benchmark_VAE
Pythae 0.1.2
Dokumentasi
Perpustakaan ini mengimplementasikan beberapa model autoencoder yang paling umum (variasional) di bawah implementasi terpadu. Secara khusus, ini memberikan kemungkinan untuk melakukan percobaan dan perbandingan benchmark dengan melatih model dengan arsitektur jaringan saraf autoencoding yang sama. Fitur ini membuat autoencoder Anda sendiri memungkinkan Anda untuk melatih salah satu model ini dengan data Anda sendiri dan encoder sendiri dan jaringan saraf decoder. Ini mengintegrasikan alat pemantauan eksperimen seperti itu, MLFLOW atau COMET-ML? dan memungkinkan berbagi model dan pemuatan dari hub Huggingface? dalam beberapa baris kode.
Berita ?
Pada V0.1.0, Pythae sekarang mendukung pelatihan terdistribusi menggunakan DDP Pytorch. Anda sekarang dapat melatih VAE favorit Anda lebih cepat dan pada set data yang lebih besar, masih dengan beberapa baris kode. Lihat tolok ukur kecepatan kami.
wandb / eksperimen dengan pelacakan mlflow / eksperimen dengan comet_ml Untuk menginstal rilis stabil terbaru dari perpustakaan ini jalankan yang berikut menggunakan pip
$ pip install pythae Untuk menginstal versi GitHub terbaru dari perpustakaan ini, jalankan yang berikut menggunakan pip
$ pip install git+https://github.com/clementchadebec/benchmark_VAE.gitAtau sebagai alternatif Anda dapat mengkloning repo GitHub untuk mengakses tes, tutorial, dan skrip.
$ git clone https://github.com/clementchadebec/benchmark_VAE.gitdan instal perpustakaan
$ cd benchmark_VAE
$ pip install -e . Di bawah ini adalah daftar model yang saat ini diimplementasikan di perpustakaan.
| Model | Contoh pelatihan | Kertas | Implementasi resmi |
|---|---|---|---|
| Autoencoder (AE) | |||
| Autoencoder variasional (VAE) | link | ||
| Autoencoder variasional beta (betavae) | link | ||
| VAE dengan aliran normalisasi linier (VAE_LINNF) | link | ||
| VAE dengan aliran autoregresif terbalik (VAE_IAF) | link | link | |
| Disentangled Beta Variational Autoencoder (DisentangledBetavae) | link | ||
| Disentangling dengan factorising (factorvae) | link | ||
| Beta-tc-vae (betatcvae) | link | link | |
| Pentingnya Autoencoder Berat (IWAE) | link | link | |
| Kalikan Autoencoder Berat (Miwae) | link | ||
| Pentingnya Autoencoder Tertimbang (Piwae) | link | ||
| Kombinasi pentingnya autoencoder tertimbang (ciwae) | link | ||
| VAE dengan kesamaan metrik perseptual (msssim_vae) | link | ||
| Wasserstein Autoencoder (WAE) | link | link | |
| Info autoencoder variasional (infovae_mmd) | link | ||
| VAMP Autoencoder (VAMP) | link | link | |
| VAE Hyperspherical (SVAE) | link | link | |
| Poincaré Disk Vae (Poincarevae) | link | link | |
| Autoencoder permusuhan (adversarial_ae) | link | ||
| Variasional Autoencoder Gan (Vaegan)? | link | link | |
| VECTISTILES VAE (VQVAE) | link | link | |
| Hamiltonian Vae (HVAE) | link | link | |
| AE yang diatur dengan Param Decoder L2 (RAE_L2) | link | link | |
| AE yang diatur dengan penalti gradien (rae_gp) | link | link | |
| Riemannian Hamiltonian Vae (RHVAE) | link | link | |
| Kuantisasi residu hierarkis (HRQVAE) | link | link |
Lihat Hasil Rekonstruksi dan Generasi untuk Semua Model di atas
Di bawah ini adalah daftar model yang saat ini diimplementasikan di perpustakaan.
| Sampler | Model | Kertas | Implementasi resmi |
|---|---|---|---|
| Prior Normal (Normalsampler) | Semua model | link | |
| Campuran Gaussian (GaussianMixturesampler) | Semua model | link | link |
| Two Stage Vae Sampler (TwostageVaesampler) | Semua model berbasis VAE | link | link |
| Unit Sphere Seragam Sampler (HypersphereuniformSampler) | Svae | link | link |
| Poincaré Disk Sampler (Poincaredisksampler) | Poincarevae | link | link |
| Vamp Prior Sampler (Vampsampler) | MENGGODA | link | link |
| Manifold Sampler (Rhvaesampler) | Rhvae | link | link |
| Sampler aliran autoregresif bertopeng (mafsampler) | Semua model | link | link |
| Inverse Autoregressive Flow Sampler (IAFSAMPLER) | Semua model | link | link |
| Pixelcnn (pixelcnnsampler) | VQVAE | link |
Kami memvalidasi implementasi dengan mereproduksi beberapa hasil yang disajikan dalam publikasi asli ketika kode resmi telah dirilis atau ketika rincian yang cukup tentang bagian eksperimental dari makalah tersedia. Lihat Reproduksibilitas untuk detail lebih lanjut.
Untuk meluncurkan pelatihan model, Anda hanya perlu memanggil instance TrainingPipeline .
> >> from pythae . pipelines import TrainingPipeline
> >> from pythae . models import VAE , VAEConfig
> >> from pythae . trainers import BaseTrainerConfig
> >> # Set up the training configuration
>> > my_training_config = BaseTrainerConfig (
... output_dir = 'my_model' ,
... num_epochs = 50 ,
... learning_rate = 1e-3 ,
... per_device_train_batch_size = 200 ,
... per_device_eval_batch_size = 200 ,
... train_dataloader_num_workers = 2 ,
... eval_dataloader_num_workers = 2 ,
... steps_saving = 20 ,
... optimizer_cls = "AdamW" ,
... optimizer_params = { "weight_decay" : 0.05 , "betas" : ( 0.91 , 0.995 )},
... scheduler_cls = "ReduceLROnPlateau" ,
... scheduler_params = { "patience" : 5 , "factor" : 0.5 }
... )
> >> # Set up the model configuration
>> > my_vae_config = model_config = VAEConfig (
... input_dim = ( 1 , 28 , 28 ),
... latent_dim = 10
... )
> >> # Build the model
>> > my_vae_model = VAE (
... model_config = my_vae_config
... )
> >> # Build the Pipeline
>> > pipeline = TrainingPipeline (
... training_config = my_training_config ,
... model = my_vae_model
... )
> >> # Launch the Pipeline
>> > pipeline (
... train_data = your_train_data , # must be torch.Tensor, np.array or torch datasets
... eval_data = your_eval_data # must be torch.Tensor, np.array or torch datasets
... ) Pada akhir pelatihan, bobot model terbaik, konfigurasi model, dan konfigurasi pelatihan disimpan dalam folder final_model yang tersedia di my_model/MODEL_NAME_training_YYYY-MM-DD_hh-mm-ss (dengan my_model menjadi argumen output_dir dari BaseTrainerConfig ). Jika Anda lebih lanjut mengatur argumen steps_saving ke nilai tertentu, folder bernama checkpoint_epoch_k yang berisi bobot model terbaik, pengoptimal, penjadwal, konfigurasi, dan konfigurasi pelatihan di Epoch K juga akan muncul di my_model/MODEL_NAME_training_YYYY-MM-DD_hh-mm-ss .
Kami juga memberikan contoh skrip pelatihan di sini yang dapat digunakan untuk melatih model pada dataset tolok ukur (MNIST, CIFAR10, Celeba ...). Skrip dapat diluncurkan dengan garis perintah berikut
python training.py --dataset mnist --model_name ae --model_config ' configs/ae_config.json ' --training_config ' configs/base_training_config.json 'Lihat readme.md untuk perincian lebih lanjut tentang skrip ini
GenerationPipeline Cara termudah untuk meluncurkan pembuatan data dari model yang terlatih terdiri dari menggunakan GenerationPipeline bawaan yang disediakan di Pythae. Katakanlah Anda ingin menghasilkan 100 sampel menggunakan MAFSampler yang harus Anda lakukan adalah 1) Relaod model terlatih, 2) Tentukan konfigurasi sampler dan 3) buat dan luncurkan GenerationPipeline sebagai berikut
> >> from pythae . models import AutoModel
> >> from pythae . samplers import MAFSamplerConfig
> >> from pythae . pipelines import GenerationPipeline
> >> # Retrieve the trained model
>> > my_trained_vae = AutoModel . load_from_folder (
... 'path/to/your/trained/model'
... )
> >> my_sampler_config = MAFSamplerConfig (
... n_made_blocks = 2 ,
... n_hidden_in_made = 3 ,
... hidden_size = 128
... )
> >> # Build the pipeline
>> > pipe = GenerationPipeline (
... model = my_trained_vae ,
... sampler_config = my_sampler_config
... )
> >> # Launch data generation
>> > generated_samples = pipe (
... num_samples = args . num_samples ,
... return_gen = True , # If false returns nothing
... train_data = train_data , # Needed to fit the sampler
... eval_data = eval_data , # Needed to fit the sampler
... training_config = BaseTrainerConfig ( num_epochs = 200 ) # TrainingConfig to use to fit the sampler
... )Atau, Anda dapat meluncurkan proses pembuatan data dari model terlatih secara langsung dengan sampler. Misalnya, untuk menghasilkan data baru dengan sampler Anda, jalankan yang berikut.
> >> from pythae . models import AutoModel
> >> from pythae . samplers import NormalSampler
> >> # Retrieve the trained model
>> > my_trained_vae = AutoModel . load_from_folder (
... 'path/to/your/trained/model'
... )
> >> # Define your sampler
>> > my_samper = NormalSampler (
... model = my_trained_vae
... )
> >> # Generate samples
>> > gen_data = my_samper . sample (
... num_samples = 50 ,
... batch_size = 10 ,
... output_dir = None ,
... return_gen = True
... ) Jika Anda mengatur output_dir ke jalur tertentu, gambar yang dihasilkan akan disimpan sebagai file .png bernama 00000000.png , 00000001.png ... Sampler dapat digunakan dengan model apa pun selama cocok. Misalnya, instance GaussianMixtureSampler dapat digunakan untuk menghasilkan dari model apa pun tetapi VAMPSampler hanya akan dapat digunakan dengan model VAMP . Periksa di sini untuk melihat mana yang berlaku untuk model Anda. Bersikaplah berhati -hati bahwa beberapa sampler seperti GaussianMixtureSampler misalnya mungkin perlu dipasang dengan memanggil metode fit sebelum menggunakan. Di bawah ini adalah contoh untuk GaussianMixtureSampler .
> >> from pythae . models import AutoModel
> >> from pythae . samplers import GaussianMixtureSampler , GaussianMixtureSamplerConfig
> >> # Retrieve the trained model
>> > my_trained_vae = AutoModel . load_from_folder (
... 'path/to/your/trained/model'
... )
> >> # Define your sampler
... gmm_sampler_config = GaussianMixtureSamplerConfig (
... n_components = 10
... )
> >> my_samper = GaussianMixtureSampler (
... sampler_config = gmm_sampler_config ,
... model = my_trained_vae
... )
> >> # fit the sampler
>> > gmm_sampler . fit ( train_dataset )
> >> # Generate samples
>> > gen_data = my_samper . sample (
... num_samples = 50 ,
... batch_size = 10 ,
... output_dir = None ,
... return_gen = True
... )Pythae memberi Anda kemungkinan untuk mendefinisikan jaringan saraf Anda sendiri dalam model VAE. Misalnya, katakanlah Anda ingin melatih Wassertstein AE dengan enkoder dan dekoder tertentu, Anda dapat melakukan hal berikut:
> >> from pythae . models . nn import BaseEncoder , BaseDecoder
> >> from pythae . models . base . base_utils import ModelOutput
> >> class My_Encoder ( BaseEncoder ):
... def __init__ ( self , args = None ): # Args is a ModelConfig instance
... BaseEncoder . __init__ ( self )
... self . layers = my_nn_layers ()
...
... def forward ( self , x : torch . Tensor ) -> ModelOutput :
... out = self . layers ( x )
... output = ModelOutput (
... embedding = out # Set the output from the encoder in a ModelOutput instance
... )
... return output
...
... class My_Decoder ( BaseDecoder ):
... def __init__ ( self , args = None ):
... BaseDecoder . __init__ ( self )
... self . layers = my_nn_layers ()
...
... def forward ( self , x : torch . Tensor ) -> ModelOutput :
... out = self . layers ( x )
... output = ModelOutput (
... reconstruction = out # Set the output from the decoder in a ModelOutput instance
... )
... return output
...
> >> my_encoder = My_Encoder ()
> >> my_decoder = My_Decoder ()Dan sekarang bangun model
> >> from pythae . models import WAE_MMD , WAE_MMD_Config
> >> # Set up the model configuration
>> > my_wae_config = model_config = WAE_MMD_Config (
... input_dim = ( 1 , 28 , 28 ),
... latent_dim = 10
... )
...
> >> # Build the model
>> > my_wae_model = WAE_MMD (
... model_config = my_wae_config ,
... encoder = my_encoder , # pass your encoder as argument when building the model
... decoder = my_decoder # pass your decoder as argument when building the model
... ) Catatan Penting 1 : Untuk semua model berbasis AE (AE, WAE, RAE_L2, RAE_GP), baik encoder dan decoder harus mengembalikan instance ModelOutput . Untuk enkoder, instance ModelOutput harus berisi embeddings di bawah embedding kunci. Untuk dekoder, contoh ModelOutput harus berisi rekonstruksi di bawah reconstruction kunci.
Catatan Penting 2 : Untuk semua model berbasis VAE (VAE, Betavae, Iwae, HVAE, VAMP, RHVAE), baik encoder dan decoder harus mengembalikan contoh ModelOutput . Untuk encoder, contoh ModelOutput harus berisi matriks embbeddings dan log -covariance (bentuk batch_size x latent_space_dim) masing -masing di bawah kunci embedding dan log_covariance kunci. Untuk dekoder, contoh ModelOutput harus berisi rekonstruksi di bawah reconstruction kunci.
Anda juga dapat menemukan arsitektur jaringan saraf yang telah ditentukan sebelumnya untuk set data yang paling umum ( yaitu mnist, cifar, celeba ...) yang dapat dimuat sebagai berikut
> >> from pythae . models . nn . benchmark . mnist import (
... Encoder_Conv_AE_MNIST , # For AE based model (only return embeddings)
... Encoder_Conv_VAE_MNIST , # For VAE based model (return embeddings and log_covariances)
... Decoder_Conv_AE_MNIST
... )Ganti Mnist oleh Cifar atau Celeba untuk mengakses jaring saraf lainnya.
Pythae Pada v0.1.0 , Pythae sekarang mendukung pelatihan terdistribusi menggunakan DDP Pytorch. Ini memungkinkan Anda untuk melatih VAE favorit Anda lebih cepat dan pada dataset yang lebih besar menggunakan pelatihan multi-GPU dan/atau multi-node.
Untuk melakukannya, Anda dapat membangun skrip Python yang kemudian akan diluncurkan oleh peluncur (seperti srun pada cluster). Satu -satunya hal yang diperlukan dalam skrip adalah menentukan beberapa elemen relatif terhadap lingkungan terdistribusi (seperti jumlah node/GPU) secara langsung dalam konfigurasi pelatihan sebagai berikut
> >> training_config = BaseTrainerConfig (
... num_epochs = 10 ,
... learning_rate = 1e-3 ,
... per_device_train_batch_size = 64 ,
... per_device_eval_batch_size = 64 ,
... train_dataloader_num_workers = 8 ,
... eval_dataloader_num_workers = 8 ,
... dist_backend = "nccl" , # distributed backend
... world_size = 8 # number of gpus to use (n_nodes x n_gpus_per_node),
... rank = 5 # global gpu id,
... local_rank = 1 # gpu id within a node,
... master_addr = "localhost" # master address,
... master_port = "12345" # master port,
... ) Lihat contoh skrip ini yang mendefinisikan pelatihan multi-GPU VQVAE pada dataset Imagenet. Harap dicatat bahwa cara variabel lingkungan yang didistribusikan ( world_size , rank ...) dipulihkan mungkin spesifik untuk cluster dan peluncur yang Anda gunakan.
Di bawah ini diindikasikan waktu pelatihan untuk vektor kuantisasi VAE (VQ-VAE) dengan Pythae untuk 100 zaman pada Mnist pada V100 16GB GPU (s), untuk 50 zaman pada FFHQ (1024x1024 gambar) dan 20 zaman pada ImageNet-1K pada V100 32GB GPU (s).
| Data melatih | 1 GPU | 4 GPU | 2x4 GPU | |
|---|---|---|---|---|
| MNIST (VQ-VAE) | 28x28 gambar (50k) | 235.18 s | 62.00 s | 35.86 s |
| FFHQ 1024X1024 (VQVAE) | Gambar 1024x1024 RGB (60K) | 19 jam 1 menit | 5H 6 menit | 2H 37 menit |
| ImageNet-1K 128x128 (VQVAE) | Gambar 128x128 RGB (~ 1.2m) | 6h 25 menit | 1H 41 menit | 51 menit 26s |
Untuk setiap dataset, kami menyediakan skrip benchmarking di sini
Pythae juga memungkinkan Anda untuk berbagi model di hub Huggingface. Untuk melakukannya Anda butuhkan:
huggingface_hub diinstal di env virtual Anda. Jika tidak, Anda dapat menginstalnya dengan $ python -m pip install huggingface_hub
$ huggingface-cli login
Setiap model pythae dapat dengan mudah diunggah dengan menggunakan metode push_to_hf_hub
> >> my_vae_model . push_to_hf_hub ( hf_hub_path = "your_hf_username/your_hf_hub_repo" ) Catatan: Jika your_hf_hub_repo sudah ada dan tidak kosong, file akan ditimpa. Dalam kasus, repo your_hf_hub_repo tidak ada, folder yang memiliki nama yang sama akan dibuat.
Secara setara, Anda dapat mengunduh atau memuat ulang model Pythae apa pun langsung dari hub menggunakan metode load_from_hf_hub
> >> from pythae . models import AutoModel
> >> my_downloaded_vae = AutoModel . load_from_hf_hub ( hf_hub_path = "path_to_hf_repo" )wandb ?Pythae juga mengintegrasikan alat pelacak eksperimen Wandb yang memungkinkan pengguna untuk menyimpan konfigurasi mereka, memantau pelatihan mereka dan membandingkan berjalan melalui antarmuka grafis. Untuk dapat menggunakan fitur ini Anda akan membutuhkan:
wandb diinstal di env virtual Anda. Jika tidak, Anda dapat menginstalnya dengan $ pip install wandb
$ wandb login
WandbCallback Meluncurkan pemantauan percobaan dengan wandb di Pythae cukup sederhana. Satu -satunya hal yang perlu dilakukan pengguna adalah membuat instance WandbCallback ...
> >> # Create you callback
>> > from pythae . trainers . training_callbacks import WandbCallback
> >> callbacks = [] # the TrainingPipeline expects a list of callbacks
> >> wandb_cb = WandbCallback () # Build the callback
> >> # SetUp the callback
>> > wandb_cb . setup (
... training_config = your_training_config , # training config
... model_config = your_model_config , # model config
... project_name = "your_wandb_project" , # specify your wandb project
... entity_name = "your_wandb_entity" , # specify your wandb entity
... )
> >> callbacks . append ( wandb_cb ) # Add it to the callbacks list ... dan kemudian berikan ke TrainingPipeline .
> >> pipeline = TrainingPipeline (
... training_config = config ,
... model = model
... )
> >> pipeline (
... train_data = train_dataset ,
... eval_data = eval_dataset ,
... callbacks = callbacks # pass the callbacks to the TrainingPipeline and you are done!
... )
> >> # You can log to https://wandb.ai/your_wandb_entity/your_wandb_project to monitor your trainingLihat tutorial terperinci
mlflow ?Pythae juga mengintegrasikan alat pelacakan percobaan MLFLOW yang memungkinkan pengguna untuk menyimpan konfigurasi mereka, memantau pelatihan mereka dan membandingkan berjalan melalui antarmuka grafis. Untuk dapat menggunakan fitur ini Anda akan membutuhkan:
mlfow diinstal di env virtual Anda. Jika tidak, Anda dapat menginstalnya dengan $ pip install mlflow
MLFlowCallback Meluncurkan pemantauan percobaan dengan mlfow di Pythae cukup sederhana. Satu -satunya hal yang perlu dilakukan pengguna adalah membuat instance MLFlowCallback ...
> >> # Create you callback
>> > from pythae . trainers . training_callbacks import MLFlowCallback
> >> callbacks = [] # the TrainingPipeline expects a list of callbacks
> >> mlflow_cb = MLFlowCallback () # Build the callback
> >> # SetUp the callback
>> > mlflow_cb . setup (
... training_config = your_training_config , # training config
... model_config = your_model_config , # model config
... run_name = "mlflow_cb_example" , # specify your mlflow run
... )
> >> callbacks . append ( mlflow_cb ) # Add it to the callbacks list ... dan kemudian berikan ke TrainingPipeline .
> >> pipeline = TrainingPipeline (
... training_config = config ,
... model = model
... )
> >> pipeline (
... train_data = train_dataset ,
... eval_data = eval_dataset ,
... callbacks = callbacks # pass the callbacks to the TrainingPipeline and you are done!
... ) Anda dapat memvisualisasikan metrik Anda dengan menjalankan yang berikut di direktori di mana ./mlruns
$ mlflow ui Lihat tutorial terperinci
comet_ml ?Pythae juga mengintegrasikan alat pelacakan percobaan COMET_ML yang memungkinkan pengguna untuk menyimpan konfigurasi mereka, memantau pelatihan mereka dan membandingkan berjalan melalui antarmuka grafis. Untuk dapat menggunakan fitur ini Anda akan membutuhkan:
comet_ml yang diinstal di env virtual Anda. Jika tidak, Anda dapat menginstalnya dengan $ pip install comet_ml
CometCallback Meluncurkan pemantauan percobaan dengan comet_ml di Pythae cukup sederhana. Satu -satunya hal yang perlu dilakukan pengguna adalah membuat instance CometCallback ...
> >> # Create you callback
>> > from pythae . trainers . training_callbacks import CometCallback
> >> callbacks = [] # the TrainingPipeline expects a list of callbacks
> >> comet_cb = CometCallback () # Build the callback
> >> # SetUp the callback
>> > comet_cb . setup (
... training_config = training_config , # training config
... model_config = model_config , # model config
... api_key = "your_comet_api_key" , # specify your comet api-key
... project_name = "your_comet_project" , # specify your wandb project
... #offline_run=True, # run in offline mode
... #offline_directory='my_offline_runs' # set the directory to store the offline runs
... )
> >> callbacks . append ( comet_cb ) # Add it to the callbacks list ... dan kemudian berikan ke TrainingPipeline .
> >> pipeline = TrainingPipeline (
... training_config = config ,
... model = model
... )
> >> pipeline (
... train_data = train_dataset ,
... eval_data = eval_dataset ,
... callbacks = callbacks # pass the callbacks to the TrainingPipeline and you are done!
... )
> >> # You can log to https://comet.com/your_comet_username/your_comet_project to monitor your trainingLihat tutorial terperinci
Untuk membantu Anda memahami cara kerja Pythae dan bagaimana Anda dapat melatih model Anda dengan perpustakaan ini, kami juga menyediakan tutorial:
Making_your_own_autoencoder.ipynb menunjukkan kepada Anda cara meneruskan jaringan Anda sendiri ke model yang diimplementasikan di Pythae
custom_dataset.ipynb menunjukkan kepada Anda cara menggunakan kumpulan data khusus dengan salah satu model yang diimplementasikan dalam pythae
hf_hub_models_sharing.ipynb menunjukkan kepada Anda cara mengunggah dan mengunduh model untuk hub huggingface
wandb_experiment_monitoring.ipynb menunjukkan kepada Anda cara memantau Anda eksperimen menggunakan wandb
mlflow_experiment_monitoring.ipynb menunjukkan kepada Anda cara memantau Anda eksperimen menggunakan mlflow
comet_experiment_monitoring.ipynb menunjukkan kepada Anda cara memantau Anda eksperimen menggunakan comet_ml
Folder Models_training menyediakan buku catatan yang menunjukkan cara melatih setiap model yang diimplementasikan dan cara mencicipinya menggunakan pythae.samplers .
Folder skrip memberikan contoh khusus dari skrip pelatihan untuk melatih model pada set data benchmark (MNIST, CIFAR10, Celeba ...)
Jika Anda mengalami masalah apa pun saat menjalankan kode atau meminta fitur/model baru untuk diimplementasikan, buka masalah di GitHub.
Anda ingin berkontribusi ke perpustakaan ini dengan menambahkan model, sampler atau hanya memperbaiki bug? Itu luar biasa! Terima kasih! Silakan lihat Contributing.md untuk mengikuti pedoman yang berkontribusi utama.
Pertama mari kita lihat sampel yang direkonstruksi yang diambil dari set evaluasi.
| Model | Mnist | Celeba |
|---|---|---|
| Evaluasi data |  |  |
| AE |  |  |
| Vae |  |  |
| Beta-vae |  |  |
| VAE Lin NF |  |  |
| Vae IAF |  |  |
| Disentangled beta-vae |  |  |
| Factorvae |  |  |
| Betatcvae |  |  |
| Iwae |  |  |
| Msssim_vae |  |  |
| Wae |  |  |
| Info vae |  |  |
| MENGGODA |  |  |
| Svae |  |  |
| Presperarial_ae |  |  |
| Vae_gan |  |  |
| VQVAE |  |  |
| Hvae |  |  |
| Rae_l2 |  |  |
| Rae_gp |  |  |
| Riemannian Hamiltonian Vae (RHVAE) |  |  |
Di sini, kami menunjukkan sampel yang dihasilkan menggunakan setiap model yang diimplementasikan di perpustakaan dan sampler yang berbeda.
| Model | Mnist | Celeba |
|---|---|---|
| AE + GaussianMixturesampler |  |  |
| VAE + Normalsampler |  |  |
| VAE + GaussianMixturesampler |  |  |
| Vae + TwostageVaesampler |  |  |
| Vae + Mafsampler |  |  |
| Beta-vae + normalsampler | 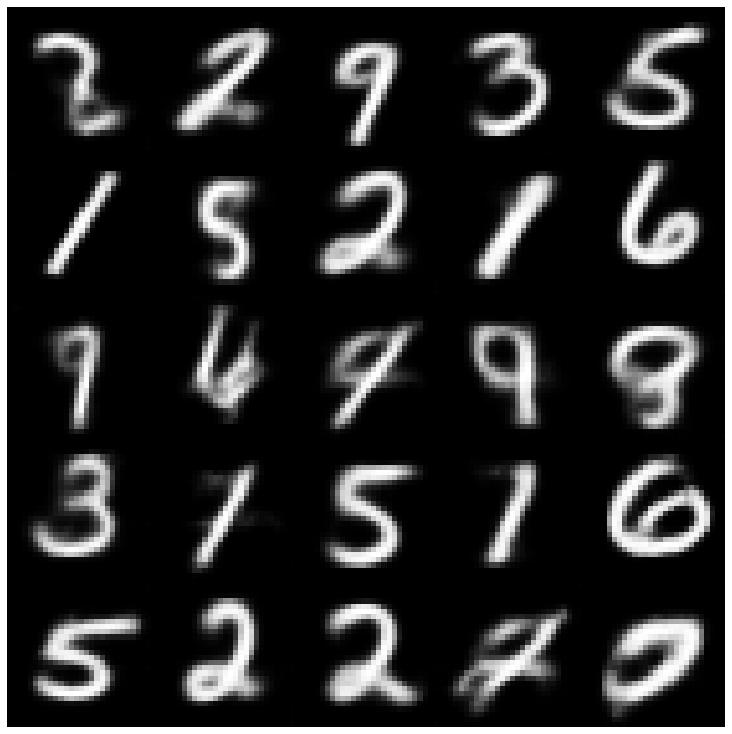 |  |
| Vae lin nf + normalsampler |  |  |
| Vae IAF + Normalsampler |  |  |
| Disentangled beta-vae + normalsampler |  |  |
| Factorvae + normalsampler |  |  |
| Betatcvae + Normalsampler |  |  |
| Iwae + sampler normal |  |  |
| MSSSIM_VAE + Normalsampler |  |  |
| Wae + normalsampler |  |  |
| Info vae + normalsampler |  |  |
| SVAE + HypershereUniformSampler |  |  |
| VAMP + VAMPSAMPLER |  |  |
| Presperarial_ae + Normalsampler |  |  |
| Vaegan + Normalsampler |  |  |
| VQVAE + MAFSAMPLER |  |  |
| Hvae + normalsampler |  |  |
| Rae_l2 + gaussianmixturesampler |  |  |
| Rae_gp + gaussianmixturesampler |  |  |
| Riemannian Hamiltonian Vae (rhvae) + rhvae sampler |  |  |
Jika Anda menemukan pekerjaan ini bermanfaat atau menggunakannya dalam riset Anda, silakan pertimbangkan mengutip kami
@inproceedings { chadebec2022pythae ,
author = { Chadebec, Cl'{e}ment and Vincent, Louis and Allassonniere, Stephanie } ,
booktitle = { Advances in Neural Information Processing Systems } ,
editor = { S. Koyejo and S. Mohamed and A. Agarwal and D. Belgrave and K. Cho and A. Oh } ,
pages = { 21575--21589 } ,
publisher = { Curran Associates, Inc. } ,
title = { Pythae: Unifying Generative Autoencoders in Python - A Benchmarking Use Case } ,
volume = { 35 } ,
year = { 2022 }
}

