ml workspace
0.13.2

Ambiente de Desenvolvimento Baseado na Web para aprendizado de máquina para aprendizado de máquina
Introdução • Recursos e capturas de tela • Suporte • Relate um bug • Perguntas frequentes • Problemas conhecidos • Contribuição
O ML Workspace é um IDE baseado na Web, especializado em aprendizado de máquina e ciência de dados. É simples de implantar e você inicia em minutos para obter soluções de ML produtivamente construídas em suas próprias máquinas. Este espaço de trabalho é a ferramenta definitiva para desenvolvedores pré -carregados com uma variedade de bibliotecas de ciências de dados populares (por exemplo, Tensorflow, Pytorch, Keras, Sklearn) e ferramentas de desenvolvimento (por exemplo, Jupyter, vs código, Tensorboard) perfeitamente configuradas, otimizadas e integradas.
O espaço de trabalho exige que o Docker seja instalado em sua máquina (guia de instalação).
A implantação de uma única instância do espaço de trabalho é tão simples quanto:
docker run -p 8080:8080 mltooling/ml-workspace:0.13.2Voilà, isso foi fácil! Agora, o Docker puxará a imagem mais recente do espaço de trabalho para sua máquina. Isso pode levar alguns minutos, dependendo da sua velocidade da Internet. Depois que o espaço de trabalho for iniciado, você pode acessá -lo via http: // localhost: 8080.
Se iniciado em outra máquina ou com uma porta diferente, use o IP/DNS da máquina e/ou a porta exposta.
Para implantar uma única instância para uso produtivo, recomendamos aplicar pelo menos as seguintes opções:
docker run -d
-p 8080:8080
--name " ml-workspace "
-v " ${PWD} :/workspace "
--env AUTHENTICATE_VIA_JUPYTER= " mytoken "
--shm-size 512m
--restart always
mltooling/ml-workspace:0.13.2 This command runs the container in background ( -d ), mounts your current working directory into the /workspace folder ( -v ), secures the workspace via a provided token ( --env AUTHENTICATE_VIA_JUPYTER ), provides 512MB of shared memory ( --shm-size ) to prevent unexpected crashes (see known issues section), and keeps the container running even on system restarts ( --restart always ). Você pode encontrar opções adicionais para o Docker Run aqui e as opções de configuração da área de trabalho na seção abaixo.
O espaço de trabalho fornece uma variedade de opções de configuração que podem ser usadas definindo variáveis de ambiente (via opção de execução do Docker: --env ).
| Variável | Descrição | Padrão |
|---|---|---|
| Workspace_base_url | O URL base sob o qual Jupyter e todas as outras ferramentas serão acessíveis. | / |
| Workspace_ssl_enabled | Ativar ou desativar SSL. Quando definido como true, o certificado (cert.crt) deve ser montado para /resources/ssl ou, se não, o contêiner gera certificado autoassinado. | falso |
| Workspace_auth_user | Nome de usuário básico de autenticação. Para ativar a autenticação básica, o usuário e a senha precisam ser definidos. Recomendamos usar o AUTHENTICATE_VIA_JUPYTER para proteger o espaço de trabalho. | |
| Workspace_auth_password | Senha básica de usuário de autenticação. Para ativar a autenticação básica, o usuário e a senha precisam ser definidos. Recomendamos usar o AUTHENTICATE_VIA_JUPYTER para proteger o espaço de trabalho. | |
| Workspace_port | Configura a porta principal interna do contêiner do proxy da área de trabalho. Para a maioria dos cenários, essa configuração não deve ser alterada e a configuração da porta via docker deve ser usada em vez da área de trabalho deve estar acessível a partir de uma porta diferente. | 8080 |
| Config_backup_enabled | Backup automaticamente e restaure a configuração do usuário para a pasta persistida /workspace , como o .ssh, .Jupyter ou .gitConfig do diretório inicial dos usuários. | verdadeiro |
| Shared_links_enabled | Habilite ou desative a capacidade de compartilhar recursos por meio de links externos. Isso é usado para ativar o compartilhamento de arquivos, acesso a portas internas da área de trabalho e fácil configuração SSH baseada em comando. Todos os links compartilhados são protegidos por meio de um token. No entanto, existem certos riscos, pois o token não pode ser facilmente invalidado após o compartilhamento e não expira. | verdadeiro |
| Incluir_tutorials | Se true , uma seleção de notebooks de tutorial e introdução é adicionada à pasta /workspace na inicialização do contêiner, mas apenas se a pasta estiver vazia. | verdadeiro |
| Max_num_threads | O número de threads usados para cálculos ao usar várias bibliotecas comuns (MKL, OpenBlas, OMP, numba, ...). Você também pode usar auto para permitir que o espaço de trabalho determine dinamicamente o número de threads com base nos recursos da CPU disponíveis. Essa configuração pode ser substituída pelo usuário dentro da área de trabalho. Geralmente, é bom configurá -lo no número ou abaixo do número de CPUs disponíveis para o espaço de trabalho. | auto |
| Configuração de Jupyter: | ||
| Shutdown_inactive_kernels | Desligue automaticamente os kernels inativos após um determinado tempo limite (para limpar a memória ou os recursos da GPU). O valor pode ser um tempo limite em segundos ou definido como true com um valor padrão de 48h. | falso |
| Autenticate_via_jupyter | Se true , todas as solicitações HTTP serão autenticadas contra o servidor Jupyter, o que significa que o método de autenticação configurado com Jupyter também será usado para todas as outras ferramentas. Isso pode ser desativado com false . Qualquer outro valor ativará essa autenticação e será aplicado como token via notebookapp.token configuration of Jupyter. | falso |
| Notebook_args | Adicione e substitua as opções de configuração Jupyter via linha de comando args. Consulte esta visão geral para todas as opções. | |
Para persistir os dados, você precisa montar um volume no /workspace (via opção de execução do Docker: -v ).
O diretório de trabalho padrão dentro do contêiner é /workspace , que também é o diretório raiz da instância de Jupyter. O diretório /workspace deve ser usado para todos os artefatos de trabalho importantes. Os dados em outros diretórios do servidor (por exemplo, /root ) podem se perder nas reinicializações de contêineres.
Recomendamos fortemente permitir a autenticação por meio de uma das duas opções a seguir. Para ambas as opções, o usuário deverá autenticar para acessar qualquer uma das ferramentas pré-instaladas.
A autenticação funciona apenas para todas as ferramentas acessadas através da porta principal da área de trabalho (padrão:
8080). Isso funciona para todas as ferramentas pré -instaladas e o recurso de portas de acesso. Se você expõe outra porta do contêiner, certifique -se de protegê -lo com autenticação também!
Ative a autenticação baseada em token com base na implementação de autenticação de Jupyter através da variável AUTHENTICATE_VIA_JUPYTER :
docker run -p 8080:8080 --env AUTHENTICATE_VIA_JUPYTER= " mytoken " mltooling/ml-workspace:0.13.2 Você também pode usar <generated> para deixar Jupyter gerar um token aleatório impresso nos logs do contêiner. Um valor do true não definirá nenhum token, mas ativará que todas as solicitações para qualquer ferramenta no espaço de trabalho serão verificadas com a instância de Jupyter se o usuário for autenticado. Isso é usado para ferramentas como o JupyterHub, que configura sua própria maneira de autenticação.
Ative a autenticação básica através da variável WORKSPACE_AUTH_USER e WORKSPACE_AUTH_PASSWORD :
docker run -p 8080:8080 --env WORKSPACE_AUTH_USER= " user " --env WORKSPACE_AUTH_PASSWORD= " pwd " mltooling/ml-workspace:0.13.2 A autenticação básica é configurada através do proxy nginx e pode ser mais executada em comparação com a outra opção, pois com AUTHENTICATE_VIA_JUPYTER todas as solicitações para qualquer ferramenta no espaço de trabalho verificarão através da instância Jupyter se o usuário (com base nos cookies de solicitação) for autenticado.
Recomendamos ativar o SSL para que o espaço de trabalho seja acessível via HTTPS (comunicação criptografada). A criptografia SSL pode ser ativada através da variável WORKSPACE_SSL_ENABLED .
Quando definido como true , o arquivo cert.crt e cert.key deve ser montado para /resources/ssl ou, se os arquivos de certificado não existirem, o contêiner gerará certificados autoassinados. Por exemplo, se o /path/with/certificate/files no sistema local contiver um certificado válido para o domínio do host (arquivo cert.crt e cert.key ), ele poderá ser usado na área de trabalho, como mostrado abaixo:
docker run
-p 8080:8080
--env WORKSPACE_SSL_ENABLED= " true "
-v /path/with/certificate/files:/resources/ssl:ro
mltooling/ml-workspace:0.13.2 Se você deseja hospedar o espaço de trabalho em um domínio público, recomendamos usar o Let's Encrypt para obter um certificado confiável para o seu domínio. Para usar o certificado gerado (por exemplo, via ferramenta certbot) para o espaço de trabalho, o privkey.pem corresponde ao arquivo cert.key e ao arquivo fullchain.pem ao arquivo cert.crt .
Ao ativar o suporte SSL, você deve acessar o espaço de trabalho em
https://, não sobrehttp://.
Por padrão, o contêiner da área de trabalho não possui restrições de recursos e pode usar o máximo de um determinado recurso que o agendador de kernel do host permitir. O Docker fornece maneiras de controlar a quantidade de memória, ou CPU, um contêiner pode usar, configurando sinalizadores de configuração de tempo de execução do comando run do docker.
O espaço de trabalho requer pelo menos 2 CPUs e 500 MB para executar estáveis e ser utilizáveis.
Por exemplo, o comando a seguir restringe o espaço de trabalho a usar apenas um máximo de 8 CPUs, 16 GB de memória e 1 GB de memória compartilhada (ver questões conhecidas):
docker run -p 8080:8080 --cpus=8 --memory=16g --shm-size=1G mltooling/ml-workspace:0.13.2Para obter mais opções e documentação sobre restrições de recursos, consulte o guia oficial do Docker.
Se for necessário um proxy, você poderá passar a configuração de proxy por meio das variáveis de ambiente HTTP_PROXY , HTTPS_PROXY e NO_PROXY .
Além da imagem principal da área de trabalho ( mltooling/ml-workspace ), fornecemos outros sabores de imagem que estendem os recursos ou minimizam o tamanho da imagem para suportar uma variedade de casos de uso.
O sabor mínimo ( mltooling/ml-workspace-minimal ) é a nossa menor imagem que contém a maioria das ferramentas e recursos descritos na seção Recursos sem a maioria das bibliotecas Python que são pré-instaladas em nossa imagem principal. Qualquer biblioteca Python ou ferramenta excluída pode ser instalada manualmente durante o tempo de execução pelo usuário.
docker run -p 8080:8080 mltooling/ml-workspace-minimal:0.13.2 O sabor R ( mltooling/ml-workspace-r ) é baseado em nossa imagem padrão do espaço de trabalho e a estende com o interpregador R, R-Jupyter Kernel, RStudio Server (Access via Open Tool -> RStudio ) e uma variedade de pacotes populares do sistema R R.
docker run -p 8080:8080 mltooling/ml-workspace-r:0.12.1 O Spark Flavor ( mltooling/ml-workspace-spark ) é baseado em nossa imagem de espaço de trabalho com sabor R e a estende com o Spark Runtime, Kernel Jupyter, notebook Zeppelin (Acesso através da Open Tool -> Zeppelin ), Pyspark, Hadoop, Java KernEl, e poucos Libraries e Jenstern), Java Ferties e Libraries e Librariças adicionais), Java, Hadoop, Java KernEl, e poucas Libraries & Jeppelin), Java, Hadoop.
docker run -p 8080:8080 mltooling/ml-workspace-spark:0.12.1Atualmente, o sabor da GPU suporta apenas o CUDA 11.2. O suporte a outras versões do CUDA pode ser adicionado no futuro.
O sabor da GPU ( mltooling/ml-workspace-gpu ) é baseado em nossa imagem padrão do espaço de trabalho e a estende com versões prontas para CUDA 10.1 e GPU de várias bibliotecas de aprendizado de máquina (por exemplo, tensorflow, pytorch, CNTK, JAX). Esta imagem da GPU possui os seguintes requisitos adicionais para o sistema:
>=460.32.03 (instruções).docker run -p 8080:8080 --gpus all mltooling/ml-workspace-gpu:0.13.2docker run -p 8080:8080 --runtime nvidia --env NVIDIA_VISIBLE_DEVICES= " all " mltooling/ml-workspace-gpu:0.13.2O sabor da GPU também vem com algumas opções de configuração adicionais, conforme explicado abaixo:
| Variável | Descrição | Padrão |
|---|---|---|
| Nvidia_visible_devices | Controles quais GPUs estarão acessíveis dentro da área de trabalho. Por padrão, todas as GPUs do host estão acessíveis no espaço de trabalho. Você pode usar all , none ou especificar uma lista separada por vírgula de IDs de dispositivo (por exemplo, 0,1 ). Você pode descobrir a lista de IDs de dispositivo disponíveis executando nvidia-smi na máquina host. | todos |
| Cuda_visible_devices | Controla quais aplicativos GPUs CUDA em execução no espaço de trabalho verão. Por padrão, todas as GPUs a que o espaço de trabalho tem acesso será visível. Para restringir os aplicativos, forneça uma lista separada por vírgula dos IDs internos do dispositivo (por exemplo, 0,2 ) com base nos dispositivos disponíveis na área de trabalho (execute nvidia-smi ). Em comparação com NVIDIA_VISIBLE_DEVICES , o usuário do espaço de trabalho ainda poderá acessar outras GPUs, substituindo essa configuração dentro da área de trabalho. | |
| Tf_force_gpu_allow_growth | Por padrão, a maioria da memória da GPU será alocada pela primeira execução de um gráfico de tensorflow. Embora esse comportamento possa ser desejável para pipelines de produção, é menos desejável para uso interativo. Use true para ativar a alocação dinâmica de memória da GPU ou false para instruir o tensorflow a alocar toda a memória na execução. | verdadeiro |
O espaço de trabalho é projetado como um ambiente de desenvolvimento de um usuário único. Para uma configuração de vários usuários, recomendamos a implantação? ML Hub. O ML Hub é baseado no JupyterHub com a tarefa de gerar, gerenciar e proxy, instâncias de espaço de trabalho para vários usuários.
O ML Hub facilita a configuração de um ambiente multiusuário em um único servidor (via Docker) ou um cluster (via Kubernetes) e suporta uma variedade de cenários de uso e provedores de autenticação. Você pode experimentar o ML Hub via:
docker run -p 8080:8080 -v /var/run/docker.sock:/var/run/docker.sock mltooling/ml-hub:latestPara obter mais informações e documentação sobre o ML Hub, consulte o site do GitHub.
Este projeto é mantido por Benjamin Räthlein, Lukas Masuch e Jan Kalkan. Por favor, entenda que não poderemos fornecer suporte individual por e -mail. Também acreditamos que a ajuda é muito mais valiosa se for compartilhada publicamente para que mais pessoas possam se beneficiar disso.
| Tipo | Canal |
|---|---|
| Relatórios de bug | |
| ? Solicitações de recursos | |
| ? Perguntas de uso | |
| ? Anúncios | |
| ❓ Outras solicitações |
Jupyter • GUI da área de trabalho • Código vs • Jupyterlab • Integração do Git • Compartilhamento de arquivos • Portas de acesso • Tensorboard • Extensibilidade • Monitoramento de hardware • Acesso SSH • Desenvolvimento remoto • Execução de empregos
O espaço de trabalho está equipado com uma seleção das melhores ferramentas de desenvolvimento de código aberto para ajudar no fluxo de trabalho de aprendizado de máquina. Muitas dessas ferramentas podem ser iniciadas no menu Open Tool da Jupyter (o aplicativo principal da área de trabalho):
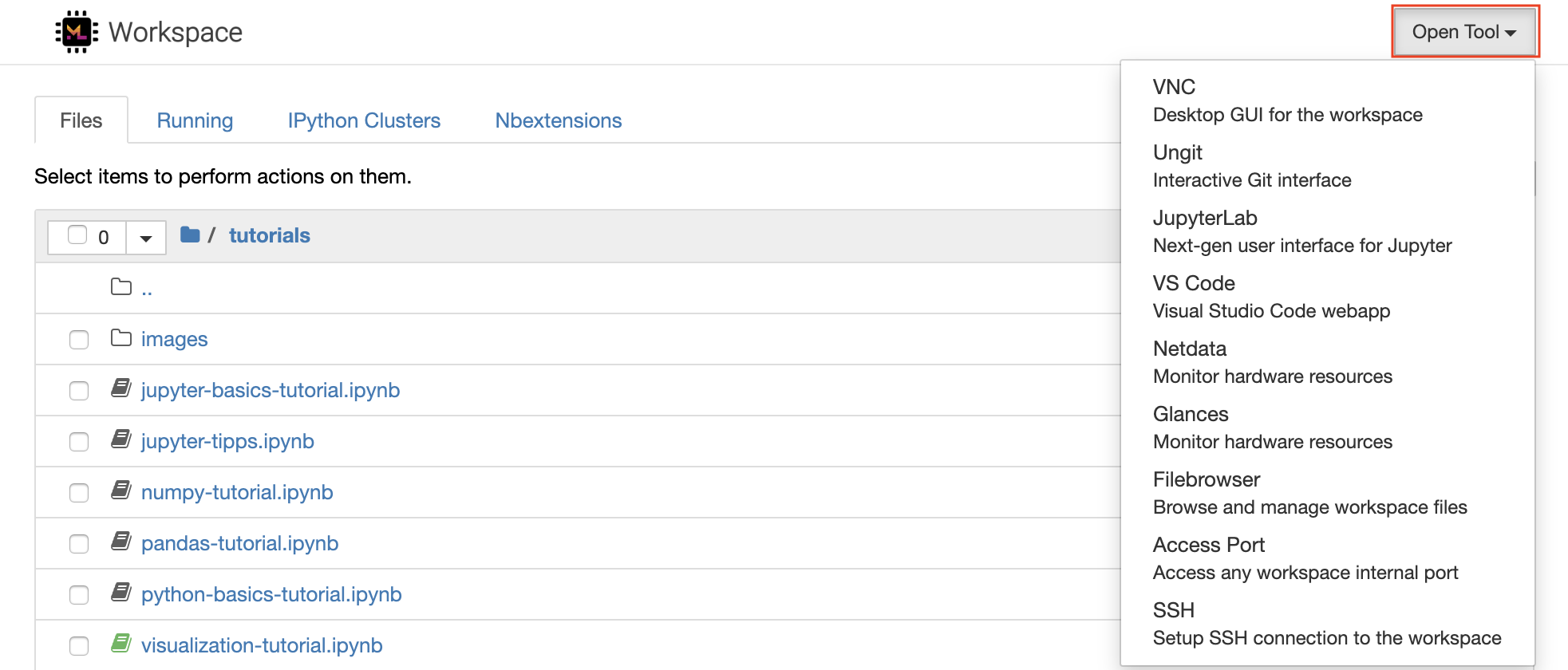
No seu espaço de trabalho, você tem privilégios completos de raiz e sudo para instalar qualquer biblioteca ou ferramenta necessária via terminal (por exemplo,
pip,apt-get,condaounpm). Você pode encontrar mais maneiras de estender o espaço de trabalho dentro da seção de extensibilidade
O Jupyter Notebook é um ambiente interativo baseado na Web para escrever e executar o código. Os principais blocos de construção de Jupyter são o navegador de arquivos, o editor de notebooks e os kernels. O navegador de arquivos fornece um gerenciador de arquivos interativo para todos os notebooks, arquivos e pastas no diretório /workspace .
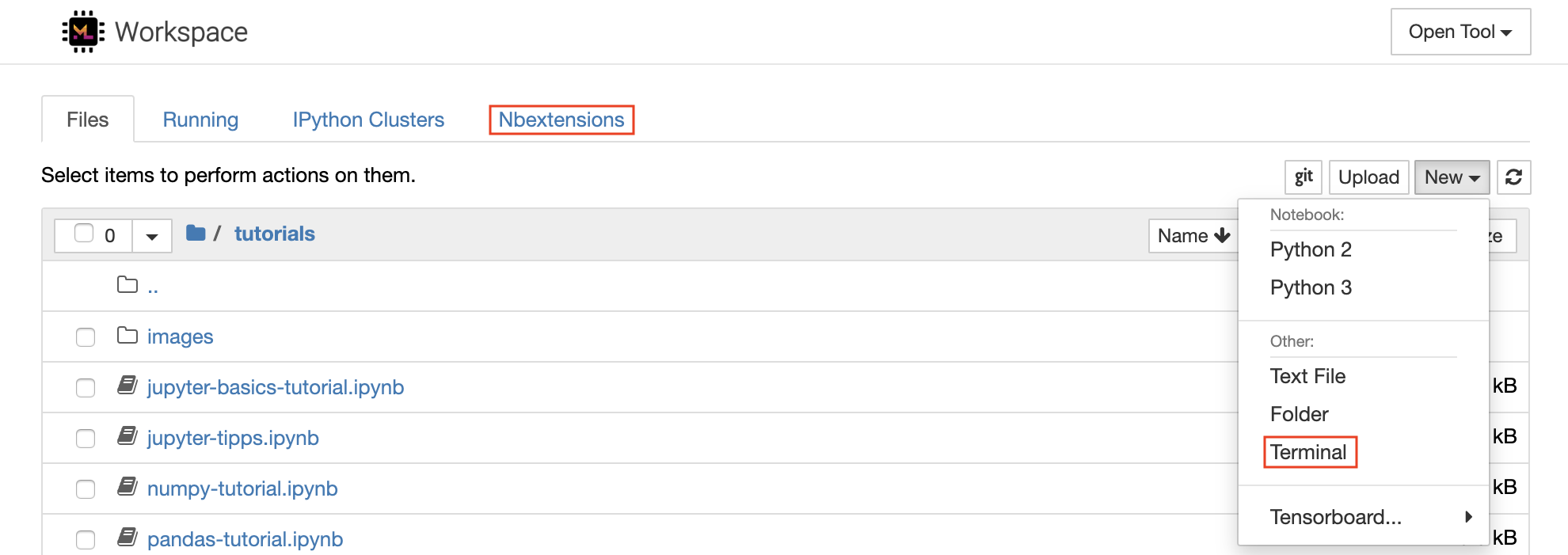
Um novo caderno pode ser criado clicando no New botão suspenso na parte superior da lista e selecionando o kernel de idioma desejado.
Você também pode gerar instâncias interativas do terminal , selecionando
New -> Terminalno navegador de arquivos.
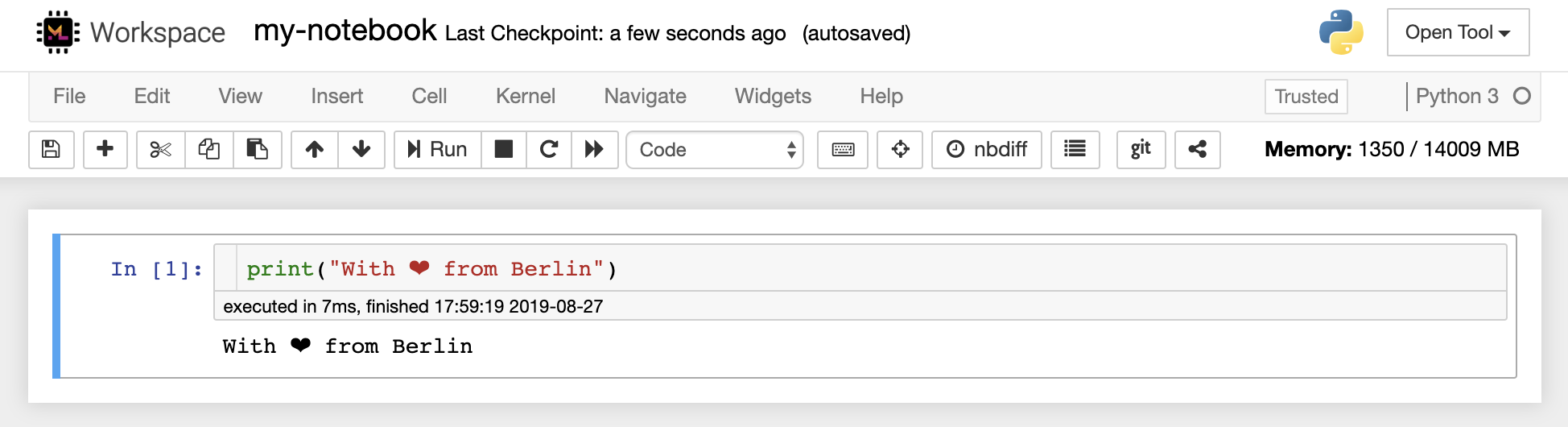
O editor de notebook permite que os usuários dos autores que incluem código ao vivo, texto de marcação, comandos do shell, equações de látex, widgets interativos, gráficos e imagens. Esses documentos de notebook fornecem um registro completo e independente de um cálculo que pode ser convertido em vários formatos e compartilhado com outras pessoas.
Este espaço de trabalho tem uma variedade de extensões de Jupyter de terceiros ativadas. Você pode configurar essas extensões na guia Nbextensions Configurator:
nbextensionsno navegador do arquivo
O notebook permite que o código seja executado em uma variedade de diferentes linguagens de programação. Para cada documento de notebook que um usuário é aberto, o aplicativo da Web inicia um kernel que executa o código para esse notebook e retorna a saída. Este espaço de trabalho tem um kernel Python 3 pré-instalado. Os kernels adicionais podem ser instalados para obter acesso a outros idiomas (por exemplo, r, scala, go) ou recursos de computação adicionais (por exemplo, GPUs, CPUs, memória).
O Python 2 é depreciado e não recomendamos usá -lo. No entanto, você ainda pode instalar um kernel python 2.7 através deste comando:
/bin/bash /resources/tools/python-27.sh
Este espaço de trabalho fornece um acesso VNC baseado em HTTP ao espaço de trabalho via NOVNC. Assim, você pode acessar e trabalhar dentro do espaço de trabalho com uma GUI de desktop totalmente caracterizada. Para acessar esta GUI da área de trabalho, vá para Open Tool , selecione VNC e clique no botão Connect . No caso, você solicita uma senha, use vncpassword .
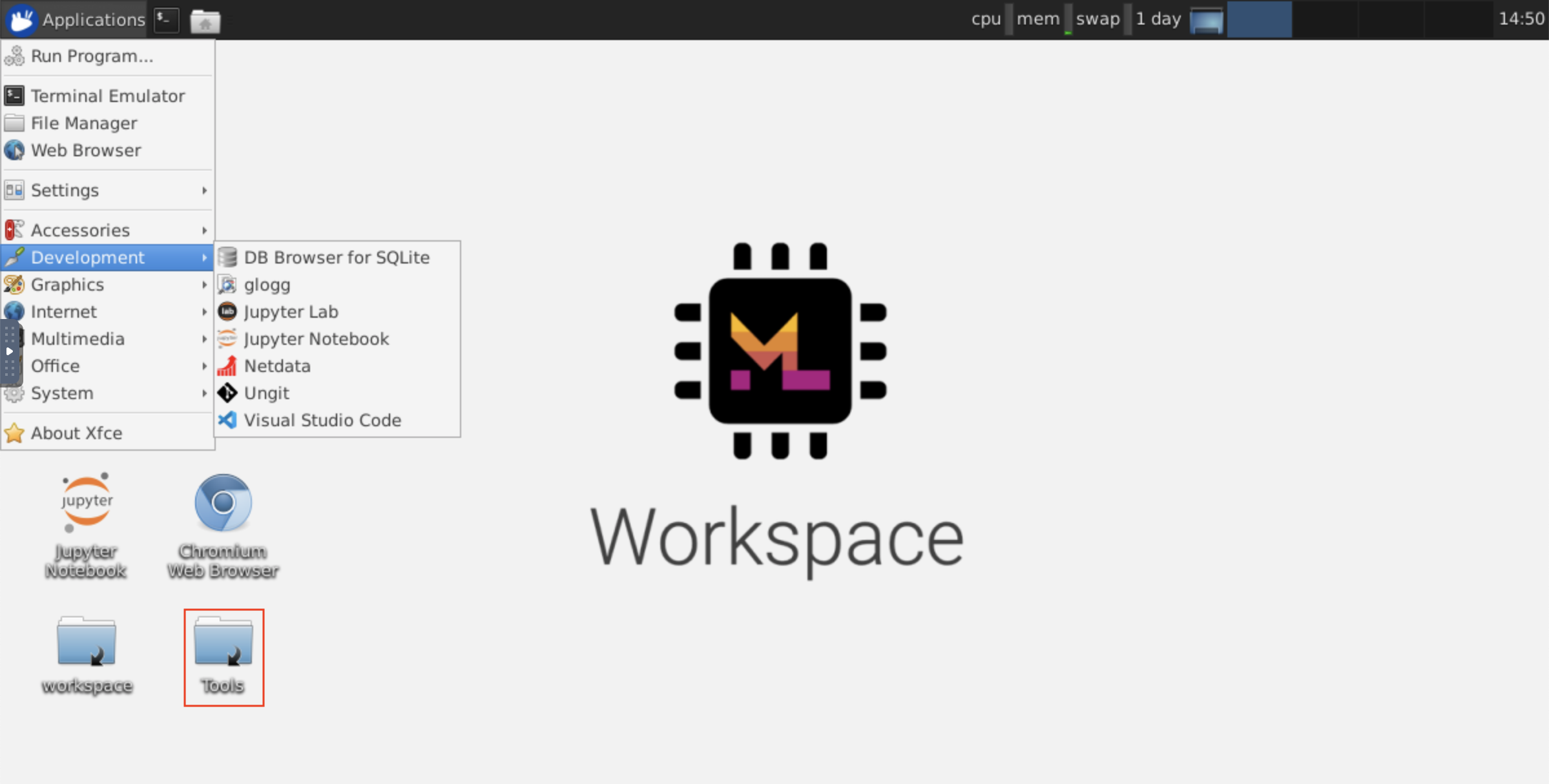
Depois de estar conectado, você verá uma GUI da área de trabalho que permite instalar e usar navegadores da Web completos ou qualquer outra ferramenta disponível para o Ubuntu. Na pasta Tools na área de trabalho, você encontrará uma coleção de scripts de instalação que o torna simples instalar algumas das ferramentas de desenvolvimento mais usadas, como Atom, PyCharm, Runtime, R-Studio ou Postman (basta clicar duas vezes no script).
Armadora: se você deseja compartilhar a área de transferência entre sua máquina e o espaço de trabalho, poderá usar a funcionalidade de cola de cópia conforme descrito abaixo:
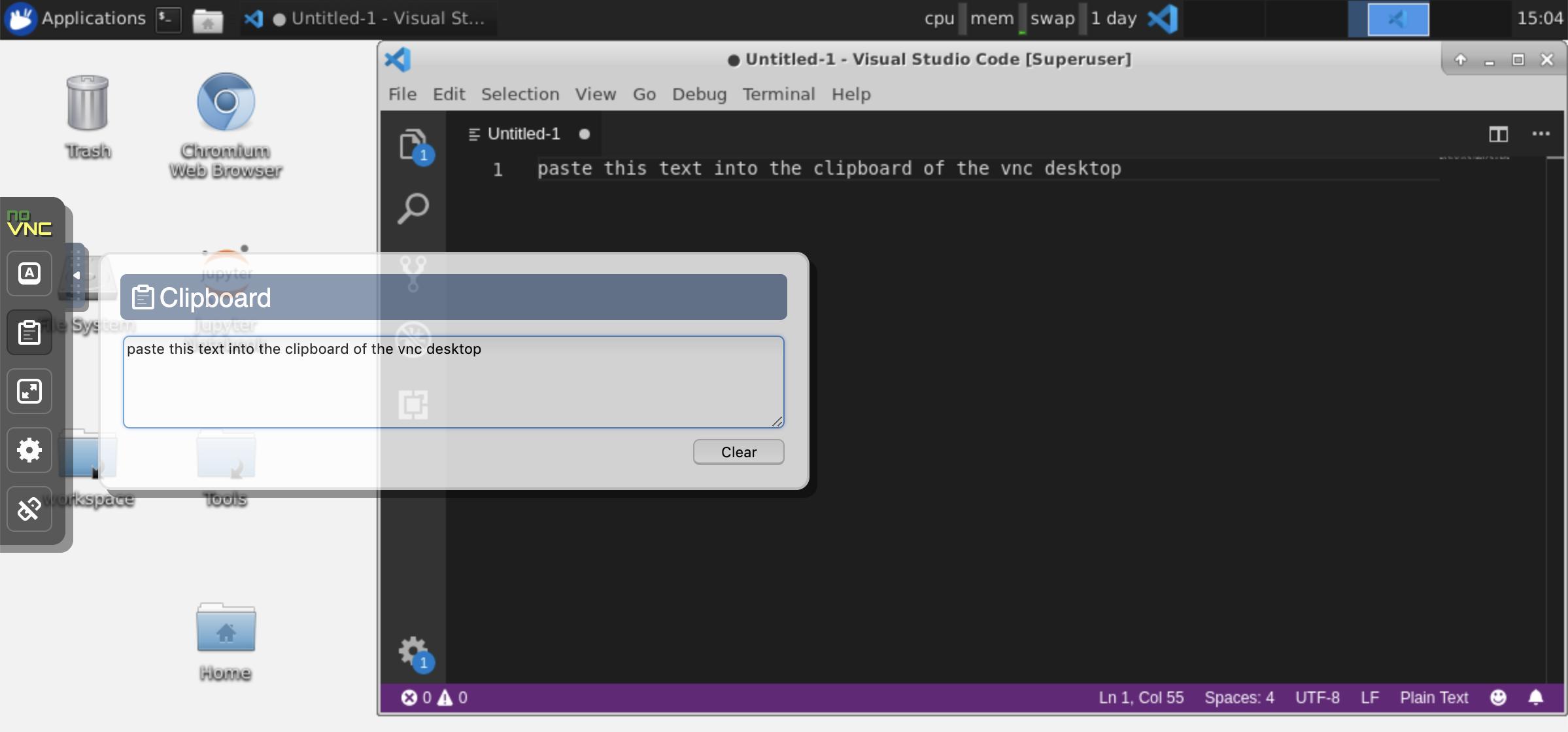
Tarefas de longa duração: use a GUI da área de trabalho para execuções de Jupyter de longa data. Ao executar notebooks do navegador da sua GUI da área de trabalho, toda a saída será sincronizada com o notebook, mesmo que você tenha desconectado o navegador do notebook.
O Código do Visual Studio ( Open Tool -> VS Code ) é um editor de código leve, mas poderoso de código aberto, com suporte interno para uma variedade de idiomas e um rico ecossistema de extensões. Ele combina a simplicidade de um editor de código -fonte com poderosas ferramentas de desenvolvedor, como a conclusão e a depuração do código Intellisense. O espaço de trabalho integra o código VS como um aplicativo baseado na Web acessível através do navegador baseado no incrível projeto de código-servidor. Ele permite que você personalize todos os recursos do seu gosto e instale qualquer número de extensões de terceiros.
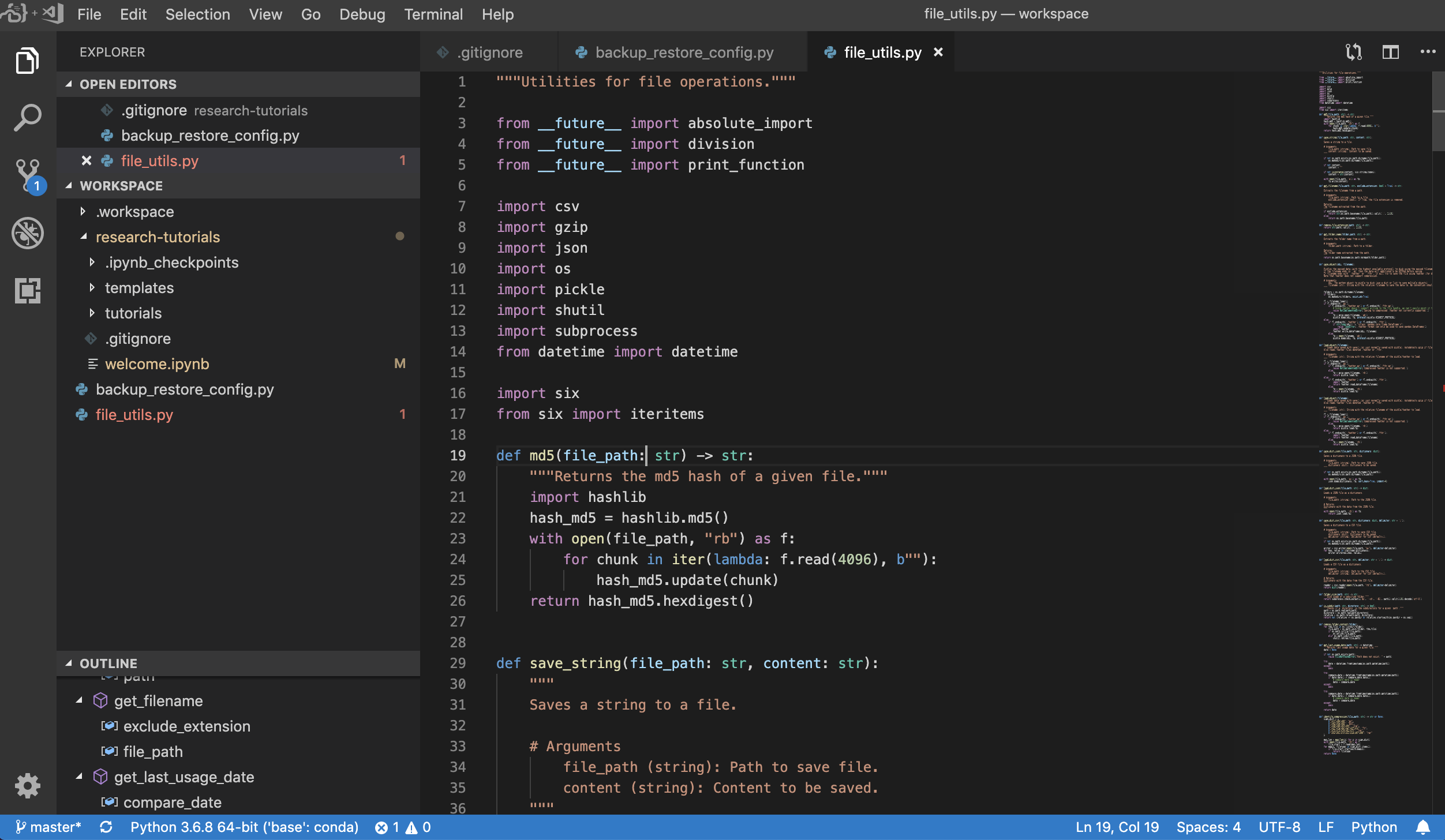
O espaço de trabalho também fornece uma integração de código VS no Jupyter, permitindo que você abra uma instância do código VS para qualquer pasta selecionada, como mostrado abaixo:

JupyterLab ( Open Tool -> JupyterLab ) é a interface de usuário da próxima geração do Project Jupyter. Ele oferece todos os blocos de construção familiar do Classic Jupyter Notebook (notebook, terminal, editor de texto, navegador de arquivos, saídas ricas, etc.) em uma interface de usuário flexível e poderosa. Esta instância do Jupyterlab é pré-instalada com algumas extensões úteis, como um Jupyterlab-toc, Jupyterlab-Git e Juptyterlab-tensorboard.
O controle da versão é um aspecto crucial da colaboração produtiva. Para tornar esse processo o mais suave possível, integramos uma extensão de Jupyter feita personalizada especializada em empurrar notebooks únicos, um cliente Git (Ungit) baseado na Web (UNGIT), uma ferramenta para abrir e editar documentos de texto simples (por exemplo, .py , .md ) como notebooks (jupyText), além de uma ferramenta de fusão de cadernos (nb). Além disso, o JupyterLab e o Code VS também fornecem clientes Git baseados na GUI.
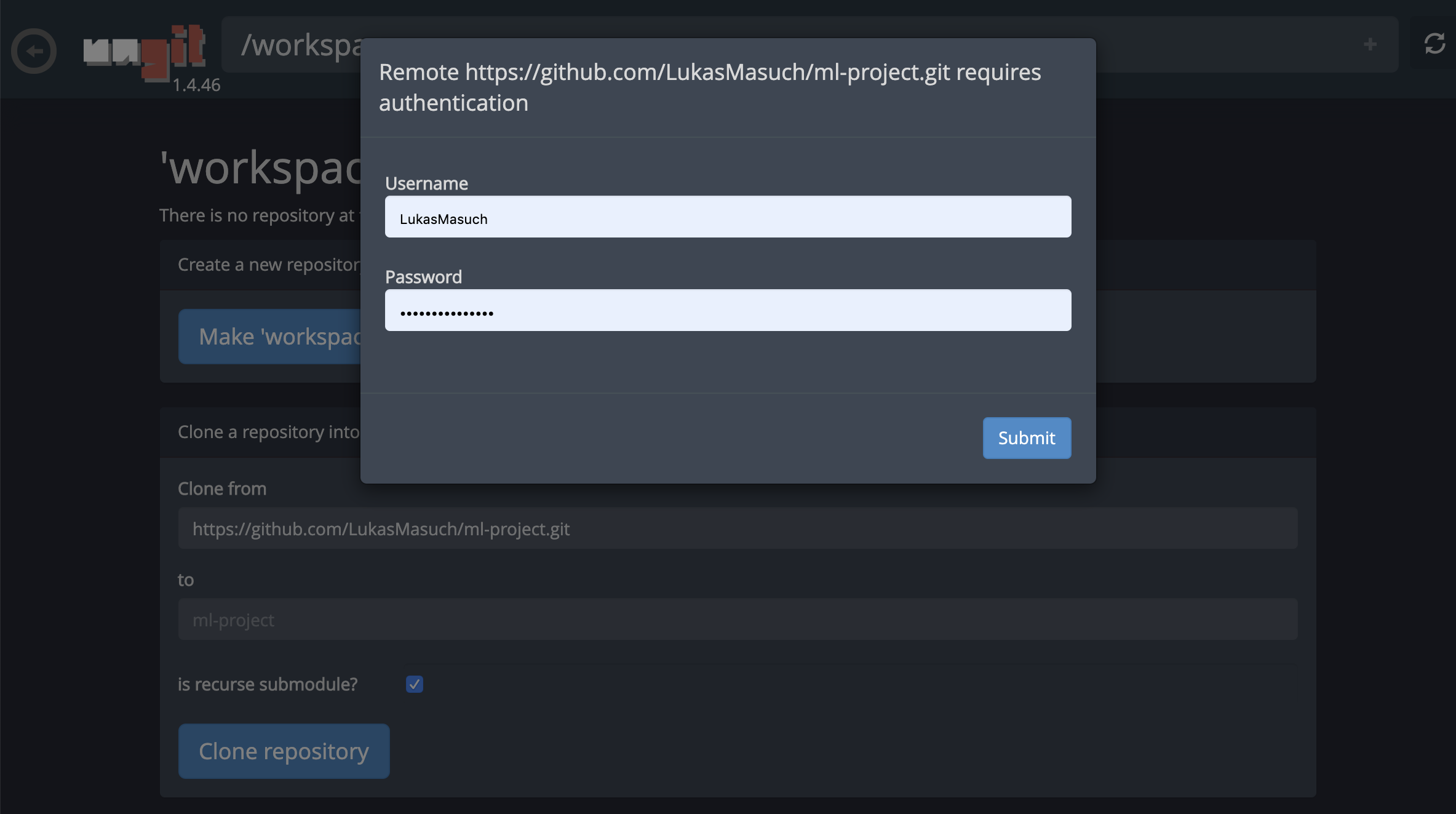
Para repositórios de clonagem via https , recomendamos navegar para a pasta raiz desejada e clicar no botão git , como mostrado abaixo:

Isso pode solicitar algumas configurações necessárias e, posteriormente, abre o Ungit, um cliente Git baseado na Web com uma interface do usuário limpa e intuitiva que torna conveniente sincronizar seus artefatos de código. No Ungit, você pode clonar qualquer repositório. Se for necessária autenticação, você será solicitado suas credenciais.
Para comprometer e empurrar um único notebook para um repositório Git remoto, recomendamos usar o plug -in Git integrado ao Jupyter, como mostrado abaixo:
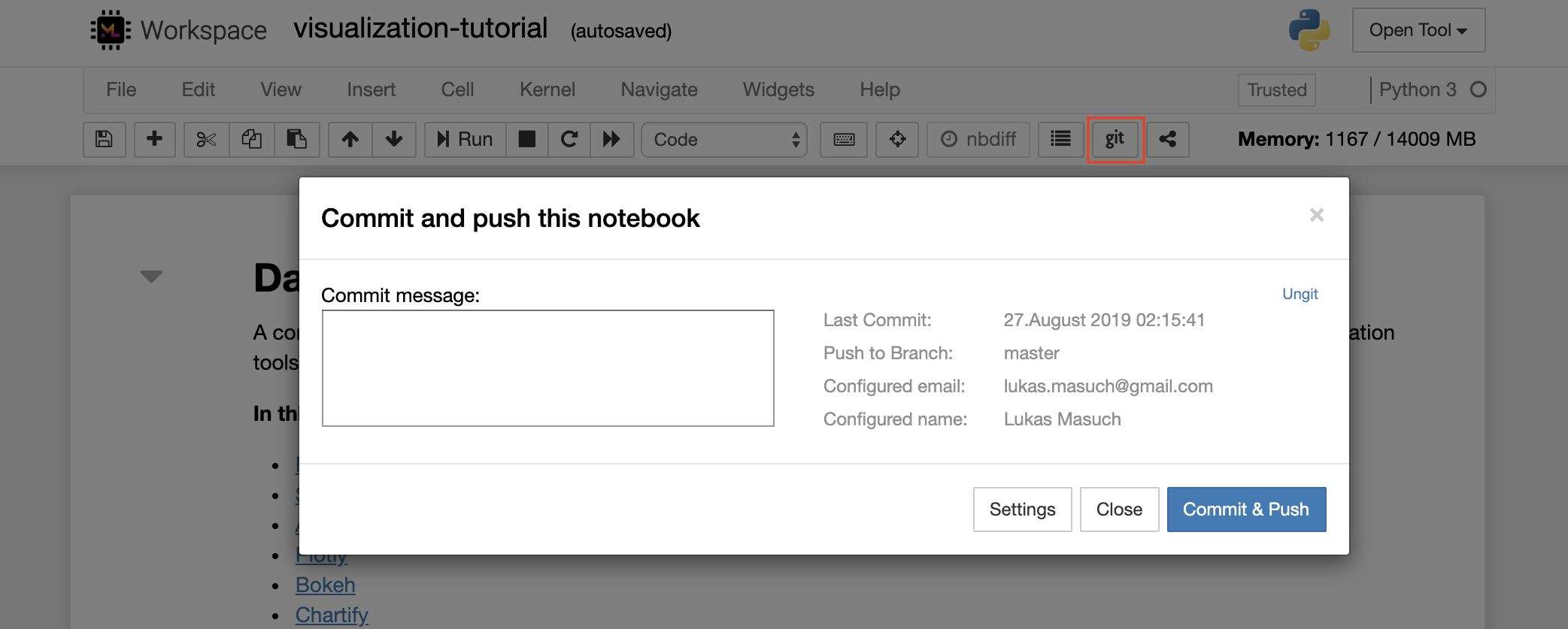
Para operações Git mais avançadas, recomendamos usar o Ungit. Com o Ungit, você pode fazer a maioria das ações comuns do GIT, como push, pule, mescla, ramificação, etiqueta, checkout e muito mais.
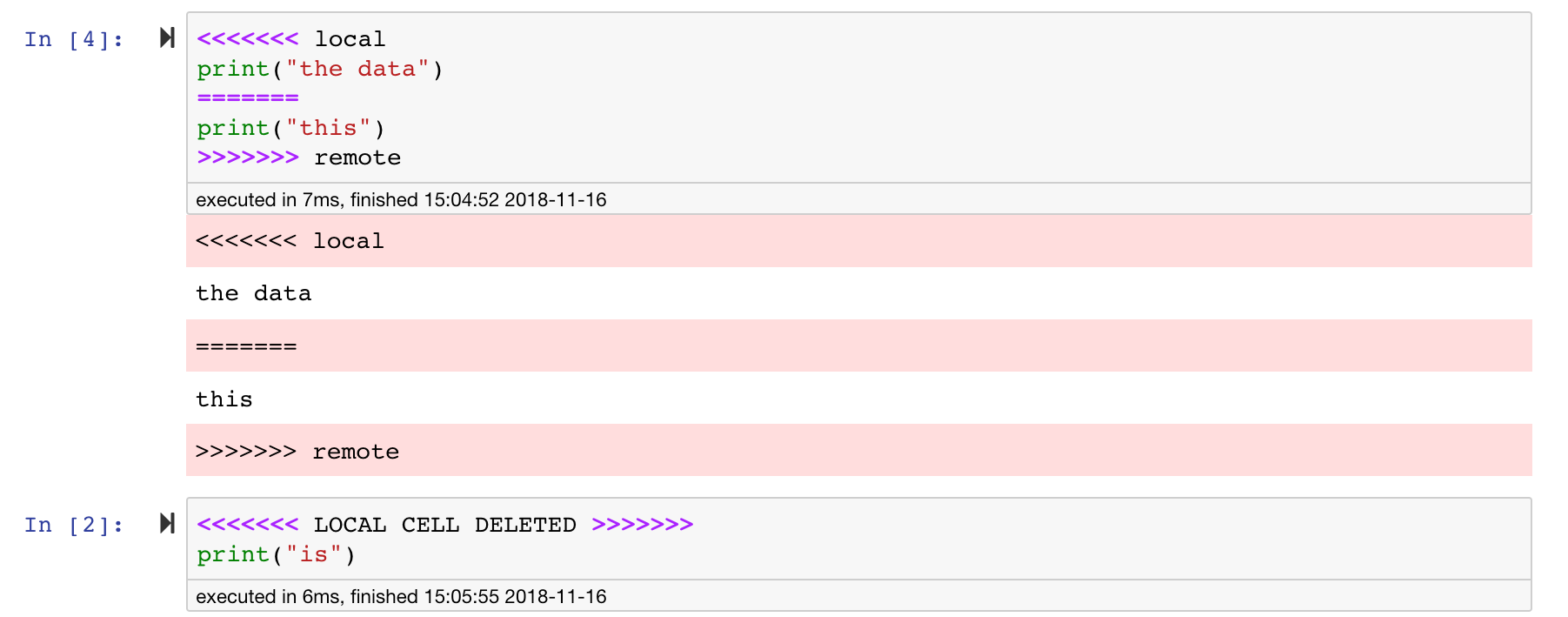
Os notebooks Jupyter são ótimos, mas geralmente são arquivos enormes, com um formato de arquivo JSON muito específico. Para ativar a diferença e a fusão perfeitas via Git, este espaço de trabalho é pré-instalado com o NBDime. O NBDIME entende a estrutura dos documentos de notebook e, portanto, toma automaticamente decisões inteligentes ao diferenciar e mesclar cadernos. No caso de você ter conflitos de mesclagem, o NBDime garantirá que o notebook ainda seja legível por Jupyter, como mostrado abaixo:
Além disso, o espaço de trabalho é pré-instalado com o JupyText, um plug-in Jupyter que lê e grava notebooks como arquivos de texto sem formatação. Isso permite que você abra, edite e execute scripts ou arquivos de marcação (por exemplo, .py , .md ) como notebooks em Jupyter. Na captura de tela a seguir, abrimos um arquivo de marcação via Jupyter:
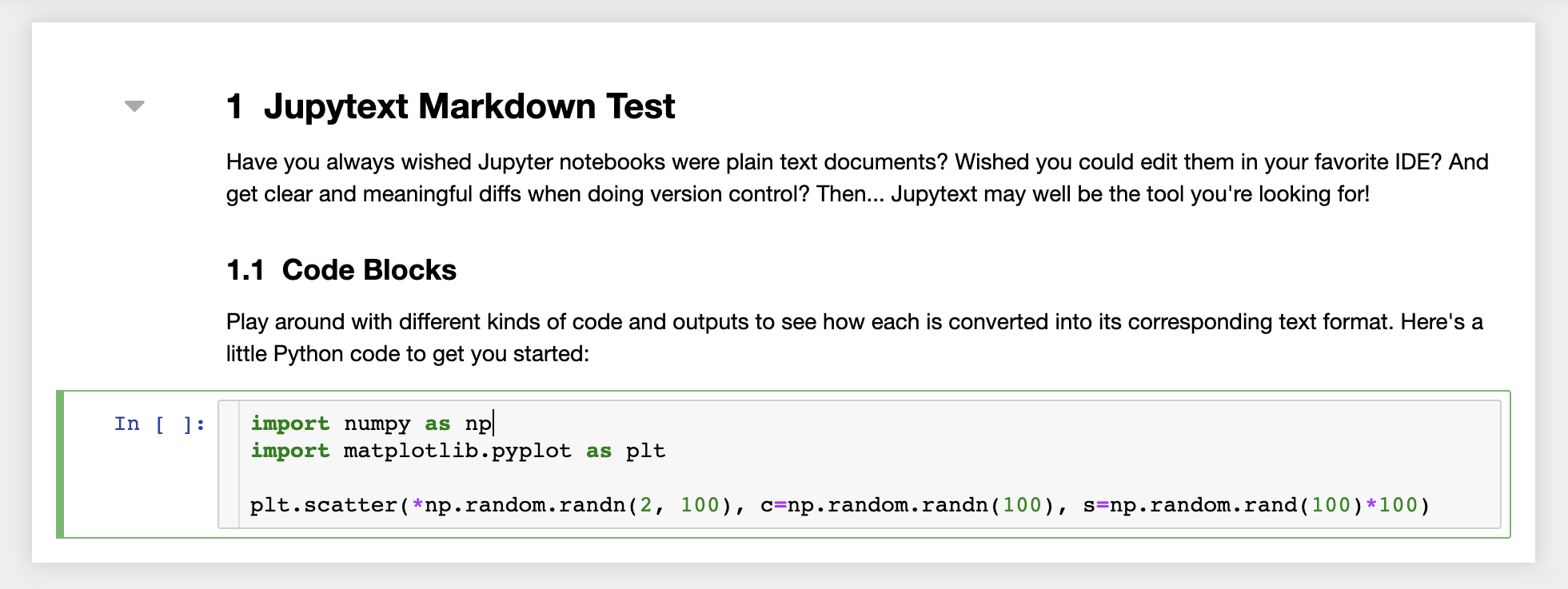
Em combinação com o Git, o JupyText permite um histórico de diff claro e fácil de fusão de conflitos de versão. Com ambas as ferramentas, colaborar nos cadernos Jupyter com Git se torna direto.
O espaço de trabalho tem um recurso para compartilhar qualquer arquivo ou pasta com qualquer pessoa através de um link protegido por token. Para compartilhar dados por meio de um link, selecione qualquer arquivo ou pasta na árvore do diretório Jupyter e clique no botão Compartilhar, como mostrado na captura de tela a seguir:
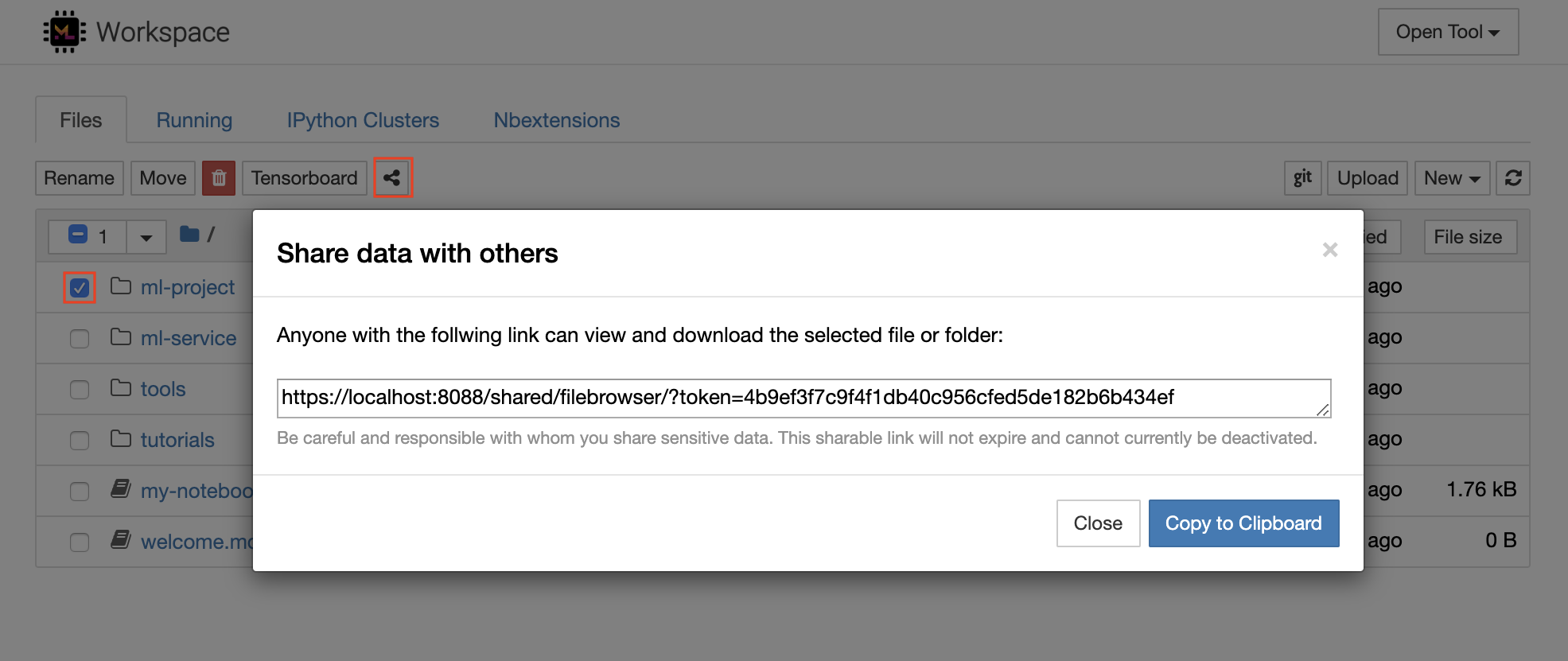
Isso gerará um link exclusivo protegido por meio de um token que oferece a qualquer pessoa com o acesso ao link para visualizar e baixar os dados selecionados através da interface do usuário da FileBrowser:
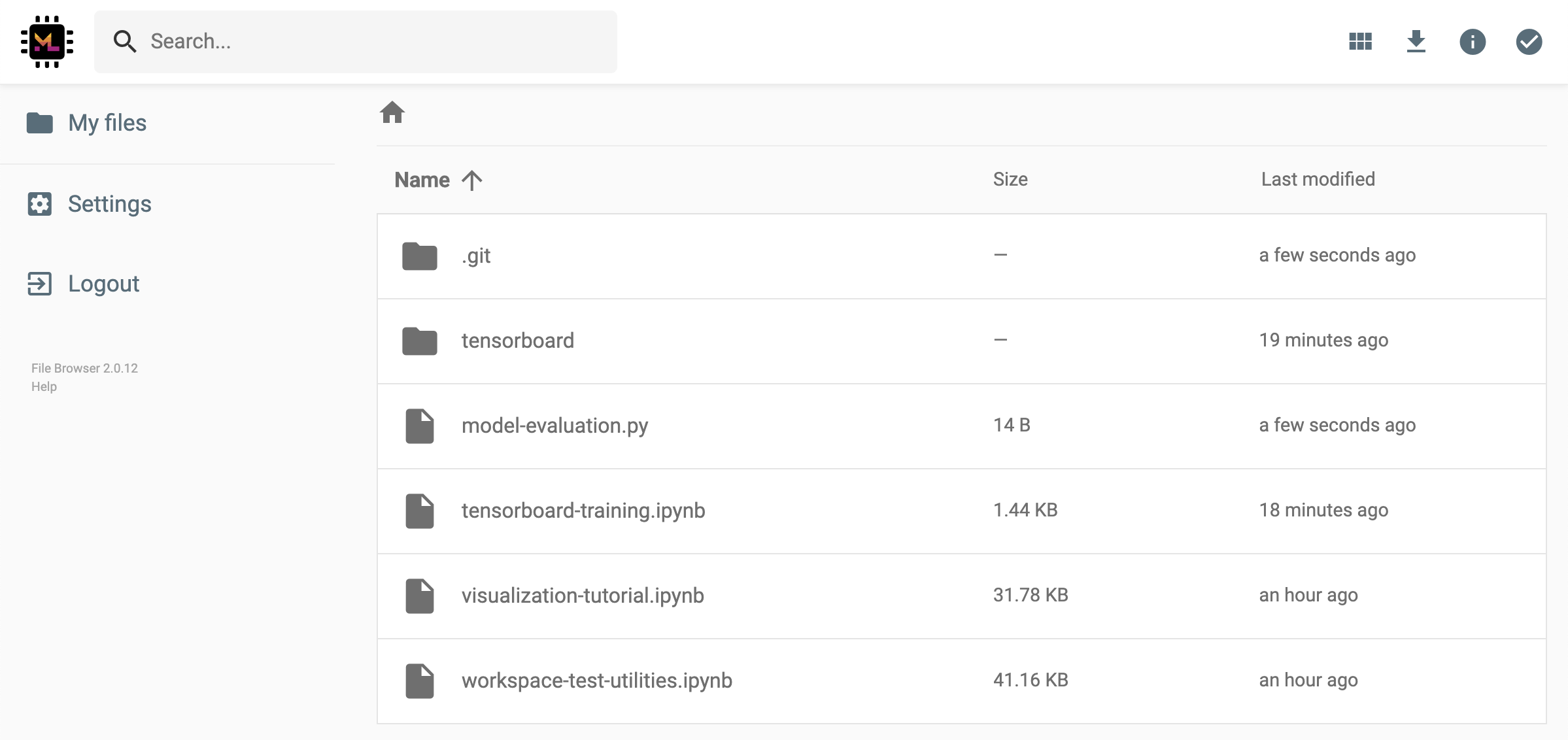
Para desativar ou gerenciar (por exemplo, fornecer permissões de edição) Links compartilhados, abra o arquivo FileBrowser através Open Tool -> Filebrowser e selecione Settings->User Management .
É possível acessar com segurança qualquer porta interna da área de trabalho selecionando Open Tool -> Access Port . Com esse recurso, você pode acessar uma API REST ou aplicativo da Web em execução dentro do espaço de trabalho diretamente com o navegador. O recurso permite que os desenvolvedores construam, executem, testem e depurem APIs REST ou aplicativos da Web diretamente a partir do espaço de trabalho.
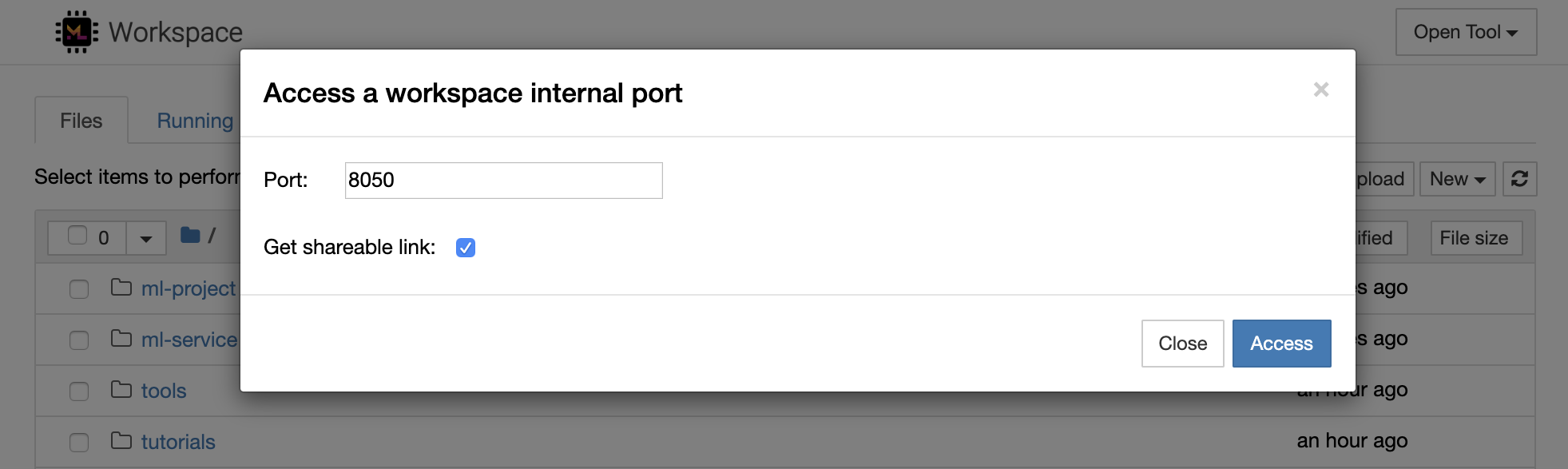
Se você deseja usar um cliente HTTP ou compartilhar acesso a uma determinada porta, pode selecionar a opção Get shareable link . Isso gera um link seguro de token que qualquer pessoa com acesso ao link pode usar para acessar a porta especificada.
O aplicativo HTTP precisa ser resolvido a partir de um caminho de URL relativo ou configurar um caminho base (
/tools/PORT/). As ferramentas tornadas acessíveis dessa maneira são protegidas pelo sistema de autenticação do espaço de trabalho! Se você decidir publicar qualquer outra porta do contêiner, em vez de usar esse recurso para tornar uma ferramenta acessível, certifique -se de protegê -lo por meio de um mecanismo de autenticação!
1234 executando este comando em um terminal dentro da área de trabalho: python -m http.server 1234Open Tool -> Access Port , porta de entrada 1234 e selecione a opção Get shareable link .Access e você verá o conteúdo fornecido pelo http.server do Python. O SSH fornece um poderoso conjunto de recursos que permite que você seja mais produtivo com suas tarefas de desenvolvimento. Você pode configurar facilmente uma conexão SSH segura e sem senha para um espaço de trabalho selecionando Open Tool -> SSH . Isso gerará um comando de configuração seguro que pode ser executado em qualquer máquina Linux ou Mac para configurar uma conexão SSH sem senha e segura com a área de trabalho. Como alternativa, você também pode baixar o script de configuração e executá -lo (em vez de usar o comando).
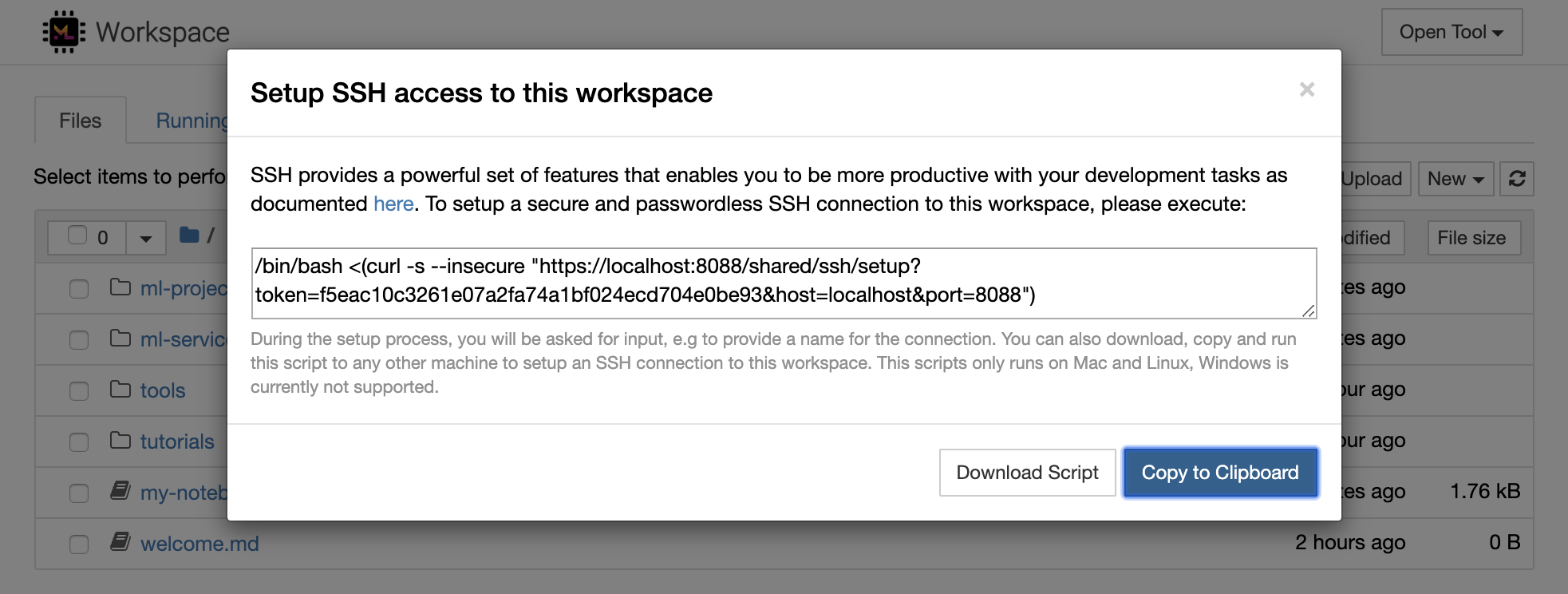
O script de configuração é executado apenas no Mac e Linux. O Windows atualmente não é suportado.
Basta executar o comando ou script de configuração na máquina de onde você deseja configurar uma conexão com o espaço de trabalho e inserir um nome para a conexão (por exemplo, my-workspace ). Você também pode ser solicitado a uma entrada adicional durante o processo, por exemplo, para instalar um kernel remoto se remote_ikernel estiver instalado. Depois que a conexão SSH sem senha for configurada e testada com sucesso, você pode se conectar com segurança ao espaço de trabalho simplesmente executando ssh my-workspace .
Além da capacidade de executar comandos em uma máquina remota, o SSH também fornece uma variedade de outros recursos que podem melhorar seu fluxo de trabalho de desenvolvimento, conforme descrito nas seções a seguir.
Uma conexão SSH pode ser usada para portas de aplicativos de tunelamento da máquina remota para a máquina local ou vice -versa. Por exemplo, você pode expor a porta interna da área de trabalho 5901 (servidor VNC) à máquina local na porta 5000 executando:
ssh -nNT -L 5000:localhost:5901 my-workspacePara expor uma porta de aplicativo da sua máquina local a uma área de trabalho, use a opção
-R(em vez de-L).
Depois que o túnel é estabelecido, você pode usar seu visualizador VNC favorito na máquina local e conectar -se ao vnc://localhost:5000 (senha padrão: vncpassword ). Para tornar a conexão do túnel mais resistente e confiável, recomendamos usar o AutoSSH para reiniciar automaticamente os túneis SSH no caso de a conexão morrer:
autossh -M 0 -f -nNT -L 5000:localhost:5901 my-workspaceO tunelamento da porta é bastante útil quando você iniciou qualquer ferramenta baseada em servidor dentro da área de trabalho que você gosta de tornar acessível para outra máquina. Em sua configuração padrão, o espaço de trabalho tem uma variedade de ferramentas já em execução em diferentes portas, como:
8080 : Porta de espaço de trabalho principal com acesso a todas as ferramentas integradas.8090 : Jupyter Server.8054 : VS Code Server.5901 : servidor VNC.22 : Servidor SSH.Você pode encontrar informações da porta sobre todas as ferramentas na configuração do supervisor.
Para obter mais informações sobre o tunelamento/encaminhamento da porta, recomendamos este guia.
O SCP permite que arquivos e diretórios sejam copiados com segurança para, de diferentes máquinas por meio de conexões SSH. Por exemplo, para copiar um arquivo local ( ./local-file.txt ) na pasta /workspace dentro da área de trabalho, execute:
scp ./local-file.txt my-workspace:/workspace Para copiar o diretório /workspace do my-workspace para o diretório de trabalho da máquina local, execute:
scp -r my-workspace:/workspace .Para mais informações sobre o SCP, recomendamos este guia.
O RSYNC é um utilitário para transferir e sincronizar eficientemente arquivos entre diferentes máquinas (por exemplo, através de conexões SSH) comparando os tempos de modificação e tamanhos dos arquivos. O comando rsync determinará quais arquivos precisam ser atualizados sempre que for executado, o que é muito mais eficiente e conveniente do que usar algo como SCP ou SFTP. Por exemplo, para sincronizar todo o conteúdo de uma pasta local ( ./local-project-folder/ ) no /workspace/remote-project-folder/ pasta dentro da área de trabalho, execute:
rsync -rlptzvP --delete --exclude= " .git " " ./local-project-folder/ " " my-workspace:/workspace/remote-project-folder/ "Se você tiver algumas alterações dentro da pasta na área de trabalho, poderá sincronizar essas alterações na pasta local alterando os argumentos de origem e destino:
rsync -rlptzvP --delete --exclude= " .git " " my-workspace:/workspace/remote-project-folder/ " " ./local-project-folder/ "Você pode executar novamente esses comandos sempre que deseja sincronizar a cópia mais recente de seus arquivos. O RSYNC garantirá que apenas as atualizações sejam transferidas.
Você pode encontrar mais informações sobre o RSYNC nesta página do homem.
Além de copiar e sincronizar dados, uma conexão SSH também pode ser usada para montar diretórios de uma máquina remota no sistema de arquivos local via SSHFS. Por exemplo, para montar o diretório /workspace do my-workspace em um caminho local (por exemplo /local/folder/path ), execute:
sshfs -o reconnect my-workspace:/workspace /local/folder/pathDepois que o diretório remoto estiver montado, você pode interagir com o sistema de arquivos remotos da mesma maneira que em qualquer diretório e arquivo local.
Para mais informações sobre o SSHFS, recomendamos este guia.
O espaço de trabalho pode ser integrado e usado como um tempo de execução remoto (também conhecido como kernel remoto/máquina/intérprete) para uma variedade de ferramentas e IDEs de desenvolvimento populares, como Jupyter, Vs Code, Pycharm, Colab ou Atom Hydrogen. Assim, você pode conectar sua ferramenta de desenvolvimento favorita em execução na máquina local a uma máquina remota para execução de código. Isso permite uma experiência de desenvolvimento de qualidade local com recursos de computação hostil.
Essas integrações geralmente exigem uma conexão SSH sem senha da máquina local para o espaço de trabalho. Para configurar uma conexão SSH, siga as etapas explicadas na seção de acesso SSH.
O espaço de trabalho pode ser adicionado a uma instância de Jupyter como um kernel remoto usando a ferramenta Remote_ikernel. Se você instalou Remote_ikernel ( pip install remote_ikernel ) em sua máquina local, o script de configuração SSH da área de trabalho oferecerá automaticamente a opção de configurar uma conexão remota do kernel.
Ao executar kernels em máquinas remotas, os notebooks serão salvos no sistema de arquivos local, mas o kernel só terá acesso ao sistema de arquivos da máquina remota executando o kernel. Se você precisar sincronizar dados, poderá usar o RSYNC, SCP ou SSHFS, conforme explicado na seção de acesso SSH.
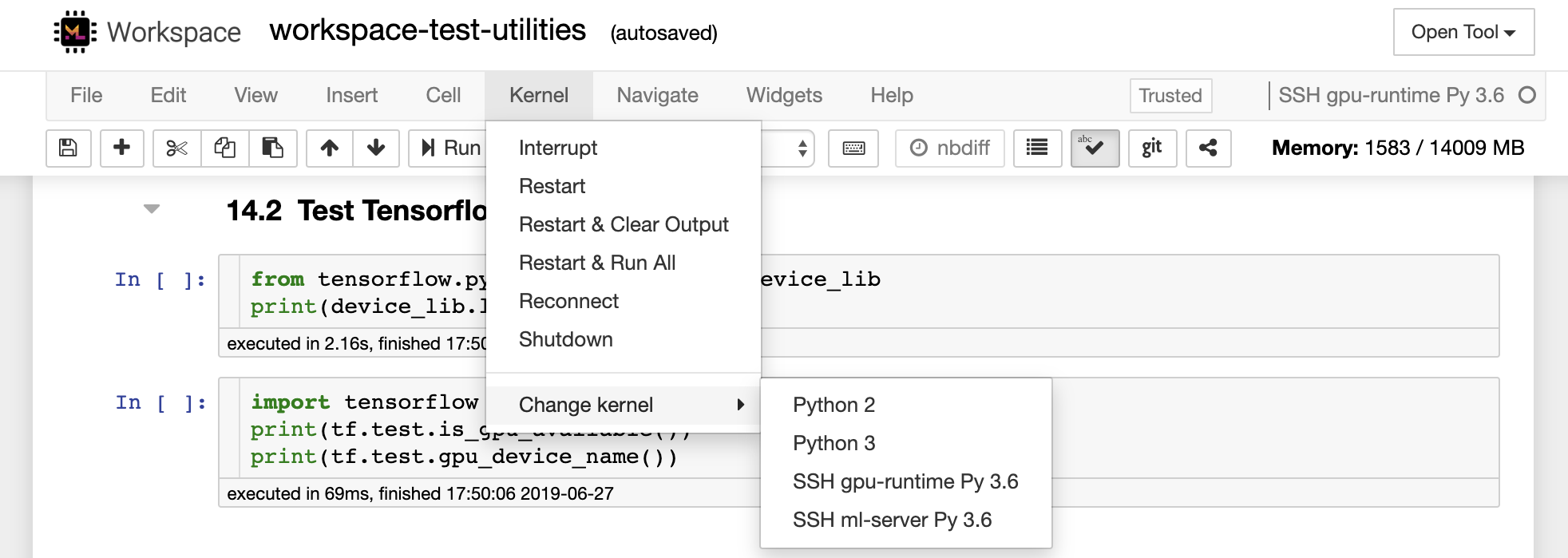
Caso você queira configurar e gerenciar manualmente os kernels remotos, use a ferramenta de linha de comando remote_ikernel, como mostrado abaixo:
# Change my-workspace with the name of a workspace SSH connection
remote_ikernel manage --add
--interface=ssh
--kernel_cmd= " ipython kernel -f {connection_file} "
--name= " ml-server (Python) "
--host= " my-workspace " Você pode usar a funcionalidade da linha de comando remote_ikernel para listar ( remote_ikernel manage --show ) ou excluir ( remote_ikernel manage --delete <REMOTE_KERNEL_NAME> ) conexões remotas do kernel.
O Remote Remote - SSH do Código do Visual Studio permite abrir uma pasta remota em qualquer máquina remota com acesso SSH e trabalhe com ela exatamente como faria se a pasta estivesse em sua própria máquina. Uma vez conectado a uma máquina remota, você pode interagir com arquivos e pastas em qualquer lugar do sistema de arquivos remoto e aproveitar ao máximo o conjunto de recursos do VS Code (suporte IntelliSense, depuração e extensão). Os descobertos e trabalhos fora da caixa com conexões SSH sem senha, conforme configurado pelo script de configuração SSH da área de trabalho. Para ativar o seu aplicativo local de código vs, conectar -se a um espaço de trabalho:
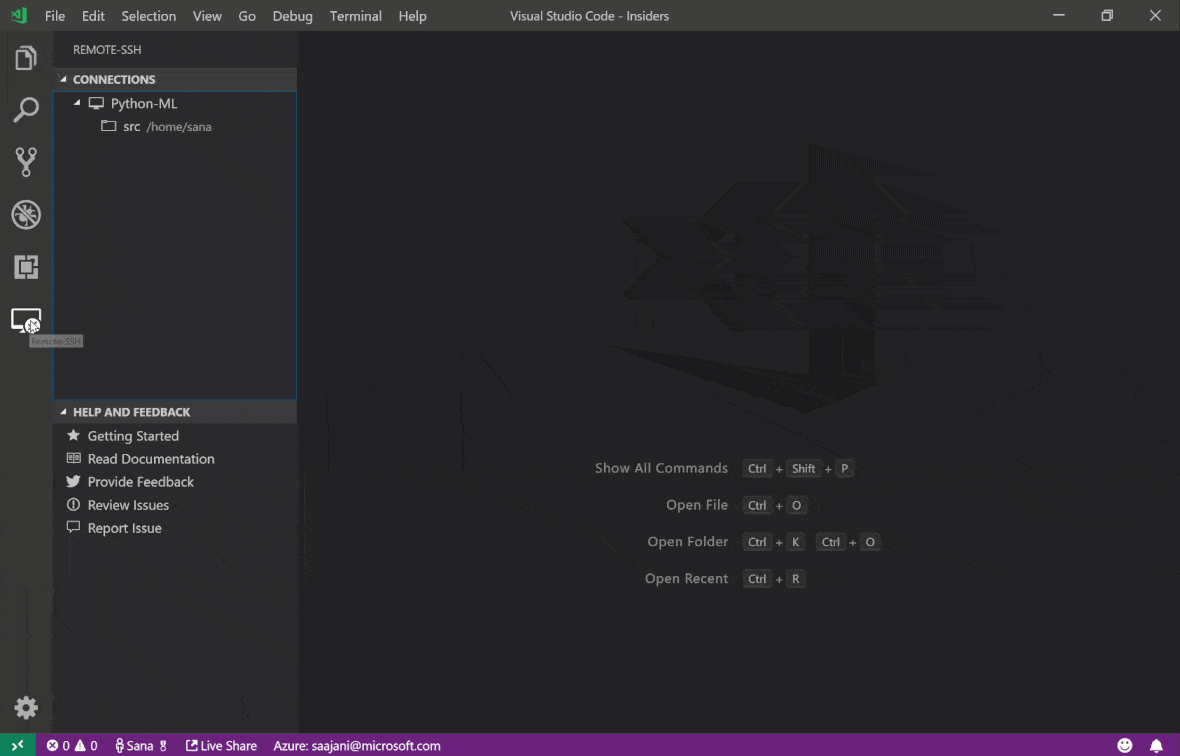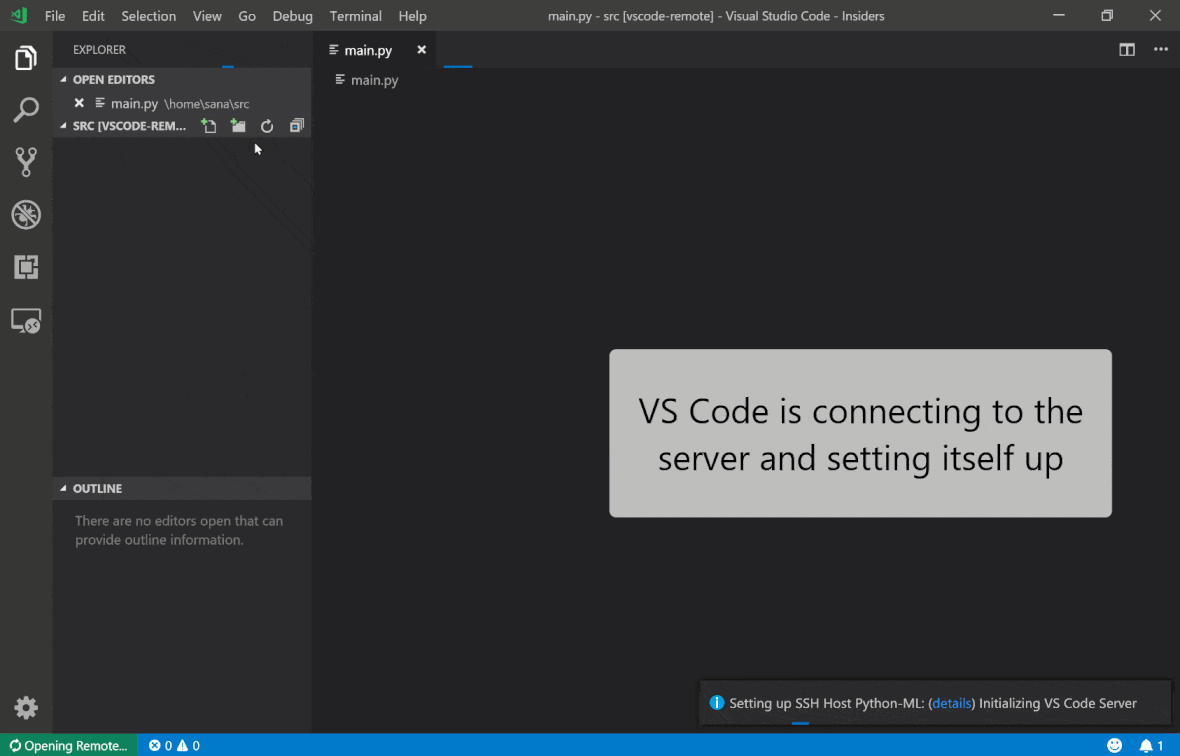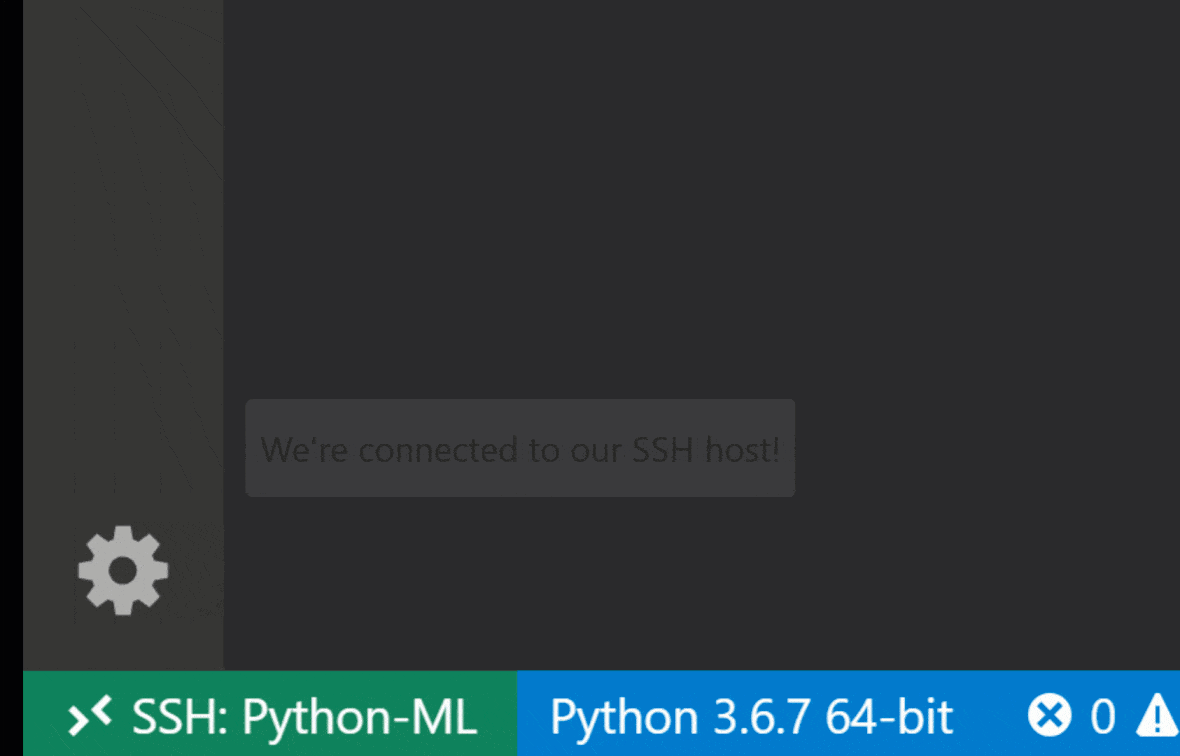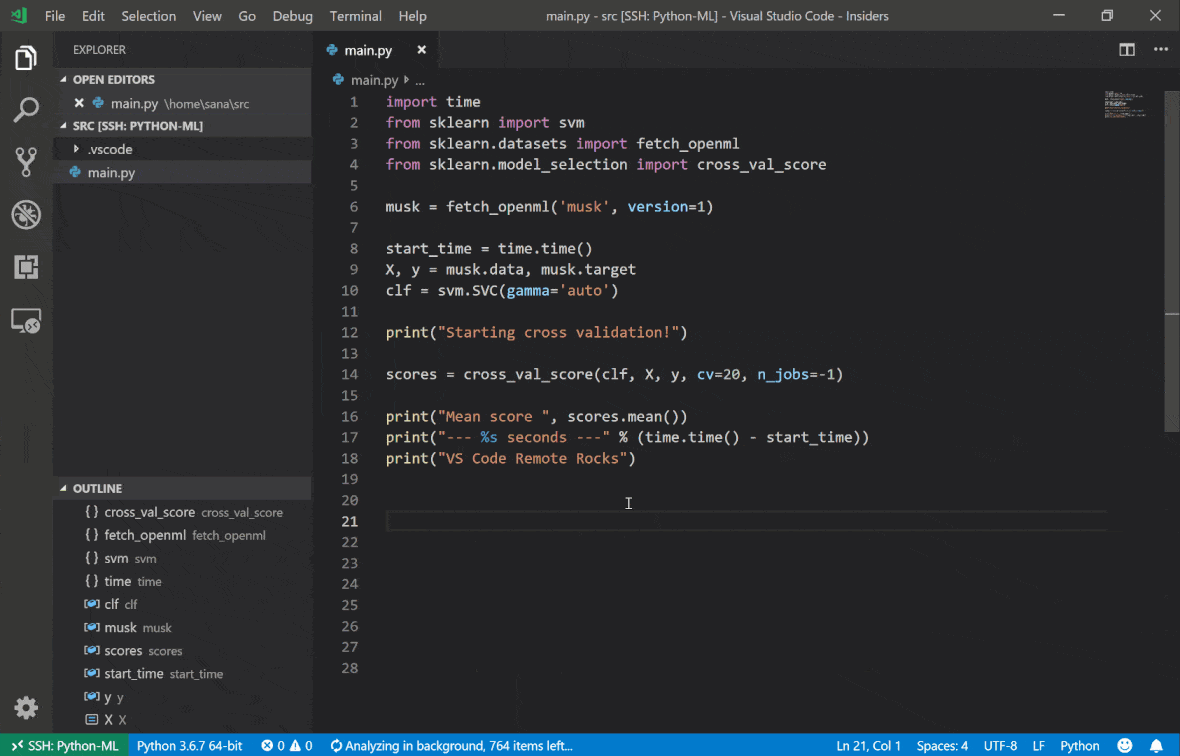
Você pode encontrar recursos e informações adicionais sobre a extensão SSH remota neste guia.
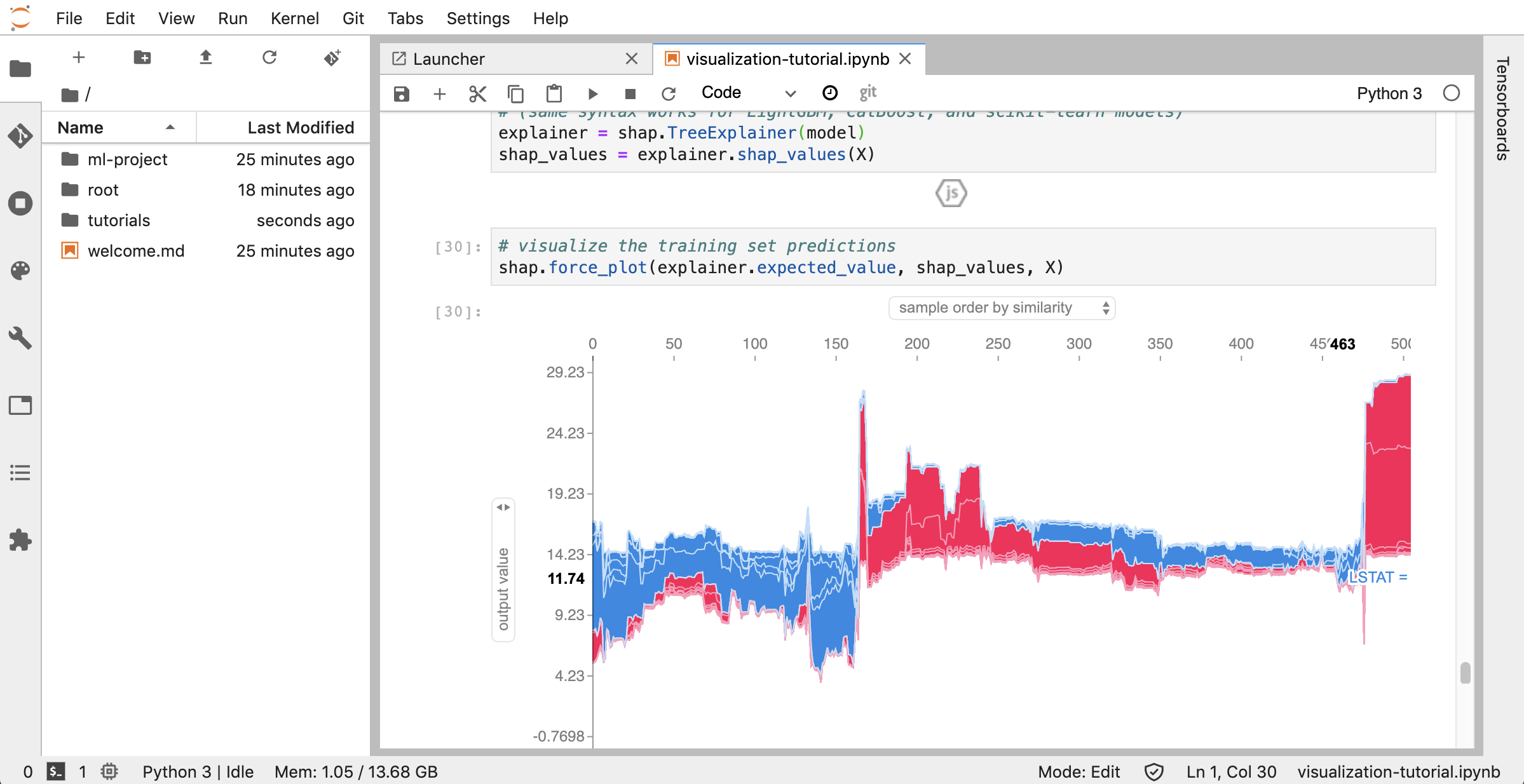
O Tensorboard fornece um conjunto de ferramentas de visualização para facilitar o entendimento, a depuração e otimizar o experimento. Inclui recursos de registro para escalar, histograma, estrutura do modelo, incorporação e visualização de texto e imagem. O espaço de trabalho é pré-instalado com a extensão Jupyter_tensorboard que integra o Tensorboard na interface Jupyter com as funcionalidades para iniciar, gerenciar e interromper instâncias. Você pode abrir uma nova instância para um diretório de logs válido, como mostrado abaixo:
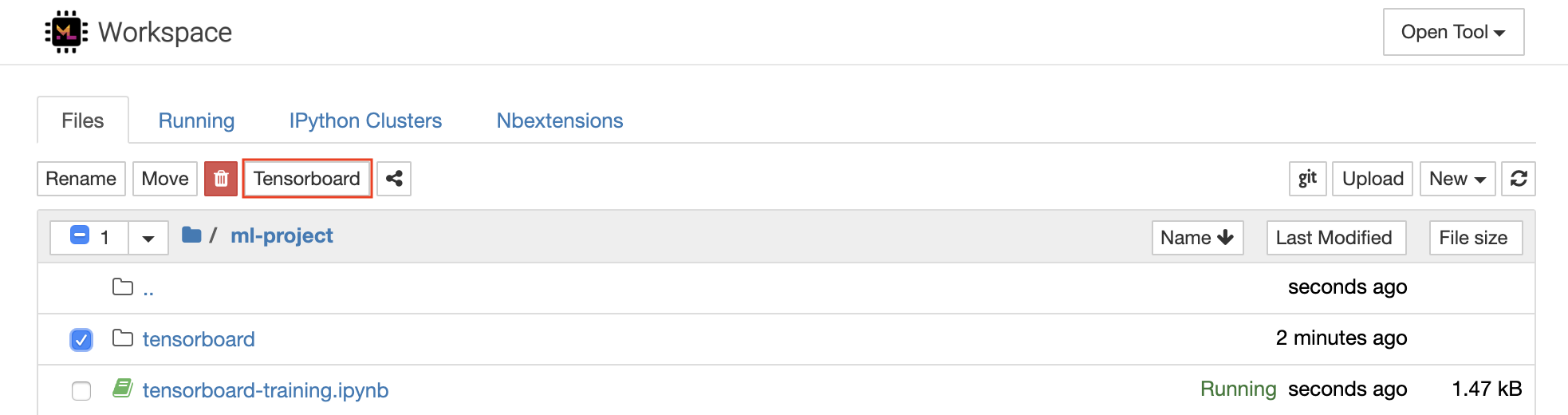
Se você abriu uma instância do Tensorboard em um diretório de log válido, verá as visualizações de seus dados registrados:
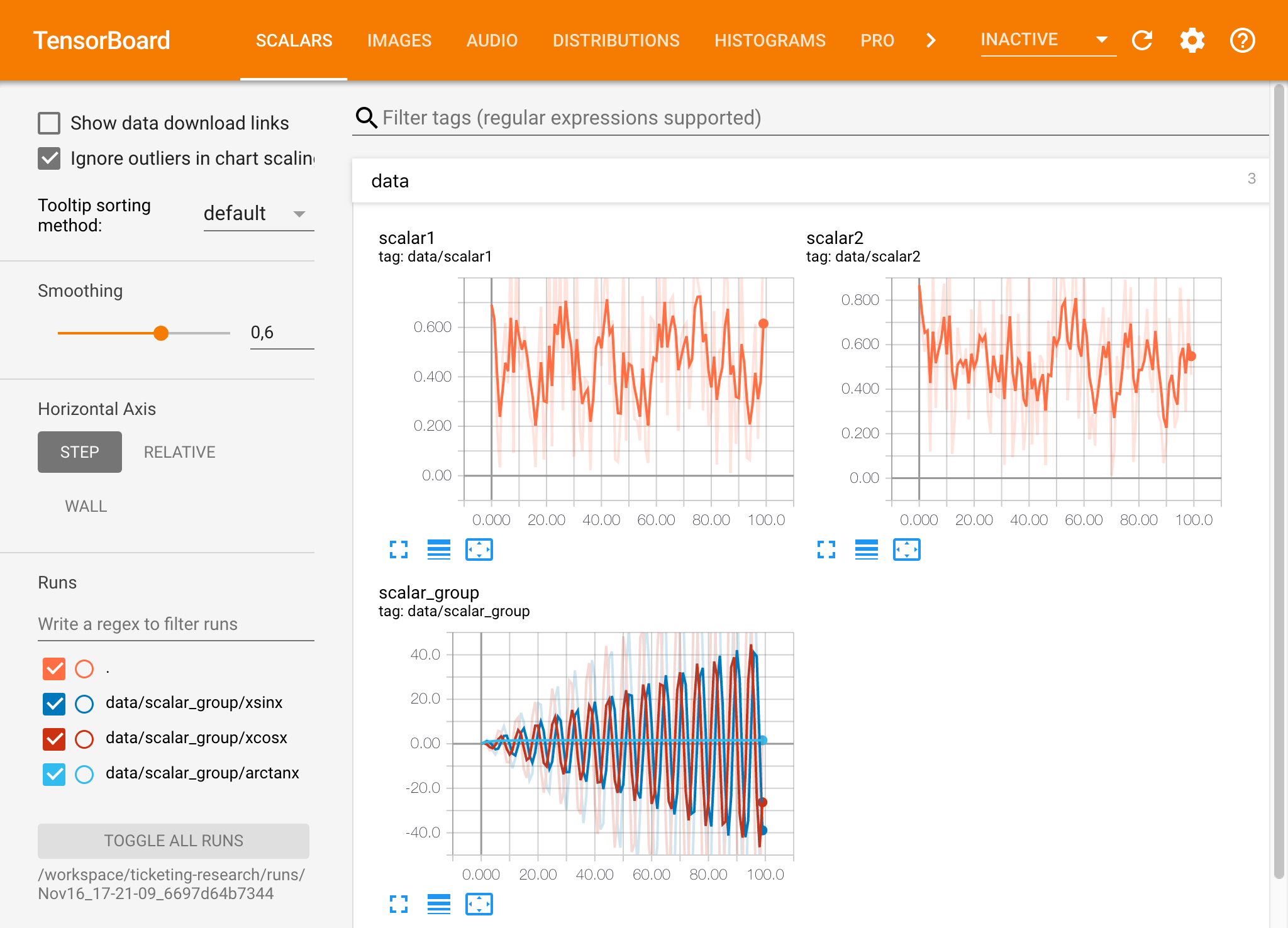
O Tensorboard pode ser usado em combinação com muitas outras estruturas de ML além do Tensorflow. Usando a biblioteca Tensorboardx, você pode registrar basicamente em qualquer biblioteca baseada em Python. Além disso, o Pytorch possui uma integração direta de tensorboard, conforme descrito aqui.
Se você preferir ver o Tensorboard diretamente dentro do seu caderno, poderá usar o seguinte Jupyter Magic :
%load_ext tensorboard
%tensorboard --logdir /workspace/path/to/logs
O espaço de trabalho fornece duas ferramentas baseadas na Web pré-instaladas para ajudar os desenvolvedores durante o treinamento de modelos e outras tarefas de experimentação para obter informações sobre tudo o que está acontecendo no sistema e descobrir gargalos de desempenho.
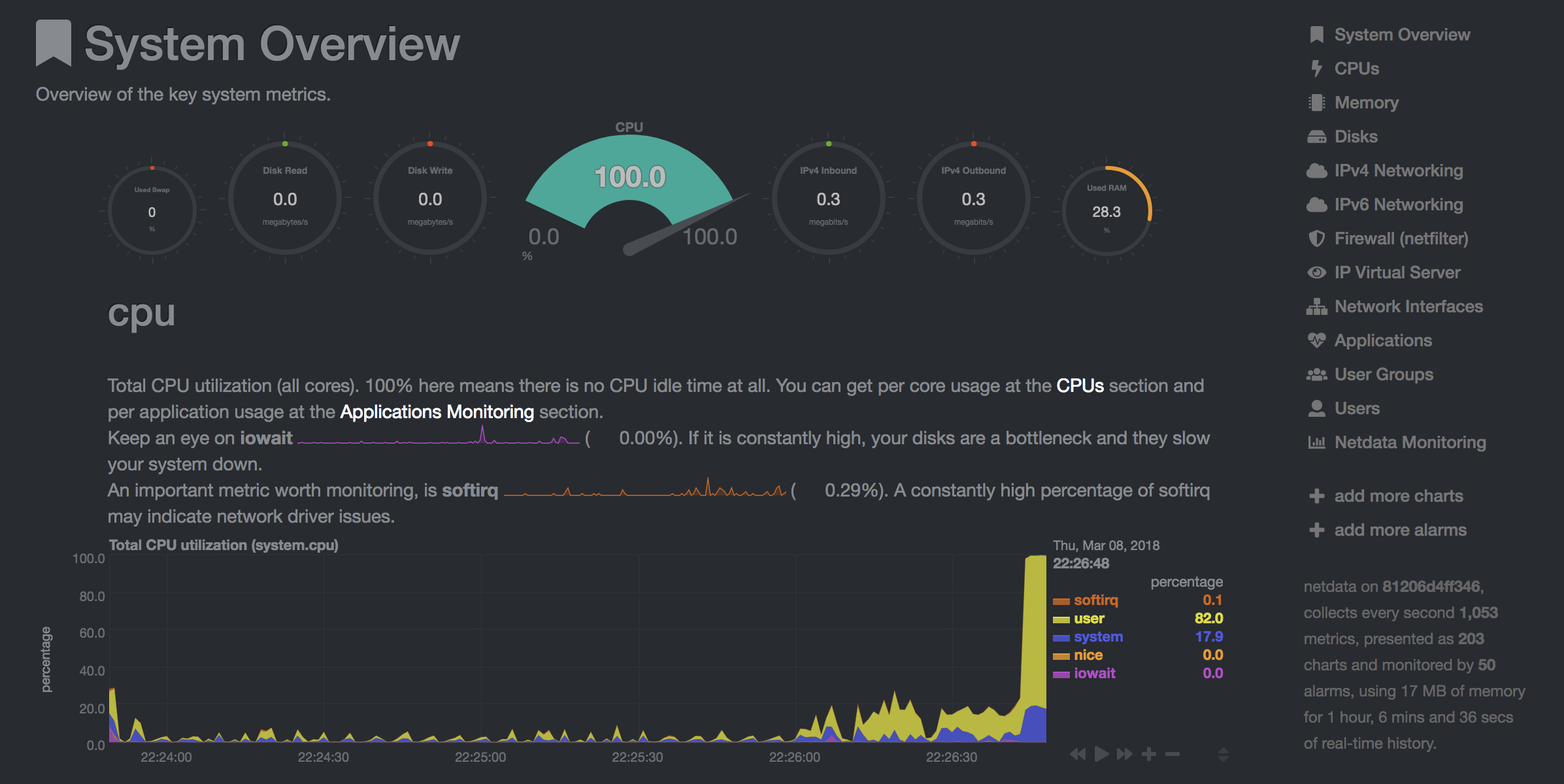
O NetData ( Open Tool -> Netdata ) é um painel de monitoramento de hardware e desempenho em tempo real que visualiza os processos e serviços em seus sistemas Linux. Ele monitora métricas sobre CPU, GPU, memória, discos, redes, processos e muito mais.
O Ofncs ( Open Tool -> Glances ) também é um painel de monitoramento de hardware baseado na Web e pode ser usado como uma alternativa ao NetData.
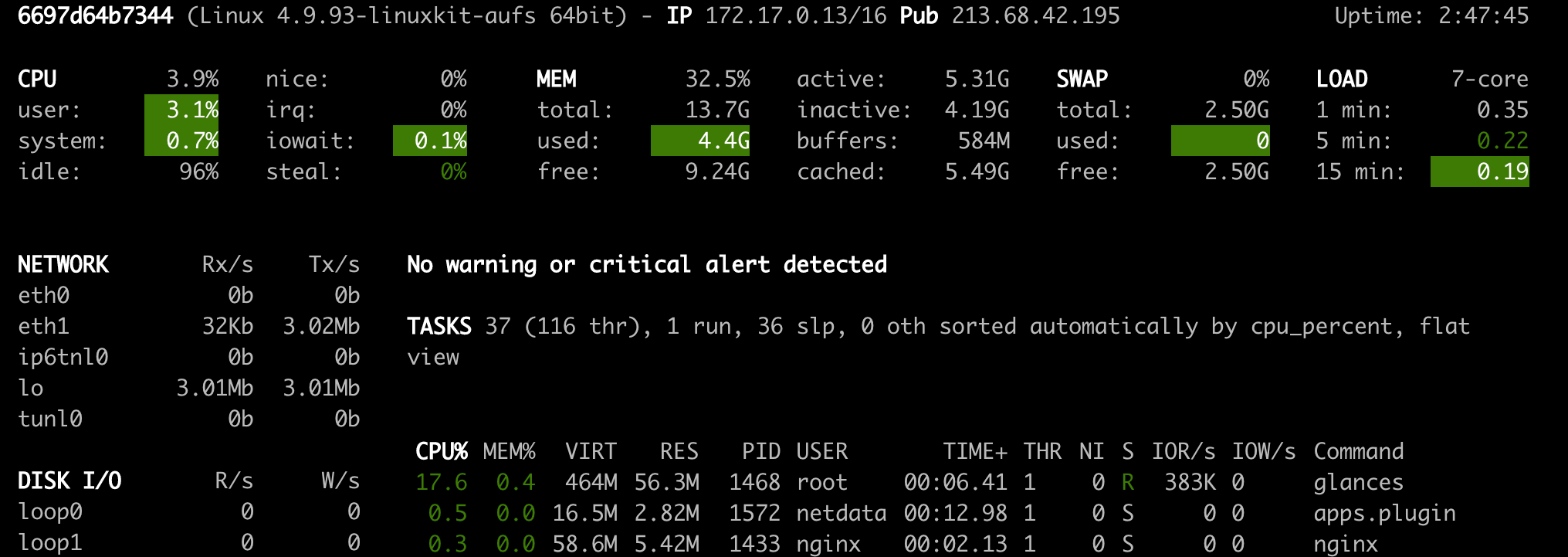
O NetData e os olhares mostrarão as estatísticas de hardware para toda a máquina na qual o contêiner da área de trabalho está em execução.
Um trabalho é definido como qualquer tarefa computacional que seja executada por um determinado momento até a conclusão, como um treinamento de modelo ou um pipeline de dados.
A imagem da área de trabalho também pode ser usada para executar o código Python arbitrário sem iniciar nenhuma das ferramentas pré-instaladas. This provides a seamless way to productize your ML projects since the code that has been developed interactively within the workspace will have the same environment and configuration when run as a job via the same workspace image.
To run Python code as a job, you need to provide a path or URL to a code directory (or script) via EXECUTE_CODE . The code can be either already mounted into the workspace container or downloaded from a version control system (eg, git or svn) as described in the following sections. The selected code path needs to be python executable. In case the selected code is a directory (eg, whenever you download the code from a VCS) you need to put a __main__.py file at the root of this directory. The __main__.py needs to contain the code that starts your job.
You can execute code directly from Git, Mercurial, Subversion, or Bazaar by using the pip-vcs format as described in this guide. For example, to execute code from a subdirectory of a git repository, just run:
docker run --env EXECUTE_CODE= " git+https://github.com/ml-tooling/ml-workspace.git#subdirectory=resources/tests/ml-job " mltooling/ml-workspace:0.13.2For additional information on how to specify branches, commits, or tags please refer to this guide.
In the following example, we mount and execute the current working directory (expected to contain our code) into the /workspace/ml-job/ directory of the workspace:
docker run -v " ${PWD} :/workspace/ml-job/ " --env EXECUTE_CODE= " /workspace/ml-job/ " mltooling/ml-workspace:0.13.2In the case that the pre-installed workspace libraries are not compatible with your code, you can install or change dependencies by just adding one or multiple of the following files to your code directory:
requirements.txt : pip requirements format for pip-installable dependencies.environment.yml : conda environment file to create a separate Python environment.setup.sh : A shell script executed via /bin/bash . The execution order is 1. environment.yml -> 2. setup.sh -> 3. requirements.txt
You can test your job code within the workspace (started normally with interactive tools) by executing the following python script:
python /resources/scripts/execute_code.py /path/to/your/jobIt is also possible to embed your code directly into a custom job image, as shown below:
FROM mltooling/ml-workspace:0.13.2
# Add job code to image
COPY ml-job /workspace/ml-job
ENV EXECUTE_CODE=/workspace/ml-job
# Install requirements only
RUN python /resources/scripts/execute_code.py --requirements-only
# Execute only the code at container startup
CMD [ "python" , "/resources/docker-entrypoint.py" , "--code-only" ]The workspace is pre-installed with many popular interpreters, data science libraries, and ubuntu packages:
conda , pip , apt-get , npm , yarn , sdk , poetry , gdebi ...The full list of installed tools can be found within the Dockerfile.
For every minor version release, we run vulnerability, virus, and security checks within the workspace using safety, clamav, trivy, and snyk via docker scan to make sure that the workspace environment is as secure as possible. We are committed to fix and prevent all high- or critical-severity vulnerabilities. You can find some up-to-date reports here.
The workspace provides a high degree of extensibility. Within the workspace, you have full root & sudo privileges to install any library or tool you need via terminal (eg, pip , apt-get , conda , or npm ). You can open a terminal by one of the following ways:
New -> TerminalApplications -> Terminal EmulatorFile -> New -> TerminalTerminal -> New Terminal Additionally, pre-installed tools such as Jupyter, JupyterLab, and Visual Studio Code each provide their own rich ecosystem of extensions. The workspace also contains a collection of installer scripts for many commonly used development tools or libraries (eg, PyCharm , Zeppelin , RStudio , Starspace ). You can find and execute all tool installers via Open Tool -> Install Tool . Those scripts can be also executed from the Desktop VNC (double-click on the script within the Tools folder on the Desktop VNC).
For example, to install the Apache Zeppelin notebook server, simply execute:
/resources/tools/zeppelin.sh --port=1234 After installation, refresh the Jupyter website and the Zeppelin tool will be available under Open Tool -> Zeppelin . Other tools might only be available within the Desktop VNC (eg, atom or pycharm ) or do not provide any UI (eg, starspace , docker-client ).
As an alternative to extending the workspace at runtime, you can also customize the workspace Docker image to create your own flavor as explained in the FAQ section.
The workspace can be extended in many ways at runtime, as explained here. However, if you like to customize the workspace image with your own software or configuration, you can do that via a Dockerfile as shown below:
# Extend from any of the workspace versions/flavors
FROM mltooling/ml-workspace:0.13.2
# Run you customizations, e.g.
RUN
# Install r-runtime, r-kernel, and r-studio web server from provided install scripts
/bin/bash $RESOURCES_PATH/tools/r-runtime.sh --install &&
/bin/bash $RESOURCES_PATH/tools/r-studio-server.sh --install &&
# Cleanup Layer - removes unneccessary cache files
clean-layer.shFinally, use docker build to build your customized Docker image.
For a more comprehensive Dockerfile example, take a look at the Dockerfile of the R-flavor.
To update a running workspace instance to a more recent version, the running Docker container needs to be replaced with a new container based on the updated workspace image.
All data within the workspace that is not persisted to a mounted volume will be lost during this update process. As mentioned in the persist data section, a volume is expected to be mounted into the /workspace folder. All tools within the workspace are configured to make use of the /workspace folder as the root directory for all source code and data artifacts. During an update, data within other directories will be removed, including installed/updated libraries or certain machine configurations. We have integrated a backup and restore feature ( CONFIG_BACKUP_ENABLED ) for various selected configuration files/folders, such as the user's Jupyter/VS-Code configuration, ~/.gitconfig , and ~/.ssh .
If the workspace is deployed via Docker (Kubernetes will have a different update process), you need to remove the existing container (via docker rm ) and start a new one (via docker run ) with the newer workspace image. Make sure to use the same configuration, volume, name, and port. For example, a workspace (image version 0.8.7 ) was started with this command:
docker run -d
-p 8080:8080
--name "ml-workspace"
-v "/path/on/host:/workspace"
--env AUTHENTICATE_VIA_JUPYTER="mytoken"
--restart always
mltooling/ml-workspace:0.8.7
and needs to be updated to version 0.9.1 , you need to:
docker stop "ml-workspace" && docker rm "ml-workspace"docker run -d -p 8080:8080 --name "ml-workspace" -v "/path/on/host:/workspace" --env AUTHENTICATE_VIA_JUPYTER="mytoken" --restart always mltooling/ml-workspace:0.9.1 If you want to directly connect to the workspace via a VNC client (not using the noVNC webapp), you might be interested in changing certain VNC server configurations. To configure the VNC server, you can provide/overwrite the following environment variables at container start (via docker run option: --env ):
| Variável | Descrição | Padrão |
|---|---|---|
| VNC_PW | Password of VNC connection. This password only needs to be secure if the VNC server is directly exposed. If it is used via noVNC, it is already protected based on the configured authentication mechanism. | vncpassword |
| VNC_RESOLUTION | Default desktop resolution of VNC connection. When using noVNC, the resolution will be dynamically adapted to the window size. | 1600x900 |
| VNC_COL_DEPTH | Default color depth of VNC connection. | 24 |
Unfortunately, we currently do not support using a non-root user within the workspace. We plan to provide this capability and already started with some refactoring to allow this configuration. However, this still requires a lot more work, refactoring, and testing from our side.
Using root-user (or users with sudo permission) within containers is generally not recommended since, in case of system/kernel vulnerabilities, a user might be able to break out of the container and be able to access the host system. Since it is not very common to have such problematic kernel vulnerabilities, the risk of a severe attack is quite minimal. As explained in the official Docker documentation, containers (even with root users) are generally quite secure in preventing a breakout to the host. And compared to many other container use-cases, we actually want to provide the flexibility to the user to have control and system-level installation permissions within the workspace container.
The workspace comes preinstalled with various common tools to create isolated Python environments (virtual environments). The following sections provide a quick-intro on how to use these tools within the workspace. You can find information on when to use which tool here. Please refer to the documentation of the given tool for additional usage information.
venv (recommended):
To create a virtual environment via venv, execute the following commands:
# Create environment in the working directory
python -m venv my-venv
# Activate environment in shell
source ./my-venv/bin/activate
# Optional: Create Jupyter kernel for this environment
pip install ipykernel
python -m ipykernel install --user --name=my-venv --display-name= " my-venv ( $( python --version ) ) "
# Optional: Close enviornment session
deactivatepipenv (recommended):
To create a virtual environment via pipenv, execute the following commands:
# Create environment in the working directory
pipenv install
# Activate environment session in shell
pipenv shell
# Optional: Create Jupyter kernel for this environment
pipenv install ipykernel
python -m ipykernel install --user --name=my-pipenv --display-name= " my-pipenv ( $( python --version ) ) "
# Optional: Close environment session
exitvirtualenv :
To create a virtual environment via virtualenv, execute the following commands:
# Create environment in the working directory
virtualenv my-virtualenv
# Activate environment session in shell
source ./my-virtualenv/bin/activate
# Optional: Create Jupyter kernel for this environment
pip install ipykernel
python -m ipykernel install --user --name=my-virtualenv --display-name= " my-virtualenv ( $( python --version ) ) "
# Optional: Close environment session
deactivateconda :
To create a virtual environment via conda, execute the following commands:
# Create environment (globally)
conda create -n my-conda-env
# Activate environment session in shell
conda activate my-conda-env
# Optional: Create Jupyter kernel for this environment
python -m ipykernel install --user --name=my-conda-env --display-name= " my-conda-env ( $( python --version ) ) "
# Optional: Close environment session
conda deactivateTip: Shell Commands in Jupyter Notebooks:
If you install and use a virtual environment via a dedicated Jupyter Kernel and use shell commands within Jupyter (eg !pip install matplotlib ), the wrong python/pip version will be used. To use the python/pip version of the selected kernel, do the following instead:
import sys
!{ sys . executable } - m pip install matplotlibThe workspace provides three easy options to install different Python versions alongside the main Python instance: pyenv, pipenv (recommended), conda.
pipenv (recommended):
To install a different python version (eg 3.7.8 ) within the workspace via pipenv, execute the following commands:
# Install python vers
pipenv install --python=3.7.8
# Activate environment session in shell
pipenv shell
# Check python installation
python --version
# Optional: Create Jupyter kernel for this environment
pipenv install ipykernel
python -m ipykernel install --user --name=my-pipenv --display-name= " my-pipenv ( $( python --version ) ) "
# Optional: Close environment session
exitpyenv :
To install a different python version (eg 3.7.8 ) within the workspace via pyenv, execute the following commands:
# Install python version
pyenv install 3.7.8
# Make globally accessible
pyenv global 3.7.8
# Activate python version in shell
pyenv shell 3.7.8
# Check python installation
python3.7 --version
# Optional: Create Jupyter kernel for this python version
python3.7 -m pip install ipykernel
python3.7 -m ipykernel install --user --name=my-pyenv-3.7.8 --display-name= " my-pyenv (Python 3.7.8) "conda :
To install a different python version (eg 3.7.8 ) within the workspace via conda, execute the following commands:
# Create environment with python version
conda create -n my-conda-3.7 python=3.7.8
# Activate environment session in shell
conda activate my-conda-3.7
# Check python installation
python --version
# Optional: Create Jupyter kernel for this python version
pip install ipykernel
python -m ipykernel install --user --name=my-conda-3.7 --display-name= " my-conda ( $( python --version ) ) "
# Optional: Close environment session
conda deactivateTip: Shell Commands in Jupyter Notebooks:
If you install and use another Python version via a dedicated Jupyter Kernel and use shell commands within Jupyter (eg !pip install matplotlib ), the wrong python/pip version will be used. To use the python/pip version of the selected kernel, do the following instead:
import sys
!{ sys . executable } - m pip install matplotlib Certain desktop tools (eg, recent versions of Firefox) or libraries (eg, Pytorch - see Issues: 1, 2) might crash if the shared memory size ( /dev/shm ) is too small. The default shared memory size of Docker is 64MB, which might not be enough for a few tools. You can provide a higher shared memory size via the shm-size docker run option:
docker run --shm-size=2G mltooling/ml-workspace:0.13.2 In general, the performance of running code within Docker is nearly identical compared to running it directly on the machine. However, in case you have limited the container's CPU quota (as explained in this section), the container can still see the full count of CPU cores available on the machine and there is no technical way to prevent this. Many libraries and tools will use the full CPU count (eg, via os.cpu_count() ) to set the number of threads used for multiprocessing/-threading. This might cause the program to start more threads/processes than it can efficiently handle with the available CPU quota, which can tremendously slow down the overall performance. Therefore, it is important to set the available CPU count or the maximum number of threads explicitly to the configured CPU quota. The workspace provides capabilities to detect the number of available CPUs automatically, which are used to configure a variety of common libraries via environment variables such as OMP_NUM_THREADS or MKL_NUM_THREADS . It is also possible to explicitly set the number of available CPUs at container startup via the MAX_NUM_THREADS environment variable (see configuration section). The same environment variable can also be used to get the number of available CPUs at runtime.
Even though the automatic configuration capabilities of the workspace will fix a variety of inefficiencies, we still recommend configuring the number of available CPUs with all libraries explicitly. Por exemplo:
import os
MAX_NUM_THREADS = int ( os . getenv ( "MAX_NUM_THREADS" ))
# Set in pytorch
import torch
torch . set_num_threads ( MAX_NUM_THREADS )
# Set in tensorflow
import tensorflow as tf
config = tf . ConfigProto (
device_count = { "CPU" : MAX_NUM_THREADS },
inter_op_parallelism_threads = MAX_NUM_THREADS ,
intra_op_parallelism_threads = MAX_NUM_THREADS ,
)
tf_session = tf . Session ( config = config )
# Set session for keras
import keras . backend as K
K . set_session ( tf_session )
# Set in sklearn estimator
from sklearn . linear_model import LogisticRegression
LogisticRegression ( n_jobs = MAX_NUM_THREADS ). fit ( X , y )
# Set for multiprocessing pool
from multiprocessing import Pool
with Pool ( MAX_NUM_THREADS ) as pool :
results = pool . map ( lst )If you encounter the following error within the container logs when starting the workspace, it will most likely not be possible to run the workspace on your hardware:
exited: nginx (terminated by SIGILL (core dumped); not expected)
The OpenResty/Nginx binary package used within the workspace requires to run on a CPU with SSE4.2 support (see this issue). Unfortunately, some older CPUs do not have support for SSE4.2 and, therefore, will not be able to run the workspace container. On Linux, you can check if your CPU supports SSE4.2 when looking into the cat /proc/cpuinfo flags section. If you encounter this problem, feel free to notify us by commenting on the following issue: #30.
Requirements : Docker and Act are required to be installed on your machine to execute the build process.
To simplify the process of building this project from scratch, we provide build-scripts - based on universal-build - that run all necessary steps (build, test, and release) within a containerized environment. To build and test your changes, execute the following command in the project root folder:
act -b -j buildUnder the hood it uses the build.py files in this repo based on the universal-build library. So, if you want to build it locally, you can also execute this command in the project root folder to build the docker container:
python build.py --makeFor additional script options:
python build.py --helpRefer to our contribution guides for more detailed information on our build scripts and development process.
Licensed Apache 2.0 . Created and maintained with ❤️ by developers from Berlin.


