benchmark_VAE
Pythae 0.1.2
ドキュメント
このライブラリは、統一された実装の下で最も一般的な(変分)自動エンコーダーモデルの一部を実装しています。特に、同じ自動エンコードニューラルネットワークアーキテクチャでモデルをトレーニングすることにより、ベンチマーク実験と比較を実行する可能性を提供します。この機能により、独自の自動エンコーダーを使用すると、独自のデータと独自のエンコーダーおよびデコーダーニューラルネットワークでこれらのモデルのいずれかをトレーニングできます。 Wandb、Mlflow、Comet-MLなどの実験監視ツールを統合しますか?また、ハグFaceハブからモデルの共有と読み込みを許可しますか?コードの数行で。
ニュース?
V0.1.0の時点で、 Pythae PytorchのDDPを使用した分散トレーニングをサポートしています。これで、お気に入りのVAEをより速く、より大きなデータセットでトレーニングできるようになりました。スピードアップベンチマークをご覧ください。
wandb /実験追跡mlflowでの実験追跡comet_mlでの実験追跡このライブラリの最新の安定したリリースをインストールするには、 pipを使用して以下を実行します
$ pip install pythaeこのライブラリの最新のgithubバージョンをインストールするには、 pipを使用して以下を実行します
$ pip install git+https://github.com/clementchadebec/benchmark_VAE.gitまたは、GitHub Repoをクローンして、テスト、チュートリアル、スクリプトにアクセスすることができます。
$ git clone https://github.com/clementchadebec/benchmark_VAE.gitライブラリをインストールします
$ cd benchmark_VAE
$ pip install -e . 以下は、現在ライブラリに実装されているモデルのリストです。
| モデル | トレーニングの例 | 紙 | 公式実装 |
|---|---|---|---|
| 自動エンコーダー(AE) | |||
| 変分自動エンコーダー(VAE) | リンク | ||
| ベータ変動自動エンコーダー(ベータヴェ) | リンク | ||
| 線形正規化フローを備えたvae(vae_linnf) | リンク | ||
| 逆の自己網性フローを持つvae(vae_iaf) | リンク | リンク | |
| direnentangled beta variational autoencoder(disentangledbetavae) | リンク | ||
| 因数分解による解放(因子) | リンク | ||
| beta-tc-vae(betatcvae) | リンク | リンク | |
| 重要性の加重オートエンコーダー(IWAE) | リンク | リンク | |
| 重要性の重み付きオートエンコーダー(miwae)を掛ける | リンク | ||
| 部分的に重要な加重オートエンコーダー(PIWAE) | リンク | ||
| 組み合わせの重要性加重オートエンコーダー(Ciwae) | リンク | ||
| 知覚メトリックの類似性を持つvae(msssim_vae) | リンク | ||
| wasserstein autoencoder(wae) | リンク | リンク | |
| 情報変動自動エンコーダー(infovae_mmd) | リンク | ||
| Vamp Autoencoder(Vamp) | リンク | リンク | |
| hyperspherical vae(svae) | リンク | リンク | |
| ポアンカレディスクvae(ポインカレバエ) | リンク | リンク | |
| 敵対的な自動エンコーダー(Anversarial_ae) | リンク | ||
| 変分自動エンコーダーガン(Vaegan)? | リンク | リンク | |
| ベクター量子化されたvae(vqvae) | リンク | リンク | |
| ハミルトニアンvae(hvae) | リンク | リンク | |
| L2デコーダーパラマ(RAE_L2)を備えた正規化されたAE | リンク | リンク | |
| 勾配ペナルティを備えた正規化されたAE(RAE_GP) | リンク | リンク | |
| Riemannian Hamiltonian Vae(rhvae) | リンク | リンク | |
| 階層的な残留量子化(HRQVAE) | リンク | リンク |
前述のすべてのモデルの再構成と生成の結果を参照してください
以下は、現在ライブラリに実装されているモデルのリストです。
| サンプラー | モデル | 紙 | 公式実装 |
|---|---|---|---|
| 通常の事前(NormalSampler) | すべてのモデル | リンク | |
| ガウス混合物(gaussianmixturesampler) | すべてのモデル | リンク | リンク |
| 2ステージVAEサンプラー(Twostagevaesampler) | すべてのVAEベースのモデル | リンク | リンク |
| ユニット球体の均一なサンプラー(Hypersphereuniformsampler) | svae | リンク | リンク |
| ポアンカレディスクサンプラー(poincaredisksksampler) | ポインカレヴェ | リンク | リンク |
| Vamp Prior Sampler(vampsampler) | ヴァンプ | リンク | リンク |
| マニホールドサンプラー(rhvaesampler) | rhvae | リンク | リンク |
| マスクされた自己回帰フローサンプラー(Mafsampler) | すべてのモデル | リンク | リンク |
| 逆自己回帰フローサンプラー(IAFSAMPLER) | すべてのモデル | リンク | リンク |
| pixelcnn(pixelcnnsampler) | vqvae | リンク |
公式コードがリリースされたとき、または論文の実験セクションに関する十分な詳細が利用可能なときに、元の出版物に提示されたいくつかの結果を再現することにより、実装を検証します。詳細については、再現性を参照してください。
モデルトレーニングを開始するには、 TrainingPipelineインスタンスを呼び出すだけです。
> >> from pythae . pipelines import TrainingPipeline
> >> from pythae . models import VAE , VAEConfig
> >> from pythae . trainers import BaseTrainerConfig
> >> # Set up the training configuration
>> > my_training_config = BaseTrainerConfig (
... output_dir = 'my_model' ,
... num_epochs = 50 ,
... learning_rate = 1e-3 ,
... per_device_train_batch_size = 200 ,
... per_device_eval_batch_size = 200 ,
... train_dataloader_num_workers = 2 ,
... eval_dataloader_num_workers = 2 ,
... steps_saving = 20 ,
... optimizer_cls = "AdamW" ,
... optimizer_params = { "weight_decay" : 0.05 , "betas" : ( 0.91 , 0.995 )},
... scheduler_cls = "ReduceLROnPlateau" ,
... scheduler_params = { "patience" : 5 , "factor" : 0.5 }
... )
> >> # Set up the model configuration
>> > my_vae_config = model_config = VAEConfig (
... input_dim = ( 1 , 28 , 28 ),
... latent_dim = 10
... )
> >> # Build the model
>> > my_vae_model = VAE (
... model_config = my_vae_config
... )
> >> # Build the Pipeline
>> > pipeline = TrainingPipeline (
... training_config = my_training_config ,
... model = my_vae_model
... )
> >> # Launch the Pipeline
>> > pipeline (
... train_data = your_train_data , # must be torch.Tensor, np.array or torch datasets
... eval_data = your_eval_data # must be torch.Tensor, np.array or torch datasets
... )トレーニングの終了時に、最適なモデルの重み、モデル構成、トレーニング構成はmy_model/MODEL_NAME_training_YYYY-MM-DD_hh-mm-ss ( my_modelがBaseTrainerConfigのoutput_dir引数である)で利用可能なfinal_modelフォルダーに保存されます。さらに、 steps_saving引数を特定の値に設定すると、Epoch Kで最適なモデルの重み、オプティマイザー、スケジューラ、構成、およびトレーニング構成を含むcheckpoint_epoch_kという名前のフォルダーもmy_model/MODEL_NAME_training_YYYY-MM-DD_hh-mm-ss 。
また、ここでは、ベンチマークデータセット(MNIST、CIFAR10、CELEBA ...)でモデルをトレーニングするために使用できるトレーニングスクリプトの例を提供します。スクリプトは、次のコマンドラインで起動できます
python training.py --dataset mnist --model_name ae --model_config ' configs/ae_config.json ' --training_config ' configs/base_training_config.json 'このスクリプトの詳細については、readme.mdを参照してください
GenerationPipelineを使用します訓練されたモデルからデータ生成を起動する最も簡単な方法は、Pythaeで提供される組み込みのGenerationPipelineを使用することです。 MAFSamplerを使用して100個のサンプルを生成したいとすると、1)トレーニングモデルをrelaod、2)サンプラーの構成を定義し、3)次のようにGenerationPipelineを作成して起動する
> >> from pythae . models import AutoModel
> >> from pythae . samplers import MAFSamplerConfig
> >> from pythae . pipelines import GenerationPipeline
> >> # Retrieve the trained model
>> > my_trained_vae = AutoModel . load_from_folder (
... 'path/to/your/trained/model'
... )
> >> my_sampler_config = MAFSamplerConfig (
... n_made_blocks = 2 ,
... n_hidden_in_made = 3 ,
... hidden_size = 128
... )
> >> # Build the pipeline
>> > pipe = GenerationPipeline (
... model = my_trained_vae ,
... sampler_config = my_sampler_config
... )
> >> # Launch data generation
>> > generated_samples = pipe (
... num_samples = args . num_samples ,
... return_gen = True , # If false returns nothing
... train_data = train_data , # Needed to fit the sampler
... eval_data = eval_data , # Needed to fit the sampler
... training_config = BaseTrainerConfig ( num_epochs = 200 ) # TrainingConfig to use to fit the sampler
... )または、訓練を受けたモデルからサンプラーを使用して直接データ生成プロセスを起動することもできます。たとえば、サンプラーで新しいデータを生成するには、以下を実行します。
> >> from pythae . models import AutoModel
> >> from pythae . samplers import NormalSampler
> >> # Retrieve the trained model
>> > my_trained_vae = AutoModel . load_from_folder (
... 'path/to/your/trained/model'
... )
> >> # Define your sampler
>> > my_samper = NormalSampler (
... model = my_trained_vae
... )
> >> # Generate samples
>> > gen_data = my_samper . sample (
... num_samples = 50 ,
... batch_size = 10 ,
... output_dir = None ,
... return_gen = True
... ) output_dir特定のパスに設定すると、生成された画像は00000000.png 、 00000001.pngという名前の.pngファイルとして保存されます...サンプラーは、任意のモデルで適している限り使用できます。たとえば、 GaussianMixtureSamplerインスタンスを使用して任意のモデルから生成することができますが、 VAMPSampler VAMPモデルでのみ使用できます。モデルに適用されるものを確認するには、こちらを確認してください。 GaussianMixtureSamplerなどの一部のサンプラーは、使用する前にfitメソッドを呼び出すことで取り付けられる必要があることに注意してください。以下は、 GaussianMixtureSamplerの例です。
> >> from pythae . models import AutoModel
> >> from pythae . samplers import GaussianMixtureSampler , GaussianMixtureSamplerConfig
> >> # Retrieve the trained model
>> > my_trained_vae = AutoModel . load_from_folder (
... 'path/to/your/trained/model'
... )
> >> # Define your sampler
... gmm_sampler_config = GaussianMixtureSamplerConfig (
... n_components = 10
... )
> >> my_samper = GaussianMixtureSampler (
... sampler_config = gmm_sampler_config ,
... model = my_trained_vae
... )
> >> # fit the sampler
>> > gmm_sampler . fit ( train_dataset )
> >> # Generate samples
>> > gen_data = my_samper . sample (
... num_samples = 50 ,
... batch_size = 10 ,
... output_dir = None ,
... return_gen = True
... )Pythaeは、VAEモデル内で独自のニューラルネットワークを定義する可能性を提供します。たとえば、特定のエンコーダーとデコーダーを使用してWassertstein AEをトレーニングしたいとします。次のことを行うことができます。
> >> from pythae . models . nn import BaseEncoder , BaseDecoder
> >> from pythae . models . base . base_utils import ModelOutput
> >> class My_Encoder ( BaseEncoder ):
... def __init__ ( self , args = None ): # Args is a ModelConfig instance
... BaseEncoder . __init__ ( self )
... self . layers = my_nn_layers ()
...
... def forward ( self , x : torch . Tensor ) -> ModelOutput :
... out = self . layers ( x )
... output = ModelOutput (
... embedding = out # Set the output from the encoder in a ModelOutput instance
... )
... return output
...
... class My_Decoder ( BaseDecoder ):
... def __init__ ( self , args = None ):
... BaseDecoder . __init__ ( self )
... self . layers = my_nn_layers ()
...
... def forward ( self , x : torch . Tensor ) -> ModelOutput :
... out = self . layers ( x )
... output = ModelOutput (
... reconstruction = out # Set the output from the decoder in a ModelOutput instance
... )
... return output
...
> >> my_encoder = My_Encoder ()
> >> my_decoder = My_Decoder ()そして今、モデルを構築します
> >> from pythae . models import WAE_MMD , WAE_MMD_Config
> >> # Set up the model configuration
>> > my_wae_config = model_config = WAE_MMD_Config (
... input_dim = ( 1 , 28 , 28 ),
... latent_dim = 10
... )
...
> >> # Build the model
>> > my_wae_model = WAE_MMD (
... model_config = my_wae_config ,
... encoder = my_encoder , # pass your encoder as argument when building the model
... decoder = my_decoder # pass your decoder as argument when building the model
... )重要な注意1 :すべてのAEベースのモデル(AE、WAE、RAE_L2、RAE_GP)について、エンコーダとデコーダーの両方がModelOutputインスタンスを返す必要があります。エンコーダの場合、 ModelOutputインスタンスには、キーembeddingの下に埋め込みが含まれている必要があります。デコーダーの場合、 ModelOutputインスタンスには、キーreconstructionの下に再構成を含める必要があります。
重要な注2 :すべてのVaeベースのモデル(Vae、Betavae、Iwae、Hvae、Vamp、Rhvae)について、エンコーダーとデコーダーの両方がModelOutputインスタンスを返す必要があります。エンコーダーの場合、 ModelOutputインスタンスには、キーembeddingおよびlog_covarianceキーの下に、それぞれbatch_size x latent_space_dimのログ -コバリケーションマトリックスが含まれている必要があります。デコーダーの場合、 ModelOutputインスタンスには、キーreconstructionの下に再構成を含める必要があります。
また、次のように読み込むことができる最も一般的なデータセット(すなわち、cifar、celeba ...)の事前定義されたニューラルネットワークアーキテクチャを見つけることができます。
> >> from pythae . models . nn . benchmark . mnist import (
... Encoder_Conv_AE_MNIST , # For AE based model (only return embeddings)
... Encoder_Conv_VAE_MNIST , # For VAE based model (return embeddings and log_covariances)
... Decoder_Conv_AE_MNIST
... )MnistをCifarまたはCelebaに置き換えて、他のニューラルネットにアクセスします。
Pythaeを使用した分散トレーニングv0.1.0の時点で、PythaeはPytorchのDDPを使用した分散トレーニングをサポートしています。マルチGPUおよび/またはマルチノードトレーニングを使用して、お気に入りのVAEをより速く、より大きなデータセットでトレーニングすることができます。
そのために、ランチャー(クラスター上のsrunなど)が起動するPythonスクリプトを作成できます。スクリプトで必要な唯一のことは、次のように、トレーニング構成の分散環境(ノード/GPUの数など)に関連するいくつかの要素を指定することです。
> >> training_config = BaseTrainerConfig (
... num_epochs = 10 ,
... learning_rate = 1e-3 ,
... per_device_train_batch_size = 64 ,
... per_device_eval_batch_size = 64 ,
... train_dataloader_num_workers = 8 ,
... eval_dataloader_num_workers = 8 ,
... dist_backend = "nccl" , # distributed backend
... world_size = 8 # number of gpus to use (n_nodes x n_gpus_per_node),
... rank = 5 # global gpu id,
... local_rank = 1 # gpu id within a node,
... master_addr = "localhost" # master address,
... master_port = "12345" # master port,
... ) Imagenet DatasetでマルチGPU VQVAEトレーニングを定義するこの例を参照してください。分散環境変数( world_size 、 rank ...)の回復方法は、使用するクラスターとランチャーに固有の場合があることに注意してください。
以下は、V100 16GB GPU(s)のMnistの100エポック、FFHQの50エポック(1024x1024画像)、およびV100 32GB GPU(s)のイメージェネット1Kでの20エポック(s)のPythaeを使用したベクトル量子化されたvae(VQ-vae)のトレーニング時間を示しています。
| データを訓練します | 1 GPU | 4 GPU | 2x4 GPU | |
|---|---|---|---|---|
| mnist(vq-vae) | 28x28画像(50k) | 235.18 s | 62.00秒 | 35.86 s |
| FFHQ 1024x1024(VQVAE) | 1024x1024 RGB画像(60k) | 19h 1分 | 5H 6分 | 2H 37分 |
| imagenet-1k 128x128(vqvae) | 128x128 RGB画像(〜1.2m) | 6H 25分 | 1H 41分 | 51分26秒 |
各データセットについて、ここでベンチマークスクリプトを提供します
Pythaeを使用すると、モデルをHuggingface Hubで共有することもできます。そうするには、次のことが必要です。
huggingface_hub 。そうでない場合は、一緒にインストールできます $ python -m pip install huggingface_hub
$ huggingface-cli login
Pythaeモデルは、メソッドpush_to_hf_hubを使用して簡単にアップロードできます
> >> my_vae_model . push_to_hf_hub ( hf_hub_path = "your_hf_username/your_hf_hub_repo" )注: your_hf_hub_repoが既に存在し、空でない場合、ファイルはオーバーライドされます。 Repo your_hf_hub_repoが存在しない場合、同じ名前を持つフォルダーが作成されます。
同等に、メソッドload_from_hf_hubを使用して、Pythaeのモデルをハブから直接ダウンロードまたはリロードできます
> >> from pythae . models import AutoModel
> >> my_downloaded_vae = AutoModel . load_from_hf_hub ( hf_hub_path = "path_to_hf_repo" )wandbでの実験を監視していますか?Pythaeは、実験追跡ツールWandBを統合して、ユーザーが構成を保存し、トレーニングを監視し、グラフィックインターフェイスを介した実行を比較できるようにします。この機能を使用できるようにするには:
wandb 。そうでない場合は、一緒にインストールできます $ pip install wandb
$ wandb login
WandbCallbackを作成しますPythaeでwandbを使用して実験監視を開始するのは非常に簡単です。ユーザーがする必要がある唯一のことは、 WandbCallbackインスタンスを作成することです...
> >> # Create you callback
>> > from pythae . trainers . training_callbacks import WandbCallback
> >> callbacks = [] # the TrainingPipeline expects a list of callbacks
> >> wandb_cb = WandbCallback () # Build the callback
> >> # SetUp the callback
>> > wandb_cb . setup (
... training_config = your_training_config , # training config
... model_config = your_model_config , # model config
... project_name = "your_wandb_project" , # specify your wandb project
... entity_name = "your_wandb_entity" , # specify your wandb entity
... )
> >> callbacks . append ( wandb_cb ) # Add it to the callbacks list ...そしてそれをTrainingPipelineに渡します。
> >> pipeline = TrainingPipeline (
... training_config = config ,
... model = model
... )
> >> pipeline (
... train_data = train_dataset ,
... eval_data = eval_dataset ,
... callbacks = callbacks # pass the callbacks to the TrainingPipeline and you are done!
... )
> >> # You can log to https://wandb.ai/your_wandb_entity/your_wandb_project to monitor your training詳細なチュートリアルを参照してください
mlflowで実験を監視していますか?Pythaeは、ユーザーが構成を保存し、トレーニングを監視し、グラフィックインターフェイスを介した実行を比較できる実験追跡ツールMLFLOWを統合します。この機能を使用できるようにするには:
mlfow 。そうでない場合は、一緒にインストールできます $ pip install mlflow
MLFlowCallbackの作成Pythaeでmlfowを使用して実験監視を開始するのは非常に簡単です。ユーザーがする必要がある唯一のことは、 MLFlowCallbackインスタンスを作成することです。
> >> # Create you callback
>> > from pythae . trainers . training_callbacks import MLFlowCallback
> >> callbacks = [] # the TrainingPipeline expects a list of callbacks
> >> mlflow_cb = MLFlowCallback () # Build the callback
> >> # SetUp the callback
>> > mlflow_cb . setup (
... training_config = your_training_config , # training config
... model_config = your_model_config , # model config
... run_name = "mlflow_cb_example" , # specify your mlflow run
... )
> >> callbacks . append ( mlflow_cb ) # Add it to the callbacks list ...そしてそれをTrainingPipelineに渡します。
> >> pipeline = TrainingPipeline (
... training_config = config ,
... model = model
... )
> >> pipeline (
... train_data = train_dataset ,
... eval_data = eval_dataset ,
... callbacks = callbacks # pass the callbacks to the TrainingPipeline and you are done!
... ) ./mlrunsがあるディレクトリで以下を実行することにより、メトリックを視覚化できます
$ mlflow ui 詳細なチュートリアルを参照してください
comet_mlで実験を監視していますか?Pythaeはまた、実験追跡ツールcomet_mlを統合して、ユーザーが構成を保存し、トレーニングを監視し、グラフィックインターフェイスを介した実行を比較できるようにします。この機能を使用できるようにするには:
comet_ml 。そうでない場合は、一緒にインストールできます $ pip install comet_ml
CometCallbackの作成pythaeでcomet_mlを使用して実験監視を開始するのは非常に簡単です。ユーザーがする必要がある唯一のことは、 CometCallbackインスタンスを作成することです...
> >> # Create you callback
>> > from pythae . trainers . training_callbacks import CometCallback
> >> callbacks = [] # the TrainingPipeline expects a list of callbacks
> >> comet_cb = CometCallback () # Build the callback
> >> # SetUp the callback
>> > comet_cb . setup (
... training_config = training_config , # training config
... model_config = model_config , # model config
... api_key = "your_comet_api_key" , # specify your comet api-key
... project_name = "your_comet_project" , # specify your wandb project
... #offline_run=True, # run in offline mode
... #offline_directory='my_offline_runs' # set the directory to store the offline runs
... )
> >> callbacks . append ( comet_cb ) # Add it to the callbacks list ...そしてそれをTrainingPipelineに渡します。
> >> pipeline = TrainingPipeline (
... training_config = config ,
... model = model
... )
> >> pipeline (
... train_data = train_dataset ,
... eval_data = eval_dataset ,
... callbacks = callbacks # pass the callbacks to the TrainingPipeline and you are done!
... )
> >> # You can log to https://comet.com/your_comet_username/your_comet_project to monitor your training詳細なチュートリアルを参照してください
Pythaeの仕組みと、このライブラリでモデルをトレーニングする方法を理解するために、チュートリアルも提供します。
making_your_own_autoencoder.ipynbは、Pythaeで実装されているモデルに独自のネットワークを渡す方法を示しています
custom_dataset.ipynbは、pythaeに実装されているモデルのいずれかでカスタムデータセットを使用する方法を示しています
hf_hub_models_sharing.ipynbは
wandb_experiment_monitoring.ipynbは、 wandbを使用して実験を監視する方法を示しています
mlflow_experiment_monitoring.ipynbは、 mlflowを使用して実験を監視する方法を示します
comet_experiment_monitoring.ipynbがcomet_mlを使用して実験を監視する方法を示します
Models_Trainingフォルダーは、実装された各モデルをトレーニングする方法と、 pythae.samplersを使用してそこからサンプリングする方法を示すノートブックを提供します。
スクリプトフォルダーは、特にベンチマークデータセットでモデルをトレーニングするトレーニングスクリプトの例を提供します(MNIST、CIFAR10、CELEBA ...)
コードの実行中に問題が発生している場合や、実装する新しい機能/モデルを要求している場合は、GitHubで問題を開きます。
モデル、サンプラーを追加するか、単にバグを修正して、このライブラリに貢献したいですか?それは素晴らしいです!ありがとう!主な貢献ガイドラインに従うには、Converting.mdを参照してください。
まず、評価セットから取得した再構築されたサンプルを見てみましょう。
| モデル | mnist | セレバ |
|---|---|---|
| 評価データ |  |  |
| ae |  |  |
| vae |  |  |
| ベータヴェ |  |  |
| Vae Lin nf |  |  |
| Vae Iaf |  |  |
| disentangled beta-vae |  |  |
| 因子 |  |  |
| betatcvae |  |  |
| iwae |  |  |
| MSSSIM_VAE |  |  |
| wae |  |  |
| 情報vae |  |  |
| ヴァンプ |  |  |
| svae |  |  |
| 敵対的 |  |  |
| Vae_gan |  |  |
| vqvae |  |  |
| hvae |  |  |
| RAE_L2 |  |  |
| rae_gp |  |  |
| Riemannian Hamiltonian Vae(rhvae) |  |  |
ここでは、ライブラリと異なるサンプラーに実装されている各モデルを使用して生成されたサンプルを表示します。
| モデル | mnist | セレバ |
|---|---|---|
| ae + gaussianmixturesampler |  |  |
| Vae + normalSampler |  |  |
| vae + gaussianmixturesampler |  |  |
| vae + twostagevaesampler |  |  |
| vae + mafsampler |  |  |
| beta-vae + normalSampler | 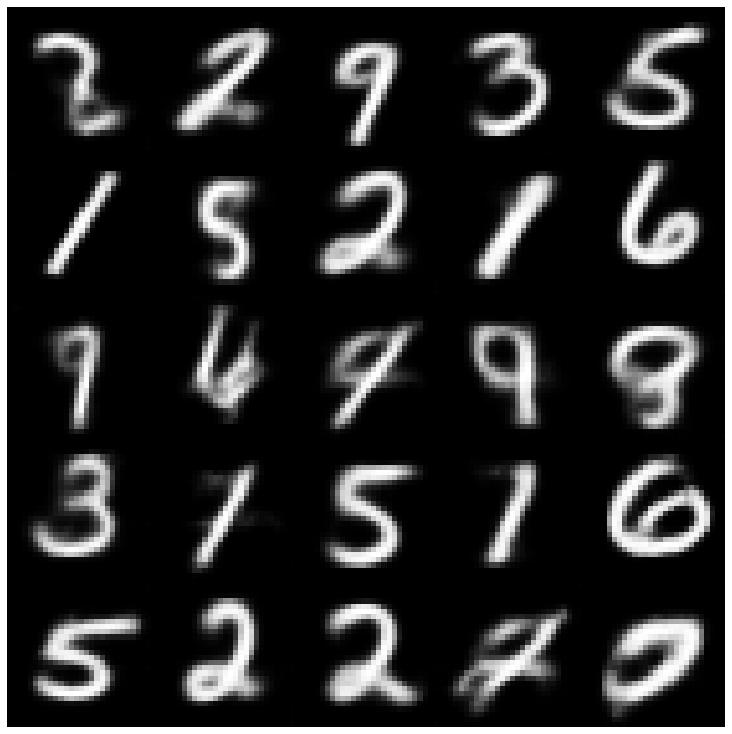 |  |
| Vae Lin NF + NormalSampler |  |  |
| Vae IAF + NormalSampler |  |  |
| 解き放たれたベータvae + normalSampler |  |  |
| FactorVae + NormalSampler |  |  |
| betatcvae + normalSampler |  |  |
| iwae +通常のサンプラー |  |  |
| MSSSIM_VAE + NORMALSAMPLER |  |  |
| wae + normalSampler |  |  |
| 情報vae + normalSampler |  |  |
| Svae + Hypersheririformsampler |  |  |
| vamp + vampsampler |  |  |
| Anversarial_ae + NormalSampler |  |  |
| Vaegan + NormalSampler |  |  |
| vqvae + mafsampler |  |  |
| hvae + normalSampler |  |  |
| RAE_L2 + GAUSSIANMIXTURESAMPLER |  |  |
| rae_gp + gaussianmixturesampler |  |  |
| Riemannian Hamiltonian Vae(Rhvae) + Rhvaeサンプラー |  |  |
この作業が役立つか、研究で使用する場合は、私たちを引用することを検討してください
@inproceedings { chadebec2022pythae ,
author = { Chadebec, Cl'{e}ment and Vincent, Louis and Allassonniere, Stephanie } ,
booktitle = { Advances in Neural Information Processing Systems } ,
editor = { S. Koyejo and S. Mohamed and A. Agarwal and D. Belgrave and K. Cho and A. Oh } ,
pages = { 21575--21589 } ,
publisher = { Curran Associates, Inc. } ,
title = { Pythae: Unifying Generative Autoencoders in Python - A Benchmarking Use Case } ,
volume = { 35 } ,
year = { 2022 }
}

