ml workspace
0.13.2

All-in-One-webbasierte Entwicklungsumgebung für maschinelles Lernen
Erste Schritte • Funktionen und Screenshots • Support • Melden Sie einen Fehler • FAQ • Bekannte Probleme • Beitrag
Der ML Workspace ist eine webbasierte All-in-One-IDE für maschinelles Lernen und Datenwissenschaft. Es ist einfach bereit zu bereitstellen und Sie können innerhalb von Minuten mit produktiv erstellten ML -Lösungen auf Ihren eigenen Maschinen gestartet werden. Dieser Arbeitsbereich ist das ultimative Werkzeug für Entwickler, die mit einer Vielzahl beliebter Datenwissenschaftsbibliotheken (z. B. Tensorflow, Pytorch, Keras, Sklearn) und Dev -Tools (z. B. Jupyter, VS -Code, Tensorboard) perfekt konfiguriert, optimiert und integriert wurden.
Im Arbeitsbereich muss Docker auf Ihrem Computer installiert werden (Installationshandbuch).
Die Bereitstellung einer einzelnen Arbeitsspace -Instanz ist so einfach wie:
docker run -p 8080:8080 mltooling/ml-workspace:0.13.2Voilà, das war einfach! Jetzt wird Docker das neueste Arbeitsbereich auf Ihre Maschine ziehen. Dies kann je nach Internetgeschwindigkeit einige Minuten dauern. Sobald der Arbeitsbereich gestartet ist, können Sie über http: // localhost: 8080 darauf zugreifen.
Wenn Sie auf einem anderen Computer oder mit einem anderen Port gestartet werden, verwenden Sie die IP/DNS des Geräts und/oder den exponierten Port.
Um eine einzelne Instanz für die produktive Verwendung bereitzustellen, empfehlen wir, mindestens die folgenden Optionen anzuwenden:
docker run -d
-p 8080:8080
--name " ml-workspace "
-v " ${PWD} :/workspace "
--env AUTHENTICATE_VIA_JUPYTER= " mytoken "
--shm-size 512m
--restart always
mltooling/ml-workspace:0.13.2 In diesem Befehl wird der Container im Hintergrund ( -d ) ausgeführt, Ihr aktuelles Arbeitsverzeichnis in den Ordner /workspace ( -v ) montiert, den Arbeitsbereich über einen bereitgestellten Token ( --env AUTHENTICATE_VIA_JUPYTER ) befestigt, bietet 512MB gemeinsames Gedächtnis ( --shm-size ), um unerwartete Abstürze zu verhindern (siehe bekannte Probleme, und das Abschnitt "Impuls) und das Abschnitt" In Abschnitt "und --restart always " Im Rahmen. Weitere Optionen für Docker finden Sie hier und die Konfigurationsoptionen für Arbeitsbereiche im Abschnitt unten.
Der Arbeitsbereich bietet eine Vielzahl von Konfigurationsoptionen, die durch Einstellen von Umgebungsvariablen verwendet werden können (über Docker -Auslaufoption: --env ).
| Variable | Beschreibung | Standard |
|---|---|---|
| Workspace_Base_url | Die Basis -URL, unter der Jupyter und alle anderen Werkzeuge erreichbar sind. | / |
| Workspace_SSL_Enabled | SSL aktivieren oder deaktivieren. Wenn auf true eingestellt ist, muss entweder Zertifikat (Cert.Crt) an /resources/ssl montiert werden oder, wenn nicht, der Container selbstsigniertes Zertifikat generiert. | FALSCH |
| Workspace_Auth_User | Grundlegender Auth -Benutzername. Um Basic AUTH zu aktivieren, müssen sowohl der Benutzer als auch das Kennwort festgelegt werden. Wir empfehlen, die AUTHENTICATE_VIA_JUPYTER zur Sicherung des Arbeitsbereichs zu verwenden. | |
| Workspace_Auth_Password | Grundlegende Auth -Benutzerkennwort. Um Basic AUTH zu aktivieren, müssen sowohl der Benutzer als auch das Kennwort festgelegt werden. Wir empfehlen, die AUTHENTICATE_VIA_JUPYTER zur Sicherung des Arbeitsbereichs zu verwenden. | |
| Workspace_port | Konfiguriert den wichtigsten Container-Internal-Port des Arbeitsbereichs Proxy. Für die meisten Szenarien sollte diese Konfiguration nicht geändert werden, und die Portkonfiguration über Docker sollte anstelle des Arbeitsbereichs verwendet werden. | 8080 |
| Config_backup_enabled | Sichern und wiederherstellen Sie die Benutzerkonfiguration automatisch in den Ordner "Persisted /workspace , wie z. | WAHR |
| Shared_links_enabled | Aktivieren oder deaktivieren Sie die Fähigkeit, Ressourcen über externe Links zu teilen. Dies wird verwendet, um die Dateifreigabe, den Zugriff auf Arbeitsbereich-internationale Ports und ein einfaches Befehlsbasis-SSH-Setup zu aktivieren. Alle gemeinsam genutzten Links werden über ein Token geschützt. Es besteht jedoch bestimmte Risiken, da das Token nach der Freigabe nicht leicht ungültig werden kann und nicht abläuft. | WAHR |
| Integrieren_tutorials | Wenn true , wird eine Auswahl an Tutorial- und Einführungsnotenbüchern zum Ordner /workspace beim Container -Start hinzugefügt, jedoch nur, wenn der Ordner leer ist. | WAHR |
| Max_num_threads | Die Anzahl der Threads, die bei der Verwendung verschiedener gemeinsamer Bibliotheken für Berechnungen verwendet werden (MKL, OpenBLAs, OMP, Numba, ...). Sie können auch auto verwenden, um den Arbeitsbereich die Anzahl der Threads basierend auf den verfügbaren CPU -Ressourcen dynamisch zu bestimmen. Diese Konfiguration kann vom Benutzer innerhalb des Arbeitsbereichs überschrieben werden. Im Allgemeinen ist es gut, es auf oder unter der Anzahl der dem Arbeitsbereich zur Verfügung stehenden CPUs zu setzen. | Auto |
| Jupyter -Konfiguration: | ||
| Schadendown_inactive_kernels | Automatisch inaktive Kernel nach einem bestimmten Zeitüberschreitungen (zum Aufräumen von Speicher oder GPU -Ressourcen) automatisch herunterfahren. Wert kann entweder eine Zeitlimit in Sekunden sein oder mit einem Standardwert von 48 Stunden auf true eingestellt werden. | FALSCH |
| Authenticate_via_jupyter | Wenn true , werden alle HTTP -Anforderungen mit dem Jupyter -Server authentifiziert, was bedeutet, dass die mit JUPYTER konfigurierte Authentifizierungsmethode auch für alle anderen Tools verwendet wird. Dies kann mit false deaktiviert werden. Jeder andere Wert aktiviert diese Authentifizierung und wird als Token über NotebookApp.Token -Konfiguration der Jupyter angewendet. | FALSCH |
| Notebook_Args | Fügen Sie Jupyter -Konfigurationsoptionen hinzufügen und überschreiben Sie über Befehlszeilen -Argumente. In dieser Übersicht finden Sie alle Optionen. | |
Um die Daten zu bestehen, müssen Sie einen Volumen in /workspace befestigen (über Docker -Auslaufoption: -v ).
Das Standardarbeitsverzeichnis im Container ist /workspace , das auch das Stammverzeichnis der Jupyter -Instanz ist. Das Verzeichnis /workspace soll für alle wichtigen Arbeitsartefakte verwendet werden. Daten in anderen Verzeichnissen des Servers (z. B. /root ) können bei Container -Neustarts verloren gehen.
Wir empfehlen dringend, die Authentifizierung über eine der folgenden zwei Optionen zu aktivieren. Für beide Optionen muss der Benutzer sich für den Zugriff auf die vorinstallierten Tools authentifizieren.
Die Authentifizierung funktioniert nur für alle Tools, auf die über den Hauptarbeitsportanschluss zugegriffen wird (Standard:
8080). Dies eignet sich für alle vorinstallierten Tools und die Funktion "Access Ports". Wenn Sie einen anderen Port des Containers aufdecken, stellen Sie ihn bitte auch mit Authentifizierung sicher!
Aktivieren Sie die tokenbasierte Authentifizierung basierend auf der Authentifizierungsimplementierung von Jupyter über die Variable AUTHENTICATE_VIA_JUPYTER :
docker run -p 8080:8080 --env AUTHENTICATE_VIA_JUPYTER= " mytoken " mltooling/ml-workspace:0.13.2 Sie können auch <generated> verwenden, um Jupyter ein zufälliges Token zu generieren, das auf den Containerprotokollen ausgedruckt wird. Ein Wert von true wird kein Token festlegen, sondern aktivieren, dass jede Anforderung an ein Tool im Arbeitsbereich mit der Jupyter -Instanz überprüft wird, wenn der Benutzer authentifiziert ist. Dies wird für Tools wie JupyterHub verwendet, die seine eigene Authentifizierung konfigurieren.
Aktivieren Sie die grundlegende Authentifizierung über die Variable WORKSPACE_AUTH_USER und WORKSPACE_AUTH_PASSWORD :
docker run -p 8080:8080 --env WORKSPACE_AUTH_USER= " user " --env WORKSPACE_AUTH_PASSWORD= " pwd " mltooling/ml-workspace:0.13.2 Die grundlegende Authentifizierung wird über den Nginx -Proxy konfiguriert und kann im Vergleich zur anderen Option möglicherweise leistungsfähiger sein, da mit AUTHENTICATE_VIA_JUPYTER jede Anforderung an ein beliebiges Tool im Arbeitsbereich über die Jupyter -Instanz überprüft, wenn der Benutzer (basierend auf den Anforderungs -Cookies) authentifiziert ist.
Wir empfehlen, SSL zu aktivieren, damit der Arbeitsbereich über HTTPS (verschlüsselte Kommunikation) zugänglich ist. Die SSL -Verschlüsselung kann über die Variable WORKSPACE_SSL_ENABLED aktiviert werden.
Wenn auf true festgelegt wird, müssen entweder die Datei cert.crt und cert.key an /resources/ssl montiert oder, falls die Zertifikatdateien vorhanden sind, der Container selbst signiert Zertifikate generiert. Wenn beispielsweise der /path/with/certificate/files im lokalen System ein gültiges Zertifikat für die Hostdomäne ( cert.crt und cert.key -Datei) enthält, kann sie wie unten gezeigt verwendet werden:
docker run
-p 8080:8080
--env WORKSPACE_SSL_ENABLED= " true "
-v /path/with/certificate/files:/resources/ssl:ro
mltooling/ml-workspace:0.13.2 Wenn Sie den Arbeitsbereich auf einer öffentlichen Domain hosten möchten, empfehlen wir, Let's Encrypt zu verwenden, um ein vertrauenswürdiges Zertifikat für Ihre Domain zu erhalten. Um das generierte Zertifikat (z. B. über Certbot -Tool) für den Arbeitsbereich zu verwenden, entspricht der privkey.pem der cert.key -Datei und der fullchain.pem in der Datei cert.crt .
Wenn Sie die SSL -Unterstützung aktivieren, müssen Sie über
https://auf den Arbeitsbereich zugreifen, nicht über einfachhttp://.
Standardmäßig verfügt der Arbeitsbereich Container über keine Ressourcenbeschränkungen und kann so viel von einer bestimmten Ressource verwenden, wie der Kernel -Scheduler des Hosts dies zulässt. Docker bietet Möglichkeiten, zu steuern, wie viel Speicher oder CPU ein Container verwenden kann, indem die Flags der Laufzeitkonfiguration des Befehls Docker -Run festgelegt wird.
Der Arbeitsbereich erfordert mindestens 2 CPUs und 500 MB, um stabil zu laufen und verwendbar zu sein.
Der folgende Befehl beschränkt beispielsweise den Arbeitsbereich auf nur maximal 8 CPUs, 16 GB Speicher und 1 GB gemeinsamer Speicher (siehe bekannte Probleme):
docker run -p 8080:8080 --cpus=8 --memory=16g --shm-size=1G mltooling/ml-workspace:0.13.2Weitere Optionen und Dokumentation zu Ressourcenbeschränkungen finden Sie im offiziellen Docker -Handbuch.
Wenn ein Proxy erforderlich ist, können Sie die Proxy -Konfiguration über die Variablen HTTP_PROXY , HTTPS_PROXY und NO_PROXY -Umgebung übergeben.
Zusätzlich zum wichtigsten Arbeitsbereichsbild ( mltooling/ml-workspace ) stellen wir andere Bildaromen bereit, die die Merkmale erweitern oder die Bildgröße minimieren, um eine Vielzahl von Anwendungsfällen zu unterstützen.
Der minimale Geschmack ( mltooling/ml-workspace-minimal ) ist unser kleines Bild, das die meisten Werkzeuge und Merkmale enthält, die im Abschnitt "Features" beschrieben wurden, ohne die meisten Python-Bibliotheken, die in unserem Hauptbild vorinstalliert sind. Jede Python -Bibliothek oder ein ausgeschlossenes Tool kann während der Laufzeit durch den Benutzer manuell installiert werden.
docker run -p 8080:8080 mltooling/ml-workspace-minimal:0.13.2 Der R-Aroma ( mltooling/ml-workspace-r ) basiert auf unserem Standard-Arbeitsbereichsbild und erweitert es mit dem R-Interpreter, R-Jupyter-Kernel, Rstudio-Server (Zugriff über Open Tool -> RStudio ) und eine Vielzahl beliebter Pakete aus dem R-Ökosystem.
docker run -p 8080:8080 mltooling/ml-workspace-r:0.12.1 Der Spark-Aroma ( mltooling/ml-workspace-spark ) basiert auf unserem R-Flavor-Arbeitsbereich und erweitert es mit der Spark Runtime, Spark-Jupyter-Kernel, Zeppelin-Notizbuch (Zugriff über Open Tool -> Zeppelin ), Pysspark, Hadoop, Java Kernel sowie einige zusätzliche zusätzliche Bibliotheken und einige zusätzliche Bibliotheken und einige zusätzliche Bibliotheken.
docker run -p 8080:8080 mltooling/ml-workspace-spark:0.12.1Derzeit unterstützt der GPU-Blavor Cuda 11.2 nur. Die Unterstützung für andere CUDA -Versionen könnte in Zukunft hinzugefügt werden.
Der GPU-Aroma ( mltooling/ml-workspace-gpu ) basiert auf unserem Standard-Arbeitsbereichsbild und erweitert ihn mit CUDA 10.1- und GPU-fähigen Versionen verschiedener maschineller Lernbibliotheken (z. B. Tensorflow, Pytorch, CNTK, JAX). Dieses GPU -Bild hat die folgenden zusätzlichen Anforderungen für das System:
>=460.32.03 (Anweisungen).docker run -p 8080:8080 --gpus all mltooling/ml-workspace-gpu:0.13.2docker run -p 8080:8080 --runtime nvidia --env NVIDIA_VISIBLE_DEVICES= " all " mltooling/ml-workspace-gpu:0.13.2Der GPU -Aroma wird auch mit einigen zusätzlichen Konfigurationsoptionen geliefert, wie unten erläutert:
| Variable | Beschreibung | Standard |
|---|---|---|
| Nvidia_visible_devices | Steuerelemente, auf welchen GPUs im Arbeitsbereich zugänglich sind. Standardmäßig sind alle GPUs des Hosts im Arbeitsbereich zugänglich. Sie können entweder all , none verwenden oder eine von Kommas getrennte Liste von Geräte-IDs (z. B. 0,1 ) angeben. Sie finden die Liste der verfügbaren Geräte-IDs, indem Sie nvidia-smi auf dem Host-Computer ausführen. | alle |
| CUDA_VISIBLE_DEVICES | Steuert, welche GPUs CUDA -Anwendungen im Arbeitsbereich ausführen. Standardmäßig wird alle GPUs, auf die der Arbeitsbereich zugreifen kann, sichtbar sein. Um Anwendungen einzuschränken, geben Sie eine von Kommas getrennte Liste der internen Geräte-IDs (z. B. 0,2 ) an, basierend auf den verfügbaren Geräten innerhalb des Arbeitsbereichs (Run nvidia-smi ). Im Vergleich zu NVIDIA_VISIBLE_DEVICES kann der Arbeitsbereich Benutzer weiterhin auf andere GPUs zugreifen, indem er diese Konfiguration innerhalb des Arbeitsbereichs überschreibt. | |
| Tf_force_gpu_allow_growth | Standardmäßig wird der Großteil des GPU -Speichers durch die erste Ausführung eines Tensorflow -Diagramms zugewiesen. Während dieses Verhalten für Produktionspipelines wünschenswert sein kann, ist es für den interaktiven Gebrauch weniger wünschenswert. Verwenden Sie true , um die dynamische GPU -Speicherzuweisung oder false zu aktivieren, um den TensorFlow zur Zuweisung des gesamten Speichers bei der Ausführung zu veranlassen. | WAHR |
Der Arbeitsbereich ist als Einzelbenutzerentwicklungsumgebung konzipiert. Für ein Multi-User-Setup empfehlen wir die Bereitstellung? ML Hub. ML HUB basiert auf JupyterHub mit der Aufgabe, Instanzen für mehrere Benutzer zu laken, zu verwalten und zu proxy -Arbeitsbereiche zu verwalten und zu sterben.
ML Hub erleichtert es einfach, eine Multi-Benutzer-Umgebung auf einem einzelnen Server (über Docker) oder einem Cluster (über Kubernetes) einzurichten und unterstützt eine Vielzahl von Nutzungsszenarien und Authentifizierungsanbietern. Sie können ML Hub ausprobieren:
docker run -p 8080:8080 -v /var/run/docker.sock:/var/run/docker.sock mltooling/ml-hub:latestWeitere Informationen und Dokumentation zu ML Hub finden Sie in der Github -Site.
Dieses Projekt wird von Benjamin Rätlein, Lukas Masuch und Jan Kalkan gepflegt. Bitte haben Sie Verständnis dafür, dass wir nicht in der Lage sind, individuelle Unterstützung per E -Mail zu bieten. Wir glauben auch, dass Hilfe viel wertvoller ist, wenn sie öffentlich geteilt wird, damit mehr Menschen davon profitieren können.
| Typ | Kanal |
|---|---|
| Fehlerberichte | |
| ? Feature -Anfragen | |
| ? Nutzungsfragen | |
| ? Ankündigungen | |
| ❓ Andere Anfragen |
Jupyter • Desktop -GUI • VS -Code • JupyterLab • GIT -Integration • Dateifreigabe • Zugriffsanschlüsse • Tensorboard • Erweiterbarkeit • Hardwareüberwachung • SSH -Zugriff • Remote -Entwicklung • Jobausführung
Der Arbeitsbereich ist mit einer Auswahl an erstklassigen Open-Source-Entwicklungstools ausgestattet, um den Workflow für maschinelles Lernen zu unterstützen. Viele dieser Tools können aus dem Menü Open Tool von Jupyter (Hauptanwendung des Arbeitsbereichs) gestartet werden:
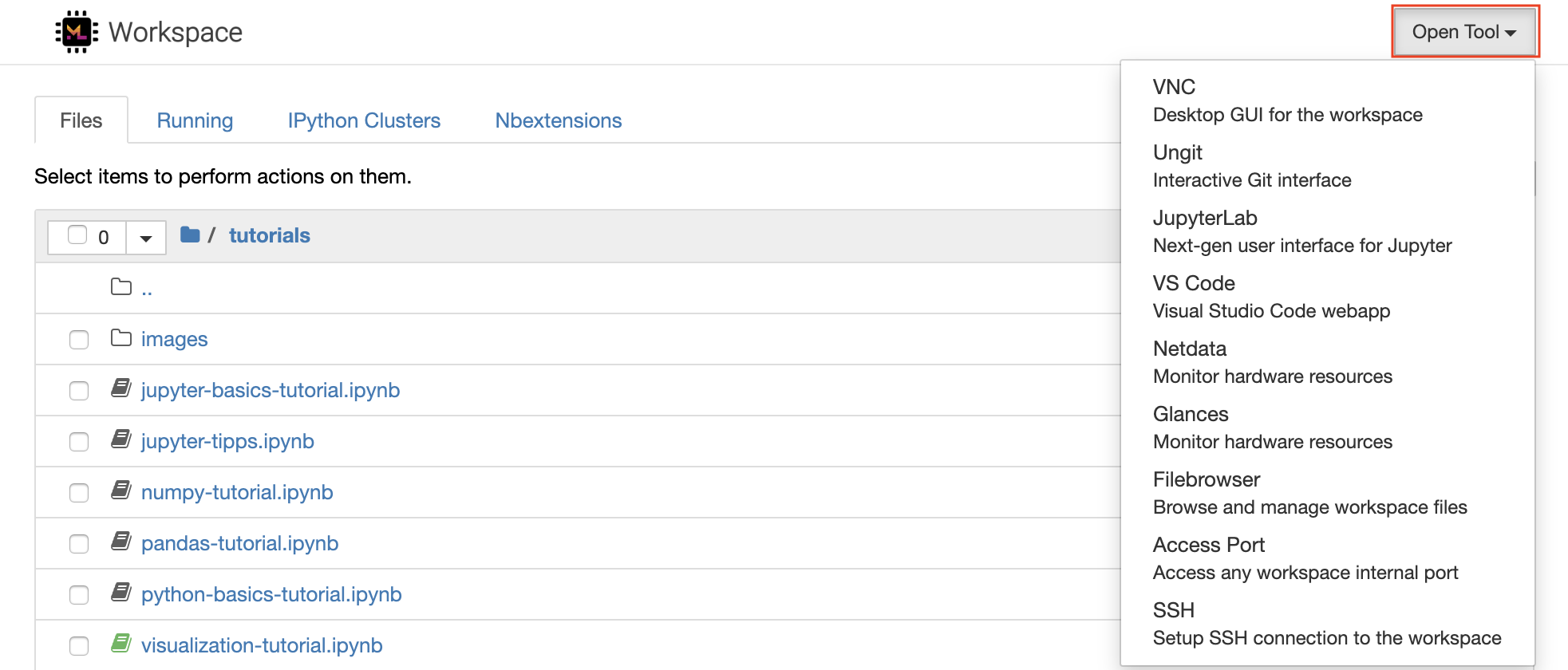
In Ihrem Arbeitsbereich verfügen Sie über vollständige Root- und Sudo-Berechtigungen, um eine Bibliothek oder ein beliebiges Tool zu installieren, das Sie über Terminal benötigen (z. B.
pip,apt-get,condaodernpm). Weitere Möglichkeiten finden Sie, um den Arbeitsbereich innerhalb des Abschnitts der Erweiterbarkeit zu erweitern
Jupyter Notebook ist eine webbasierte interaktive Umgebung zum Schreiben und Ausführen von Code. Die Hauptbausteine von Jupyter sind der Dateibrowser, der Notebook-Editor und die Kernel. Der Dateibrowser bietet einen interaktiven Dateimanager für alle Notizbücher, Dateien und Ordner im Verzeichnis /workspace .
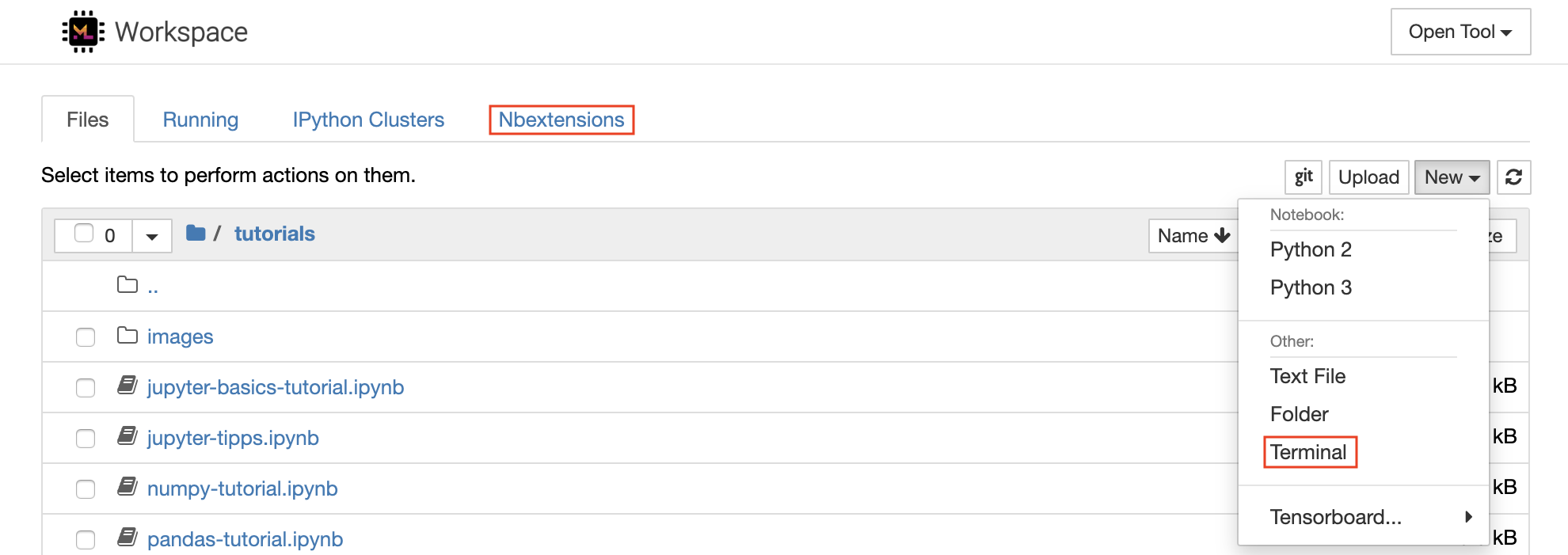
Ein neues Notizbuch kann erstellt werden, indem Sie oben in der Liste auf die New Dropdown-Schaltfläche klicken und den gewünschten Sprachkernel auswählen.
Sie können auch interaktive Terminalinstanzen hervorbringen, indem Sie
New -> Terminalim Dateibrowser auswählen.
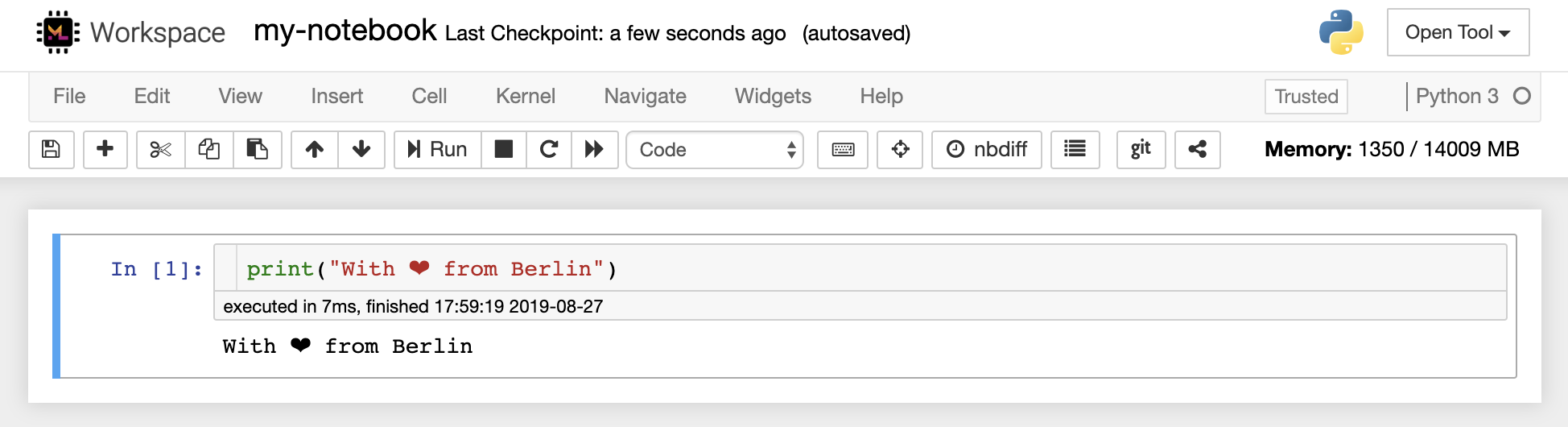
Mit dem Notebook -Editor können Benutzer Dokumente, die Live -Code, Markdown -Text, Shell -Befehle, Latex -Gleichungen, interaktive Widgets, Handlungen und Bilder enthalten. Diese Notebook-Dokumente bieten eine vollständige und in sich geschlossene Aufzeichnung einer Berechnung, die in verschiedene Formate umgewandelt und mit anderen geteilt werden kann.
Dieser Arbeitsbereich verfügt über eine Vielzahl von Jupyter-Erweiterungen von Drittanbietern . Sie können diese Erweiterungen in der Registerkarte "NBEXTENSIONS CONFESTENS:
nbextensionsauf dem Dateibrowser" konfigurieren
Mit dem Notebook kann Code in einer Reihe verschiedener Programmiersprachen ausgeführt werden. Für jedes Notebook -Dokument, das ein Benutzer öffnet, startet die Webanwendung einen Kernel , der den Code für dieses Notebook ausführt und die Ausgabe zurückgibt. Dieser Arbeitsbereich hat einen Python 3-Kernel vorinstalliert. Zusätzliche Kerne können installiert werden, um Zugriff auf andere Sprachen (z. B. R, Scala, GO) oder zusätzliche Rechenressourcen (z. B. GPUs, CPUs, Speicher) zu erhalten.
Python 2 ist deaktiviert und wir empfehlen nicht, es zu verwenden. Sie können jedoch weiterhin einen Python 2.7-Kernel über diesen Befehl installieren:
/bin/bash /resources/tools/python-27.sh
Dieser Arbeitsbereich bietet einen HTTP-basierten VNC-Zugriff auf den Arbeitsbereich über Novnc. Dadurch können Sie mit einer voll befriedigten Desktop-GUI im Arbeitsbereich zugreifen und arbeiten. Um auf diese Desktop -GUI zuzugreifen, gehen Sie zum Open Tool , wählen Sie VNC und klicken Sie auf die Schaltfläche Connect . Wenn Sie nach einem Passwort gefragt werden, verwenden Sie vncpassword .
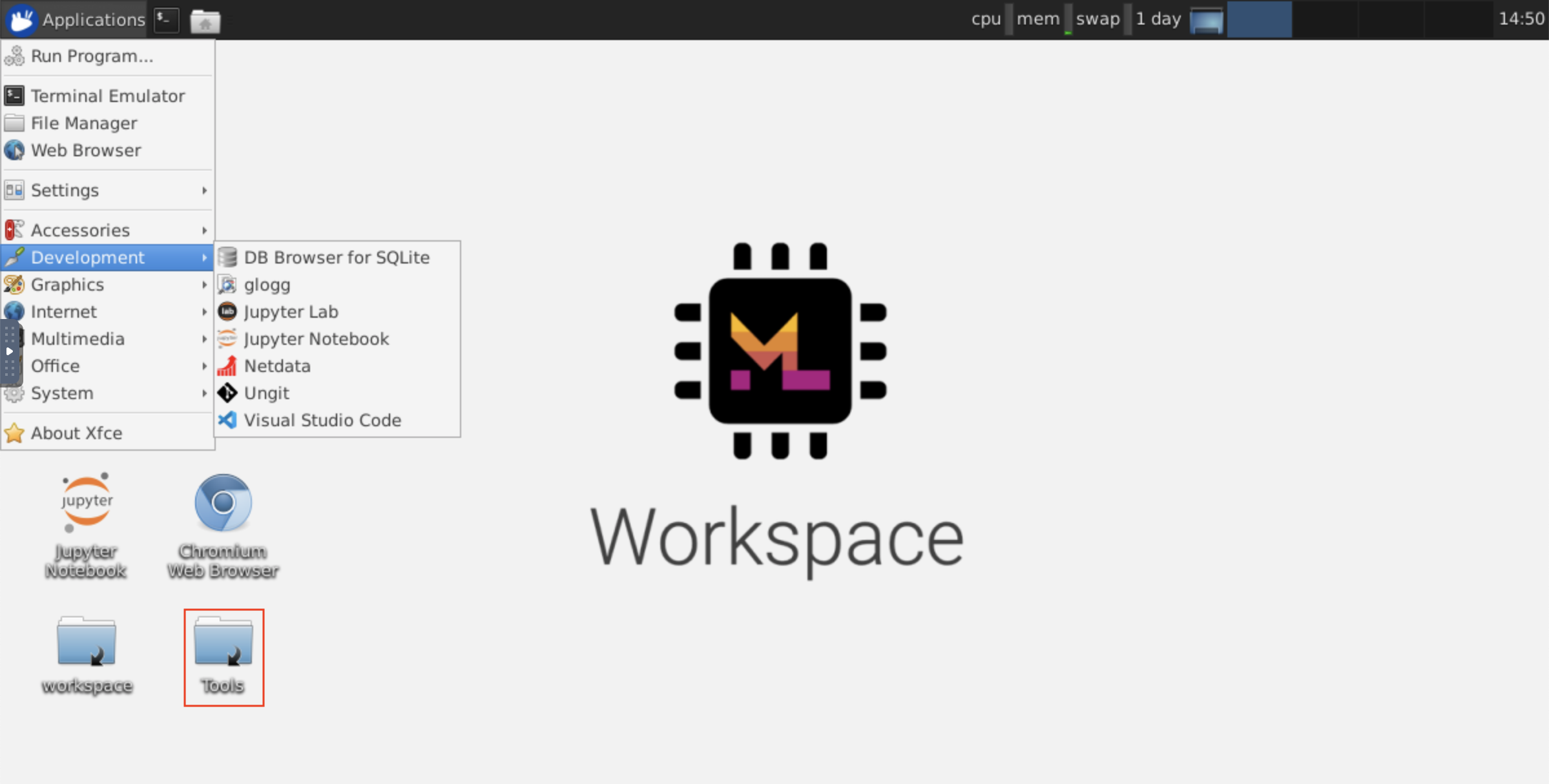
Sobald Sie angeschlossen sind, sehen Sie eine Desktop-GUI, mit der Sie vollwertige Webbrowser oder ein anderes Tool für Ubuntu installieren und verwenden können. In dem Ordner Tools auf dem Desktop finden Sie eine Sammlung von Installationsskripten, mit denen einige der am häufigsten verwendeten Entwicklungswerkzeuge wie Atom, Pycharm, Runtime, R-Studio oder Postmann installiert werden (Doppelklicken Sie einfach auf das Skript).
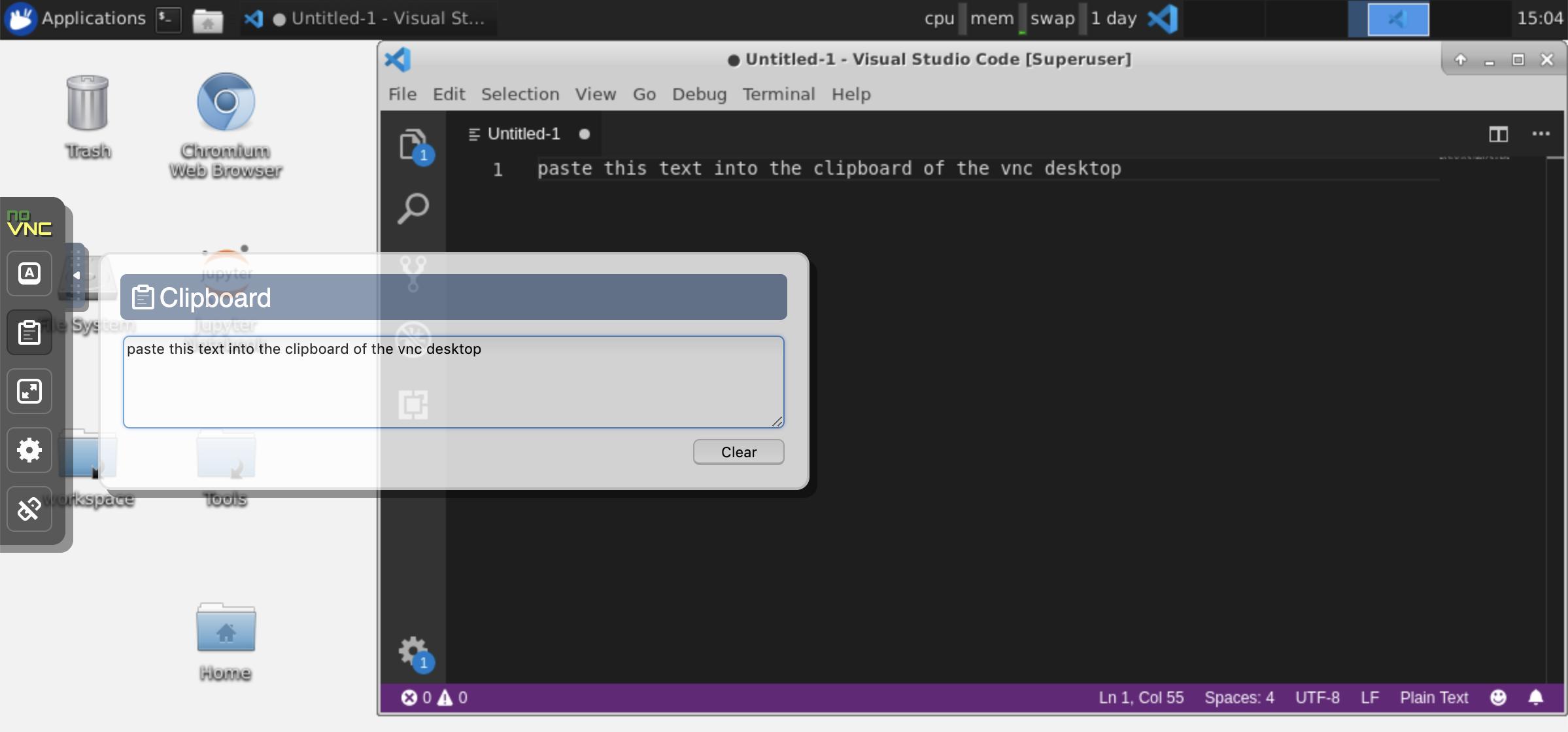
Zwischenablage: Wenn Sie die Zwischenablage zwischen Ihrem Computer und dem Arbeitsbereich freigeben möchten, können Sie die nachstehend beschriebene Kopierfunktionalität verwenden:
Langzeitaufgaben: Verwenden Sie die Desktop-GUI für langjährige Jupyter-Ausführungen. Durch Ausführen von Notizbüchern aus dem Browser Ihrer Workspace Desktop -GUI wird alle Ausgaben auch dann mit dem Notebook synchronisiert, wenn Sie Ihren Browser vom Notebook getrennt haben.
Visual Studio Code ( Open Tool -> VS Code ) ist ein leichter, aber leistungsstarker Code-Editor mit Open-Source-Code mit integrierter Unterstützung für eine Vielzahl von Sprachen und ein reichhaltiges Ökosystem der Erweiterungen. Es kombiniert die Einfachheit eines Quellcode -Editors mit leistungsstarken Entwickler -Tooling wie IntelliSense -Code -Abschluss und Debugging. Der Arbeitsbereich integriert VS-Code als webbasierte Anwendung, die über das auf dem fantastische Code-Server-Projekt basierende Browser basiert. Sie können jede Funktion nach Ihren Wünschen anpassen und eine beliebige Anzahl von Erweiterungen von Drittanbietern installieren.
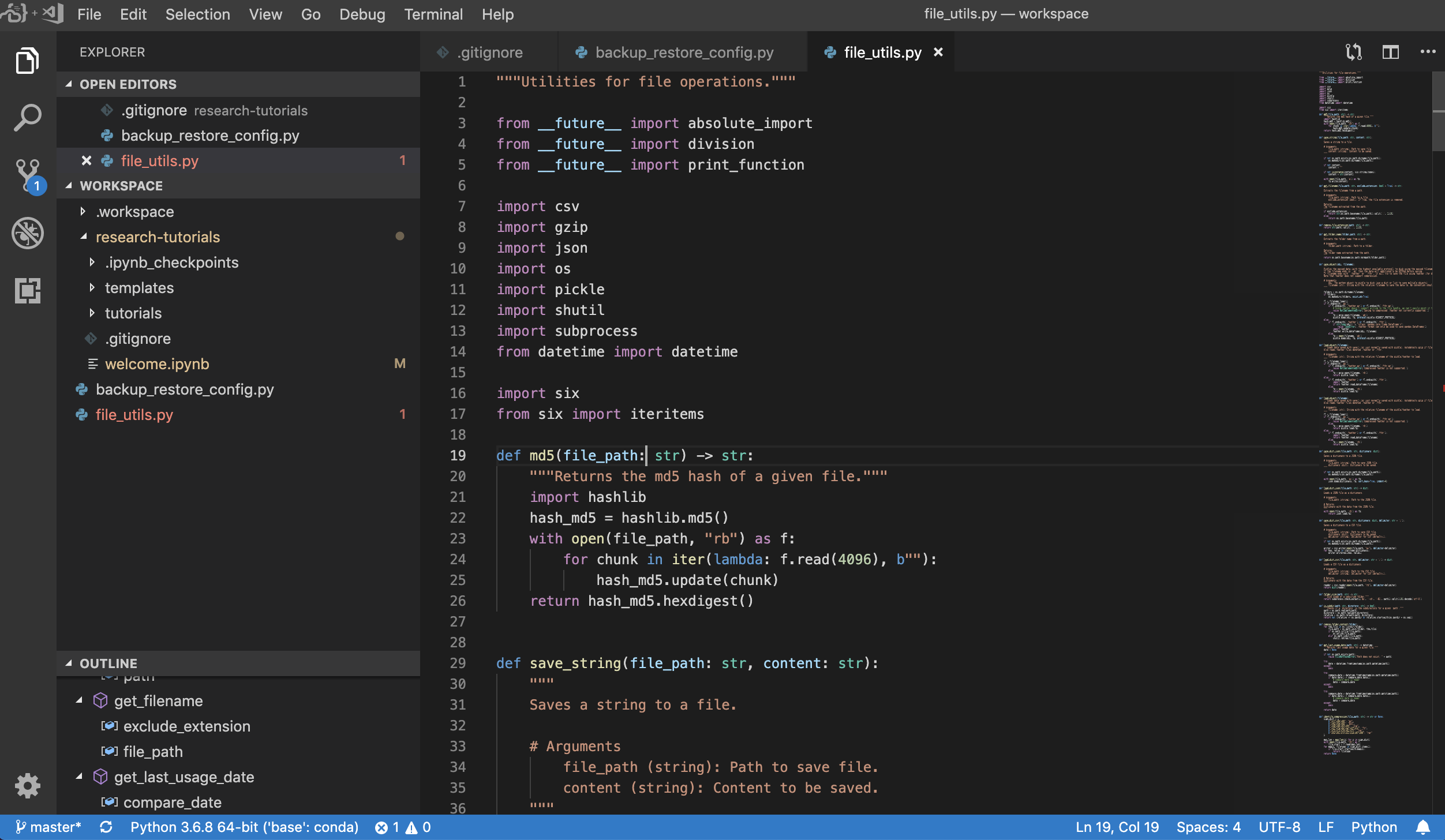
Der Arbeitsbereich bietet auch eine VS -Code -Integration in Jupyter, mit der Sie eine VS -Code -Instanz für einen beliebigen Ordner öffnen können, wie unten gezeigt:

JupyterLab ( Open Tool -> JupyterLab ) ist die Benutzeroberfläche der nächsten Generation für das Projekt Jupyter. Es bietet alle vertrauten Bausteine des klassischen Jupyter -Notizbuchs (Notebook, Terminal, Texteditor, Dateibrowser, Rich -Ausgänge usw.) in einer flexiblen und leistungsstarken Benutzeroberfläche. Diese JupyterLab-Instanz ist vorinstalliert mit einigen hilfreichen Erweiterungen wie einem JupyterLab-TOC, Jupyterlab-Git und JuptyterLab-Tensorboard.
Die Versionskontrolle ist ein entscheidender Aspekt der produktiven Zusammenarbeit. Um diesen Vorgang so reibungslos wie möglich zu gestalten, haben wir eine maßgefertigte Jupyter-Erweiterung integriert, die sich auf das Drücken einzelner Notizbücher, einen vollwertigen webbasierten Git-Client (UNGIT), ein Tool zum Öffnen und Bearbeiten einfacher Textdokumente (zB, .py , .md ) als Notizbücher (JupyText) sowie ein Notebook-Tool (NBDIME) spezialisiert haben. Darüber hinaus bieten JupyterLab und VS Code GIT-basierte GIT-Clients an.
Für die Klonen von Repositories über https empfehlen wir, zum gewünschten Stammordner zu navigieren und wie unten gezeigt auf die git -Schaltfläche zu klicken:

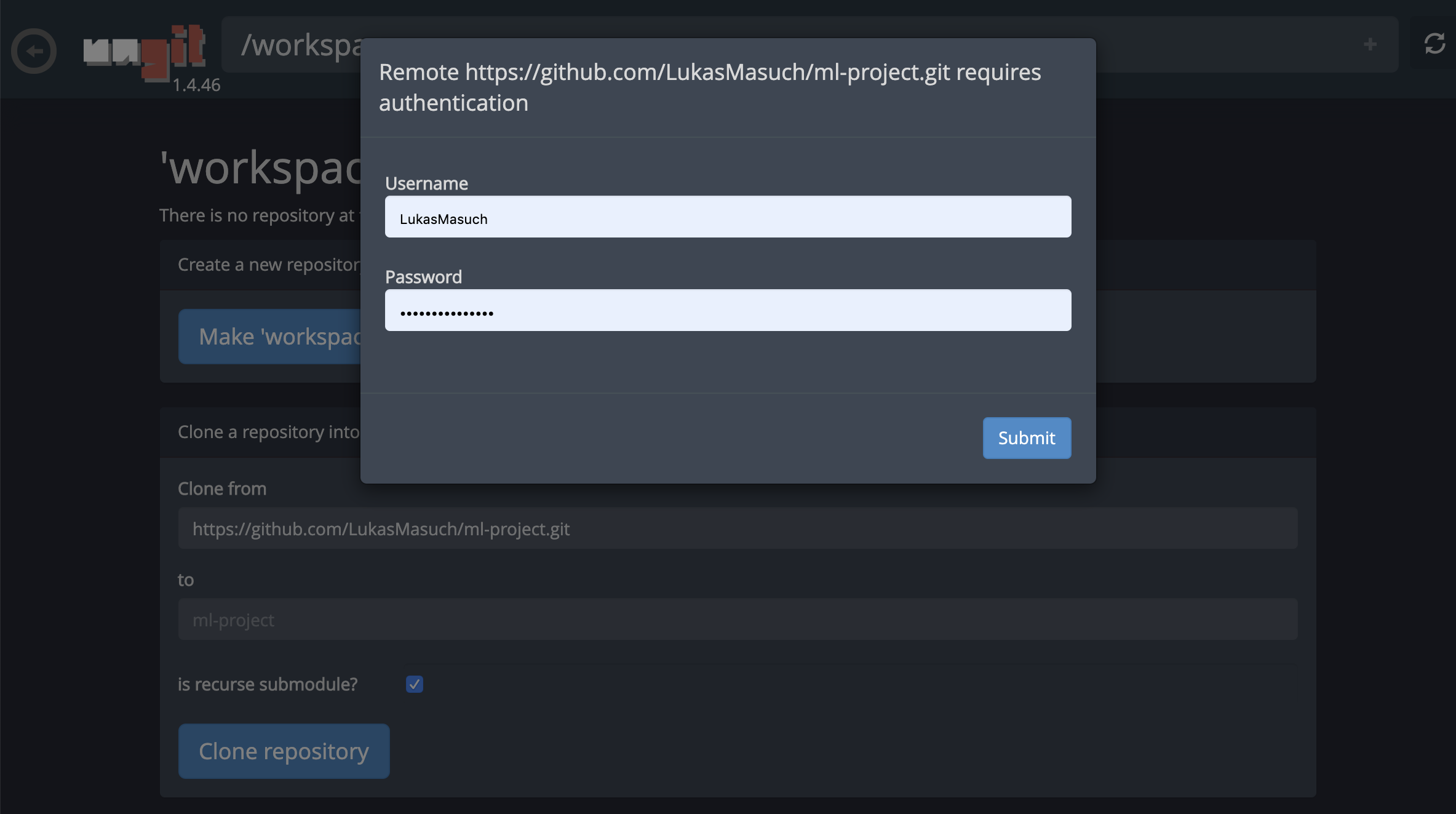
Dies könnte nach einigen erforderlichen Einstellungen gebeten und anschließend Ungit, einen webbasierten GIT-Client mit einer sauberen und intuitiven Benutzeroberfläche, eröffnet, die es bequem macht, Ihre Code-Artefakte zu synchronisieren. Innerhalb von UNGIT können Sie jedes Repository klonen. Wenn eine Authentifizierung erforderlich ist, werden Sie nach Ihren Anmeldeinformationen gefragt.
Um ein einzelnes Notizbuch in ein Remote -Git -Repository zu verabschieden, empfehlen wir, das in Jupyter integrierte GIT -Plugin zu verwenden, wie unten gezeigt:
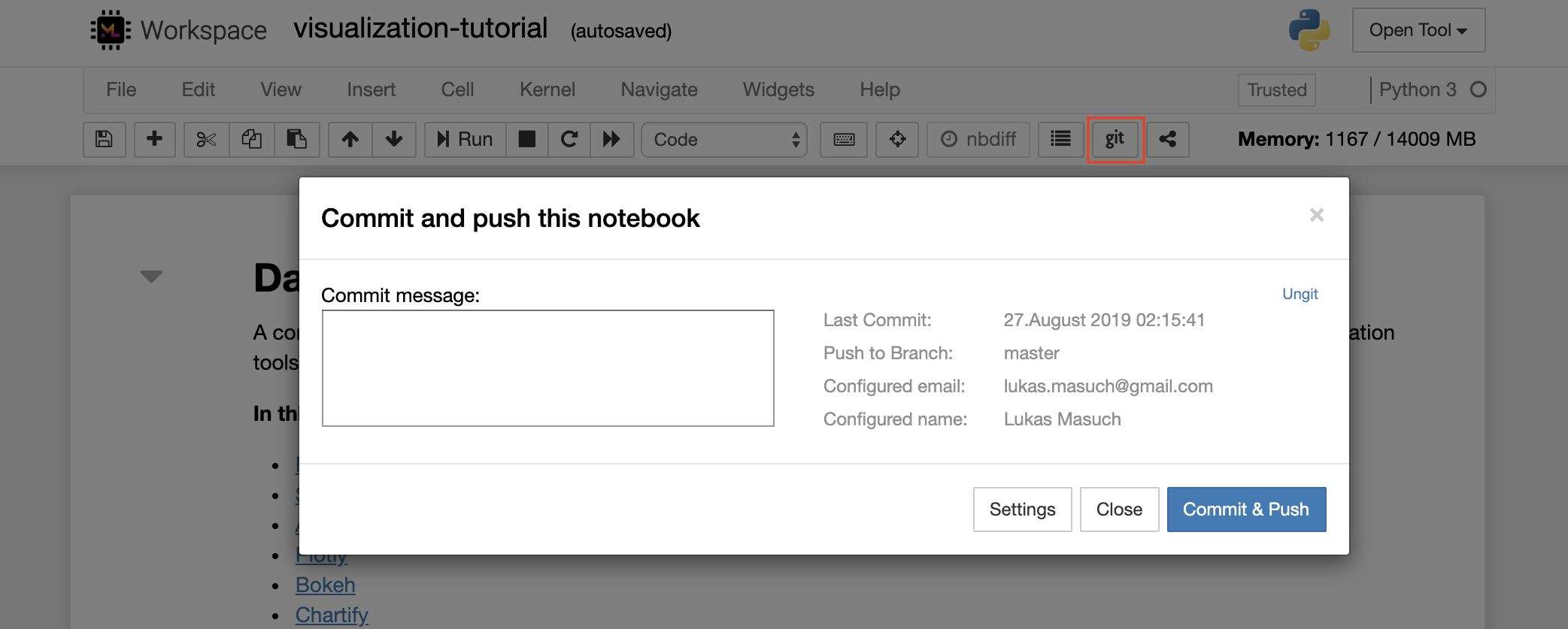
Für fortgeschrittene GIT -Operationen empfehlen wir, UNGIT zu verwenden. Mit Ungit können Sie die meisten gängigen Git -Aktionen wie Push, Pull, Merge, Zweig, Tag, Checkout und viele mehr ausführen.
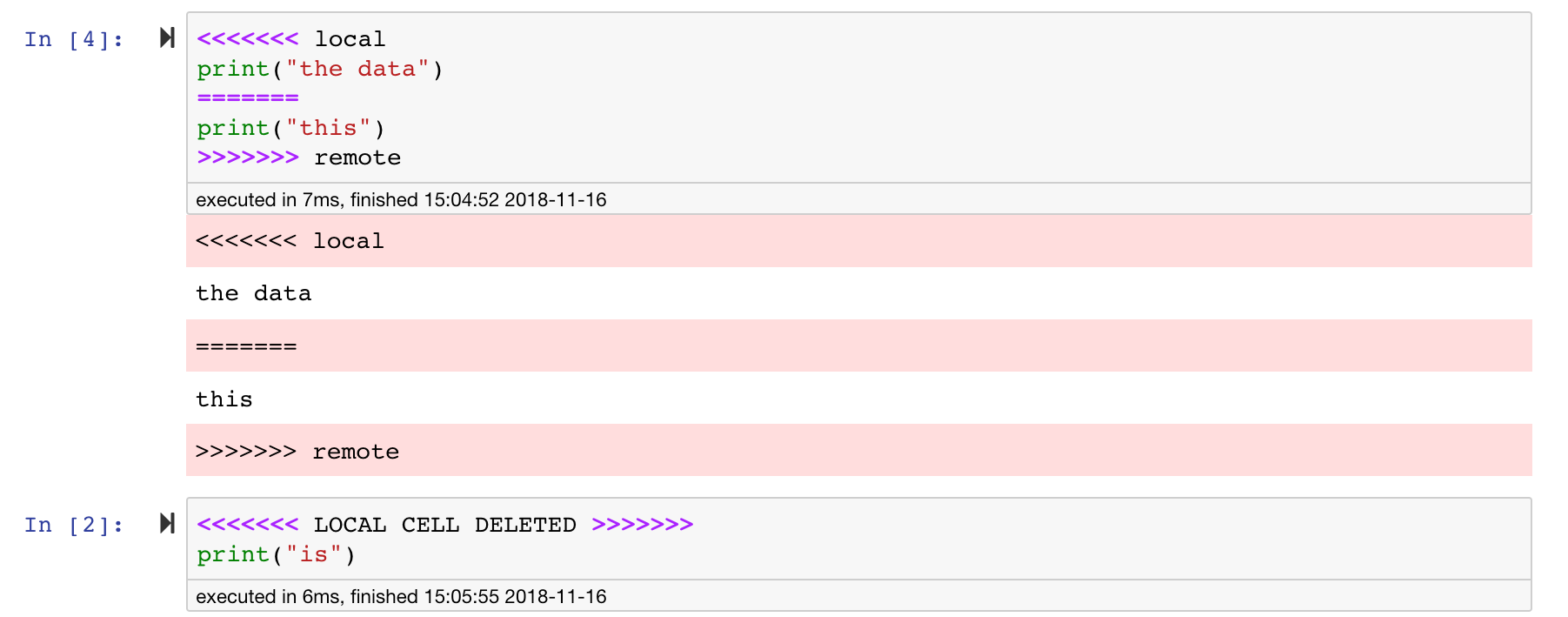
Jupyter -Notizbücher sind großartig, aber sie sind oft riesige Dateien mit einem sehr spezifischen JSON -Dateiformat. Um eine nahtlose Differenz und Verschmelzung über Git zu ermöglichen, ist dieser Arbeitsbereich mit NBDime vorinstalliert. NBDIME versteht die Struktur von Notebook -Dokumenten und trifft daher automatisch intelligente Entscheidungen bei der Differenzierung und Verschmelzung von Notizbüchern. In dem Fall, dass Sie Konflikte verschmelzen, stellt die NBDime sicher, dass das Notizbuch wie unten gezeigt von Jupyter lesbar ist:
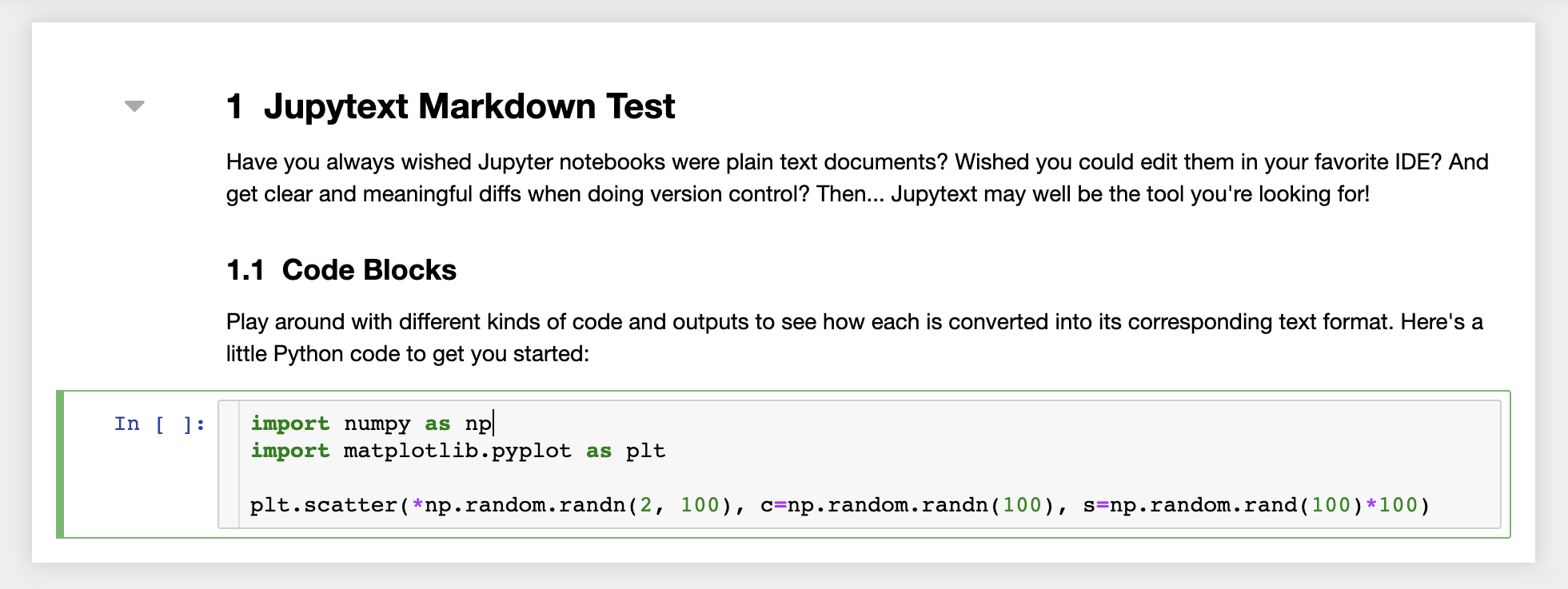
Darüber hinaus wird der Arbeitsbereich mit JupyText vorinstalliert, einem Jupyter-Plugin, das Notizbücher als Klartextdateien liest und schreibt. Auf diese Weise können Sie Skripte oder Markdown -Dateien (z. B. .py , .md ) als Notizbücher in Jupyter öffnen, bearbeiten und ausführen. Im folgenden Screenshot haben wir eine Markdown -Datei über Jupyter eröffnet:
In Kombination mit Git ermöglicht JupyText eine klare Diff -Geschichte und eine einfache Verschmelzung von Versionskonflikten. Bei beiden Tools wird die Zusammenarbeit an Jupyter -Notizbüchern mit Git unkompliziert.
Der Arbeitsbereich verfügt über eine Funktion, um eine Datei oder einen Ordner über einen mit Token geschützten Link zu teilen. Um Daten über einen Link freizugeben, wählen Sie eine beliebige Datei oder einen Ordner aus dem Jupyter -Verzeichnisbaum aus und klicken Sie auf die Schaltfläche Freigabe, wie im folgenden Screenshot gezeigt:
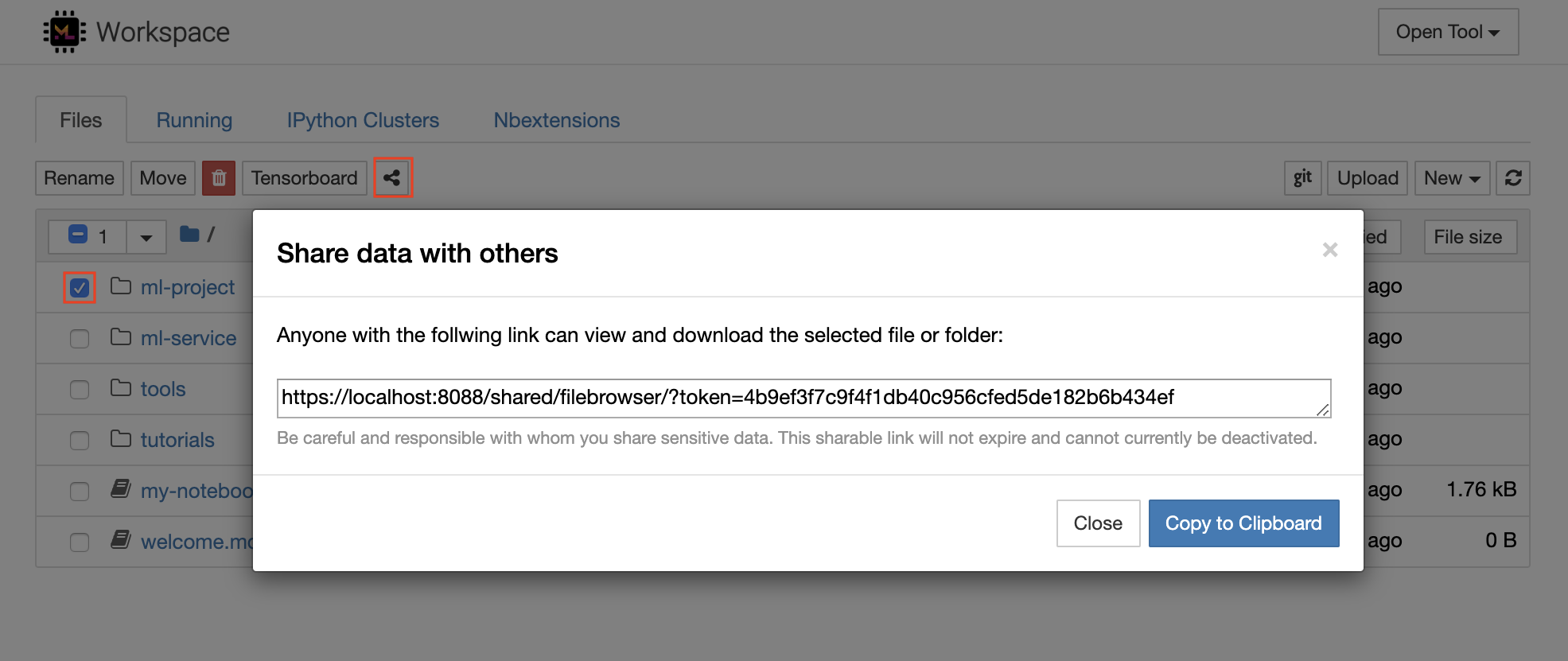
Dadurch wird ein eindeutiger Link generiert, der über ein Token geschützt ist, mit dem jeder mit dem Linkzugriff zu Ansicht und Herunterladen der ausgewählten Daten über die Dateibrowser -Benutzeroberfläche erhalten wird:
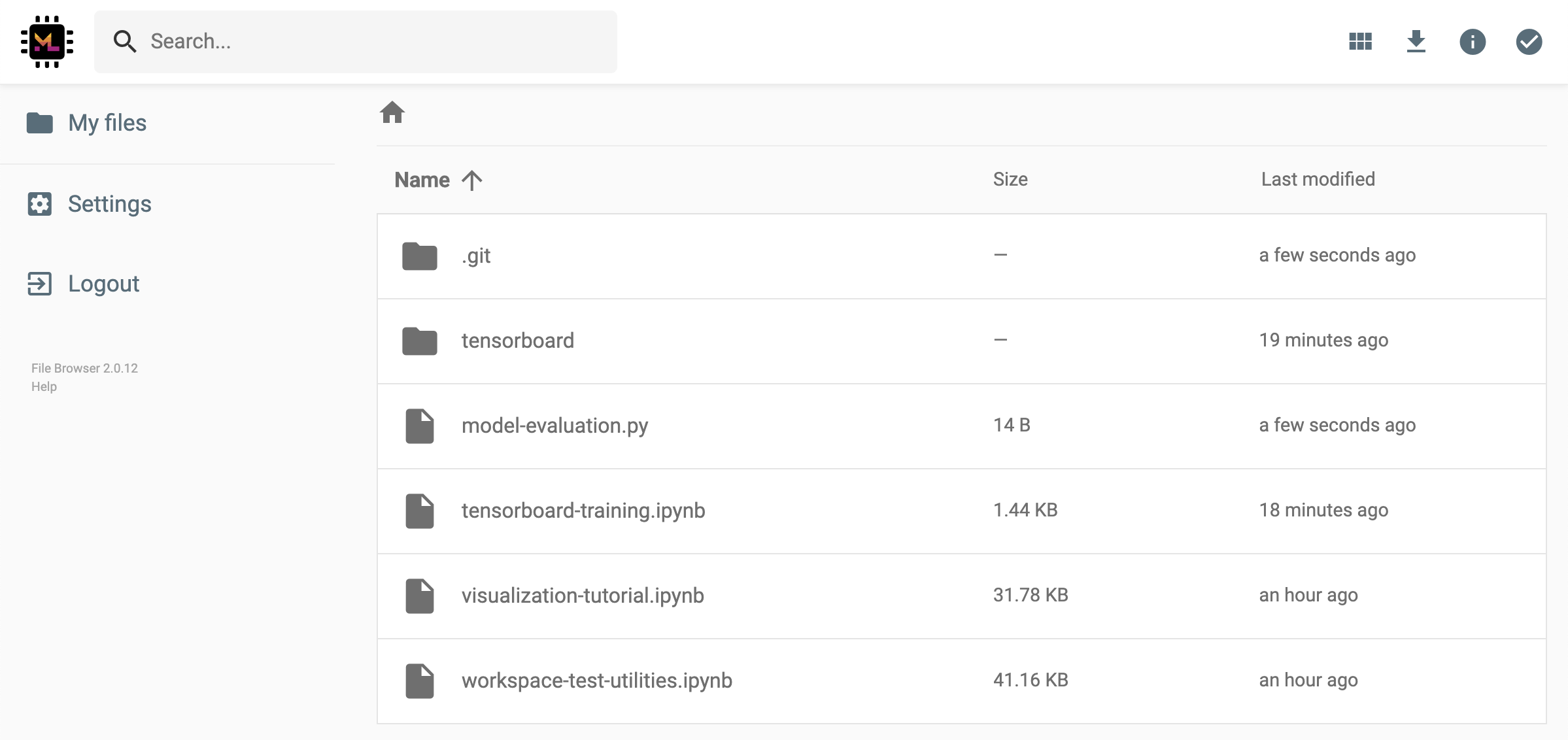
So deaktivieren oder verwalten (z. B. Berechtigungen bearbeiten) gemeinsam genutzte Links, öffnen Sie den FileBrowser über Open Tool -> Filebrowser und wählen Sie Settings->User Management .
Es ist möglich, auf jeden internen Arbeitsbereich sicher zugreifen, indem er Open Tool -> Access Port . Mit dieser Funktion können Sie auf eine REST -API oder Webanwendung zugreifen, die direkt mit Ihrem Browser im Arbeitsbereich ausgeführt wird. Mit der Funktion können Entwickler REST -APIs oder Webanwendungen direkt aus dem Arbeitsbereich erstellen, ausführen, testen und debuggen.
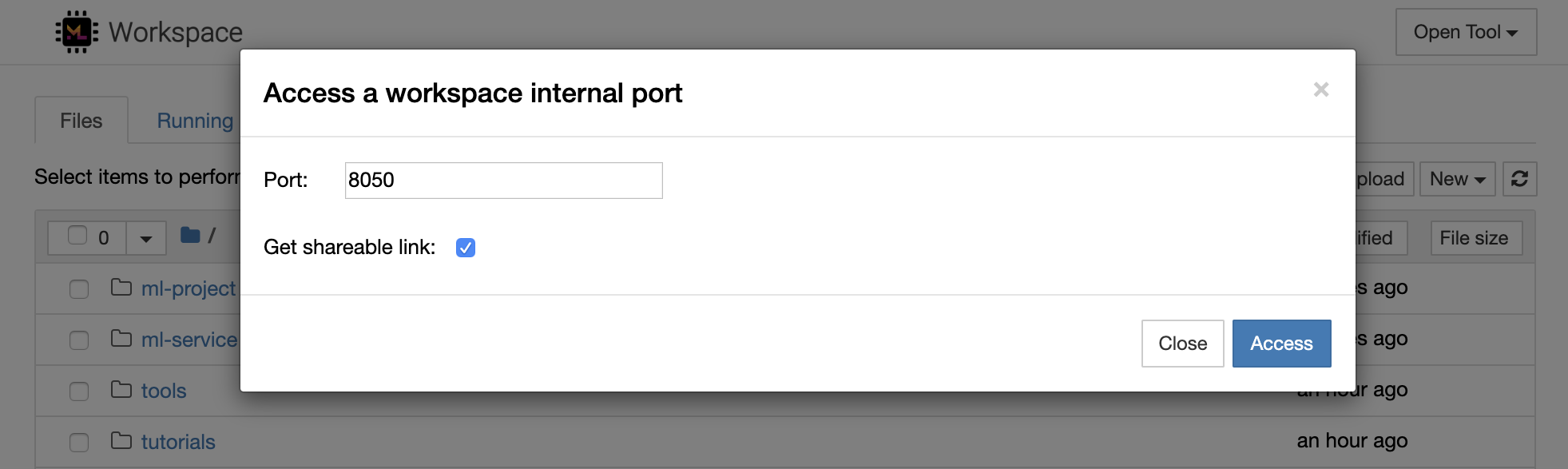
Wenn Sie einen HTTP -Client verwenden oder auf einen bestimmten Port freigeben möchten, können Sie die Option Get shareable link auswählen. Dies erzeugt einen mit Token sichergestellten Link, den jeder, der auf den Link zugreifen kann, auf den angegebenen Port zugreifen kann.
Die HTTP -App muss von einem relativen URL -Pfad aufgelöst werden oder einen Basispfad (
/tools/PORT/) konfigurieren. Auf diese Weise zugängliche Tools werden durch das Authentifizierungssystem des Arbeitsbereichs gesichert! Wenn Sie sich entscheiden, einen anderen Port des Containers selbst zu veröffentlichen, anstatt diese Funktion zugänglich zu machen, um ein Tool zugänglich zu machen, sicherstellen Sie ihn sicher, dass Sie ihn über einen Authentifizierungsmechanismus sichern!
1234 , indem Sie diesen Befehl in einem Terminal innerhalb des Arbeitsbereichs ausführen: python -m http.server 1234Open Tool -> Access Port , Eingangsport 1234 und wählen Sie die Option Get shareable link ab.Access , und Sie sehen den Inhalt von Pythons http.server . SSH bietet eine leistungsstarke Reihe von Funktionen, mit denen Sie mit Ihren Entwicklungsaufgaben produktiver werden können. Sie können problemlos eine sichere und passwortlose SSH -Verbindung zu einem Arbeitsbereich einrichten, indem Sie Open Tool -> SSH auswählen. Dadurch wird ein sicherer Setup -Befehl generiert, der auf einem beliebigen Linux- oder Mac -Computer ausgeführt werden kann, um eine passwortlose und sichere SSH -Verbindung zum Arbeitsbereich zu konfigurieren. Alternativ können Sie auch das Setup -Skript herunterladen und es ausführen (anstatt den Befehl zu verwenden).
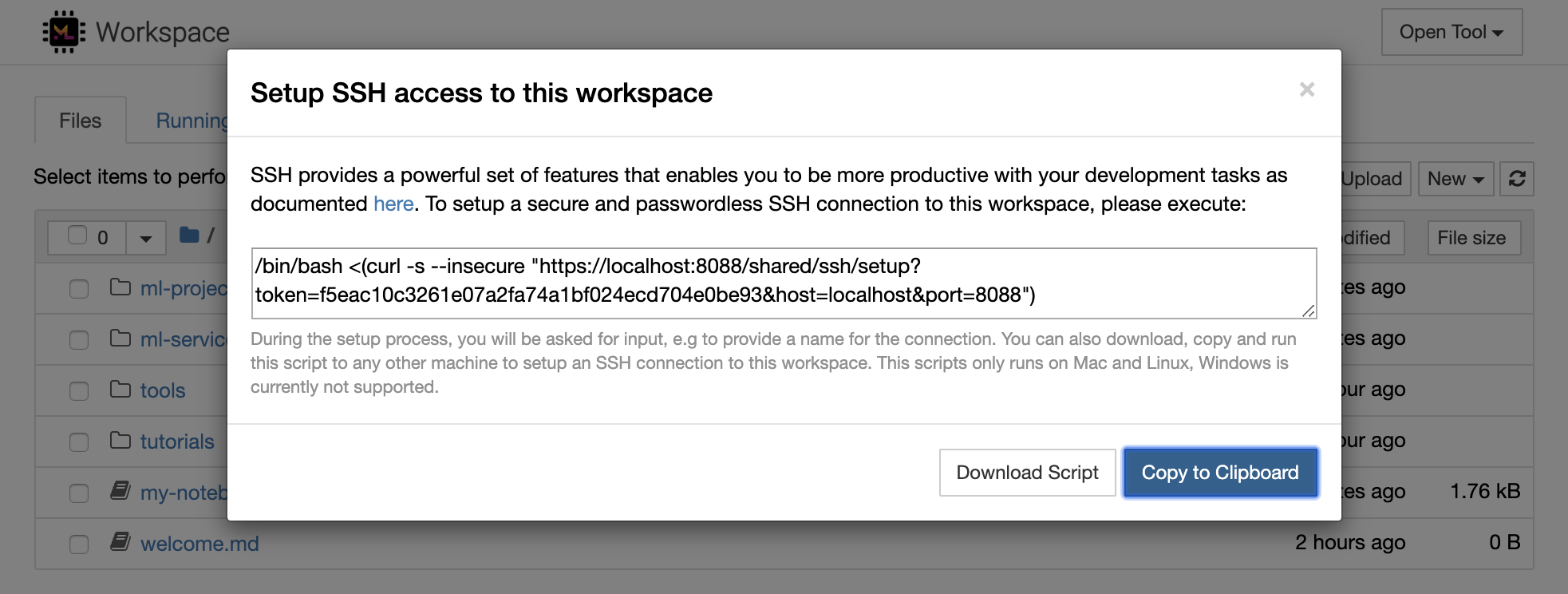
Das Setup -Skript wird nur auf Mac und Linux ausgeführt. Windows wird derzeit nicht unterstützt.
Führen Sie einfach den Befehl oder Skript für Setup oder Skript auf dem Computer aus, von dem Sie eine Verbindung zum Arbeitsbereich einstellen möchten, und geben Sie einen Namen für die Verbindung (z. B. my-workspace ) ein. Sie können auch nach zusätzlichen Eingaben während des Vorgangs gefragt werden, z. B. um einen Remote -Kernel zu installieren, wenn remote_ikernel installiert ist. Sobald die passwortlose SSH-Verbindung erfolgreich eingerichtet und getestet wurde, können Sie sich sicher eine Verbindung zum Arbeitsbereich herstellen, indem Sie einfach ssh my-workspace ausführen.
Neben der Möglichkeit, Befehle auf einer Remote -Maschine auszuführen, bietet SSH auch eine Vielzahl anderer Funktionen, die Ihren Entwicklungsworkflow wie in den folgenden Abschnitten beschrieben verbessern können.
Eine SSH -Verbindung kann zum Tunnelantragsanschluss von der Remote -Maschine zum lokalen Computer oder umgekehrt verwendet werden. Sie können beispielsweise den Internationalen Port 5901 (VNC Server) für den internationalen Port 5000 auf den lokalen Computer aufzeigen:
ssh -nNT -L 5000:localhost:5901 my-workspaceVerwenden Sie die Option
-R(anstelle von-L), um einen Anwendungsport von Ihrem lokalen Computer einem Arbeitsbereich auszusetzen.
Nachdem der Tunnel festgelegt wurde, können Sie Ihren bevorzugten VNC -Viewer auf Ihrem lokalen Computer verwenden und eine Verbindung zu vnc://localhost:5000 herstellen (Standardkennwort: vncpassword ). Um den Tunnelverbindung resistenter und zuverlässiger zu gestalten, empfehlen wir, AutoSH zu verwenden, um SSH -Tunnel automatisch neu zu starten, wenn die Verbindung stirbt:
autossh -M 0 -f -nNT -L 5000:localhost:5901 my-workspacePort-Tunneling ist sehr nützlich, wenn Sie ein serverbasiertes Tool in dem Arbeitsbereich gestartet haben, das Sie für einen anderen Computer zugänglich machen möchten. In seiner Standardeinstellung verfügt der Arbeitsbereich über eine Vielzahl von Tools, die bereits auf verschiedenen Ports ausgeführt werden, wie z. B.:
8080 : Hauptarbeitsportanschluss mit Zugriff auf alle integrierten Tools.8090 : Jupyter Server.8054 : VS -Codeserver.5901 : VNC Server.22 : SSH -Server.Sie finden Portinformationen zu allen Tools in der Supervisor -Konfiguration.
Weitere Informationen zum Port -Tunneling/-wesung empfehlen diesen Leitfaden.
Mit SCP können Dateien und Verzeichnisse über SSH -Verbindungen sicher, von oder zwischen verschiedenen Maschinen kopiert werden. Um eine lokale Datei ( ./local-file.txt ) in den Ordner /workspace im Arbeitsbereich zu kopieren, führen Sie aus:
scp ./local-file.txt my-workspace:/workspace Führen Sie aus, um das Verzeichnis /workspace von my-workspace in das Arbeitsverzeichnis der lokalen Maschine zu kopieren:
scp -r my-workspace:/workspace .Weitere Informationen zu SCP empfehlen diesen Leitfaden.
RSYNC ist ein Dienstprogramm zur effizienten Übertragung und Synchronisierung von Dateien zwischen verschiedenen Maschinen (z. B. über SSH -Verbindungen), indem die Änderungszeiten und -größen von Dateien verglichen werden. Der Befehl rsync bestimmt, welche Dateien jedes Mal aktualisiert werden müssen, wenn er ausgeführt wird. Dies ist weitaus effizienter und bequemer als die Verwendung von SCP oder SFTP. Führen Sie beispielsweise alle Inhalte eines lokalen Ordners ( ./local-project-folder/ ) in den /workspace/remote-project-folder/ Ordner im Arbeitsbereich aus:
rsync -rlptzvP --delete --exclude= " .git " " ./local-project-folder/ " " my-workspace:/workspace/remote-project-folder/ "Wenn Sie einige Änderungen im Ordner im Arbeitsbereich haben, können Sie diese Änderungen wieder in den lokalen Ordner synchronisieren, indem Sie die Quell- und Zielargumente ändern:
rsync -rlptzvP --delete --exclude= " .git " " my-workspace:/workspace/remote-project-folder/ " " ./local-project-folder/ "Sie können diese Befehle jedes Mal, wenn Sie die neueste Kopie Ihrer Dateien synchronisieren möchten. RSYNC sorgt dafür, dass nur Updates übertragen werden.
Weitere Informationen zu RSYNC finden Sie auf dieser Mannseite.
Neben dem Kopieren und Synchronisieren von Daten kann auch eine SSH -Verbindung verwendet werden, um Verzeichnisse von einem Remote -Computer über SSHFs in das lokale Dateisystem zu montieren. Führen Sie beispielsweise das Verzeichnis /workspace von my-workspace in einen lokalen Pfad (z /local/folder/path ) aus:
sshfs -o reconnect my-workspace:/workspace /local/folder/pathSobald das Remote -Verzeichnis montiert ist, können Sie mit dem Remote -Dateisystem wie in jedem lokalen Verzeichnis und jeder lokalen Datei interagieren.
Weitere Informationen zu SSHFs empfehlen diesen Leitfaden.
Der Arbeitsbereich kann als Remote -Laufzeit (auch als Remote -Kernel/Maschine/Dolmetscher bezeichnet) für eine Vielzahl beliebter Entwicklungstools und -IDes wie Jupyter, VS Code, Pycharm, Colab oder Atom -Wasserstoff integriert und verwendet werden. Dadurch können Sie Ihr bevorzugtes Entwicklungswerkzeug auf Ihrem lokalen Computer an einen Remote -Computer zur Codeausführung anschließen. Dies ermöglicht eine Entwicklungserfahrung in der lokalen Qualität mit fernhostierten Rechenressourcen.
Diese Integrationen erfordern normalerweise eine passwortlose SSH -Verbindung von der lokalen Maschine zum Arbeitsbereich. Um eine SSH -Verbindung einzurichten, befolgen Sie bitte die im Abschnitt SSH Access erläuterten Schritte.
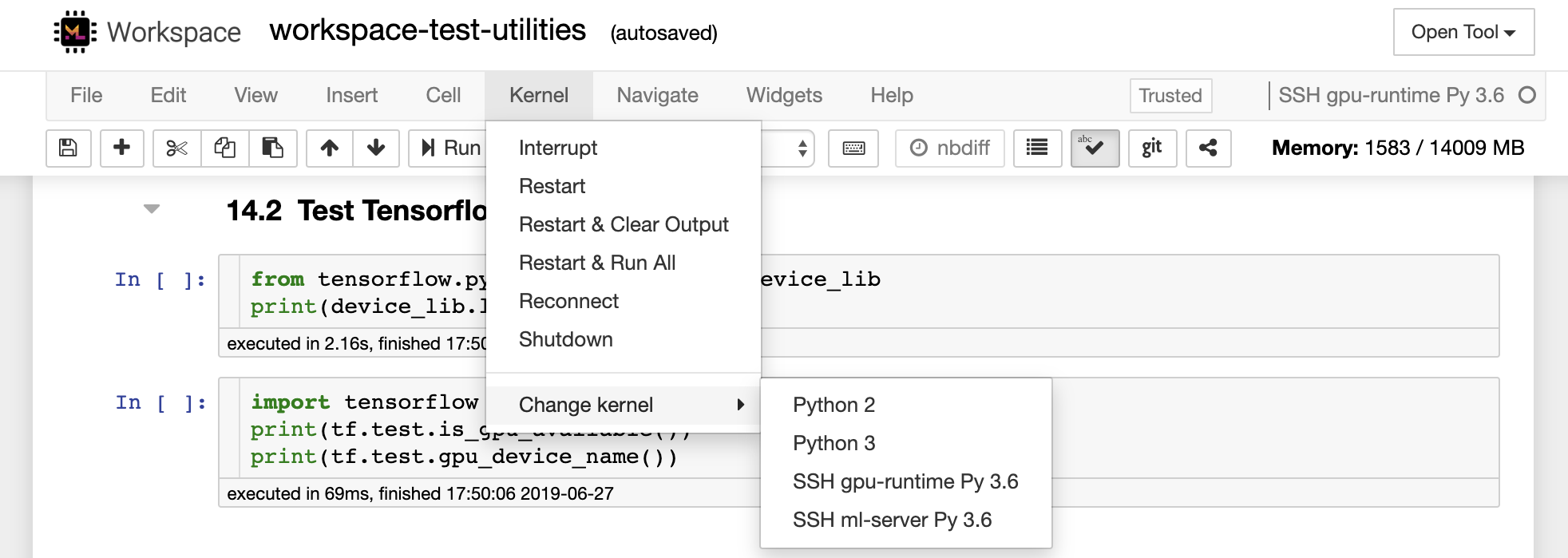
Der Arbeitsbereich kann einer Jupyter -Instanz als Remote -Kernel mithilfe des Remote_ikernel -Tools hinzugefügt werden. Wenn Sie Remote_ikernel ( pip install remote_ikernel ) auf Ihrem lokalen Computer installiert haben, bietet Ihnen das SSH -Setup -Skript des Arbeitsbereichs automatisch die Möglichkeit, eine Remote -Kernel -Verbindung einzurichten.
Beim Ausführen von Kerneln auf Remote -Maschinen werden die Notizbücher selbst auf dem lokalen Dateisystem gespeichert, aber der Kernel hat nur Zugriff auf das Dateisystem des Remote -Computers, das den Kernel ausführt. Wenn Sie Daten synchronisieren müssen, können Sie RSYNC, SCP oder SSHFS verwenden, wie im SSH -Zugriffsabschnitt erläutert.
Wenn Sie Remote-Kernel manuell einrichten und verwalten möchten, verwenden Sie das Befehlszeilen-Tool von Remote_ikernel, wie unten gezeigt:
# Change my-workspace with the name of a workspace SSH connection
remote_ikernel manage --add
--interface=ssh
--kernel_cmd= " ipython kernel -f {connection_file} "
--name= " ml-server (Python) "
--host= " my-workspace " Sie können die Befehlszeilenfunktion mit Remote_ikernel verwenden, um ( remote_ikernel manage --show ) oder löschen ( remote_ikernel manage --delete <REMOTE_KERNEL_NAME> ) Remote -Kernel -Verbindungen.
Mit der SSH -Erweiterung von Visual Studio Code Remote - können Sie einen Remote -Ordner auf jedem Remote -Computer mit SSH -Zugriff öffnen und genau wie Sie tun, wenn der Ordner auf Ihrem eigenen Computer wäre. Sobald Sie mit einem Remote -Computer verbunden sind, können Sie mit Dateien und Ordnern überall im Remote -Dateisystem interagieren und den Funktionssatz von VS Code (IntelliSense, Debugging und Erweiterungsunterstützung) voll ausnutzen. Die Entdeckungen und funktionieren außerhalb des Boxs mit passwortlosen SSH-Verbindungen, die vom Workspace SSH-Setup-Skript konfiguriert sind. Damit Ihre lokale VS -Codeanwendung eine Verbindung zu einem Arbeitsbereich herstellt:
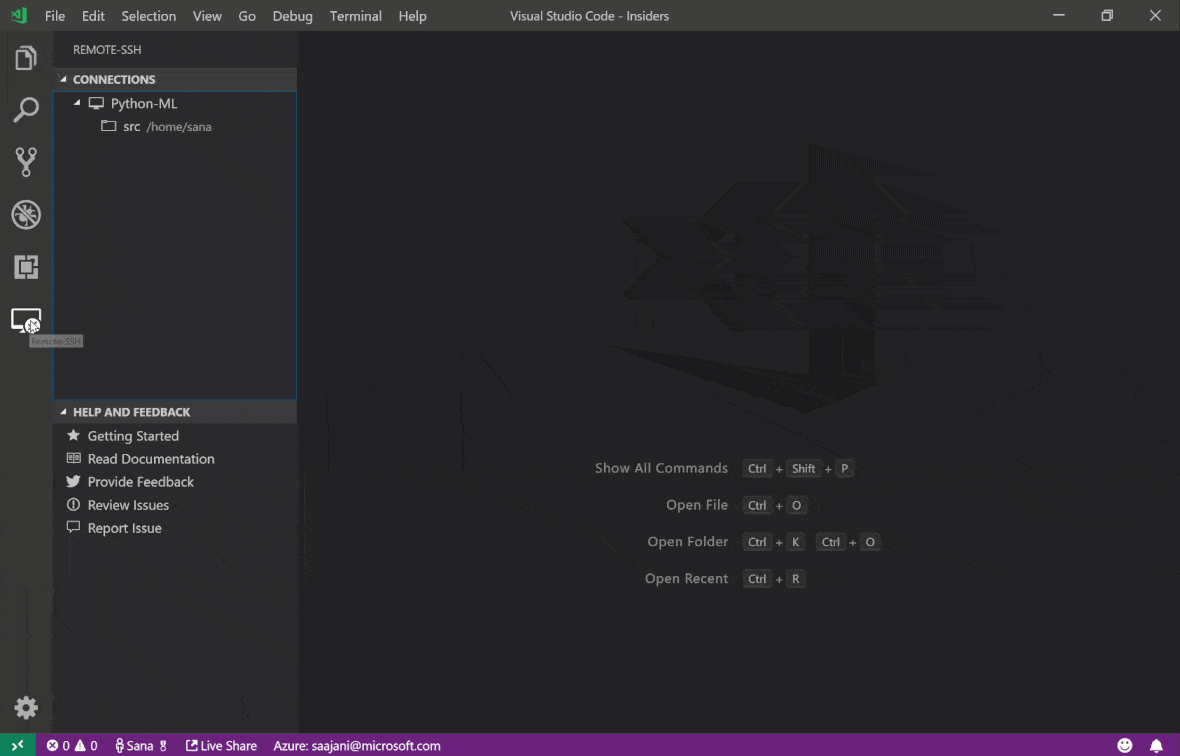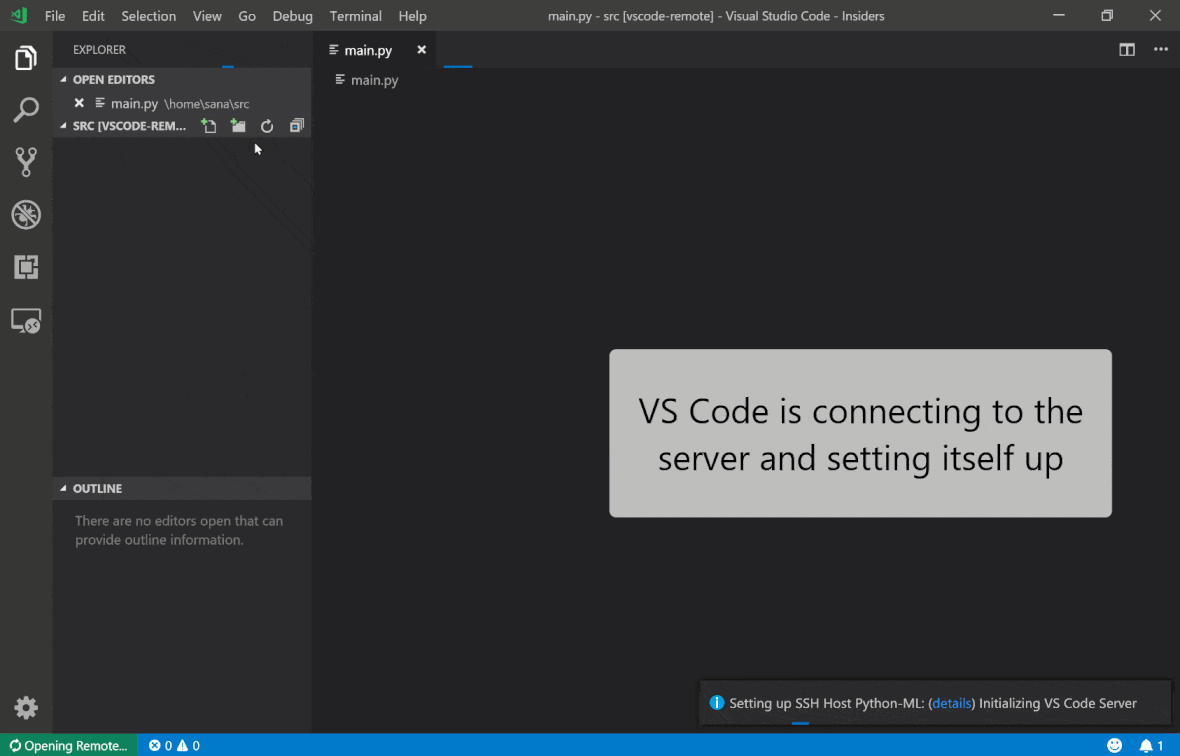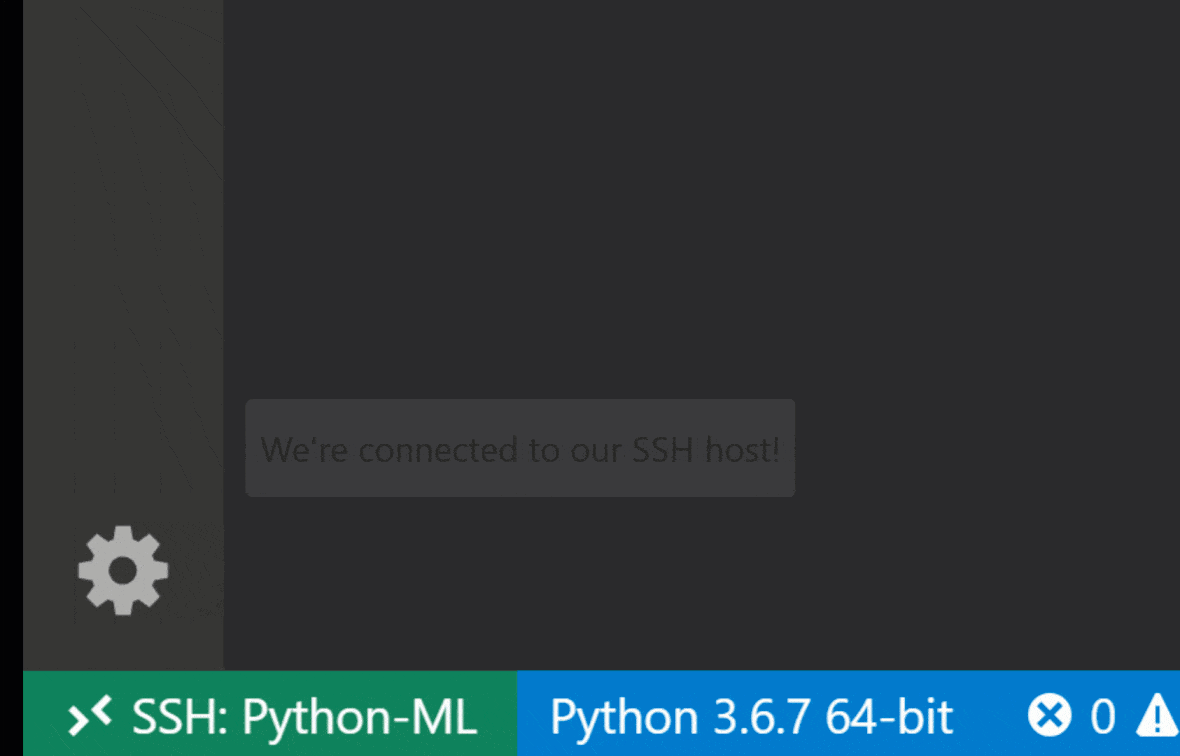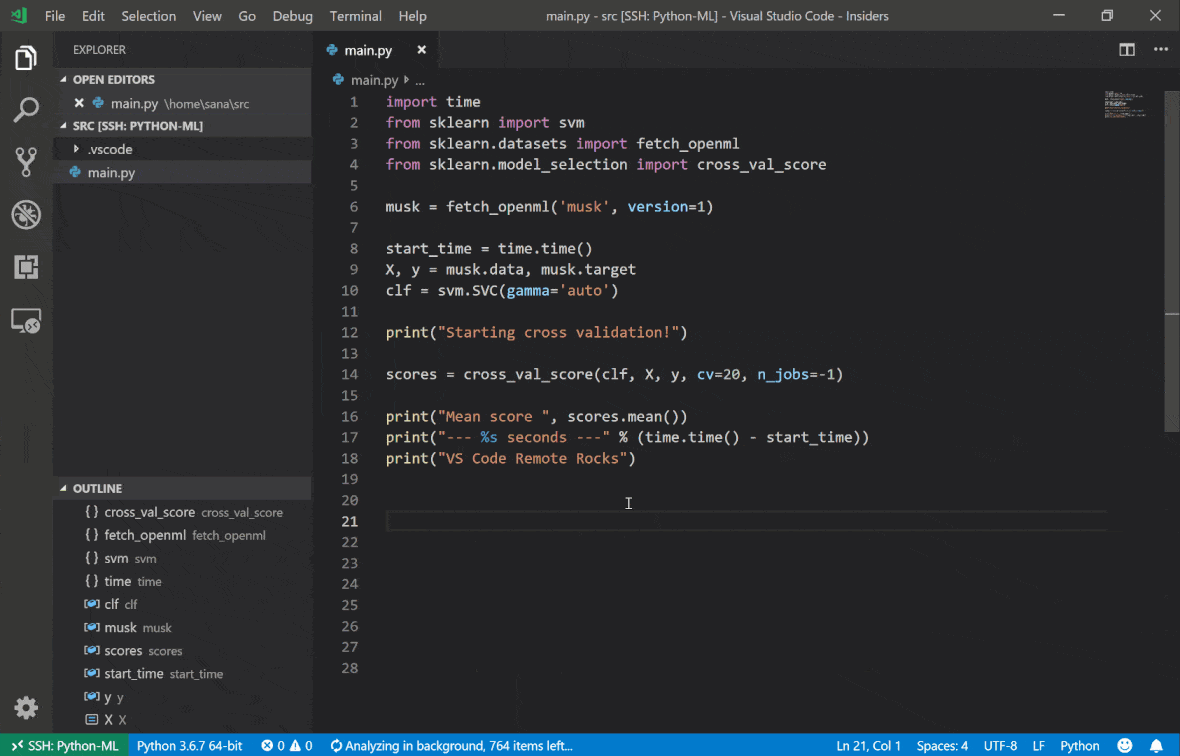
In diesem Handbuch finden Sie zusätzliche Funktionen und Informationen zur Remote -SSH -Erweiterung.
Tensorboard bietet eine Reihe von Visualisierungstools, um das Verständnis, das Debuggen und die Optimierung Ihrer Experiment -Läufe zu erleichtern. Es enthält Protokollierungsfunktionen für Skalar, Histogramm, Modellstruktur, Einbettungen und Text- und Bildvisualisierung. Der Arbeitsbereich wird mit Jupyter_tensorboard-Erweiterung vorinstalliert, die Tensorboard in die Jupyter-Schnittstelle mit Funktionen integriert, um Instanzen zu starten, zu verwalten und zu stoppen. Sie können eine neue Instanz für ein gültiges Protokoll -Verzeichnis öffnen, wie unten gezeigt:
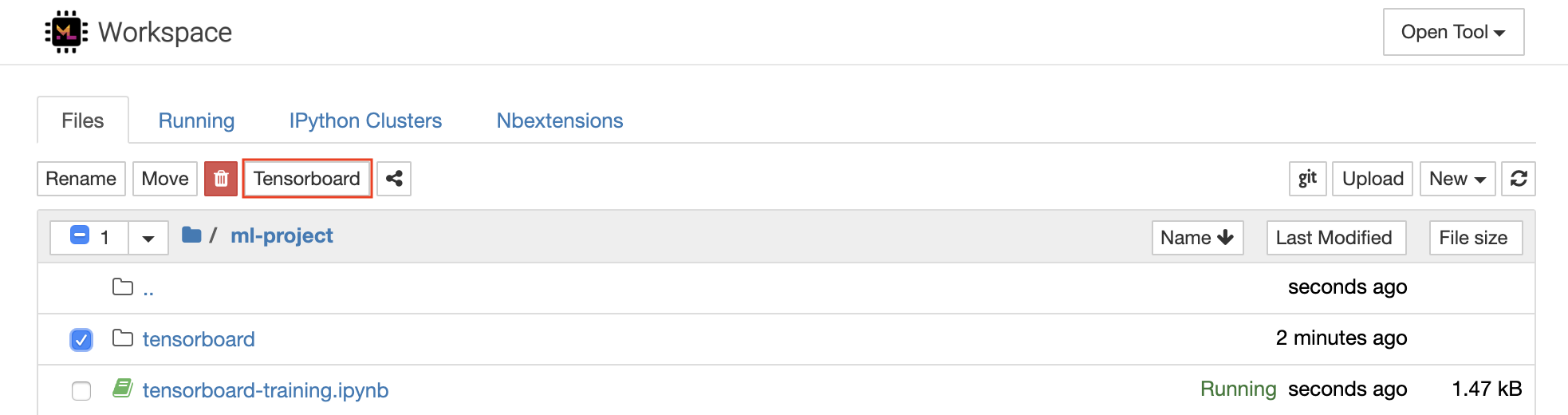
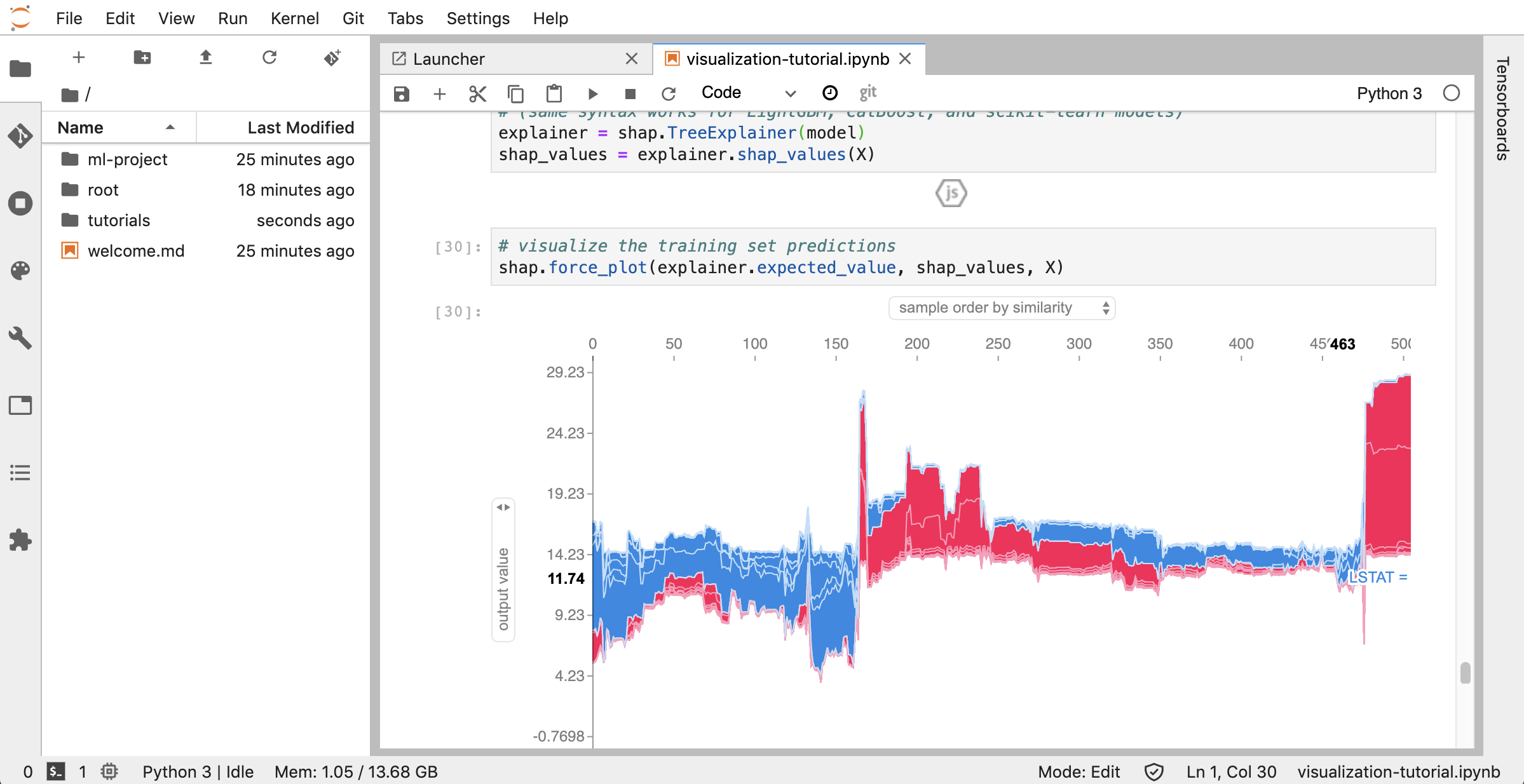
Wenn Sie in einem gültigen Protokollverzeichnis eine Tensorboard -Instanz geöffnet haben, werden die Visualisierungen Ihrer protokollierten Daten angezeigt:
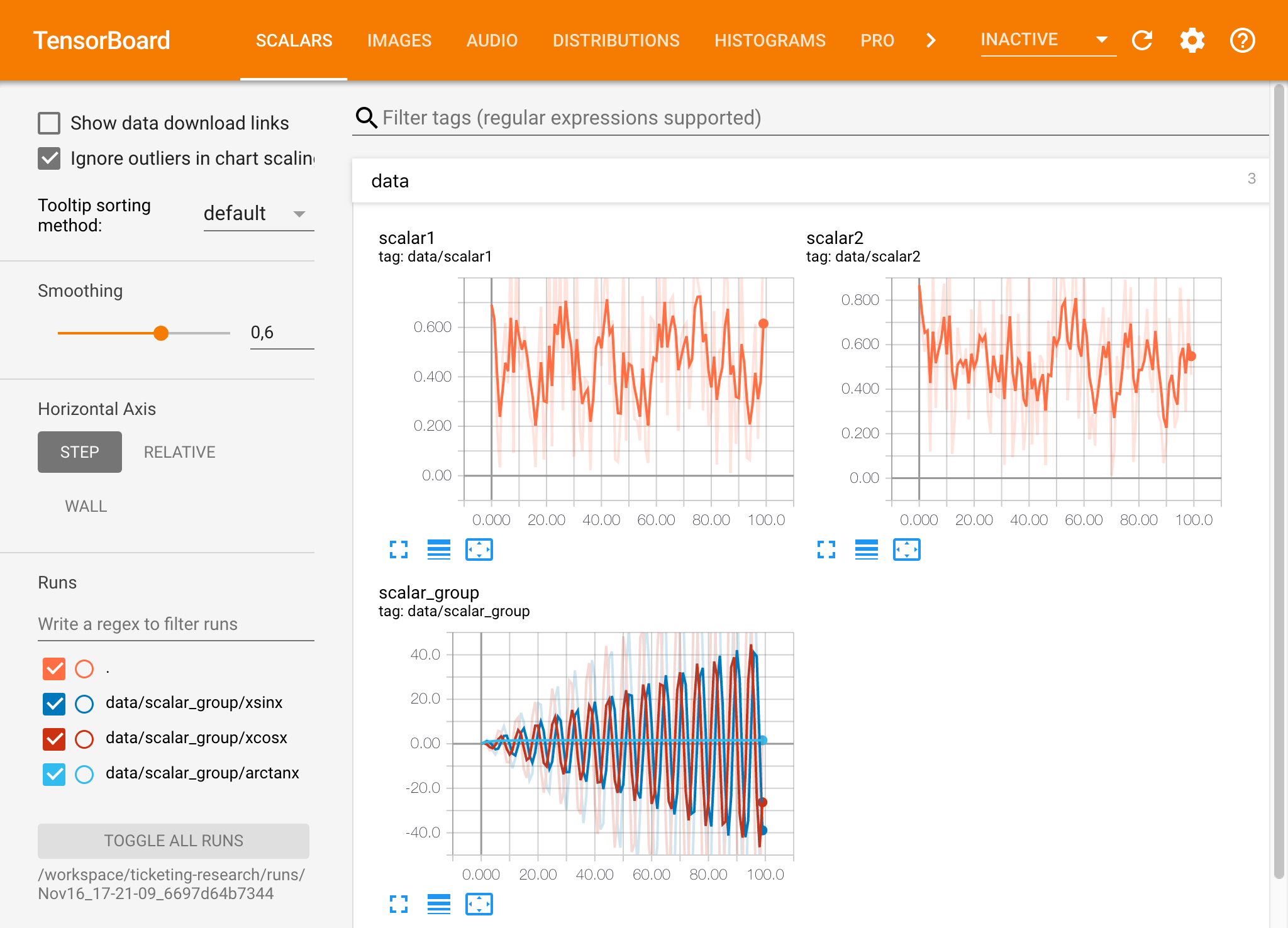
Tensorboard kann neben dem Tensorflow in Kombination mit vielen anderen ML -Frameworks verwendet werden. Durch die Verwendung der Tensorboardx -Bibliothek können Sie im Grunde genommen in jeder Python -basierten Bibliothek protokollieren. Außerdem hat Pytorch eine direkte Tensorboard -Integration, wie hier beschrieben.
Wenn Sie es vorziehen, das Tensorboard direkt in Ihrem Notebook zu sehen, können Sie Jupyter Magic folgen:
%load_ext tensorboard
%tensorboard --logdir /workspace/path/to/logs
Der Arbeitsbereich bietet zwei vorinstallierte webbasierte Tools, mit denen Entwickler während des Modelltrainings und anderen Experimentieraufgaben ein Einblick in alles, was auf dem System geschieht, und Performance-Engpässen herausfinden kann.
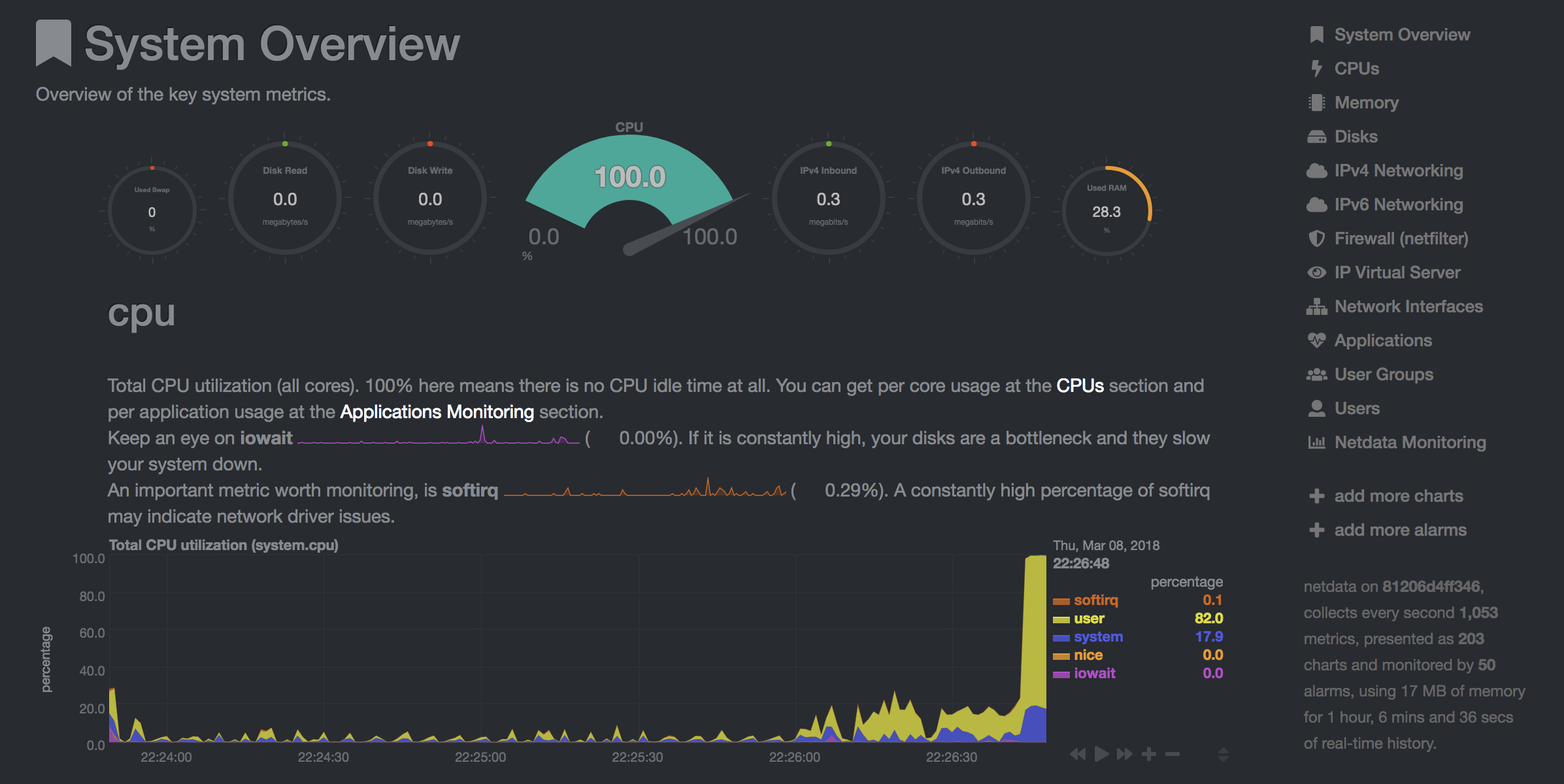
NetData ( Open Tool -> Netdata ) ist ein Echtzeit -Hardware- und Leistungsüberwachungs -Dashboard, das die Prozesse und Dienste auf Ihren Linux -Systemen visualisieren. Es überwacht Metriken über CPU, GPU, Speicher, Festplatten, Netzwerke, Prozesse und mehr.
Blinds ( Open Tool -> Glances ) ist ebenfalls ein webbasiertes Hardware -Überwachungs -Dashboard und kann als Alternative zu Netdata verwendet werden.
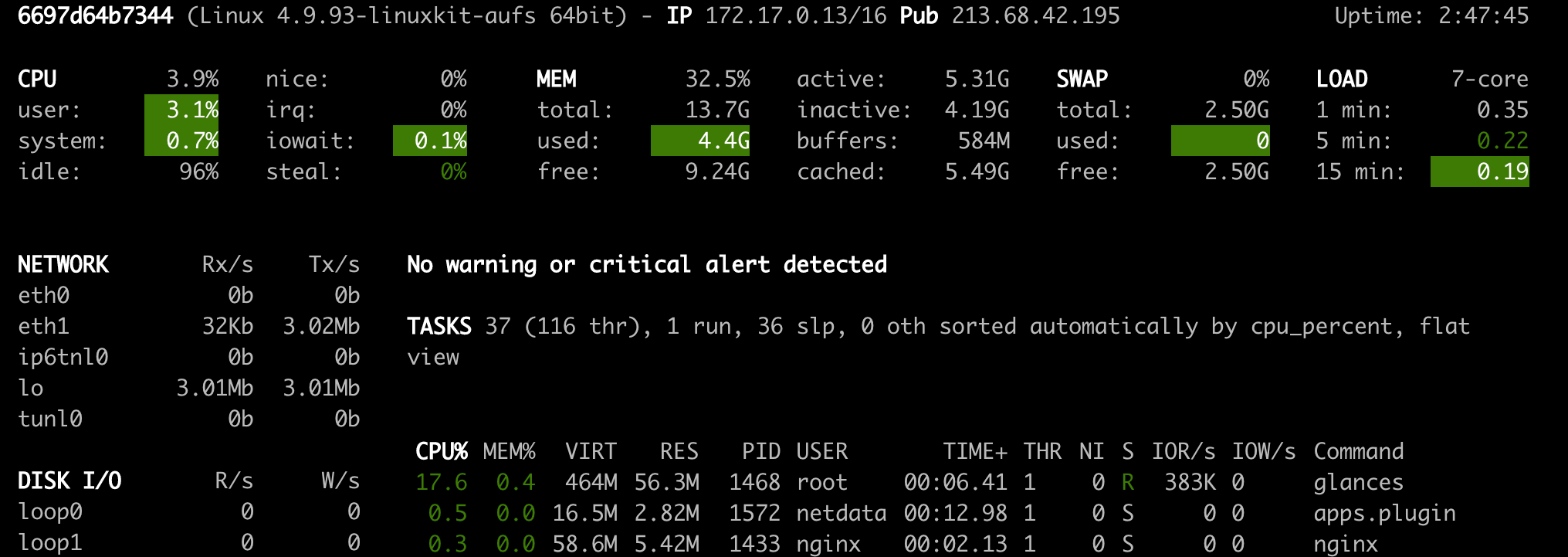
NetData und Blinds zeigen Ihnen die Hardware -Statistiken für die gesamte Maschine, auf der der Arbeitsbereichscontainer ausgeführt wird.
Ein Job ist definiert als jede Rechenaufgabe, die für einen bestimmten Zeitpunkt bis zum Abschluss ausgeführt wird, z. B. ein Modelltraining oder eine Datenpipeline.
Mit dem Arbeitsbereichsbild kann auch der beliebige Python-Code ausgeführt werden, ohne die vorinstallierten Tools zu starten. This provides a seamless way to productize your ML projects since the code that has been developed interactively within the workspace will have the same environment and configuration when run as a job via the same workspace image.
To run Python code as a job, you need to provide a path or URL to a code directory (or script) via EXECUTE_CODE . The code can be either already mounted into the workspace container or downloaded from a version control system (eg, git or svn) as described in the following sections. The selected code path needs to be python executable. In case the selected code is a directory (eg, whenever you download the code from a VCS) you need to put a __main__.py file at the root of this directory. The __main__.py needs to contain the code that starts your job.
You can execute code directly from Git, Mercurial, Subversion, or Bazaar by using the pip-vcs format as described in this guide. For example, to execute code from a subdirectory of a git repository, just run:
docker run --env EXECUTE_CODE= " git+https://github.com/ml-tooling/ml-workspace.git#subdirectory=resources/tests/ml-job " mltooling/ml-workspace:0.13.2For additional information on how to specify branches, commits, or tags please refer to this guide.
In the following example, we mount and execute the current working directory (expected to contain our code) into the /workspace/ml-job/ directory of the workspace:
docker run -v " ${PWD} :/workspace/ml-job/ " --env EXECUTE_CODE= " /workspace/ml-job/ " mltooling/ml-workspace:0.13.2In the case that the pre-installed workspace libraries are not compatible with your code, you can install or change dependencies by just adding one or multiple of the following files to your code directory:
requirements.txt : pip requirements format for pip-installable dependencies.environment.yml : conda environment file to create a separate Python environment.setup.sh : A shell script executed via /bin/bash . The execution order is 1. environment.yml -> 2. setup.sh -> 3. requirements.txt
You can test your job code within the workspace (started normally with interactive tools) by executing the following python script:
python /resources/scripts/execute_code.py /path/to/your/jobIt is also possible to embed your code directly into a custom job image, as shown below:
FROM mltooling/ml-workspace:0.13.2
# Add job code to image
COPY ml-job /workspace/ml-job
ENV EXECUTE_CODE=/workspace/ml-job
# Install requirements only
RUN python /resources/scripts/execute_code.py --requirements-only
# Execute only the code at container startup
CMD [ "python" , "/resources/docker-entrypoint.py" , "--code-only" ]The workspace is pre-installed with many popular interpreters, data science libraries, and ubuntu packages:
conda , pip , apt-get , npm , yarn , sdk , poetry , gdebi ...The full list of installed tools can be found within the Dockerfile.
For every minor version release, we run vulnerability, virus, and security checks within the workspace using safety, clamav, trivy, and snyk via docker scan to make sure that the workspace environment is as secure as possible. We are committed to fix and prevent all high- or critical-severity vulnerabilities. You can find some up-to-date reports here.
The workspace provides a high degree of extensibility. Within the workspace, you have full root & sudo privileges to install any library or tool you need via terminal (eg, pip , apt-get , conda , or npm ). You can open a terminal by one of the following ways:
New -> TerminalApplications -> Terminal EmulatorFile -> New -> TerminalTerminal -> New Terminal Additionally, pre-installed tools such as Jupyter, JupyterLab, and Visual Studio Code each provide their own rich ecosystem of extensions. The workspace also contains a collection of installer scripts for many commonly used development tools or libraries (eg, PyCharm , Zeppelin , RStudio , Starspace ). You can find and execute all tool installers via Open Tool -> Install Tool . Those scripts can be also executed from the Desktop VNC (double-click on the script within the Tools folder on the Desktop VNC).
For example, to install the Apache Zeppelin notebook server, simply execute:
/resources/tools/zeppelin.sh --port=1234 After installation, refresh the Jupyter website and the Zeppelin tool will be available under Open Tool -> Zeppelin . Other tools might only be available within the Desktop VNC (eg, atom or pycharm ) or do not provide any UI (eg, starspace , docker-client ).
As an alternative to extending the workspace at runtime, you can also customize the workspace Docker image to create your own flavor as explained in the FAQ section.
The workspace can be extended in many ways at runtime, as explained here. However, if you like to customize the workspace image with your own software or configuration, you can do that via a Dockerfile as shown below:
# Extend from any of the workspace versions/flavors
FROM mltooling/ml-workspace:0.13.2
# Run you customizations, e.g.
RUN
# Install r-runtime, r-kernel, and r-studio web server from provided install scripts
/bin/bash $RESOURCES_PATH/tools/r-runtime.sh --install &&
/bin/bash $RESOURCES_PATH/tools/r-studio-server.sh --install &&
# Cleanup Layer - removes unneccessary cache files
clean-layer.shFinally, use docker build to build your customized Docker image.
For a more comprehensive Dockerfile example, take a look at the Dockerfile of the R-flavor.
To update a running workspace instance to a more recent version, the running Docker container needs to be replaced with a new container based on the updated workspace image.
All data within the workspace that is not persisted to a mounted volume will be lost during this update process. As mentioned in the persist data section, a volume is expected to be mounted into the /workspace folder. All tools within the workspace are configured to make use of the /workspace folder as the root directory for all source code and data artifacts. During an update, data within other directories will be removed, including installed/updated libraries or certain machine configurations. We have integrated a backup and restore feature ( CONFIG_BACKUP_ENABLED ) for various selected configuration files/folders, such as the user's Jupyter/VS-Code configuration, ~/.gitconfig , and ~/.ssh .
If the workspace is deployed via Docker (Kubernetes will have a different update process), you need to remove the existing container (via docker rm ) and start a new one (via docker run ) with the newer workspace image. Make sure to use the same configuration, volume, name, and port. For example, a workspace (image version 0.8.7 ) was started with this command:
docker run -d
-p 8080:8080
--name "ml-workspace"
-v "/path/on/host:/workspace"
--env AUTHENTICATE_VIA_JUPYTER="mytoken"
--restart always
mltooling/ml-workspace:0.8.7
and needs to be updated to version 0.9.1 , you need to:
docker stop "ml-workspace" && docker rm "ml-workspace"docker run -d -p 8080:8080 --name "ml-workspace" -v "/path/on/host:/workspace" --env AUTHENTICATE_VIA_JUPYTER="mytoken" --restart always mltooling/ml-workspace:0.9.1 If you want to directly connect to the workspace via a VNC client (not using the noVNC webapp), you might be interested in changing certain VNC server configurations. To configure the VNC server, you can provide/overwrite the following environment variables at container start (via docker run option: --env ):
| Variable | Beschreibung | Standard |
|---|---|---|
| VNC_PW | Password of VNC connection. This password only needs to be secure if the VNC server is directly exposed. If it is used via noVNC, it is already protected based on the configured authentication mechanism. | vncpassword |
| VNC_RESOLUTION | Default desktop resolution of VNC connection. When using noVNC, the resolution will be dynamically adapted to the window size. | 1600x900 |
| VNC_COL_DEPTH | Default color depth of VNC connection. | 24 |
Unfortunately, we currently do not support using a non-root user within the workspace. We plan to provide this capability and already started with some refactoring to allow this configuration. However, this still requires a lot more work, refactoring, and testing from our side.
Using root-user (or users with sudo permission) within containers is generally not recommended since, in case of system/kernel vulnerabilities, a user might be able to break out of the container and be able to access the host system. Since it is not very common to have such problematic kernel vulnerabilities, the risk of a severe attack is quite minimal. As explained in the official Docker documentation, containers (even with root users) are generally quite secure in preventing a breakout to the host. And compared to many other container use-cases, we actually want to provide the flexibility to the user to have control and system-level installation permissions within the workspace container.
The workspace comes preinstalled with various common tools to create isolated Python environments (virtual environments). The following sections provide a quick-intro on how to use these tools within the workspace. You can find information on when to use which tool here. Please refer to the documentation of the given tool for additional usage information.
venv (recommended):
To create a virtual environment via venv, execute the following commands:
# Create environment in the working directory
python -m venv my-venv
# Activate environment in shell
source ./my-venv/bin/activate
# Optional: Create Jupyter kernel for this environment
pip install ipykernel
python -m ipykernel install --user --name=my-venv --display-name= " my-venv ( $( python --version ) ) "
# Optional: Close enviornment session
deactivatepipenv (recommended):
To create a virtual environment via pipenv, execute the following commands:
# Create environment in the working directory
pipenv install
# Activate environment session in shell
pipenv shell
# Optional: Create Jupyter kernel for this environment
pipenv install ipykernel
python -m ipykernel install --user --name=my-pipenv --display-name= " my-pipenv ( $( python --version ) ) "
# Optional: Close environment session
exitvirtualenv :
To create a virtual environment via virtualenv, execute the following commands:
# Create environment in the working directory
virtualenv my-virtualenv
# Activate environment session in shell
source ./my-virtualenv/bin/activate
# Optional: Create Jupyter kernel for this environment
pip install ipykernel
python -m ipykernel install --user --name=my-virtualenv --display-name= " my-virtualenv ( $( python --version ) ) "
# Optional: Close environment session
deactivateconda :
To create a virtual environment via conda, execute the following commands:
# Create environment (globally)
conda create -n my-conda-env
# Activate environment session in shell
conda activate my-conda-env
# Optional: Create Jupyter kernel for this environment
python -m ipykernel install --user --name=my-conda-env --display-name= " my-conda-env ( $( python --version ) ) "
# Optional: Close environment session
conda deactivateTip: Shell Commands in Jupyter Notebooks:
If you install and use a virtual environment via a dedicated Jupyter Kernel and use shell commands within Jupyter (eg !pip install matplotlib ), the wrong python/pip version will be used. To use the python/pip version of the selected kernel, do the following instead:
import sys
!{ sys . executable } - m pip install matplotlibThe workspace provides three easy options to install different Python versions alongside the main Python instance: pyenv, pipenv (recommended), conda.
pipenv (recommended):
To install a different python version (eg 3.7.8 ) within the workspace via pipenv, execute the following commands:
# Install python vers
pipenv install --python=3.7.8
# Activate environment session in shell
pipenv shell
# Check python installation
python --version
# Optional: Create Jupyter kernel for this environment
pipenv install ipykernel
python -m ipykernel install --user --name=my-pipenv --display-name= " my-pipenv ( $( python --version ) ) "
# Optional: Close environment session
exitpyenv :
To install a different python version (eg 3.7.8 ) within the workspace via pyenv, execute the following commands:
# Install python version
pyenv install 3.7.8
# Make globally accessible
pyenv global 3.7.8
# Activate python version in shell
pyenv shell 3.7.8
# Check python installation
python3.7 --version
# Optional: Create Jupyter kernel for this python version
python3.7 -m pip install ipykernel
python3.7 -m ipykernel install --user --name=my-pyenv-3.7.8 --display-name= " my-pyenv (Python 3.7.8) "conda :
To install a different python version (eg 3.7.8 ) within the workspace via conda, execute the following commands:
# Create environment with python version
conda create -n my-conda-3.7 python=3.7.8
# Activate environment session in shell
conda activate my-conda-3.7
# Check python installation
python --version
# Optional: Create Jupyter kernel for this python version
pip install ipykernel
python -m ipykernel install --user --name=my-conda-3.7 --display-name= " my-conda ( $( python --version ) ) "
# Optional: Close environment session
conda deactivateTip: Shell Commands in Jupyter Notebooks:
If you install and use another Python version via a dedicated Jupyter Kernel and use shell commands within Jupyter (eg !pip install matplotlib ), the wrong python/pip version will be used. To use the python/pip version of the selected kernel, do the following instead:
import sys
!{ sys . executable } - m pip install matplotlib Certain desktop tools (eg, recent versions of Firefox) or libraries (eg, Pytorch - see Issues: 1, 2) might crash if the shared memory size ( /dev/shm ) is too small. The default shared memory size of Docker is 64MB, which might not be enough for a few tools. You can provide a higher shared memory size via the shm-size docker run option:
docker run --shm-size=2G mltooling/ml-workspace:0.13.2 In general, the performance of running code within Docker is nearly identical compared to running it directly on the machine. However, in case you have limited the container's CPU quota (as explained in this section), the container can still see the full count of CPU cores available on the machine and there is no technical way to prevent this. Many libraries and tools will use the full CPU count (eg, via os.cpu_count() ) to set the number of threads used for multiprocessing/-threading. This might cause the program to start more threads/processes than it can efficiently handle with the available CPU quota, which can tremendously slow down the overall performance. Therefore, it is important to set the available CPU count or the maximum number of threads explicitly to the configured CPU quota. The workspace provides capabilities to detect the number of available CPUs automatically, which are used to configure a variety of common libraries via environment variables such as OMP_NUM_THREADS or MKL_NUM_THREADS . It is also possible to explicitly set the number of available CPUs at container startup via the MAX_NUM_THREADS environment variable (see configuration section). The same environment variable can also be used to get the number of available CPUs at runtime.
Even though the automatic configuration capabilities of the workspace will fix a variety of inefficiencies, we still recommend configuring the number of available CPUs with all libraries explicitly. Zum Beispiel:
import os
MAX_NUM_THREADS = int ( os . getenv ( "MAX_NUM_THREADS" ))
# Set in pytorch
import torch
torch . set_num_threads ( MAX_NUM_THREADS )
# Set in tensorflow
import tensorflow as tf
config = tf . ConfigProto (
device_count = { "CPU" : MAX_NUM_THREADS },
inter_op_parallelism_threads = MAX_NUM_THREADS ,
intra_op_parallelism_threads = MAX_NUM_THREADS ,
)
tf_session = tf . Session ( config = config )
# Set session for keras
import keras . backend as K
K . set_session ( tf_session )
# Set in sklearn estimator
from sklearn . linear_model import LogisticRegression
LogisticRegression ( n_jobs = MAX_NUM_THREADS ). fit ( X , y )
# Set for multiprocessing pool
from multiprocessing import Pool
with Pool ( MAX_NUM_THREADS ) as pool :
results = pool . map ( lst )If you encounter the following error within the container logs when starting the workspace, it will most likely not be possible to run the workspace on your hardware:
exited: nginx (terminated by SIGILL (core dumped); not expected)
The OpenResty/Nginx binary package used within the workspace requires to run on a CPU with SSE4.2 support (see this issue). Unfortunately, some older CPUs do not have support for SSE4.2 and, therefore, will not be able to run the workspace container. On Linux, you can check if your CPU supports SSE4.2 when looking into the cat /proc/cpuinfo flags section. If you encounter this problem, feel free to notify us by commenting on the following issue: #30.
Requirements : Docker and Act are required to be installed on your machine to execute the build process.
To simplify the process of building this project from scratch, we provide build-scripts - based on universal-build - that run all necessary steps (build, test, and release) within a containerized environment. To build and test your changes, execute the following command in the project root folder:
act -b -j buildUnder the hood it uses the build.py files in this repo based on the universal-build library. So, if you want to build it locally, you can also execute this command in the project root folder to build the docker container:
python build.py --makeFor additional script options:
python build.py --helpRefer to our contribution guides for more detailed information on our build scripts and development process.
Licensed Apache 2.0 . Created and maintained with ❤️ by developers from Berlin.


