benchmark_VAE
Pythae 0.1.2
Documentação
Esta biblioteca implementa alguns dos modelos de autoencoder mais comuns (variacionais) sob uma implementação unificada. Em particular, ele fornece a possibilidade de realizar experimentos e comparações de referência, treinando os modelos com a mesma arquitetura de rede neural de autoencodificação. O recurso Make Your Own AutoEncoder permite que você treine qualquer um desses modelos com seus próprios dados e redes neurais de codificador e decodificador. Ele integra ferramentas de monitoramento de experimentos como wandb, mlflow ou cometa-ml? e permite o compartilhamento e o carregamento de modelos do hub do Huggingface? em algumas linhas de código.
Notícias ?
A partir da v0.1.0, Pythae agora suporta treinamento distribuído usando o DDP de Pytorch. Agora você pode treinar seu VAE favorito mais rápido e em conjuntos de dados maiores, ainda com algumas linhas de código. Veja nosso benchmark acelerado.
wandb / experimento com rastreamento mlflow / experimento com comet_ml Para instalar o lançamento estável mais recente desta biblioteca, execute o seguinte usando pip
$ pip install pythae Para instalar a versão mais recente do Github desta biblioteca, execute o seguinte usando pip
$ pip install git+https://github.com/clementchadebec/benchmark_VAE.gitou, alternativamente, você pode clonar o repositório do GitHub para acessar testes, tutoriais e scripts.
$ git clone https://github.com/clementchadebec/benchmark_VAE.gite instalar a biblioteca
$ cd benchmark_VAE
$ pip install -e . Abaixo está a lista dos modelos atualmente implementados na biblioteca.
| Modelos | Exemplo de treinamento | Papel | Implementação oficial |
|---|---|---|---|
| AutoEncoder (AE) | |||
| AutoEncoder variacional (VAE) | link | ||
| AutoEncoder de autoencis | link | ||
| VAE com fluxos normalizadores lineares (VAE_LINNF) | link | ||
| VAE com fluxos autoregressivos inversos (VAE_IAF) | link | link | |
| Autoencoder de variação beta semenda (DisEntangledBetavae) | link | ||
| Desenvolvimento por fator (fatorvae) | link | ||
| Beta-tc-vrae (betatcvae) | link | link | |
| Importância ponderada autoencoder (iwae) | link | link | |
| Multiplicar a importância AutoEncoder ponderado (MIWAE) | link | ||
| Parcialmente Importância ponderada Autoencoder (PIWAE) | link | ||
| Importância combinada AutoEncoder ponderado (CIWAE) | link | ||
| VAE com similaridade métrica perceptiva (MSSSIM_VAE) | link | ||
| Wasserstein AutoEncoder (WAE) | link | link | |
| Informações Variaivas AutoEncoder (INFOVAE_MMD) | link | ||
| Vamp AutoEncoder (vamp) | link | link | |
| VAE hiperesférico (SVAE) | link | link | |
| Poincaré Disk Vae (Poincarevae) | link | link | |
| AutoEncoder adversário (Adversarial_Ae) | link | ||
| GaN de autoencoder variacional (Vaegan)? | link | link | |
| Vector quantizado VAE (VQVAE) | link | link | |
| Hamiltoniano VAE (HVAE) | link | link | |
| EA regularizada com L2 Decoder Param (RAE_L2) | link | link | |
| EA regularizada com penalidade de gradiente (RAE_GP) | link | link | |
| Riemannian Hamiltonian Vae (Rhvae) | link | link | |
| Quantização residual hierárquica (HRQVAE) | link | link |
Consulte Resultados de reconstrução e geração para todos os modelos mencionados acima
Abaixo está a lista dos modelos atualmente implementados na biblioteca.
| Amostradores | Modelos | Papel | Implementação oficial |
|---|---|---|---|
| Normal Prior (NormalSampler) | Todos os modelos | link | |
| Mistura gaussiana (GaussianMixTuresSampler) | Todos os modelos | link | link |
| Sampler VAE de dois estágios (Twostagevaesampler) | Todos os modelos baseados em VAE | link | link |
| Sampler uniforme da esfera da unidade (hiperfereuniformes -amostrador) | Svae | link | link |
| Sampler de disco Poincaré (PoincaryDisksampler) | Poincarevae | link | link |
| Sampler Prior Vamp (Vampsampler) | Vamp | link | link |
| Amostrador de coletores (rhvaesampler) | Rhvae | link | link |
| Amostrador de fluxo autoregressivo mascarado (mafsampler) | Todos os modelos | link | link |
| Amostrador de fluxo autoregressivo inverso (iafsampler) | Todos os modelos | link | link |
| Pixelcnn (pixelcnnsampler) | Vqvae | link |
Validamos as implementações reproduzindo alguns resultados apresentados nas publicações originais quando o código oficial for divulgado ou quando detalhes suficientes sobre a seção experimental dos trabalhos estavam disponíveis. Veja a reprodutibilidade para obter mais detalhes.
Para iniciar um treinamento de modelo, você só precisa chamar uma instância TrainingPipeline .
> >> from pythae . pipelines import TrainingPipeline
> >> from pythae . models import VAE , VAEConfig
> >> from pythae . trainers import BaseTrainerConfig
> >> # Set up the training configuration
>> > my_training_config = BaseTrainerConfig (
... output_dir = 'my_model' ,
... num_epochs = 50 ,
... learning_rate = 1e-3 ,
... per_device_train_batch_size = 200 ,
... per_device_eval_batch_size = 200 ,
... train_dataloader_num_workers = 2 ,
... eval_dataloader_num_workers = 2 ,
... steps_saving = 20 ,
... optimizer_cls = "AdamW" ,
... optimizer_params = { "weight_decay" : 0.05 , "betas" : ( 0.91 , 0.995 )},
... scheduler_cls = "ReduceLROnPlateau" ,
... scheduler_params = { "patience" : 5 , "factor" : 0.5 }
... )
> >> # Set up the model configuration
>> > my_vae_config = model_config = VAEConfig (
... input_dim = ( 1 , 28 , 28 ),
... latent_dim = 10
... )
> >> # Build the model
>> > my_vae_model = VAE (
... model_config = my_vae_config
... )
> >> # Build the Pipeline
>> > pipeline = TrainingPipeline (
... training_config = my_training_config ,
... model = my_vae_model
... )
> >> # Launch the Pipeline
>> > pipeline (
... train_data = your_train_data , # must be torch.Tensor, np.array or torch datasets
... eval_data = your_eval_data # must be torch.Tensor, np.array or torch datasets
... ) No final do treinamento, os melhores pesos do modelo, a configuração do modelo e a configuração de treinamento são armazenados em uma pasta final_model disponível em my_model/MODEL_NAME_training_YYYY-MM-DD_hh-mm-ss (com my_model sendo o argumento output_dir do BaseTrainerConfig ). Se você definir ainda mais o argumento steps_saving para um determinado valor, as pastas denominadas checkpoint_epoch_k contendo os melhores pesos do modelo, otimizador, agendador, configuração e configuração de treinamento em Epoch K também aparecerão em my_model/MODEL_NAME_training_YYYY-MM-DD_hh-mm-ss .
Também fornecemos um exemplo de script de treinamento aqui que pode ser usado para treinar os modelos nos conjuntos de dados de benchmarks (MNIST, CIFAR10, CELEBA ...). O script pode ser lançado com o seguinte linha de comando
python training.py --dataset mnist --model_name ae --model_config ' configs/ae_config.json ' --training_config ' configs/base_training_config.json 'Consulte Readme.md para obter mais detalhes sobre este script
GenerationPipeline A maneira mais fácil de lançar uma geração de dados a partir de um modelo treinado consiste no uso da GenerationPipeline interna fornecida no Pythae. Digamos que você deseja gerar 100 amostras usando um MAFSampler , tudo o que você precisa fazer é 1) relacionar o modelo treinado, 2) Definir a configuração do amostrador e 3) Criar e iniciar a GenerationPipeline da seguinte forma da seguinte maneira da seguinte
> >> from pythae . models import AutoModel
> >> from pythae . samplers import MAFSamplerConfig
> >> from pythae . pipelines import GenerationPipeline
> >> # Retrieve the trained model
>> > my_trained_vae = AutoModel . load_from_folder (
... 'path/to/your/trained/model'
... )
> >> my_sampler_config = MAFSamplerConfig (
... n_made_blocks = 2 ,
... n_hidden_in_made = 3 ,
... hidden_size = 128
... )
> >> # Build the pipeline
>> > pipe = GenerationPipeline (
... model = my_trained_vae ,
... sampler_config = my_sampler_config
... )
> >> # Launch data generation
>> > generated_samples = pipe (
... num_samples = args . num_samples ,
... return_gen = True , # If false returns nothing
... train_data = train_data , # Needed to fit the sampler
... eval_data = eval_data , # Needed to fit the sampler
... training_config = BaseTrainerConfig ( num_epochs = 200 ) # TrainingConfig to use to fit the sampler
... )Como alternativa, você pode iniciar o processo de geração de dados a partir de um modelo treinado diretamente com o amostrador. Por exemplo, para gerar novos dados com o seu amostrador, execute o seguinte.
> >> from pythae . models import AutoModel
> >> from pythae . samplers import NormalSampler
> >> # Retrieve the trained model
>> > my_trained_vae = AutoModel . load_from_folder (
... 'path/to/your/trained/model'
... )
> >> # Define your sampler
>> > my_samper = NormalSampler (
... model = my_trained_vae
... )
> >> # Generate samples
>> > gen_data = my_samper . sample (
... num_samples = 50 ,
... batch_size = 10 ,
... output_dir = None ,
... return_gen = True
... ) Se você definir output_dir como um caminho específico, as imagens geradas serão salvas como arquivos .png denominados 00000000.png , 00000001.png ... os amostradores podem ser usados com qualquer modelo, desde que seja adequado. Por exemplo, uma instância GaussianMixtureSampler pode ser usada para gerar a partir de qualquer modelo, mas um VAMPSampler só será utilizável com um modelo VAMP . Verifique aqui para ver quais se aplicam ao seu modelo. Cuidado com o fato de alguns amostradores como o GaussianMixtureSampler , por exemplo, podem precisar ser instalados chamando o método fit antes de usar. Abaixo está um exemplo para o GaussianMixtureSampler .
> >> from pythae . models import AutoModel
> >> from pythae . samplers import GaussianMixtureSampler , GaussianMixtureSamplerConfig
> >> # Retrieve the trained model
>> > my_trained_vae = AutoModel . load_from_folder (
... 'path/to/your/trained/model'
... )
> >> # Define your sampler
... gmm_sampler_config = GaussianMixtureSamplerConfig (
... n_components = 10
... )
> >> my_samper = GaussianMixtureSampler (
... sampler_config = gmm_sampler_config ,
... model = my_trained_vae
... )
> >> # fit the sampler
>> > gmm_sampler . fit ( train_dataset )
> >> # Generate samples
>> > gen_data = my_samper . sample (
... num_samples = 50 ,
... batch_size = 10 ,
... output_dir = None ,
... return_gen = True
... )O Pythae oferece a possibilidade de definir suas próprias redes neurais nos modelos VAE. Por exemplo, digamos que você deseja treinar um wassertstein ae com um codificador e decodificador específico, você pode fazer o seguinte:
> >> from pythae . models . nn import BaseEncoder , BaseDecoder
> >> from pythae . models . base . base_utils import ModelOutput
> >> class My_Encoder ( BaseEncoder ):
... def __init__ ( self , args = None ): # Args is a ModelConfig instance
... BaseEncoder . __init__ ( self )
... self . layers = my_nn_layers ()
...
... def forward ( self , x : torch . Tensor ) -> ModelOutput :
... out = self . layers ( x )
... output = ModelOutput (
... embedding = out # Set the output from the encoder in a ModelOutput instance
... )
... return output
...
... class My_Decoder ( BaseDecoder ):
... def __init__ ( self , args = None ):
... BaseDecoder . __init__ ( self )
... self . layers = my_nn_layers ()
...
... def forward ( self , x : torch . Tensor ) -> ModelOutput :
... out = self . layers ( x )
... output = ModelOutput (
... reconstruction = out # Set the output from the decoder in a ModelOutput instance
... )
... return output
...
> >> my_encoder = My_Encoder ()
> >> my_decoder = My_Decoder ()E agora construa o modelo
> >> from pythae . models import WAE_MMD , WAE_MMD_Config
> >> # Set up the model configuration
>> > my_wae_config = model_config = WAE_MMD_Config (
... input_dim = ( 1 , 28 , 28 ),
... latent_dim = 10
... )
...
> >> # Build the model
>> > my_wae_model = WAE_MMD (
... model_config = my_wae_config ,
... encoder = my_encoder , # pass your encoder as argument when building the model
... decoder = my_decoder # pass your decoder as argument when building the model
... ) NOTA IMPORTANTE 1 : Para todos os modelos baseados em AE (AE, WAE, RAE_L2, RAE_GP), o codificador e o decodificador devem retornar uma instância ModelOutput . Para o codificador, a instância ModelOutput deve conter os incorporados sob a chave embedding . Para o decodificador, a instância ModelOutput deve conter as reconstruções sob a principal reconstruction .
NOTA IMPORTANTE 2 : Para todos os modelos baseados em VAE (VAE, Betavae, Iwae, HVAE, Vamp, RHVAE), o codificador e o decodificador devem retornar uma instância ModelOutput . Para o codificador, a instância ModelOutput deve conter as matrizes incorporadas e log -covariância (da forma batch_size x latent_space_dim) respectivamente sob a chave embedding e log_covariance . Para o decodificador, a instância ModelOutput deve conter as reconstruções sob a principal reconstruction .
Você também pode encontrar arquiteturas de rede neural predefinidas para os conjuntos de dados mais comuns ( por exemplo , Mnist, Cifar, Celeba ...) que podem ser carregados da seguinte maneira
> >> from pythae . models . nn . benchmark . mnist import (
... Encoder_Conv_AE_MNIST , # For AE based model (only return embeddings)
... Encoder_Conv_VAE_MNIST , # For VAE based model (return embeddings and log_covariances)
... Decoder_Conv_AE_MNIST
... )Substitua o MNIST por Cifar ou Celeba para acessar outras redes neurais.
Pythae A partir da v0.1.0 , o Pythae agora suporta treinamento distribuído usando o DDP de Pytorch. Ele permite que você treine seu VAE favorito mais rápido e em conjunto de dados maiores usando treinamento multi-GPU e/ou vários nós.
Para fazer isso, você pode criar um script python que será lançado por um lançador (como srun em um cluster). A única coisa necessária no script é especificar alguns elementos em relação ao ambiente distribuído (como o número de nós/GPUs) diretamente na configuração de treinamento da seguinte maneira
> >> training_config = BaseTrainerConfig (
... num_epochs = 10 ,
... learning_rate = 1e-3 ,
... per_device_train_batch_size = 64 ,
... per_device_eval_batch_size = 64 ,
... train_dataloader_num_workers = 8 ,
... eval_dataloader_num_workers = 8 ,
... dist_backend = "nccl" , # distributed backend
... world_size = 8 # number of gpus to use (n_nodes x n_gpus_per_node),
... rank = 5 # global gpu id,
... local_rank = 1 # gpu id within a node,
... master_addr = "localhost" # master address,
... master_port = "12345" # master port,
... ) Consulte este exemplo de script que define um treinamento VQVAE multi-GPU no conjunto de dados ImageNet. Observe que a maneira como as variáveis distribuídas do ambiente ( world_size , rank ...) são recuperadas pode ser específico para o cluster e o lançador que você usa.
Abaixo estão indicados os tempos de treinamento para um vetor quantizado VAE (VQ-VAE) com Pythae para 100 épocas no MNIST em GPU (s) V100 16GB (s), para 50 épocas no FFHQ (imagens 1024x1024) e para 20 épocas no ImageNet-1K no V100 32GB GPU (s).
| Dados de treinar | 1 GPU | 4 GPUs | 2x4 GPUs | |
|---|---|---|---|---|
| Mnist (vq-vé) | 28x28 imagens (50k) | 235.18 s | 62,00 s | 35.86 s |
| FFHQ 1024X1024 (VQVAE) | 1024x1024 imagens RGB (60k) | 19h 1min | 5h 6min | 2H 37min |
| ImageNet-1K 128x128 (VQVAE) | Imagens 128x128 RGB (~ 1,2m) | 6h 25min | 1H 41min | 51min 26s |
Para cada conjunto de dados, fornecemos os scripts de benchmarking aqui
O Pythae também permite que você compartilhe seus modelos no hub do Huggingface. Para fazer isso, você precisa:
huggingface_hub instalado no seu Env virtual. Se não você pode instalá -lo com $ python -m pip install huggingface_hub
$ huggingface-cli login
Qualquer modelo Pythae pode ser facilmente carregado usando o método push_to_hf_hub
> >> my_vae_model . push_to_hf_hub ( hf_hub_path = "your_hf_username/your_hf_hub_repo" ) NOTA: Se your_hf_hub_repo já existir, se você estiver vazio, os arquivos serão substituídos. No caso, o repo your_hf_hub_repo não existe, uma pasta com o mesmo nome será criada.
Equivalentemente, você pode baixar ou recarregar qualquer modelo de Pythae diretamente do hub usando o método load_from_hf_hub
> >> from pythae . models import AutoModel
> >> my_downloaded_vae = AutoModel . load_from_hf_hub ( hf_hub_path = "path_to_hf_repo" )wandb ?O Pythae também integra a ferramenta de rastreamento do experimento Wandb, permitindo que os usuários armazenem suas configurações, monitorem seus treinamentos e comparem o excesso de uma interface gráfica. Para poder usar esse recurso que você precisará:
wandb instalado no seu Env virtual. Se não você pode instalá -lo com $ pip install wandb
$ wandb login
WandbCallback O lançamento de um experimento de monitoramento com wandb em Pythae é bastante simples. A única coisa que um usuário precisa fazer é criar uma instância WandbCallback ...
> >> # Create you callback
>> > from pythae . trainers . training_callbacks import WandbCallback
> >> callbacks = [] # the TrainingPipeline expects a list of callbacks
> >> wandb_cb = WandbCallback () # Build the callback
> >> # SetUp the callback
>> > wandb_cb . setup (
... training_config = your_training_config , # training config
... model_config = your_model_config , # model config
... project_name = "your_wandb_project" , # specify your wandb project
... entity_name = "your_wandb_entity" , # specify your wandb entity
... )
> >> callbacks . append ( wandb_cb ) # Add it to the callbacks list ... e depois passe para a TrainingPipeline .
> >> pipeline = TrainingPipeline (
... training_config = config ,
... model = model
... )
> >> pipeline (
... train_data = train_dataset ,
... eval_data = eval_dataset ,
... callbacks = callbacks # pass the callbacks to the TrainingPipeline and you are done!
... )
> >> # You can log to https://wandb.ai/your_wandb_entity/your_wandb_project to monitor your trainingVeja o tutorial detalhado
mlflow ?O Pythae também integra a ferramenta de rastreamento de experimentos MLFlow, permitindo que os usuários armazenem suas configurações, monitorem seus treinamentos e comparem execuções por uma interface gráfica. Para poder usar esse recurso que você precisará:
mlfow instalou em seu Env virtual. Se não você pode instalá -lo com $ pip install mlflow
MLFlowCallback O lançamento de um experimento de monitoramento com mlfow em Pythae é bastante simples. A única coisa que um usuário precisa fazer é criar uma instância MLFlowCallback ...
> >> # Create you callback
>> > from pythae . trainers . training_callbacks import MLFlowCallback
> >> callbacks = [] # the TrainingPipeline expects a list of callbacks
> >> mlflow_cb = MLFlowCallback () # Build the callback
> >> # SetUp the callback
>> > mlflow_cb . setup (
... training_config = your_training_config , # training config
... model_config = your_model_config , # model config
... run_name = "mlflow_cb_example" , # specify your mlflow run
... )
> >> callbacks . append ( mlflow_cb ) # Add it to the callbacks list ... e depois passe para a TrainingPipeline .
> >> pipeline = TrainingPipeline (
... training_config = config ,
... model = model
... )
> >> pipeline (
... train_data = train_dataset ,
... eval_data = eval_dataset ,
... callbacks = callbacks # pass the callbacks to the TrainingPipeline and you are done!
... ) Você pode visualizar sua métrica executando o seguinte no diretório onde o ./mlruns
$ mlflow ui Veja o tutorial detalhado
comet_ml ?O Pythae também integra a ferramenta de rastreamento do experimento COMET_ML, permitindo que os usuários armazenem suas configurações, monitorem seus treinamentos e comparem execuções através de uma interface gráfica. Para poder usar esse recurso que você precisará:
comet_ml instalado em seu Env virtual. Se não você pode instalá -lo com $ pip install comet_ml
CometCallback O lançamento de um experimento de monitoramento com comet_ml em Pythae é bastante simples. A única coisa que um usuário precisa fazer é criar uma instância CometCallback ...
> >> # Create you callback
>> > from pythae . trainers . training_callbacks import CometCallback
> >> callbacks = [] # the TrainingPipeline expects a list of callbacks
> >> comet_cb = CometCallback () # Build the callback
> >> # SetUp the callback
>> > comet_cb . setup (
... training_config = training_config , # training config
... model_config = model_config , # model config
... api_key = "your_comet_api_key" , # specify your comet api-key
... project_name = "your_comet_project" , # specify your wandb project
... #offline_run=True, # run in offline mode
... #offline_directory='my_offline_runs' # set the directory to store the offline runs
... )
> >> callbacks . append ( comet_cb ) # Add it to the callbacks list ... e depois passe para a TrainingPipeline .
> >> pipeline = TrainingPipeline (
... training_config = config ,
... model = model
... )
> >> pipeline (
... train_data = train_dataset ,
... eval_data = eval_dataset ,
... callbacks = callbacks # pass the callbacks to the TrainingPipeline and you are done!
... )
> >> # You can log to https://comet.com/your_comet_username/your_comet_project to monitor your trainingVeja o tutorial detalhado
Para ajudá -lo a entender a maneira como o Pythae funciona e como você pode treinar seus modelos com esta biblioteca, também fornecemos tutoriais:
making_your_own_autoncoder.ipynb mostra como passar suas próprias redes para os modelos implementados em pythae
Custom_Dataset.ipynb mostra como usar conjuntos de dados personalizados com qualquer um dos modelos implementados em pythae
hf_hub_models_sharing.ipynb mostra como fazer upload e download de modelos para o hub do huggingface
wandb_experiment_monitoring.ipynb mostra como monitorar seus experimentos usando wandb
mlflow_experiment_monitoring.ipynb mostra como monitorar seus experimentos usando mlflow
comet_experiment_monitoring.ipynb mostra como monitorar seus experimentos usando comet_ml
Models_training Pasta fornece notebooks mostrando como treinar cada modelo implementado e como amostrar usando pythae.samplers .
A pasta Scripts fornece, em particular, um exemplo de um script de treinamento para treinar os modelos nos conjuntos de dados de benchmark (MNIST, CIFAR10, CELEBA ...)
Se você estiver com problemas ao executar o código ou solicitar novos recursos/modelos a serem implementados, abra um problema no Github.
Você deseja contribuir com esta biblioteca adicionando um modelo, um amostrador ou simplesmente corrige um bug? Isso é incrível! Obrigado! Consulte Contribuindo.md para seguir as principais diretrizes contribuintes.
Primeiro, vamos dar uma olhada nas amostras reconstruídas retiradas do conjunto de avaliação.
| Modelos | Mnist | Celeba |
|---|---|---|
| Dados de avaliação |  |  |
| Ae |  |  |
| Vae |  |  |
| Beta-vas |  |  |
| VAE LIN NF |  |  |
| VAE IAF |  |  |
| Desembaltado beta-vas |  |  |
| Fatorvae |  |  |
| Betatcvae |  |  |
| Iwae |  |  |
| MssSIM_VAE |  |  |
| Wae |  |  |
| Info Vae |  |  |
| Vamp |  |  |
| Svae |  |  |
| Adversas_ae |  |  |
| Vae_gan |  |  |
| Vqvae |  |  |
| Hvae |  |  |
| Rae_l2 |  |  |
| Rae_gp |  |  |
| Riemannian Hamiltonian Vae (Rhvae) |  |  |
Aqui, mostramos as amostras geradas usando cada modelo implementado na biblioteca e diferentes amostradores.
| Modelos | Mnist | Celeba |
|---|---|---|
| AE + GaussianMixtureSampler |  |  |
| VAE + NORMALSAMPLER |  |  |
| VAE + GAUSSIANMIXTURSAMPLER |  |  |
| VAE + TWOSTAGEVAESAMPLER |  |  |
| VAE + Mafsampler |  |  |
| Beta-vas + normandalsampler | 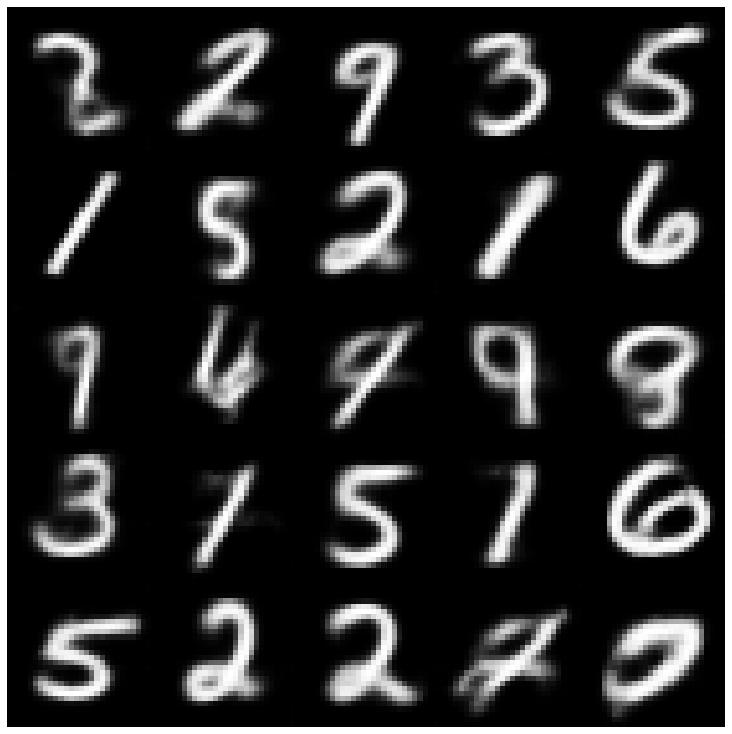 |  |
| Vae Lin NF + Normalsampler |  |  |
| VAE IAF + Normalsampler |  |  |
| Desembaleia beta-vase + normandal |  |  |
| Fatorvae + normalMampler |  |  |
| Betatcvae + NormalSampler |  |  |
| Iwae + amostrador normal |  |  |
| MSSSIM_VAE + NORMALSAMPLER |  |  |
| WAE + NORMALSAMPLER |  |  |
| Info Vae + Normalsampler |  |  |
| SVAE + HyperShereuniformsMampler |  |  |
| VAMP + VAMPSAMPLER |  |  |
| Adversas_ae + normandsampler |  |  |
| Vaegan + Normalsampler |  |  |
| Vqvae + mafsampler |  |  |
| HVAE + NORMALSAMPLER |  |  |
| RAE_L2 + GAUSSIANMIXTURSAMPLER |  |  |
| RAE_GP + GAUSSIANMIXTURSAMPLER |  |  |
| Riemannian Hamiltonian VAE (RHVAE) + RHVAE Sampler |  |  |
Se você achar este trabalho útil ou usá -lo em sua pesquisa, considere nos citar
@inproceedings { chadebec2022pythae ,
author = { Chadebec, Cl'{e}ment and Vincent, Louis and Allassonniere, Stephanie } ,
booktitle = { Advances in Neural Information Processing Systems } ,
editor = { S. Koyejo and S. Mohamed and A. Agarwal and D. Belgrave and K. Cho and A. Oh } ,
pages = { 21575--21589 } ,
publisher = { Curran Associates, Inc. } ,
title = { Pythae: Unifying Generative Autoencoders in Python - A Benchmarking Use Case } ,
volume = { 35 } ,
year = { 2022 }
}

