benchmark_VAE
Pythae 0.1.2
الوثائق
تنفذ هذه المكتبة بعضًا من نماذج المشفر التلقائي الأكثر شيوعًا (التباين) تحت تطبيق موحد. على وجه الخصوص ، فإنه يوفر إمكانية إجراء تجارب ومقارنات قياسية من خلال تدريب النماذج على نفس بنية الشبكة العصبية للتشفير التلقائي. تتيح لك الميزة التي تصنع Autoencoder الخاص بك تدريب أي من هذه النماذج مع بياناتك الخاصة والشبكات العصبية الخاصة بك ودلو المدجرة. يدمج أدوات مراقبة التجربة مثل wandb أو mlflow أو Comet-ML؟ ويسمح بمشاركة النماذج والتحميل من مركز Huggingface؟ في بضعة أسطر من التعليمات البرمجية.
أخبار ؟
اعتبارًا من V0.1.0 ، تدعم Pythae الآن التدريب الموزع باستخدام DDP Pytorch. يمكنك الآن تدريب VAE المفضل لديك بشكل أسرع وعلى مجموعات بيانات أكبر ، لا يزال مع بضعة أسطر من التعليمات البرمجية. انظر معيارنا السريع.
wandb / التجربة مع تتبع mlflow / التجربة مع comet_ml لتثبيت أحدث إصدار مستقر من هذه المكتبة تشغيل ما يلي باستخدام pip
$ pip install pythae لتثبيت أحدث إصدار من GitHub من هذه المكتبة ، قم بتشغيل ما يلي باستخدام pip
$ pip install git+https://github.com/clementchadebec/benchmark_VAE.gitأو بدلاً من ذلك ، يمكنك استنساخ Github Repo للوصول إلى الاختبارات والدروس والبرامج النصية.
$ git clone https://github.com/clementchadebec/benchmark_VAE.gitوتثبيت المكتبة
$ cd benchmark_VAE
$ pip install -e . فيما يلي قائمة النماذج التي تم تنفيذها حاليًا في المكتبة.
| النماذج | مثال التدريب | ورق | التنفيذ الرسمي |
|---|---|---|---|
| Autoencoder (AE) | |||
| أدوات تلقائية التباين (VAE) | وصلة | ||
| Autoencoder الاختلاف التجريبي (Betavae) | وصلة | ||
| VAE مع تدفقات التطبيع الخطية (VAE_LINNF) | وصلة | ||
| vae مع تدفقات الانحدار التلقائي العكسي (VAE_IAF) | وصلة | وصلة | |
| Disentangled Beta Variational Autoencoder (DisentangledBetavae) | وصلة | ||
| تفكيك عن طريق عوامل (Factorvae) | وصلة | ||
| بيتا-TC-vae (Betatcvae) | وصلة | وصلة | |
| أهمية مرجحة تلقائية (IWAE) | وصلة | وصلة | |
| ضاعف الأهمية ذات الأهمية المرجحة (miwae) | وصلة | ||
| الأهمية الجزئية مرجحة مرجحة (piwae) | وصلة | ||
| الجمع بين الأهمية المرجحة Autoender (CIWAE) | وصلة | ||
| VAE مع تشابه متري إدراكي (MSSSIM_VAE) | وصلة | ||
| Wasserstein Autoencoder (WAE) | وصلة | وصلة | |
| info variational autoencoder (infovae_mmd) | وصلة | ||
| Vamp Autoencoder (Vamp) | وصلة | وصلة | |
| VAE الفائقة (SVAE) | وصلة | وصلة | |
| Poincaré Disk Vae (Poincarevae) | وصلة | وصلة | |
| Autoenderial Autoender (inversarial_ae) | وصلة | ||
| التباين التلقائي GAN (Vaegan)؟ | وصلة | وصلة | |
| ناقل VAE (vqvae) | وصلة | وصلة | |
| هاميلتون VAE (HVAE) | وصلة | وصلة | |
| منظم AE مع Decoder L2 Param (RAE_L2) | وصلة | وصلة | |
| منظم AE مع عقوبة التدرج (RAE_GP) | وصلة | وصلة | |
| ريمانيان هاملتون فاي (rhvae) | وصلة | وصلة | |
| الكمي المتبقي الهرمي (HRQVAE) | وصلة | وصلة |
انظر نتائج إعادة الإعمار وتوليد جميع النماذج المذكورة أعلاه
فيما يلي قائمة النماذج التي تم تنفيذها حاليًا في المكتبة.
| عينات | النماذج | ورق | التنفيذ الرسمي |
|---|---|---|---|
| قبل العادي (NormalSampler) | جميع النماذج | وصلة | |
| مزيج غاوسي (Gaussianmixturesampler) | جميع النماذج | وصلة | وصلة |
| مرحلتين VAE SAMPLER (TWOSTAGEVAESAMPLER) | جميع النماذج القائمة على VAE | وصلة | وصلة |
| عينة وحدة موحدة وحدة (hypersphereiforiformsampler) | svae | وصلة | وصلة |
| Poincaré Disk Sampler (PoincaredIsksampler) | Poincarevae | وصلة | وصلة |
| عينات VAMP السابقة (VampSampler) | تغوي الرجال | وصلة | وصلة |
| عينة متعددة (Rhvaesampler) | rhvae | وصلة | وصلة |
| عينات التدفق الذاتي المقنعة (mafsampler) | جميع النماذج | وصلة | وصلة |
| عاكسة عكس تدفق التدفق التلقائي (IAFSampler) | جميع النماذج | وصلة | وصلة |
| pixelcnn (pixelcnnsampler) | vqvae | وصلة |
نحن نتحقق من صحة التطبيقات من خلال إعادة إنتاج بعض النتائج المقدمة في المنشورات الأصلية عندما تم إصدار الرمز الرسمي أو عندما تتوفر تفاصيل كافية حول القسم التجريبي من الأوراق. انظر استنساخ لمزيد من التفاصيل.
لإطلاق تدريب نموذجية ، تحتاج فقط إلى استدعاء مثيل TrainingPipeline .
> >> from pythae . pipelines import TrainingPipeline
> >> from pythae . models import VAE , VAEConfig
> >> from pythae . trainers import BaseTrainerConfig
> >> # Set up the training configuration
>> > my_training_config = BaseTrainerConfig (
... output_dir = 'my_model' ,
... num_epochs = 50 ,
... learning_rate = 1e-3 ,
... per_device_train_batch_size = 200 ,
... per_device_eval_batch_size = 200 ,
... train_dataloader_num_workers = 2 ,
... eval_dataloader_num_workers = 2 ,
... steps_saving = 20 ,
... optimizer_cls = "AdamW" ,
... optimizer_params = { "weight_decay" : 0.05 , "betas" : ( 0.91 , 0.995 )},
... scheduler_cls = "ReduceLROnPlateau" ,
... scheduler_params = { "patience" : 5 , "factor" : 0.5 }
... )
> >> # Set up the model configuration
>> > my_vae_config = model_config = VAEConfig (
... input_dim = ( 1 , 28 , 28 ),
... latent_dim = 10
... )
> >> # Build the model
>> > my_vae_model = VAE (
... model_config = my_vae_config
... )
> >> # Build the Pipeline
>> > pipeline = TrainingPipeline (
... training_config = my_training_config ,
... model = my_vae_model
... )
> >> # Launch the Pipeline
>> > pipeline (
... train_data = your_train_data , # must be torch.Tensor, np.array or torch datasets
... eval_data = your_eval_data # must be torch.Tensor, np.array or torch datasets
... ) في نهاية التدريب ، يتم تخزين أفضل أوزان النموذج وتكوين النماذج وتكوين التدريب في مجلد final_model المتوفر في my_model/MODEL_NAME_training_YYYY-MM-DD_hh-mm-ss (مع وجود my_model كونه وسيطة output_dir من BaseTrainerConfig ). إذا قمت بتعيين وسيطة steps_saving إلى قيمة معينة ، فإن المجلدات المسماة checkpoint_epoch_k التي تحتوي على أفضل أوزان النموذج ، المحسّن ، الجدولة ، التكوين والتكوين التدريبي في Epoch K ، ستظهر أيضًا في my_model/MODEL_NAME_training_YYYY-MM-DD_hh-mm-ss .
نقدم أيضًا مثالًا على برنامج تدريبي هنا يمكن استخدامه لتدريب النماذج على مجموعات بيانات المعايير (Mnist ، CIFAR10 ، Celeba ...). يمكن إطلاق البرنامج النصي مع سطر الأوامر التالي
python training.py --dataset mnist --model_name ae --model_config ' configs/ae_config.json ' --training_config ' configs/base_training_config.json 'انظر readme.md لمزيد من التفاصيل حول هذا البرنامج النصي
GenerationPipeline تتكون أسهل طريقة لإطلاق توليد البيانات من نموذج مدرب في استخدام GenerationPipeline المدمج المقدم في Pythae. لنفترض أنك ترغب في إنشاء 100 عينة باستخدام MAFSampler كل ما عليك فعله هو 1) Relaod the Model Trained ، 2) تحديد تكوين العينات و 3) إنشاء وبدء تشغيل GenerationPipeline على النحو التالي
> >> from pythae . models import AutoModel
> >> from pythae . samplers import MAFSamplerConfig
> >> from pythae . pipelines import GenerationPipeline
> >> # Retrieve the trained model
>> > my_trained_vae = AutoModel . load_from_folder (
... 'path/to/your/trained/model'
... )
> >> my_sampler_config = MAFSamplerConfig (
... n_made_blocks = 2 ,
... n_hidden_in_made = 3 ,
... hidden_size = 128
... )
> >> # Build the pipeline
>> > pipe = GenerationPipeline (
... model = my_trained_vae ,
... sampler_config = my_sampler_config
... )
> >> # Launch data generation
>> > generated_samples = pipe (
... num_samples = args . num_samples ,
... return_gen = True , # If false returns nothing
... train_data = train_data , # Needed to fit the sampler
... eval_data = eval_data , # Needed to fit the sampler
... training_config = BaseTrainerConfig ( num_epochs = 200 ) # TrainingConfig to use to fit the sampler
... )بدلاً من ذلك ، يمكنك تشغيل عملية توليد البيانات من نموذج مدرب مباشرة مع أخذ العينات. على سبيل المثال ، لإنشاء بيانات جديدة باستخدام أخذ العينات الخاص بك ، قم بتشغيل ما يلي.
> >> from pythae . models import AutoModel
> >> from pythae . samplers import NormalSampler
> >> # Retrieve the trained model
>> > my_trained_vae = AutoModel . load_from_folder (
... 'path/to/your/trained/model'
... )
> >> # Define your sampler
>> > my_samper = NormalSampler (
... model = my_trained_vae
... )
> >> # Generate samples
>> > gen_data = my_samper . sample (
... num_samples = 50 ,
... batch_size = 10 ,
... output_dir = None ,
... return_gen = True
... ) إذا قمت بتعيين output_dir على مسار معين ، فسيتم حفظ الصور التي تم إنشاؤها كملفات .png المسمى 00000000.png ، 00000001.png ... يمكن استخدام العينات مع أي نموذج طالما كان مناسبًا. على سبيل المثال ، يمكن استخدام مثيل GaussianMixtureSampler لتوليده من أي نموذج ولكن لن يكون VAMPSampler قابلاً للاستخدام إلا مع نموذج VAMP . تحقق هنا لمعرفة أي منها ينطبق على النموذج الخاص بك. احرص على أن بعض العينات مثل GaussianMixtureSampler على سبيل المثال قد تحتاج إلى تركيب عن طريق استدعاء طريقة fit قبل الاستخدام. فيما يلي مثال على GaussianMixtureSampler .
> >> from pythae . models import AutoModel
> >> from pythae . samplers import GaussianMixtureSampler , GaussianMixtureSamplerConfig
> >> # Retrieve the trained model
>> > my_trained_vae = AutoModel . load_from_folder (
... 'path/to/your/trained/model'
... )
> >> # Define your sampler
... gmm_sampler_config = GaussianMixtureSamplerConfig (
... n_components = 10
... )
> >> my_samper = GaussianMixtureSampler (
... sampler_config = gmm_sampler_config ,
... model = my_trained_vae
... )
> >> # fit the sampler
>> > gmm_sampler . fit ( train_dataset )
> >> # Generate samples
>> > gen_data = my_samper . sample (
... num_samples = 50 ,
... batch_size = 10 ,
... output_dir = None ,
... return_gen = True
... )يوفر لك Pythae إمكانية تحديد الشبكات العصبية الخاصة بك داخل نماذج VAE. على سبيل المثال ، لنفترض أنك تريد تدريب Wassertstein Ae مع تشفير معين ودلو المدافع ، يمكنك القيام بما يلي:
> >> from pythae . models . nn import BaseEncoder , BaseDecoder
> >> from pythae . models . base . base_utils import ModelOutput
> >> class My_Encoder ( BaseEncoder ):
... def __init__ ( self , args = None ): # Args is a ModelConfig instance
... BaseEncoder . __init__ ( self )
... self . layers = my_nn_layers ()
...
... def forward ( self , x : torch . Tensor ) -> ModelOutput :
... out = self . layers ( x )
... output = ModelOutput (
... embedding = out # Set the output from the encoder in a ModelOutput instance
... )
... return output
...
... class My_Decoder ( BaseDecoder ):
... def __init__ ( self , args = None ):
... BaseDecoder . __init__ ( self )
... self . layers = my_nn_layers ()
...
... def forward ( self , x : torch . Tensor ) -> ModelOutput :
... out = self . layers ( x )
... output = ModelOutput (
... reconstruction = out # Set the output from the decoder in a ModelOutput instance
... )
... return output
...
> >> my_encoder = My_Encoder ()
> >> my_decoder = My_Decoder ()والآن بناء النموذج
> >> from pythae . models import WAE_MMD , WAE_MMD_Config
> >> # Set up the model configuration
>> > my_wae_config = model_config = WAE_MMD_Config (
... input_dim = ( 1 , 28 , 28 ),
... latent_dim = 10
... )
...
> >> # Build the model
>> > my_wae_model = WAE_MMD (
... model_config = my_wae_config ,
... encoder = my_encoder , # pass your encoder as argument when building the model
... decoder = my_decoder # pass your decoder as argument when building the model
... ) ملاحظة مهمة 1 : بالنسبة لجميع النماذج المستندة إلى AE (AE ، WAE ، RAE_L2 ، RAE_GP) ، يجب على كل من المشفر وفرق الترميز إرجاع مثيل ModelOutput . بالنسبة للمشفر ، يجب أن يحتوي مثيل ModelOutput على الأسس تحت embedding المفتاح. بالنسبة إلى وحدة فك الترميز ، يجب أن يحتوي مثيل ModelOutput على عمليات إعادة البناء تحت reconstruction المفتاح.
ملاحظة مهمة 2 : بالنسبة لجميع النماذج المستندة إلى VAE (VAE ، Betavae ، IWAE ، HVAE ، VAMP ، RHVAE) ، يجب على كل من التشفير وفرق الترميز إرجاع مثيل ModelOutput . بالنسبة للمشفر ، يجب أن يحتوي مثيل ModelOutput على غرزات السجاز ومصفوفات السجل (من شكل batch_size x latent_space_dim) على التوالي تحت مفتاح embedding المفتاح و log_covariance . بالنسبة إلى وحدة فك الترميز ، يجب أن يحتوي مثيل ModelOutput على عمليات إعادة البناء تحت reconstruction المفتاح.
يمكنك أيضًا العثور على بنيات الشبكة العصبية المحددة مسبقًا لمجموعات البيانات الأكثر شيوعًا ( أي mnist ، cifar ، celeba ...) التي يمكن تحميلها على النحو التالي
> >> from pythae . models . nn . benchmark . mnist import (
... Encoder_Conv_AE_MNIST , # For AE based model (only return embeddings)
... Encoder_Conv_VAE_MNIST , # For VAE based model (return embeddings and log_covariances)
... Decoder_Conv_AE_MNIST
... )استبدل Mnist بواسطة Cifar أو Celeba للوصول إلى الشباك العصبية الأخرى.
Pythae اعتبارًا من v0.1.0 ، تدعم Pythae الآن التدريب الموزع باستخدام DDP Pytorch. يتيح لك تدريب VAE المفضل لديك بشكل أسرع وعلى مجموعة بيانات أكبر باستخدام تدريب متعدد GPU و/أو متعدد العقدة.
للقيام بذلك ، يمكنك بناء نص Python الذي سيتم إطلاقه بواسطة قاذفة (مثل srun على مجموعة). الشيء الوحيد المطلوب في البرنامج النصي هو تحديد بعض العناصر المتعلقة بالبيئة الموزعة (مثل عدد العقد/وحدات معالجة الرسومات) مباشرة في تكوين التدريب على النحو التالي
> >> training_config = BaseTrainerConfig (
... num_epochs = 10 ,
... learning_rate = 1e-3 ,
... per_device_train_batch_size = 64 ,
... per_device_eval_batch_size = 64 ,
... train_dataloader_num_workers = 8 ,
... eval_dataloader_num_workers = 8 ,
... dist_backend = "nccl" , # distributed backend
... world_size = 8 # number of gpus to use (n_nodes x n_gpus_per_node),
... rank = 5 # global gpu id,
... local_rank = 1 # gpu id within a node,
... master_addr = "localhost" # master address,
... master_port = "12345" # master port,
... ) راجع هذا البرنامج النصي الذي يحدد تدريبًا متعدد GPU VQVAE على مجموعة بيانات ImageNet. يرجى ملاحظة أن الطريقة التي يتم بها استرداد متغيرات البيئة الموزعة ( world_size ، rank ...) قد تكون خاصة بالمجموعة والمشرفات التي تستخدمها.
فيما يلي أوقات التدريب لقياس VAE الكمي المتجه (VQ-VAE) مع Pythae لـ 100 عصر على MNIST على V100 16GB GPU (S) ، مقابل 50 عصرًا على FFHQ (1024x1024 صور) وللصور على Imagenet-1K على V100 32GB GPU (S).
| تدريب البيانات | 1 GPU | 4 وحدات معالجة الرسومات | 2x4 وحدات معالجة الرسومات | |
|---|---|---|---|---|
| Mnist (VQ-VAE) | 28x28 صور (50 ك) | 235.18 ق | 62.00 ق | 35.86 ق |
| FFHQ 1024x1024 (VQVAE) | 1024x1024 صور RGB (60K) | 19H 1 دقيقة | 5h 6min | 2H 37 دقيقة |
| ImageNet-1k 128x128 (Vqvae) | 128x128 صور RGB (~ 1.2M) | 6H 25 دقيقة | 1H 41min | 51min 26s |
لكل مجموعة بيانات ، نقدم البرامج النصية القياسية هنا
يسمح لك Pythae أيضًا بمشاركة النماذج الخاصة بك على مركز Huggingface. للقيام بذلك تحتاج:
huggingface_hub مثبتة في ENV الظاهري. إذا لم يكن بإمكانك تثبيته مع $ python -m pip install huggingface_hub
$ huggingface-cli login
يمكن تحميل أي طراز Pythae بسهولة باستخدام Method push_to_hf_hub
> >> my_vae_model . push_to_hf_hub ( hf_hub_path = "your_hf_username/your_hf_hub_repo" ) ملاحظة: في حالة وجودك your_hf_hub_repo بالفعل وليس فارغًا ، فسيتم تجاوز الملفات. في حالة عدم وجود repo your_hf_hub_repo ، سيتم إنشاء مجلد له نفس الاسم.
على ما يعادل ، يمكنك تنزيل أو إعادة تحميل أي نموذج Pythae مباشرة من المحور باستخدام Method load_from_hf_hub
> >> from pythae . models import AutoModel
> >> my_downloaded_vae = AutoModel . load_from_hf_hub ( hf_hub_path = "path_to_hf_repo" )wandb ؟يدمج Pythae أيضًا أداة تتبع التجربة WANDB مما يسمح للمستخدمين بتخزين تكويناتهم ومراقبة تدريباتهم ومقارنة عمليات التشغيل عبر واجهة رسومية. لتتمكن من استخدام هذه الميزة ستحتاج إليها:
wandb مثبتة في ENV الظاهري الخاص بك. إذا لم يكن بإمكانك تثبيته مع $ pip install wandb
$ wandb login
WandbCallback إن إطلاق تجربة مراقبة مع wandb في Pythae أمر بسيط للغاية. الشيء الوحيد الذي يحتاج المستخدم إلى القيام به هو إنشاء مثيل WandbCallback ...
> >> # Create you callback
>> > from pythae . trainers . training_callbacks import WandbCallback
> >> callbacks = [] # the TrainingPipeline expects a list of callbacks
> >> wandb_cb = WandbCallback () # Build the callback
> >> # SetUp the callback
>> > wandb_cb . setup (
... training_config = your_training_config , # training config
... model_config = your_model_config , # model config
... project_name = "your_wandb_project" , # specify your wandb project
... entity_name = "your_wandb_entity" , # specify your wandb entity
... )
> >> callbacks . append ( wandb_cb ) # Add it to the callbacks list ... ثم تمريرها إلى TrainingPipeline .
> >> pipeline = TrainingPipeline (
... training_config = config ,
... model = model
... )
> >> pipeline (
... train_data = train_dataset ,
... eval_data = eval_dataset ,
... callbacks = callbacks # pass the callbacks to the TrainingPipeline and you are done!
... )
> >> # You can log to https://wandb.ai/your_wandb_entity/your_wandb_project to monitor your trainingانظر البرنامج التعليمي التفصيلي
mlflow ؟يدمج Pythae أيضًا أداة تتبع التجربة MLFlow مما يتيح للمستخدمين تخزين تكويناتهم ومراقبة تدريباتهم ومقارنة عمليات التشغيل عبر واجهة رسومية. لتتمكن من استخدام هذه الميزة ستحتاج إليها:
mlfow مثبتة في ENV الظاهري الخاص بك. إذا لم يكن بإمكانك تثبيته مع $ pip install mlflow
MLFlowCallback إن إطلاق تجربة مراقبة مع mlfow في Pythae أمر بسيط للغاية. الشيء الوحيد الذي يحتاج المستخدم إلى القيام به هو إنشاء مثيل MLFlowCallback ...
> >> # Create you callback
>> > from pythae . trainers . training_callbacks import MLFlowCallback
> >> callbacks = [] # the TrainingPipeline expects a list of callbacks
> >> mlflow_cb = MLFlowCallback () # Build the callback
> >> # SetUp the callback
>> > mlflow_cb . setup (
... training_config = your_training_config , # training config
... model_config = your_model_config , # model config
... run_name = "mlflow_cb_example" , # specify your mlflow run
... )
> >> callbacks . append ( mlflow_cb ) # Add it to the callbacks list ... ثم تمريرها إلى TrainingPipeline .
> >> pipeline = TrainingPipeline (
... training_config = config ,
... model = model
... )
> >> pipeline (
... train_data = train_dataset ,
... eval_data = eval_dataset ,
... callbacks = callbacks # pass the callbacks to the TrainingPipeline and you are done!
... ) يمكنك تصور مقياسك عن طريق تشغيل ما يلي في الدليل حيث ./mlruns
$ mlflow ui انظر البرنامج التعليمي التفصيلي
comet_ml ؟يدمج Pythae أيضًا أداة تتبع التجربة Comet_ML مما يسمح للمستخدمين بتخزين التكوينات الخاصة بهم ومراقبة تدريباتهم ومقارنة عمليات التشغيل عبر واجهة رسومية. لتتمكن من استخدام هذه الميزة ستحتاج إليها:
comet_ml مثبتة في ENV الظاهري. إذا لم يكن بإمكانك تثبيته مع $ pip install comet_ml
CometCallback إن إطلاق تجربة مراقبة مع comet_ml في Pythae أمر بسيط للغاية. الشيء الوحيد الذي يحتاج المستخدم إلى القيام به هو إنشاء مثيل CometCallback ...
> >> # Create you callback
>> > from pythae . trainers . training_callbacks import CometCallback
> >> callbacks = [] # the TrainingPipeline expects a list of callbacks
> >> comet_cb = CometCallback () # Build the callback
> >> # SetUp the callback
>> > comet_cb . setup (
... training_config = training_config , # training config
... model_config = model_config , # model config
... api_key = "your_comet_api_key" , # specify your comet api-key
... project_name = "your_comet_project" , # specify your wandb project
... #offline_run=True, # run in offline mode
... #offline_directory='my_offline_runs' # set the directory to store the offline runs
... )
> >> callbacks . append ( comet_cb ) # Add it to the callbacks list ... ثم تمريرها إلى TrainingPipeline .
> >> pipeline = TrainingPipeline (
... training_config = config ,
... model = model
... )
> >> pipeline (
... train_data = train_dataset ,
... eval_data = eval_dataset ,
... callbacks = callbacks # pass the callbacks to the TrainingPipeline and you are done!
... )
> >> # You can log to https://comet.com/your_comet_username/your_comet_project to monitor your trainingانظر البرنامج التعليمي التفصيلي
لمساعدتك على فهم الطريقة التي يعمل بها Pythae وكيف يمكنك تدريب النماذج الخاصة بك مع هذه المكتبة ، نقدم أيضًا دروسًا تعليمية:
Make_your_own_autoencoder.ipynb يوضح لك كيفية تمرير شبكاتك الخاصة إلى النماذج التي تم تنفيذها في Pythae
يوضح لك custom_dataset.ipynb كيفية استخدام مجموعات البيانات المخصصة مع أي من النماذج التي تم تنفيذها في Pythae
يوضح لك HF_HUB_MODELS_SHARKING
Wandb_experiment_monitoring.ipynb يوضح لك كيفية مراقبة التجارب باستخدام wandb
mlflow_experiment_monitoring.ipynb يوضح لك كيفية مراقبة التجارب باستخدام mlflow
comet_experiment_monitoring.ipynb يوضح لك كيفية مراقبة التجارب باستخدام comet_ml
يوفر مجلد Models_training أجهزة الكمبيوتر المحمولة التي توضح كيفية تدريب كل نموذج تم تنفيذه وكيفية أخذ عينات منه باستخدام pythae.samplers .
يوفر مجلد البرامج النصية على وجه الخصوص مثالًا على البرنامج النصي التدريبي لتدريب النماذج على مجموعات البيانات القياسية (MNIST ، CIFAR10 ، CELEBA ...)
إذا كنت تواجه أي مشكلات أثناء تشغيل الرمز أو طلب ميزات/نماذج جديدة لتنفيذها ، فيرجى فتح مشكلة على GitHub.
تريد المساهمة في هذه المكتبة عن طريق إضافة نموذج أو أخذ عينات أو ببساطة إصلاح خطأ؟ هذا رائع! شكرًا لك! يرجى الاطلاع على المساهمة. md لمتابعة الإرشادات الرئيسية المساهمة.
أولاً ، دعونا نلقي نظرة على العينات التي أعيد بناؤها مأخوذة من مجموعة التقييم.
| النماذج | mnist | سيليبا |
|---|---|---|
| بيانات eval |  |  |
| Ae |  |  |
| vae |  |  |
| بيتا-فاي |  |  |
| vae lin nf |  |  |
| vae iaf |  |  |
| Disentangled بيتا-فاي |  |  |
| عامل |  |  |
| Betatcvae |  |  |
| iwae |  |  |
| MSSSIM_VAE |  |  |
| وا |  |  |
| معلومات VAE |  |  |
| تغوي الرجال |  |  |
| svae |  |  |
| inversarial_ae |  |  |
| vae_gan |  |  |
| vqvae |  |  |
| HVAE |  |  |
| RAE_L2 |  |  |
| RAE_GP |  |  |
| ريمانيان هاملتون فاي (rhvae) |  |  |
هنا ، نعرض العينات التي تم إنشاؤها باستخدام كل نموذج يتم تنفيذه في المكتبة وأخذ عينات مختلفة.
| النماذج | mnist | سيليبا |
|---|---|---|
| Ae + GaussianMixTuresAmpler |  |  |
| VAE + NormalSampler |  |  |
| vae + gaussianmixturesampler |  |  |
| VAE + TWOSTAGEVAESAMPLER |  |  |
| VAE + Mafsampler |  |  |
| بيتا-فاي + normalsampler | 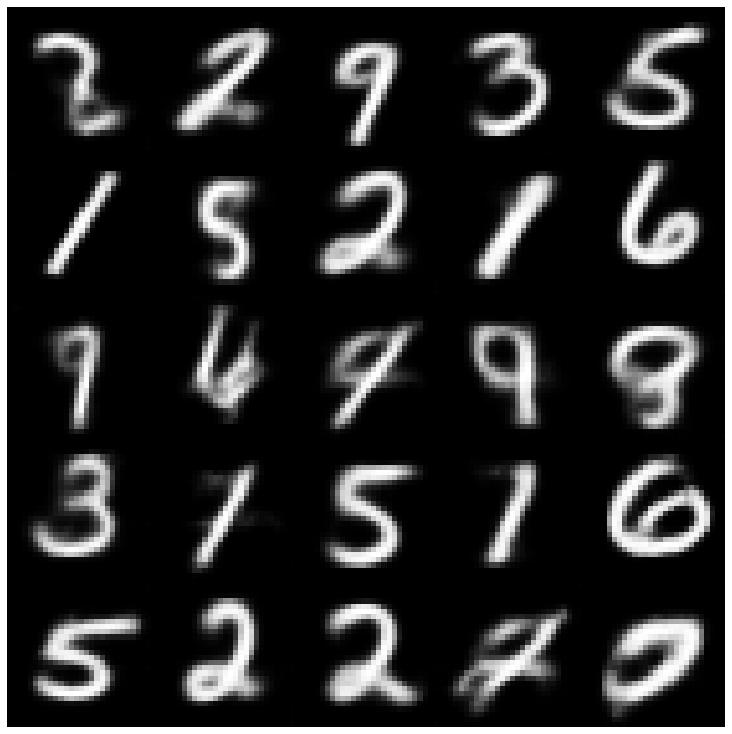 |  |
| vae lin nf + normalsampler |  |  |
| vae iaf + normalsampler |  |  |
| Disentangled Beta-vae + NormalsAmpler |  |  |
| Factorvae + NormalSampler |  |  |
| Betatcvae + NormalSampler |  |  |
| iwae + أخذ العينات العادية |  |  |
| MSSSIM_VAE + NormalSampler |  |  |
| WAE + NormalSampler |  |  |
| info vae + normalsampler |  |  |
| SVAE + hyperhyphyiformsampler |  |  |
| Vamp + Vampsampler |  |  |
| inversarial_ae + normalsampler |  |  |
| vaegan + normalsampler |  |  |
| vqvae + mafsampler |  |  |
| HVAE + NormalSampler |  |  |
| RAE_L2 + GaussianMixTuresAmpler |  |  |
| RAE_GP + GaussianMixTuresAmpler |  |  |
| ريمانيان هاميلتون فاي (rhvae) + rhvae sampler |  |  |
إذا وجدت هذا العمل مفيدًا أو استخدمه في بحثك ، فيرجى التفكير في الاستشهاد بنا
@inproceedings { chadebec2022pythae ,
author = { Chadebec, Cl'{e}ment and Vincent, Louis and Allassonniere, Stephanie } ,
booktitle = { Advances in Neural Information Processing Systems } ,
editor = { S. Koyejo and S. Mohamed and A. Agarwal and D. Belgrave and K. Cho and A. Oh } ,
pages = { 21575--21589 } ,
publisher = { Curran Associates, Inc. } ,
title = { Pythae: Unifying Generative Autoencoders in Python - A Benchmarking Use Case } ,
volume = { 35 } ,
year = { 2022 }
}

