benchmark_VAE
Pythae 0.1.2
Документация
Эта библиотека реализует некоторые из наиболее распространенных (вариационных) моделей аутоэкодер в единой реализации. В частности, он дает возможность провести контрольные эксперименты и сравнения, обучая модели с той же архитектурой нейронной сети с автоэкодированием. Эта функция сделает ваш собственный автоподдер, который позволяет вам обучать любую из этих моделей с вашими собственными данными и собственными энкодерами и нейронными сети декодера. Он интегрирует инструменты мониторинга эксперимента, такие как Wandb, Mlflow или Comet-ML? И позволяет обмен модели и загрузку из центра Huggingface? В нескольких строках кода.
Новости ?
По состоянию на v0.1.0 Pythae теперь поддерживает распределенное обучение с использованием DDP Pytorch. Теперь вы можете обучить свой любимый VAE быстрее и на более крупных наборах данных, все еще с несколькими строками кода. Смотрите наш эталон ускорения.
wandb / Experiment с отслеживанием mlflow / Experiment с comet_ml Чтобы установить последний стабильный выпуск этой библиотеки. Запустите следующее с помощью pip
$ pip install pythae Чтобы установить последнюю версию GitHub этой библиотеки. Запустите следующее с помощью pip
$ pip install git+https://github.com/clementchadebec/benchmark_VAE.gitИли, в качестве альтернативы, вы можете клонировать репо Github для доступа к тестам, учебным пособиям и сценариям.
$ git clone https://github.com/clementchadebec/benchmark_VAE.gitи установить библиотеку
$ cd benchmark_VAE
$ pip install -e . Ниже приведен список моделей, в настоящее время реализованных в библиотеке.
| Модели | Пример обучения | Бумага | Официальная реализация |
|---|---|---|---|
| AutoEncoder (AE) | |||
| Вариационный автоэкодер (VAE) | связь | ||
| Бета -вариационный автоэкодер (Betavae) | связь | ||
| Vae с линейными нормализующими потоками (vae_linnf) | связь | ||
| Vae с обратными авторегрессивными потоками (vae_iaf) | связь | связь | |
| Распущенная бета -вариационная автоэкодер (DisEneangledbetavae) | связь | ||
| Рассеяние путем факторизации (Factorvae) | связь | ||
| Бета-TC-Vae (Betatcvae) | связь | связь | |
| Важность взвешенного автоэнкодера (iwae) | связь | связь | |
| Умножьте важность взвешенного автоэкодер (Miwae) | связь | ||
| Частично важность взвешенного автоэкодер (piwae) | связь | ||
| Комбинированная важность, взвешенная автоэкодер (CIWAE) | связь | ||
| VAE с сходством показателя восприятия (MSSSIM_VAE) | связь | ||
| Wasserstein AutoEncoder (WAE) | связь | связь | |
| Информационный вариационный автоэкодер (Infovae_mmd) | связь | ||
| Vamp AutoEcoder (Вамп) | связь | связь | |
| Гиперферический Vae (Svae) | связь | связь | |
| Пуанкаре диск vae (pincarevae) | связь | связь | |
| Adversarial Autoencoder (Adversarial_AE) | связь | ||
| Вариационный Autoencoder Gan (Vaegan)? | связь | связь | |
| Вектор квантовый Vae (VQVAE) | связь | связь | |
| Гамильтониан Vae (HVAE) | связь | связь | |
| Зарегулизованный AE с L2 Decoder Param (rae_l2) | связь | связь | |
| Зарегистрированный AE с градиентным штрафом (RAE_GP) | связь | связь | |
| Риеманн Гамильтониан Ваэ (Rhvae) | связь | связь | |
| Иерархическое остаточное квантование (HRQVAE) | связь | связь |
См. Реконструкцию и результаты генерации для всех вышеупомянутых моделей
Ниже приведен список моделей, в настоящее время реализованных в библиотеке.
| Пробоотборники | Модели | Бумага | Официальная реализация |
|---|---|---|---|
| Нормальный предварительный (normalsampler) | Все модели | связь | |
| Гауссовая смесь (Gaussianmixturesampler) | Все модели | связь | связь |
| Двухступенчатые Vae Sampler (Twostagevaesampler) | Все модели на основе VAE | связь | связь |
| Единая сфера равномерная пробоотборник (HypersphereUniformsampler) | Svae | связь | связь |
| Пробоотборник диска в Пуанкаре (Poincaredisksampler) | Пуанкарева | связь | связь |
| Вамп -предварительный пробоотборник (Vampsampler) | Вампир | связь | связь |
| Manifold Sampler (Rhvaesampler) | Rhvae | связь | связь |
| Сэмплер с авторегрессивным потоком в масках (Mafsampler) | Все модели | связь | связь |
| Обратный пробоотборник потока ауторегрессии (IAFSAMPLER) | Все модели | связь | связь |
| Pixelcnn (pixelcnnsampler) | VQVAE | связь |
Мы проверяем реализации, воспроизводя некоторые результаты, представленные в оригинальных публикациях, когда был выпущен официальный код или когда было доступно достаточно подробностей о экспериментальном разделе документов. Смотрите воспроизводимость для более подробной информации.
Чтобы запустить модельную обучение, вам нужно только позвонить в экземпляр TrainingPipeline .
> >> from pythae . pipelines import TrainingPipeline
> >> from pythae . models import VAE , VAEConfig
> >> from pythae . trainers import BaseTrainerConfig
> >> # Set up the training configuration
>> > my_training_config = BaseTrainerConfig (
... output_dir = 'my_model' ,
... num_epochs = 50 ,
... learning_rate = 1e-3 ,
... per_device_train_batch_size = 200 ,
... per_device_eval_batch_size = 200 ,
... train_dataloader_num_workers = 2 ,
... eval_dataloader_num_workers = 2 ,
... steps_saving = 20 ,
... optimizer_cls = "AdamW" ,
... optimizer_params = { "weight_decay" : 0.05 , "betas" : ( 0.91 , 0.995 )},
... scheduler_cls = "ReduceLROnPlateau" ,
... scheduler_params = { "patience" : 5 , "factor" : 0.5 }
... )
> >> # Set up the model configuration
>> > my_vae_config = model_config = VAEConfig (
... input_dim = ( 1 , 28 , 28 ),
... latent_dim = 10
... )
> >> # Build the model
>> > my_vae_model = VAE (
... model_config = my_vae_config
... )
> >> # Build the Pipeline
>> > pipeline = TrainingPipeline (
... training_config = my_training_config ,
... model = my_vae_model
... )
> >> # Launch the Pipeline
>> > pipeline (
... train_data = your_train_data , # must be torch.Tensor, np.array or torch datasets
... eval_data = your_eval_data # must be torch.Tensor, np.array or torch datasets
... ) В конце обучения лучшие веса модели, конфигурация модели и тренировочная конфигурация хранятся в папке final_model , доступной в my_model/MODEL_NAME_training_YYYY-MM-DD_hh-mm-ss (с my_model , являющимся аргументом output_dir of BaseTrainerConfig ). Если вы дополнительно установите аргумент steps_saving на определенное значение, папки с именем checkpoint_epoch_k , содержащие лучшие веса модели, оптимизатор, планировщик, конфигурацию и тренировочную конфигурацию в Epoch K , также появятся в my_model/MODEL_NAME_training_YYYY-MM-DD_hh-mm-ss .
Мы также приведем пример обучающего сценария, который можно использовать для обучения моделей на наборах данных контрольных данных (MNIST, CIFAR10, Celeba ...). Сценарий может быть запущен со следующей командной линией
python training.py --dataset mnist --model_name ae --model_config ' configs/ae_config.json ' --training_config ' configs/base_training_config.json 'Смотрите readme.md для получения более подробной информации об этом сценарии
GenerationPipeline Самый простой способ запустить генерацию данных из обученной модели состоит в том, чтобы использование встроенной GenerationPipeline предоставленной в Pythae. Скажем, вы хотите сгенерировать 100 образцов, используя MAFSampler , все, что вам нужно сделать, это 1) Отправить обученную модель, 2) определить конфигурацию Sampler и 3) Создать и запустить GenerationPipeline
> >> from pythae . models import AutoModel
> >> from pythae . samplers import MAFSamplerConfig
> >> from pythae . pipelines import GenerationPipeline
> >> # Retrieve the trained model
>> > my_trained_vae = AutoModel . load_from_folder (
... 'path/to/your/trained/model'
... )
> >> my_sampler_config = MAFSamplerConfig (
... n_made_blocks = 2 ,
... n_hidden_in_made = 3 ,
... hidden_size = 128
... )
> >> # Build the pipeline
>> > pipe = GenerationPipeline (
... model = my_trained_vae ,
... sampler_config = my_sampler_config
... )
> >> # Launch data generation
>> > generated_samples = pipe (
... num_samples = args . num_samples ,
... return_gen = True , # If false returns nothing
... train_data = train_data , # Needed to fit the sampler
... eval_data = eval_data , # Needed to fit the sampler
... training_config = BaseTrainerConfig ( num_epochs = 200 ) # TrainingConfig to use to fit the sampler
... )В качестве альтернативы вы можете запустить процесс генерации данных из обученной модели непосредственно с Sampler. Например, чтобы сгенерировать новые данные с помощью вашего сэмплера, запустите следующее.
> >> from pythae . models import AutoModel
> >> from pythae . samplers import NormalSampler
> >> # Retrieve the trained model
>> > my_trained_vae = AutoModel . load_from_folder (
... 'path/to/your/trained/model'
... )
> >> # Define your sampler
>> > my_samper = NormalSampler (
... model = my_trained_vae
... )
> >> # Generate samples
>> > gen_data = my_samper . sample (
... num_samples = 50 ,
... batch_size = 10 ,
... output_dir = None ,
... return_gen = True
... ) Если вы установите output_dir в определенный путь, сгенерированные изображения будут сохранены в виде файлов .png с именем 00000000.png , 00000001.png ... Пробоотреми могут использоваться с любой моделью, пока она подходит. Например, экземпляр GaussianMixtureSampler может использоваться для генерации из любой модели, но VAMPSampler будет использоваться только с помощью модели VAMP . Проверьте здесь, чтобы увидеть, какие из них относятся к вашей модели. Будьте осторожны с тем, что некоторые пробоотборники, такие как GaussianMixtureSampler , например, могут быть установлены, вызывая метод fit перед использованием. Ниже приведен пример для GaussianMixtureSampler .
> >> from pythae . models import AutoModel
> >> from pythae . samplers import GaussianMixtureSampler , GaussianMixtureSamplerConfig
> >> # Retrieve the trained model
>> > my_trained_vae = AutoModel . load_from_folder (
... 'path/to/your/trained/model'
... )
> >> # Define your sampler
... gmm_sampler_config = GaussianMixtureSamplerConfig (
... n_components = 10
... )
> >> my_samper = GaussianMixtureSampler (
... sampler_config = gmm_sampler_config ,
... model = my_trained_vae
... )
> >> # fit the sampler
>> > gmm_sampler . fit ( train_dataset )
> >> # Generate samples
>> > gen_data = my_samper . sample (
... num_samples = 50 ,
... batch_size = 10 ,
... output_dir = None ,
... return_gen = True
... )Pythae предоставляет вам возможность определить свои собственные нейронные сети в моделях VAE. Например, скажем, вы хотите обучить Wassertstein AE с определенным энкодером и декодером, вы можете сделать следующее:
> >> from pythae . models . nn import BaseEncoder , BaseDecoder
> >> from pythae . models . base . base_utils import ModelOutput
> >> class My_Encoder ( BaseEncoder ):
... def __init__ ( self , args = None ): # Args is a ModelConfig instance
... BaseEncoder . __init__ ( self )
... self . layers = my_nn_layers ()
...
... def forward ( self , x : torch . Tensor ) -> ModelOutput :
... out = self . layers ( x )
... output = ModelOutput (
... embedding = out # Set the output from the encoder in a ModelOutput instance
... )
... return output
...
... class My_Decoder ( BaseDecoder ):
... def __init__ ( self , args = None ):
... BaseDecoder . __init__ ( self )
... self . layers = my_nn_layers ()
...
... def forward ( self , x : torch . Tensor ) -> ModelOutput :
... out = self . layers ( x )
... output = ModelOutput (
... reconstruction = out # Set the output from the decoder in a ModelOutput instance
... )
... return output
...
> >> my_encoder = My_Encoder ()
> >> my_decoder = My_Decoder ()А теперь создайте модель
> >> from pythae . models import WAE_MMD , WAE_MMD_Config
> >> # Set up the model configuration
>> > my_wae_config = model_config = WAE_MMD_Config (
... input_dim = ( 1 , 28 , 28 ),
... latent_dim = 10
... )
...
> >> # Build the model
>> > my_wae_model = WAE_MMD (
... model_config = my_wae_config ,
... encoder = my_encoder , # pass your encoder as argument when building the model
... decoder = my_decoder # pass your decoder as argument when building the model
... ) Важное примечание 1 : Для всех моделей на основе AE (AE, WAE, RAE_L2, RAE_GP) как энкодер, так и декодер должны вернуть экземпляр ModelOutput . Для энкодера экземпляр ModelOutput должен содержать посольства под embedding ключа. Для декодера экземпляр ModelOutput должен содержать реконструкции в соответствии с ключевой reconstruction .
Важное примечание 2 : Для всех моделей на основе VAE (VAE, Betavae, Iwae, HVAE, VAMP, RHVAE) как энкодер, так и декодер должны вернуть экземпляр ModelOutput . Для Encoder экземпляр ModelOutput должен содержать матрицы полдчиков и логарифмических ковариаций (из формы batch_size x latent_space_dim) соответственно под embedding и клавиш log_covariance . Для декодера экземпляр ModelOutput должен содержать реконструкции в соответствии с ключевой reconstruction .
Вы также можете найти предопределенные архитектуры нейронной сети для наиболее распространенных наборов данных ( то есть Mnist, Cifar, Celeba ...), которые можно загрузить следующим образом
> >> from pythae . models . nn . benchmark . mnist import (
... Encoder_Conv_AE_MNIST , # For AE based model (only return embeddings)
... Encoder_Conv_VAE_MNIST , # For VAE based model (return embeddings and log_covariances)
... Decoder_Conv_AE_MNIST
... )Замените Mnist Cifar или Celeba, чтобы получить доступ к другим нейронным сетям.
Pythae По состоянию на v0.1.0 Pythae теперь поддерживает распределенное обучение с использованием DDP Pytorch. Это позволяет вам обучать ваш любимый VAE быстрее и на более крупном наборе данных, используя мульти-GPU и/или обучение мульти-узлам.
Для этого вы можете построить сценарий Python, который затем будет запущен пусковой установкой (такой как srun на кластере). Единственное, что необходимо в сценарии, - это указать некоторые элементы относительно распределенной среды (например, количество узлов/графических процессоров) непосредственно в тренировочной конфигурации следующим образом
> >> training_config = BaseTrainerConfig (
... num_epochs = 10 ,
... learning_rate = 1e-3 ,
... per_device_train_batch_size = 64 ,
... per_device_eval_batch_size = 64 ,
... train_dataloader_num_workers = 8 ,
... eval_dataloader_num_workers = 8 ,
... dist_backend = "nccl" , # distributed backend
... world_size = 8 # number of gpus to use (n_nodes x n_gpus_per_node),
... rank = 5 # global gpu id,
... local_rank = 1 # gpu id within a node,
... master_addr = "localhost" # master address,
... master_port = "12345" # master port,
... ) См. Этот пример сценария, который определяет обучение VQVAE с несколькими GPU на наборе данных ImageNet. Обратите внимание, что способ восстановления распределенных переменных среды ( world_size , rank ...), может быть специфичным для кластера и пусковой установки, которую вы используете.
Ниже приведены время обучения для вектора квантового VAE (VQ-VAE) с Pythae для 100 эпох на MNIST на GPU (S) V100 16 ГБ для 50 эпох на FFHQ (1024x1024 изображения) и для 20 эпох на ImageNet-1K на GPU 32GB V100 32GB (S).
| Данные поезда | 1 графин | 4 графические процессоры | 2x4 графические процессоры | |
|---|---|---|---|---|
| Mnist (vq-vae) | 28x28 изображения (50K) | 235,18 с | 62,00 с | 35,86 с |
| FFHQ 1024X1024 (VQVAE) | 1024x1024 RGB изображения (60K) | 19h 1min | 5H 6 минут | 2H 37 мин |
| ImageNet-1K 128x128 (VQVAE) | 128x128 RGB -изображения (~ 1,2 м) | 6 ч 25 мин | 1H 41 мин | 51 мин 26 с |
Для каждого набора данных мы предоставляем здесь сценарии сравнительного анализа
Pythae также позволяет вам поделиться своими моделями в концентраторе Huggingface. Для этого вам нужно:
huggingface_hub установлен в вашей виртуальной Env. Если нет, вы можете установить его с $ python -m pip install huggingface_hub
$ huggingface-cli login
Любая модель Pythae можно легко загрузить с помощью метода push_to_hf_hub
> >> my_vae_model . push_to_hf_hub ( hf_hub_path = "your_hf_username/your_hf_hub_repo" ) ПРИМЕЧАНИЕ. Если your_hf_hub_repo уже существует и не является пустым, файлы будут переопределены. В случае, если репо your_hf_hub_repo не существует, будет создана папка с тем же именем.
Эквивалентно, вы можете загрузить или перезагрузить любую модель Pythae непосредственно из концентратора, используя метод load_from_hf_hub
> >> from pythae . models import AutoModel
> >> my_downloaded_vae = AutoModel . load_from_hf_hub ( hf_hub_path = "path_to_hf_repo" )wandb ?Pythae также интегрирует инструмент отслеживания эксперимента Wandb, позволяя пользователям хранить свои конфигурации, отслеживать свои тренинги и сравнивать запуска через графический интерфейс. Чтобы использовать эту функцию, вам понадобится:
wandb установил в вашей виртуальной Env. Если нет, вы можете установить его с $ pip install wandb
$ wandb login
WandbCallback Запуск экспериментального мониторинга с wandb в Pythae довольно просто. Единственное, что нужно сделать пользователю, - это создать экземпляр WandbCallback ...
> >> # Create you callback
>> > from pythae . trainers . training_callbacks import WandbCallback
> >> callbacks = [] # the TrainingPipeline expects a list of callbacks
> >> wandb_cb = WandbCallback () # Build the callback
> >> # SetUp the callback
>> > wandb_cb . setup (
... training_config = your_training_config , # training config
... model_config = your_model_config , # model config
... project_name = "your_wandb_project" , # specify your wandb project
... entity_name = "your_wandb_entity" , # specify your wandb entity
... )
> >> callbacks . append ( wandb_cb ) # Add it to the callbacks list ... а затем передай его в TrainingPipeline .
> >> pipeline = TrainingPipeline (
... training_config = config ,
... model = model
... )
> >> pipeline (
... train_data = train_dataset ,
... eval_data = eval_dataset ,
... callbacks = callbacks # pass the callbacks to the TrainingPipeline and you are done!
... )
> >> # You can log to https://wandb.ai/your_wandb_entity/your_wandb_project to monitor your trainingСмотрите подробный учебник
mlflow ?Pythae также интегрирует инструмент отслеживания эксперимента Mlflow, позволяя пользователям хранить свои конфигурации, отслеживать свои тренинги и сравнивать запуска через графический интерфейс. Чтобы использовать эту функцию, вам понадобится:
mlfow установлен в вашей виртуальной Env. Если нет, вы можете установить его с $ pip install mlflow
MLFlowCallback Запуск экспериментального мониторинга с mlfow в Pythae довольно просто. Единственное, что нужно сделать пользователю, - это создать экземпляр MLFlowCallback ...
> >> # Create you callback
>> > from pythae . trainers . training_callbacks import MLFlowCallback
> >> callbacks = [] # the TrainingPipeline expects a list of callbacks
> >> mlflow_cb = MLFlowCallback () # Build the callback
> >> # SetUp the callback
>> > mlflow_cb . setup (
... training_config = your_training_config , # training config
... model_config = your_model_config , # model config
... run_name = "mlflow_cb_example" , # specify your mlflow run
... )
> >> callbacks . append ( mlflow_cb ) # Add it to the callbacks list ... а затем передай его в TrainingPipeline .
> >> pipeline = TrainingPipeline (
... training_config = config ,
... model = model
... )
> >> pipeline (
... train_data = train_dataset ,
... eval_data = eval_dataset ,
... callbacks = callbacks # pass the callbacks to the TrainingPipeline and you are done!
... ) Вы можете визуализировать свою метрику, запустив следующее в каталоге, где ./mlruns
$ mlflow ui Смотрите подробный учебник
comet_ml ?Pythae также интегрирует инструмент отслеживания эксперимента Comet_ml, позволяя пользователям хранить свои конфигурации, отслеживать свои тренинги и сравнивать пробеги через графический интерфейс. Чтобы использовать эту функцию, вам понадобится:
comet_ml установлен в вашей виртуальной Env. Если нет, вы можете установить его с $ pip install comet_ml
CometCallback Запуск экспериментального мониторинга с comet_ml в Pythae довольно просто. Единственное, что нужно сделать пользователю, - это создать экземпляр CometCallback ...
> >> # Create you callback
>> > from pythae . trainers . training_callbacks import CometCallback
> >> callbacks = [] # the TrainingPipeline expects a list of callbacks
> >> comet_cb = CometCallback () # Build the callback
> >> # SetUp the callback
>> > comet_cb . setup (
... training_config = training_config , # training config
... model_config = model_config , # model config
... api_key = "your_comet_api_key" , # specify your comet api-key
... project_name = "your_comet_project" , # specify your wandb project
... #offline_run=True, # run in offline mode
... #offline_directory='my_offline_runs' # set the directory to store the offline runs
... )
> >> callbacks . append ( comet_cb ) # Add it to the callbacks list ... а затем передай его в TrainingPipeline .
> >> pipeline = TrainingPipeline (
... training_config = config ,
... model = model
... )
> >> pipeline (
... train_data = train_dataset ,
... eval_data = eval_dataset ,
... callbacks = callbacks # pass the callbacks to the TrainingPipeline and you are done!
... )
> >> # You can log to https://comet.com/your_comet_username/your_comet_project to monitor your trainingСмотрите подробный учебник
Чтобы помочь вам понять, как работает Pythae и как вы можете обучить свои модели с этой библиотекой, мы также предоставляем учебные пособия:
Mate_your_own_autoencoder.ipynb показывает вам, как передавать свои собственные сети в модели, реализованные в Pythae
custom_dataset.ipynb показывает вам, как использовать пользовательские наборы данных с любой из моделей, реализованных в Pythae
hf_hub_models_sharing.ipynb показывает, как загружать и загружать модели для концентратора huggingface
wandb_experiment_monitoring.ipynb показывает, как контролировать ваши эксперименты с использованием wandb
mlflow_experiment_monitoring.ipynb показывает, как контролировать эксперименты с использованием mlflow
comet_experiment_monitoring.ipynb показывает вам, как контролировать вас эксперименты, используя comet_ml
Папка Models_training предоставляет записные книжки, показывающие, как обучать каждую реализованную модель и как выбирать ее с помощью pythae.samplers .
Папка сценариев содержит, в частности, пример обучающего сценария для обучения моделей на наборах данных (MNIST, CIFAR10, Celeba ...)
Если вы испытываете какие -либо проблемы при запуска кода или запросите новые функции/модели, которые будут реализованы, откройте проблему на GitHub.
Вы хотите внести свой вклад в эту библиотеку, добавив модель, пробоотборник или просто исправить ошибку? Это круто! Спасибо! Пожалуйста, смотрите Anforming.md, чтобы следовать основным руководящим принципам.
Сначала давайте посмотрим на реконструированные образцы, взятые из набора оценки.
| Модели | Мнист | Селеба |
|---|---|---|
| Оценка данных |  |  |
| Аэ |  |  |
| Вал |  |  |
| Бета-вар |  |  |
| VAE LIN NF |  |  |
| Vae Iaf |  |  |
| Отключенная бета-варка |  |  |
| Факторв |  |  |
| Betatcvae |  |  |
| Iwae |  |  |
| MSSIM_VAE |  |  |
| Вай |  |  |
| Информация Vae |  |  |
| Вампир |  |  |
| Svae |  |  |
| Adversarial_ae |  |  |
| Vae_gan |  |  |
| VQVAE |  |  |
| HVAE |  |  |
| Rae_l2 |  |  |
| Rae_gp |  |  |
| Риеманн Гамильтониан Ваэ (Rhvae) |  |  |
Здесь мы показываем сгенерированные образцы, используя каждую модель, реализованную в библиотеке, и в разных пробоотборниках.
| Модели | Мнист | Селеба |
|---|---|---|
| Ae + gaussianmixturesampler |  |  |
| Vae + normalsampler |  |  |
| Vae + gaussianmixturesampler |  |  |
| Vae + twostagevaesampler |  |  |
| Vae + mafsampler |  |  |
| Бета-варки + normalsampler | 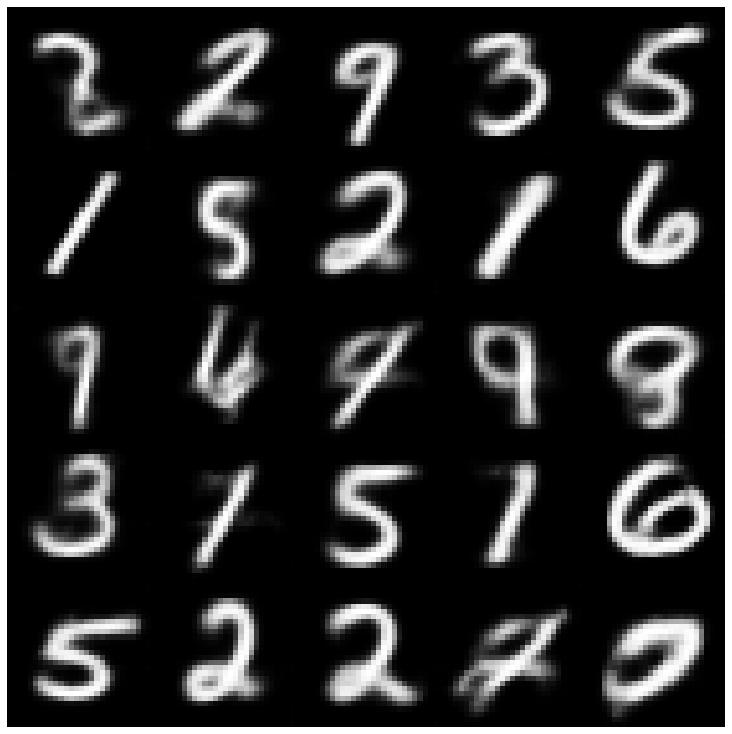 |  |
| Vae lin nf + normalsampler |  |  |
| Vae iaf + normalsampler |  |  |
| Рассеянный бета-Vae + normalsampler |  |  |
| Factorvae + Normalsampler |  |  |
| Betatcvae + normalsampler |  |  |
| Iwae + нормальный пробоотборник |  |  |
| Mssisim_vae + normalsampler |  |  |
| Wae + Normalsampler |  |  |
| Информация vae + normalsampler |  |  |
| Svae + HypershereUniformsampler |  |  |
| Вамп + Вампсамплер |  |  |
| Adversarial_ae + Normalsampler |  |  |
| Vaegan + Normalsampler |  |  |
| VQVAE + MAFSAMPLER |  |  |
| Hvae + Normalsampler |  |  |
| Rae_l2 + gaussianmixturesampler |  |  |
| Rae_gp + gaussianmixturesampler |  |  |
| Riemannian hamiltonian vae (Rhvae) + Rhvae Sampler |  |  |
Если вы обнаружите эту работу полезной или используйте ее в своем исследовании, пожалуйста, рассмотрите возможность ссылаться на нас
@inproceedings { chadebec2022pythae ,
author = { Chadebec, Cl'{e}ment and Vincent, Louis and Allassonniere, Stephanie } ,
booktitle = { Advances in Neural Information Processing Systems } ,
editor = { S. Koyejo and S. Mohamed and A. Agarwal and D. Belgrave and K. Cho and A. Oh } ,
pages = { 21575--21589 } ,
publisher = { Curran Associates, Inc. } ,
title = { Pythae: Unifying Generative Autoencoders in Python - A Benchmarking Use Case } ,
volume = { 35 } ,
year = { 2022 }
}

