ml workspace
0.13.2

สภาพแวดล้อมการพัฒนาบนเว็บทั้งหมดสำหรับการเรียนรู้ของเครื่องจักร
การเริ่มต้นใช้งาน•คุณสมบัติและภาพหน้าจอ•การสนับสนุน•รายงานข้อผิดพลาด•คำถามที่พบบ่อย•ปัญหาที่รู้จัก•การบริจาค
ML Workspace เป็น IDE บนเว็บแบบครบวงจรสำหรับการเรียนรู้ของเครื่องและวิทยาศาสตร์ข้อมูล มันง่ายที่จะปรับใช้และทำให้คุณเริ่มต้นภายในไม่กี่นาทีเพื่อสร้างโซลูชั่น ML ที่สร้างขึ้นอย่างมีประสิทธิภาพบนเครื่องจักรของคุณเอง พื้นที่ทำงานนี้เป็นเครื่องมือที่ดีที่สุดสำหรับนักพัฒนาที่โหลดไว้ล่วงหน้าด้วยห้องสมุดวิทยาศาสตร์ข้อมูลยอดนิยมที่หลากหลาย (เช่น TensorFlow, Pytorch, Keras, Sklearn) และเครื่องมือ Dev (เช่น Jupyter, VS Code, Tensorboard) กำหนดค่าอย่างสมบูรณ์แบบ
เวิร์กสเปซต้องการให้ติดตั้ง Docker บนเครื่องของคุณ (คู่มือการติดตั้ง)
การปรับใช้อินสแตนซ์เวิร์กสเปซเดียวนั้นง่ายเหมือน:
docker run -p 8080:8080 mltooling/ml-workspace:0.13.2Voilàนั้นง่ายมาก! ตอนนี้ Docker จะดึงภาพพื้นที่ทำงานล่าสุดไปยังเครื่องของคุณ อาจใช้เวลาไม่กี่นาทีขึ้นอยู่กับความเร็วอินเทอร์เน็ตของคุณ เมื่อพื้นที่ทำงานเริ่มต้นขึ้นคุณสามารถเข้าถึงได้ผ่าน http: // localhost: 8080
หากเริ่มต้นในเครื่องอื่นหรือด้วยพอร์ตที่แตกต่างกันตรวจสอบให้แน่ใจว่าใช้ IP/DNS ของเครื่องและ/หรือพอร์ตที่เปิดเผย
ในการปรับใช้อินสแตนซ์เดียวสำหรับการใช้งานที่มีประสิทธิผลเราขอแนะนำให้สมัครอย่างน้อยตัวเลือกต่อไปนี้:
docker run -d
-p 8080:8080
--name " ml-workspace "
-v " ${PWD} :/workspace "
--env AUTHENTICATE_VIA_JUPYTER= " mytoken "
--shm-size 512m
--restart always
mltooling/ml-workspace:0.13.2 คำสั่งนี้เรียกใช้คอนเทนเนอร์ในพื้นหลัง ( -d ), ติดตั้งไดเรกทอรีการทำงานปัจจุบันของคุณลงในโฟลเดอร์ /workspace --shm-size -v ) ยึดพื้นที่ทำงานผ่านโทเค็นที่ให้ไว้ ( --env AUTHENTICATE_VIA_JUPYTER --restart always ให้บริการหน่วยความจำที่ใช้ร่วมกัน 512MB คุณสามารถค้นหาตัวเลือกเพิ่มเติมสำหรับ Docker Run ที่นี่และตัวเลือกการกำหนดค่าพื้นที่ทำงานในส่วนด้านล่าง
พื้นที่ทำงานมีตัวเลือกการกำหนดค่าที่หลากหลายซึ่งสามารถใช้งานได้โดยการตั้งค่าตัวแปรสภาพแวดล้อม (ผ่านตัวเลือก Docker Run: --env )
| ตัวแปร | คำอธิบาย | ค่าเริ่มต้น |
|---|---|---|
| workspace_base_url | URL พื้นฐานที่ Jupyter และเครื่องมืออื่น ๆ ทั้งหมดจะสามารถเข้าถึงได้ | - |
| workspace_ssl_enabled | เปิดใช้งานหรือปิดการใช้งาน SSL เมื่อตั้งค่าเป็น TRUE ทั้งใบรับรอง (CERT.CRT) จะต้องติดตั้งกับ /resources/ssl หรือหากไม่ได้สร้างใบรับรองที่ลงนามด้วยตนเอง | เท็จ |
| workspace_auth_user | ชื่อผู้ใช้ Auth Auth พื้นฐาน ในการเปิดใช้งานการรับรองความถูกต้องพื้นฐานทั้งผู้ใช้และรหัสผ่านจะต้องตั้งค่า เราขอแนะนำให้ใช้ AUTHENTICATE_VIA_JUPYTER เพื่อรักษาความปลอดภัยพื้นที่ทำงาน | |
| workspace_auth_password | รหัสผ่านผู้ใช้ Auth Auth ขั้นพื้นฐาน ในการเปิดใช้งานการรับรองความถูกต้องพื้นฐานทั้งผู้ใช้และรหัสผ่านจะต้องตั้งค่า เราขอแนะนำให้ใช้ AUTHENTICATE_VIA_JUPYTER เพื่อรักษาความปลอดภัยพื้นที่ทำงาน | |
| workspace_port | กำหนดค่าพอร์ตคอนเทนเนอร์ภายในของพอร์ตเวิร์กสเปซ สำหรับสถานการณ์ส่วนใหญ่การกำหนดค่านี้ไม่ควรเปลี่ยนแปลงและการกำหนดค่าพอร์ตผ่าน Docker ควรใช้แทนพื้นที่ทำงานควรเข้าถึงได้จากพอร์ตอื่น | 8080 |
| config_backup_enabled | การสำรองข้อมูลและกู้คืนการกำหนดค่าผู้ใช้โดยอัตโนมัติไปยังโฟลเดอร์คงที่ /workspace เช่น. ssh, .jupyter หรือ. gitConfig จากผู้ใช้โฮมไดเรกทอรี | จริง |
| shared_links_enabled | เปิดหรือปิดใช้งานความสามารถในการแบ่งปันทรัพยากรผ่านลิงก์ภายนอก สิ่งนี้ใช้เพื่อเปิดใช้งานการแชร์ไฟล์การเข้าถึงพอร์ตเวิร์กสเปซภายในและการตั้งค่า SSH ตามคำสั่งง่ายๆ ลิงก์ที่ใช้ร่วมกันทั้งหมดได้รับการปกป้องผ่านโทเค็น อย่างไรก็ตามมีความเสี่ยงบางอย่างเนื่องจากโทเค็นไม่สามารถเป็นโมฆะได้อย่างง่ายดายหลังจากการแบ่งปันและไม่หมดอายุ | จริง |
| รวม _Tutorials | หาก true การเลือกโน้ตบุ๊กและบทนำจะถูกเพิ่มลงในโฟลเดอร์ /workspace ซที่การเริ่มต้นคอนเทนเนอร์ แต่เฉพาะในกรณีที่โฟลเดอร์ว่างเปล่า | จริง |
| max_num_threads | จำนวนเธรดที่ใช้สำหรับการคำนวณเมื่อใช้ไลบรารีทั่วไปต่างๆ (MKL, OpenBlas, OMP, NUMBA, ... ) นอกจากนี้คุณยังสามารถใช้ auto เพื่อให้พื้นที่ทำงานกำหนดจำนวนเธรดที่ใช้ทรัพยากร CPU ที่มีอยู่แบบไดนามิก การกำหนดค่านี้สามารถเขียนทับโดยผู้ใช้จากภายในพื้นที่ทำงาน โดยทั่วไปจะเป็นการดีที่จะตั้งค่าที่หรือต่ำกว่าจำนวนซีพียูที่มีอยู่ในพื้นที่ทำงาน | รถยนต์ |
| การกำหนดค่า Jupyter: | ||
| shutdown_inactive_kernels | ปิดเมล็ดที่ไม่ได้ใช้งานโดยอัตโนมัติหลังจากหมดเวลาที่กำหนด (เพื่อทำความสะอาดหน่วยความจำหรือทรัพยากร GPU) ค่าสามารถเป็นทั้งการหมดเวลาในวินาทีหรือตั้งค่าเป็น true ด้วยค่าเริ่มต้นที่ 48H | เท็จ |
| Authenticate_via_jupyter | หาก true คำขอ HTTP ทั้งหมดจะได้รับการรับรองความถูกต้องกับเซิร์ฟเวอร์ Jupyter ซึ่งหมายความว่าวิธีการตรวจสอบความถูกต้องที่กำหนดค่าด้วย Jupyter จะถูกใช้สำหรับเครื่องมืออื่น ๆ ทั้งหมดเช่นกัน สิ่งนี้สามารถปิดการใช้งานด้วย false ค่าอื่นใดจะเปิดใช้งานการรับรองความถูกต้องนี้และใช้เป็นโทเค็นผ่าน NotebookApp.token การกำหนดค่าของ Jupyter | เท็จ |
| notebook_args | เพิ่มและเขียนทับตัวเลือกการกำหนดค่า Jupyter ผ่านบรรทัดคำสั่ง args อ้างถึงภาพรวมนี้สำหรับตัวเลือกทั้งหมด | |
ในการคงข้อมูลไว้คุณจะต้องติดตั้งระดับเสียงเข้าสู่ /workspace (ผ่านตัวเลือก Docker Run: -v )
ไดเรกทอรีงานเริ่มต้นภายในคอนเทนเนอร์คือ /workspace ซึ่งเป็นไดเรกทอรีรากของอินสแตนซ์ Jupyter ไดเรกทอรี /workspace มีจุดประสงค์เพื่อใช้สำหรับสิ่งประดิษฐ์งานที่สำคัญทั้งหมด ข้อมูลภายในไดเรกทอรีอื่น ๆ ของเซิร์ฟเวอร์ (เช่น /root ) อาจหายไปที่คอนเทนเนอร์รีสตาร์ท
เราขอแนะนำให้เปิดใช้งานการรับรองความถูกต้องผ่านหนึ่งในสองตัวเลือกต่อไปนี้ สำหรับตัวเลือกทั้งสองผู้ใช้จะต้องตรวจสอบสิทธิ์สำหรับการเข้าถึงเครื่องมือที่ติดตั้งไว้ล่วงหน้า
การรับรองความถูกต้องใช้งานได้สำหรับเครื่องมือทั้งหมดที่เข้าถึงได้ผ่านพอร์ตพื้นที่ทำงานหลัก (ค่าเริ่มต้น:
8080) สิ่งนี้ใช้ได้กับเครื่องมือที่ติดตั้งไว้ล่วงหน้าทั้งหมดและคุณสมบัติการเข้าถึงพอร์ต หากคุณเปิดเผยพอร์ตอื่นของคอนเทนเนอร์โปรดตรวจสอบให้แน่ใจว่าได้รับการรับรองความถูกต้องด้วย!
เปิดใช้งานการรับรองความถูกต้องตามโทเค็นตามการใช้งานการตรวจสอบความถูกต้องของ Jupyter ผ่านตัวแปร AUTHENTICATE_VIA_JUPYTER :
docker run -p 8080:8080 --env AUTHENTICATE_VIA_JUPYTER= " mytoken " mltooling/ml-workspace:0.13.2 นอกจากนี้คุณยังสามารถใช้ <generated> เพื่อให้ Jupyter สร้างโทเค็นแบบสุ่มที่พิมพ์ออกมาบนบันทึกคอนเทนเนอร์ ค่าของ true จะไม่ตั้งค่าโทเค็นใด ๆ แต่เปิดใช้งานว่าทุกคำขอไปยังเครื่องมือใด ๆ ในพื้นที่ทำงานจะถูกตรวจสอบด้วยอินสแตนซ์ Jupyter หากผู้ใช้ได้รับการรับรองความถูกต้อง สิ่งนี้ใช้สำหรับเครื่องมือเช่น JupyterHub ซึ่งกำหนดค่าวิธีการตรวจสอบความถูกต้องของตัวเอง
เปิดใช้งานการรับรองความถูกต้องพื้นฐานผ่านตัวแปร WORKSPACE_AUTH_USER และ WORKSPACE_AUTH_PASSWORD : ตัวแปร:
docker run -p 8080:8080 --env WORKSPACE_AUTH_USER= " user " --env WORKSPACE_AUTH_PASSWORD= " pwd " mltooling/ml-workspace:0.13.2 การรับรองความถูกต้องขั้นพื้นฐานได้รับการกำหนดค่าผ่าน Nginx Proxy และอาจมีประสิทธิภาพมากกว่าเมื่อเทียบกับตัวเลือกอื่น ๆ เนื่องจากมี AUTHENTICATE_VIA_JUPYTER ทุกคำขอไปยังเครื่องมือใด ๆ ในเวิร์กสเปซจะตรวจสอบผ่านอินสแตนซ์ Jupyter หากผู้ใช้ (ตามคุกกี้คำขอ) ได้รับการรับรองความถูกต้อง
เราขอแนะนำให้เปิดใช้งาน SSL เพื่อให้สามารถเข้าถึงพื้นที่ทำงานผ่าน HTTPS (การสื่อสารที่เข้ารหัส) การเข้ารหัส SSL สามารถเปิดใช้งานได้ผ่านตัวแปร WORKSPACE_SSL_ENABLED
เมื่อตั้งค่าเป็น true ไฟล์ cert.crt และ cert.key จะต้องติดตั้งกับ /resources/ssl หรือหากไม่มีไฟล์ใบรับรองคอนเทนเนอร์จะสร้างใบรับรองที่ลงนามด้วยตนเอง ตัวอย่างเช่นหาก /path/with/certificate/files ในระบบท้องถิ่นมีใบรับรองที่ถูกต้องสำหรับโดเมนโฮสต์ ( cert.crt และ cert.key ไฟล์) สามารถใช้งานได้จากพื้นที่ทำงานดังแสดงด้านล่าง:
docker run
-p 8080:8080
--env WORKSPACE_SSL_ENABLED= " true "
-v /path/with/certificate/files:/resources/ssl:ro
mltooling/ml-workspace:0.13.2 หากคุณต้องการโฮสต์พื้นที่ทำงานในโดเมนสาธารณะเราขอแนะนำให้ใช้ Let's encrypt เพื่อรับใบรับรองที่เชื่อถือได้สำหรับโดเมนของคุณ หากต้องการใช้ใบรับรองที่สร้างขึ้น (เช่นผ่านเครื่องมือ CertBot) สำหรับ Workspace, privkey.pem สอดคล้องกับไฟล์ cert.key และ fullchain.pem ไปยังไฟล์ cert.crt
เมื่อคุณเปิดใช้งานการสนับสนุน SSL คุณต้องเข้าถึงพื้นที่ทำงานผ่าน
https://ไม่เกินhttp://
โดยค่าเริ่มต้นคอนเทนเนอร์เวิร์กสเปซไม่มีข้อ จำกัด ด้านทรัพยากรและสามารถใช้ทรัพยากรที่กำหนดได้มากเท่าที่กำหนดการเคอร์เนลของโฮสต์อนุญาต Docker ให้วิธีการควบคุมจำนวนหน่วยความจำหรือ CPU ที่คอนเทนเนอร์สามารถใช้งานได้โดยการตั้งค่าการกำหนดค่าการกำหนดค่ารันไทม์ของคำสั่ง Docker Run
พื้นที่ทำงานต้องการ CPU อย่างน้อย 2 CPU และ 500MB เพื่อให้ทำงานเสถียรและสามารถใช้งานได้
ตัวอย่างเช่นคำสั่งต่อไปนี้ จำกัด พื้นที่ทำงานให้ใช้เฉพาะ 8 ซีพียู, หน่วยความจำ 16 GB และหน่วยความจำที่ใช้ร่วมกัน 1 GB (ดูปัญหาที่รู้จัก):
docker run -p 8080:8080 --cpus=8 --memory=16g --shm-size=1G mltooling/ml-workspace:0.13.2สำหรับตัวเลือกและเอกสารเพิ่มเติมเกี่ยวกับข้อ จำกัด ด้านทรัพยากรโปรดดูคู่มือ Docker อย่างเป็นทางการ
หากจำเป็นต้องมีพร็อกซีคุณสามารถผ่านการกำหนดค่าพร็อกซีผ่าน HTTP_PROXY , HTTPS_PROXY และตัวแปรสภาพแวดล้อม NO_PROXY
นอกเหนือจากอิมเมจพื้นที่ทำงานหลัก ( mltooling/ml-workspace ) เรายังมีรสชาติของภาพอื่น ๆ ที่ขยายคุณสมบัติหรือลดขนาดภาพให้น้อยที่สุดเพื่อรองรับกรณีการใช้งานที่หลากหลาย
รสชาติน้อยที่สุด ( mltooling/ml-workspace-minimal ) เป็นภาพที่เล็กที่สุดของเราที่มีเครื่องมือและคุณสมบัติส่วนใหญ่ที่อธิบายไว้ในส่วนคุณสมบัติโดยไม่มีไลบรารี Python ส่วนใหญ่ที่ติดตั้งไว้ล่วงหน้าในภาพหลักของเรา สามารถติดตั้งไลบรารี Python หรือเครื่องมือที่ยกเว้นได้ด้วยตนเองในระหว่างการรันไทม์โดยผู้ใช้
docker run -p 8080:8080 mltooling/ml-workspace-minimal:0.13.2 รสชาติ R ( mltooling/ml-workspace-r ) ขึ้นอยู่กับอิมเมจพื้นที่ทำงานเริ่มต้นของเราและขยายด้วย R-Interpreter, เคอร์เนล R-Jupyter, เซิร์ฟเวอร์ RSTUDIO (เข้าถึงผ่าน Open Tool -> RStudio ) และแพ็คเกจยอดนิยมที่หลากหลาย
docker run -p 8080:8080 mltooling/ml-workspace-r:0.12.1 รสชาติของ Spark ( mltooling/ml-workspace-spark ) ขึ้นอยู่กับภาพพื้นที่ทำงาน R-Flavor ของเราและขยายออกไปด้วยรันไทม์ Spark, Kernel Spark-Jupyter, Notebook Zeppelin (เข้าถึงผ่าน Open Tool -> Zeppelin ), Pyspark, Hadoop, Java Kernel
docker run -p 8080:8080 mltooling/ml-workspace-spark:0.12.1ปัจจุบันรสชาติของ GPU รองรับ CUDA 11.2 เท่านั้น การสนับสนุนสำหรับรุ่น CUDA อื่น ๆ อาจถูกเพิ่มเข้ามาในอนาคต
รสชาติของ GPU ( mltooling/ml-workspace-gpu ) ขึ้นอยู่กับภาพพื้นที่ทำงานเริ่มต้นของเราและขยายด้วย CUDA 10.1 และ GPU-ready ของห้องสมุดการเรียนรู้ของเครื่องจักรที่หลากหลาย (เช่น Tensorflow, Pytorch, CNTK, JAX) ภาพ GPU นี้มีข้อกำหนดเพิ่มเติมดังต่อไปนี้สำหรับระบบ:
>=460.32.03 (คำแนะนำ)docker run -p 8080:8080 --gpus all mltooling/ml-workspace-gpu:0.13.2docker run -p 8080:8080 --runtime nvidia --env NVIDIA_VISIBLE_DEVICES= " all " mltooling/ml-workspace-gpu:0.13.2รสชาติของ GPU ยังมาพร้อมกับตัวเลือกการกำหนดค่าเพิ่มเติมสองสามตัวตามที่อธิบายไว้ด้านล่าง:
| ตัวแปร | คำอธิบาย | ค่าเริ่มต้น |
|---|---|---|
| nvidia_visible_devices | ควบคุม GPU ที่จะสามารถเข้าถึงได้ภายในพื้นที่ทำงาน โดยค่าเริ่มต้น GPU ทั้งหมดจากโฮสต์สามารถเข้าถึงได้ภายในพื้นที่ทำงาน คุณสามารถใช้ all none หรือระบุรายการรหัสอุปกรณ์ที่คั่นด้วยเครื่องหมายจุลภาค (เช่น 0,1 ) คุณสามารถค้นหารายการรหัสอุปกรณ์ที่มีอยู่ได้โดยเรียกใช้ nvidia-smi บนเครื่องโฮสต์ | ทั้งหมด |
| cuda_visible_devices | การควบคุมแอปพลิเคชัน GPUS CUDA ที่ทำงานภายในพื้นที่ทำงานจะเห็น โดยค่าเริ่มต้น GPU ทั้งหมดที่เวิร์กสเปซสามารถเข้าถึงได้จะมองเห็นได้ ในการ จำกัด แอปพลิเคชันให้จัดทำรายการรหัสอุปกรณ์ภายในที่คั่นด้วยเครื่องหมายจุลภาค (เช่น 0,2 ) ตามอุปกรณ์ที่มีอยู่ภายในพื้นที่ทำงาน (เรียกใช้ nvidia-smi ) เมื่อเปรียบเทียบกับ NVIDIA_VISIBLE_DEVICES ผู้ใช้พื้นที่ทำงานจะยังคงสามารถเข้าถึง GPU อื่น ๆ โดยการเขียนทับการกำหนดค่านี้จากภายในพื้นที่ทำงาน | |
| tf_force_gpu_allow_growth | โดยค่าเริ่มต้นหน่วยความจำ GPU ส่วนใหญ่จะถูกจัดสรรโดยการดำเนินการครั้งแรกของกราฟ tensorflow ในขณะที่พฤติกรรมนี้สามารถเป็นที่ต้องการสำหรับท่อผลิต แต่ก็เป็นที่ต้องการน้อยกว่าสำหรับการใช้งานแบบโต้ตอบ ใช้ true เพื่อเปิดใช้งานการจัดสรรหน่วยความจำ GPU แบบไดนามิกหรือ false เพื่อสั่งให้ TensorFlow จัดสรรหน่วยความจำทั้งหมดเมื่อดำเนินการ | จริง |
พื้นที่ทำงานได้รับการออกแบบให้เป็นสภาพแวดล้อมการพัฒนาผู้ใช้เดี่ยว สำหรับการตั้งค่าผู้ใช้หลายคนเราขอแนะนำให้ปรับใช้หรือไม่? ML Hub ML Hub ขึ้นอยู่กับ JupyterHub พร้อมกับงานที่จะวางไข่จัดการและพร็อกซีเวิร์กสเปซอินสแตนซ์สำหรับผู้ใช้หลายคน
ML Hub ทำให้ง่ายต่อการตั้งค่าสภาพแวดล้อมผู้ใช้หลายผู้ใช้บนเซิร์ฟเวอร์เดียว (ผ่าน Docker) หรือคลัสเตอร์ (ผ่าน Kubernetes) และรองรับสถานการณ์การใช้งานที่หลากหลายและผู้ให้บริการรับรองความถูกต้อง คุณสามารถลอง ML Hub ผ่าน:
docker run -p 8080:8080 -v /var/run/docker.sock:/var/run/docker.sock mltooling/ml-hub:latestสำหรับข้อมูลเพิ่มเติมและเอกสารเกี่ยวกับ ML Hub โปรดดูที่ไซต์ GitHub
โครงการนี้ได้รับการดูแลโดย Benjamin Räthlein, Lukas Masuch และ Jan Kalkan โปรดเข้าใจว่าเราจะไม่สามารถให้การสนับสนุนรายบุคคลทางอีเมลได้ นอกจากนี้เรายังเชื่อว่าความช่วยเหลือนั้นมีค่ามากขึ้นหากมีการแบ่งปันต่อสาธารณะเพื่อให้ผู้คนจำนวนมากสามารถได้รับประโยชน์จากมัน
| พิมพ์ | ช่อง |
|---|---|
| รายงานข้อผิดพลาด | |
| - คำขอคุณสมบัติ | |
| คำถามการใช้งาน | |
| - การประกาศ | |
| ❓ คำขออื่น ๆ |
JUPYTER • DESKTOP GUI • VS CODE • JUPYTERLAB •การรวม GIT •การแชร์ไฟล์•พอร์ตการเข้าถึง• TENSORBOARD •การขยายความสามารถ•การตรวจสอบฮาร์ดแวร์•การเข้าถึง SSH •การพัฒนาระยะไกล•การดำเนินงานการทำงาน
เวิร์กสเปซมาพร้อมกับเครื่องมือพัฒนาโอเพนซอร์ซที่ดีที่สุดในชั้นเรียนที่ดีที่สุดเพื่อช่วยในการทำงานของเครื่องจักรการเรียนรู้ของเครื่อง เครื่องมือเหล่านี้จำนวนมากสามารถเริ่มต้นได้จากเมนู Open Tool จาก Jupyter (แอปพลิเคชันหลักของพื้นที่ทำงาน):
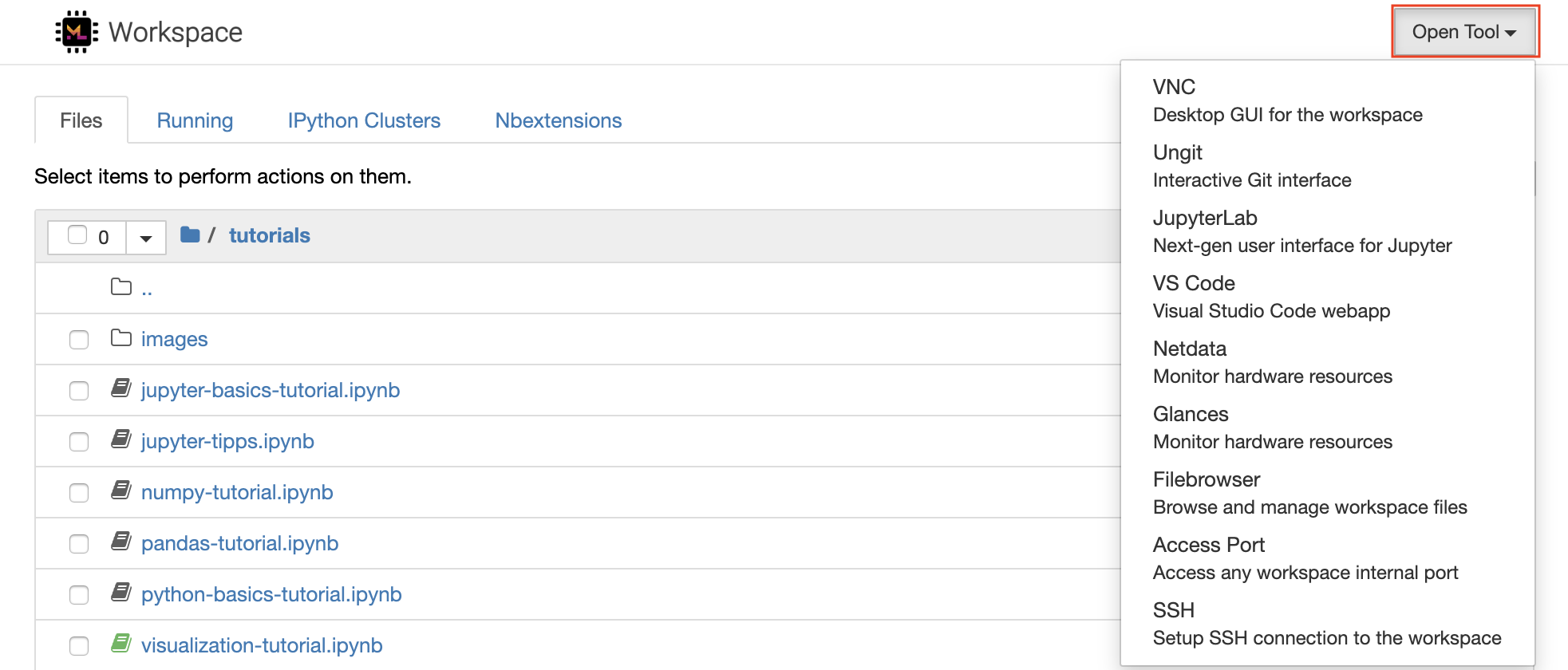
ภายในพื้นที่ทำงานของคุณคุณมี สิทธิ์เต็มรูทและ sudo เพื่อติดตั้งไลบรารีหรือเครื่องมือใด ๆ ที่คุณต้องการผ่านเทอร์มินัล (เช่น
pip,apt-get,condaหรือnpm) คุณสามารถค้นหาวิธีเพิ่มเติมในการขยายพื้นที่ทำงานภายในส่วนการขยาย
Jupyter Notebook เป็นสภาพแวดล้อมแบบโต้ตอบบนเว็บสำหรับการเขียนและเรียกใช้รหัส หน่วยการสร้างหลักของ Jupyter คือ File-Browser, Editor Notebook และ Kernels File-Browser จัดเตรียมตัวจัดการไฟล์แบบโต้ตอบสำหรับโน้ตบุ๊กไฟล์และโฟลเดอร์ทั้งหมดในไดเรกทอรี /workspace
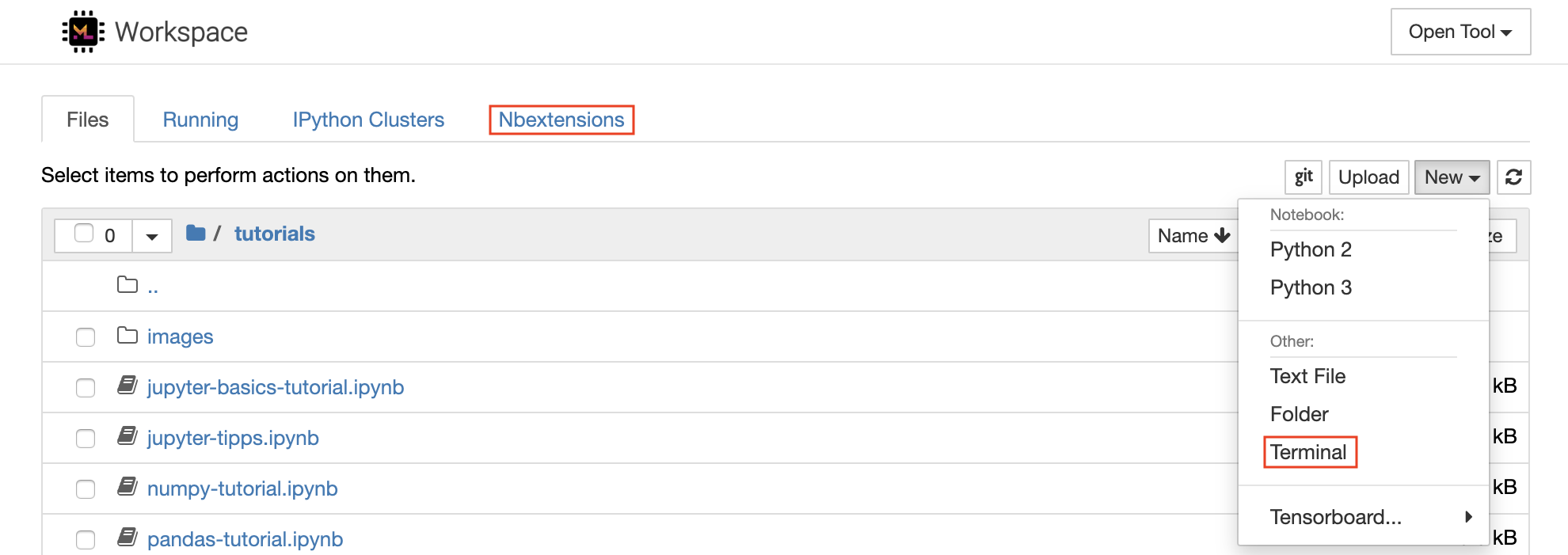
สามารถสร้างสมุดบันทึกใหม่ได้โดยคลิกที่ปุ่มดรอปดาวน์ New ที่ด้านบนของรายการและเลือกเคอร์เนลภาษาที่ต้องการ
คุณสามารถวางไข่อินสแตนซ์เท อร์มินัล แบบอินเทอร์แอคทีฟได้เช่นกันโดยเลือก
New -> Terminalในเบราว์เซอร์ไฟล์
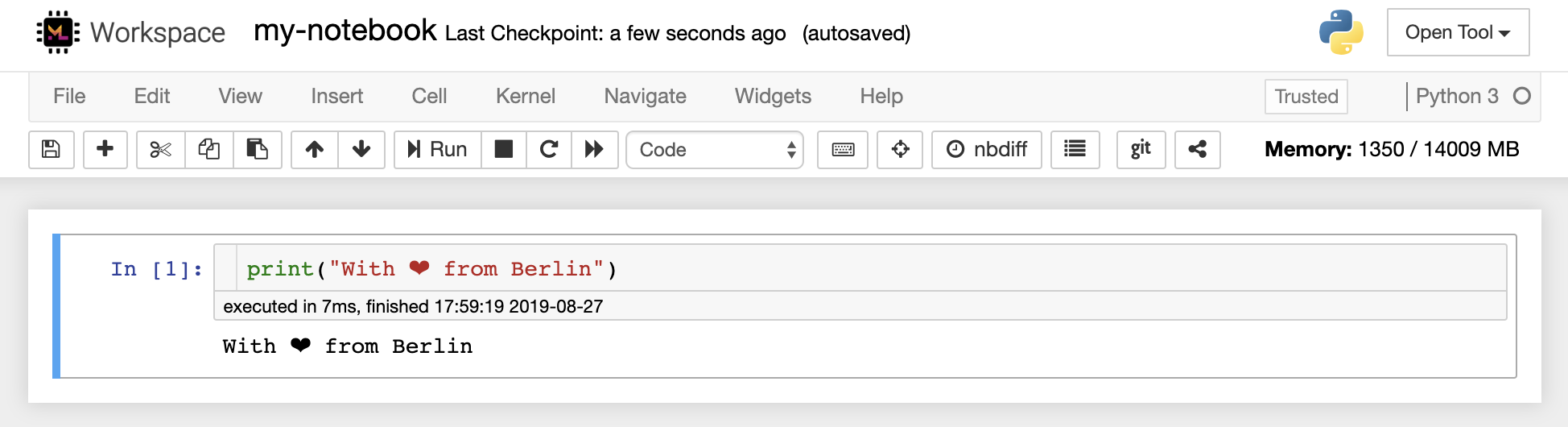
ตัวแก้ไขโน้ตบุ๊กช่วยให้ผู้ใช้สามารถใช้เอกสารผู้แต่งซึ่งรวมถึงรหัสสดข้อความมาร์เดอร์คำสั่งเชลล์สมการแบบลาเท็กซ์วิดเจ็ตอินเทอร์แอคทีฟพล็อตและรูปภาพ เอกสารสมุดบันทึกเหล่านี้ให้บันทึกที่สมบูรณ์และมีอยู่ในตัวเองของการคำนวณที่สามารถแปลงเป็นรูปแบบต่าง ๆ และแบ่งปันกับผู้อื่น
พื้นที่ทำงานนี้มีการเปิด ใช้งาน Jupyter ของบุคคลที่สาม ที่หลากหลาย คุณสามารถกำหนดค่าส่วนขยายเหล่านี้ในแท็บ NBEXTENSIONS: แท็บ
nbextensionsบนเบราว์เซอร์ไฟล์
โน้ตบุ๊กอนุญาตให้ใช้รหัสในช่วงของภาษาการเขียนโปรแกรมที่แตกต่างกัน สำหรับเอกสารสมุดบันทึกแต่ละฉบับที่ผู้ใช้เปิดขึ้นเว็บแอปพลิเคชันจะเริ่ม เคอร์เนล ที่เรียกใช้รหัสสำหรับสมุดบันทึกนั้นและส่งคืนผลลัพธ์ พื้นที่ทำงานนี้มีเคอร์เนล Python 3 ที่ติดตั้งไว้ล่วงหน้า สามารถติดตั้งเมล็ดเพิ่มเติมเพื่อเข้าถึงภาษาอื่น ๆ (เช่น, R, Scala, GO) หรือทรัพยากรการคำนวณเพิ่มเติม (เช่น GPU, CPU, หน่วยความจำ)
Python 2 ถูกลงโทษและเราไม่แนะนำให้ใช้ อย่างไรก็ตามคุณยังสามารถติดตั้งเคอร์เนล Python 2.7 ผ่านคำสั่งนี้:
/bin/bash /resources/tools/python-27.sh
พื้นที่ทำงานนี้ให้การเข้าถึง VNC ที่ใช้ HTTP ไปยังพื้นที่ทำงานผ่าน NOVNC ดังนั้นคุณสามารถเข้าถึงและทำงานภายในพื้นที่ทำงานด้วย Desktop GUI ที่มีคุณสมบัติครบถ้วน ในการเข้าถึงเดสก์ท็อป GUI นี้ให้ไปที่ Open Tool เลือก VNC และคลิกปุ่ม Connect ในกรณีที่คุณถูกขอรหัสผ่านให้ใช้ vncpassword
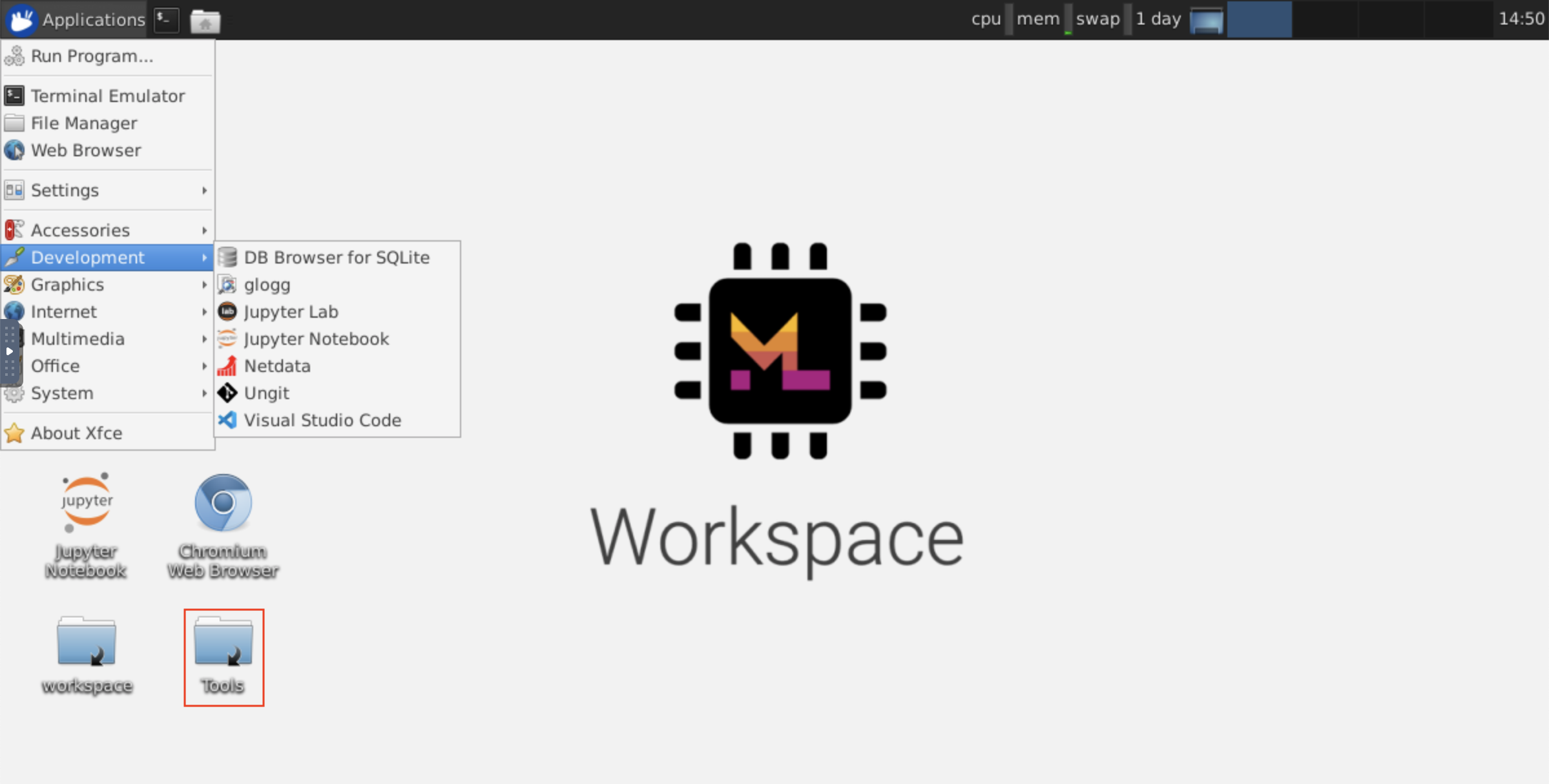
เมื่อคุณเชื่อมต่อแล้วคุณจะเห็น GUI เดสก์ท็อปที่ช่วยให้คุณติดตั้งและใช้เว็บเบราว์เซอร์เว็บเต็มรูปแบบหรือเครื่องมืออื่น ๆ ที่มีให้สำหรับ Ubuntu ภายในโฟลเดอร์ Tools บนเดสก์ท็อปคุณจะพบคอลเลกชันของสคริปต์การติดตั้งที่ทำให้มันตรงไปตรงมาเพื่อติดตั้งเครื่องมือพัฒนาที่ใช้กันมากที่สุดเช่นอะตอม, Pycharm, R-runtime, R-Studio หรือ Postman (เพียงคลิกสองครั้งบนสคริปต์)
คลิปบอร์ด: หากคุณต้องการแชร์คลิปบอร์ดระหว่างเครื่องและพื้นที่ทำงานคุณสามารถใช้ฟังก์ชันการคัดลอกได้ตามที่อธิบายไว้ด้านล่าง:
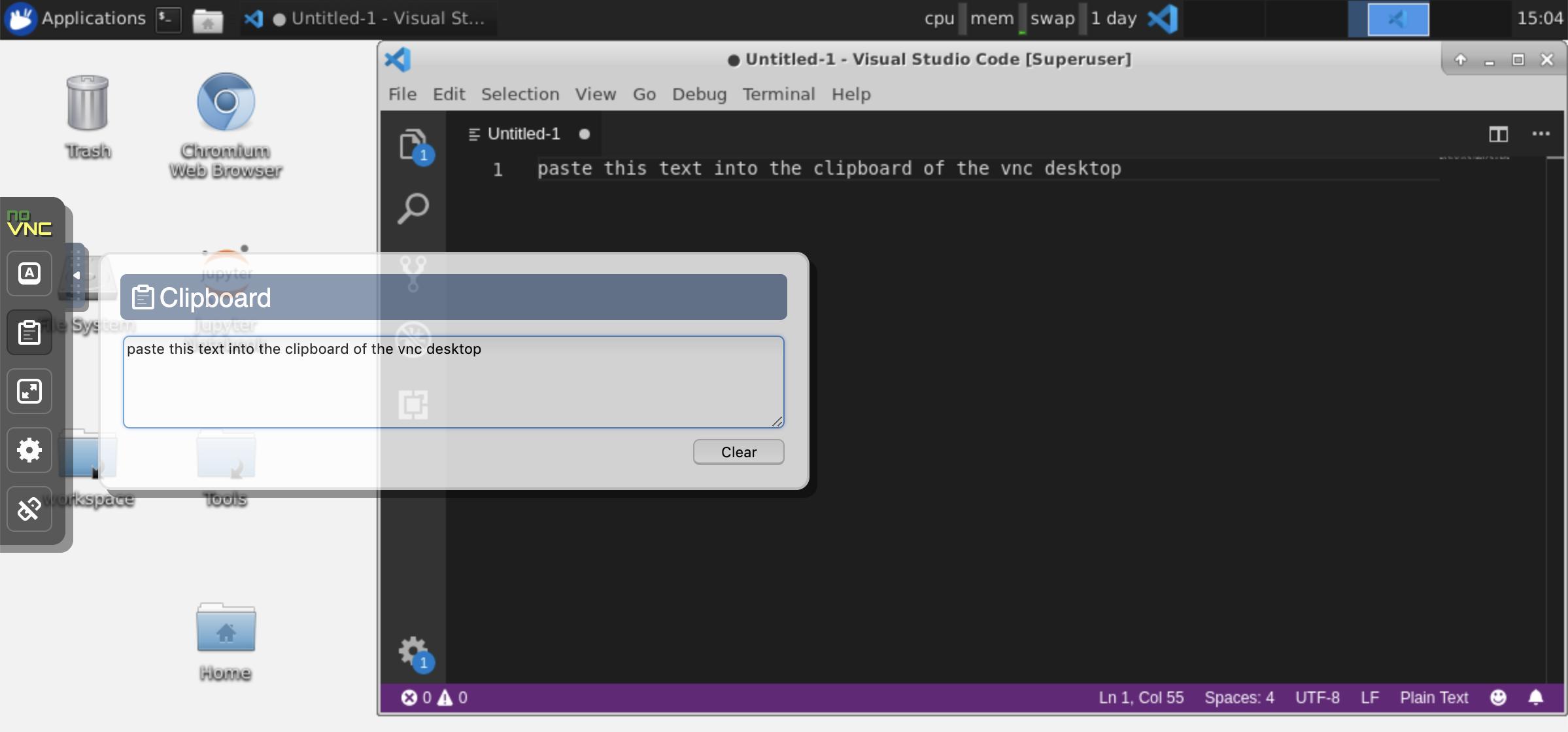
งานระยะยาว: ใช้เดสก์ท็อป GUI สำหรับการประหารชีวิต Jupyter ที่ดำเนินการมานาน ด้วยการเรียกใช้โน้ตบุ๊กจากเบราว์เซอร์ของเดสก์ท็อป GUI ของคุณเอาท์พุททั้งหมดจะถูกซิงโครไนซ์กับสมุดบันทึกแม้ว่าคุณจะตัดการเชื่อมต่อเบราว์เซอร์ของคุณจากสมุดบันทึก
Visual Studio Code ( Open Tool -> VS Code ) เป็นโปรแกรมแก้ไขรหัสที่มีน้ำหนักเบา แต่มีประสิทธิภาพที่มีน้ำหนักเบา แต่มีการสนับสนุนในตัวสำหรับภาษาที่หลากหลายและระบบนิเวศที่หลากหลายของส่วนขยาย มันรวมความเรียบง่ายของตัวแก้ไขซอร์สโค้ดเข้ากับเครื่องมือนักพัฒนาที่มีประสิทธิภาพเช่นการทำให้รหัส IntelliSense เสร็จสมบูรณ์และการดีบัก Workspace รวมรหัส VS เป็นแอปพลิเคชันบนเว็บที่สามารถเข้าถึงได้ผ่านเบราว์เซอร์ในโครงการ Code-Server ที่ยอดเยี่ยม ช่วยให้คุณปรับแต่งคุณสมบัติทุกอย่างตามความชอบของคุณและติดตั้งส่วนขยายของบุคคลที่สามจำนวนใดก็ได้
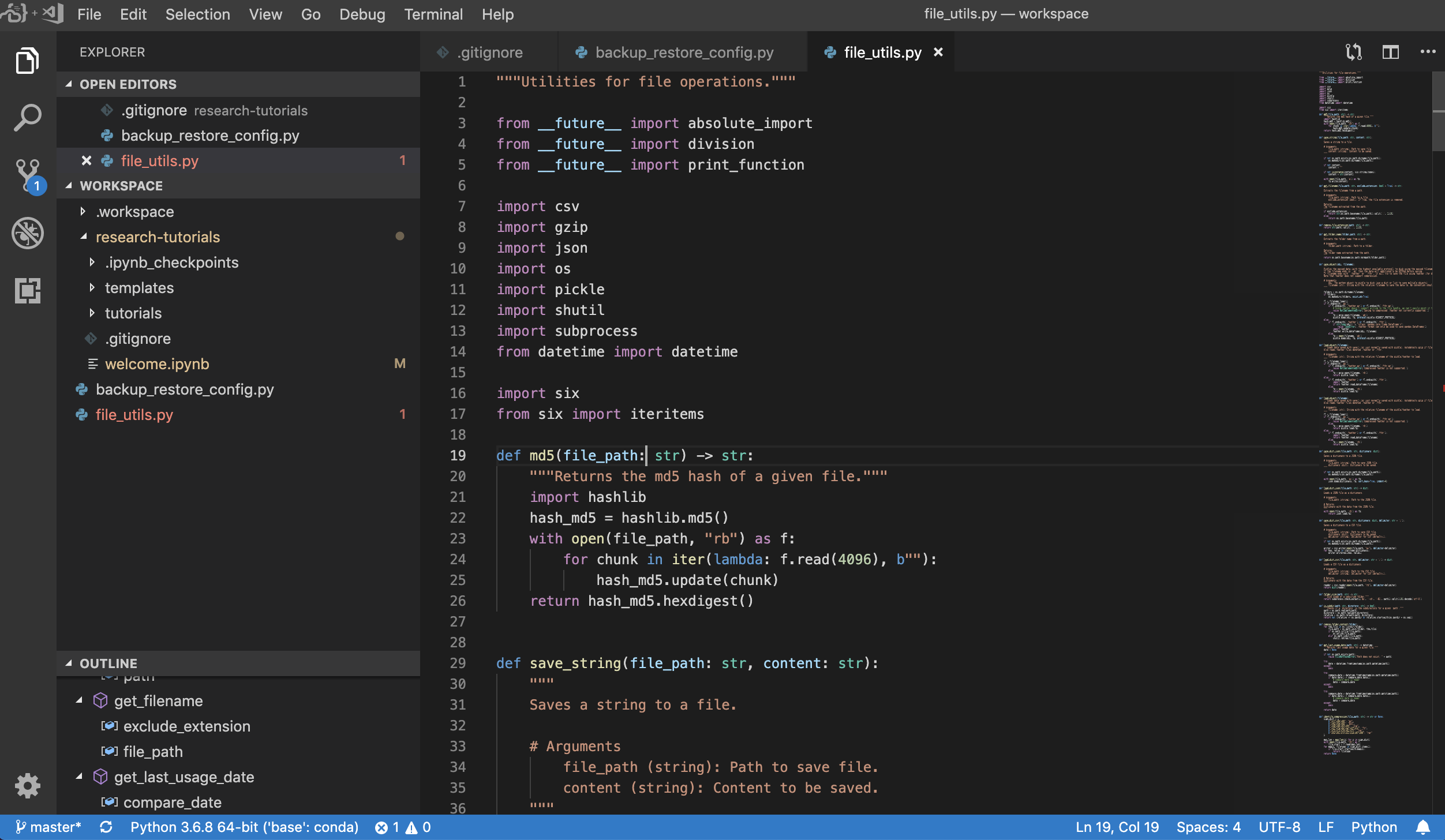
เวิร์กสเปซยังมีการรวมรหัส VS เข้ากับ Jupyter ช่วยให้คุณสามารถเปิดอินสแตนซ์ VS Code สำหรับโฟลเดอร์ที่เลือกได้ดังที่แสดงด้านล่าง:

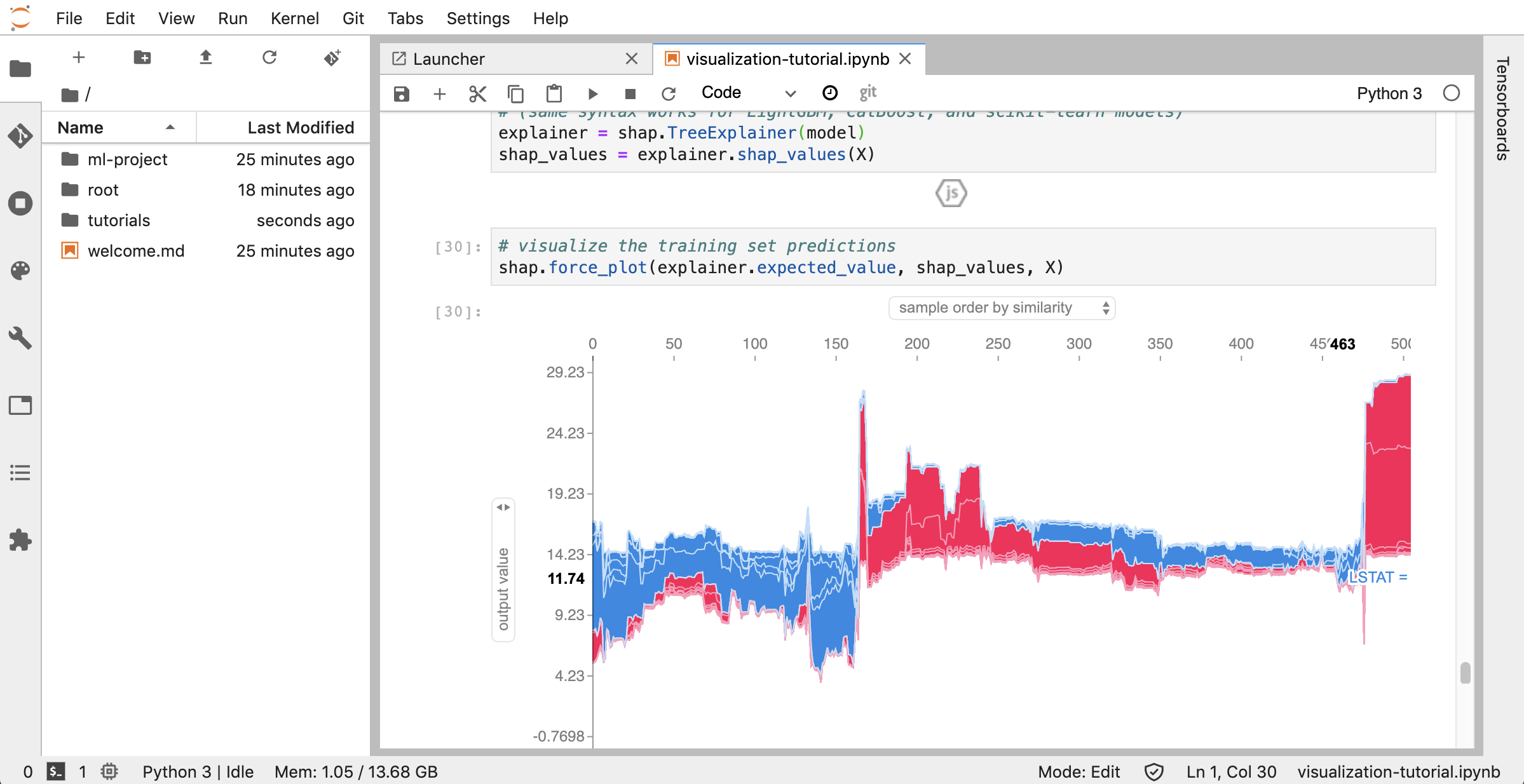
JupyterLab ( Open Tool -> JupyterLab ) เป็นส่วนต่อประสานผู้ใช้รุ่นต่อไปสำหรับโครงการ Jupyter มันมีการสร้างบล็อกที่คุ้นเคยทั้งหมดของสมุดบันทึก Jupyter คลาสสิก (สมุดบันทึกเทอร์มินัลตัวแก้ไขข้อความเบราว์เซอร์ไฟล์เอาต์พุตที่หลากหลาย ฯลฯ ) ในส่วนต่อประสานผู้ใช้ที่ยืดหยุ่นและทรงพลัง อินสแตนซ์ของ JupyterLab นี้มาพร้อมกับส่วนขยายที่เป็นประโยชน์สองสามอย่างเช่น JupyterLab-Toc, JupyterLab-Git และ JuptyterLab-Tensorboard
การควบคุมเวอร์ชันเป็นสิ่งสำคัญของการทำงานร่วมกันที่มีประสิทธิผล เพื่อให้กระบวนการนี้ราบรื่นที่สุดเท่าที่จะเป็นไปได้เราได้รวมส่วนขยายของ Jupyter ที่ทำเองให้พิเศษในการผลักดันโน้ตบุ๊กเดี่ยวไคลเอนต์ GIT บนเว็บที่เต็มเปี่ยม (UNGIT) เครื่องมือในการเปิดและแก้ไขเอกสารข้อความธรรมดา (เช่น . .py , .md ) นอกจากนี้ JupyterLab และ VS Code ยังมีไคลเอนต์ GIT ที่ใช้ GUI
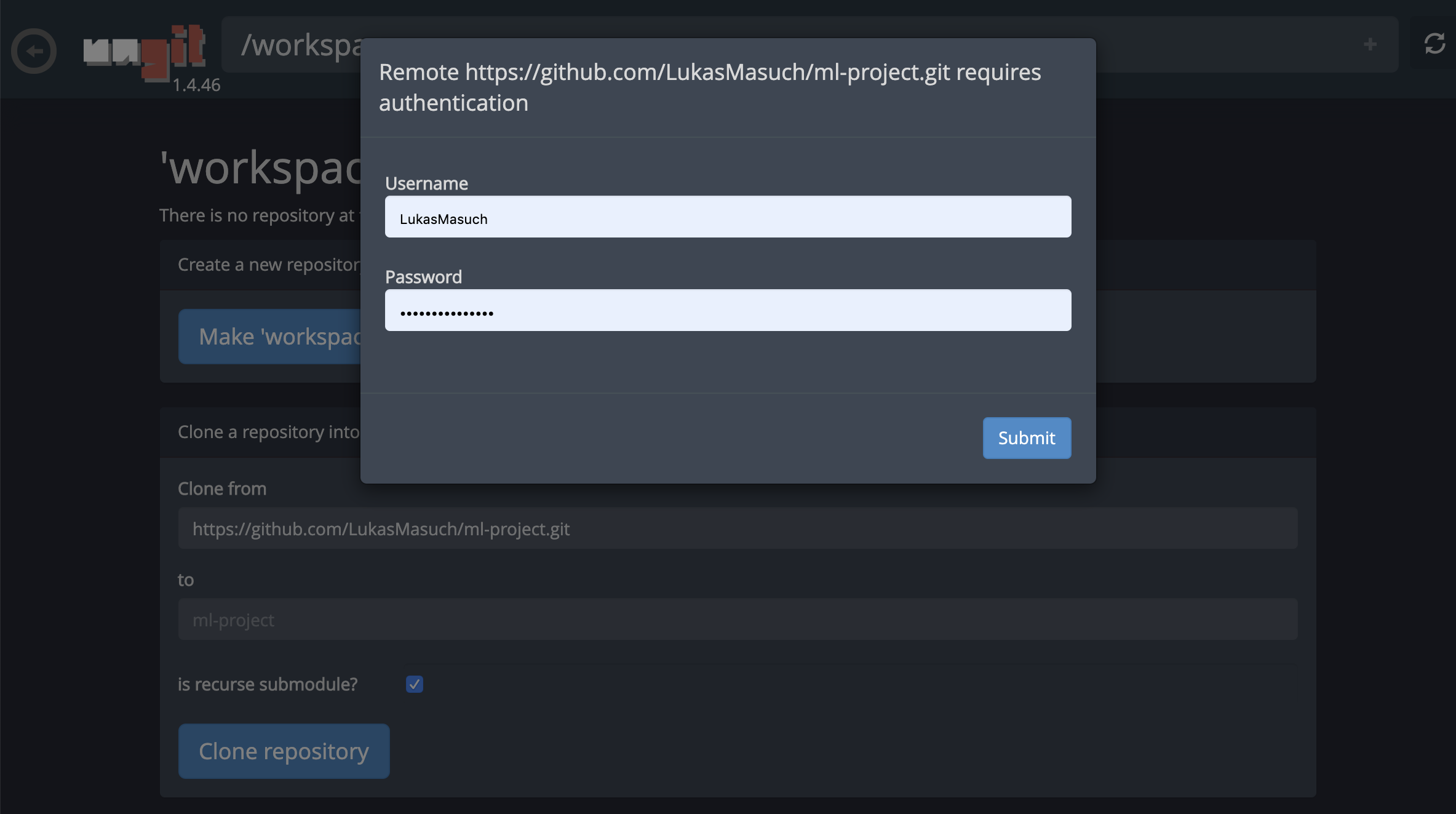
สำหรับการโคลนนิ่งที่เก็บผ่าน https เราขอแนะนำให้นำทางไปยังโฟลเดอร์รูทที่ต้องการและคลิกที่ปุ่ม git ดังที่แสดงด้านล่าง:

สิ่งนี้อาจขอการตั้งค่าที่จำเป็นบางอย่างและต่อมาเปิด Ungit ไคลเอนต์ GIT บนเว็บด้วย UI ที่สะอาดและใช้งานง่ายซึ่งทำให้สะดวกในการซิงค์สิ่งประดิษฐ์รหัสของคุณ ภายใน UNGIT คุณสามารถโคลนที่เก็บใด ๆ ได้ หากจำเป็นต้องมีการรับรองความถูกต้องคุณจะได้รับข้อมูลรับรองของคุณ
ในการกระทำและผลักดันโน้ตบุ๊กตัวเดียวไปยังที่เก็บ GIT ระยะไกลเราขอแนะนำให้ใช้ปลั๊กอิน GIT ที่รวมเข้ากับ Jupyter ดังที่แสดงด้านล่าง:
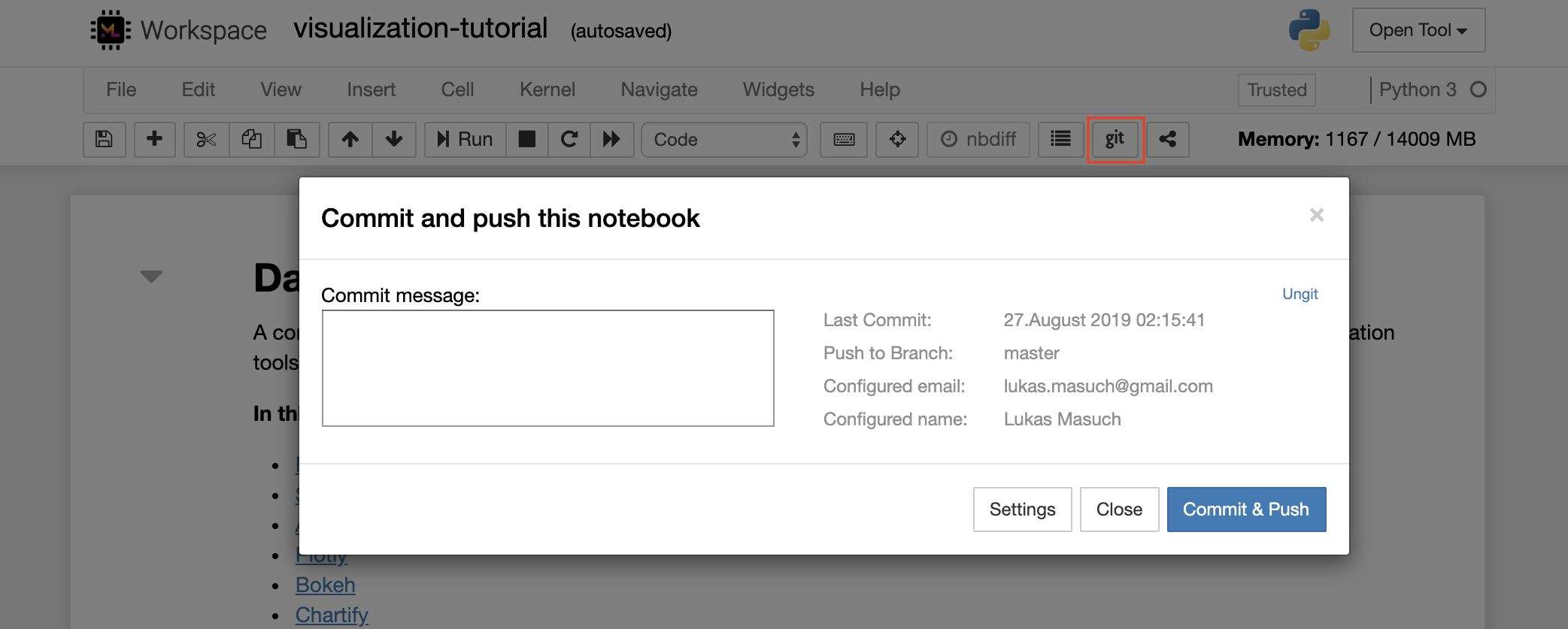
สำหรับการดำเนินการ GIT ขั้นสูงมากขึ้นเราขอแนะนำให้ใช้ UnGIT ด้วย UnGIT คุณสามารถทำการกระทำ GIT ทั่วไปส่วนใหญ่เช่นการผลัก, ดึง, ผสาน, สาขา, แท็ก, เช็คเอาต์และอื่น ๆ อีกมากมาย
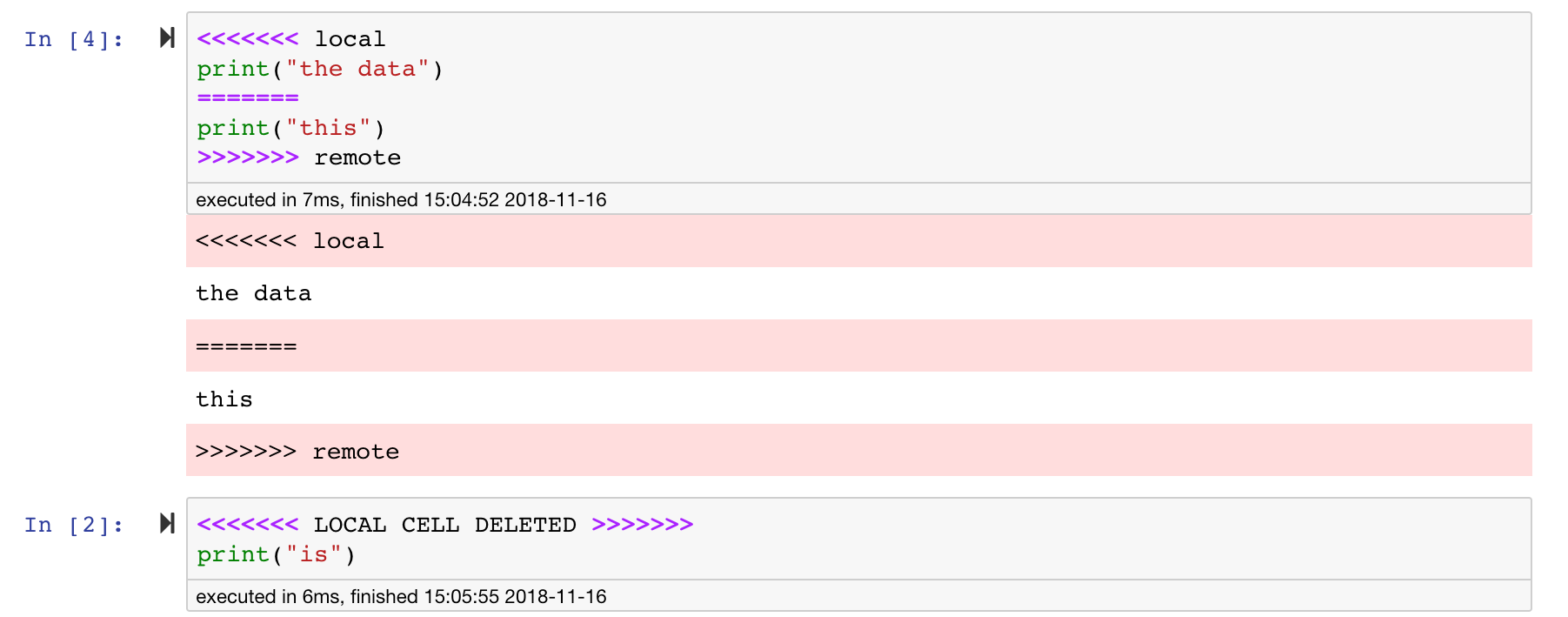
สมุดบันทึก Jupyter นั้นยอดเยี่ยม แต่พวกเขามักจะเป็นไฟล์ขนาดใหญ่ที่มีรูปแบบไฟล์ JSON ที่เฉพาะเจาะจงมาก เพื่อเปิดใช้งานการกระจายและการรวมที่ไร้รอยต่อผ่าน GIT พื้นที่ทำงานนี้ได้รับการติดตั้งล่วงหน้าด้วย NBDIME NBDime เข้าใจโครงสร้างของเอกสารสมุดบันทึกและดังนั้นจึงทำการตัดสินใจอย่างชาญฉลาดโดยอัตโนมัติเมื่อมีการกระจายและรวมโน้ตบุ๊ก ในกรณีที่คุณมีความขัดแย้งผสาน NBDIME จะทำให้แน่ใจว่าสมุดบันทึกยังคงสามารถอ่านได้โดย Jupyter ดังที่แสดงด้านล่าง:
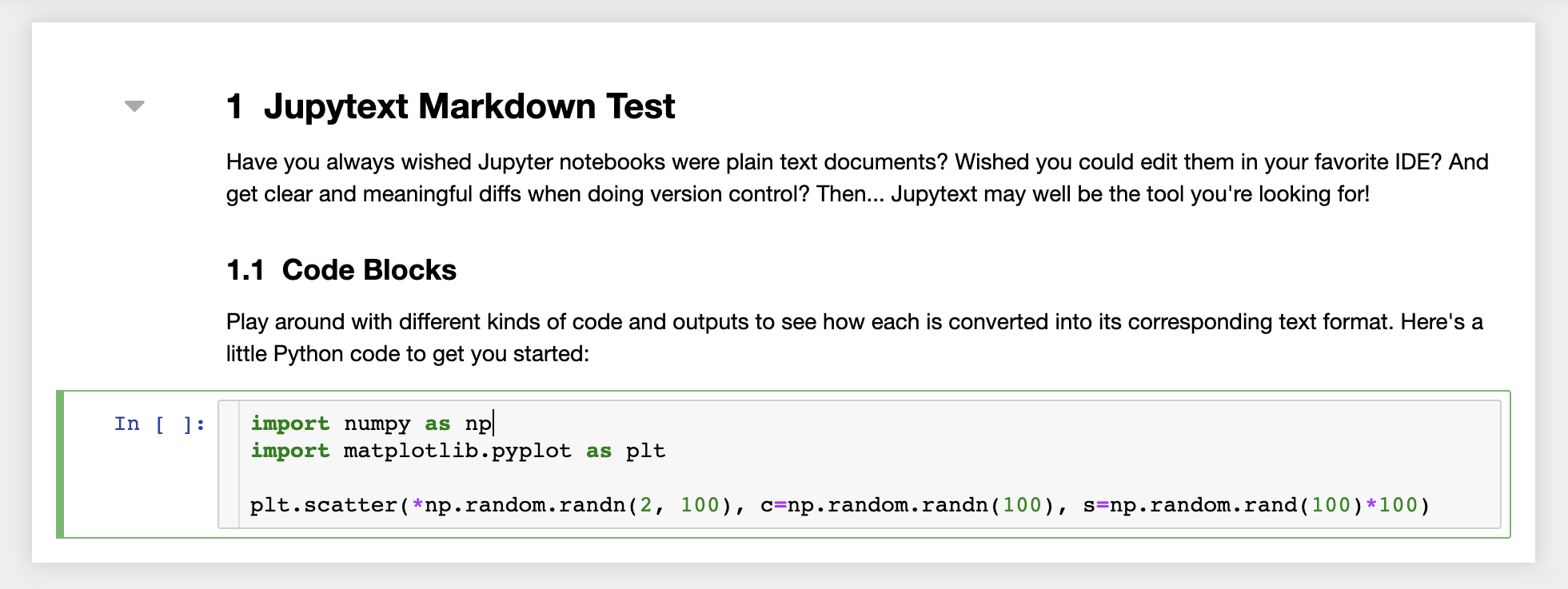
นอกจากนี้พื้นที่ทำงานยังติดตั้งไว้ล่วงหน้าด้วย Jupytext ปลั๊กอิน Jupyter ที่อ่านและเขียนสมุดบันทึกเป็นไฟล์ข้อความธรรมดา สิ่งนี้ช่วยให้คุณสามารถเปิดแก้ไขและเรียกใช้สคริปต์หรือไฟล์ markdown (เช่น .py , .md ) เป็นสมุดบันทึกภายใน Jupyter ในภาพหน้าจอต่อไปนี้เราได้เปิดไฟล์ Markdown ผ่าน Jupyter:
เมื่อใช้ร่วมกับ Git JupyText ช่วยให้มีประวัติความแตกต่างที่ชัดเจนและการรวมความขัดแย้งของเวอร์ชันอย่างง่ายดาย ด้วยเครื่องมือทั้งสองเหล่านี้การร่วมมือกับ Jupyter Notebooks กับ Git จะกลายเป็นเรื่องตรงไปตรงมา
เวิร์กสเปซมีคุณสมบัติในการแชร์ไฟล์หรือโฟลเดอร์ใด ๆ กับทุกคนผ่านลิงก์ที่ป้องกันโทเค็น หากต้องการแชร์ข้อมูลผ่านลิงค์ให้เลือกไฟล์หรือโฟลเดอร์ใด ๆ จากแผนผังไดเรกทอรี Jupyter และคลิกที่ปุ่มแชร์ดังที่แสดงในภาพหน้าจอต่อไปนี้:
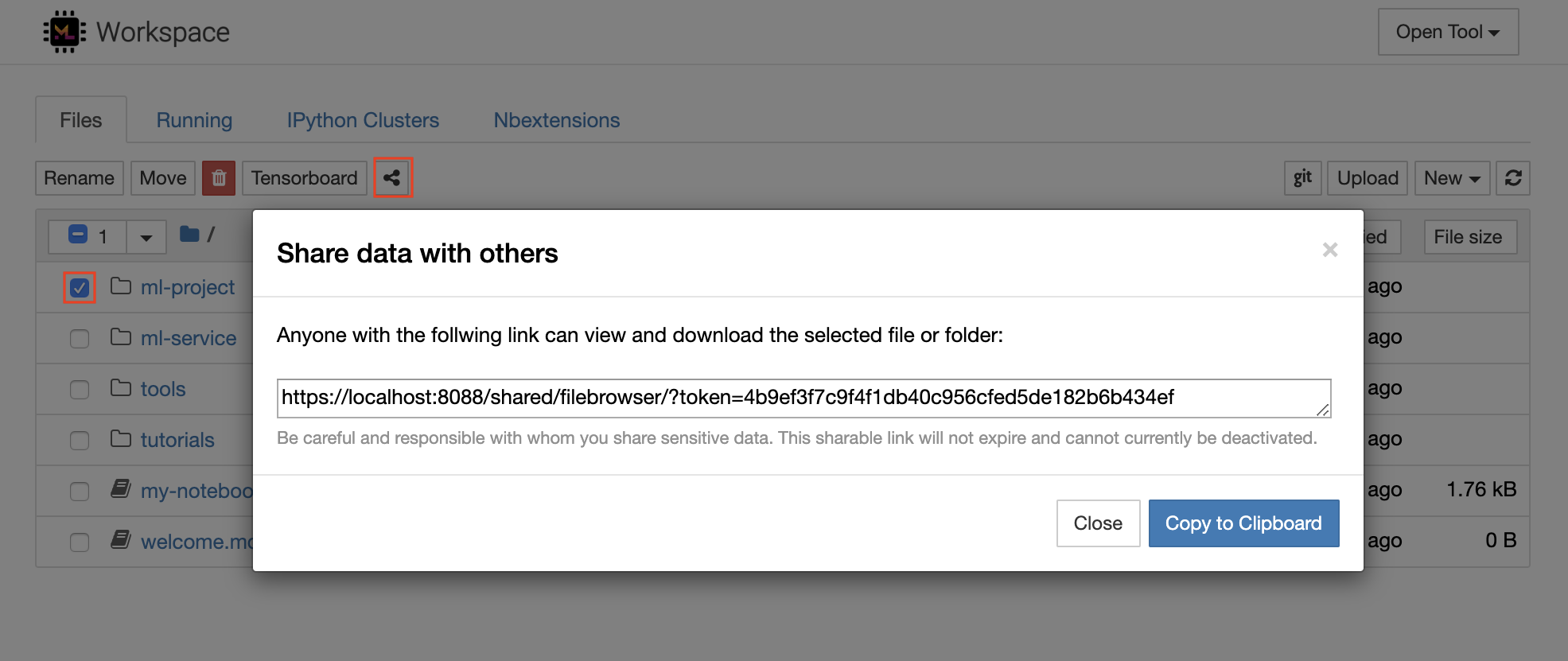
สิ่งนี้จะสร้างลิงก์ที่ไม่ซ้ำกันผ่านโทเค็นที่ให้ทุกคนที่มีการเข้าถึงลิงก์เพื่อดูและดาวน์โหลดข้อมูลที่เลือกผ่าน FileBrowser UI:
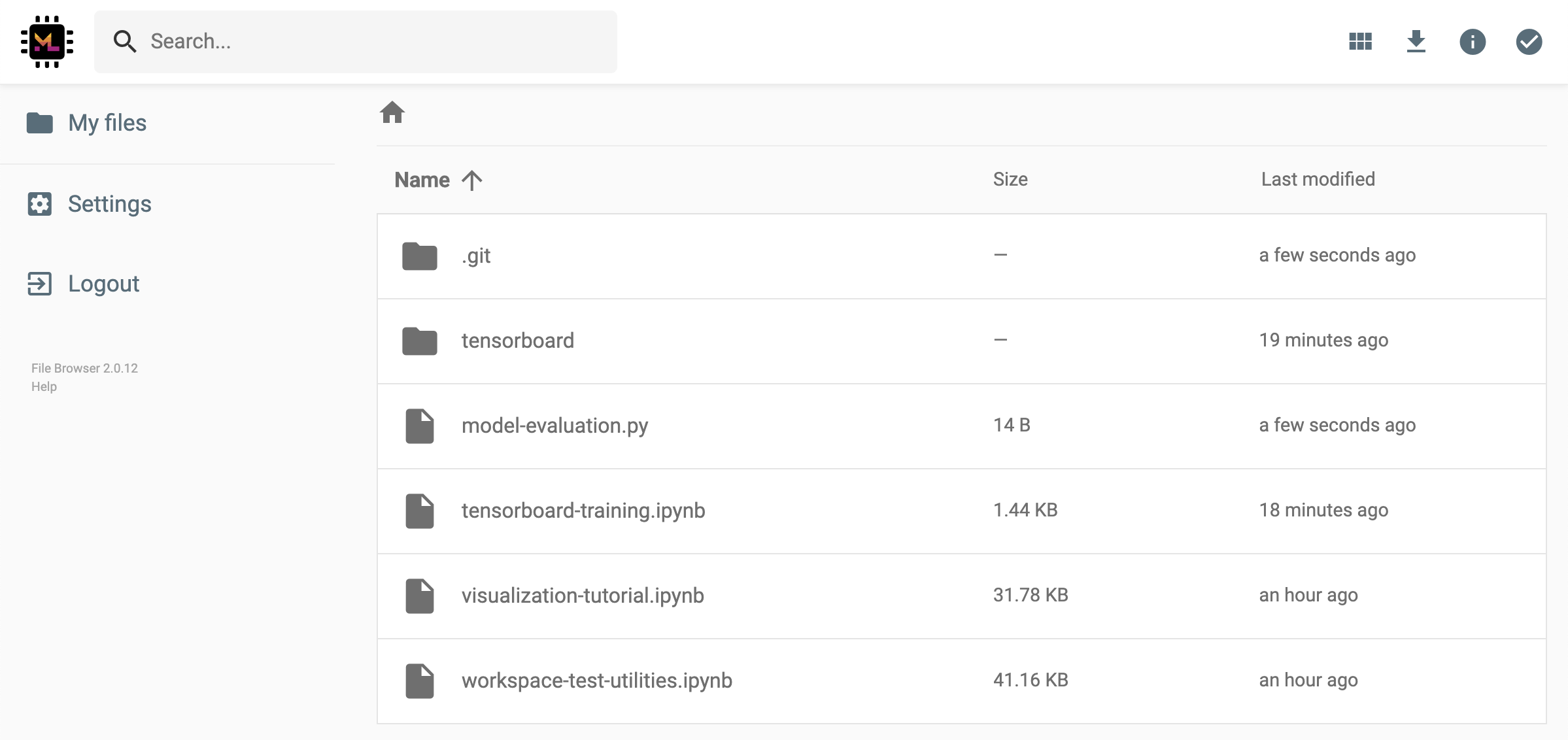
ในการปิดใช้งานหรือจัดการ (เช่นให้การแก้ไขสิทธิ์) ลิงก์ที่ใช้ร่วมกันให้เปิด FileBrowser ผ่าน Open Tool -> Filebrowser และเลือก Settings->User Management
เป็นไปได้ที่จะเข้าถึงพอร์ตภายในเวิร์กสเปซอย่างปลอดภัยโดยเลือก Open Tool -> Access Port ด้วยคุณสมบัตินี้คุณสามารถเข้าถึง REST API หรือเว็บแอปพลิเคชันที่ทำงานภายในพื้นที่ทำงานโดยตรงกับเบราว์เซอร์ของคุณ คุณลักษณะนี้ช่วยให้นักพัฒนาสามารถสร้างรันทดสอบและดีบัก REST API หรือเว็บแอปพลิเคชันโดยตรงจากพื้นที่ทำงาน
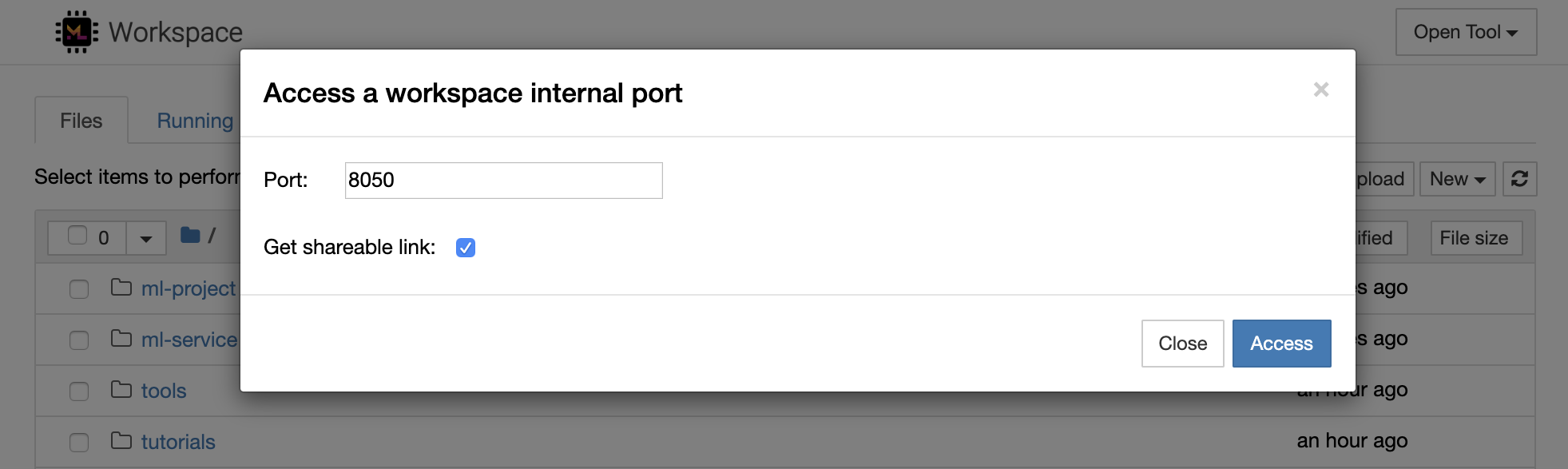
หากคุณต้องการใช้ไคลเอนต์ HTTP หรือแชร์การเข้าถึงพอร์ตที่กำหนดคุณสามารถเลือกตัวเลือก Get shareable link สิ่งนี้สร้างลิงก์ที่มีความปลอดภัยโทเค็นที่ทุกคนที่มีการเข้าถึงลิงก์สามารถใช้เพื่อเข้าถึงพอร์ตที่ระบุ
แอป HTTP ต้องได้รับการแก้ไขจากเส้นทาง URL ที่สัมพันธ์กันหรือกำหนดค่าเส้นทางพื้นฐาน (
/tools/PORT/) เครื่องมือที่ทำให้สามารถเข้าถึงได้ด้วยวิธีนี้ได้รับการรักษาความปลอดภัยโดยระบบตรวจสอบความถูกต้องของพื้นที่ทำงาน! หากคุณตัดสินใจที่จะเผยแพร่พอร์ตอื่น ๆ ของคอนเทนเนอร์ด้วยตัวคุณเองแทนที่จะใช้คุณสมบัตินี้เพื่อให้สามารถเข้าถึงเครื่องมือได้โปรดตรวจสอบให้แน่ใจว่าได้รับการรักษาความปลอดภัยผ่านกลไกการรับรองความถูกต้อง!
1234 โดยเรียกใช้คำสั่งนี้ในเทอร์มินัลภายในเวิร์กสเปซ: python -m http.server 1234Open Tool -> Access Port พอร์ตอินพุต 1234 และเลือกตัวเลือก Get shareable linkAccess และคุณจะเห็นเนื้อหาที่จัดทำโดย http.server ของ Python SSH จัดเตรียมชุดคุณสมบัติที่ทรงพลังที่ช่วยให้คุณมีประสิทธิภาพมากขึ้นกับงานการพัฒนาของคุณ คุณสามารถตั้งค่าการเชื่อมต่อ SSH ที่ปลอดภัยและไม่มีรหัสผ่านไปยังพื้นที่ทำงานได้อย่างง่ายดายโดยเลือก Open Tool -> SSH สิ่งนี้จะสร้างคำสั่ง Secure Setup ที่สามารถรันบนเครื่อง Linux หรือ Mac ใด ๆ เพื่อกำหนดค่าการเชื่อมต่อ SSH แบบไม่มีรหัสผ่านและปลอดภัยไปยังเวิร์กสเปซ หรือคุณสามารถดาวน์โหลดสคริปต์การตั้งค่าและเรียกใช้ (แทนที่จะใช้คำสั่ง)
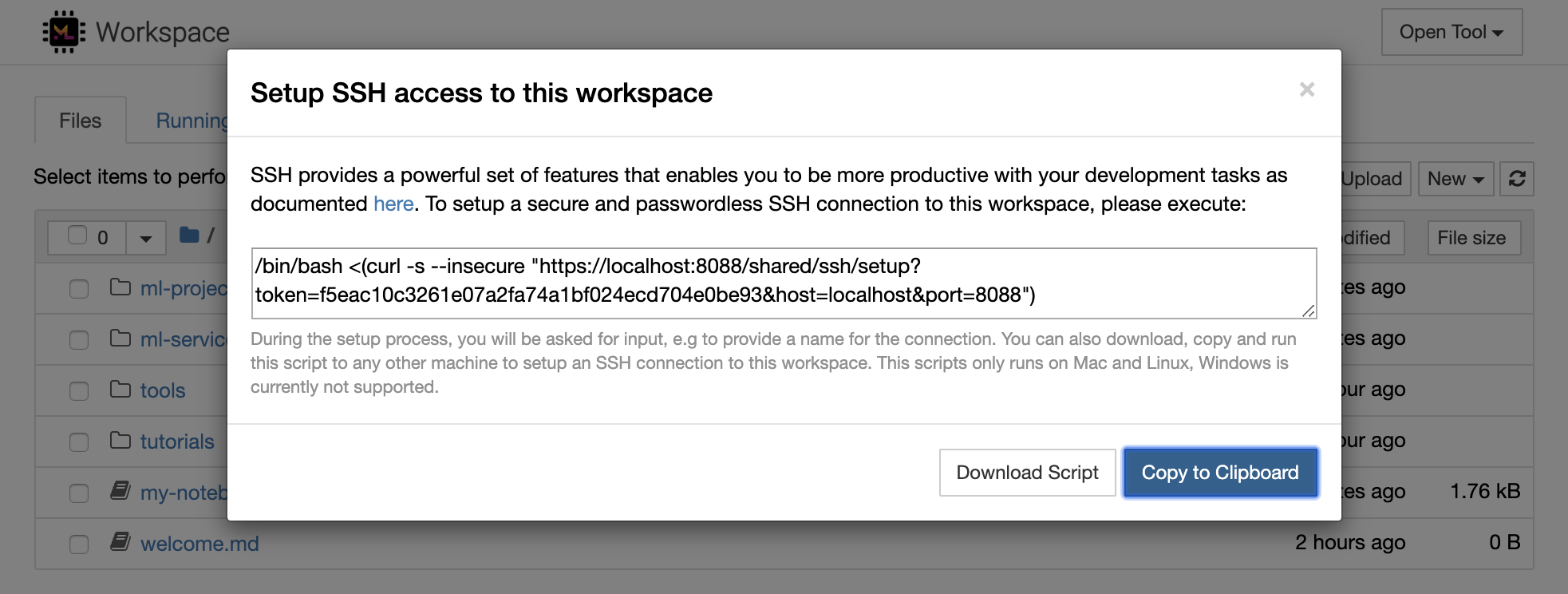
สคริปต์การตั้งค่าทำงานบน Mac และ Linux เท่านั้น ปัจจุบัน Windows ไม่รองรับ
เพียงเรียกใช้คำสั่ง SETUP หรือสคริปต์บนเครื่องจากที่คุณต้องการตั้งค่าการเชื่อมต่อไปยังพื้นที่ทำงานและป้อนชื่อสำหรับการเชื่อมต่อ (เช่น my-workspace ) คุณอาจได้รับการขออินพุตเพิ่มเติมในระหว่างกระบวนการเช่นการติดตั้งเคอร์เนลระยะไกลหากติดตั้ง remote_ikernel เมื่อการเชื่อมต่อ SSH แบบไม่มีรหัสผ่านถูกตั้งค่าและทดสอบเรียบร้อยแล้วคุณสามารถเชื่อมต่อกับพื้นที่ทำงานได้อย่างปลอดภัยโดยเพียงแค่ดำเนินการ ssh my-workspace
นอกเหนือจากความสามารถในการดำเนินการคำสั่งบนเครื่องระยะไกลแล้ว SSH ยังมีคุณสมบัติอื่น ๆ ที่หลากหลายซึ่งสามารถปรับปรุงเวิร์กโฟลว์การพัฒนาของคุณตามที่อธิบายไว้ในส่วนต่อไปนี้
การเชื่อมต่อ SSH สามารถใช้สำหรับพอร์ตแอปพลิเคชันอุโมงค์จากเครื่องไกลไปยังเครื่องท้องถิ่นหรือในทางกลับกัน ตัวอย่างเช่นคุณสามารถเปิดเผยพอร์ตภายในเวิร์กสเปซ 5901 (เซิร์ฟเวอร์ VNC) ไปยังเครื่องท้องถิ่นบนพอร์ต 5000 โดยดำเนินการ:
ssh -nNT -L 5000:localhost:5901 my-workspaceในการเปิดเผยพอร์ตแอปพลิเคชันจากเครื่องในพื้นที่ของคุณไปยังพื้นที่ทำงานให้ใช้ตัวเลือก
-R(แทน-L)
หลังจากสร้างอุโมงค์แล้วคุณสามารถใช้ VNC Viewer ที่คุณชื่นชอบบนเครื่องในเครื่องของคุณและเชื่อมต่อกับ vnc://localhost:5000 (รหัสผ่านเริ่มต้น: vncpassword ) เพื่อให้การเชื่อมต่ออุโมงค์ต้านทานและเชื่อถือได้มากขึ้นเราขอแนะนำให้ใช้ AutosSH เพื่อรีสตาร์ท SSH Tunnels โดยอัตโนมัติในกรณีที่การเชื่อมต่อตาย:
autossh -M 0 -f -nNT -L 5000:localhost:5901 my-workspaceพอร์ตอุโมงค์ค่อนข้างมีประโยชน์เมื่อคุณเริ่มเครื่องมือบนเซิร์ฟเวอร์ภายในพื้นที่ทำงานที่คุณต้องการให้สามารถเข้าถึงได้สำหรับเครื่องอื่น ในการตั้งค่าเริ่มต้นพื้นที่ทำงานมีเครื่องมือที่หลากหลายที่ทำงานอยู่บนพอร์ตที่แตกต่างกันเช่น:
8080 : พอร์ตพื้นที่ทำงานหลักพร้อมการเข้าถึงเครื่องมือรวมทั้งหมด8090 : เซิร์ฟเวอร์ Jupyter8054 : VS Code Server5901 : VNC Server22 : เซิร์ฟเวอร์ SSHคุณสามารถค้นหาข้อมูลพอร์ตเกี่ยวกับเครื่องมือทั้งหมดในการกำหนดค่าหัวหน้างาน
สำหรับข้อมูลเพิ่มเติมเกี่ยวกับพอร์ตอุโมงค์/การส่งต่อเราขอแนะนำคู่มือนี้
SCP ช่วยให้ไฟล์และไดเรกทอรีถูกคัดลอกอย่างปลอดภัยจากหรือระหว่างเครื่องจักรที่แตกต่างกันผ่านการเชื่อมต่อ SSH ตัวอย่างเช่นในการคัดลอกไฟล์โลคัล ( ./local-file.txt ) ลงในโฟลเดอร์ /workspace ภายในเวิร์กสเปซดำเนินการ:
scp ./local-file.txt my-workspace:/workspace ในการคัดลอกไดเรกทอรี /workspace จาก my-workspace ไปยังไดเรกทอรีการทำงานของเครื่องท้องถิ่นให้ดำเนินการ:
scp -r my-workspace:/workspace .สำหรับข้อมูลเพิ่มเติมเกี่ยวกับ SCP เราขอแนะนำคู่มือนี้
RSYNC เป็นยูทิลิตี้สำหรับการถ่ายโอนและซิงโครไนซ์ไฟล์อย่างมีประสิทธิภาพระหว่างเครื่องที่แตกต่างกัน (เช่นผ่านการเชื่อมต่อ SSH) โดยการเปรียบเทียบเวลาการปรับเปลี่ยนและขนาดของไฟล์ คำสั่ง RSYNC จะกำหนดไฟล์ที่จำเป็นต้องได้รับการอัปเดตทุกครั้งที่มีการรันซึ่งมีประสิทธิภาพและสะดวกกว่าการใช้ SCP หรือ SFTP ตัวอย่างเช่นในการซิงค์เนื้อหาทั้งหมดของโฟลเดอร์ท้องถิ่น ( ./local-project-folder/ ) ลงใน /workspace/remote-project-folder/ โฟลเดอร์ภายในพื้นที่ทำงานดำเนินการ:
rsync -rlptzvP --delete --exclude= " .git " " ./local-project-folder/ " " my-workspace:/workspace/remote-project-folder/ "หากคุณมีการเปลี่ยนแปลงบางอย่างภายในโฟลเดอร์บนพื้นที่ทำงานคุณสามารถซิงค์การเปลี่ยนแปลงเหล่านั้นกลับไปที่โฟลเดอร์ท้องถิ่นโดยการเปลี่ยนอาร์กิวเมนต์ต้นทางและปลายทาง:
rsync -rlptzvP --delete --exclude= " .git " " my-workspace:/workspace/remote-project-folder/ " " ./local-project-folder/ "คุณสามารถเรียกใช้คำสั่งเหล่านี้อีกครั้งทุกครั้งที่คุณต้องการซิงโครไนซ์สำเนาไฟล์ล่าสุดของคุณ RSYNC จะทำให้แน่ใจว่าจะมีการถ่ายโอนเฉพาะการอัปเดตเท่านั้น
คุณสามารถค้นหาข้อมูลเพิ่มเติมเกี่ยวกับ RSYNC ในหน้าชายคนนี้
นอกเหนือจากการคัดลอกและการซิงค์ข้อมูลแล้วการเชื่อมต่อ SSH ยังสามารถใช้ในการติดตั้งไดเรกทอรีจากเครื่องระยะไกลไปยังระบบไฟล์ท้องถิ่นผ่าน SSHFS ตัวอย่างเช่นในการเมานต์ไดเรกทอรี /workspace ของ my-workspace ลงในเส้นทางท้องถิ่น (เช่น /local/folder/path ) ให้ดำเนินการ:
sshfs -o reconnect my-workspace:/workspace /local/folder/pathเมื่อมีการติดตั้งไดเรกทอรีระยะไกลคุณสามารถโต้ตอบกับระบบไฟล์ระยะไกลได้เช่นเดียวกับไดเรกทอรีและไฟล์ท้องถิ่นใด ๆ
สำหรับข้อมูลเพิ่มเติมเกี่ยวกับ SSHFS เราขอแนะนำคู่มือนี้
พื้นที่ทำงานสามารถรวมและใช้เป็นรันไทม์ระยะไกล (หรือที่เรียกว่าเคอร์เนลระยะไกล/เครื่องจักร/ล่าม) สำหรับเครื่องมือการพัฒนาที่เป็นที่นิยมและ IDEs เช่น Jupyter, VS Code, Pycharm, Colab หรือ Atom Hydrogen ดังนั้นคุณสามารถเชื่อมต่อเครื่องมือพัฒนาที่คุณชื่นชอบที่ทำงานบนเครื่องในพื้นที่ของคุณกับเครื่องระยะไกลสำหรับการดำเนินการรหัส สิ่งนี้ช่วยให้ประสบการณ์การพัฒนาที่มีคุณภาพในท้องถิ่นด้วยทรัพยากรการคำนวณระยะไกลที่เป็นโฮสต์
การรวมเหล่านี้มักจะต้องใช้การเชื่อมต่อ SSH แบบไม่มีรหัสผ่านจากเครื่องท้องถิ่นไปยังพื้นที่ทำงาน ในการตั้งค่าการเชื่อมต่อ SSH โปรดทำตามขั้นตอนที่อธิบายไว้ในส่วนการเข้าถึง SSH
พื้นที่ทำงานสามารถเพิ่มลงในอินสแตนซ์ Jupyter เป็นเคอร์เนลระยะไกลโดยใช้เครื่องมือ remote_ikernel หากคุณติดตั้ง Remote_ikerNel ( pip install remote_ikernel ) บนเครื่องในเครื่องของคุณสคริปต์การตั้งค่า SSH ของพื้นที่ทำงานจะเสนอตัวเลือกให้คุณตั้งค่าการเชื่อมต่อเคอร์เนลระยะไกลโดยอัตโนมัติ
เมื่อเรียกใช้เมล็ดในเครื่องรีโมตโน้ตบุ๊กจะถูกบันทึกลงในระบบไฟล์ท้องถิ่น แต่เคอร์เนลจะสามารถเข้าถึงระบบไฟล์ของเครื่องระยะไกลที่ใช้เคอร์เนลเท่านั้น หากคุณต้องการซิงค์ข้อมูลคุณสามารถใช้ประโยชน์จาก RSYNC, SCP หรือ SSHFs ตามที่อธิบายไว้ในส่วนการเข้าถึง SSH
ในกรณีที่คุณต้องการตั้งค่าและจัดการเคอร์เนลระยะไกลด้วยตนเองให้ใช้เครื่องมือบรรทัดคำสั่ง remote_ikernel ดังที่แสดงด้านล่าง:
# Change my-workspace with the name of a workspace SSH connection
remote_ikernel manage --add
--interface=ssh
--kernel_cmd= " ipython kernel -f {connection_file} "
--name= " ml-server (Python) "
--host= " my-workspace " คุณสามารถใช้ฟังก์ชั่นบรรทัดคำสั่ง remote_ikernel ไปยังรายการ ( remote_ikernel manage --show ) หรือ DELETE ( remote_ikernel manage --delete <REMOTE_KERNEL_NAME> ) การเชื่อมต่อเคอร์เนลระยะไกล
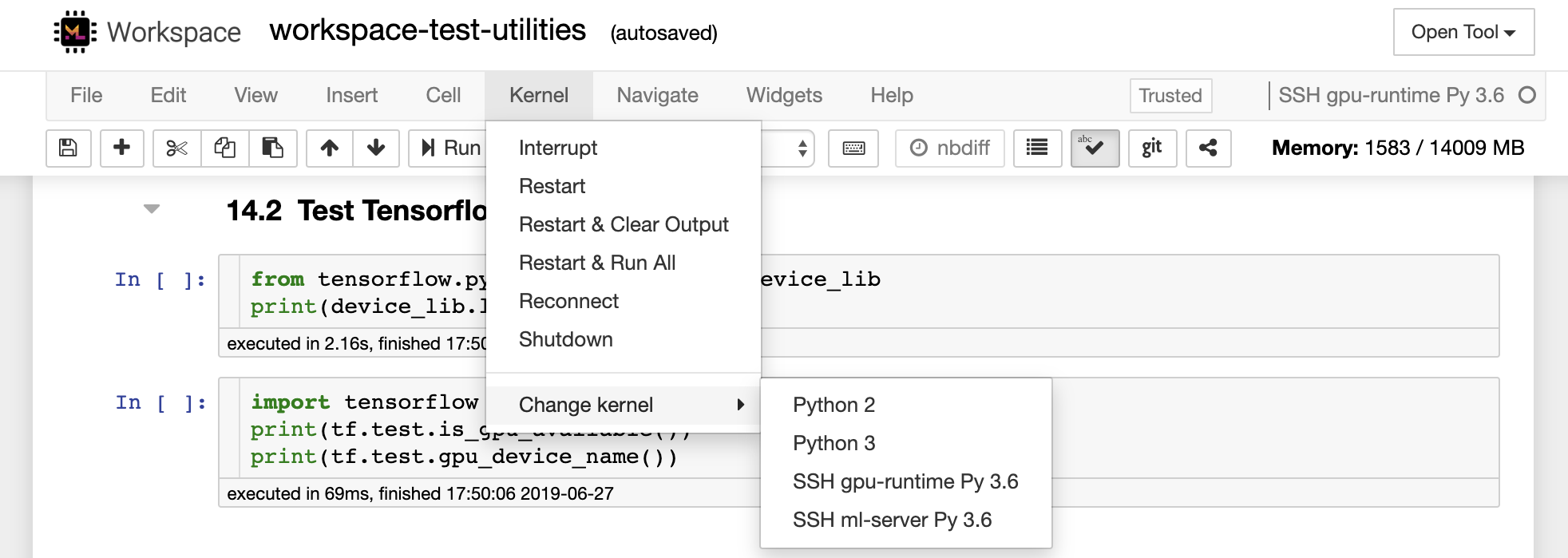
Visual Studio Code Remote - SSH Extension ช่วยให้คุณเปิดโฟลเดอร์ระยะไกลบนเครื่องรีโมตที่มีการเข้าถึง SSH และทำงานกับมันเช่นเดียวกับที่คุณต้องการหากโฟลเดอร์อยู่ในเครื่องของคุณเอง เมื่อเชื่อมต่อกับเครื่องระยะไกลคุณสามารถโต้ตอบกับไฟล์และโฟลเดอร์ได้ทุกที่ในระบบไฟล์ระยะไกลและใช้ประโยชน์อย่างเต็มที่จากชุดคุณสมบัติของ VS Code (IntelliSense, Debugging และ Extension Support) การค้นพบและทำงานนอกกรอบด้วยการเชื่อมต่อ SSH แบบไม่มีรหัสผ่านตามที่กำหนดค่าโดยสคริปต์การตั้งค่า SSH Workspace เพื่อเปิดใช้งานแอปพลิเคชันรหัสในพื้นที่ของคุณเพื่อเชื่อมต่อกับพื้นที่ทำงาน:
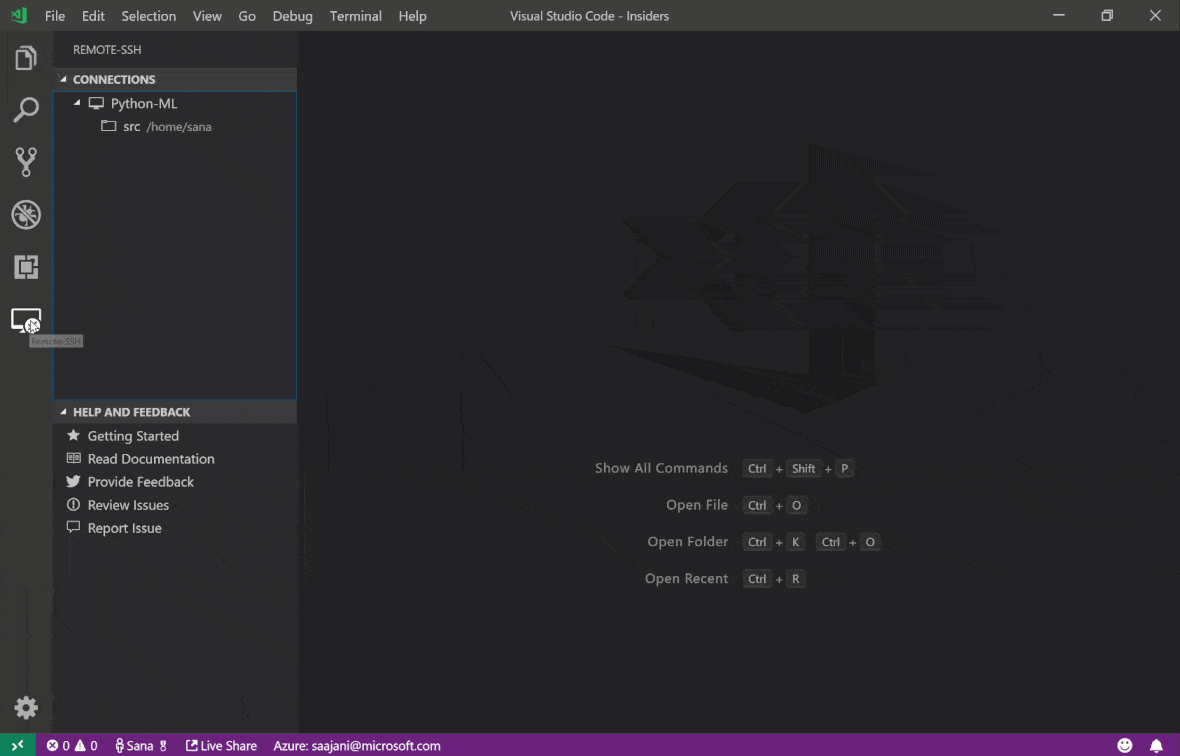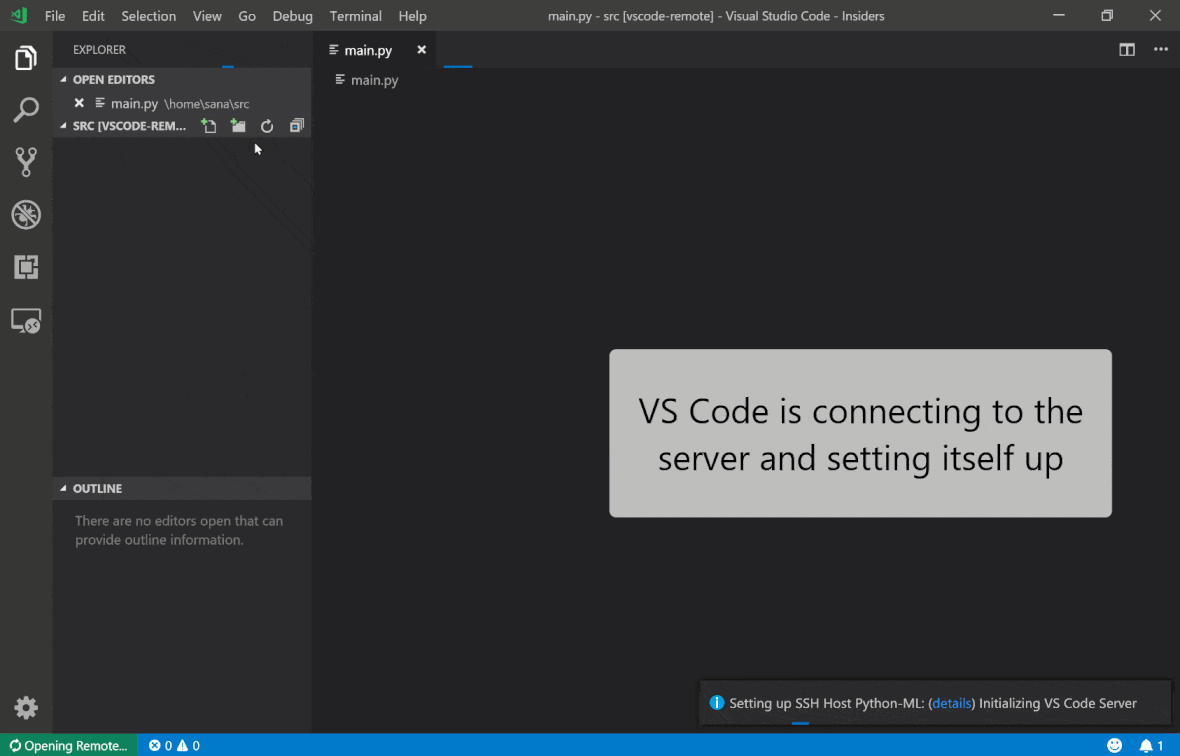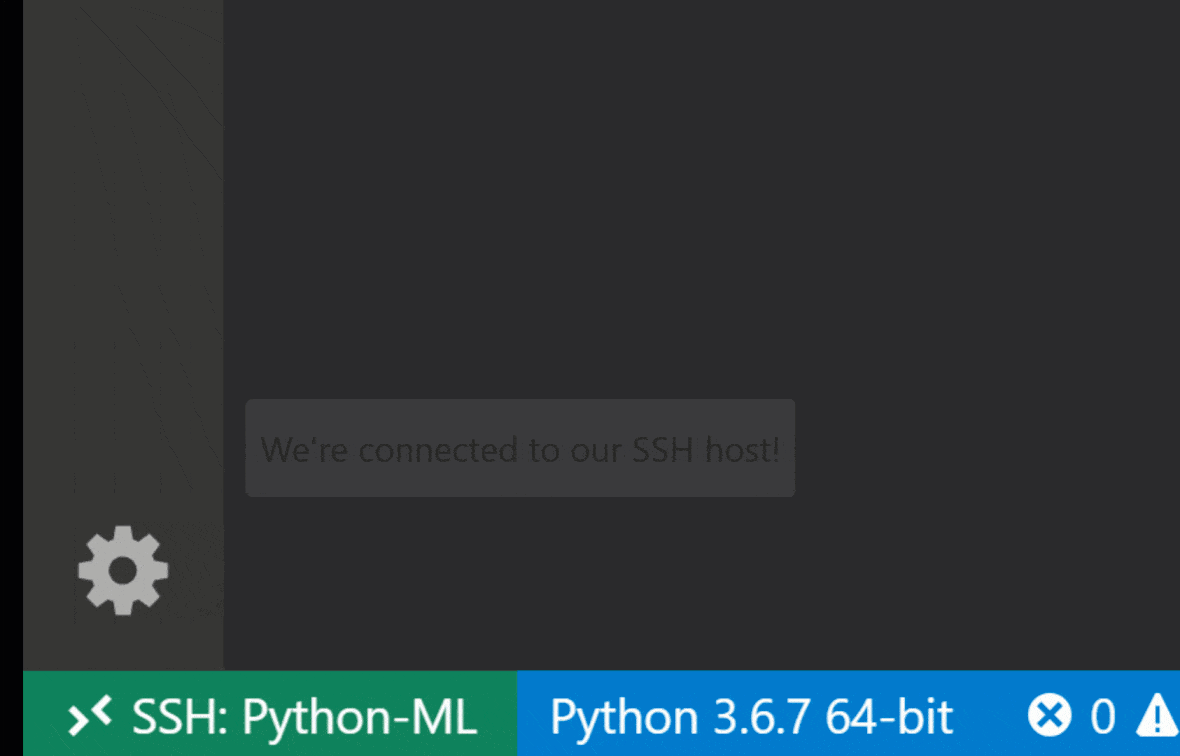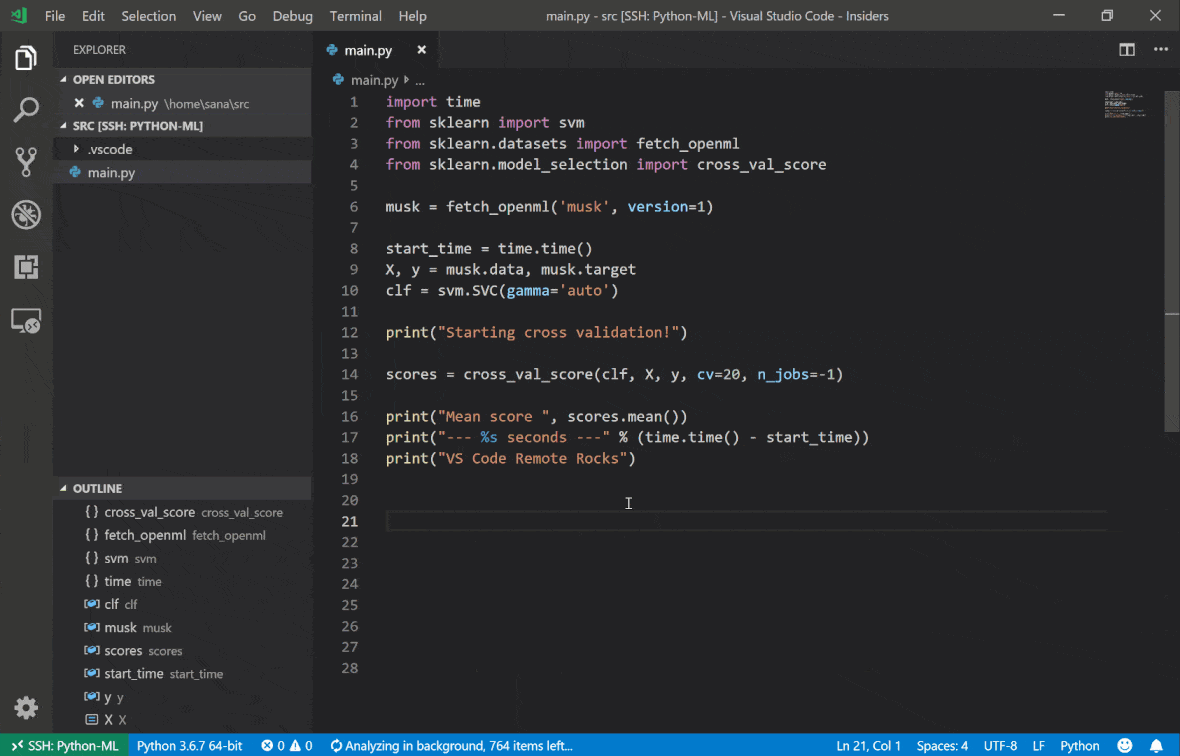
คุณสามารถค้นหาคุณสมบัติและข้อมูลเพิ่มเติมเกี่ยวกับส่วนขยาย SSH ระยะไกลในคู่มือนี้
Tensorboard จัดเตรียมชุดเครื่องมือสร้างภาพเพื่อให้เข้าใจดีบักและเพิ่มประสิทธิภาพการทดสอบของคุณให้เหมาะสม มันมีคุณสมบัติการบันทึกสำหรับสเกลาร์ฮิสโตแกรมโครงสร้างโมเดลฝังและการสร้างภาพข้อความและภาพ เวิร์กสเปซมาพร้อมกับส่วนขยาย Jupyter_Tensorboard ที่รวม Tensorboard เข้ากับอินเตอร์เฟส Jupyter พร้อมฟังก์ชันการทำงานเพื่อเริ่มจัดการและหยุดอินสแตนซ์ คุณสามารถเปิดอินสแตนซ์ใหม่สำหรับไดเรกทอรีบันทึกที่ถูกต้องดังที่แสดงด้านล่าง:
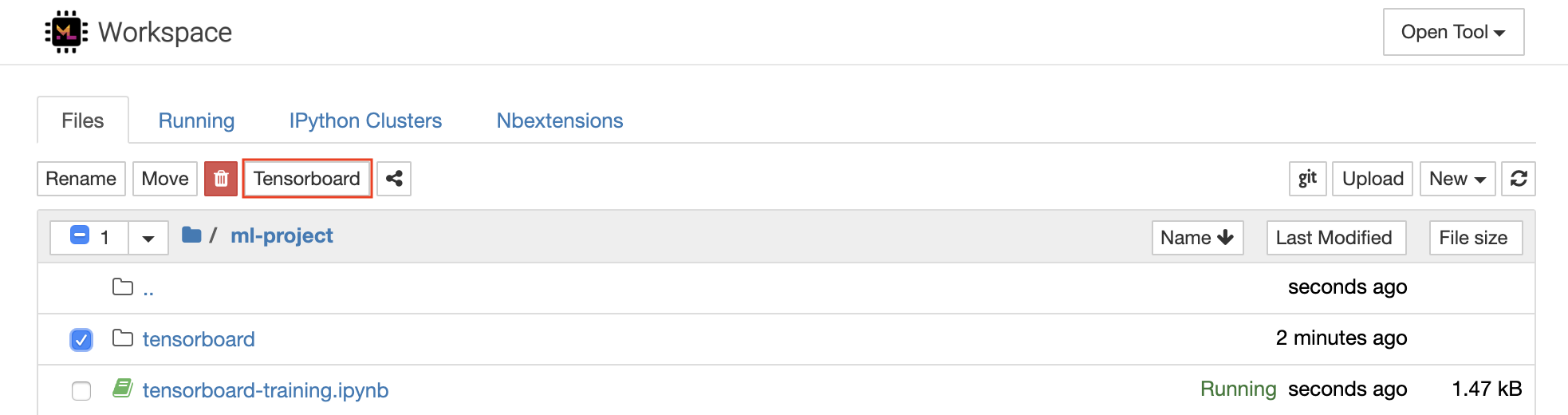
หากคุณเปิดอินสแตนซ์ Tensorboard ในไดเรกทอรีบันทึกที่ถูกต้องคุณจะเห็นการสร้างภาพข้อมูลของข้อมูลที่บันทึกไว้ของคุณ:
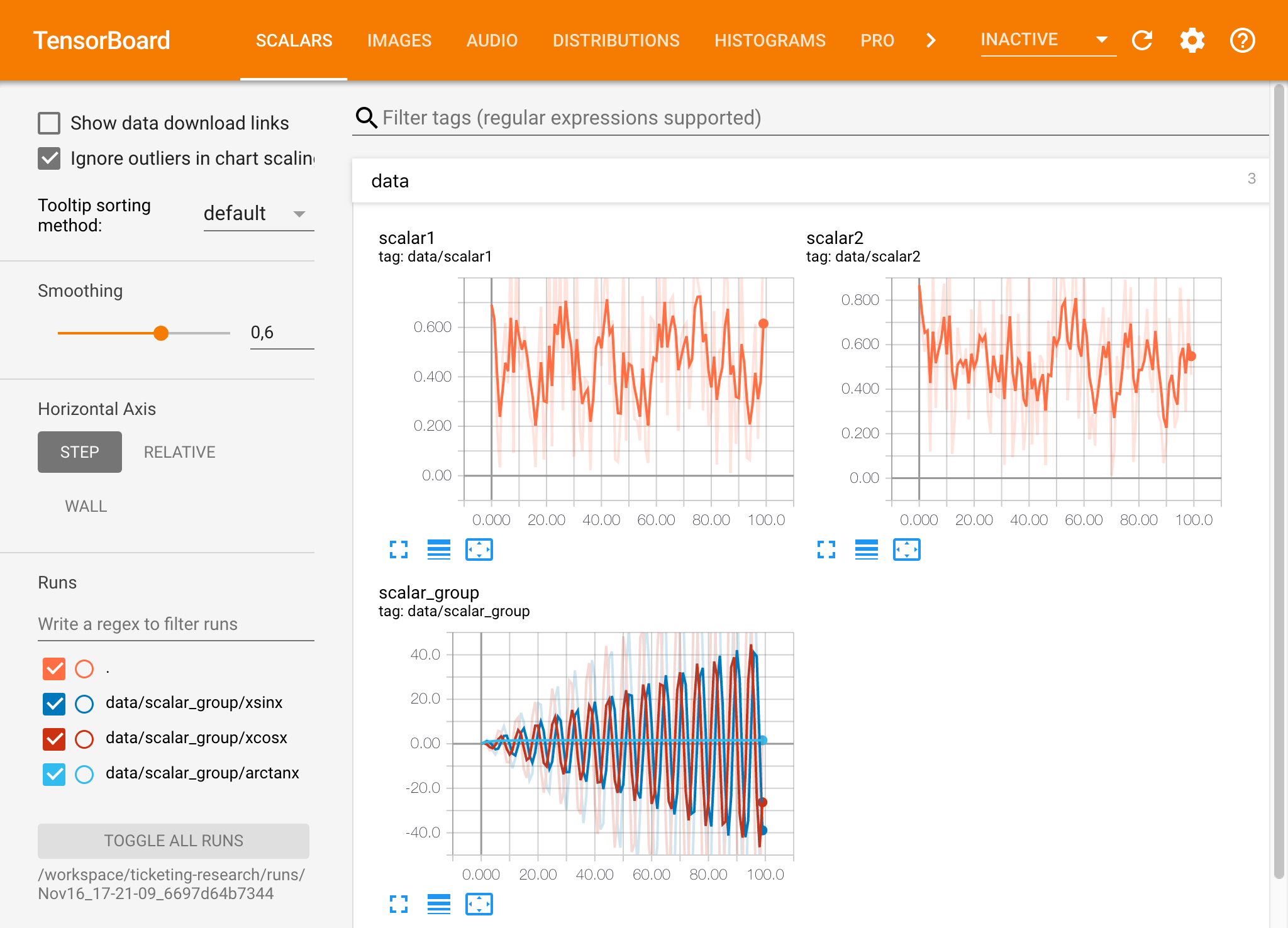
Tensorboard สามารถใช้ร่วมกับเฟรมเวิร์ก ML อื่น ๆ อีกมากมายนอกเหนือจาก TensorFlow โดยใช้ไลบรารี TensorBoardX คุณสามารถบันทึกโดยทั่วไปจากไลบรารีที่ใช้ Python นอกจากนี้ Pytorch ยังมีการรวม Tensorboard โดยตรงตามที่อธิบายไว้ที่นี่
หากคุณต้องการดู tensorboard โดยตรงภายในสมุดบันทึกของคุณคุณสามารถใช้ประโยชน์จาก Jupyter Magic :
%load_ext tensorboard
%tensorboard --logdir /workspace/path/to/logs
เวิร์กสเปซมีเครื่องมือบนเว็บที่ติดตั้งไว้ล่วงหน้าสองเครื่องมือเพื่อช่วยนักพัฒนาในระหว่างการฝึกอบรมแบบจำลองและงานการทดลองอื่น ๆ เพื่อรับข้อมูลเชิงลึกเกี่ยวกับทุกสิ่งที่เกิดขึ้นในระบบและหาปัญหาคอขวดประสิทธิภาพ
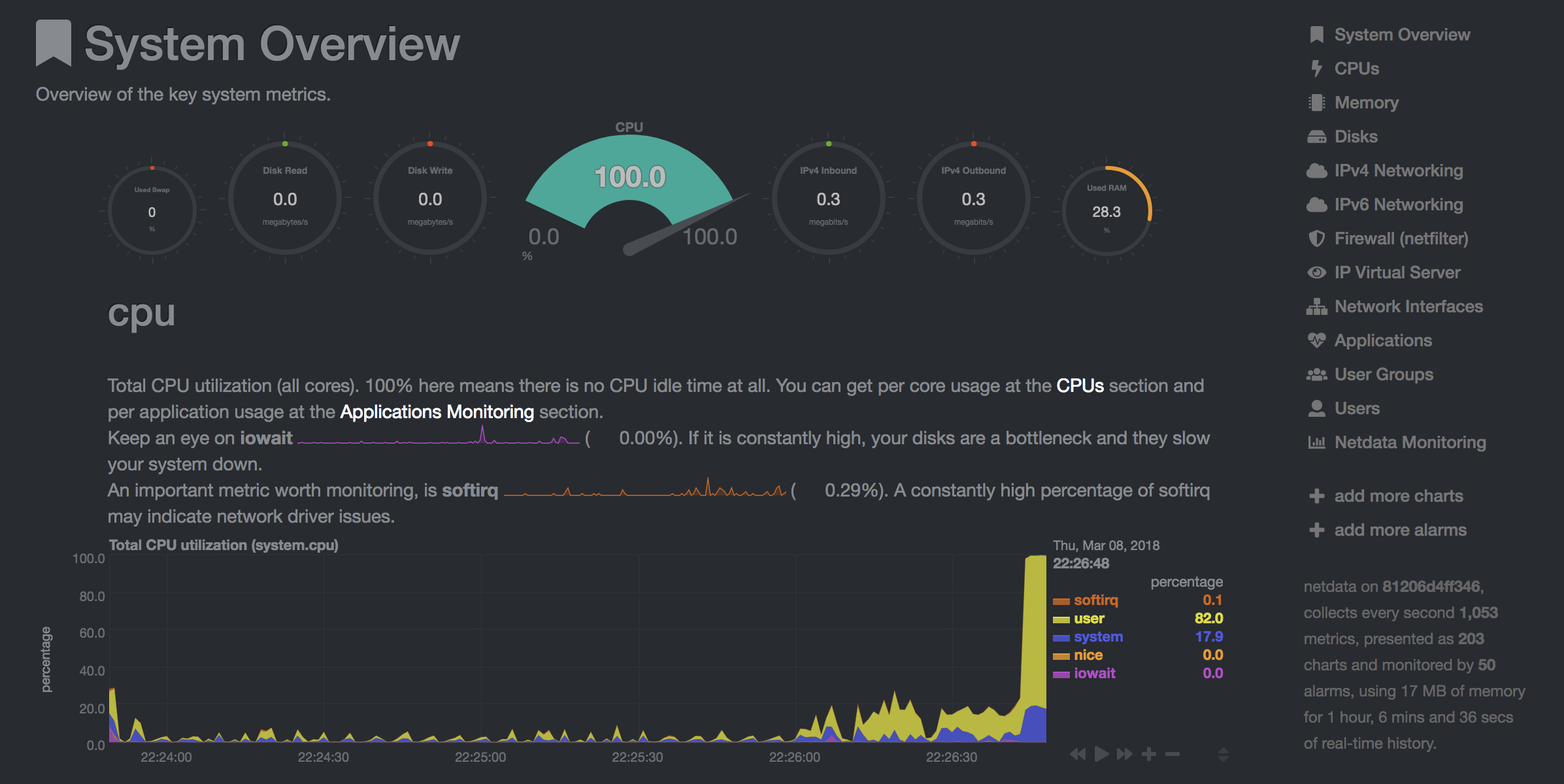
NetData ( Open Tool -> Netdata ) เป็นแผงควบคุมฮาร์ดแวร์และประสิทธิภาพการตรวจสอบประสิทธิภาพแบบเรียลไทม์ที่มองเห็นกระบวนการและบริการในระบบ Linux ของคุณ มันตรวจสอบตัวชี้วัดเกี่ยวกับ CPU, GPU, หน่วยความจำ, ดิสก์, เครือข่าย, กระบวนการและอื่น ๆ
GLANCES ( Open Tool -> Glances ) เป็นแผงควบคุมฮาร์ดแวร์บนเว็บและสามารถใช้เป็นทางเลือกแทน NetData
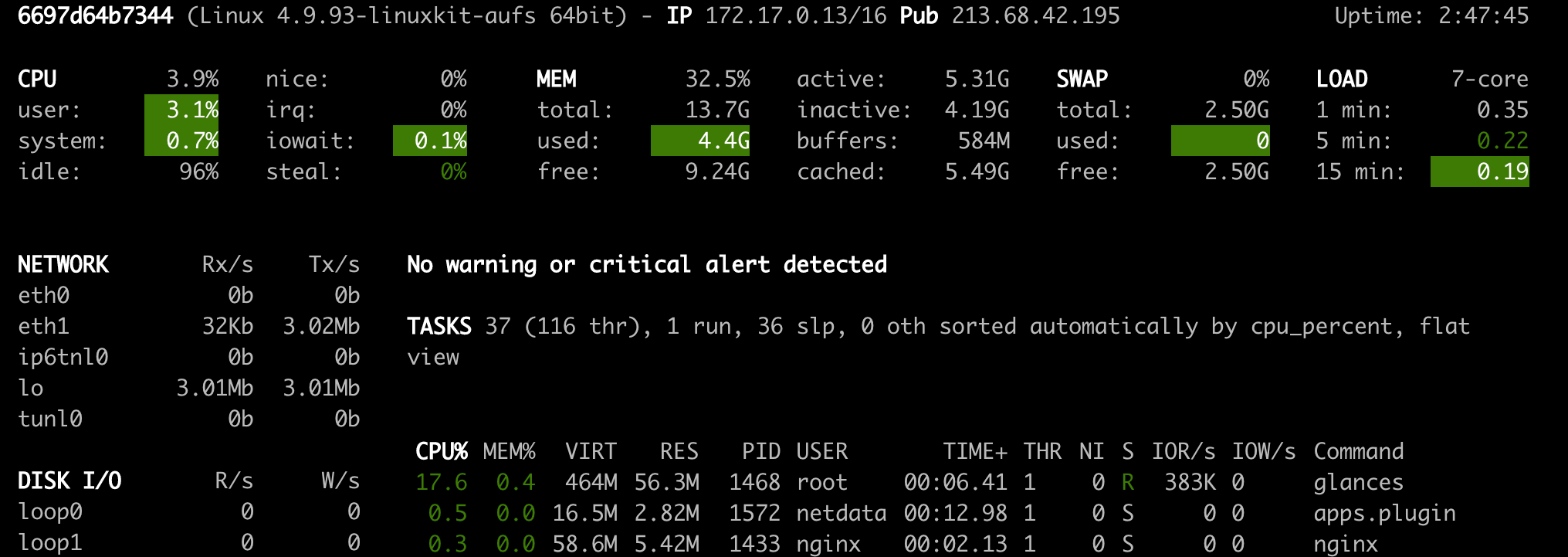
NetData และสายตาจะแสดงสถิติฮาร์ดแวร์สำหรับเครื่องทั้งหมดที่คอนเทนเนอร์ Workspace กำลังทำงานอยู่
งานถูกกำหนดให้เป็นงานการคำนวณใด ๆ ที่ทำงานในช่วงเวลาหนึ่งเพื่อให้เสร็จสมบูรณ์เช่นการฝึกอบรมแบบจำลองหรือไปป์ไลน์ข้อมูล
ภาพพื้นที่ทำงานยังสามารถใช้ในการเรียกใช้รหัส Python โดยพลการโดยไม่ต้องเริ่มเครื่องมือที่ติดตั้งไว้ล่วงหน้า This provides a seamless way to productize your ML projects since the code that has been developed interactively within the workspace will have the same environment and configuration when run as a job via the same workspace image.
To run Python code as a job, you need to provide a path or URL to a code directory (or script) via EXECUTE_CODE . The code can be either already mounted into the workspace container or downloaded from a version control system (eg, git or svn) as described in the following sections. The selected code path needs to be python executable. In case the selected code is a directory (eg, whenever you download the code from a VCS) you need to put a __main__.py file at the root of this directory. The __main__.py needs to contain the code that starts your job.
You can execute code directly from Git, Mercurial, Subversion, or Bazaar by using the pip-vcs format as described in this guide. For example, to execute code from a subdirectory of a git repository, just run:
docker run --env EXECUTE_CODE= " git+https://github.com/ml-tooling/ml-workspace.git#subdirectory=resources/tests/ml-job " mltooling/ml-workspace:0.13.2For additional information on how to specify branches, commits, or tags please refer to this guide.
In the following example, we mount and execute the current working directory (expected to contain our code) into the /workspace/ml-job/ directory of the workspace:
docker run -v " ${PWD} :/workspace/ml-job/ " --env EXECUTE_CODE= " /workspace/ml-job/ " mltooling/ml-workspace:0.13.2In the case that the pre-installed workspace libraries are not compatible with your code, you can install or change dependencies by just adding one or multiple of the following files to your code directory:
requirements.txt : pip requirements format for pip-installable dependencies.environment.yml : conda environment file to create a separate Python environment.setup.sh : A shell script executed via /bin/bash . The execution order is 1. environment.yml -> 2. setup.sh -> 3. requirements.txt
You can test your job code within the workspace (started normally with interactive tools) by executing the following python script:
python /resources/scripts/execute_code.py /path/to/your/jobIt is also possible to embed your code directly into a custom job image, as shown below:
FROM mltooling/ml-workspace:0.13.2
# Add job code to image
COPY ml-job /workspace/ml-job
ENV EXECUTE_CODE=/workspace/ml-job
# Install requirements only
RUN python /resources/scripts/execute_code.py --requirements-only
# Execute only the code at container startup
CMD [ "python" , "/resources/docker-entrypoint.py" , "--code-only" ]The workspace is pre-installed with many popular interpreters, data science libraries, and ubuntu packages:
conda , pip , apt-get , npm , yarn , sdk , poetry , gdebi ...The full list of installed tools can be found within the Dockerfile.
For every minor version release, we run vulnerability, virus, and security checks within the workspace using safety, clamav, trivy, and snyk via docker scan to make sure that the workspace environment is as secure as possible. We are committed to fix and prevent all high- or critical-severity vulnerabilities. You can find some up-to-date reports here.
The workspace provides a high degree of extensibility. Within the workspace, you have full root & sudo privileges to install any library or tool you need via terminal (eg, pip , apt-get , conda , or npm ). You can open a terminal by one of the following ways:
New -> TerminalApplications -> Terminal EmulatorFile -> New -> TerminalTerminal -> New Terminal Additionally, pre-installed tools such as Jupyter, JupyterLab, and Visual Studio Code each provide their own rich ecosystem of extensions. The workspace also contains a collection of installer scripts for many commonly used development tools or libraries (eg, PyCharm , Zeppelin , RStudio , Starspace ). You can find and execute all tool installers via Open Tool -> Install Tool . Those scripts can be also executed from the Desktop VNC (double-click on the script within the Tools folder on the Desktop VNC).
For example, to install the Apache Zeppelin notebook server, simply execute:
/resources/tools/zeppelin.sh --port=1234 After installation, refresh the Jupyter website and the Zeppelin tool will be available under Open Tool -> Zeppelin . Other tools might only be available within the Desktop VNC (eg, atom or pycharm ) or do not provide any UI (eg, starspace , docker-client ).
As an alternative to extending the workspace at runtime, you can also customize the workspace Docker image to create your own flavor as explained in the FAQ section.
The workspace can be extended in many ways at runtime, as explained here. However, if you like to customize the workspace image with your own software or configuration, you can do that via a Dockerfile as shown below:
# Extend from any of the workspace versions/flavors
FROM mltooling/ml-workspace:0.13.2
# Run you customizations, e.g.
RUN
# Install r-runtime, r-kernel, and r-studio web server from provided install scripts
/bin/bash $RESOURCES_PATH/tools/r-runtime.sh --install &&
/bin/bash $RESOURCES_PATH/tools/r-studio-server.sh --install &&
# Cleanup Layer - removes unneccessary cache files
clean-layer.shFinally, use docker build to build your customized Docker image.
For a more comprehensive Dockerfile example, take a look at the Dockerfile of the R-flavor.
To update a running workspace instance to a more recent version, the running Docker container needs to be replaced with a new container based on the updated workspace image.
All data within the workspace that is not persisted to a mounted volume will be lost during this update process. As mentioned in the persist data section, a volume is expected to be mounted into the /workspace folder. All tools within the workspace are configured to make use of the /workspace folder as the root directory for all source code and data artifacts. During an update, data within other directories will be removed, including installed/updated libraries or certain machine configurations. We have integrated a backup and restore feature ( CONFIG_BACKUP_ENABLED ) for various selected configuration files/folders, such as the user's Jupyter/VS-Code configuration, ~/.gitconfig , and ~/.ssh .
If the workspace is deployed via Docker (Kubernetes will have a different update process), you need to remove the existing container (via docker rm ) and start a new one (via docker run ) with the newer workspace image. Make sure to use the same configuration, volume, name, and port. For example, a workspace (image version 0.8.7 ) was started with this command:
docker run -d
-p 8080:8080
--name "ml-workspace"
-v "/path/on/host:/workspace"
--env AUTHENTICATE_VIA_JUPYTER="mytoken"
--restart always
mltooling/ml-workspace:0.8.7
and needs to be updated to version 0.9.1 , you need to:
docker stop "ml-workspace" && docker rm "ml-workspace"docker run -d -p 8080:8080 --name "ml-workspace" -v "/path/on/host:/workspace" --env AUTHENTICATE_VIA_JUPYTER="mytoken" --restart always mltooling/ml-workspace:0.9.1 If you want to directly connect to the workspace via a VNC client (not using the noVNC webapp), you might be interested in changing certain VNC server configurations. To configure the VNC server, you can provide/overwrite the following environment variables at container start (via docker run option: --env ):
| ตัวแปร | คำอธิบาย | ค่าเริ่มต้น |
|---|---|---|
| VNC_PW | Password of VNC connection. This password only needs to be secure if the VNC server is directly exposed. If it is used via noVNC, it is already protected based on the configured authentication mechanism. | vncpassword |
| VNC_RESOLUTION | Default desktop resolution of VNC connection. When using noVNC, the resolution will be dynamically adapted to the window size. | 1600x900 |
| VNC_COL_DEPTH | Default color depth of VNC connection. | 24 |
Unfortunately, we currently do not support using a non-root user within the workspace. We plan to provide this capability and already started with some refactoring to allow this configuration. However, this still requires a lot more work, refactoring, and testing from our side.
Using root-user (or users with sudo permission) within containers is generally not recommended since, in case of system/kernel vulnerabilities, a user might be able to break out of the container and be able to access the host system. Since it is not very common to have such problematic kernel vulnerabilities, the risk of a severe attack is quite minimal. As explained in the official Docker documentation, containers (even with root users) are generally quite secure in preventing a breakout to the host. And compared to many other container use-cases, we actually want to provide the flexibility to the user to have control and system-level installation permissions within the workspace container.
The workspace comes preinstalled with various common tools to create isolated Python environments (virtual environments). The following sections provide a quick-intro on how to use these tools within the workspace. You can find information on when to use which tool here. Please refer to the documentation of the given tool for additional usage information.
venv (recommended):
To create a virtual environment via venv, execute the following commands:
# Create environment in the working directory
python -m venv my-venv
# Activate environment in shell
source ./my-venv/bin/activate
# Optional: Create Jupyter kernel for this environment
pip install ipykernel
python -m ipykernel install --user --name=my-venv --display-name= " my-venv ( $( python --version ) ) "
# Optional: Close enviornment session
deactivatepipenv (recommended):
To create a virtual environment via pipenv, execute the following commands:
# Create environment in the working directory
pipenv install
# Activate environment session in shell
pipenv shell
# Optional: Create Jupyter kernel for this environment
pipenv install ipykernel
python -m ipykernel install --user --name=my-pipenv --display-name= " my-pipenv ( $( python --version ) ) "
# Optional: Close environment session
exitvirtualenv :
To create a virtual environment via virtualenv, execute the following commands:
# Create environment in the working directory
virtualenv my-virtualenv
# Activate environment session in shell
source ./my-virtualenv/bin/activate
# Optional: Create Jupyter kernel for this environment
pip install ipykernel
python -m ipykernel install --user --name=my-virtualenv --display-name= " my-virtualenv ( $( python --version ) ) "
# Optional: Close environment session
deactivateconda :
To create a virtual environment via conda, execute the following commands:
# Create environment (globally)
conda create -n my-conda-env
# Activate environment session in shell
conda activate my-conda-env
# Optional: Create Jupyter kernel for this environment
python -m ipykernel install --user --name=my-conda-env --display-name= " my-conda-env ( $( python --version ) ) "
# Optional: Close environment session
conda deactivateTip: Shell Commands in Jupyter Notebooks:
If you install and use a virtual environment via a dedicated Jupyter Kernel and use shell commands within Jupyter (eg !pip install matplotlib ), the wrong python/pip version will be used. To use the python/pip version of the selected kernel, do the following instead:
import sys
!{ sys . executable } - m pip install matplotlibThe workspace provides three easy options to install different Python versions alongside the main Python instance: pyenv, pipenv (recommended), conda.
pipenv (recommended):
To install a different python version (eg 3.7.8 ) within the workspace via pipenv, execute the following commands:
# Install python vers
pipenv install --python=3.7.8
# Activate environment session in shell
pipenv shell
# Check python installation
python --version
# Optional: Create Jupyter kernel for this environment
pipenv install ipykernel
python -m ipykernel install --user --name=my-pipenv --display-name= " my-pipenv ( $( python --version ) ) "
# Optional: Close environment session
exitpyenv :
To install a different python version (eg 3.7.8 ) within the workspace via pyenv, execute the following commands:
# Install python version
pyenv install 3.7.8
# Make globally accessible
pyenv global 3.7.8
# Activate python version in shell
pyenv shell 3.7.8
# Check python installation
python3.7 --version
# Optional: Create Jupyter kernel for this python version
python3.7 -m pip install ipykernel
python3.7 -m ipykernel install --user --name=my-pyenv-3.7.8 --display-name= " my-pyenv (Python 3.7.8) "conda :
To install a different python version (eg 3.7.8 ) within the workspace via conda, execute the following commands:
# Create environment with python version
conda create -n my-conda-3.7 python=3.7.8
# Activate environment session in shell
conda activate my-conda-3.7
# Check python installation
python --version
# Optional: Create Jupyter kernel for this python version
pip install ipykernel
python -m ipykernel install --user --name=my-conda-3.7 --display-name= " my-conda ( $( python --version ) ) "
# Optional: Close environment session
conda deactivateTip: Shell Commands in Jupyter Notebooks:
If you install and use another Python version via a dedicated Jupyter Kernel and use shell commands within Jupyter (eg !pip install matplotlib ), the wrong python/pip version will be used. To use the python/pip version of the selected kernel, do the following instead:
import sys
!{ sys . executable } - m pip install matplotlib Certain desktop tools (eg, recent versions of Firefox) or libraries (eg, Pytorch - see Issues: 1, 2) might crash if the shared memory size ( /dev/shm ) is too small. The default shared memory size of Docker is 64MB, which might not be enough for a few tools. You can provide a higher shared memory size via the shm-size docker run option:
docker run --shm-size=2G mltooling/ml-workspace:0.13.2 In general, the performance of running code within Docker is nearly identical compared to running it directly on the machine. However, in case you have limited the container's CPU quota (as explained in this section), the container can still see the full count of CPU cores available on the machine and there is no technical way to prevent this. Many libraries and tools will use the full CPU count (eg, via os.cpu_count() ) to set the number of threads used for multiprocessing/-threading. This might cause the program to start more threads/processes than it can efficiently handle with the available CPU quota, which can tremendously slow down the overall performance. Therefore, it is important to set the available CPU count or the maximum number of threads explicitly to the configured CPU quota. The workspace provides capabilities to detect the number of available CPUs automatically, which are used to configure a variety of common libraries via environment variables such as OMP_NUM_THREADS or MKL_NUM_THREADS . It is also possible to explicitly set the number of available CPUs at container startup via the MAX_NUM_THREADS environment variable (see configuration section). The same environment variable can also be used to get the number of available CPUs at runtime.
Even though the automatic configuration capabilities of the workspace will fix a variety of inefficiencies, we still recommend configuring the number of available CPUs with all libraries explicitly. ตัวอย่างเช่น:
import os
MAX_NUM_THREADS = int ( os . getenv ( "MAX_NUM_THREADS" ))
# Set in pytorch
import torch
torch . set_num_threads ( MAX_NUM_THREADS )
# Set in tensorflow
import tensorflow as tf
config = tf . ConfigProto (
device_count = { "CPU" : MAX_NUM_THREADS },
inter_op_parallelism_threads = MAX_NUM_THREADS ,
intra_op_parallelism_threads = MAX_NUM_THREADS ,
)
tf_session = tf . Session ( config = config )
# Set session for keras
import keras . backend as K
K . set_session ( tf_session )
# Set in sklearn estimator
from sklearn . linear_model import LogisticRegression
LogisticRegression ( n_jobs = MAX_NUM_THREADS ). fit ( X , y )
# Set for multiprocessing pool
from multiprocessing import Pool
with Pool ( MAX_NUM_THREADS ) as pool :
results = pool . map ( lst )If you encounter the following error within the container logs when starting the workspace, it will most likely not be possible to run the workspace on your hardware:
exited: nginx (terminated by SIGILL (core dumped); not expected)
The OpenResty/Nginx binary package used within the workspace requires to run on a CPU with SSE4.2 support (see this issue). Unfortunately, some older CPUs do not have support for SSE4.2 and, therefore, will not be able to run the workspace container. On Linux, you can check if your CPU supports SSE4.2 when looking into the cat /proc/cpuinfo flags section. If you encounter this problem, feel free to notify us by commenting on the following issue: #30.
Requirements : Docker and Act are required to be installed on your machine to execute the build process.
To simplify the process of building this project from scratch, we provide build-scripts - based on universal-build - that run all necessary steps (build, test, and release) within a containerized environment. To build and test your changes, execute the following command in the project root folder:
act -b -j buildUnder the hood it uses the build.py files in this repo based on the universal-build library. So, if you want to build it locally, you can also execute this command in the project root folder to build the docker container:
python build.py --makeFor additional script options:
python build.py --helpRefer to our contribution guides for more detailed information on our build scripts and development process.
Licensed Apache 2.0 . Created and maintained with ❤️ by developers from Berlin.


