ml workspace
0.13.2

Entorno de desarrollo basado en la web todo en uno para el aprendizaje automático
Introducción • Características y capturas de pantalla • Soporte • Informe un error • Preguntas frecuentes • Problemas conocidos • Contribución
El espacio de trabajo ML es un IDE basado en la web todo en uno especializado para aprendizaje automático y ciencia de datos. Es fácil de implementar y lo hace comenzar en cuestión de minutos para construir soluciones ML productivas en sus propias máquinas. Este espacio de trabajo es la herramienta definitiva para los desarrolladores precargados con una variedad de bibliotecas populares de ciencia de datos (por ejemplo, TensorFlow, Pytorch, Keras, Sklearn) y herramientas de desarrollo (EG, Jupyter, VS Code, Tensorboard) perfectamente configuradas, optimizadas e integradas.
El espacio de trabajo requiere que Docker se instale en su máquina (Guía de instalación).
Implementar una sola instancia de espacio de trabajo es tan simple como:
docker run -p 8080:8080 mltooling/ml-workspace:0.13.2Voilà, eso fue fácil! Ahora, Docker atraerá la última imagen del espacio de trabajo a su máquina. Esto puede tomar unos minutos, dependiendo de su velocidad de Internet. Una vez que se inicia el espacio de trabajo, puede acceder a él a través de http: // localhost: 8080.
Si se inicia en otra máquina o con un puerto diferente, asegúrese de usar el IP/DNS de la máquina y/o el puerto expuesto.
Para implementar una sola instancia para un uso productivo, recomendamos aplicar al menos las siguientes opciones:
docker run -d
-p 8080:8080
--name " ml-workspace "
-v " ${PWD} :/workspace "
--env AUTHENTICATE_VIA_JUPYTER= " mytoken "
--shm-size 512m
--restart always
mltooling/ml-workspace:0.13.2 Este comando ejecuta el contenedor en segundo plano ( -d ), monta su directorio de trabajo actual en la carpeta /workspace ( -v ), asegura el espacio de trabajo a través de un token proporcionado ( --env AUTHENTICATE_VIA_JUPYTER ), proporciona 512MB de memoria compartida ( --shm-size ) para evitar que los bloqueos inesperados (ver la sección de problemas conocidos) y mantenga el contenedor que se ejecuta incluso en los --restart always del sistema ( - - - - - - - - - - - - - - - - - - - - - - - - -) Puede encontrar opciones adicionales para la ejecución de Docker aquí y las opciones de configuración del espacio de trabajo en la sección a continuación.
El espacio de trabajo proporciona una variedad de opciones de configuración que se pueden utilizar configurando variables de entorno (a través de la opción de ejecución de Docker: --env ).
| Variable | Descripción | Por defecto |
|---|---|---|
| Workspace_base_url | La URL base bajo la cual Jupyter y todas las demás herramientas serán alcanzables. | / |
| Workspace_ssl_enabled | Habilitar o deshabilitar SSL. Cuando se establece en True, cualquiera de los certificados (cert.crt) debe montarse en /resources/ssl o, si no, el contenedor genera certificado autofirmado. | FALSO |
| Espacio de trabajo_auth_user | Nombre de usuario de autenticación básica. Para habilitar la autenticación básica, tanto el usuario como la contraseña deben establecerse. Recomendamos usar el AUTHENTICATE_VIA_JUPYTER para asegurar el espacio de trabajo. | |
| Workspace_auth_password | Contraseña de usuario de autenticación básica. Para habilitar la autenticación básica, tanto el usuario como la contraseña deben establecerse. Recomendamos usar el AUTHENTICATE_VIA_JUPYTER para asegurar el espacio de trabajo. | |
| Space_port | Configura el puerto interno principal del contenedor del proxy del espacio de trabajo. Para la mayoría de los escenarios, esta configuración no debe cambiarse, y la configuración del puerto a través de Docker debe usarse en lugar del espacio de trabajo debe ser accesible desde un puerto diferente. | 8080 |
| Config_backup_enabled | Compensar y restaurar automáticamente la configuración del usuario en la carpeta persistida /workspace , como .SSH, .Jupyter o .gitConfig desde el directorio de inicio de los usuarios. | verdadero |
| Shared_links_enabled | Habilitar o deshabilitar la capacidad de compartir recursos a través de enlaces externos. Esto se utiliza para habilitar el intercambio de archivos, el acceso a los puertos de espacio de trabajo interno y una fácil configuración de SSH basada en comandos. Todos los enlaces compartidos están protegidos a través de un token. Sin embargo, existen ciertos riesgos ya que el token no se puede invalidar fácilmente después de compartir y no expira. | verdadero |
| Incluir_tutorials | Si es true , se agregan una selección de cuadernos de tutoriales e introducción a la carpeta /workspace al inicio del contenedor, pero solo si la carpeta está vacía. | verdadero |
| Max_num_threads | El número de subprocesos utilizados para los cálculos cuando se usan varias bibliotecas comunes (MKL, Openblas, OMP, numba, ...). También puede usar auto para permitir que el espacio de trabajo determine dinámicamente el número de subprocesos en función de los recursos de CPU disponibles. El usuario puede sobrescribir esta configuración desde el espacio de trabajo. En general, es bueno configurarlo en o por debajo del número de CPU disponibles para el espacio de trabajo. | auto |
| Configuración de Jupyter: | ||
| Shutdown_inactive_kernels | Apague automáticamente los núcleos inactivos después de un tiempo de espera dado (para limpiar la memoria o los recursos de GPU). El valor puede ser un tiempo de espera en segundos o establecerse en true con un valor predeterminado de 48H. | FALSO |
| Autenticate_via_jupyter | Si true , todas las solicitudes HTTP se autenticarán en el servidor Jupyter, lo que significa que el método de autenticación configurado con Jupyter también se utilizará para todas las demás herramientas. Esto se puede desactivar con false . Cualquier otro valor activará esta autenticación y se aplicará como token a través de la configuración de Notebook.Token de Jupyter. | FALSO |
| Cuaderno_args | Agregue y sobrescriba las opciones de configuración de Jupyter a través de Args de línea de comandos. Consulte esta descripción general para todas las opciones. | |
Para persistir los datos, debe montar un volumen en /workspace (a través de la opción de ejecución de Docker: -v ).
El directorio de trabajo predeterminado dentro del contenedor es /workspace , que también es el directorio raíz de la instancia de Jupyter. El directorio /workspace está destinado a ser utilizado para todos los artefactos laborales importantes. Los datos dentro de otros directorios del servidor (por ejemplo, /root ) pueden perderse en los reinicios del contenedor.
Recomendamos encarecidamente habilitar la autenticación a través de una de las siguientes dos opciones. Para ambas opciones, el usuario deberá autenticarse para acceder a cualquiera de las herramientas preinstaladas.
La autenticación solo funciona para todas las herramientas a los que se accede a través del puerto del espacio de trabajo principal (predeterminado:
8080). Esto funciona para todas las herramientas preinstaladas y la función de puertos de acceso. Si expone otro puerto del contenedor, ¡asegúrese de asegurarlo también con autenticación!
Active la autenticación basada en token basada en la implementación de autenticación de Jupyter a través de la variable AUTHENTICATE_VIA_JUPYTER :
docker run -p 8080:8080 --env AUTHENTICATE_VIA_JUPYTER= " mytoken " mltooling/ml-workspace:0.13.2 También puede usar <generated> para dejar que Jupyter genere un token aleatorio que se imprime en los registros de contenedores. Un valor de true no establecerá ningún token, sino que activará que cada solicitud a cualquier herramienta en el espacio de trabajo se verificará con la instancia de Jupyter si el usuario está autenticado. Esto se utiliza para herramientas como Jupyterhub, que configura su propia forma de autenticación.
Active la autenticación básica a través de la variable WORKSPACE_AUTH_USER y WORKSPACE_AUTH_PASSWORD :
docker run -p 8080:8080 --env WORKSPACE_AUTH_USER= " user " --env WORKSPACE_AUTH_PASSWORD= " pwd " mltooling/ml-workspace:0.13.2 La autenticación básica se configura a través del proxy NGINX y puede ser más desempeñante en comparación con la otra opción, ya que con AUTHENTICATE_VIA_JUPYTER cada solicitud a cualquier herramienta en el espacio de trabajo verificará a través de la instancia de Jupyter si el usuario (basado en las cookies de solicitudes) se autentica.
Recomendamos habilitar SSL para que el espacio de trabajo sea accesible a través de HTTPS (comunicación cifrada). El cifrado SSL se puede activar a través de la variable WORKSPACE_SSL_ENABLED .
Cuando se establece en true , el archivo cert.crt y cert.key debe montarse a /resources/ssl o, si los archivos de certificado no existen, el contenedor genera certificados autofirmados. Por ejemplo, si la /path/with/certificate/files en el sistema local contiene un certificado válido para el dominio del host ( cert.crt y cert.key archivo), se puede usar desde el espacio de trabajo como se muestra a continuación:
docker run
-p 8080:8080
--env WORKSPACE_SSL_ENABLED= " true "
-v /path/with/certificate/files:/resources/ssl:ro
mltooling/ml-workspace:0.13.2 Si desea alojar el espacio de trabajo en un dominio público, le recomendamos usar Let's Encrypt para obtener un certificado de confianza para su dominio. Para usar el certificado generado (por ejemplo, a través de la herramienta CERTBOT) para el espacio de trabajo, el privkey.pem corresponde al archivo cert.key y el fullchain.pem al archivo cert.crt .
Cuando habilita el soporte SSL, debe acceder al espacio de trabajo a través de
https://, no sobrehttp://.
De manera predeterminada, el contenedor de espacio de trabajo no tiene restricciones de recursos y puede usar tanto un recurso determinado como lo permita el planificador del núcleo del host. Docker proporciona formas de controlar la cantidad de memoria o CPU que puede usar un contenedor, configurando los indicadores de configuración de tiempo de ejecución del comando Docker Ejecutar.
El espacio de trabajo requiere al menos 2 CPU y 500 MB para ejecutar estable y ser utilizable.
Por ejemplo, el siguiente comando restringe el espacio de trabajo para usar solo un máximo de 8 CPU, 16 GB de memoria y 1 GB de memoria compartida (ver problemas conocidos):
docker run -p 8080:8080 --cpus=8 --memory=16g --shm-size=1G mltooling/ml-workspace:0.13.2Para obtener más opciones y documentación sobre restricciones de recursos, consulte la Guía oficial de Docker.
Si se requiere un proxy, puede pasar la configuración de proxy a través de las variables de entorno HTTP_PROXY , HTTPS_PROXY y NO_PROXY .
Además de la imagen principal del espacio de trabajo ( mltooling/ml-workspace ), proporcionamos otros sabores de imagen que extienden las características o minimizan el tamaño de la imagen para admitir una variedad de casos de uso.
El sabor mínimo ( mltooling/ml-workspace-minimal ) es nuestra imagen más pequeña que contiene la mayoría de las herramientas y características descritas en la sección de características sin la mayoría de las bibliotecas de Python que están preinstaladas en nuestra imagen principal. Cualquier biblioteca de Python o herramienta excluida se puede instalar manualmente durante el tiempo de ejecución por el usuario.
docker run -p 8080:8080 mltooling/ml-workspace-minimal:0.13.2 El sabor R ( mltooling/ml-workspace-r ) se basa en nuestra imagen predeterminada del espacio de trabajo y lo extiende con el interprendedor R, el kernel R-Jupyter, el servidor rstudio (acceso a través de Open Tool -> RStudio ), y una variedad de paquetes populares del ecosistema R.
docker run -p 8080:8080 mltooling/ml-workspace-r:0.12.1 El sabor de chispa ( mltooling/ml-workspace-spark ) se basa en nuestra imagen del espacio de trabajo R-sabor y lo extiende con el tiempo de ejecución de Spark, Spark-Jupyter Kernel, Zeppelin Notebook (Acceso a través de Open Tool -> Zeppelin ), Pyspark, Hadoop, Java Kernel y algunas pocas extensiones de bibliotecas adicionales.
docker run -p 8080:8080 mltooling/ml-workspace-spark:0.12.1Actualmente, el sabor GPU solo admite CUDA 11.2. El apoyo a otras versiones CUDA podría agregarse en el futuro.
El sabor GPU ( mltooling/ml-workspace-gpu ) se basa en nuestra imagen de espacio de trabajo predeterminada y la extiende con CUDA 10.1 y versiones listas para GPU de varias bibliotecas de aprendizaje automático (por ejemplo, TensorFlow, Pytorch, CNTK, Jax). Esta imagen de GPU tiene los siguientes requisitos adicionales para el sistema:
>=460.32.03 (Instrucciones).docker run -p 8080:8080 --gpus all mltooling/ml-workspace-gpu:0.13.2docker run -p 8080:8080 --runtime nvidia --env NVIDIA_VISIBLE_DEVICES= " all " mltooling/ml-workspace-gpu:0.13.2El sabor de GPU también viene con algunas opciones de configuración adicionales, como se explica a continuación:
| Variable | Descripción | Por defecto |
|---|---|---|
| Nvidia_visible_devices | Controles a qué GPU se puede acceder dentro del espacio de trabajo. Por defecto, se pueden acceder a todas las GPU del host dentro del espacio de trabajo. Puede usar all , none o especificar una lista separada por comas de ID de dispositivo (por ejemplo, 0,1 ). Puede encontrar la lista de ID de dispositivo disponibles ejecutando nvidia-smi en la máquina host. | todo |
| Cuda_visible_devices | Controlas qué aplicaciones GPU CUDA que se ejecutan dentro del espacio de trabajo verán. Por defecto, todas las GPU a las que el espacio de trabajo tiene acceso será visible. Para restringir las aplicaciones, proporcione una lista separada por comas de ID de dispositivo interno (por ejemplo, 0,2 ) basado en los dispositivos disponibles dentro del espacio de trabajo (ejecute nvidia-smi ). En comparación con NVIDIA_VISIBLE_DEVICES , el usuario del espacio de trabajo aún podrá acceder a otras GPU sobrescribiendo esta configuración desde el espacio de trabajo. | |
| Tf_force_gpu_allow_growth | Por defecto, la mayoría de la memoria de GPU se asignará mediante la primera ejecución de un gráfico TensorFlow. Si bien este comportamiento puede ser deseable para las tuberías de producción, es menos deseable para el uso interactivo. Use true para habilitar la asignación de memoria dinámica de GPU o false para instruir a TensorFlow para asignar toda la memoria en la ejecución. | verdadero |
El espacio de trabajo está diseñado como un entorno de desarrollo de un solo usuario. Para una configuración de usuarios múltiples, recomendamos implementar? Ml Hub. ML Hub se basa en Jupyterhub con la tarea de generar, administrar y proxy Workspace instancias para múltiples usuarios.
ML Hub facilita la configuración de un entorno de usuarios múltiples en un solo servidor (a través de Docker) o un clúster (a través de Kubernetes) y admite una variedad de escenarios de uso y proveedores de autenticación. Puedes probar ML Hub a través de:
docker run -p 8080:8080 -v /var/run/docker.sock:/var/run/docker.sock mltooling/ml-hub:latestPara obtener más información y documentación sobre ML Hub, eche un vistazo al sitio de GitHub.
Este proyecto es mantenido por Benjamin Räthlein, Lukas Masuch y Jan Kalkan. Comprenda que no podremos proporcionar soporte individual por correo electrónico. También creemos que la ayuda es mucho más valiosa si se comparte públicamente para que más personas puedan beneficiarse de ella.
| Tipo | Canal |
|---|---|
| Informes de errores | |
| ? Solicitudes de funciones | |
| ? Preguntas de uso | |
| ? Anuncios | |
| ❓ Otras solicitudes |
Jupyter • GUI de escritorio • VS Código • Jupyterlab • Integración de GIT • Compartir archivos • Puertos de acceso • Tensorboard • Extensibilidad • Monitoreo de hardware • Acceso a SSH • Desarrollo remoto • Ejecución de trabajo
El espacio de trabajo está equipado con una selección de las mejores herramientas de desarrollo de código abierto para ayudar con el flujo de trabajo de aprendizaje automático. Muchas de estas herramientas se pueden iniciar desde el menú Open Tool desde Jupyter (la aplicación principal del espacio de trabajo):
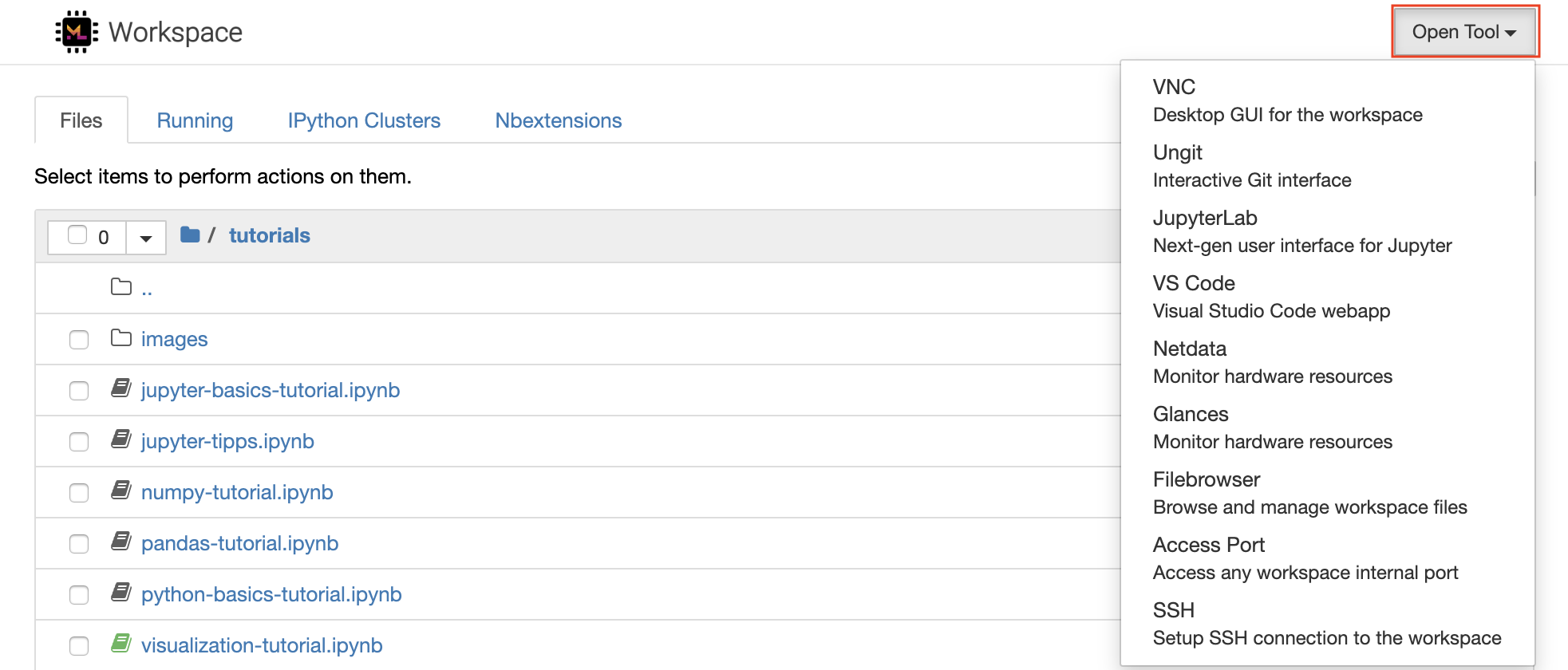
Dentro de su espacio de trabajo, tiene privilegios completos de root y sudo para instalar cualquier biblioteca o herramienta que necesita a través de Terminal (por ejemplo,
pip,apt-get,condaonpm). Puede encontrar más formas de extender el espacio de trabajo dentro de la sección de extensibilidad
Jupyter Notebook es un entorno interactivo basado en la web para escribir y ejecutar código. Los principales bloques de construcción de Jupyter son el navegador de archivos, el editor del cuaderno y los núcleos. El navegador de archivos proporciona un administrador de archivos interactivo para todos los cuadernos, archivos y carpetas en el directorio /workspace .
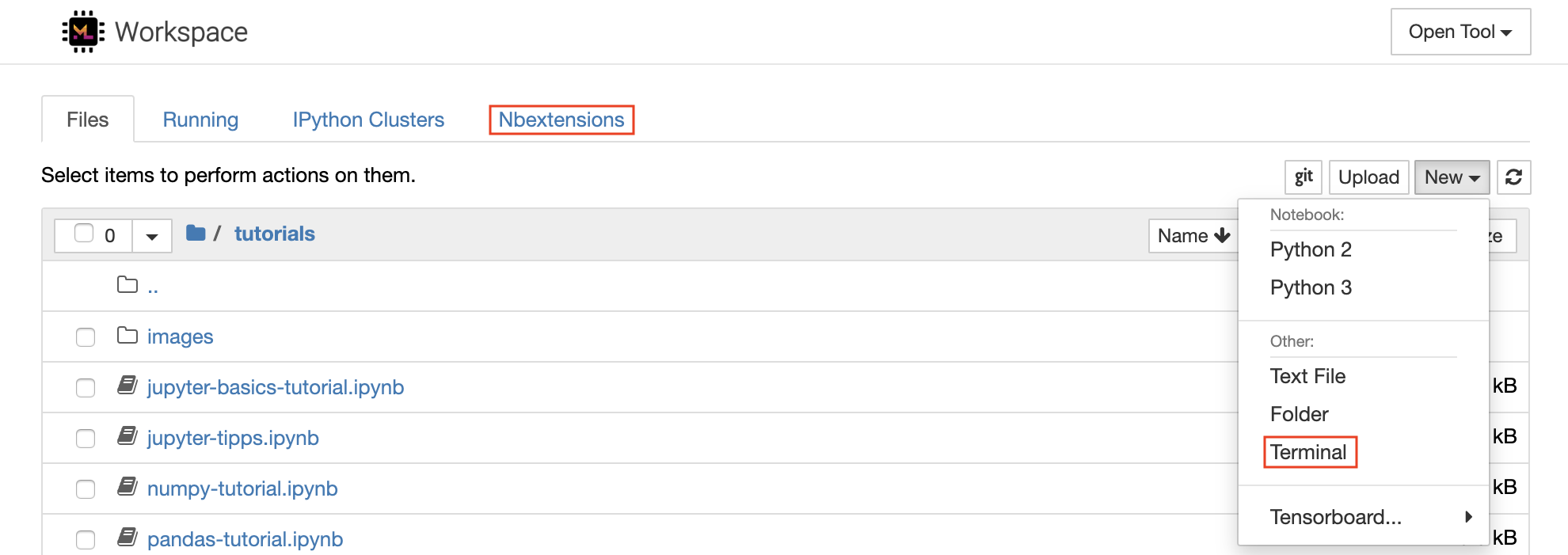
Se puede crear un nuevo cuaderno haciendo clic en el New botón desplegable en la parte superior de la lista y seleccionando el núcleo de idioma deseado.
También puede generar instancias terminales interactivas seleccionando
New -> Terminalen el navegador de archivos.
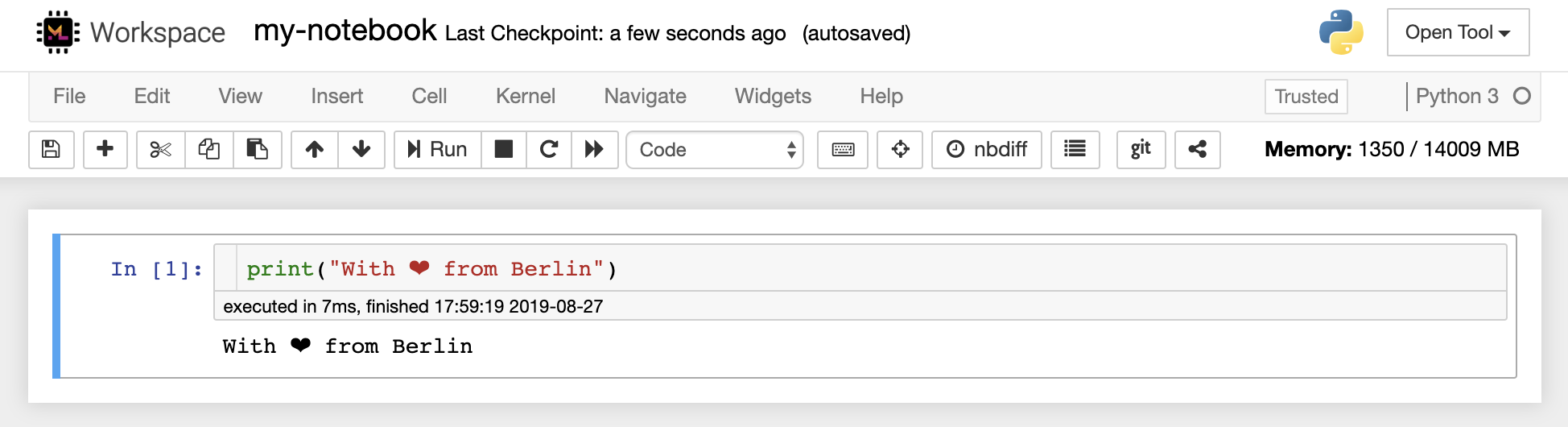
El editor del cuaderno permite a los usuarios documentos de autor que incluyen código en vivo, texto Markdown, comandos de shell, ecuaciones de látex, widgets interactivos, tramas e imágenes. Estos documentos de cuaderno proporcionan un registro completo y autónomo de un cálculo que se puede convertir a varios formatos y compartir con otros.
Este espacio de trabajo tiene una variedad de extensiones de Jupyter de terceros activadas. Puede configurar estas extensiones en la pestaña Nbextensions Configurator:
nbextensionsen el navegador de archivos
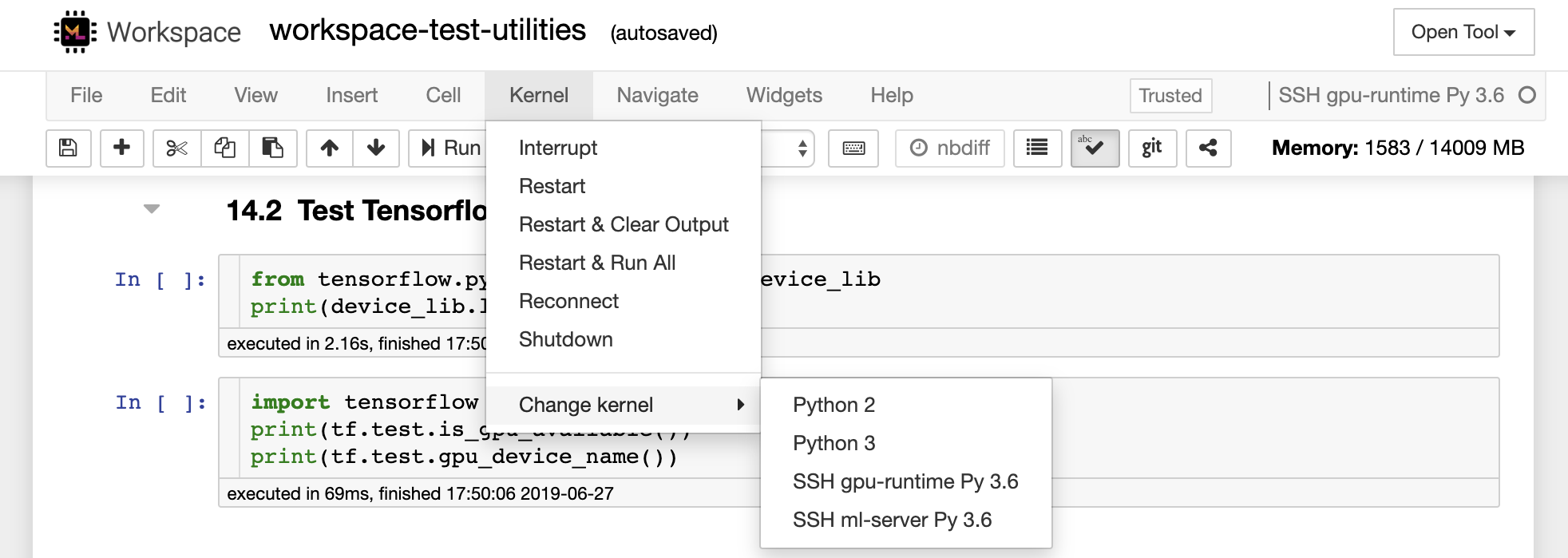
El cuaderno permite que el código se ejecute en una gama de lenguajes de programación diferentes. Para cada documento de cuaderno que abre un usuario, la aplicación web inicia un kernel que ejecuta el código para ese cuaderno y devuelve la salida. Este espacio de trabajo tiene un kernel Python 3 preinstalado. Se pueden instalar núcleos adicionales para obtener acceso a otros idiomas (p. Ej., R, Scala, GO) o recursos informáticos adicionales (por ejemplo, GPU, CPU, memoria).
Python 2 está deprimido y no recomendamos usarlo. Sin embargo, aún puede instalar un kernel Python 2.7 a través de este comando:
/bin/bash /resources/tools/python-27.sh
Este espacio de trabajo proporciona un acceso VNC basado en HTTP al espacio de trabajo a través de NovNC. De este modo, puede acceder y trabajar dentro del espacio de trabajo con una GUI de escritorio con todas las funciones. Para acceder a esta GUI de escritorio, vaya a Open Tool , seleccione VNC y haga clic en el botón Connect . En el caso de que se le pida una contraseña, use vncpassword .
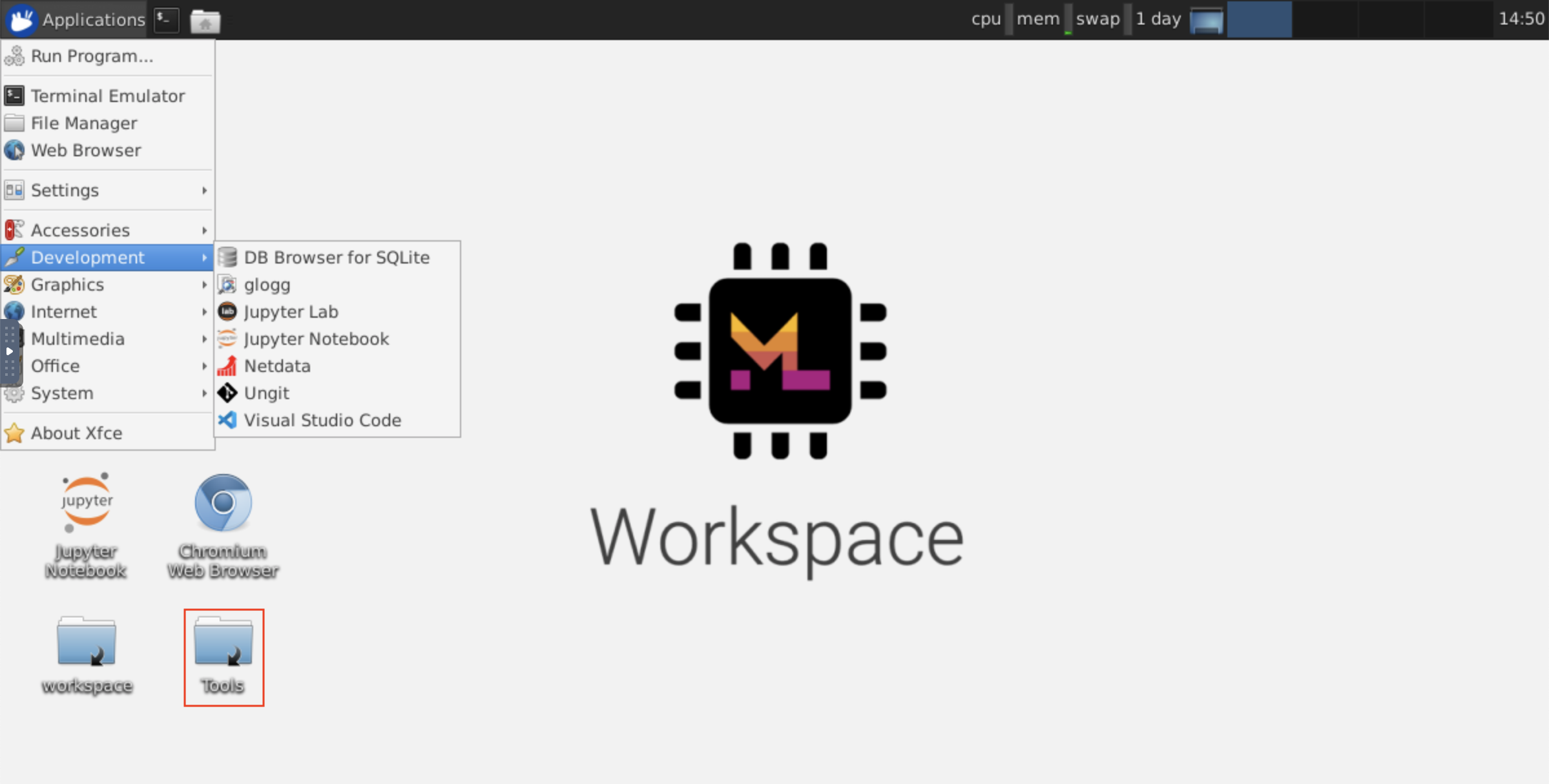
Una vez que esté conectado, verá una GUI de escritorio que le permite instalar y usar navegadores web completos o cualquier otra herramienta disponible para Ubuntu. Dentro de la carpeta Tools en el escritorio, encontrará una colección de scripts de instalación que hace que sea sencillo instalar algunas de las herramientas de desarrollo más utilizadas, como Atom, PyCharm, R-Runtime, R-Studio o Postman (simplemente haga doble clic en el script).
Portapapeles: si desea compartir el portapapeles entre su máquina y el espacio de trabajo, puede usar la funcionalidad Copy-Paste como se describe a continuación:
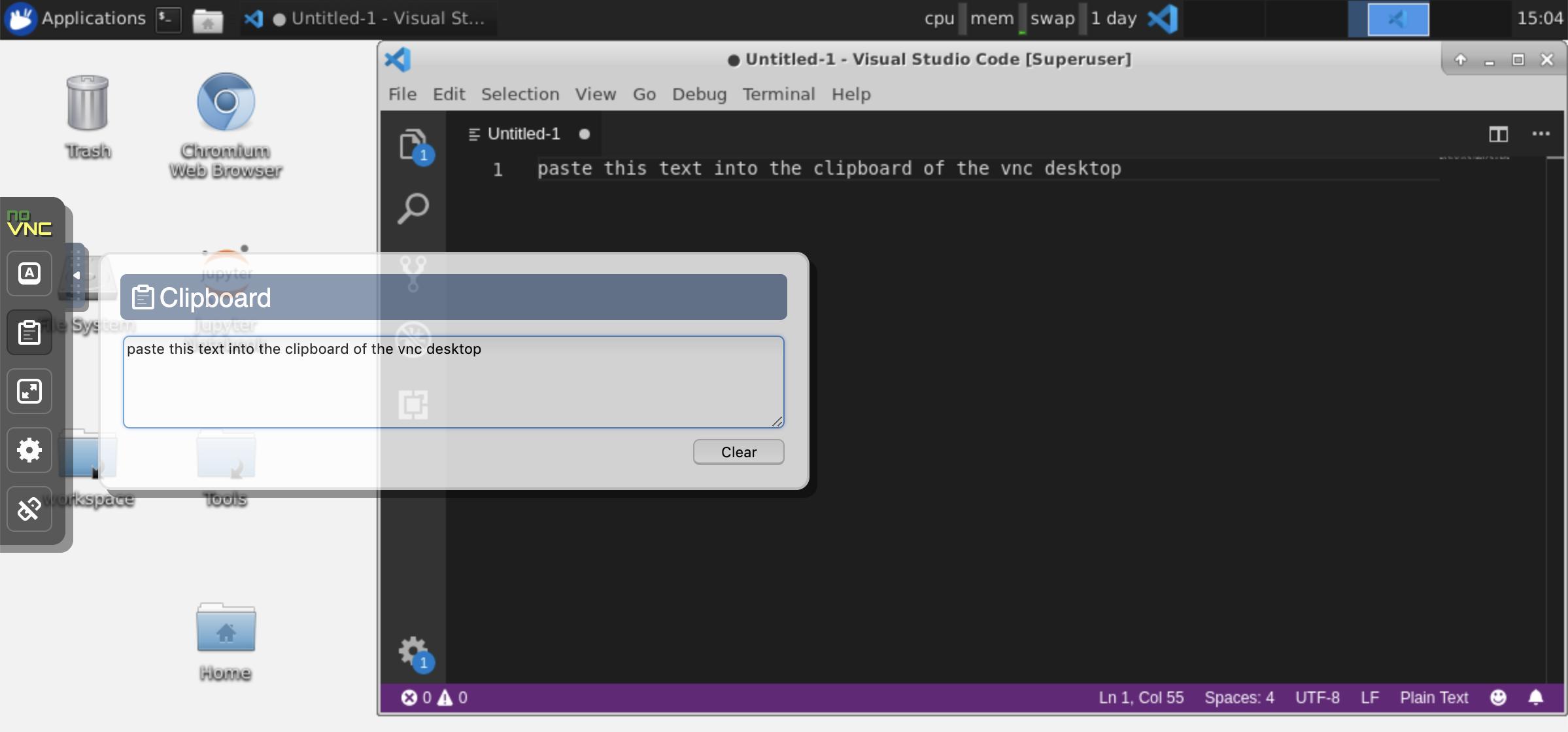
Tareas de larga duración: use la GUI de escritorio para ejecuciones de Jupyter de larga duración. Al ejecutar portátiles desde el navegador de la GUI de escritorio de su espacio de trabajo, toda la salida se sincronizará con el cuaderno incluso si ha desconectado su navegador del cuaderno.
Visual Studio Code ( Open Tool -> VS Code ) es un editor de código ligero pero poderoso de código abierto con soporte incorporado para una variedad de idiomas y un rico ecosistema de extensiones. Combina la simplicidad de un editor de código fuente con herramientas de desarrollador potentes, como la finalización y depuración del código Intellisense. El espacio de trabajo integra el código VS como una aplicación basada en la web accesible a través del navegador basado en el increíble proyecto de servidor de código. Le permite personalizar cada característica a su gusto e instalar cualquier cantidad de extensiones de terceros.
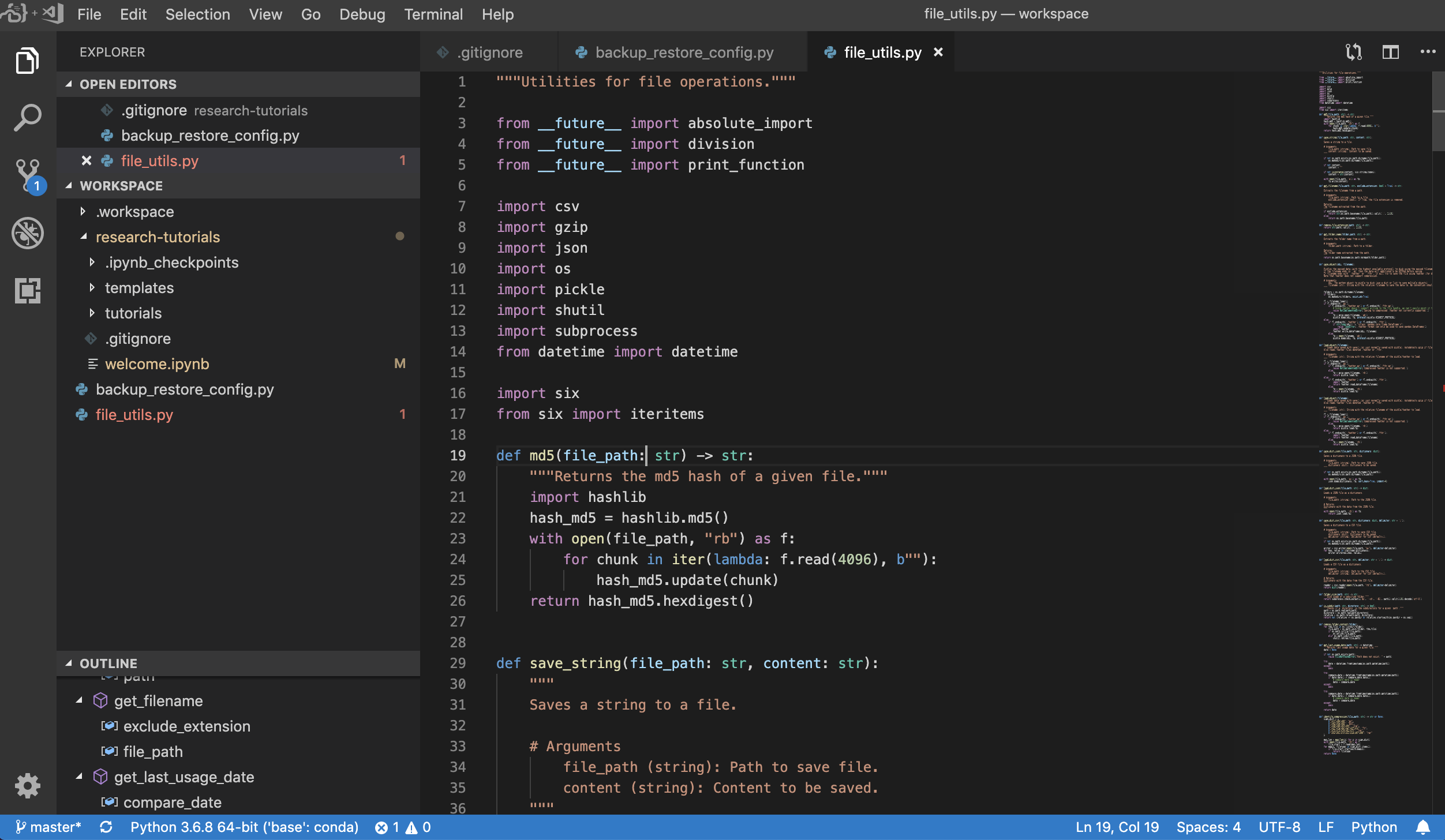
El espacio de trabajo también proporciona una integración de código VS en Jupyter, lo que le permite abrir una instancia de código VS para cualquier carpeta seleccionada, como se muestra a continuación:

JUPYTERLAB ( Open Tool -> JupyterLab ) es la interfaz de usuario de próxima generación para Project Jupyter. Ofrece todos los bloques de construcción familiares del clásico cuaderno Jupyter (cuaderno, terminal, editor de texto, navegador de archivos, salidas ricas, etc.) en una interfaz de usuario flexible y potente. Esta instancia de Jupyterlab viene preinstalada con algunas extensiones útiles, como un Jupyterlab-Toc, Jupyterlab-git y Juptyterlab-tensorboard.
El control de versiones es un aspecto crucial de la colaboración productiva. Para que este proceso sea lo más suave posible, hemos integrado una extensión de Jupyter hecha a medida especializada .md presionar cuadernos individuales, un cliente GIT basado en la web completo (UNGIT), una herramienta para abrir y editar documentos de texto sin formato ( .py ). Además, Jupyterlab y VS Code también proporcionan clientes GIT basados en GUI.
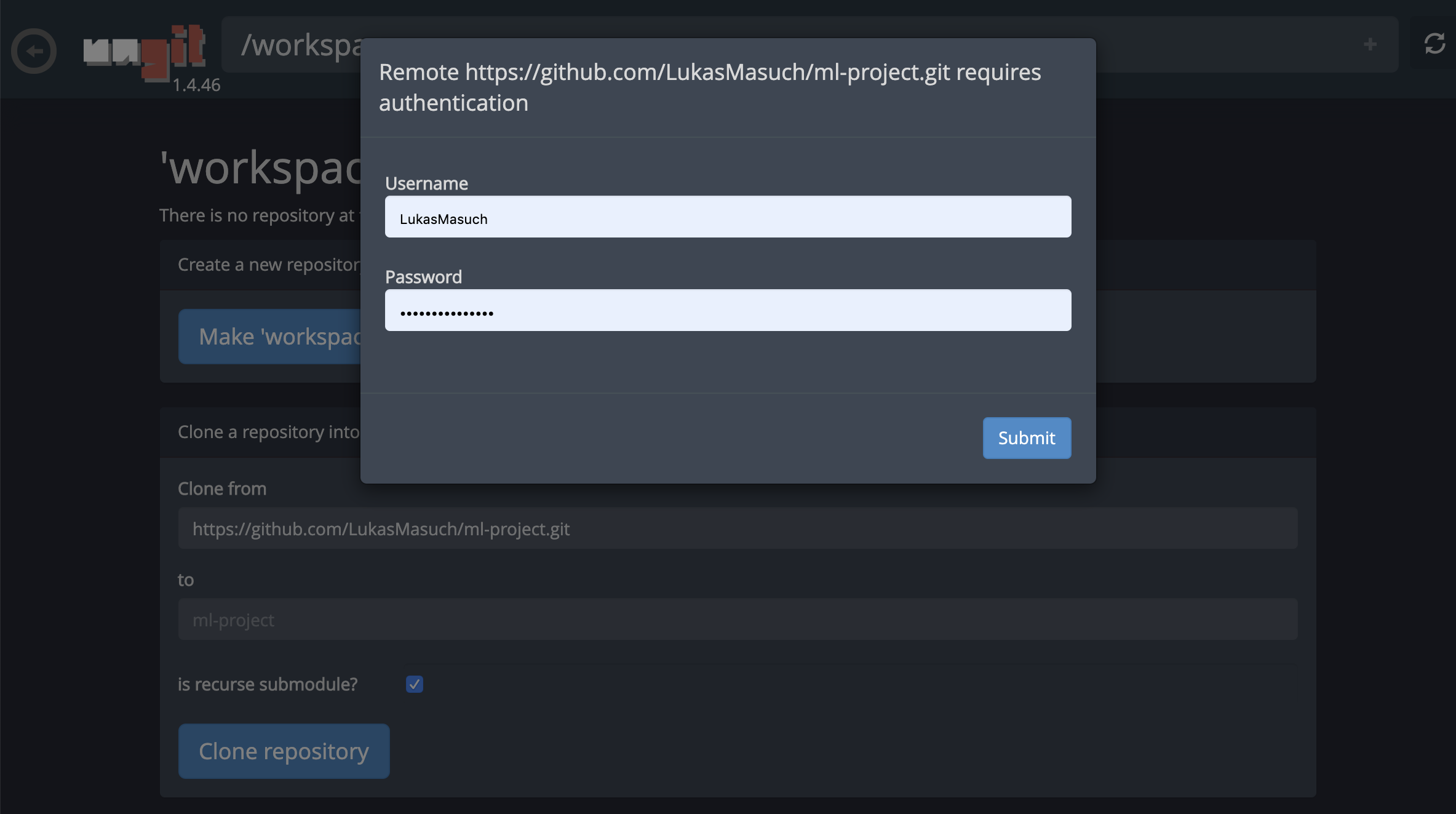
Para los repositorios de clonación a través de https , recomendamos navegar a la carpeta de raíz deseada y hacer clic en el botón git como se muestra a continuación:

Esto podría solicitar algunas configuraciones requeridas y, posteriormente, abre UNGIT, un cliente GIT basado en la web con una interfaz de usuario limpia e intuitiva que hace que sea conveniente sincronizar sus artefactos de código. Dentro de UNGIT, puede clonar cualquier repositorio. Si se requiere autenticación, se le solicitará sus credenciales.
Para comprometer y empujar un solo cuaderno a un repositorio de git remoto, recomendamos usar el complemento Git integrado en Jupyter, como se muestra a continuación:
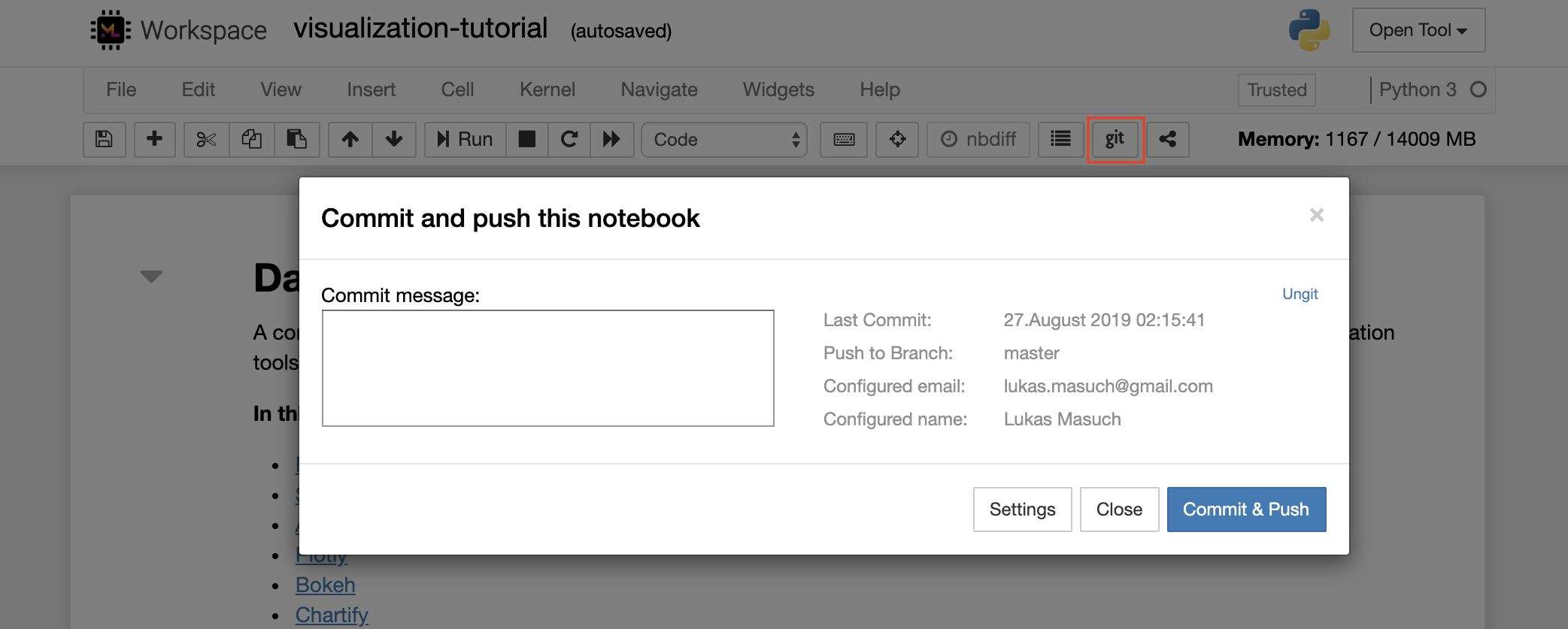
Para operaciones GIT más avanzadas, recomendamos usar UNGIT. Con UNGIT, puede realizar la mayoría de las acciones comunes de GIT, como Push, Pull, Merge, Branch, Tag, Checkout y muchos más.
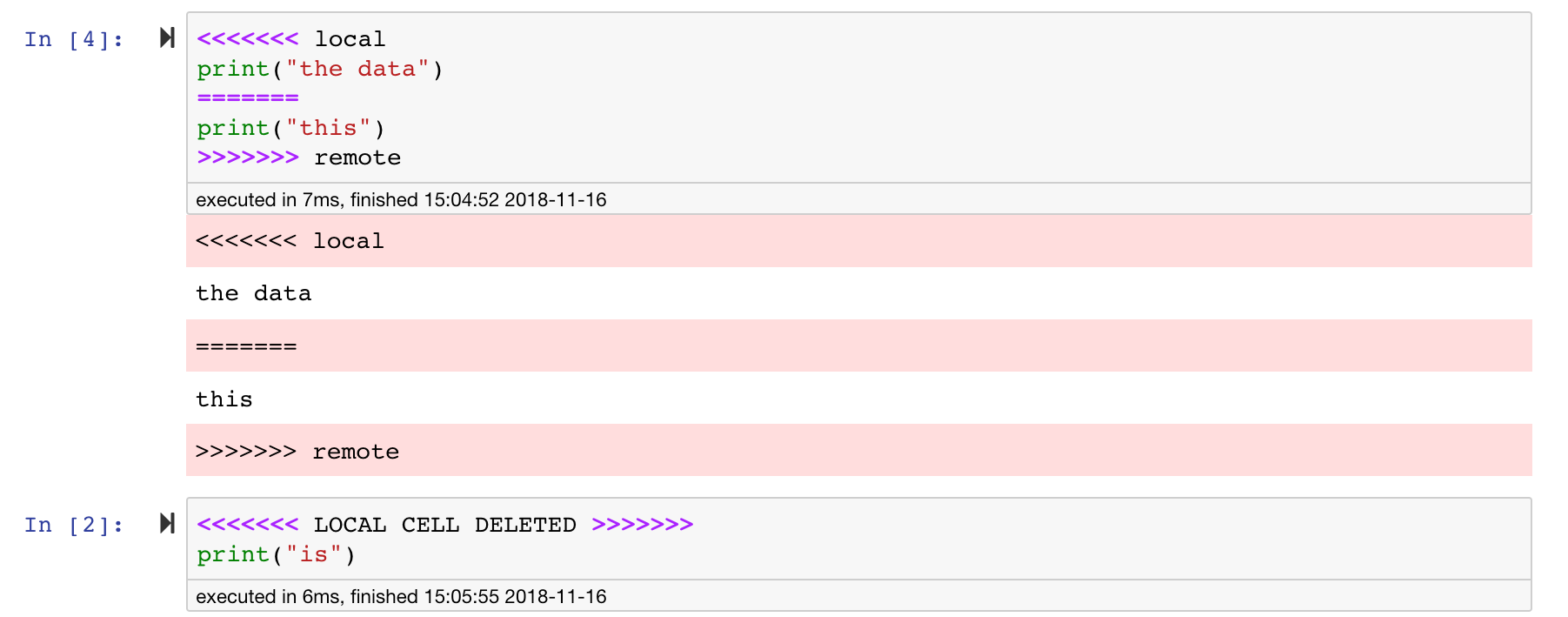
Los cuadernos Jupyter son geniales, pero a menudo son archivos enormes, con un formato de archivo JSON muy específico. Para habilitar la difusión y la fusión perfecta a través de Git, este espacio de trabajo está preinstalado con NBDIME. NBDIME comprende la estructura de los documentos de cuadernos y, por lo tanto, toma automáticamente decisiones inteligentes al difundir y fusionar cuadernos. En el caso de que tenga conflictos de fusiones, NBDIME se asegurará de que el cuaderno todavía sea legible por Jupyter, como se muestra a continuación:
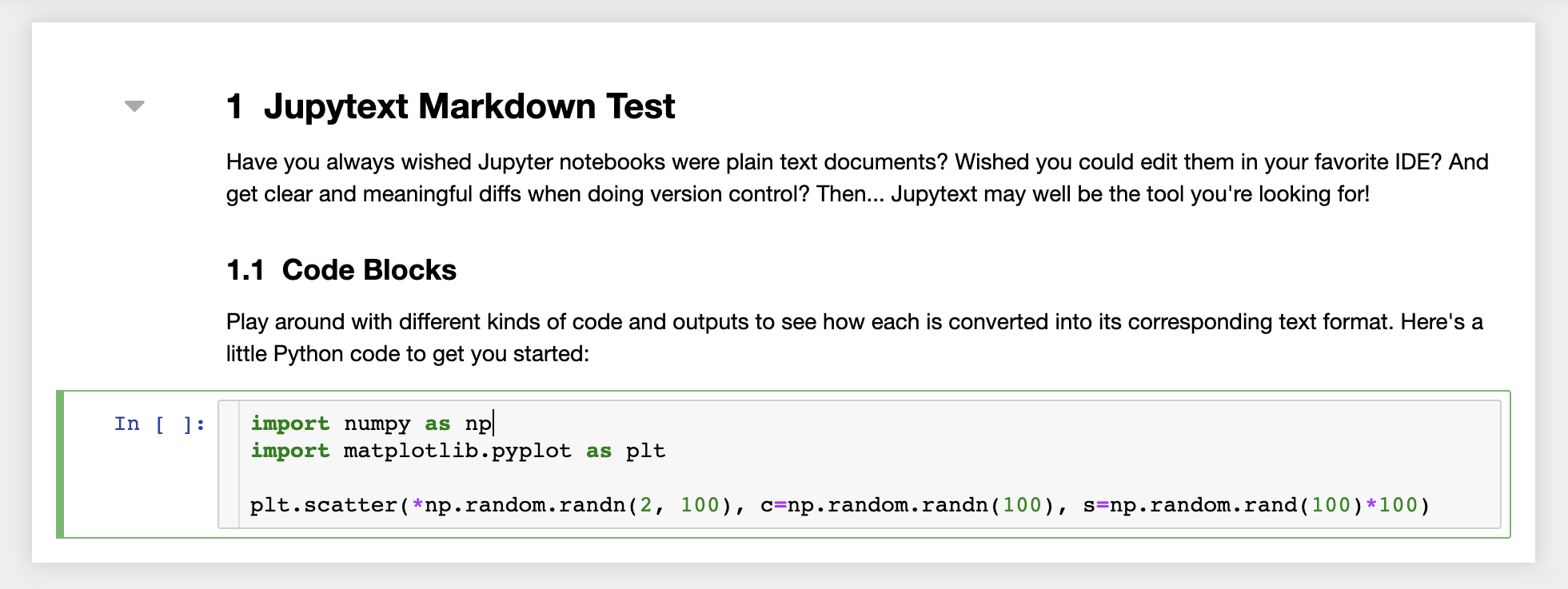
Además, el espacio de trabajo viene preinstalado con JupyText, un complemento Jupyter que lee y escribe cuadernos como archivos de texto sin formato. Esto le permite abrir, editar y ejecutar scripts o archivos de Markdown (por ejemplo, .py , .md ) como cuadernos dentro de Jupyter. En la siguiente captura de pantalla, hemos abierto un archivo de Markdown a través de Jupyter:
En combinación con GIT, JupyText permite un historial de diff claro y una fusión fácil de los conflictos de versión. Con ambas herramientas, colaborar en los cuadernos de Jupyter con GIT se vuelve directo.
El espacio de trabajo tiene una función para compartir cualquier archivo o carpeta con cualquier persona a través de un enlace protegido por token. Para compartir datos a través de un enlace, seleccione cualquier archivo o carpeta del árbol del directorio Jupyter y haga clic en el botón Compartir como se muestra en la siguiente captura de pantalla:
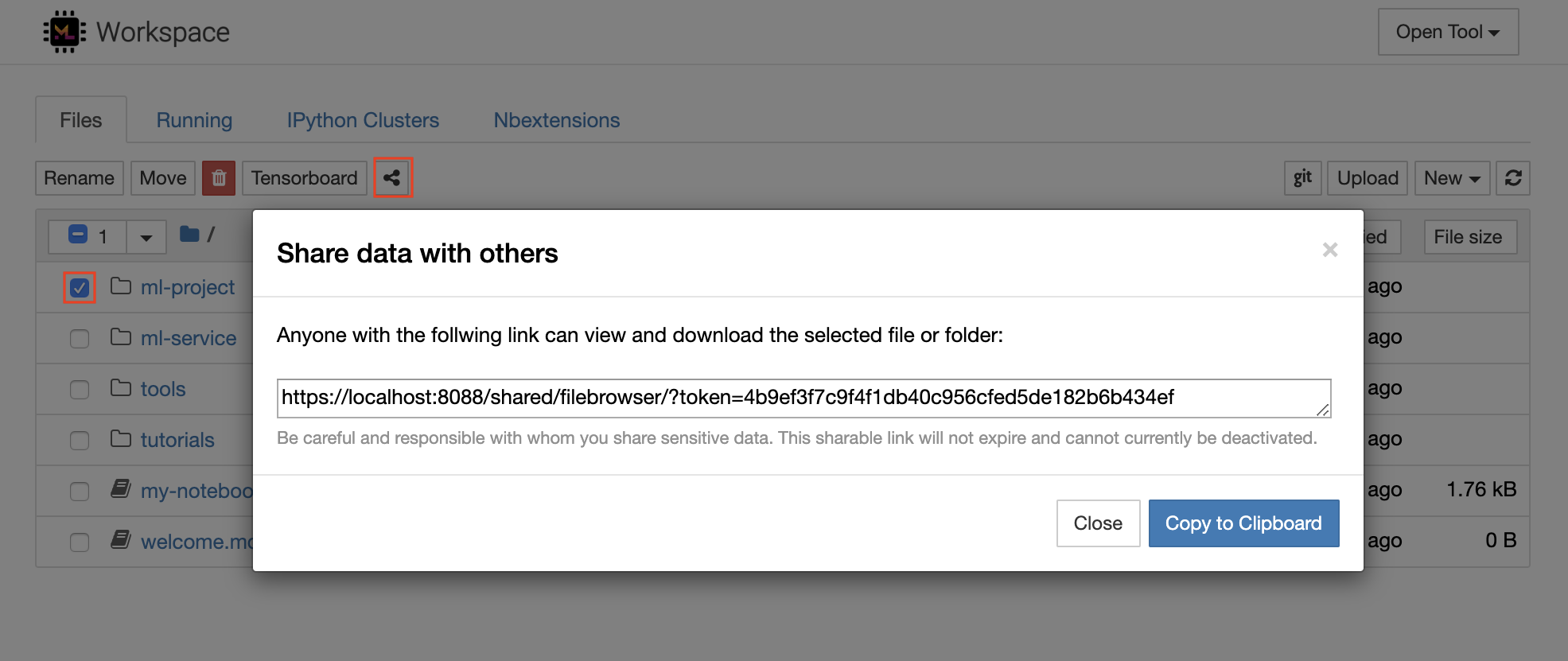
Esto generará un enlace único protegido a través de un token que brinde a cualquier persona con el acceso del enlace para ver y descargar los datos seleccionados a través de la interfaz de usuario de FileBrowser:
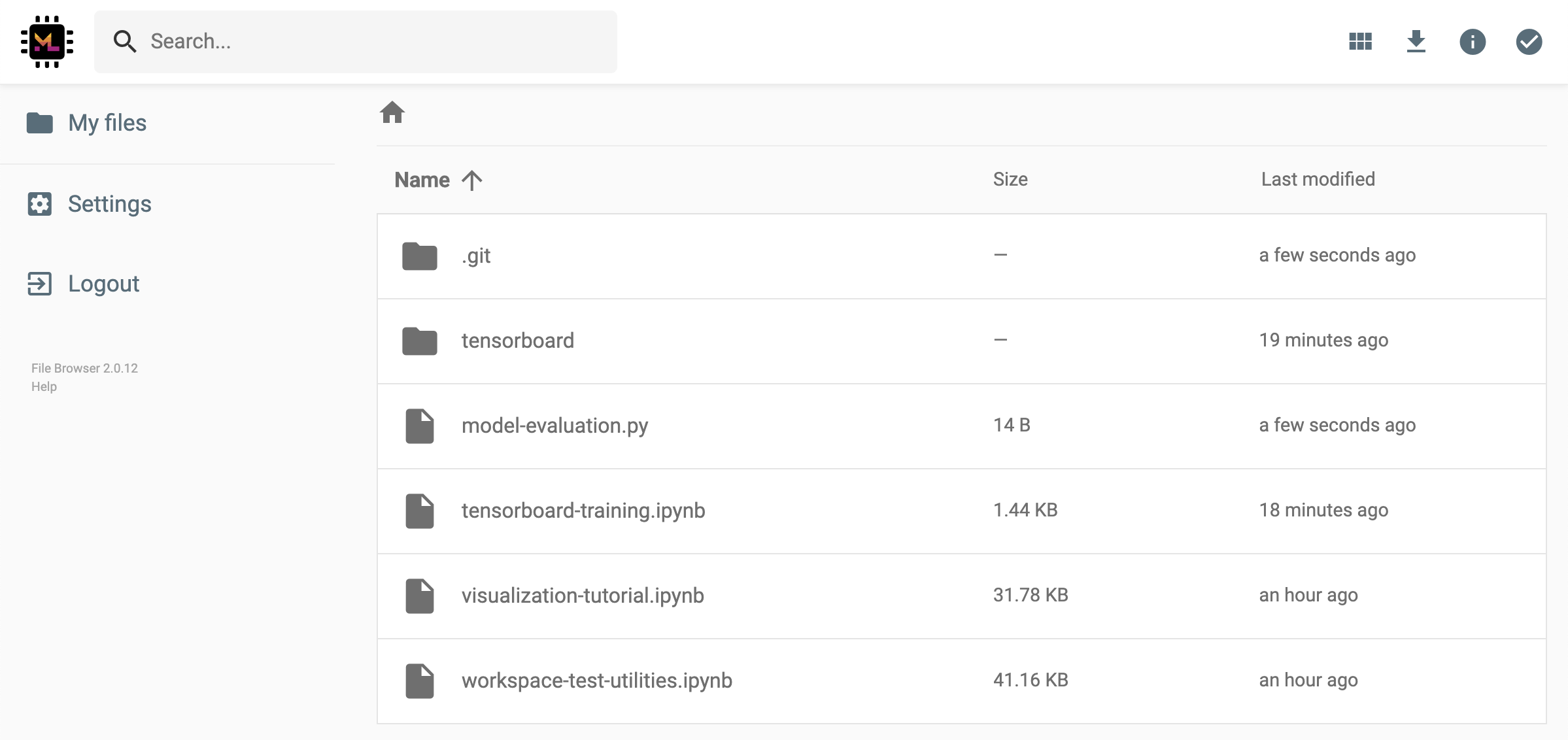
Para desactivar o administrar (p. Ej., Proporcionar permisos de edición) enlaces compartidos, abra el archivo de archivos a través de Open Tool -> Filebrowser y seleccione Settings->User Management .
Es posible acceder de forma segura a cualquier puerto interno del espacio de trabajo seleccionando Open Tool -> Access Port . Con esta función, puede acceder a una API REST o una aplicación web que se ejecuta dentro del espacio de trabajo directamente con su navegador. La función permite a los desarrolladores construir, ejecutar, probar y depurar API REST o aplicaciones web directamente desde el espacio de trabajo.
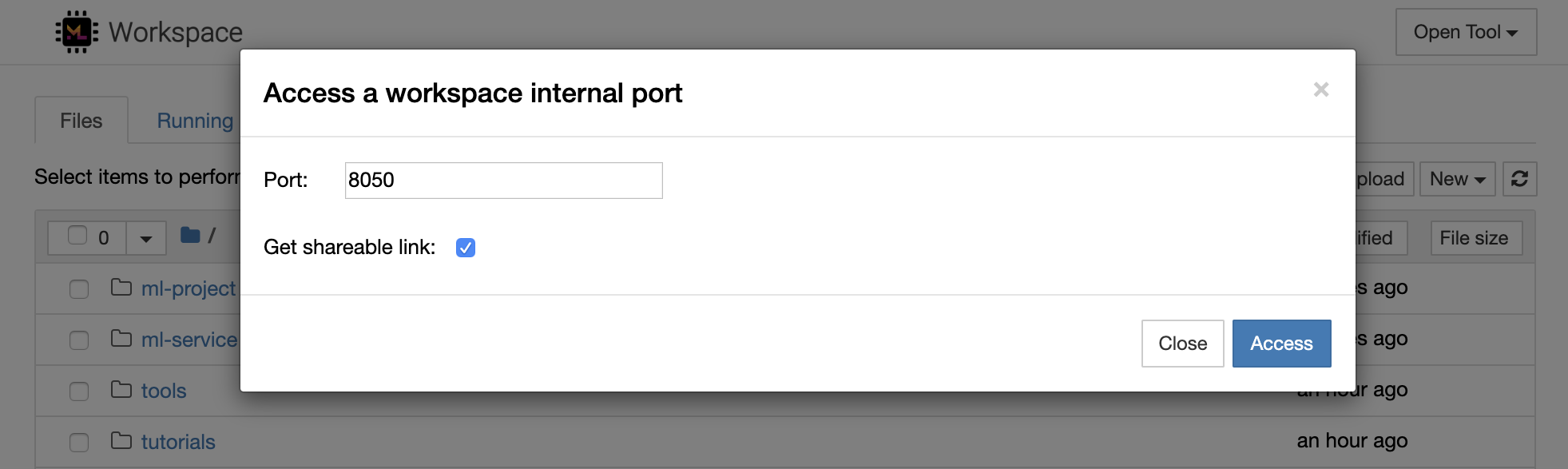
Si desea utilizar un cliente HTTP o compartir acceso a un puerto determinado, puede seleccionar la opción Get shareable link . Esto genera un enlace asegurado por el token que cualquier persona con acceso al enlace puede usar para acceder al puerto especificado.
La aplicación HTTP requiere resolverse desde una ruta de URL relativa o configurar una ruta base (
/tools/PORT/). ¡Las herramientas hechas accesibles de esta manera están aseguradas por el sistema de autenticación del espacio de trabajo! Si decide publicar cualquier otro puerto del contenedor usted mismo en lugar de usar esta función para que una herramienta sea accesible, ¡asegúrese de asegurarlo a través de un mecanismo de autenticación!
1234 ejecutando este comando en un terminal dentro del espacio de trabajo: python -m http.server 1234Open Tool -> Access Port , el puerto de entrada 1234 y seleccione la opción Get shareable link .Access y verá el contenido proporcionado por http.server de Python. SSH proporciona un poderoso conjunto de características que le permite ser más productivo con sus tareas de desarrollo. Puede configurar fácilmente una conexión SSH segura y sin contraseña a un espacio de trabajo seleccionando Open Tool -> SSH . Esto generará un comando de configuración seguro que se puede ejecutar en cualquier máquina Linux o Mac para configurar una conexión SSH sin contraseña y segura al espacio de trabajo. Alternativamente, también puede descargar el script de configuración y ejecutarlo (en lugar de usar el comando).
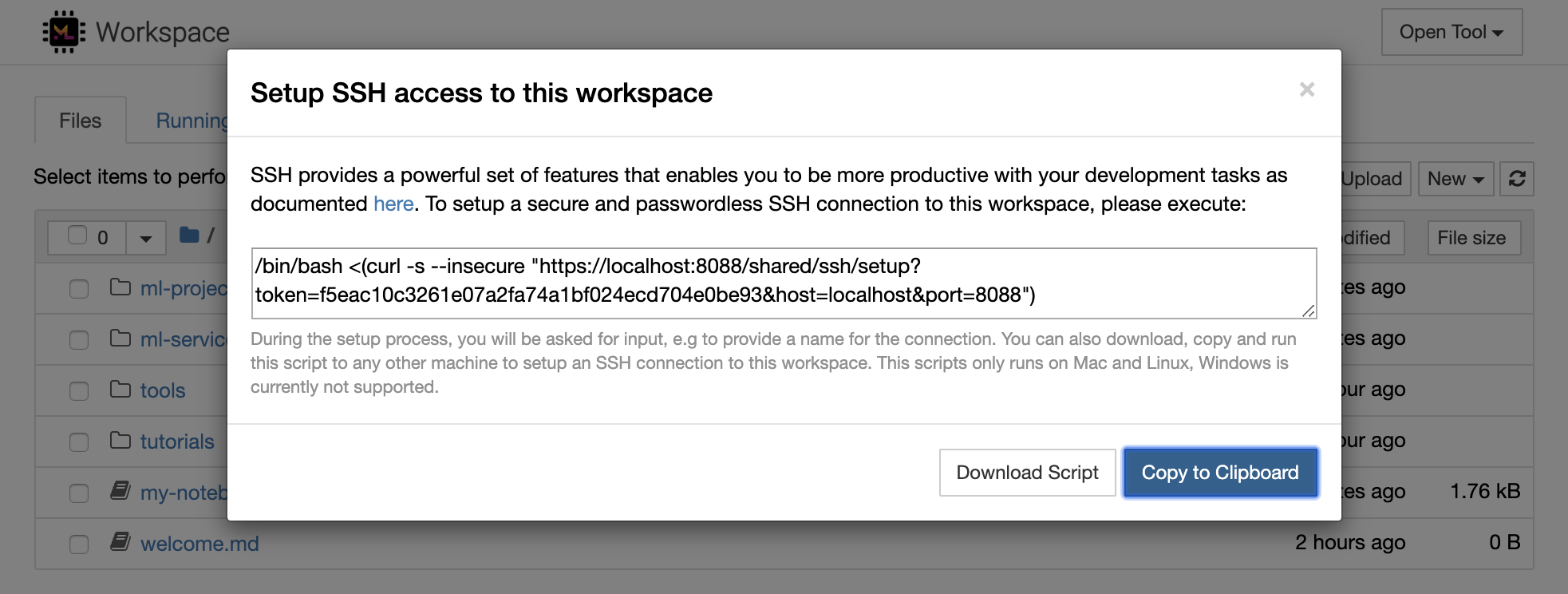
El script de configuración solo se ejecuta en Mac y Linux. Windows no es compatible actualmente.
Simplemente ejecute el comando de configuración o script en la máquina desde donde desea configurar una conexión al espacio de trabajo e ingrese un nombre para la conexión (por ejemplo, my-workspace ). También se le solicitará una entrada adicional durante el proceso, por ejemplo, para instalar un núcleo remoto si se instala remote_ikernel . Una vez que la conexión SSH sin contraseña se configura y prueba con éxito, puede conectarse de forma segura al espacio de trabajo simplemente ejecutando ssh my-workspace .
Además de la capacidad de ejecutar comandos en una máquina remota, SSH también proporciona una variedad de otras características que pueden mejorar su flujo de trabajo de desarrollo como se describe en las siguientes secciones.
Se puede utilizar una conexión SSH para los puertos de aplicación de túneles desde la máquina remota a la máquina local, o viceversa. Por ejemplo, puede exponer el puerto interno del espacio de trabajo 5901 (servidor VNC) a la máquina local en el puerto 5000 ejecutando:
ssh -nNT -L 5000:localhost:5901 my-workspacePara exponer un puerto de aplicación desde su máquina local a un espacio de trabajo, use la opción
-R(en lugar de-L).
Después de establecer el túnel, puede usar su visor VNC favorito en su máquina local y conectarse a vnc://localhost:5000 (contraseña predeterminada: vncpassword ). Para que la conexión del túnel sea más resistente y confiable, recomendamos usar AutoSH para reiniciar automáticamente los túneles SSH en el caso de que la conexión muera:
autossh -M 0 -f -nNT -L 5000:localhost:5901 my-workspaceEl túnel de puerto es bastante útil cuando ha comenzado cualquier herramienta basada en servidor dentro del espacio de trabajo que le gustaría hacer accesible para otra máquina. En su configuración predeterminada, el espacio de trabajo tiene una variedad de herramientas que ya se ejecutan en diferentes puertos, como:
8080 : Puerto principal del espacio de trabajo con acceso a todas las herramientas integradas.8090 : servidor Jupyter.8054 : VS Servidor de código.5901 : servidor VNC.22 : servidor SSH.Puede encontrar información de puerto sobre todas las herramientas en la configuración del supervisor.
Para obtener más información sobre el túnel/reenvío de puertos, recomendamos esta guía.
SCP permite que los archivos y directorios se copian de forma segura, desde o entre diferentes máquinas a través de conexiones SSH. Por ejemplo, para copiar un archivo local ( ./local-file.txt ) en la carpeta /workspace dentro del espacio de trabajo, ejecute:
scp ./local-file.txt my-workspace:/workspace Para copiar el directorio /workspace de my-workspace al directorio de trabajo de la máquina local, ejecute:
scp -r my-workspace:/workspace .Para obtener más información sobre SCP, recomendamos esta guía.
RSYNC es una utilidad para transferir y sincronizar eficientemente archivos entre diferentes máquinas (por ejemplo, a través de conexiones SSH) comparando los tiempos de modificación y los tamaños de los archivos. El comando RSYNC determinará qué archivos deben actualizarse cada vez que se ejecute, lo cual es mucho más eficiente y conveniente que usar algo como SCP o SFTP. Por ejemplo, para sincronizar todo el contenido de una carpeta local ( ./local-project-folder/ ) en la /workspace/remote-project-folder/ dentro del espacio de trabajo, ejecutar:
rsync -rlptzvP --delete --exclude= " .git " " ./local-project-folder/ " " my-workspace:/workspace/remote-project-folder/ "Si tiene algunos cambios dentro de la carpeta en el espacio de trabajo, puede sincronizar esos cambios a la carpeta local cambiando los argumentos de origen y destino:
rsync -rlptzvP --delete --exclude= " .git " " my-workspace:/workspace/remote-project-folder/ " " ./local-project-folder/ "Puede volver a ejecutar estos comandos cada vez que desee sincronizar la última copia de sus archivos. RSYNC se asegurará de que solo se transferirán actualizaciones.
Puede encontrar más información sobre RSYNC en esta página de Man.
Además de copiar y sincronizar datos, también se puede utilizar una conexión SSH para montar directorios de una máquina remota en el sistema de archivos local a través de SSHFS. Por ejemplo, para montar el directorio /workspace de my-workspace en una ruta local (por ejemplo /local/folder/path ), ejecute:
sshfs -o reconnect my-workspace:/workspace /local/folder/pathUna vez que se monta el directorio remoto, puede interactuar con el sistema de archivos remoto de la misma manera que con cualquier directorio y archivo local.
Para obtener más información sobre SSHFS, recomendamos esta guía.
El espacio de trabajo se puede integrar y utilizar como un tiempo de ejecución remoto (también conocido como kernel/máquina/intérprete remoto) para una variedad de herramientas e ides de desarrollo populares, como Jupyter, VS Code, Pycharm, Colab o Atom Hydogen. De este modo, puede conectar su herramienta de desarrollo favorita que se ejecuta en su máquina local a una máquina remota para la ejecución del código. Esto permite una experiencia de desarrollo de calidad local con recursos de cómputo alojados a distancia.
Estas integraciones generalmente requieren una conexión SSH sin contraseña de la máquina local al espacio de trabajo. Para configurar una conexión SSH, siga los pasos explicados en la sección de acceso SSH.
El espacio de trabajo se puede agregar a una instancia de Jupyter como un núcleo remoto utilizando la herramienta Remote_ikernel. Si ha instalado Remote_ikernel ( pip install remote_ikernel ) en su máquina local, el script de configuración SSH del espacio de trabajo le ofrecerá automáticamente la opción de configurar una conexión de kernel remota.
Al ejecutar kernels en máquinas remotas, los cuadernos en sí se guardarán en el sistema de archivos local, pero el núcleo solo tendrá acceso al sistema de archivos de la máquina remota que ejecuta el núcleo. Si necesita sincronizar datos, puede utilizar RSYNC, SCP o SSHFS como se explica en la sección de acceso SSH.
En caso de que desee configurar y administrar manualmente los núcleos remotos, use la herramienta de línea de comandos Remote_ikernel, como se muestra a continuación:
# Change my-workspace with the name of a workspace SSH connection
remote_ikernel manage --add
--interface=ssh
--kernel_cmd= " ipython kernel -f {connection_file} "
--name= " ml-server (Python) "
--host= " my-workspace " Puede usar la funcionalidad de línea de comandos Remote_ikernel para enumerar ( remote_ikernel manage --show ) o Delete ( remote_ikernel manage --delete <REMOTE_KERNEL_NAME> ) conexiones de núcleo remoto.
Visual Studio Code Remote: SSH Extension le permite abrir una carpeta remota en cualquier máquina remota con acceso SSH y trabajar con ella tal como lo haría si la carpeta estuviera en su propia máquina. Una vez conectado a una máquina remota, puede interactuar con archivos y carpetas en cualquier parte del sistema de archivos remoto y aprovechar al máximo el conjunto de características de VS Code (Intellisense, Depurging y Extension Support). Descubre y funciona fuera de la caja con conexiones SSH sin contraseña según lo configurado por el script de configuración del espacio de trabajo SSH. Para habilitar su aplicación local de código VS para conectarse a un espacio de trabajo:
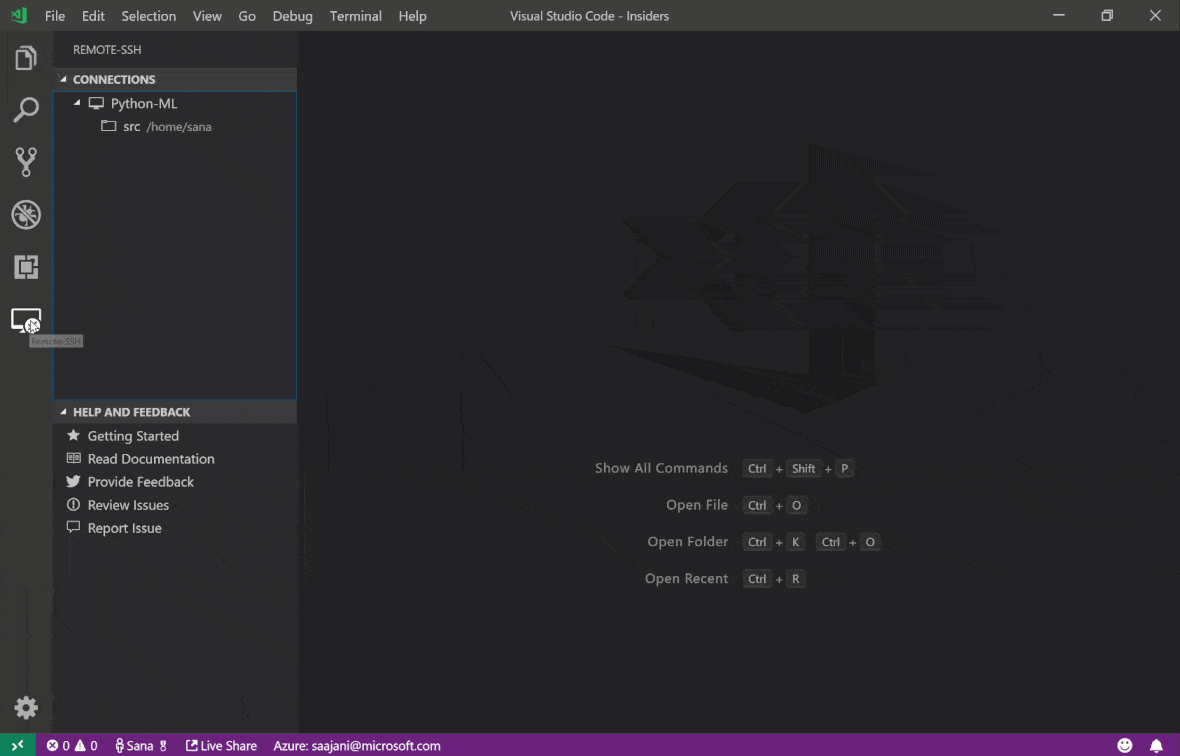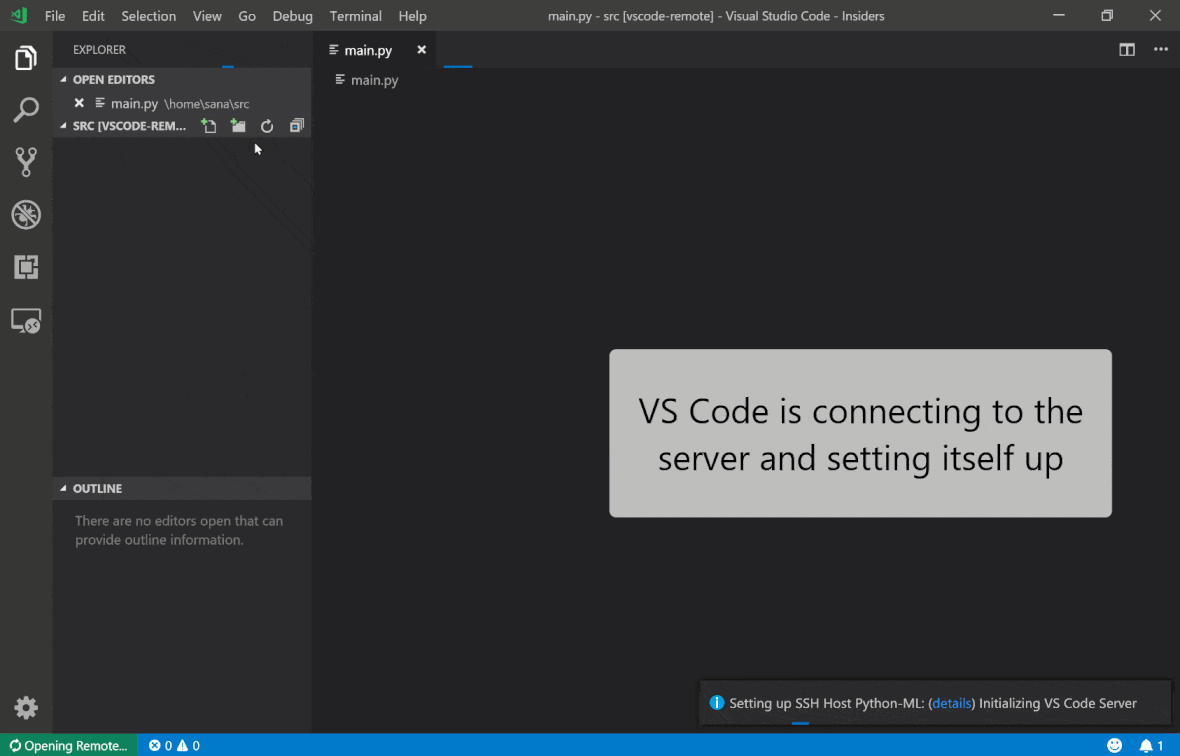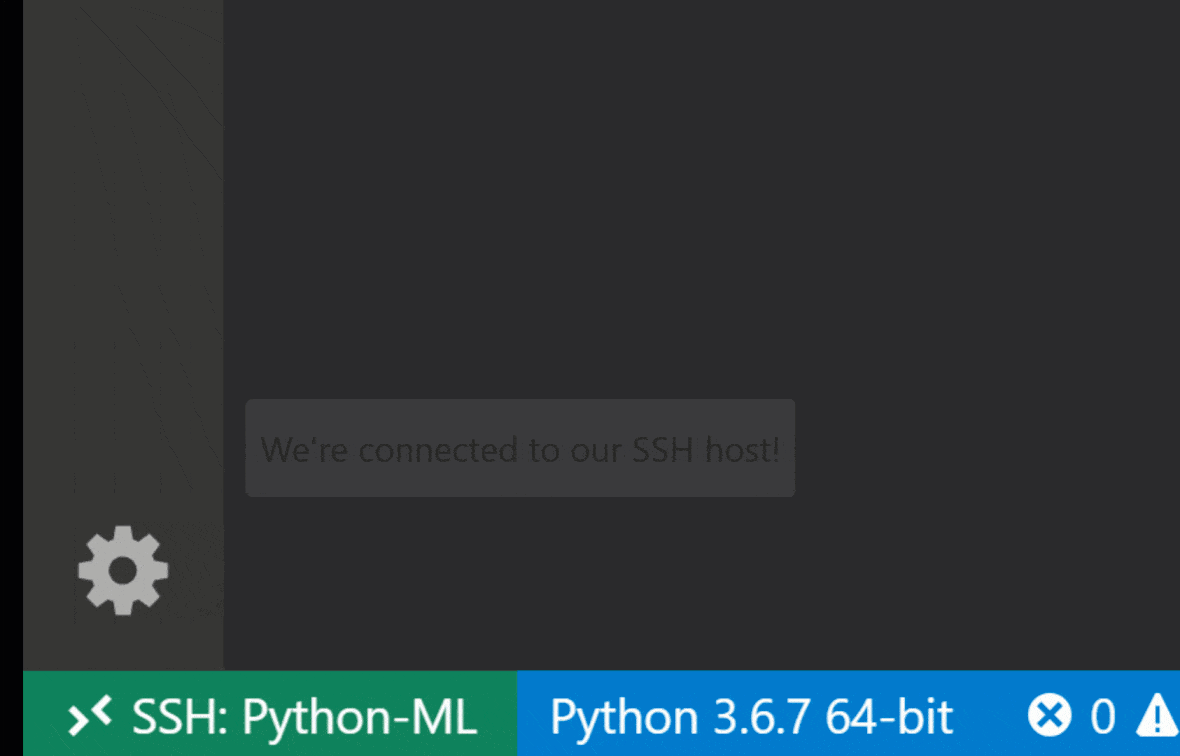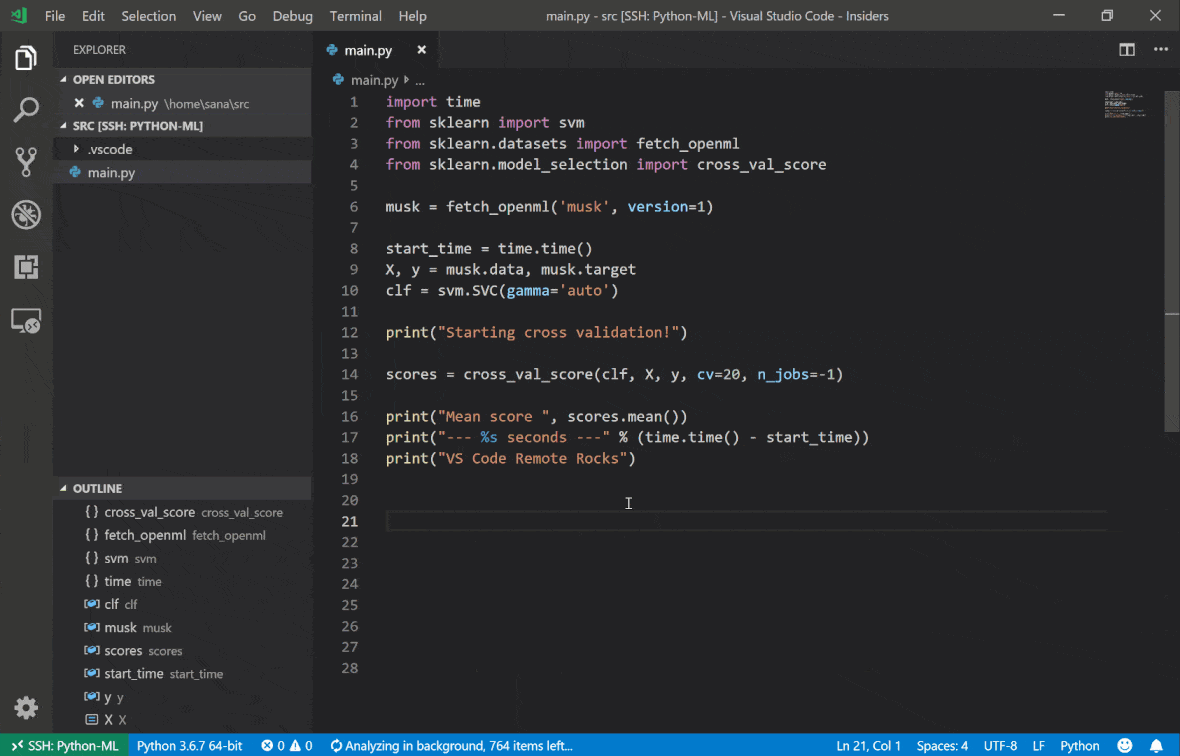
Puede encontrar características e información adicionales sobre la extensión SSH remota en esta guía.
TensorBoard proporciona un conjunto de herramientas de visualización para facilitar la comprensión, depurar y optimizar sus ejecuciones de experimentos. Incluye características de registro para escalar, histograma, estructura del modelo, incrustaciones y visualización de texto e imágenes. El espacio de trabajo viene preinstalado con Jupyter_Tensorboard Extension que integra TensorBoard en la interfaz Jupyter con funcionalidades para iniciar, administrar y detener las instancias. Puede abrir una nueva instancia para un directorio de registros válido, como se muestra a continuación:
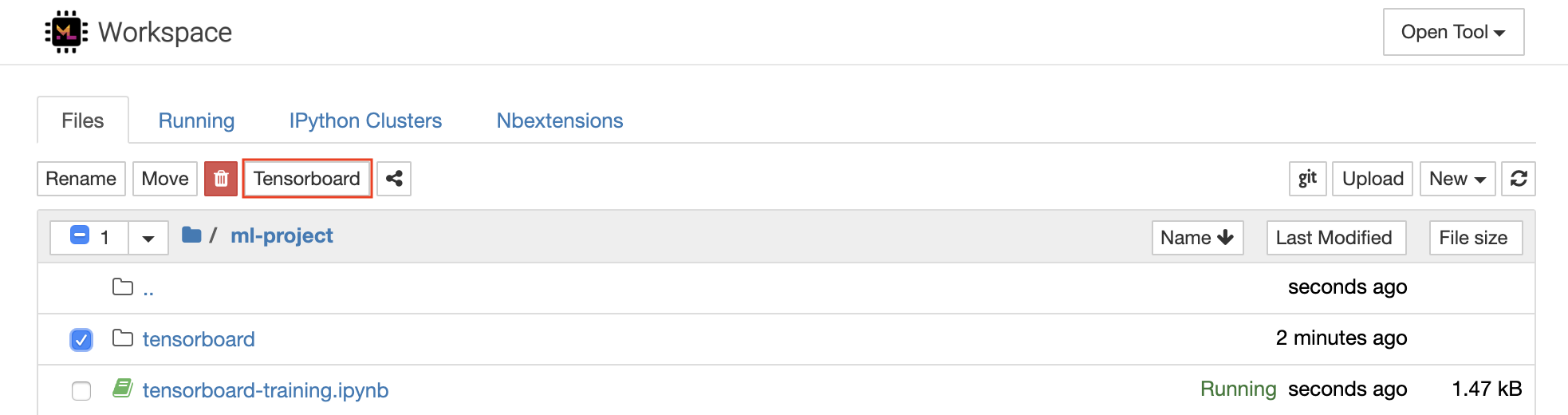
Si ha abierto una instancia de Tensorboard en un directorio de registro válido, verá las visualizaciones de sus datos registrados:
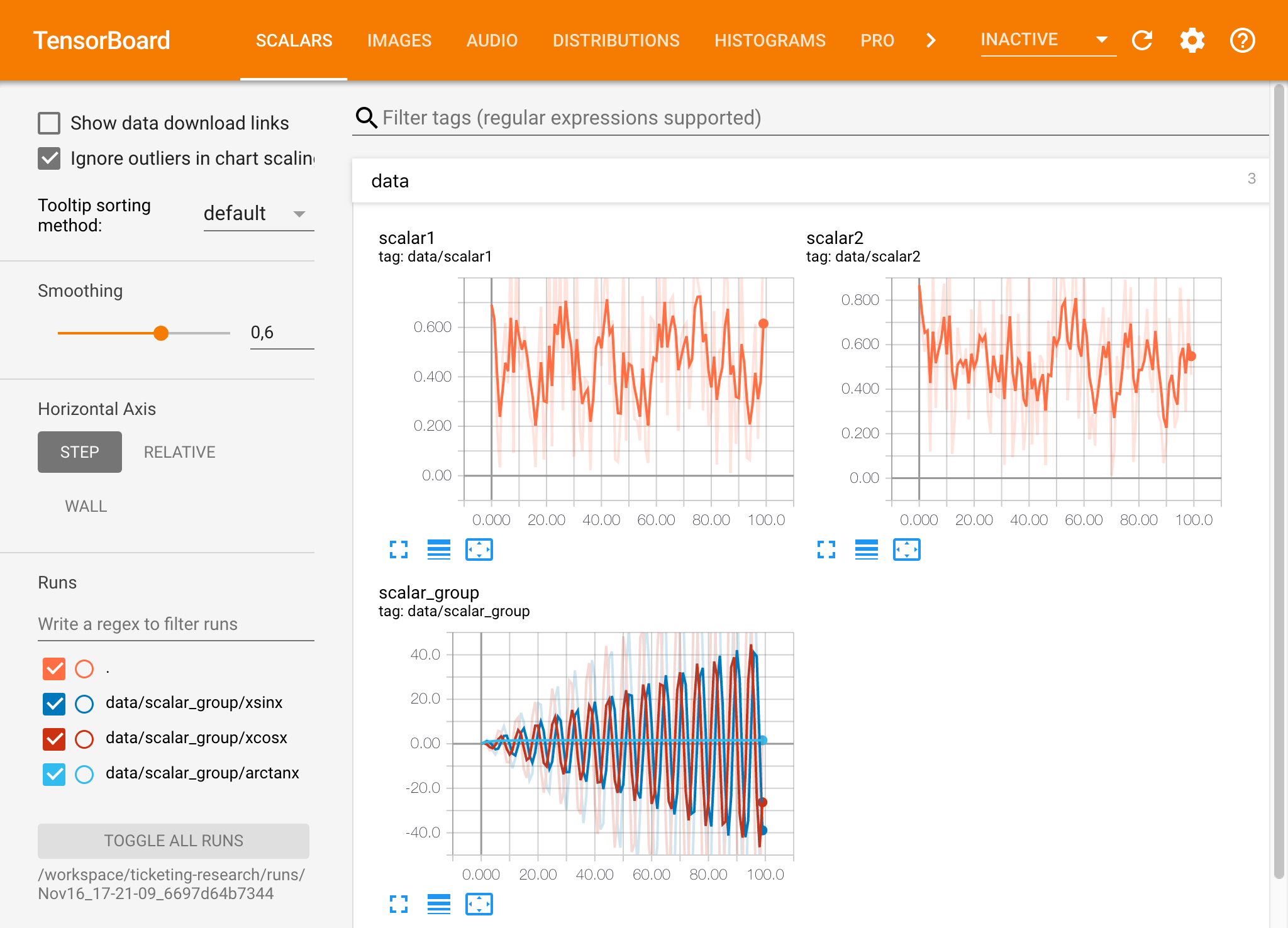
Tensorboard se puede usar en combinación con muchos otros marcos ML además de TensorFlow. Al usar la biblioteca TensorBoardX, puede registrar básicamente desde cualquier biblioteca basada en Python. Además, Pytorch tiene una integración directa de Tensorboard como se describe aquí.
Si prefiere ver la placa tensor directamente dentro de su cuaderno, puede utilizar la siguiente magia de Jupyter :
%load_ext tensorboard
%tensorboard --logdir /workspace/path/to/logs
El espacio de trabajo proporciona dos herramientas basadas en la web preinstaladas para ayudar a los desarrolladores durante la capacitación de modelos y otras tareas de experimentación para obtener información sobre todo lo que sucede en el sistema y descubrir cuellos de botella de rendimiento.
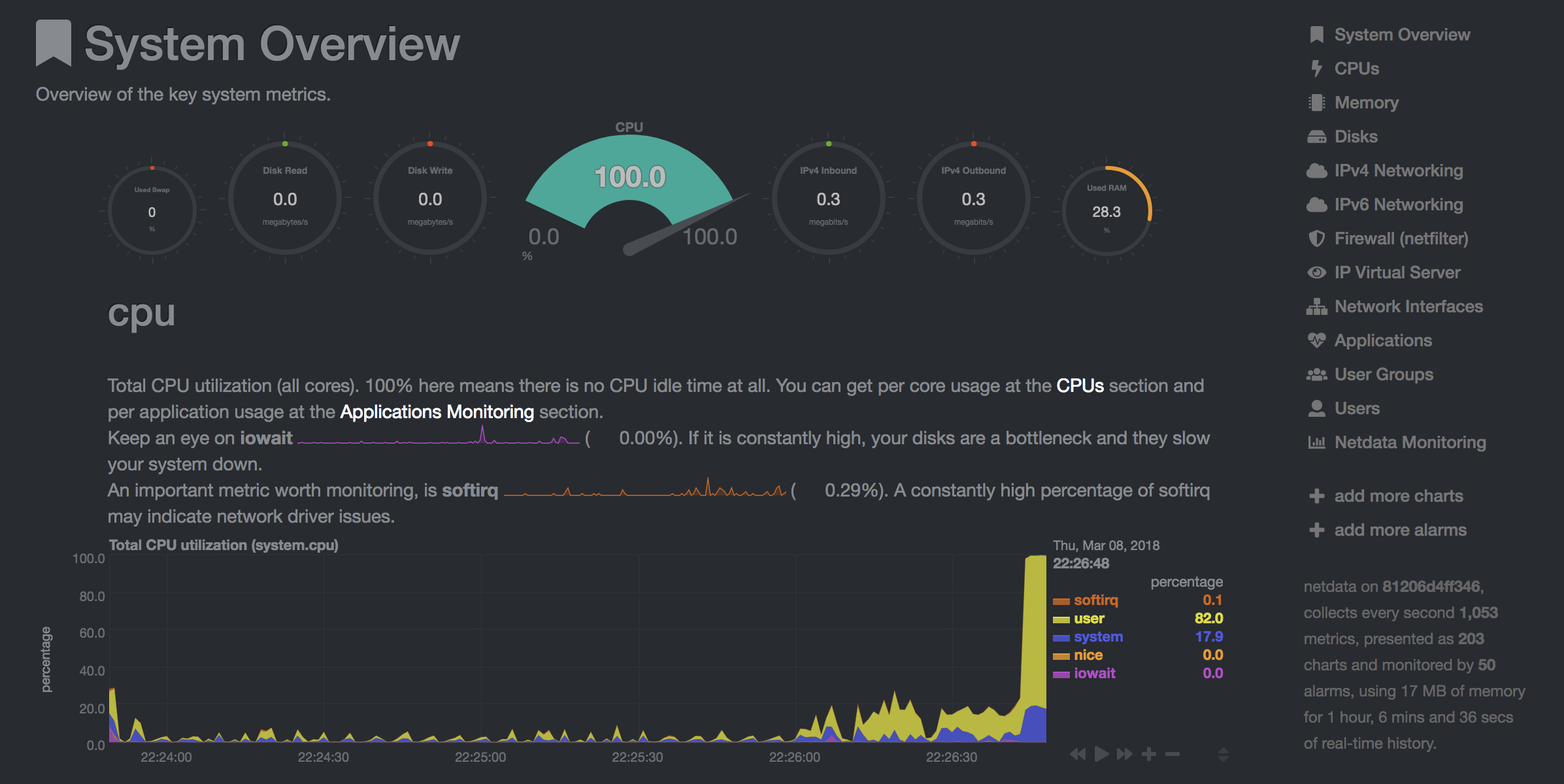
NetData ( Open Tool -> Netdata ) es un tablero de monitoreo de hardware y rendimiento en tiempo real que visualiza los procesos y servicios en sus sistemas Linux. Monitorea las métricas sobre CPU, GPU, memoria, discos, redes, procesos y más.
Glances ( Open Tool -> Glances ) también es un tablero de monitoreo de hardware basado en la web y puede usarse como alternativa a NetData.
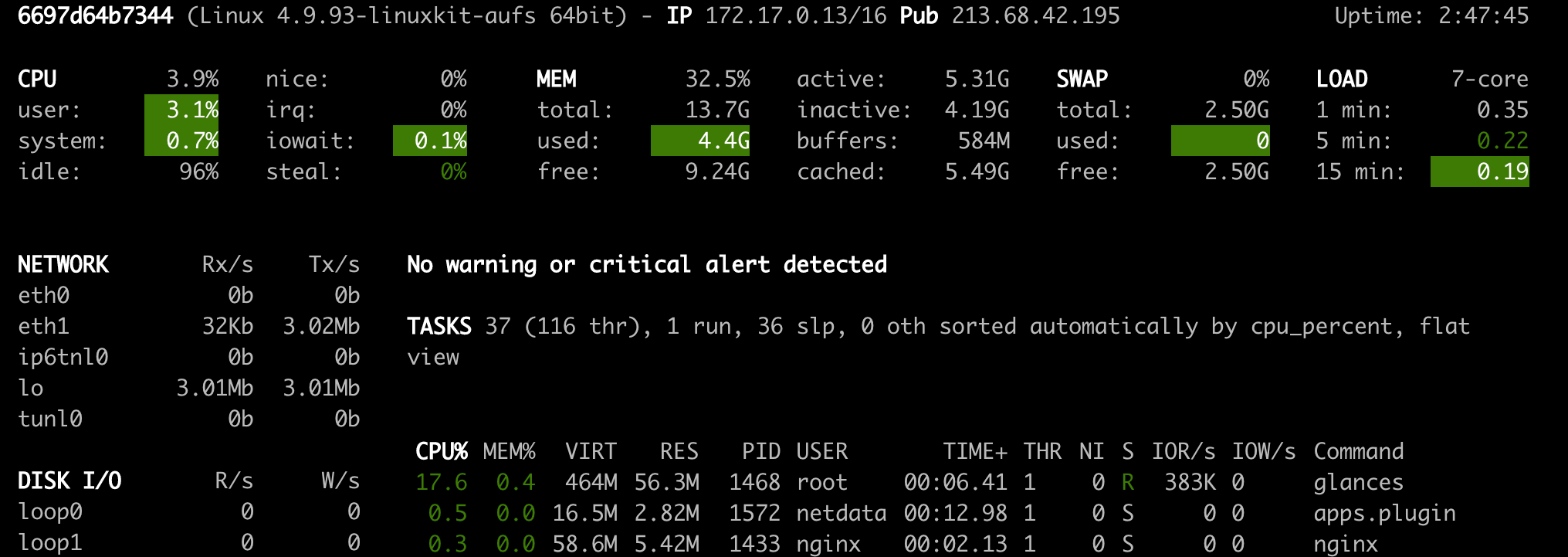
NetData y Glances le mostrarán las estadísticas de hardware para toda la máquina en la que se está ejecutando el contenedor de espacio de trabajo.
Un trabajo se define como cualquier tarea computacional que se ejecute durante un tiempo determinado para su finalización, como una capacitación modelo o una tubería de datos.
La imagen del espacio de trabajo también se puede utilizar para ejecutar código de pitón arbitrario sin comenzar ninguna de las herramientas preinstaladas. This provides a seamless way to productize your ML projects since the code that has been developed interactively within the workspace will have the same environment and configuration when run as a job via the same workspace image.
To run Python code as a job, you need to provide a path or URL to a code directory (or script) via EXECUTE_CODE . The code can be either already mounted into the workspace container or downloaded from a version control system (eg, git or svn) as described in the following sections. The selected code path needs to be python executable. In case the selected code is a directory (eg, whenever you download the code from a VCS) you need to put a __main__.py file at the root of this directory. The __main__.py needs to contain the code that starts your job.
You can execute code directly from Git, Mercurial, Subversion, or Bazaar by using the pip-vcs format as described in this guide. For example, to execute code from a subdirectory of a git repository, just run:
docker run --env EXECUTE_CODE= " git+https://github.com/ml-tooling/ml-workspace.git#subdirectory=resources/tests/ml-job " mltooling/ml-workspace:0.13.2For additional information on how to specify branches, commits, or tags please refer to this guide.
In the following example, we mount and execute the current working directory (expected to contain our code) into the /workspace/ml-job/ directory of the workspace:
docker run -v " ${PWD} :/workspace/ml-job/ " --env EXECUTE_CODE= " /workspace/ml-job/ " mltooling/ml-workspace:0.13.2In the case that the pre-installed workspace libraries are not compatible with your code, you can install or change dependencies by just adding one or multiple of the following files to your code directory:
requirements.txt : pip requirements format for pip-installable dependencies.environment.yml : conda environment file to create a separate Python environment.setup.sh : A shell script executed via /bin/bash . The execution order is 1. environment.yml -> 2. setup.sh -> 3. requirements.txt
You can test your job code within the workspace (started normally with interactive tools) by executing the following python script:
python /resources/scripts/execute_code.py /path/to/your/jobIt is also possible to embed your code directly into a custom job image, as shown below:
FROM mltooling/ml-workspace:0.13.2
# Add job code to image
COPY ml-job /workspace/ml-job
ENV EXECUTE_CODE=/workspace/ml-job
# Install requirements only
RUN python /resources/scripts/execute_code.py --requirements-only
# Execute only the code at container startup
CMD [ "python" , "/resources/docker-entrypoint.py" , "--code-only" ]The workspace is pre-installed with many popular interpreters, data science libraries, and ubuntu packages:
conda , pip , apt-get , npm , yarn , sdk , poetry , gdebi ...The full list of installed tools can be found within the Dockerfile.
For every minor version release, we run vulnerability, virus, and security checks within the workspace using safety, clamav, trivy, and snyk via docker scan to make sure that the workspace environment is as secure as possible. We are committed to fix and prevent all high- or critical-severity vulnerabilities. You can find some up-to-date reports here.
The workspace provides a high degree of extensibility. Within the workspace, you have full root & sudo privileges to install any library or tool you need via terminal (eg, pip , apt-get , conda , or npm ). You can open a terminal by one of the following ways:
New -> TerminalApplications -> Terminal EmulatorFile -> New -> TerminalTerminal -> New Terminal Additionally, pre-installed tools such as Jupyter, JupyterLab, and Visual Studio Code each provide their own rich ecosystem of extensions. The workspace also contains a collection of installer scripts for many commonly used development tools or libraries (eg, PyCharm , Zeppelin , RStudio , Starspace ). You can find and execute all tool installers via Open Tool -> Install Tool . Those scripts can be also executed from the Desktop VNC (double-click on the script within the Tools folder on the Desktop VNC).
For example, to install the Apache Zeppelin notebook server, simply execute:
/resources/tools/zeppelin.sh --port=1234 After installation, refresh the Jupyter website and the Zeppelin tool will be available under Open Tool -> Zeppelin . Other tools might only be available within the Desktop VNC (eg, atom or pycharm ) or do not provide any UI (eg, starspace , docker-client ).
As an alternative to extending the workspace at runtime, you can also customize the workspace Docker image to create your own flavor as explained in the FAQ section.
The workspace can be extended in many ways at runtime, as explained here. However, if you like to customize the workspace image with your own software or configuration, you can do that via a Dockerfile as shown below:
# Extend from any of the workspace versions/flavors
FROM mltooling/ml-workspace:0.13.2
# Run you customizations, e.g.
RUN
# Install r-runtime, r-kernel, and r-studio web server from provided install scripts
/bin/bash $RESOURCES_PATH/tools/r-runtime.sh --install &&
/bin/bash $RESOURCES_PATH/tools/r-studio-server.sh --install &&
# Cleanup Layer - removes unneccessary cache files
clean-layer.shFinally, use docker build to build your customized Docker image.
For a more comprehensive Dockerfile example, take a look at the Dockerfile of the R-flavor.
To update a running workspace instance to a more recent version, the running Docker container needs to be replaced with a new container based on the updated workspace image.
All data within the workspace that is not persisted to a mounted volume will be lost during this update process. As mentioned in the persist data section, a volume is expected to be mounted into the /workspace folder. All tools within the workspace are configured to make use of the /workspace folder as the root directory for all source code and data artifacts. During an update, data within other directories will be removed, including installed/updated libraries or certain machine configurations. We have integrated a backup and restore feature ( CONFIG_BACKUP_ENABLED ) for various selected configuration files/folders, such as the user's Jupyter/VS-Code configuration, ~/.gitconfig , and ~/.ssh .
If the workspace is deployed via Docker (Kubernetes will have a different update process), you need to remove the existing container (via docker rm ) and start a new one (via docker run ) with the newer workspace image. Make sure to use the same configuration, volume, name, and port. For example, a workspace (image version 0.8.7 ) was started with this command:
docker run -d
-p 8080:8080
--name "ml-workspace"
-v "/path/on/host:/workspace"
--env AUTHENTICATE_VIA_JUPYTER="mytoken"
--restart always
mltooling/ml-workspace:0.8.7
and needs to be updated to version 0.9.1 , you need to:
docker stop "ml-workspace" && docker rm "ml-workspace"docker run -d -p 8080:8080 --name "ml-workspace" -v "/path/on/host:/workspace" --env AUTHENTICATE_VIA_JUPYTER="mytoken" --restart always mltooling/ml-workspace:0.9.1 If you want to directly connect to the workspace via a VNC client (not using the noVNC webapp), you might be interested in changing certain VNC server configurations. To configure the VNC server, you can provide/overwrite the following environment variables at container start (via docker run option: --env ):
| Variable | Descripción | Por defecto |
|---|---|---|
| VNC_PW | Password of VNC connection. This password only needs to be secure if the VNC server is directly exposed. If it is used via noVNC, it is already protected based on the configured authentication mechanism. | vncpassword |
| VNC_RESOLUTION | Default desktop resolution of VNC connection. When using noVNC, the resolution will be dynamically adapted to the window size. | 1600x900 |
| VNC_COL_DEPTH | Default color depth of VNC connection. | 24 |
Unfortunately, we currently do not support using a non-root user within the workspace. We plan to provide this capability and already started with some refactoring to allow this configuration. However, this still requires a lot more work, refactoring, and testing from our side.
Using root-user (or users with sudo permission) within containers is generally not recommended since, in case of system/kernel vulnerabilities, a user might be able to break out of the container and be able to access the host system. Since it is not very common to have such problematic kernel vulnerabilities, the risk of a severe attack is quite minimal. As explained in the official Docker documentation, containers (even with root users) are generally quite secure in preventing a breakout to the host. And compared to many other container use-cases, we actually want to provide the flexibility to the user to have control and system-level installation permissions within the workspace container.
The workspace comes preinstalled with various common tools to create isolated Python environments (virtual environments). The following sections provide a quick-intro on how to use these tools within the workspace. You can find information on when to use which tool here. Please refer to the documentation of the given tool for additional usage information.
venv (recommended):
To create a virtual environment via venv, execute the following commands:
# Create environment in the working directory
python -m venv my-venv
# Activate environment in shell
source ./my-venv/bin/activate
# Optional: Create Jupyter kernel for this environment
pip install ipykernel
python -m ipykernel install --user --name=my-venv --display-name= " my-venv ( $( python --version ) ) "
# Optional: Close enviornment session
deactivatepipenv (recommended):
To create a virtual environment via pipenv, execute the following commands:
# Create environment in the working directory
pipenv install
# Activate environment session in shell
pipenv shell
# Optional: Create Jupyter kernel for this environment
pipenv install ipykernel
python -m ipykernel install --user --name=my-pipenv --display-name= " my-pipenv ( $( python --version ) ) "
# Optional: Close environment session
exitvirtualenv :
To create a virtual environment via virtualenv, execute the following commands:
# Create environment in the working directory
virtualenv my-virtualenv
# Activate environment session in shell
source ./my-virtualenv/bin/activate
# Optional: Create Jupyter kernel for this environment
pip install ipykernel
python -m ipykernel install --user --name=my-virtualenv --display-name= " my-virtualenv ( $( python --version ) ) "
# Optional: Close environment session
deactivateconda :
To create a virtual environment via conda, execute the following commands:
# Create environment (globally)
conda create -n my-conda-env
# Activate environment session in shell
conda activate my-conda-env
# Optional: Create Jupyter kernel for this environment
python -m ipykernel install --user --name=my-conda-env --display-name= " my-conda-env ( $( python --version ) ) "
# Optional: Close environment session
conda deactivateTip: Shell Commands in Jupyter Notebooks:
If you install and use a virtual environment via a dedicated Jupyter Kernel and use shell commands within Jupyter (eg !pip install matplotlib ), the wrong python/pip version will be used. To use the python/pip version of the selected kernel, do the following instead:
import sys
!{ sys . executable } - m pip install matplotlibThe workspace provides three easy options to install different Python versions alongside the main Python instance: pyenv, pipenv (recommended), conda.
pipenv (recommended):
To install a different python version (eg 3.7.8 ) within the workspace via pipenv, execute the following commands:
# Install python vers
pipenv install --python=3.7.8
# Activate environment session in shell
pipenv shell
# Check python installation
python --version
# Optional: Create Jupyter kernel for this environment
pipenv install ipykernel
python -m ipykernel install --user --name=my-pipenv --display-name= " my-pipenv ( $( python --version ) ) "
# Optional: Close environment session
exitpyenv :
To install a different python version (eg 3.7.8 ) within the workspace via pyenv, execute the following commands:
# Install python version
pyenv install 3.7.8
# Make globally accessible
pyenv global 3.7.8
# Activate python version in shell
pyenv shell 3.7.8
# Check python installation
python3.7 --version
# Optional: Create Jupyter kernel for this python version
python3.7 -m pip install ipykernel
python3.7 -m ipykernel install --user --name=my-pyenv-3.7.8 --display-name= " my-pyenv (Python 3.7.8) "conda :
To install a different python version (eg 3.7.8 ) within the workspace via conda, execute the following commands:
# Create environment with python version
conda create -n my-conda-3.7 python=3.7.8
# Activate environment session in shell
conda activate my-conda-3.7
# Check python installation
python --version
# Optional: Create Jupyter kernel for this python version
pip install ipykernel
python -m ipykernel install --user --name=my-conda-3.7 --display-name= " my-conda ( $( python --version ) ) "
# Optional: Close environment session
conda deactivateTip: Shell Commands in Jupyter Notebooks:
If you install and use another Python version via a dedicated Jupyter Kernel and use shell commands within Jupyter (eg !pip install matplotlib ), the wrong python/pip version will be used. To use the python/pip version of the selected kernel, do the following instead:
import sys
!{ sys . executable } - m pip install matplotlib Certain desktop tools (eg, recent versions of Firefox) or libraries (eg, Pytorch - see Issues: 1, 2) might crash if the shared memory size ( /dev/shm ) is too small. The default shared memory size of Docker is 64MB, which might not be enough for a few tools. You can provide a higher shared memory size via the shm-size docker run option:
docker run --shm-size=2G mltooling/ml-workspace:0.13.2 In general, the performance of running code within Docker is nearly identical compared to running it directly on the machine. However, in case you have limited the container's CPU quota (as explained in this section), the container can still see the full count of CPU cores available on the machine and there is no technical way to prevent this. Many libraries and tools will use the full CPU count (eg, via os.cpu_count() ) to set the number of threads used for multiprocessing/-threading. This might cause the program to start more threads/processes than it can efficiently handle with the available CPU quota, which can tremendously slow down the overall performance. Therefore, it is important to set the available CPU count or the maximum number of threads explicitly to the configured CPU quota. The workspace provides capabilities to detect the number of available CPUs automatically, which are used to configure a variety of common libraries via environment variables such as OMP_NUM_THREADS or MKL_NUM_THREADS . It is also possible to explicitly set the number of available CPUs at container startup via the MAX_NUM_THREADS environment variable (see configuration section). The same environment variable can also be used to get the number of available CPUs at runtime.
Even though the automatic configuration capabilities of the workspace will fix a variety of inefficiencies, we still recommend configuring the number of available CPUs with all libraries explicitly. Por ejemplo:
import os
MAX_NUM_THREADS = int ( os . getenv ( "MAX_NUM_THREADS" ))
# Set in pytorch
import torch
torch . set_num_threads ( MAX_NUM_THREADS )
# Set in tensorflow
import tensorflow as tf
config = tf . ConfigProto (
device_count = { "CPU" : MAX_NUM_THREADS },
inter_op_parallelism_threads = MAX_NUM_THREADS ,
intra_op_parallelism_threads = MAX_NUM_THREADS ,
)
tf_session = tf . Session ( config = config )
# Set session for keras
import keras . backend as K
K . set_session ( tf_session )
# Set in sklearn estimator
from sklearn . linear_model import LogisticRegression
LogisticRegression ( n_jobs = MAX_NUM_THREADS ). fit ( X , y )
# Set for multiprocessing pool
from multiprocessing import Pool
with Pool ( MAX_NUM_THREADS ) as pool :
results = pool . map ( lst )If you encounter the following error within the container logs when starting the workspace, it will most likely not be possible to run the workspace on your hardware:
exited: nginx (terminated by SIGILL (core dumped); not expected)
The OpenResty/Nginx binary package used within the workspace requires to run on a CPU with SSE4.2 support (see this issue). Unfortunately, some older CPUs do not have support for SSE4.2 and, therefore, will not be able to run the workspace container. On Linux, you can check if your CPU supports SSE4.2 when looking into the cat /proc/cpuinfo flags section. If you encounter this problem, feel free to notify us by commenting on the following issue: #30.
Requirements : Docker and Act are required to be installed on your machine to execute the build process.
To simplify the process of building this project from scratch, we provide build-scripts - based on universal-build - that run all necessary steps (build, test, and release) within a containerized environment. To build and test your changes, execute the following command in the project root folder:
act -b -j buildUnder the hood it uses the build.py files in this repo based on the universal-build library. So, if you want to build it locally, you can also execute this command in the project root folder to build the docker container:
python build.py --makeFor additional script options:
python build.py --helpRefer to our contribution guides for more detailed information on our build scripts and development process.
Licensed Apache 2.0 . Created and maintained with ❤️ by developers from Berlin.


