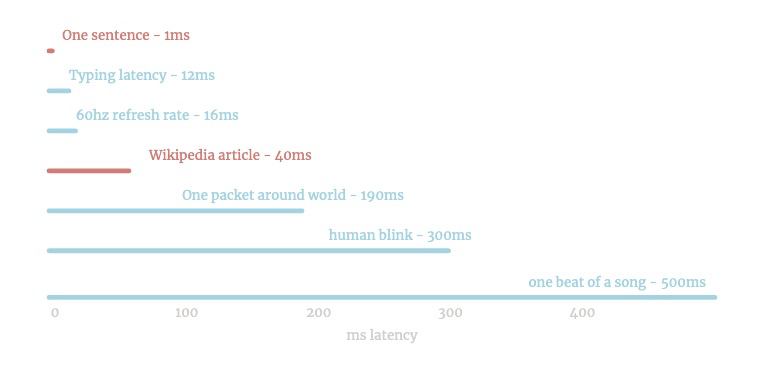
Это довольно быстро. Он может работать на Keypress:
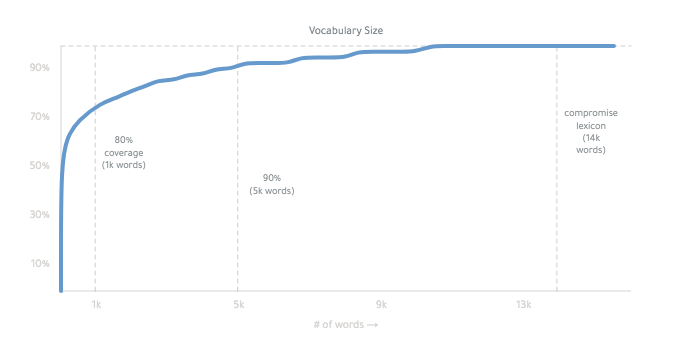
Он работает в основном путем сопряжения всех форм основного списка слов.
Окончательная лексика составляет ~ 14 000 слов:
Вы можете прочитать больше о том, как это работает, здесь. это странно.
хорошо -
compromise/one
tokenizer слов, предложений и пунктуации.
import nlp from 'compromise/one'
let doc = nlp ( "Wayne's World, party time" )
let data = doc . json ( )
/* [{
normal:"wayne's world party time",
terms:[{ text: "Wayne's", normal: "wayne" },
...
]
}]
*/ Документы из токенизатора
Компромисс/один расщепляет ваш текст, завершает его в удобном API,
и больше ничего не делает -
/Один быстрый - большинство предложений занимают 10 -е место из миллисекунды.
Он может сделать ~ 1 МБ текста на второй или 10 страницах Википедии.
Бесконечная шутка занимает 3 с.
Вы также можете параллелизировать или погрузиться в него с помощью компромисса.
compromise/two
part-of-speech и грамматическая интернет-интернет.
import nlp from 'compromise/two'
let doc = nlp ( "Wayne's World, party time" )
let str = doc . match ( '#Possessive #Noun' ) . text ( )
// "Wayne's World"
Tagger Docs
Компромисс/два автоматически рассчитывает самую основную грамматику каждого слова.
Это более полезно, чем люди иногда осознают.
Light Grammar помогает вам писать более чистые шаблоны и приблизиться к информации.
Компромисс имеет 83 тега , расположенные в красивом графике.
#Firstname → #person → #propernoun → #noun
Вы можете увидеть грамматику каждого слова, запустив doc.debug()
Вы можете увидеть причины для каждого тега с помощью nlp.verbose('tagger') .
Если вы предпочитаете теги Penn , вы можете получить их с помощью:
let doc = nlp ( 'welcome thrillho' )
doc . compute ( 'penn' )
doc . json ( )
compromise/three
Phrase и предложение инструментов.
import nlp from 'compromise/three'
let doc = nlp ( "Wayne's World, party time" )
let str = doc . people ( ) . normalize ( ) . text ( )
// "wayne"
Отбор документов
Компромисс/Три - это набор инструментов для масштабирования и работы на частях текста.
.numbers() , например, захватывает все числа в документе - и расширяет его новыми методами, такими как .subtract() .
Когда у вас есть фраза или группа слов, вы можете увидеть дополнительные метаданные об этом с .json()
let doc = nlp ( 'four out of five dentists' )
console . log ( doc . fractions ( ) . json ( ) )
/*[{
text: 'four out of five',
terms: [ [Object], [Object], [Object], [Object] ],
fraction: { numerator: 4, denominator: 5, decimal: 0.8 }
}
]*/ let doc = nlp ( '$4.09CAD' )
doc . money ( ) . json ( )
/*[{
text: '$4.09CAD',
terms: [ [Object] ],
number: { prefix: '$', num: 4.09, suffix: 'cad'}
}
]*/
API
Компромисс/один
Выход
- .Text () - вернуть документ как текст
- .json () - вернуть документ как данные
- .debug () - довольно напечатать интерпретированный документ
- .out () - названный или пользовательский вывод
- .html ({}) - вывод пользовательские теги HTML для совпадений
- .wrap ({}) - создать пользовательский вывод для соответствия документов
Утилит
- .found [Getter] - этот документ пуст?
- .docs [Getter] Получите термины объектов как json
- .length [Getter] - Подсчитайте # символов в документе (длина строки)
- .isview [Getter] - Определите компромиссный объект
- .compute () - запустить именованный анализ в документе
- .CLONE () - Глубокая копия документа, так что не осталось ссылок
- .tramplist () - вернуть плоский список всех объектов терминов в матче
- .cache ({}) - заморозить текущее состояние документа, для скорости
- .uncache () - не замерзает текущее состояние документа, поэтому он может быть преобразован
- .freeze ({}) - предотвратить удаление любых тегов, в этих терминах
- .unfreeze ({}) - Разрешить теги снова измениться, как по умолчанию
Аксессов
- .all () - вернуть весь оригинальный документ ('Zoom Out')
- .terms () - Результаты разделения по каждому отдельному термину
- . FIRST (N) - Используйте только первый результат (ы)
- .last (n) - Используйте только последний результат (ы)
- .slice (n, n) - взять подмножество результатов
- .eq (n) - Используйте только n -й результат
- . firstterms () - Получите первое слово в каждом матче
- .lastterms () - Получите конечное слово в каждом матче
- .fullSentences () - Получите все предложение для каждого матча
- .groups () - захватить любые названные группы захвата из матча
- .WordCount () - Подсчитайте # терминов в документе
- .confidence () - Средний балл для интерпретации TAG POS
Соответствовать
(Методы соответствия Используйте Satch-Syntax.)
- .match ('') - вернуть новый документ с этим как родитель
- .not ('') - вернуть все результаты, кроме этого
- .matchone ('') - вернуть только первый матч
- .if ('') - вернуть каждую текущую фразу, только если она содержит это совпадение («только»)
- .ifno ('') - отфильтровывать любые текущие фразы, которые имеют это совпадение ('Notif')
- .has ('') - вернуть логический
- .bofore ('') - вернуть все термины перед совпадением, в каждой фразе
- .after ('') - вернуть все термины после совпадения, в каждой фразе
- .union () - возвращать комбинированные совпадения без дубликатов
- .Intersection () - вернуть только дублирующие совпадения
- .complement () - Получите все, что не в другом матче
- .settle () - удалить перекрытия из совпадений
- .growright ('') - Добавьте любые соответствующие термины сразу после каждого матча
- .growleft ('') - Добавьте любые соответствующие термины непосредственно перед каждым матчем
- .grow ('') - Добавьте любые соответствующие термины до или после каждого матча
- .sweep (net) - Примените серию объектов совпадения в документ
- .spliton ('') - вернуть документ с тремя частями для каждого матча ('splowon')
- .splitbefore ('' ') - раздел фразу перед каждым сопоставлением
- .splitafter ('') - раздел фразу после каждого сопоставления сегмента
- .join () - объедините любые соседние условия в каждом матче
- .joinif (левый матч, правый матч) - объедините любые соседние условия в заданных условиях
- .lookup ([]) - быстро
- .AutoFill () - Создайте предположения о типах в документе
Ярлык
- .tag ('') - дайте всем терминам данную тег
- .tagsafe ('') - Примените тег только к терминам, если он согласуется с текущими тегами
- .untag ('') - удалить этот термин из данных терминов
- .canbe ('') - вернуть только термины, которые могут быть этим тегом
Случай
- .tolowerCase () - Поверните каждую букву каждого термина в нижнюю CSE
- .touppercase () - Поверните каждую букву каждого термина в верхний чехол
- .totitlecase () - Верхняя часть первой буквы каждого термина
- .tocamelcase () - Удалите пробел и заголовок каждый термин
Пробел
- .pre ('') - добавьте эту пунктуацию или пробел перед каждым матчем
- .post ('') - добавьте эту пунктуацию или пробел после каждого матча
- .trim () - Удалите начало и окончание пробела
- .hyphenate () - Подключите слова с дефисом и удалите пробелы
- .dehyphenate () - удалить дефисы между словами и установить пробелы
- .toquotations () - Добавить кавычки вокруг этих матчей
- .toparentheses () - добавьте кронштейны вокруг этих матчей
Петли
- .map (fn) - запустите каждую фразу через функцию и создайте новый документ
- .foreach (fn) - запустите функцию на каждой фразе, как отдельный документ
- .filter (fn) - вернуть только те фразы, которые возвращают истинные
- .find (fn) - вернуть документ только с первой фразой, которая соответствует
- . SOME (FN) - вернуть true или false, если есть одна подходящая фраза
- .random (fn) - образец подмножества результатов
Вставлять
- .Replace (Match, замените) - Поиск и замените совпадение с новым контентом
- .replacewith (заменить) - заменить новый текст
- .Remove () - полностью удалить эти термины из документа
- .insertbefore (str) - добавьте эти новые термины в переднюю часть каждого матча (Prevend)
- .insertafter (str) - добавьте эти новые термины в конце каждого матча (добавление)
- .concat () - Добавьте эти новые вещи к концу
- .swap (fromlemma, tolemma) - умная замена слов корня, используя правильное сопряжение
Преобразование
- .sort ('method') - переоценить порядок матчей (на месте)
- .Reverse () - обратить вспять порядок совпадений, но не слова
- .normalize ({}) - очистить текст различными способами
- .unique () - Удалите любые дубликаты совпадений
Либеральный
(Эти методы находятся на основном объекте nlp )
nlp.tokenize (str) -
nlp.lazy (str, match) - сканировать текст с минимальным анализом
nlp.plugin ({}) - смешивайте компромисс -плугин
nlp.parsematch (str) - предварительно переносит любые операторы матчей в JSON
nlp.world () - захватить или изменить внутреннюю библиотеку
nlp.model () - захватить все текущие лингвистические данные
nlp.methods () - захватить или изменить внутренние методы
nlp.hooks () - см., какие методы вычисления работают автоматически
nlp.verbose (mode) - Войдите наше принятие решений для отладки
nlp.version - текущая версия библиотеки Semver
nlp.addwords (obj, isfrozen?) - добавьте новые слова в лексику
nlp.addtags (obj) - добавить новые теги в теги
nlp.typeahead (arr) - Добавьте слова в словарь автоматического заполнения
nlp.buildtrie (arr) - Составьте список слов в форму быстрого поиска
NLP.Buildnet (ARR) - Составьте список совпадений в форму быстрого соответствия
компромисс/два:
Сокращения
- .contractions () - такие вещи, как «не было»
- .contractions (). Expand () - такие вещи, как «не было»
- .contract () - такие вещи, как «не было»
компромисс/три:
Существительные
- .nouns () - вернуть любые последующие термины, помеченные как существительное
- .nouns (). json () - перегруженный вывод с существительными метаданными
- .nouns (). Parse () - Get Tokenized Sun -Phrase
- .nouns (). isplural () - Возврат только существительные множественное число
- .nouns (). assingular () - вернуть только единственные существительные
- .nouns (). Toplural () -
'football captain' → 'football captains' -
'turnovers' → 'turnover' (). - .nouns (). Adjectives () - Получите любые прилагательные, описывающие это существительное
Глаголы
- .verbs () - вернуть любые последующие термины, помеченные как глагол
- .verbs (). json () - перегруженный вывод с метаданными глагола
- .verbs (). Parse () - Get Tokenized глагол -фраза
- .verbs (). subjects () - что делает глагол
- .verbs (). Adverbs () - вернуть наречия, описывающие этот глагол.
- .verbs (). assingular () - вернуть сингулярные глаголы, такие как «Прогулки с Спенсером»
- .verbs (). isplural () - возвращайте множественные глаголы, такие как «мы ходим»
- .verbs (). Isimperative () - только глаголы инструкции, такие как «Ешьте!»
- .verbs (). topasttense () -
'will go' → 'went' - .verbs (). topresenttense () -
'walked' → 'walks' - .verbs (). tofutureTense () -
'walked' → 'will walk' - .verbs (). toinfinitive () -
'walks' → 'walk' - .verbs (). Togerund () -
'walks' → 'walking' - .verbs (). TopastParticiple () -
'drive' → 'had driven' - .verbs (). Concugate () - вернуть все спряжения этих глаголов
- .verbs (). isnegative () - вернуть глаголы с «не», «никогда» или «нет»
- .verbs (). ispositive () - только глаголы без «не», «никогда» или «нет»
- .verbs (). Tonegative () -
'went' → 'did not go' - .verbs (). topositift () -
"didn't study" → 'studied'
Числа
- .numbers () - Возьмите все написанные и числовые значения
- .numbers (). Parse () - Get Tokeniced Number Phrase
- .numbers (). get () - Получите простой номер JavaScript
- .numbers (). json () - перегруженный вывод с номером метаданных
- .numbers (). Tonumber () - преобразовать «пять» в
5 - .numbers (). Tolocalestring () - добавить запятые или более приятные форматирование для чисел
- .numbers (). Totext () - конвертировать '5' в
five - .numbers (). Toordinal () - преобразовать «пять» в
fifth или 5th - .numbers (). Tocardinal () - преобразовать «пятое» в
five или 5 - .numbers (). isordinal () - вернуть только порядковые числа
- .numbers (). Iscardinal () - вернуть только кардинальные числа
- .numbers (). Isequal (n) - Возвратные числа с этим значением
- .numbers (). Больше (мин) - возвратные числа больше n
- .numbers (). меньше (максимум) - возвращаемые числа меньше n
- .numbers (). Между (мин, максимум) - возвратные числа между минем и макс.
- .numbers (). Isunit (UNIT) - возвращайте только числа в данном блоке, например, «KM»
- .numbers (). set (n) - установить номер в n
- .numbers (). добавить (n) - увеличить число на n
- .numbers (). Вычтите (n) - уменьшить число на n
- .numbers (). Increment () - увеличение числа на 1
- .numbers (). Decrement () - уменьшение числа на 1
- .money () - такие вещи, как
'$2.50'- .money (). get () - Получите проанализированную сумму (ы) денег
- .money (). json () - валюта + информация о номере
- .money (). валюта () - какая валюта в день
- .fractions () - как '2/3rds' или «один из пяти»
- .fractions (). parse () - Get Tokenized Fraction
- .fractions (). get () - простой числитель, данные знаменателя
- .fractions (). json () - метод JSON, перегруженный данными фракций
- .fractions (). todecimal () - '2/3' -> '0,66'
- .fractions (). normalize () - 'Четыре из 10' -> '4/10'
- .fractions (). Totext () - '4/10' -> 'Четыре десятых' '
- .Fractions (). ToperCentage () - '4/10' -> '40%'
- .percentages () - как '2,5%'
- .percentage (). get () - вернуть процентное число / 100
- .percentages (). json () - JSON перегружен процентной информацией
- .percentage (). TOFRACTION () - '80%' ->' 8/10 '
Предложения
- .sentences () - вернуть класс предложения с помощью дополнительных методов
- .sentences (). json () - перегруженный вывод с метаданными предложениями
- .sentences (). topasttense () -
he walks -> he walked - .sentences (). Topresenttense () -
he walked -> he walks - .sentences (). TofutureTense ()
he walks -> he will walk - .sentences (). toinfinitive () -форма корня глагола ->
he walk he walks - .sentences (). Tonegative () - -
he walks -> he didn't walk - .sentences (). isquestion () - Вопросы вернуть с помощью
? - .sentences (). isexclamation () - возврат предложения с
! - .sentences (). Isstatement () - Возврат предложения без
? или !
Прилагательные
- .Djectives () - такие вещи, как
'quick'- .Djectives (). json () - Получите прилагательные метаданные
- .Djectives (). Concugate () - Возврат все перегибы этих прилагательных
- .adjectives (). Adverbs () - Получить наречия, описывающие это прилагательное
- .adjectives (). toComparative () - 'Quick' -> 'Quicker'
- .adjectives (). tosuperlative () - 'Quick' -> 'Quick'
- .adjectives (). Toadverb () - 'Quick' -> 'быстро'
- .adjectives (). tonoun () - 'Quick' -> 'Quickensy'
Выбор разного
- .clauses () -разделение предложений на многократные фразы
- .chunks () -Разделительные предложения существительные фразы и глагольные фразы
- .hyphenated () - все термины, связанные с дефисом или
'wash-out' - .phonenumbers () - такие вещи, как
'(939) 555-0113' - .hashtags () - такие вещи, как
'#nlp' - .emails () - такие вещи, как
'[email protected]' - .emoticons () - такие вещи, как
:) - .emojis () - вещи вроде
? - .atmentions () - такие вещи, как
'@nlp_compromise' - .URLS () - такие вещи, как
'compromise.cool' - .pronouns () - такие вещи, как
'he' - .conjunctions () - такие вещи, как
'but' - .prepositions () - такие вещи, как
'of' - .AbBreviations () - такие вещи, как
'Mrs.' - .people () - имена, как «Джон Ф. Кеннеди»
- .people (). json () - Получите метаданные имени человека
- .people (). parse () - Получите имени человека
- .places () - как «Париж, Франция»
- .organizations () - как 'Google, Inc'
- .topics () -
people() + places() + organizations() - .adverbs () - такие вещи, как
'quickly'- .adverbs (). json () - Получить наречие метаданные
- .acronyms () - такие вещи, как
'FBI'- .Acronyms ().
- .Acronyms (). AddPeriods () - Добавить периоды в аббревиатуры
- .parentheses () - вернуть что -нибудь внутри (скобки)
- .parentheses (). Strip () - Удалите кронштейны
- .possessives () - такие вещи, как
"Spencer's"- .possessives (). Strip () - "Спенсер" -> "Спенсер"
- .quotations () - вернуть любые термины внутри парных кавычек
- .quotations (). Strip () - Удалите кавычки
- .slashes () - вернуть любые термины, сгруппированные по ударам
- .slashes (). Split () - превратить «любовь/ненависть» в «Любовь ненависти»
.продлевать():
Эта библиотека поставляется с внимательной, здравом смысле базовой линии для английской грамматики.
Вы свободны изменить или уложить отходы на любые настройки - что является забавной частью на самом деле.
Самое простое - просто предложить теги для любых данных:
let myWords = {
kermit : 'FirstName' ,
fozzie : 'FirstName' ,
}
let doc = nlp ( muppetText , myWords ) или внесите более тяжелые изменения с компромиссным плугином.
import nlp from 'compromise'
nlp . extend ( {
// add new tags
tags : {
Character : {
isA : 'Person' ,
notA : 'Adjective' ,
} ,
} ,
// add or change words in the lexicon
words : {
kermit : 'Character' ,
gonzo : 'Character' ,
} ,
// change inflections
irregulars : {
get : {
pastTense : 'gotten' ,
gerund : 'gettin' ,
} ,
} ,
// add new methods to compromise
api : View => {
View . prototype . kermitVoice = function ( ) {
this . sentences ( ) . prepend ( 'well,' )
this . match ( 'i [(am|was)]' ) . prepend ( 'um,' )
return this
}
} ,
} ) .plugin () документы
Документы:
Нежное введение:
- #1) Вход → Вывод
- #2) Сопоставление и преобразование
- #3) Сделать чат-бот
Документация:
| Концепции | API | Плагины |
|---|
| Точность | Аксессов | Прилагательные |
| Кэширование | Конструктор-методы | Даты |
| Случай | Сокращения | Экспорт |
| FileSize | Вставлять | Хэш |
| Внутренние | Json | HTML |
| Оправдание | Персонаж смещения | Ключ |
| Лексикон | Петли | Ngrams |
| Матч-синтаксис | Соответствовать | Числа |
| Производительность | Существительные | Абзацы |
| Плагины | Выход | Сканирование |
| Проекты | Выборы | Предложения |
| Теггер | Сортировка | Слоги |
| Теги | Расколоть | Произносить |
| Токенизация | Текст | Строгий |
| Названный | Утилит | Пенн-Тэгс |
| Пробел | Глаголы | Тип |
| Мировые данные | Нормализация | Мести |
| Нечеткое сопоставление | Машинопись | Мутация |
| Корневые формы | | |
Разговоры:
- Язык как интерфейс - Спенсер Келли
- Кодирование чат ботов - от Кахви Тенг
- На набор и данных - Спенсер Келли
Статьи:
- Геокодирование социальных разговоров с NLP и JavaScript - Microsoft
- Рецепт микросервиса - от Eventn
- Приключенческая игра наказание с компромиссом
- Создание текстовых игр - Мэтт Элэнд
- Веселье с JavaScript в Бигкери - Фелипе Хоффа
- Обработка естественного языка ... в браузере? - Чарльз Ландау
Некоторые забавные заявки:
- Автоматизированный тест Bechdel - Guardian
- Структура генерации рассказов - от Хосе Прокки
- Блог Tumbler списков - списки, подобные лошадям, - Майкл Паулюконис
- Редактирование видео от транскрипции - по новой теории
- Проверка фактов по расширению браузера - Александр Кидд
- Siri Shortcut - Майкл Бернс
- Amazon Skill - Tajddin Maghni
- Слушание Slack -Bot - Кевина Су [см. Подробнее]
Сравнения
- Компромисс и СПАЦИЯ
- Компромисс и NLTK
Плагины:
Это некоторые полезные расширения:
Даты
npm install compromise-dates
- .dates () - Найдите даты, такие как
June 8th или 03/03/18- .dates (). get () - простой начал/конец json результат
- .dates (). json () - перегруженный вывод с метаданными даты
- .dates (). Format ('') - преобразовать даты в конкретные форматы
- .dates (). Toshortform () - преобразовать «среду» в «Ср» и т. Д.
- .dates (). Tolongform () - преобразовать «февраль» в «февраль» и т. Д.
- .durations () -
2 weeks или 5mins- .durations (). get () - вернуть простой json для продолжительности
- .durations (). json () - перегруженный вывод с метаданными продолжительностью
- .times () -
4:30pm или half past five- .times (). get () - вернуть простой json для времени
- .times (). json () - перегруженный вывод со временем метаданные
Статистика
npm install compromise-stats
.tfidf ({}) - ранжировать слова по частоте и уникальности
.ngrams ({}) -Перечислите все повторяющиеся суб-фразы, по сведению слов
.unigrams () - n -граммы с одним словом
.bigrams () - n -граммы с двумя словами
.trigrams () - n -граммы с тремя словами
.startgrams () - n -граммы, включая первый термин фразы
.endgrams () - n -граммы, включая последний термин фразы
. EdgeGrams () - N -граммы, включая первый или последний термин фразы
Речь
npm install compromise-syllables
- .syllables () - разделить каждый термин на его типичное произношение
- .soundslike () - произведет предполагаемое произношение
Википедия
npm install compromise-wikipedia
- .wikipedia () - сжатое примирение статьи
Машинопись
Мы привержены поддержке TypeScript/DENO, как в Main, так и в официальных плугинах:
import nlp from 'compromise'
import stats from 'compromise-stats'
const nlpEx = nlp . extend ( stats )
nlpEx ( 'This is type safe!' ) . ngrams ( { min : 1 } ) TypeScript Docs
Ограничения:
Slash-Support: В настоящее время мы разделимся как разные слова, как мы делаем для дефисов. Так что подобные вещи не работают: nlp('the koala eats/shoots/leaves').has('koala leaves') //false
Взаимодействие: по умолчанию предложения являются абстракцией верхнего уровня. Взаимодействие, или совпадения с несколькими предложениями не поддерживаются без плагина: nlp("that's it. Back to Winnipeg!").has('it back')//false
Синтаксис вложенного матча: опасность красоты корпуса заключается в том, что вы можете повторять бесконечно. Наш синтаксис матча намного слабее. Подобные вещи не являются (пока) возможны: doc.match('(modern (major|minor))? general') Сложные совпадения должны быть достигнуты с помощью последовательных операторов .match () .
Подбор зависимости: правильное преобразование предложений требует понимания синтаксического дерева предложения, чего мы в настоящее время не делаем. Мы должны! Помогите с этим.
Часто задаваемые вопросы
☂ тоже не JavaScript ...
Да, это так!
Он не был создан, чтобы конкурировать с NLTK, и может не соответствовать каждому проекту.
Обработка строки тоже синхронна, а параллелизирующие процессы узлов странные.
Смотрите здесь для получения информации о скорости и производительности, и здесь для мотивации проекта
? Может ли он работать на моем Arduino Pwatch?
Только если это водонепроницаемое!
Читайте быстрый старт для работы с компромиссом в работниках, мобильных приложениях и всевозможных забавных условиях.
? Компромисс на других языках?
У нас есть неверные вилки для немецкого, французского, испанского и итальянского в той же философии.
и нужна помощь.
Частичные сборки?
Мы предлагаем только токеновую сборку, которая вытащила POS-Tagger.
Но в противном случае компромисс нелегко разбить дерево.
Методы мечения конкурентоспособны и жадны, поэтому не рекомендуется вытаскивать вещи.
Обратите внимание, что без полного посадного завода, сжатие-партия не будет работать идеально. ( (прохладный Спенсер) против (дом Спенсера) )
Рекомендуется полностью запустить библиотеку.

Смотрите также:
en-pos -очень умный javaScript pos-tagger от Alex Corvi
NaturalNode - более причудливый статистический NLP в JavaScript
winkjs -pos-tagger, токенизатор, машинное обучение в JavaScript
Дариук/POS -JS - Fasttag Fork в JavaScript
Компендиум -JS - POS и анализ настроений в JavaScript
Лингвистика узлов - конъюгация, перегиб в JavaScript
retext - очень впечатляющие текстовые утилиты в JavaScript
SuperScript - Двигатель разговора в JS
JSPOS -JavaScript
Spacy - Speedy, многоязычный Tagger в C/Python
Проза - Quick Tagger в Go By Joseph Kato
TextBlob - Python Tagger
Грань