benchmark_VAE
Pythae 0.1.2
Documentation
Cette bibliothèque implémente certains des modèles d'autoencoder les plus courants (variationnels) sous une implémentation unifiée. En particulier, il offre la possibilité d'effectuer des expériences de référence et des comparaisons en formant les modèles avec la même architecture de réseau neuronal automatique. La fonctionnalité de fabrication de votre propre autoencoder vous permet de former l'un de ces modèles avec vos propres données et vos propres réseaux de neurones d'encodeur et de décodeur. Il intègre des outils de surveillance des expériences tels que WANDB, MLFLOW ou COMET-ML? et permet le partage et le chargement du modèle à partir du hub HuggingFace? dans quelques lignes de code.
Nouvelles ?
À partir de V0.1.0, Pythae prend désormais en charge la formation distribuée à l'aide du DDP de Pytorch. Vous pouvez désormais former votre VAE préféré plus rapidement et sur des ensembles de données plus grands, toujours avec quelques lignes de code. Voir notre référence d'accélération.
wandb / Experiment avec mlflow / Suivi de l'expérience avec comet_ml Pour installer la dernière version stable de cette bibliothèque, exécutez ce qui suit en utilisant pip
$ pip install pythae Pour installer la dernière version github de cette bibliothèque, exécutez ce qui suit à l'aide pip
$ pip install git+https://github.com/clementchadebec/benchmark_VAE.gitOu alternativement, vous pouvez cloner le repo GitHub pour accéder aux tests, tutoriels et scripts.
$ git clone https://github.com/clementchadebec/benchmark_VAE.gitet installer la bibliothèque
$ cd benchmark_VAE
$ pip install -e . Vous trouverez ci-dessous la liste des modèles actuellement implémentés dans la bibliothèque.
| Modèles | Exemple de formation | Papier | Mise en œuvre officielle |
|---|---|---|---|
| Autoencoder (AE) | |||
| Autoencoder variationnel (VAE) | lien | ||
| Autoencoder Variational Beta (Betavae) | lien | ||
| VAE avec des flux de normalisation linéaire (VAE_LINNF) | lien | ||
| VAE avec des écoulements autorégressifs inverses (VAE_IAF) | lien | lien | |
| Autoencodeur variationnel bêta désoccupée (DissentangledBetavae) | lien | ||
| Démêlant en factorisant (Factorvae) | lien | ||
| Beta-TC-VAE (Betatcvae) | lien | lien | |
| Importance Autoencoder pondéré (IWAE) | lien | lien | |
| Multiplier l'autoencodeur pondéré d'importance (miwae) | lien | ||
| Autoencoder pondéré partiellement important (Piwae) | lien | ||
| Autoencoder pondéré d'importance combinée (Ciwae) | lien | ||
| VAE avec une similitude métrique perceptuelle (MSSSIM_VAE) | lien | ||
| Autoencoder de Wasserstein (WAE) | lien | lien | |
| Info Variational Autoencoder (infovae_mmd) | lien | ||
| Vamp Autoencoder (VAMP) | lien | lien | |
| Vae hypersphérique (SVAE) | lien | lien | |
| Disque Poincaré Vae (Poincarevae) | lien | lien | |
| Autoencoder adversaire (adversarial_ae) | lien | ||
| Variational Autoencoder Gan (Vaegan)? | lien | lien | |
| Vector quantifié VAE (VQVAE) | lien | lien | |
| Hamiltonien Vae (HVAE) | lien | lien | |
| Régularisé AE avec le décodeur L2 Param (RAE_L2) | lien | lien | |
| Régularisé AE avec pénalité de gradient (RAE_GP) | lien | lien | |
| Riemannien Hamiltonian Vae (Rhvae) | lien | lien | |
| Quantification résiduelle hiérarchique (HRQVAE) | lien | lien |
Voir les résultats de la reconstruction et de la génération pour tous les modèles susmentionnés
Vous trouverez ci-dessous la liste des modèles actuellement implémentés dans la bibliothèque.
| Échantillonneurs | Modèles | Papier | Mise en œuvre officielle |
|---|---|---|---|
| Prior normal (Normalsampler) | Tous les modèles | lien | |
| Mélange gaussien (GaussianMixturesampler) | Tous les modèles | lien | lien |
| Sampleur Vae à deux étapes (TwostageVaesampler) | Tous les modèles basés sur VAE | lien | lien |
| Échantillonneur uniforme de la sphère unitaire (HypersphereUniformSampler) | Svae | lien | lien |
| Échantillonneur de disque de Poincaré (Poingedisksampler) | Poincarevae | lien | lien |
| Vamp Sampleur antérieure (vampsampleur) | VAMP | lien | lien |
| Échantillonneur de collecteur (Rhvaesampler) | Rhvae | lien | lien |
| Échantillonneur de débit autorégressif masqué (MAFSampler) | Tous les modèles | lien | lien |
| Échantillonneur de débit autorégressif inverse (IAFSampler) | Tous les modèles | lien | lien |
| Pixelcnn (pixelcnnsampler) | Vqvae | lien |
Nous validons les implémentations en reproduisant certains résultats présentés dans les publications originales lorsque le code officiel a été publié ou lorsque suffisamment de détails sur la section expérimentale des articles étaient disponibles. Voir Reproductibilité pour plus de détails.
Pour lancer une formation de modèle, vous n'avez qu'à appeler une instance TrainingPipeline .
> >> from pythae . pipelines import TrainingPipeline
> >> from pythae . models import VAE , VAEConfig
> >> from pythae . trainers import BaseTrainerConfig
> >> # Set up the training configuration
>> > my_training_config = BaseTrainerConfig (
... output_dir = 'my_model' ,
... num_epochs = 50 ,
... learning_rate = 1e-3 ,
... per_device_train_batch_size = 200 ,
... per_device_eval_batch_size = 200 ,
... train_dataloader_num_workers = 2 ,
... eval_dataloader_num_workers = 2 ,
... steps_saving = 20 ,
... optimizer_cls = "AdamW" ,
... optimizer_params = { "weight_decay" : 0.05 , "betas" : ( 0.91 , 0.995 )},
... scheduler_cls = "ReduceLROnPlateau" ,
... scheduler_params = { "patience" : 5 , "factor" : 0.5 }
... )
> >> # Set up the model configuration
>> > my_vae_config = model_config = VAEConfig (
... input_dim = ( 1 , 28 , 28 ),
... latent_dim = 10
... )
> >> # Build the model
>> > my_vae_model = VAE (
... model_config = my_vae_config
... )
> >> # Build the Pipeline
>> > pipeline = TrainingPipeline (
... training_config = my_training_config ,
... model = my_vae_model
... )
> >> # Launch the Pipeline
>> > pipeline (
... train_data = your_train_data , # must be torch.Tensor, np.array or torch datasets
... eval_data = your_eval_data # must be torch.Tensor, np.array or torch datasets
... ) À la fin de la formation, les meilleurs poids de modèle, la configuration du modèle et la configuration de la formation sont stockés dans un dossier final_model disponible dans my_model/MODEL_NAME_training_YYYY-MM-DD_hh-mm-ss (avec my_model étant l'argument output_dir de la BaseTrainerConfig ). Si vous définissez l'argument steps_saving sur une certaine valeur, les dossiers nommés checkpoint_epoch_k contenant les meilleurs poids de modèle, Optimiseur, planificateur, configuration et configuration de la formation à Epoch K apparaîtra également dans my_model/MODEL_NAME_training_YYYY-MM-DD_hh-mm-ss .
Nous fournissons également un exemple de script de formation ici qui peut être utilisé pour former les modèles sur les ensembles de données de référence (MNIST, CIFAR10, Celeba ...). Le script peut être lancé avec la ligne de commande suivante
python training.py --dataset mnist --model_name ae --model_config ' configs/ae_config.json ' --training_config ' configs/base_training_config.json 'Voir readme.md pour plus de détails sur ce script
GenerationPipeline Le moyen le plus simple de lancer une génération de données à partir d'un modèle formé consiste à utiliser la GenerationPipeline intégrée fournie à Pythae. Supposons que vous souhaitez générer 100 échantillons à l'aide d'un MAFSampler , tout ce que vous avez à faire est 1) Relaod le modèle formé, 2) définir la configuration de l'échantillonneur et 3) créer et lancer le GenerationPipeline comme suit
> >> from pythae . models import AutoModel
> >> from pythae . samplers import MAFSamplerConfig
> >> from pythae . pipelines import GenerationPipeline
> >> # Retrieve the trained model
>> > my_trained_vae = AutoModel . load_from_folder (
... 'path/to/your/trained/model'
... )
> >> my_sampler_config = MAFSamplerConfig (
... n_made_blocks = 2 ,
... n_hidden_in_made = 3 ,
... hidden_size = 128
... )
> >> # Build the pipeline
>> > pipe = GenerationPipeline (
... model = my_trained_vae ,
... sampler_config = my_sampler_config
... )
> >> # Launch data generation
>> > generated_samples = pipe (
... num_samples = args . num_samples ,
... return_gen = True , # If false returns nothing
... train_data = train_data , # Needed to fit the sampler
... eval_data = eval_data , # Needed to fit the sampler
... training_config = BaseTrainerConfig ( num_epochs = 200 ) # TrainingConfig to use to fit the sampler
... )Alternativement, vous pouvez lancer le processus de génération de données à partir d'un modèle formé directement avec l'échantillonneur. Par exemple, pour générer de nouvelles données avec votre échantillonneur, exécutez ce qui suit.
> >> from pythae . models import AutoModel
> >> from pythae . samplers import NormalSampler
> >> # Retrieve the trained model
>> > my_trained_vae = AutoModel . load_from_folder (
... 'path/to/your/trained/model'
... )
> >> # Define your sampler
>> > my_samper = NormalSampler (
... model = my_trained_vae
... )
> >> # Generate samples
>> > gen_data = my_samper . sample (
... num_samples = 50 ,
... batch_size = 10 ,
... output_dir = None ,
... return_gen = True
... ) Si vous définissez output_dir sur un chemin spécifique, les images générées seront enregistrées sous forme de fichiers .png nommés 00000000.png , 00000001.png ... Les échantillonneurs peuvent être utilisés avec n'importe quel modèle tant qu'il est adapté. Par exemple, une instance GaussianMixtureSampler peut être utilisée pour générer à partir de n'importe quel modèle, mais un VAMPSampler ne sera utilisable qu'avec un modèle VAMP . Vérifiez ici pour voir lesquels s'appliquent à votre modèle. Soyez prudent que certains échantillonneurs tels que le GaussianMixtureSampler , par exemple, devront être ajustés en appelant la méthode fit avant de l'utiliser. Vous trouverez ci-dessous un exemple pour le GaussianMixtureSampler .
> >> from pythae . models import AutoModel
> >> from pythae . samplers import GaussianMixtureSampler , GaussianMixtureSamplerConfig
> >> # Retrieve the trained model
>> > my_trained_vae = AutoModel . load_from_folder (
... 'path/to/your/trained/model'
... )
> >> # Define your sampler
... gmm_sampler_config = GaussianMixtureSamplerConfig (
... n_components = 10
... )
> >> my_samper = GaussianMixtureSampler (
... sampler_config = gmm_sampler_config ,
... model = my_trained_vae
... )
> >> # fit the sampler
>> > gmm_sampler . fit ( train_dataset )
> >> # Generate samples
>> > gen_data = my_samper . sample (
... num_samples = 50 ,
... batch_size = 10 ,
... output_dir = None ,
... return_gen = True
... )Pythae vous offre la possibilité de définir vos propres réseaux de neurones dans les modèles VAE. Par exemple, disons que vous souhaitez former un Wassertstein AE avec un encodeur et un décodeur spécifiques, vous pouvez effectuer ce qui suit:
> >> from pythae . models . nn import BaseEncoder , BaseDecoder
> >> from pythae . models . base . base_utils import ModelOutput
> >> class My_Encoder ( BaseEncoder ):
... def __init__ ( self , args = None ): # Args is a ModelConfig instance
... BaseEncoder . __init__ ( self )
... self . layers = my_nn_layers ()
...
... def forward ( self , x : torch . Tensor ) -> ModelOutput :
... out = self . layers ( x )
... output = ModelOutput (
... embedding = out # Set the output from the encoder in a ModelOutput instance
... )
... return output
...
... class My_Decoder ( BaseDecoder ):
... def __init__ ( self , args = None ):
... BaseDecoder . __init__ ( self )
... self . layers = my_nn_layers ()
...
... def forward ( self , x : torch . Tensor ) -> ModelOutput :
... out = self . layers ( x )
... output = ModelOutput (
... reconstruction = out # Set the output from the decoder in a ModelOutput instance
... )
... return output
...
> >> my_encoder = My_Encoder ()
> >> my_decoder = My_Decoder ()Et maintenant construire le modèle
> >> from pythae . models import WAE_MMD , WAE_MMD_Config
> >> # Set up the model configuration
>> > my_wae_config = model_config = WAE_MMD_Config (
... input_dim = ( 1 , 28 , 28 ),
... latent_dim = 10
... )
...
> >> # Build the model
>> > my_wae_model = WAE_MMD (
... model_config = my_wae_config ,
... encoder = my_encoder , # pass your encoder as argument when building the model
... decoder = my_decoder # pass your decoder as argument when building the model
... ) Note importante 1 : Pour tous les modèles basés sur AE (AE, WAE, RAE_L2, RAE_GP), l'encodeur et le décodeur doivent retourner une instance ModelOutput . Pour l'encodeur, l'instance ModelOutput doit contenir les embreeurs sous la embedding de la clé. Pour le décodeur, l'instance ModelOutput doit contenir les reconstructions sous la reconstruction clé.
Note importante 2 : Pour tous les modèles à base de Vae (Vae, Betavae, Iwae, HVAE, VAMP, Rhvae), le coder et le décodeur doivent retourner une instance ModelOutput . Pour l'encodeur, l'instance ModelOutput doit contenir les matrices de covariance de emblemage et de log (de forme de forme batch_size x latent_space_dim) sous la clé embedding la clé et la clé log_covariance . Pour le décodeur, l'instance ModelOutput doit contenir les reconstructions sous la reconstruction clé.
Vous pouvez également trouver des architectures de réseau de neurones prédéfinies pour les ensembles de données les plus courants ( c'est-à-dire MNIST, Cifar, Celeba ...) qui peuvent être chargés comme suit
> >> from pythae . models . nn . benchmark . mnist import (
... Encoder_Conv_AE_MNIST , # For AE based model (only return embeddings)
... Encoder_Conv_VAE_MNIST , # For VAE based model (return embeddings and log_covariances)
... Decoder_Conv_AE_MNIST
... )Remplacez MNIST par Cifar ou Celeba pour accéder à d'autres filets neuronaux.
Pythae À partir de v0.1.0 , Pythae prend désormais en charge la formation distribuée à l'aide du DDP de Pytorch. Il vous permet de former votre VAE préféré plus rapidement et sur un ensemble de données plus grand en utilisant une formation multi-GPU et / ou multi-nœuds.
Pour ce faire, vous pouvez créer un script Python qui sera ensuite lancé par un lanceur (comme srun sur un cluster). La seule chose qui est nécessaire dans le script est de spécifier certains éléments par rapport à l'environnement distribué (comme le nombre de nœuds / GPU) directement dans la configuration de la formation comme suit
> >> training_config = BaseTrainerConfig (
... num_epochs = 10 ,
... learning_rate = 1e-3 ,
... per_device_train_batch_size = 64 ,
... per_device_eval_batch_size = 64 ,
... train_dataloader_num_workers = 8 ,
... eval_dataloader_num_workers = 8 ,
... dist_backend = "nccl" , # distributed backend
... world_size = 8 # number of gpus to use (n_nodes x n_gpus_per_node),
... rank = 5 # global gpu id,
... local_rank = 1 # gpu id within a node,
... master_addr = "localhost" # master address,
... master_port = "12345" # master port,
... ) Voir cet exemple de script qui définit une formation VQVAE multi-GPU sur ImageNet DataSet. Veuillez noter que la façon dont les variables d'environnement distribuées ( world_size , rank ...) sont récupérées peuvent être spécifiques au cluster et au lanceur que vous utilisez.
Vous trouverez ci-dessous les temps de formation pour un vecteur quantifié VAE (VQ-VAE) avec Pythae pour 100 époques sur MNIST sur V100 16GB GPU (S), pour 50 époques sur FFHQ (images 1024x1024) et pour 20 époques sur ImageNet-1k sur V100 32GB GPU (S).
| Données de formation | 1 GPU | 4 GPU | GPU 2x4 | |
|---|---|---|---|---|
| MNIST (VQ-VAE) | Images 28x28 (50k) | 235.18 s | 62,00 s | 35,86 s |
| FFHQ 1024X1024 (VQVAE) | 1024x1024 Images RVB (60K) | 19h 1 min | 5h 6min | 2h 37min |
| ImageNet-1k 128x128 (VQVAE) | 128x128 Images RVB (~ 1,2 m) | 6h 25min | 1h 41min | 51 minutes 26S |
Pour chaque ensemble de données, nous fournissons les scripts d'analyse comparative ici
Pythae vous permet également de partager vos modèles sur le hub Huggingface. Pour ce faire, vous avez besoin:
huggingface_hub a été installé dans votre Env virtual. Sinon, vous pouvez l'installer avec $ python -m pip install huggingface_hub
$ huggingface-cli login
Tout modèle Pythae peut être facilement téléchargé en utilisant la méthode push_to_hf_hub
> >> my_vae_model . push_to_hf_hub ( hf_hub_path = "your_hf_username/your_hf_hub_repo" ) Remarque: Si your_hf_hub_repo existe déjà et n'est pas vide, les fichiers seront remplacés. Dans le cas, le repo your_hf_hub_repo n'existe pas, un dossier ayant le même nom sera créé.
De manière équivalente, vous pouvez télécharger ou recharger n'importe quel modèle de Pythae directement à partir du centre en utilisant la méthode load_from_hf_hub
> >> from pythae . models import AutoModel
> >> my_downloaded_vae = AutoModel . load_from_hf_hub ( hf_hub_path = "path_to_hf_repo" )wandb ?Pythae intègre également l'outil de suivi de l'expérience WANDB permettant aux utilisateurs de stocker leurs configurations, de surveiller leurs formations et de comparer une interface graphique. Pour pouvoir utiliser cette fonctionnalité, vous aurez besoin:
wandb a été installé dans votre Env virtual. Sinon, vous pouvez l'installer avec $ pip install wandb
$ wandb login
WandbCallback Le lancement d'une surveillance d'expérience avec wandb dans Pythae est assez simple. La seule chose qu'un utilisateur doit faire est de créer une instance WandbCallback ...
> >> # Create you callback
>> > from pythae . trainers . training_callbacks import WandbCallback
> >> callbacks = [] # the TrainingPipeline expects a list of callbacks
> >> wandb_cb = WandbCallback () # Build the callback
> >> # SetUp the callback
>> > wandb_cb . setup (
... training_config = your_training_config , # training config
... model_config = your_model_config , # model config
... project_name = "your_wandb_project" , # specify your wandb project
... entity_name = "your_wandb_entity" , # specify your wandb entity
... )
> >> callbacks . append ( wandb_cb ) # Add it to the callbacks list ... puis passez-le au TrainingPipeline .
> >> pipeline = TrainingPipeline (
... training_config = config ,
... model = model
... )
> >> pipeline (
... train_data = train_dataset ,
... eval_data = eval_dataset ,
... callbacks = callbacks # pass the callbacks to the TrainingPipeline and you are done!
... )
> >> # You can log to https://wandb.ai/your_wandb_entity/your_wandb_project to monitor your trainingVoir le tutoriel détaillé
mlflow ?Pythae intègre également l'outil de suivi de l'expérience MLFlow permettant aux utilisateurs de stocker leurs configurations, de surveiller leurs formations et de comparer une interface graphique. Pour pouvoir utiliser cette fonctionnalité, vous aurez besoin:
mlfow a installé dans votre Env virtual. Sinon, vous pouvez l'installer avec $ pip install mlflow
MLFlowCallback Le lancement d'une surveillance d'expérience avec mlfow dans Pythae est assez simple. La seule chose qu'un utilisateur doit faire est de créer une instance MLFlowCallback ...
> >> # Create you callback
>> > from pythae . trainers . training_callbacks import MLFlowCallback
> >> callbacks = [] # the TrainingPipeline expects a list of callbacks
> >> mlflow_cb = MLFlowCallback () # Build the callback
> >> # SetUp the callback
>> > mlflow_cb . setup (
... training_config = your_training_config , # training config
... model_config = your_model_config , # model config
... run_name = "mlflow_cb_example" , # specify your mlflow run
... )
> >> callbacks . append ( mlflow_cb ) # Add it to the callbacks list ... puis passez-le au TrainingPipeline .
> >> pipeline = TrainingPipeline (
... training_config = config ,
... model = model
... )
> >> pipeline (
... train_data = train_dataset ,
... eval_data = eval_dataset ,
... callbacks = callbacks # pass the callbacks to the TrainingPipeline and you are done!
... ) Vous pouvez visualiser votre métrique en exécutant ce qui suit dans le répertoire où le ./mlruns
$ mlflow ui Voir le tutoriel détaillé
comet_ml ?Pythae intègre également l'outil de suivi de l'expérience Comet_ML permettant aux utilisateurs de stocker leurs configurations, de surveiller leurs formations et de comparer une interface graphique. Pour pouvoir utiliser cette fonctionnalité, vous aurez besoin:
comet_ml a été installé dans votre Env virtual. Sinon, vous pouvez l'installer avec $ pip install comet_ml
CometCallback Le lancement d'une surveillance d'expérience avec comet_ml dans Pythae est assez simple. La seule chose qu'un utilisateur doit faire est de créer une instance CometCallback ...
> >> # Create you callback
>> > from pythae . trainers . training_callbacks import CometCallback
> >> callbacks = [] # the TrainingPipeline expects a list of callbacks
> >> comet_cb = CometCallback () # Build the callback
> >> # SetUp the callback
>> > comet_cb . setup (
... training_config = training_config , # training config
... model_config = model_config , # model config
... api_key = "your_comet_api_key" , # specify your comet api-key
... project_name = "your_comet_project" , # specify your wandb project
... #offline_run=True, # run in offline mode
... #offline_directory='my_offline_runs' # set the directory to store the offline runs
... )
> >> callbacks . append ( comet_cb ) # Add it to the callbacks list ... puis passez-le au TrainingPipeline .
> >> pipeline = TrainingPipeline (
... training_config = config ,
... model = model
... )
> >> pipeline (
... train_data = train_dataset ,
... eval_data = eval_dataset ,
... callbacks = callbacks # pass the callbacks to the TrainingPipeline and you are done!
... )
> >> # You can log to https://comet.com/your_comet_username/your_comet_project to monitor your trainingVoir le tutoriel détaillé
Pour vous aider à comprendre le fonctionnement du Pythae et comment vous pouvez former vos modèles avec cette bibliothèque, nous fournissons également des tutoriels:
make_your_own_autoencoder.ipynb vous montre comment transmettre vos propres réseaux aux modèles implémentés dans Pythae
custom_dataset.ipynb vous montre comment utiliser des ensembles de données personnalisés avec l'un des modèles implémentés dans Pythae
hf_hub_models_sharing.ipynb vous montre comment télécharger et télécharger des modèles pour le hub huggingface
wandb_experiment_monitoring.ipynb vous montre comment surveiller vos expériences à l'aide wandb
mlflow_experiment_monitoring.ipynb vous montre comment surveiller vos expériences en utilisant mlflow
comet_experiment_monitoring.ipynb vous montre comment surveiller vos expériences à l'aide comet_ml
Le dossier Models_training fournit des cahiers montrant comment former chaque modèle implémenté et comment en goûter à l'aide de pythae.samplers .
Le dossier des scripts fournit en particulier un exemple de script de formation pour former les modèles sur les ensembles de données de référence (MNIST, CIFAR10, Celeba ...)
Si vous rencontrez des problèmes lors de l'exécution du code ou demandez de nouvelles fonctionnalités / modèles à implémenter, veuillez ouvrir un problème sur GitHub.
Vous souhaitez contribuer à cette bibliothèque en ajoutant un modèle, un échantillonneur ou simplement corriger un bug? C'est génial! Merci! Veuillez consulter contribution.md pour suivre les principales directives de contribution.
Voyons d'abord les échantillons reconstruits prélevés dans l'ensemble d'évaluation.
| Modèles | MNIST | Célèbre |
|---|---|---|
| Évaluation des données |  |  |
| Ae |  |  |
| Vae |  |  |
| Bêta-vae |  |  |
| Vae lin nf |  |  |
| Vae iaf |  |  |
| Bêta-vae désactivée |  |  |
| Facteur |  |  |
| Betatcvae |  |  |
| Iwae |  |  |
| MSSSIM_VAE |  |  |
| Wae |  |  |
| Info vae |  |  |
| VAMP |  |  |
| Svae |  |  |
| Adversarial_ae |  |  |
| Vae_gan |  |  |
| Vqvae |  |  |
| Hvae |  |  |
| Rae_l2 |  |  |
| Rae_gp |  |  |
| Riemannien Hamiltonian Vae (Rhvae) |  |  |
Ici, nous montrons les échantillons générés en utilisant chaque modèle implémenté dans la bibliothèque et différents échantillonneurs.
| Modèles | MNIST | Célèbre |
|---|---|---|
| AE + GaussianMixturesampler |  |  |
| Vae + Normalsampler |  |  |
| Vae + GaussianMixturesampler |  |  |
| Vae + twostagevaesampler |  |  |
| VAE + MAFSAMPLE |  |  |
| Bêta-vae + Normalsampler | 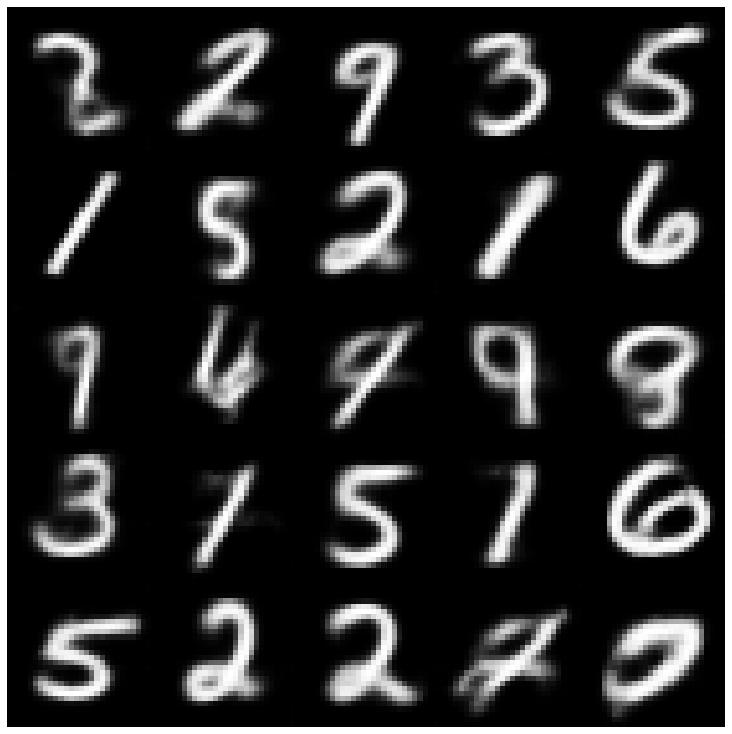 |  |
| Vae lin nf + normalsampler |  |  |
| Vae iaf + Normalsampler |  |  |
| Beta-Vae + Normalsampler en désordre |  |  |
| Factorvae + Normalsampler |  |  |
| Betatcvae + Normalsampler |  |  |
| Iwae + échantillonneur normal |  |  |
| MSSSIM_VAE + Normalsampler |  |  |
| Wae + normalsampler |  |  |
| Info Vae + Normalsampler |  |  |
| Svae + hypershereuniformesampleur |  |  |
| Vamp + vampsampler |  |  |
| Adversarial_ae + Normalsampler |  |  |
| Vaegan + Normalsampler |  |  |
| Vqvae + mafsampleur |  |  |
| Hvae + normalsampler |  |  |
| RAE_L2 + GAUSSIANMIXTRESAMPLER |  |  |
| RAE_GP + GAUSSIANMIXTRESAMPLER |  |  |
| Riemannien Hamiltonian Vae (Rhvae) + Rhvae Sampler |  |  |
Si vous trouvez ce travail utile ou l'utilisez dans vos recherches, veuillez envisager de nous citer
@inproceedings { chadebec2022pythae ,
author = { Chadebec, Cl'{e}ment and Vincent, Louis and Allassonniere, Stephanie } ,
booktitle = { Advances in Neural Information Processing Systems } ,
editor = { S. Koyejo and S. Mohamed and A. Agarwal and D. Belgrave and K. Cho and A. Oh } ,
pages = { 21575--21589 } ,
publisher = { Curran Associates, Inc. } ,
title = { Pythae: Unifying Generative Autoencoders in Python - A Benchmarking Use Case } ,
volume = { 35 } ,
year = { 2022 }
}

